An Ensemble SVM-based Approach for Voice Activity Detection
Voice activity detection (VAD), used as the front end of speech enhancement, speech and speaker recognition algorithms, determines the overall accuracy and efficiency of the algorithms. Therefore, a VAD with low complexity and high accuracy is highly…
Authors: Jayanta Dey, Md Sanzid Bin Hossain, Mohammad Ariful Haque
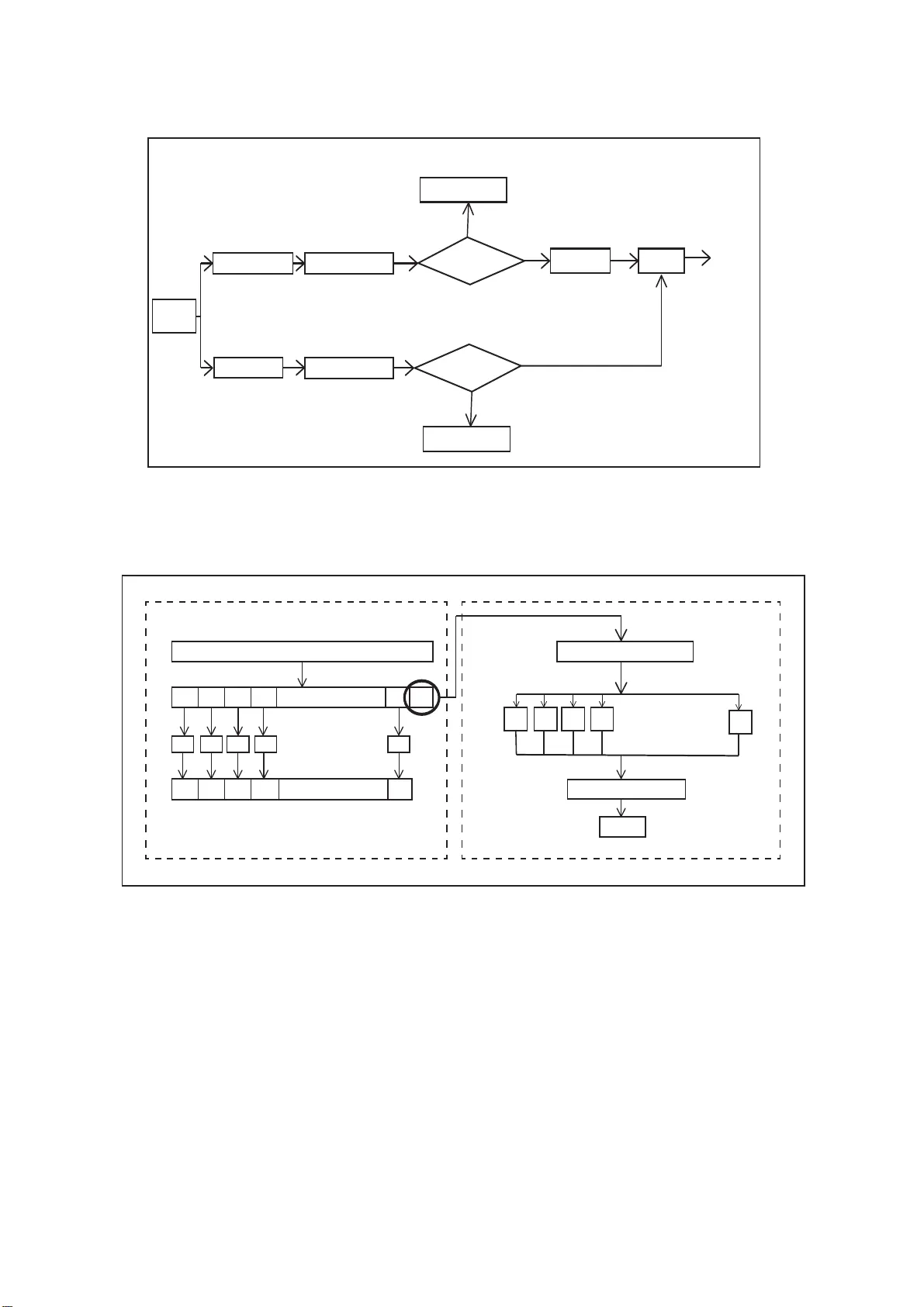
An Ensemble SVM-based A ppr oa ch f o r V oice Activity Detection J ayanta De y 1 , Md. Sanzid Bin Hossain 2 , Mohammad Ar iful Haque 3 ∗ Dept. of Electrical and Electronic Engineering, Bangladesh University of Engineering and T echnology deyjayanta76@ gmail.com, sanzidbinhoss ain33@gmail.co m, arifulhoque@e ee.buet.ac.bd Abstract V oice activ ity detection (V AD), used as the front end of speech enhanceme nt, speech and speaker recognition algorithms, de- termines the overall accuracy and efficienc y of the algorithms. Therefore, a V AD wit h low complexity and high accurac y is highly desirable for speech processing ap plications. In this pa- per , we propos e a no vel training method on large dataset for su- pervised learning-based V AD system using sup port v ector ma- chine (SVM). Despite of high classification accu racy of suppo rt vector machines (SVM), trivial SVM is not suitable for classi- fication of large data sets needed for a good V AD system be- cause of high training complexity . T o overcome this problem, a nov el ensemble-based approach using SVM has been proposed in this paper . The performance of the proposed ensemble struc- ture has been compared with a The performan ce of the pro- posed ens emble structure has been compared with a feedfor- ward neural netw ork (NN). Alt hough NN performs better than single SVM-based V A D trained on a small portion of the train- ing data, ensemble S VM gi ves accuracy comparable to neural network-b ased V AD. Ensemble SVM and NN gi ve 88 . 7 4 % and 86 . 28 % accuracy respectiv ely whereas the stand-alone SVM sho ws 57 . 05 % accurac y on average on the test dataset. Index T erms : V oice activity detection, suppo rt vector machin e, neural network, ensemble. 1. Intr oduction V oice activity detection is ba sically the act of separating the speech and the non-sp eech portions of an aud io recording. As a typical speech signal may contain silence, mono-tonic noise and e ven music frames, sorting out the speech frames from the recording usin g an efficient V AD in t he front end is of great importance for reliable operation of the speech processing al- gorithms. A number of algorithms f or vo ice activity detection have been proposed in the literature. Among them frame ener gy , pe- riodicity measure [1] or entrop y-based [2] methods are elegant in the sense of their simplicity and time-efficiency . Howe ver , they are based on parameters selection that are tuned for a par- ticular situation an d can not separate mo re critical non-sp eech frames li ke music accurately . A solution to this problem can be found by ado pting relati vely complex st ati stical approach such as statistical hypothesis testing [3], long-term spectral div er- gence measure [4], amp litude pro bability distribution [5] and lo w-va riance spectrum estimation [6]. Howe ver , these methods need to estimate the background noise le vel and are also prone to severa l parameters tuning. More recent studies attempts t o solve the problem of V AD from machine learning point-of-vie w [7], [ 8 ], [9] that classifies an audio frame as speech or no n- speech. The main problem associated with these approaches i s that they need to be trained on a large dataset which includes a rich non-speech instances for a satisfactory efficiency . This poses a problem for learners such as SVM that has high classi- fication accurac y and yet can not be trained on a larg e dataset due to comple x training algorithm. In this paper , we propose a novel ensemble technique to train SVM learners on a larg e dataset for v oice acti vit y detec- tion and com pare it with the performance of a neural netw ork- based classifier t r ained on t he similar datase t. T i me ef ficiency is a crucial factor for V AD implementation and unlike t he other methods reported in the literature [10] that use a large set of features, we focus our efforts on b uilding cl assifi er based on MFCC features only . These MFCC features are popularly used for speech processing algorithms. Therefore, the extracted fea- tures can be used in the subsequen t stages making t he ov erall procedure more efficient. In our work, we have trained a num- ber of S VMs on non-ov erlapping small datasets to cover t he whole lar ge dataset and their predicted probability is used as features for t he output l ayer SVM t hat giv es the final decision. The proposed SVM-ensemble giv es approximately similar ac- curacy compared to the state of the art neural network [10]. This approach sho ws significant improv ement in terms of accuracy from the st and-alone SVM and also the v ariance in result for a single SVM is smoothed out by the ensemb le. The paper is organ ized as follows. Secti on II describes problem formulation and data description. The system architec- ture is discussed in section III and the system efficacy i s estab- lished in section IV . Finally , mentioning the contributions and our future work, the paper is concluded in section VI. 2. Pr oblem Formulation and Data Description In our work, we have used MUSAN corpus [11] as both our testing and training database. The corpus consists of approxi- mately 109 hours of speech, music and noise data that makes it an ideal database to be used for supervised learner-based V AD application. T he speech dataset contains silent frames which are exclud ed from t he training dataset by a log-mel energy based thresholding described later in the paper and a t est dataset of duration of about 3 hours has been separated from the corpus where the silent frames of speech r ecordings were annotated by a human listener . Now both the training an d testing dataset were divide d into frames of duration 25 ms with 15 ms over - lap. Therefore, the challenge is to build a learner trained on the features extracted from the training frames that can classify the testing frames as speech or non-sp eech. Here we hav e used an ensemble-based approach for training an SVM learner and compared it with a trivial architecture-based neural network. 3. V AD System Description In this work, w e aim to de velop a binary classificati on system in which one class consists of only speech and the other one con- Energy > Threshold Silence Classified Silence Classified Energy>Threshold V AD model Classifier MUSAN corpus No No Y es Y es Speech/ non- speech decision F eature extraction F eature extraction T raining dataset T est dataset Figure 1: General system model f or the pr oposed voice activity detection. Featur e dataset (n+1)th dataset 1 1 2 3 4 2 3 4 n n+1 SVM-1 SVM-2 SVM-3 SVM-4 SVM-n SVM-1 SVM-2 SVM-3 SVM-4 SVM-n n . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . SVM Probability esma on Shuffling Predicon T raining Ensemble member training Final member training Probability esma te f eature Probabilty esma on fea ture vect or a) b) Figure 2: a) T raining n numb ers of SVM for ensembling, b) T raining the final output layer SVM. tains silence, music and noise. A general overvie w of the V AD system is sho wn in F ig. 1. As the silent frames can be sepa- rated quite ef ficiently by energy-b ased thresholding only , they were excluded from the training data and detected in the test- ing phase using a threshold ing on the log-mel energy that is the first MFCC feature. Then the remaining frames were classified using a supervised-learn er-based V AD system. 3.1. Fea ture Extraction In order to train the classifier, we hav e used MFCC features as they are the standard features used in speech processing. There are many software packages to extract the MFCC features ef- ficiently and hence it will be an elegant feature-set to be used in V AD where time-ef ficiency is high ly desirable. MFCC is a spectral feature inspired by hu man auditory model. As hu- man ea r i s efficient in distinguishing between speech and non - speech, we hope the MFCC features will also be effecti ve for our purpos e. Here we have used 13 MFCC features for a par- False Positive Rate 0.1 1 True Positive Rate 1 2 3 4 5 6 7 8 0. 9 1 0. 0. 0. 0. 0. 0. 0. 0. 0 0 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 False Positive Rate True Positive Rate non-speech speech b) non-speech speech 1 0.9 0.3 0.4 0.5 0.6 0.7 0.8 0 0.1 0.2 0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1 a) ( 0.1523, 0.8627 ) ( 0.1701, 0.8804 ) Figure 3: a) R OC curves for ensemb le-SVM, b) ROC curves for NN. ticular audio frame. 3.2. Classification usi n g Neural Network W e have de veloped and ev aluated our deep neural network (NN) model with pytho n li brary Keras ® and numerical computation software library ten sorflow . W e have trained a fully connected neural netw ork model with an input layer of 13 input v ariable ,two hidden layers w i th 12 and 8 neurons respectiv ely and an output layer with one neuron. W e have initialized network weights to small rando m nu mbers which w as generated from a uniform distribution. Details of the layer architecture is gi ven in T able 1. W e have used binary cro ssentropy as loss function and gradien t decen t algorithm Adam as optimizer . T able 1: A rc hitectur e and Tr aining P ara meters of the Neural Network Layer Details Node Numb er Activation Epochs Batch Size V alidation Split Hidden Layer 1 12 relu Hidden L ayer 2 8 relu 100 100 .2 Output Layer 1 sigmoid 3.3. Classification usi n g SVM In our work, we hav e used libsvm toolbox [12] for SVM- based classification. As a stand-alone SVM i s not suitable for the large train dataset described earlier, we shuffle the feature sets obtained from the t rain dataset and divide it into n non - ov erl apping smaller datasets. The o verview of the procedure is sho wn in the Fig. 2. Here we ha ve used an ensemb le of n = 5 SVMs with non -linear rbf kernel. T he v alues of gamma and C parameters of the kern el ha ve been tuned from the 2 -fold cross-v ali dation accuracy using grid-search [13]. The rationale behind choosing an ensemble of 5 learners is that the perfor- mance saturates for higher number of learners. In the first st age, the feature dataset was shuf fled and divided into 6 portions. Among t hem the fi rst 5 segmen ts has been used for t r aining the ensemble-members and then each of the trained members gave probability estimates for the held-out 6 -th portion of the dataset. For one feature ve ctor of 13 MFCC features each of the mem- bers gi ves 1 probability estimate and thus a ne w feature space of 5 features have been deriv ed from one input feature vector which mak es the procedure completely data-driven wit hout us- ing an y heuristic thresholding. These feature vectors hav e been used for training an SVM classifier with rbf kernel in t he final layer . Here instead of using a majority voting based decision, we hav e used SVM as majority voting system may giv e estimate biased to a particular ensemble member without considering the other members. In case of l arger dataset even than that of used in this work, the num ber of SVM layers in the system may be increased simi l ar to an NN architecture. 4. Result Analysis The proposed ensemble-SVM was tested on the t est dataset de- scribed in the data des cription section. T o prove the efficacy of the classifier , we att empt to e xamine t he ensemble architec- ture from different perspecti ves such as effect of layer members, stability and finally we compare t he classifier wit h a stable, ef- ficient neural netwo rk. In order t o test t he effect of ensemb ling, we gradually increase t he number of ensemble member and ob- serve their accurac y in T able 2. T able 2: Effect on performance for incr easing ensemble mem- bers Ensemble Member No. Ac curacy A verage indi vidual member accuracy 1 57.05% 2 72.25% 3 78.32% 57.05% 4 87.02% 5 88.74% 6 88.82% From T able 2 we see that the accurac y of classification in- creases for increasing number of ensemble members and the accurac y almost saturates aft er n = 5 ens emble members. Although individu al SVM trained on smaller dataset shows poor performance of 57 . 05% , the effect of ensemb ling is e v- ident from the higher classification accuracies of the ensem- bles. Again to observe estimation v ariance reduction of the ensemble, we present the accurac y of two testing files i n T a- ble 3. For e xample, in the case of ‘spee ch-libriv ox-0011’ file, if we use stand-alon e SVM the accuracy may v ary i n the range 8 . 65 ∼ 91 . 35% as the stand-alone SVMs are trained on differ - ent portions of data and hence, the y may perform differently for a particular test-case. From T able 3 we can observ e that the ac- curacy of indi vidual SVM may fluctuate whereas their ensemble accurac y remains stable and close to the maximum individual accurac y . T able 3: Effect on performance for incr easing ensemble mem- bers File Name Ensemble Member Accurac y T otal E nsemble Accurac y 8.6466% 8.6466% speech-libriv ox-0011 91.3534% 90.2256% 39.4737% 18.797% 5.26316% 30.8271% noise-sound-bible-00 31 21.4286% 72.45% 49.6241% 68.797% Finally , we compare the performance of t he ensemble SVM with t he NN described in the subsection 3 . 2 . NN and ensemble- SVM give 86 . 28 % and 88 . 74 % accurac y respecti vely . Their R OC curves are giv en in Fi g. 3. The operating point of each classifier is sho wn by using a circle on the curv es which sho ws that the ensemble-SVM has a better true positiv e rate of 88 . 04% and a slightly high false positi ve rate of 17 . 01% compared to that of NN. The av erage area under curve (A UC) f or NN and ensemble-SVM are 0 . 9284 and 0 . 9167 respectiv ely . From these performance indices, we can con clude that their performan ces are comparable. 5. Conclusion In this paper , we ha ve proposed a novel ensemble SVM-based approach for v oice acti vity detection. The efficac y of the pro- posed ensembling method has been established in t he result sec- tion through comparing with NN and testing on the test dataset. Here the member SVMs are i ndependent of each other and hence they can operate parallelly resulting in a significant r e- duction in runtime. Again different ensemble member can be trained on dif ferent types of feature giving a more rob ust V AD system. Replacing some of the layers of an NN wit h SVM layer may result in improv ed accurac y . In our future work, we will ex- plore composite structure of NN and S VM with reduced train- ing complexity . 6. Refer ences [1] R. Tuck er, “V oice acti vity detect ion using a peri odicit y measure, ” IEE Pr oceedings I (Communic ations, Speech an d V ision) , vol. 139, no. 4, pp. 377–380, 1992. [2] P . Rene vey and A. Drygajlo, “Entropy based voice acti vity detec- tion in very noi sy condit ions, ” in Sevent h Eur opean Con fer ence on Speec h Communicat ion and T echn olog y , 2001. [3] J.-H. Chan g, N. S. Kim, and S. K. Mi tra, “V oice acti vity detec- tion based on multiple statistica l models, ” IE EE T ransact ions on Signal Pr ocessing , vol. 54, no. 6, pp. 1965–1976, 2006. [4] J. Ramırez , J. C. Seg ura, C. Benıtez , A. De La T orre, and A. Ru- bio, “Efficie nt voice act i vity detect ion algorithms using long-te rm speech informatio n, ” Speec h communication , vol. 42, no. 3-4, pp. 271–287, 2004. [5] S. G. T anyer and H. Ozer , “V oice ac ti vity detect ion in nonstation- ary noise , ” IEE E T ransactions on spee ch and au dio pr ocessing , vol. 8, no. 4, pp. 478–482, 2000. [6] A. Davis, S. Nordholm, and R. T ogneri, “Stati stical voice acti vity detec tion using low-v ariance spectrum estimation and an adapti ve threshold , ” IEE E T ransaction s on Audio, Spee ch, and Langua ge Pr ocessing , vol . 14, no. 2, pp. 412–424, 2006. [7] J. W . Shin, J. -H. Chang, and N. S. Kim, “V oice acti vity detecti on based on s tatist ical models and machine lea rning approac hes, ” Computer Speech & Languag e , vol. 24, no. 3, pp. 515–530, 2010. [8] J. Wu and X. -L. Z hang, “Max imum margin clustering based sta- tistic al vad with multipl e observa tion compound feature, ” IEEE Signal Pr ocessing Letters , vol. 18, no. 5, pp. 283–286, 2011. [9] X.-L. Zhang and J. W u, “Deep belief networks based voic e ac- ti vity de tecti on, ” IE EE T ransact ions on Audio, Spee ch, and Lan- guag e Pr ocessing , vol. 21, no. 4, pp. 697–710, 2013. [10] M. V an Segbroeck , A. Ts iarta s, and S. Narayan an, “ A robust fron- tend for vad : exploitin g contextua l, discriminat i ve and spectral cues of human voice. ” in INTERSP E ECH , 2013, pp. 704–708. [11] D. Snyde r , G. Chen, and D. Pov ey , “Musan: A music, speech, and noise corpus, ” arXiv preprin t arXiv:1510.08484 , 2015. [12] C.-C. Chang and C.-J. Lin, “Libsvm: a library for support ve ctor machines, ” ACM tran sactions on intellig ent systems and tec hnol- ogy (TIST) , vol. 2, no. 3, p. 27, 2011. [13] C.-W . Hsu, C.-C. Chang, C.-J. Lin et al. , “ A practi cal guide to support vec tor classificati on, ” 2003.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment