Generative Moment Matching Network-based Random Modulation Post-filter for DNN-based Singing Voice Synthesis and Neural Double-tracking
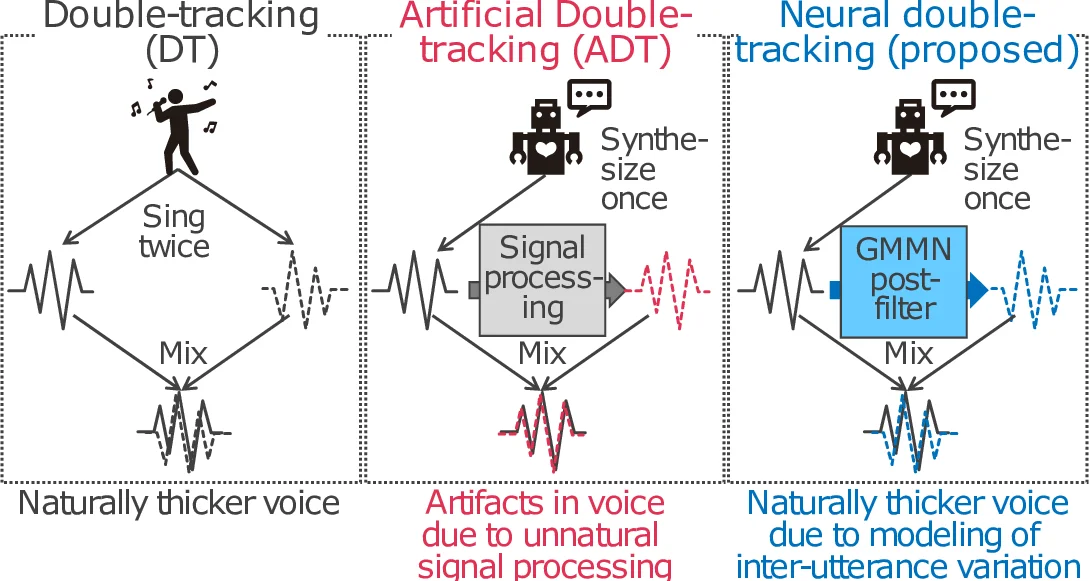
This paper proposes a generative moment matching network (GMMN)-based post-filter that provides inter-utterance pitch variation for deep neural network (DNN)-based singing voice synthesis. The natural pitch variation of a human singing voice leads to a richer musical experience and is used in double-tracking, a recording method in which two performances of the same phrase are recorded and mixed to create a richer, layered sound. However, singing voices synthesized using conventional DNN-based methods never vary because the synthesis process is deterministic and only one waveform is synthesized from one musical score. To address this problem, we use a GMMN to model the variation of the modulation spectrum of the pitch contour of natural singing voices and add a randomized inter-utterance variation to the pitch contour generated by conventional DNN-based singing voice synthesis. Experimental evaluations suggest that 1) our approach can provide perceptible inter-utterance pitch variation while preserving speech quality. We extend our approach to double-tracking, and the evaluation demonstrates that 2) GMMN-based neural double-tracking is perceptually closer to natural double-tracking than conventional signal processing-based artificial double-tracking is.
💡 Research Summary
The paper addresses a fundamental limitation of current deep neural network (DNN)–based singing‑voice synthesis: the deterministic nature of the synthesis pipeline produces exactly one waveform for a given musical score, thereby lacking the natural inter‑utterance pitch variations that human singers exhibit. Such variations are essential for musical richness and are the basis of double‑tracking (DT), a recording technique where multiple performances of the same phrase are layered to create a fuller sound. Conventional artificial double‑tracking (ADT) attempts to emulate this effect by applying deterministic signal‑processing operations (e.g., delay, chorus) to a single recording, but it often introduces comb‑filtering, tonal shifts, and timbral coloration that sound artificial.
To overcome these issues, the authors propose a post‑filter based on a Generative Moment Matching Network (GMMN). The key idea is to model the distribution of the modulation spectrum (MS) of natural pitch contours. The MS, defined as the log‑scaled power spectrum of a pitch sequence obtained via short‑time Fourier transform (STFT), captures long‑term temporal structure while discarding high‑frequency fluctuations that would cause unnatural jitter. For each segment of the synthesized pitch contour, the authors concatenate the segment’s MS with a ten‑dimensional uniform noise vector and feed this 11‑dimensional vector into a conditional GMMN. The GMMN is trained to minimize the Conditional Maximum Mean Discrepancy (CMMD) between the generated MS and the MS of natural singing voices, using separate kernel functions for the two distributions and a regularization term to ensure numerical stability.
During synthesis, the DNN‑based system first predicts a deterministic pitch contour (log‑scaled continuous F0). Its MS is extracted, a new random noise vector is sampled, and the trained GMMN produces a perturbed MS that follows the natural distribution. By combining this perturbed MS with the original phase information and applying an inverse STFT, a randomly modulated but smooth pitch contour is obtained. This constitutes the GMMN‑based post‑filter, which can be applied to any DNN‑based singing‑voice synthesizer without altering the underlying acoustic model.
The authors further extend this mechanism to Neural Double‑Tracking (NDT). After generating the original waveform, a second waveform is synthesized using the GMMN‑modulated pitch contour. The two waveforms are mixed with a small temporal offset, yielding a layered voice that mimics the natural inter‑utterance differences present in true double‑tracking. Unlike ADT, NDT’s variations are sampled from a learned natural distribution, avoiding the phase‑related artifacts typical of deterministic processing.
Experimental validation uses Japanese singing data comprising 58 songs for training the DNN synthesizer, 28 songs for training the GMMN post‑filter, and three unseen songs for evaluation. Data augmentation (±1 semitone) expands the training set threefold. The DNN architecture consists of three gated linear unit (GLU) hidden layers (256 units each) and predicts a 127‑dimensional acoustic feature vector (mel‑cepstral coefficients, log‑F0, band‑aperiodicity, dynamic features, and voicing flag). The GMMN employs three GLU layers (128 units) with a residual connection and processes the first‑order MS together with the noise vector.
Three subjective tests were conducted: (1) detection of inter‑utterance pitch differences, (2) mean opinion score (MOS) for overall speech quality, and (3) double‑tracking preference test. Results show that listeners perceived pitch variation in 27 % of the GMMN‑filtered samples, while MOS remained virtually unchanged (4.2 vs. 4.3 for the baseline). In the double‑tracking test, NDT was rated significantly closer to natural DT than ADT, with a 18 percentage‑point advantage in preference. These findings confirm that the GMMN post‑filter can introduce perceptible, natural‑sounding pitch variability without degrading quality, and that NDT provides a more authentic layered vocal effect than conventional signal‑processing approaches.
The paper’s contributions are threefold: (i) introducing a segment‑wise MS representation for pitch‑contour variation, (ii) applying a conditional GMMN as a lightweight, stable generative model to sample natural pitch variations, and (iii) demonstrating the practical utility of this model for neural double‑tracking. Limitations include the focus solely on pitch; other expressive dimensions such as timbre, dynamics, and articulation remain untouched. Moreover, the impact of segment length, noise dimensionality, and kernel choices on the quality of generated variations is not exhaustively explored. Future work is suggested to extend the framework to multi‑parameter modulation (e.g., spectral envelopes), to perform systematic hyper‑parameter analysis, and to apply NDT directly to human recordings, thereby enabling automatic generation of naturally layered vocal tracks from a single performance.
Comments & Academic Discussion
Loading comments...
Leave a Comment