SVD-PHAT: A Fast Sound Source Localization Method
This paper introduces a new localization method called SVD-PHAT. The SVD-PHAT method relies on Singular Value Decomposition of the SRP-PHAT projection matrix. A k-d tree is also proposed to speed up the search for the most likely direction of arrival…
Authors: Francois Grondin, James Glass
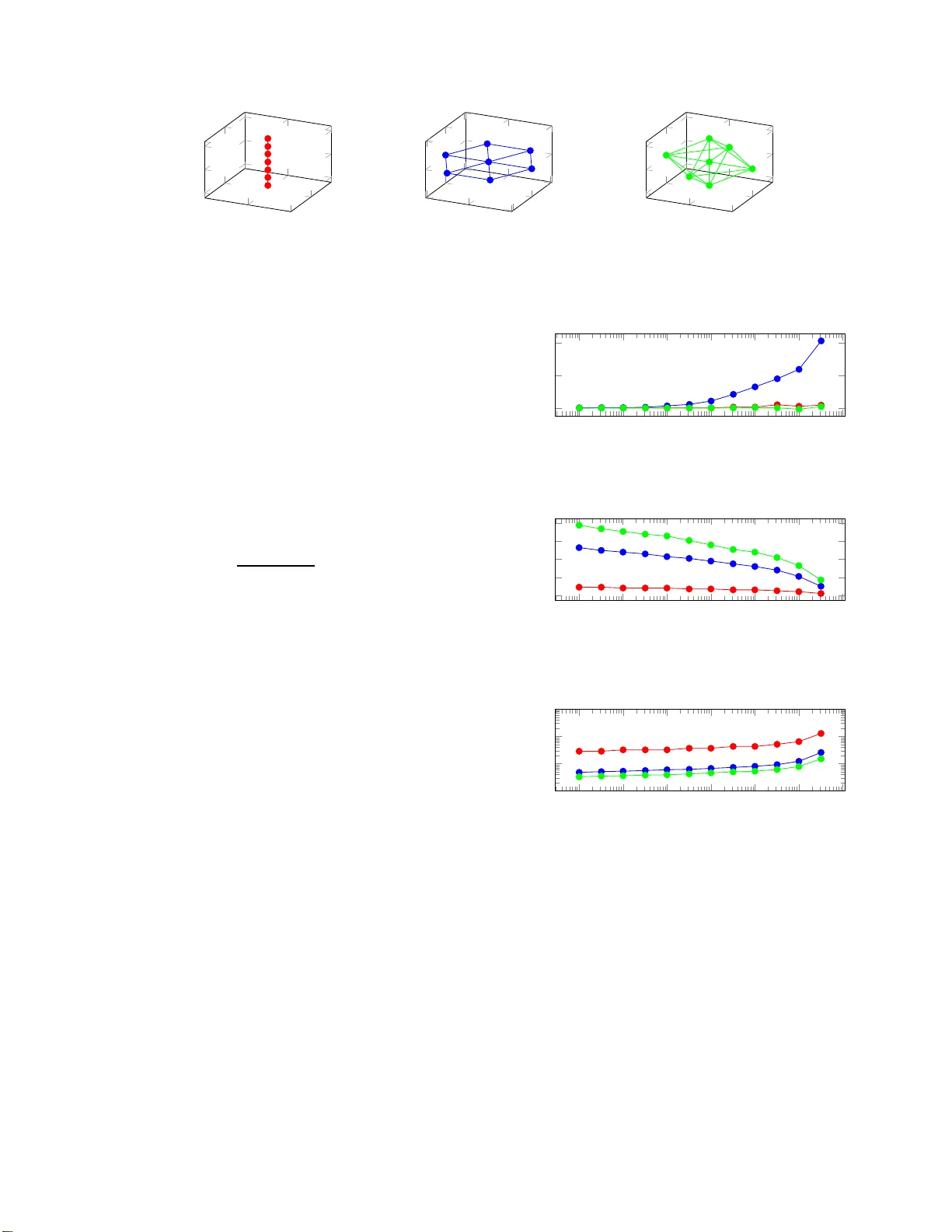
SVD-PHA T : A F AST SOUND SOURCE LOCALIZA TION METHOD F ranc ¸ ois Gr o ndin, J ames Glas s Computer Science and Artificial Intel l igence Laboratory Massachusetts Insti tute of T echnology Cambridge, MA 02139, USA { fgrondin,glass } @mi t.edu ABSTRA CT This paper intro duces a ne w localization metho d called SVD- PHA T . The SVD-PHA T method relies on Sing ular V alu e De- composition of the SRP-PHA T projectio n matr ix. A k-d tree is also propo sed to spee d up the sear c h for the m ost likely direction of arriv al o f sound. W e show that this method per- forms as accurately as SRP-PHA T , while reducin g sign ifi- cantly th e amo unt of com p utation requ ir ed. Index T erms — Sou n d Source Localization, SRP-PHA T , SVD-PHA T , Direction o f Ar r i val 1. INTR ODUCTION Distant speech processing is a ch allenging task, as the target sound source is u sually c orrupted b y n oise fr om the envi- ronmen t a nd is degraded by reverberation [1]. Beamforming methods are often used as a p reprocessing step to enhance the corrup ted speech signal using mu ltip le microp hones. Many beamformin g methods, suc h as Delay and Sum (DS), Geometric Sou rce Separation ( GSS) [2] and Minimu m V ari- ance Distortion less Respon se (MVDR) [3], require the target source direction o f arriv al (DOA). Sound source localization consists in estimating th is DO A, an d often relies on Multi- ple Sign al Classification (MUSIC) [4] o r Steered -Response Power Phase T ransform (SRP-PHA T) [5] meth ods. MUSIC is based on Standard Eigenvalue Deco m posi- tion (SEVD-MUSI C), and was initially used for narrowband signals, then adapted to broad band signals to m ake localiza- tion r o bust to additive no ise [6]. The latter method howe ver assumes tha t the target signal is m ore p owerful than noise. T o cope with this limitation, MUSIC based on Generalized Eigenv alu e Decompo sition (GEVD-MUSI C) hand les scenar- ios when n oise is m ore powerful th an the signal of interest [7]. Alternatively , MUSIC based on Ge n eralized Sing ular V alue Decomposition (SVD-MUSIC), red u ces the c omputa- tional lo ad of GEVD-MUSIC and improves DOA estimation accuracy [8]. Howe ver, all M U SI C-based methods require This work w as supported in pa rt by the T oyota R esearch Institute and by the Fonds de recherche du Qu ´ ebec - Nature et technol ogies. perfor ming onlin e eig en value or singular v alue decompo si- tions, which inv olve a significant amou n t o f computatio ns, and m a ke real-time pro cessing more challengin g. SRP-PHA T compu tes the Generalized Cross-Correlatio n with Phase T ransform (GCC-PHA T) b etween each pair of mi- cropho nes [9]. Th e exact SRP-PHA T solution in volves frac- tional T ime-Difference of Arriv al (TDOA) delays, and r e - quires a sign ificant amount of computatio n. The Fast Fourier T ransform (FFT) is th us often used to speed u p the comp uta- tion of GCC-PHA T , which makes this metho d appe a ling for real-time application s [ 10, 11]. Howe ver, u sing the FFT re- stricts the transfor m to discrete TDO A values, which r educes localization accuracy . Interpo lation [12, 13, 14], fractional delay estimation [15] and fractional Fourier tr ansform [16] attempt to overcome the FFT discretization drawback. More- over , searching for sound sou rce in volves a significant amount of c o mputations when scannin g the 3D-spac e . Stocha stic re- gion contraction [1 7], hierarchical search [18, 19, 20] and vectorization [21] are pr oposed to speed up scann ing, but are usually r e stricted to a 2D surface. In th is paper, we propo se a new method inspired f rom the original SRP-PHA T a p proach, called SVD-PHA T . The objective is to reduce th e am o unt of co mputations typically in volved in the exact SRP-PHA T , while preser v ing its accu- racy . The pro p osed techniq ue relies on SVD to generate a transform related to the matrix geometry that map s the ini- tial observations to a smaller sub space. This subspace is then searched with a k -d tree, which retu rns the estimated DO A. 2. SRP-PHA T SRP-PHA T relies on the TDOA estimation for all pairs of microph ones (for an a rray with M m icrophon es, the r e are P = M ( M − 1) / 2 possible pairs). The TDO A (in sec) corr e - sponds to the difference between the distan c e f rom th e source s q ∈ R 3 to micr ophone i at position r i ∈ R 3 , and th e distance between the same source and another microph one j at posi- tion r j ∈ R 3 , d i vided b y the speed of sound in air c ∈ R + (in m/sec). Sin c e all signals are discretized in time, it is also con- venient to express the TDO A in terms of samp les by adding the sample rate ( f S ∈ R + ) in the expression, as shown in ( 1). τ q,i,j = f S c ( k s q − r i k 2 − k s q − r j k 2 ) (1) where k . . . k 2 stands f or th e Eu c lidean nor m. In m ost microp hone arra y c o nfiguration s, the array aper- ture is small compa r ed to the distan ce between th e sou rce and the array , such that the farfield assum ption h olds. In th is case, (1) ca n b e fo rmulated as in (2). τ q,i,j = f S c ( r j − r i ) · s q k s q k 2 (2) Let x m [ n ] be the signal of m icrophon e m in the time do- main. The expression X l m [ k ] ∈ C is obtain ed with a Short T ime Fourier T ra nsform (STFT) with a sine window , where N ∈ N and ∆ N ∈ N stand for the fra m e and h o p sizes in samples, r especti vely , and k ∈ N ∩ [0 , N / 2] an d l ∈ N stand for the f requency bin and frame indexes, respectively . F o r clarity , the fram e ind ex l is o mitted in this pap er witho ut loss of gen erality . The n ormalized cross-spectrum for ea c h pair of m ic r ophone s ( i, j ) (wher e i 6 = j ) corr esponds to the ex- pression X i,j [ k ] ∈ C in (3). The operato rs { . . . } ∗ and | . . . | stand for the complex con jugate an d the ab solute value, re - spectiv ely . X i,j [ k ] = X i [ k ] X j [ k ] ∗ | X i [ k ] || X j [ k ] | (3) In the freque n cy domain , the T DO A τ q,i,j leads to the co - efficient W q,i,j [ k ] ∈ C in (4) acco rding to SRP-PHA T beam - forming . W q,i,j [ k ] = exp 2 π √ − 1 k τ q,i,j / N (4) For each poten tial source position located at s q , SRP- PHA T returns an energy value expressed by Y q ∈ R , where ℜ{ . . . } extracts the real p art. Y q = ℜ M X i =1 M X j =( i +1) N/ 2 X k =0 W q,i,j [ k ] X i,j [ k ] (5) The e stimated direction o f arrival (DO A ) of soun d cor r e- sponds to the position den oted by s ¯ q , where ¯ q is obtained in (6). Moreover, th e scalar Y ¯ q is of ten used to discriminate a valid so und sou rce fr om back groud noise. ¯ q = arg max q { Y q } (6) Computing Y q for q ∈ N ∩ [1 , Q ] as in (6) inv olves a complexity or der of O ( QP N ) , an d searching for th e b est po- tential source results in ( 6) lead s to a O ( Q ) search . When the numb er of p o ints to scan ( Q ) gets large, th e SRP-PHA T in volves n umerous computation s, which makes the m ethod less suitable for real-tim e ap p lications. Th e pr oposed SVD- PHA T method describe d in the n ext section aims to alleviate this limitatio n. 3. SVD-PHA T T o define the SVD-PHA T method, it is con venient to start from SRP-PHA T expressed in matrix for m. W e define the vector X ∈ C P ( N/ 2+1) × 1 in (7), wh ich concaten ates a ll no r - malized cr oss-spectra previously introduc e d in (3). X = X 1 , 2 [0] X 1 , 2 [1] · · · X M − 1 ,M [ N / 2] T (7) Similarly , the matrix W ∈ C Q × P ( N/ 2+1) holds all the SRP-PHA T coefficients: W = W 1 , 1 , 2 [0] W 1 , 1 , 2 [1] · · · W 1 ,M − 1 ,M [ N / 2] . . . . . . . . . . . . W Q, 1 , 2 [0] W Q, 1 , 2 [1] · · · W Q,M − 1 ,M [ N / 2] (8) Finally , th e vector Y ∈ C Q × 1 stores the SRP-PHA T en- ergy for all Q potential sources an d is o b tained fro m the fol- lowing matrix multiplication : Y = Y 1 . . . Y Q T = ℜ{ WX } (9) As mentionn ed for SRP-PHA T , this ma trix multiplicatio n is computation ally expensive when ther e are numer ous po - tential source po sitions to scan. T o cop e with this lim ita- tion, we pr opose to perfo rm Singular V alue Deco m position on the matrix W , where U ∈ C Q × K , S ∈ C K × K and V ∈ C P ( N/ 2+1) × K , as shown in (10). W ≈ USV H (10) where { . . . } H stands f or th e Herm itian opera to r . The param e ter K ∈ N ∩ ]0 , K max ] , where the up p er bound K max = max { Q, P ( N/ 2 + 1) } , is chosen to ensure accurate reconstru ction of W , acco rding to the co ndition in (11), wher e the user-defined param eter δ is a small positive value that m odels the toler able reconstru ction error . T h e op- erator T r { . . . } stand s for the trace of the matrix. T r { SS T } ≥ (1 − δ ) T r { WW H } (11) The vector Z ∈ C K × 1 results from the projection of the observations X in th e K -dime nsions subspace: Z = V H X (12) The matrix D ∈ C Q × K is obtain ed in (13) and can be decomp o sed in a set o f Q vectors D q ∈ C 1 × K : D = US = D T 1 D T 2 . . . D T Q T (13) The index of the most likely DO A obtained in (6) no w correspo n ds to : ¯ q = ar g max q {ℜ{ D q · Z H }} (14) One way to find the corr ect value o f q in (14) consists in computin g ev ery Y q for q ∈ N ∩ [1 , Q ] , and then finding the index q that leads to the maximum value, which obviously in volves a significan t amou nt o f com putations, as the c o m- plexity o rder is linear ( O ( Q ) ). It is therefor e relevant to look for an a lter nate co st functio n that wou ld allow a more efficient search. For all values of q , th e expressions k D q k 2 are almost identical (when th e re c onstruction meets con dition in (11) for a small value of δ ) , but do not nece ssary equ al to 1. W e thus define the new vectors ˆ D q = D q / k D q k 2 and the n ormalized vector ˆ Z = Z / k Z k 2 . W ith k ˆ D q k 2 2 = 1 an d k ˆ Z k 2 2 = 1 , the dot pr oduct can the r efore be expressed as f o llows : ℜ{ D q · Z H } = 1 − 1 2 k ˆ D q − ˆ Z H k 2 2 (15) and thus maximizing (14) now cor responds to minimizing k ˆ D q − ˆ Z H k 2 2 . This minimizatio n can be d one b y com puting k ˆ D q − ˆ Z H k 2 2 for all values of q and fin d ing q that leads to the minimum value, but this brings us back to the linear complex- ity order O ( Q ) a s in ( 14). Fortun ately , the n ew formulation based on sum of squares becomes a n earest n eighbor searc h problem , which can be solved efficiently u sing a k-d tree [22]. Algorithm 1 summ a r izes the offline configu ration per- formed prior to pr ocessing and the o nline comp u tations. Th e real-time perfor mances are indep endent of th e computation - ally expensive SVD an d tree con stru ction since the se are done offline. Dur in g online pr ocessing, com puting the vector Z inv olves a complexity o rder o f O ( K P N ) and th e k -d tree search exhib its on average a complexity O (log Q ) [22]. Algorithm 1 SVD-PHA T Offline: 1: Gener ate W f rom (1), (4), an d (8). 2: Perfo rm SVD an d obtain U , S and V , with K chosen accordin g to co ndition in (1 1). 3: Gener ate the normalize d vectors ˆ D q from D q in (13). 4: Build a k-d tree for all ˆ D q . Online: 1: Gener ate X from the STFT coefficients as in (7). 2: Comp ute Z with (12) and generate ˆ Z H . 3: Find ¯ q using the k-d tree search. 4: Find Y ¯ q with the correspo nding row of W in (9) . 4. RESUL TS The para meters for the exp eriments a re summa rized in T able 1. The sample rate f S captures all the frequen cy content of speech, and the speed of soun d c c o rrespond s to ty pical in door condition s. The frame size N analyzes segmen ts o f 16 msecs, and the ho p size ∆ N provides a 50 % overlap. Th e p otential DO A are represented by equidistant po ints on a unit sp h ere generated recursiv ely from a tetrahedron , f o r a total of 2562 points, as in [11]. T able 1 . SVD-PHA T Parameters f S c N ∆ N Q 16000 343 . 0 256 128 2562 W e in vestigate three dif ferent micropho ne array geo m e- tries: a 1-D linear arr ay , a 2-D plan ar a r ray an d a 3- D array . The micro phones exact xyz-p ositions ar e giv en in cm in T able 2 and the geometries a r e shown in Fig. 1. T able 2 . Positions (x,y ,z) o f the micr ophones in cm Mic 1-D 2-D 3-D 1 (0 , 0 , − 5 . 0) (0 , 0 , 0 ) (0 , 0 , 0 ) 2 (0 , 0 , − 3 . 3) (5 , 0 , 0 ) ( − 5 , 0 , 0) 3 (0 , 0 , − 1 . 7) (2 . 5 , 4 . 3 , 0) (5 , 0 , 0 ) 4 (0 , 0 , 0 ) ( − 2 . 5 , 4 . 3 , 0) (0 , − 5 , 0) 5 (0 , 0 , 1 . 7) ( − 5 . 0 , 0 , 0) (0 , 5 , 0 ) 6 (0 , 0 , 3 . 3) ( − 2 . 5 , − 4 . 3 , 0) (0 , 0 , − 5) 7 (0 , 0 , 5 . 0) (2 . 5 , − 4 . 3 , 0) (0 , 0 , 5) Simulations ar e con ducted to m easure the accuracy of th e propo sed method. The microp hone array and the target sou rce are positionn ed ran d omly in a 10m x 10m x 3m r e ctangular room. For each co nfiguration , the roo m reverberation is mo d- eled with Room Im pulse Responses (RIRs) generated with the image method [23], where th e reflection coefficients are sampled randomly in the uniform interval between 0.2 an d 0.5. Soun d segments from the TIMI T dataset ar e the n con- volved with the g enerated RIRs. Dif fuse white no ise is add ed on each channel, for a signal-to- noise r a tio (SNR) that varies random ly b etween 0dB and 30dB. A total of 10 00 different configur ations are g enerated for each micr ophone array . W e v ary δ to analyze its impa ct o n the accur a cy of lo- calization, measured as Root Me an Squar e Error ( RMSE). For the 1-D linear array , localization can on ly p r ovide a po si- tion on 180 ◦ arc. The 3-D position fr om th e 2562 poin ts u nit sphere is th e refore m apped to an arc: f 1 ( s ) = [cos( g ( s )) , 0 , sin( g ( s ))] (16) where g ( s ) = atan2 s | z , q ( s | x ) 2 + ( s | y ) 2 (17) For the 2-D planar array , localization returns a position on a half- sphere, and thus every po int is mappe d to the p ositi ve hemispher e as f ollows: f 2 ( s ) = [ s | x , s | y , | s | z | ] (18) − 1 0 1 − 1 0 1 − 5 0 5 x y z (a) 1-D linea r array − 5 0 5 − 4 0 4 − 1 0 1 x y z (b) 2-D planar array − 5 0 5 − 5 0 5 − 5 0 5 x y z (c) 3-D array Fig. 1 . Geom etries of the microph one arrays in xyz-co ordinates (dimension s are given in cm) Finally , f or the 3-D arra y , the localization result can span the full 3-D space, su ch that th e map ping function co rre- sponds to ide n tity: f 3 ( s ) = s (19) The RMSE between the estimated DO A ( s ¯ q ) f or a ll f rames for a gi ven ro om con figuration a nd speech signal is summ ed and weighted with the energy Y q , and the n compared with the theoretical DO A d efined by s 0 . The mathematical expression correspo n ds to (20), wh ere α = { 1 , 2 , 3 } for 1-D, 2-D and 3-D arr ays, re specti vely . RMSE α = P f α ( s ¯ q ) Y ¯ q P Y ¯ q − f α ( s 0 ) 2 (20) Figure 2a shows the difference between the RMSE fr om SVD-PHA T and SRP-PHA T (denoted as ∆ RMSE), with re- spect to th e δ parameter . As expecte d , when δ in creases, the reconstruc tion erro r gets significan t and this r educes the a c- curacy o f localization fo r SVD-PHA T . It is interesting to note that the 2-D planar array sh o ws the largest inc r ease in RMSE. Figure 2b shows the value of the K param eter as a f unction of δ . Note h o w the K value is smaller when the array spans only one or two dimension s, as expected sin ce the transfer functio n between DOAs a r e mo re co rrelated. Th e gain in p e rformance is mostly d ue to the reduction from a m atrix multiplicatio n with Q rows in (9) to a matrix m u ltiplication with K rows in (12). Figure 2c therefo re shows the gain Q/K as a function of δ . It is re asonable to define δ = 10 − 5 as the RMSE between SRP-PHA T and SVD-PHA T is almost identical. W ith this configur ation, the gain Q/K rea c hes 32 0 , 5 3 an d 36 for 1-D, 2-D and 3- D array s, which is consid e rable, and demon strates the superiority o f SVD-PHA T over SRP-PHA T in terms of computatio nal require m ents, while pr eserving the same accu- racy . 5. CONCLUSION This p aper introduc es a new localization metho d named SVD- PHA T . This technique can p erform with the same accuracy as SRP-PHA T , while re d ucing significantly th e amou nt of com - putations. 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 0 . 00 0 . 10 0 . 20 δ ∆ RMSE (a) Diffe rence betwee n the Root Mean Square Error of SVD-PHA T and the exa ct SRP-PHA T – s malle r is better . 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 0 20 40 60 80 δ K (b) V alue of the va riable K (the rank of the decomposition ) for the pro- posed SVD-PHA T method – smaller is better . 10 − 6 10 − 5 10 − 4 10 − 3 10 − 2 10 − 1 10 0 10 1 10 2 10 3 10 4 δ Gain Q/K (c) Performance gain of SVD-PHA T when compared to exact SRP-PHA T method – greater is better . Fig. 2 . Performance of the proposed SVD-PHA T method with respect to the exact SRP-PHA T metho d. Results ar e presented for the 1-D linear array (red) , the 2-D planar array (b lue) and the 3-D array ( green). In futur e work, we will in vestigate multiple sourc e local- ization with SVD-PHA T . It would also be interesting to intro- duce binary time-f requency mask, which could red u ce even more the amo unt of comp utations. The metho d could also b e extended to deal with speed of sound mismatch, the near-field effect and microph one p o sition u ncertainty . 6. REFERENCES [1] H. T ang, W .-N. Hsu, F . Gron din, and J. Glass, “ A stud y of enhancem e nt, aug m entation, and autoencode r meth- ods fo r domain adap tation in distant speech recogn i- tion, ” in Pr o c. INTERSPEECH , 20 18, pp. 292 8 –2932 . [2] L. Parra and C. Alvino, “Geo metric sou rce separa tio n: Merging c o n volutive sou rce separation with geometr ic beamfor ming, ” in Pr oc. IEEE Sign al Pr ocessing Society W orkshop . IEEE , 2001 , pp. 273–2 8 2. [3] E. Habets, J. Benesty , I . Cohen, S. Gannot, and J. Dm o- chowski, “New insights into the MVDR bea mformer in room acoustics, ” IEEE T rans. A u dio, Speech, Language Pr ocess. , vol. 18, n o. 1 , pp . 158, 2010 . [4] R.O. Schmidt, “Multiple e m itter lo c ation and sig n al parameter e stima tion, ” IEEE T rans. Antenn as Pr o pag. , vol. 34, no . 3, pp. 276 –280, 1986 . [5] J.H. DiBiase, H.F . Silverman, and M.S. Brandstein, “Robust lo c alization in r e verberant ro oms, ” in Micr o- phone Arrays , pp . 15 7–180. Spring er , 2 0 01. [6] C.T . I shi, O. Chato t, H. Ishiguro , an d N. Hagita, “Eval- uation of a MUSIC-based real-time sound localiza tio n of m u ltiple so und sources in r eal noisy environments, ” in Pr oc. IEEE/R SJ Int. Conf. Intell. Robots & S ystems , 2009, pp. 2027– 2032. [7] K. Naka mura, K. Nakad ai, F . Asano, an d G. In c e , “In- telligent sound source localization and its application to multimoda l hu man tr acking, ” in Pr oc. I EEE/RSJ Int. Conf. Intell. Robots & Systems , 20 11, pp . 143– 148. [8] K. Nakamur a, K. Nakadai, an d G. Ince , “Real- tim e super-resolution sound source lo calization f or ro bots, ” in Pr oc. IEEE/R SJ Int. Conf. Intell. Robots & S ystems , 2012, pp. 694–6 99. [9] M.S. Bran dstein an d H.F . Silverman, “ A robust method for speech signal time-delay estimatio n in reverberant rooms, ” in Pr oc. I EEE Int. Conf. Acoustics, Sp eech & Signals Pr o cess. IEEE, 19 97, vol. 1, pp . 37 5–378. [10] F . G r ondin, D. L ´ etournea u , F . Ferland, V . Rousseau , an d F . Michaud , “The ManyEars open f ramew ork, ” Auton. Robots , vol. 34, no. 3, pp . 217– 232, 2013. [11] J.-M. V alin, F . Michaud, and J. Rouat, “Robust localiza- tion an d track ing o f simultan e ous moving sound sources using beamfor ming and particle filtering, ” Rob. Auton. Syst. , vol. 55, no. 3, pp. 216 –228, 2007 . [12] G. Jacovitti and G. Scarano, “Discrete time techniques for time delay estimation, ” IE EE T rans. Sig nal P r ocess. , vol. 41, no . 2, pp. 525 –533, 1993 . [13] M. McCo r mick and T . V arghese, “ An a p proach to unb i- ased subsample in terpolation for m otion tr a cking, ” Ul- trasonic ima ging , vol. 35, no. 2, pp. 76– 89, 2013 . [14] F . V iola and W .F . W alker , “ A splin e-based algorithm for continuo us time - delay estimation using sam pled data, ” IEEE T rans Ultrason F err oelectr F r eq Con tr ol , vol. 52, no. 1 , pp . 80 –93, 200 5. [15] D.L. Maskell and G.S. W o ods, “The estimatio n of sub- sample time delay of ar ri val in the d iscrete-time mea- surement of phase delay , ” IEE E T rans. I nstrum. Meas , vol. 48, no. 6, pp. 1227– 1231, 1 999. [16] K.K. Shar ma and S.D. Joshi, “T ime d elay estimation using fractio nal fourier tr ansform, ” EUR ASIP J. Audio Speech , vol. 87 , no. 5, pp. 85 3–865, 200 7 . [17] H. Do, H.F . Silverman, an d Y . Y u, “A real-tim e SRP- PHA T source location imple m entation using stochas- tic region c o ntraction ( SRC) on a large-ap erture micro- phone array , ” in Pr oc. I EEE Int. Conf. Aco ustics, Speech & Signals Pr ocess. , 200 7, vol. 1, pp. 12 1 –124. [18] D.N. Zotk in and R. Dur aiswami, “Accelerated speech source localization v ia a hierarchical search of steered response p ower, ” IE EE T rans. Audio, Sp eech, Language Pr ocess. , vol. 12 , no. 5, pp. 49 9 –508, 2004 . [19] H. Do and H. F . Silverman , “Stochastic p article filtering : A fast srp -phat sing le source localization algorithm , ” in IEEE W orkshop on Applications of Signal Pr ocessing to Audio & Acoustics , 2009, pp. 213–2 16. [20] L.O. Nunes, W .A . Martins, M. Lima, L. Biscainho, M. Costa, F . Goncalves, A. Said, a n d B. Lee, “A steered-respo nse power algorithm employing hierarchi- cal search f or acoustic sour ce localization using micro- phone arrays, ” IEEE T rans. Signal Pr ocess. , vol. 62 , n o. 19, p p. 5 171–51 83, 201 4. [21] B. Lee and T . Kalker, “ A vectorized meth od for co mpu- tationally efficient srp-phat soun d sourc e localization , ” in Int. W orkshop on Acou stic Echo & Noise Contr o l , 2010. [22] J.L. Bentley , “Multidimensional bin ary search trees used for associati ve searching, ” Commu n. A CM , v ol. 18, n o. 9 , pp . 509– 517, 1975. [23] J.B. Allen and D.A. Berkley , “Image method for ef- ficiently simulating small-roo m acoustics, ” J . Acoust. Soc. Am. , vol. 65, no. 4, pp. 9 43–950 , 1 979.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment