A Parallel Projection Method for Metric Constrained Optimization
Many clustering applications in machine learning and data mining rely on solving metric-constrained optimization problems. These problems are characterized by $O(n^3)$ constraints that enforce triangle inequalities on distance variables associated with $n$ objects in a large dataset. Despite its usefulness, metric-constrained optimization is challenging in practice due to the cubic number of constraints and the high-memory requirements of standard optimization software. Recent work has shown that iterative projection methods are able to solve metric-constrained optimization problems on a much larger scale than was previously possible, thanks to their comparatively low memory requirement. However, the major limitation of projection methods is their slow convergence rate. In this paper we present a parallel projection method for metric-constrained optimization which allows us to speed up the convergence rate in practice. The key to our approach is a new parallel execution schedule that allows us to perform projections at multiple metric constraints simultaneously without any conflicts or locking of variables. We illustrate the effectiveness of this execution schedule by implementing and testing a parallel projection method for solving the metric-constrained linear programming relaxation of correlation clustering. We show numerous experimental results on problems involving up to 2.9 trillion constraints.
💡 Research Summary
The paper addresses the computational bottleneck inherent in metric‑constrained optimization problems, where a set of distance variables (x_{ij}) must satisfy triangle‑inequality constraints of the form (x_{ij} \le x_{ik}+x_{jk}) for every triple ((i,j,k)). Since the number of such constraints grows as (O(n^{3})), conventional linear‑programming solvers quickly become infeasible due to memory consumption and the sheer size of the constraint matrix. Recent work showed that memory‑efficient projection methods, especially Dykstra’s algorithm (equivalent to Hildreth’s and Han’s methods for quadratic programs), can solve these problems at a much larger scale, but the convergence rate remains only linear, leading to long runtimes.
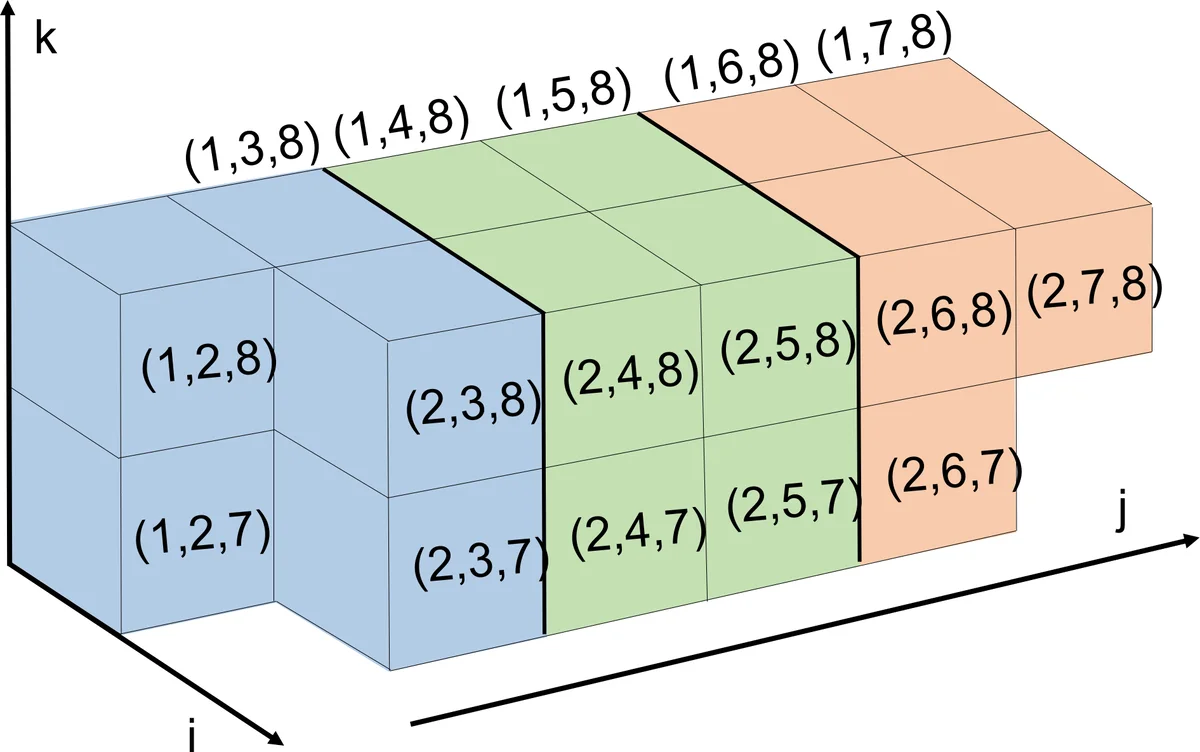
The authors propose a novel parallel execution schedule that dramatically speeds up Dykstra’s method without sacrificing its convergence guarantees. The key observation is that two projection steps can be performed simultaneously without conflict if the corresponding triples share at most one index. In such a case the six distance variables involved are all distinct, so each projection updates a disjoint set of variables. Leveraging this, the authors partition the full set of ordered triples (T = {(i,j,k) \mid 1 \le i < j < k \le n}) into blocks (S_{i,k}) defined as all triples whose smallest index is (i) and largest index is (k) (with (k \ge i+2)). Any two triples belonging to different blocks share at most one index, guaranteeing conflict‑free parallelism.
Each block (S_{i,k}) is assigned to a separate thread or processor. Within a thread, the algorithm proceeds exactly as in serial Dykstra’s method: for each triple it performs a correction step using the stored dual variable, computes the violation (\delta = x_{ij} - x_{ik} - x_{jk}), and if (\delta>0) updates the three involved variables by (-\delta/3, +\delta/3, +\delta/3) respectively. Because each constraint touches only three variables, the updates are highly localized, leading to excellent cache behavior and eliminating the need for locks or atomic operations. After a full pass over all blocks, dual variables are updated, and the next pass begins. The reordering of constraints does not affect the theoretical convergence of Dykstra’s method; the algorithm still visits every constraint exactly once per iteration.
To demonstrate the practical impact, the authors apply the parallel method to the linear‑programming relaxation of correlation clustering, a problem that can be expressed as a metric‑constrained LP with additional “slack” variables. Experiments on synthetic and real datasets with up to (n \approx 10{,}000) nodes (yielding roughly 2.9 trillion triangle constraints) show that the parallel algorithm achieves a consistent speed‑up of about 5× on a modest 8‑core machine and up to 11× on a 32‑core machine, while using less than 30 GB of RAM. Solution quality—objective value and constraint violation—matches or slightly improves upon the serial baseline, confirming that the parallel schedule preserves optimality.
The contributions of the paper are threefold: (1) a rigorous characterization of conflict‑free simultaneous projections for metric constraints; (2) a concrete block‑based partitioning scheme that enables lock‑free parallel execution of Dykstra’s method; (3) extensive empirical validation on a problem of unprecedented scale, establishing that memory‑efficient projection methods can be both fast and scalable. The approach is generic and can be applied to any metric‑constrained linear or quadratic program, including metric‑nearness, sensor‑network localization, and various graph‑clustering relaxations. Future directions suggested include extending the scheme to GPU architectures, handling non‑linear (p)-norm metric‑nearness formulations, and integrating distributed‑memory parallelism for even larger datasets. Overall, the work represents a significant step toward making metric‑constrained optimization practical for modern large‑scale data‑analysis tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment