CEM-RL: Combining evolutionary and gradient-based methods for policy search
Deep neuroevolution and deep reinforcement learning (deep RL) algorithms are two popular approaches to policy search. The former is widely applicable and rather stable, but suffers from low sample efficiency. By contrast, the latter is more sample efficient, but the most sample efficient variants are also rather unstable and highly sensitive to hyper-parameter setting. So far, these families of methods have mostly been compared as competing tools. However, an emerging approach consists in combining them so as to get the best of both worlds. Two previously existing combinations use either an ad hoc evolutionary algorithm or a goal exploration process together with the Deep Deterministic Policy Gradient (DDPG) algorithm, a sample efficient off-policy deep RL algorithm. In this paper, we propose a different combination scheme using the simple cross-entropy method (CEM) and Twin Delayed Deep Deterministic policy gradient (td3), another off-policy deep RL algorithm which improves over ddpg. We evaluate the resulting method, cem-rl, on a set of benchmarks classically used in deep RL. We show that cem-rl benefits from several advantages over its competitors and offers a satisfactory trade-off between performance and sample efficiency.
💡 Research Summary
The paper introduces CEM‑RL, a novel algorithm that merges the Cross‑Entropy Method (CEM), a simple population‑based evolutionary strategy, with Twin‑Delayed Deep Deterministic Policy Gradient (TD3), a state‑of‑the‑art off‑policy actor‑critic reinforcement learning (RL) algorithm. The motivation stems from the complementary strengths and weaknesses of evolutionary methods and deep RL: evolutionary approaches such as evolution strategies (ES) are robust and easy to parallelize but suffer from poor sample efficiency because they learn from whole episodes, while off‑policy deep RL methods like TD3 achieve high sample efficiency by reusing individual time‑step transitions stored in a replay buffer, yet they are notoriously sensitive to hyper‑parameters and can become unstable. Prior attempts to combine the two families (e.g., ERL, which couples a population of actors with a single DDPG learner, and GEP‑PG, which first fills a replay buffer via a goal‑exploration process before applying DDPG) have shown promise but either do not fully exploit the sample‑efficiency benefits of ES or treat the evolutionary and gradient‑based phases as largely independent.
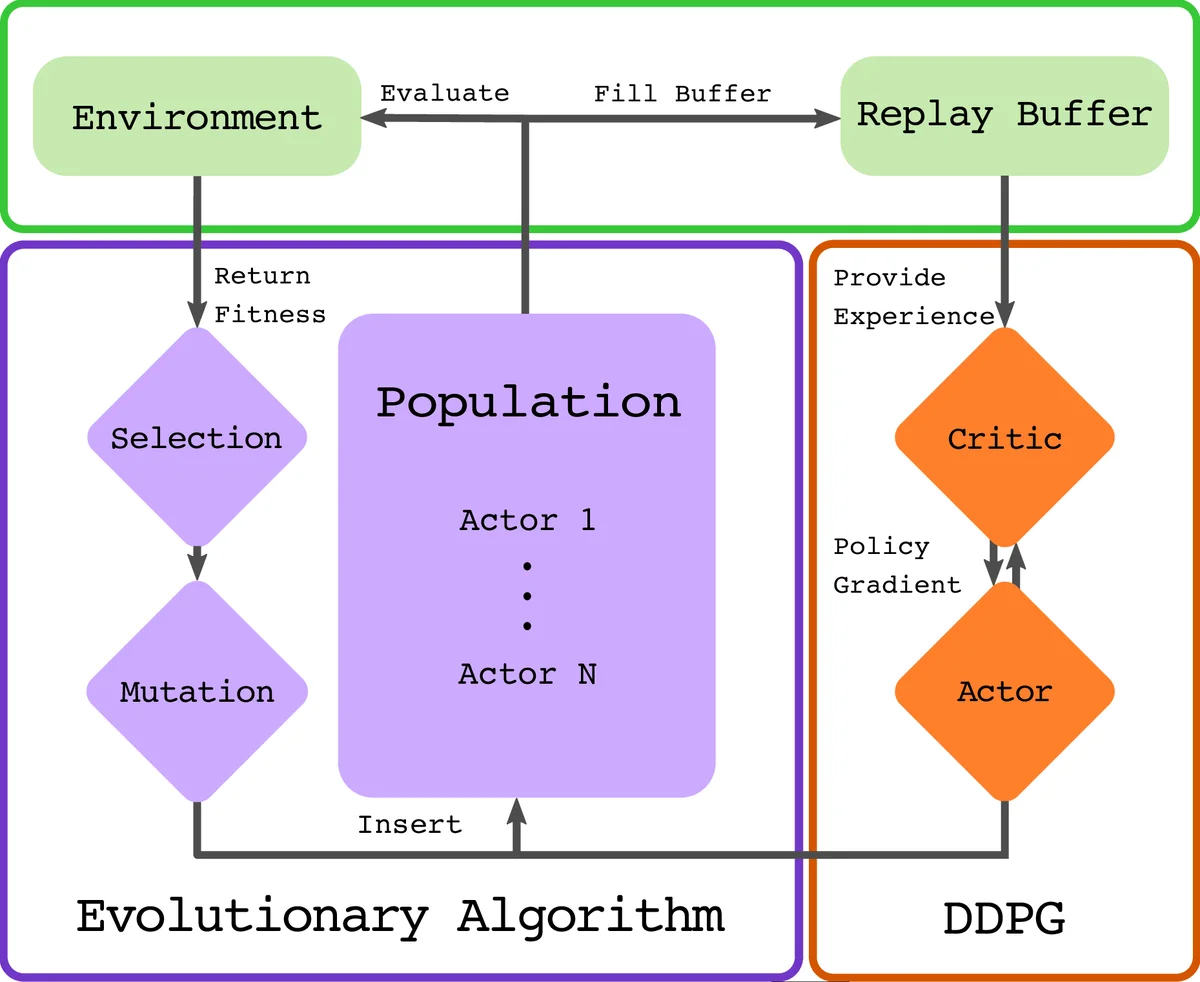
CEM‑RL addresses these gaps by interleaving evolutionary sampling and gradient‑based improvement within each generation. At the start of a generation, a Gaussian distribution defined by a mean policy µ and a diagonal covariance Σ is used to sample a population of pop_size actors. The population is split in half: the first half is evaluated directly in the environment, yielding episode returns that serve as fitness scores; the second half undergoes a short burst of policy gradient updates using the current critic Qπ from TD3. Specifically, each of these actors is updated for a fixed number of steps (proportional to actor_steps /(pop_size/2)) by following the deterministic policy gradient provided by the critic, with TD3’s twin‑critic, target‑policy smoothing, and delayed policy updates ensuring stability. After the gradient steps, these actors are also evaluated in the environment. All resulting trajectories—both from raw and gradient‑enhanced actors—are inserted into a cyclic replay buffer. The critic is then trained on mini‑batches sampled proportionally to the number of new transitions added in the current generation, mirroring standard deep RL practice (e.g., one gradient update per environment step).
Once all fitness evaluations are complete, CEM selects the top pop_size/2 actors (whether raw or gradient‑improved) as elites. Using these elites, the algorithm updates the Gaussian distribution: the new mean µ_new is the weighted average of elite parameters, and the new covariance Σ_new is computed from the squared deviations of elites around the previous mean, plus a small isotropic term εI that decays exponentially from an initial σ_init to a final σ_end. This “importance mixing” step (described in Appendix B) re‑uses previously sampled individuals to reduce variance and improve sample efficiency. The updated µ and Σ define the distribution for the next generation, completing the evolutionary loop.
The key benefits of this design are threefold. First, sample efficiency is dramatically improved: TD3’s replay buffer allows each environment interaction to be leveraged many times, while CEM’s elite‑based update ensures that high‑quality policies are propagated quickly. Second, stability is enhanced because CEM’s global search prevents the policy from collapsing into poor local minima, and TD3’s twin‑critic and delayed updates mitigate over‑estimation bias. Third, diversity is maintained: if gradient steps degrade performance, those actors are simply ignored by the elite selection, but their experiences still enrich the replay buffer, providing exploratory signals for future updates. This contrasts with ERL, where the evolutionary population can be overly influenced by a single high‑performing RL agent, potentially reducing diversity.
Empirical evaluation was conducted on four MuJoCo continuous control benchmarks: HalfCheetah‑v2, Hopper‑v2, Walker2d‑v2, and Ant‑v2. Across all tasks, CEM‑RL (both the CEM‑DDPG and CEM‑TD3 variants) outperformed pure CEM, pure TD3, ERL, and GEP‑PG in terms of learning speed and final return. Notably, on the high‑dimensional Ant task, CEM‑RL achieved a lower variance in performance across random seeds, indicating more reliable learning. The authors also performed ablation studies showing that removing the gradient‑enhanced half of the population or disabling importance mixing degrades performance, confirming that both components are essential.
Limitations discussed include the use of a diagonal covariance matrix, which simplifies computation but ignores correlations between policy parameters; this could be addressed by low‑rank covariance approximations or full‑matrix updates in future work. Additionally, hyper‑parameters such as τ_cem, σ_init, σ_end, and population size still require manual tuning, suggesting a role for automated meta‑optimization. Finally, scalability to very large neural networks (e.g., vision‑based policies) may be constrained by the O(n²) cost of sampling from a full covariance, motivating research into more scalable distribution representations.
In conclusion, CEM‑RL demonstrates that a tight integration of a simple evolutionary estimator (CEM) with a powerful off‑policy gradient learner (TD3) yields an algorithm that simultaneously enjoys high sample efficiency, robust stability, and maintained exploration diversity. The method sets a new benchmark for hybrid evolutionary‑RL approaches and opens avenues for further enhancements in covariance modeling, hyper‑parameter automation, and application to high‑dimensional perception‑driven control tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment