Multi-stream Network With Temporal Attention For Environmental Sound Classification
Environmental sound classification systems often do not perform robustly across different sound classification tasks and audio signals of varying temporal structures. We introduce a multi-stream convolutional neural network with temporal attention th…
Authors: Xinyu Li, Venkata Chebiyyam, Katrin Kirchhoff
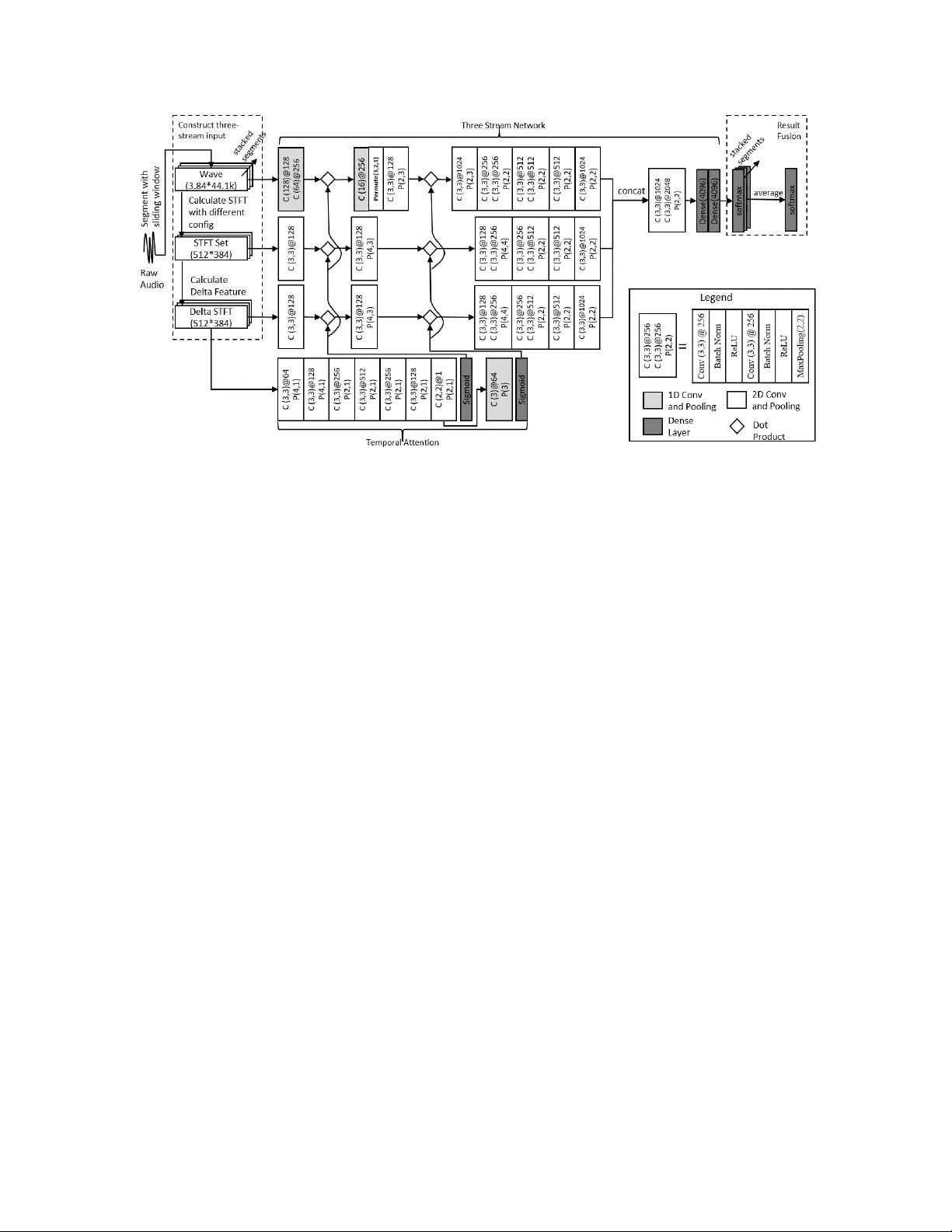
MUL TI-STREAM NETWORK WITH TEMPORAL A TTENTION FOR ENVIR ONMENT AL SOUND CLASSIFICA TION Xinyu Li, V enkata Chebiyyam, Katrin Kir c hhoff Amazon AI { xxnl,chebiyya,katrinki } @amazon.com ABSTRA CT En vironmental sound classification systems often do not per - form robustly across different sound classification tasks and audio signals of varying temporal structures. W e introduce a multi-stream con volutional neural network with temporal attention that addresses these problems. The network relies on three input streams consisting of raw audio and spectral features and utilizes a temporal attention function computed from ener gy changes over time. T raining and classification utilizes decision fusion and data augmentation techniques that incorporate uncertainty . W e ev aluate this network on three commonly used data sets for en vironmental sound and audio scene classification and achie ve new state-of-the-art perfor- mance without any changes in network architecture or front- end preprocessing, thus demonstrating better generalizability . Index T erms — environmental sound classification, audio scene classification, con volutional neural networks 1. INTRODUCTION En vironmental sound classification (ESC) has become a topic of great interest in signal processing due to its wide range of applications. Although many previous studies have sho wn promising results on ESC [1, 2, 3], largely through the in- troduction of deep learning methods, ESC still faces sev eral challenges. First, different studies have identified combina- tions of feature extraction methods and neural network de- signs that work best for individual datasets [2, 4], but that hav e failed to generalize well across different ESC tasks. An- other problem is that environmental sounds often hav e highly variable temporal characteristics (e.g., short duration for wa- ter drops but longer duration for sea wa ves). An ESC model needs to be able to isolate the meaningful features for classi- fication within the acoustic signal instead of o verfitting to the background sound. T o address these problems we propose a multi-stream neural network that uses only the most funda- mental audio representations (wa veform, short-term Fourier transform (STFT), or spectral features) as inputs while re- lying on conv olutional neural networks (CNNs) for feature learning. In order to localize class-differentiating features in highly variable sound signals we propose a temporal attention mech- anism for CNNs that applies to all input streams. Com- pared with attention used for tasks such as neural machine translation [5] our proposed attention mechanism works syn- chronously with CNN layers for feature learning. T o handle signals of variable lengths with our fixed-dimensional CNN architecture we propose a decision fusion strategy with un- certainty . W e tested our model on three published datasets that vary in the number of classes (10 to 50) and audio signal length (from 10 seconds to 30 seconds). Our system meets or surpasses the state of the art on all sets without any changes in model architecture or feature extraction method. W e include an ablation study that highlights the relati ve importance of each system component. The rest of this paper is structured as follo ws: In Section 2 we introduce pre vious related w ork. W e describe our system in Section 3 and e xperimental results in Section 4. Section 5 provides an analysis of the attention function. Section 6 concludes. 2. RELA TED WORK Initial studies of ESC heavily relied on manually designed features [6, 7] and traditional classification methods such as support vector machines (SVMs) and k-nearest neighbor (kNN) classifiers. Subsequent work introduced deep learning to the field; in [8] DNNs were used to replace traditional clas- sification methods. Inspired by work on image classification [9], CNNs were used in combination with time-frequency representations for ESC in [10, 11]. An end-to-end system to directly learn log-mel features from raw audio input was proposed in [3]. More recent research has experimented with features at different temporal scales by merging the RNN outputs o vertime in a stacked RNN architecture [12] and with modifying spatial resolution by applying dif ferent filters to the input [13]. Other approaches to wards impro ving ESC per - formance include higher -lev el input features such as MFCCs, gammatone features, or specialized filters [4, 13] and train- ing with data augmentation [3, 14]. Multiple loss functions were used for the detection of rare sound ev ents in [12]. An ensemble network based on two input streams was proposed very recently [15]. 3. METHOD 3.1. Multi-Stream Network 3.1.1. Pr epr ocessing W e introduce a three-stream netw ork that takes the ra w audio wa veform, short-term Fourier transform (STFT) coefficients, and delta spectrogram as inputs (Figure 1). The wav eform carries both magnitude and phase information represented in the time domain. W e first chunk the audio wa veform into non-ov erlapping segments of 3.84s, resulting in 44 . 1 k × 3 . 84 samples, and then calculate the STFT spectrogram. Different resolutions of STFT highlight dif ferent details in the spec- trogram and emphasize either frequency details or temporal details. W e choose a set of three resolutions corresponding to 32, 128 and 1024 FFT points with a hop length of 10ms. The generated STFTs are scaled into same dimension ( 512 × 384 ) and stacked together as STFT set features. W e further calcu- late delta features with a window size of 5 from each STFT layer and stack them to form a feature vector of the same di- mensionality as the STFT set ( 512 × 384 ). W e restrict our- selves to these basic audio representations instead of higher- lev el features since previous work did not show significant benefit of manually engineered features [9]. 3.1.2. Network Structure W e adopted and modified the EnvNet [3] architecture, which extracts log-mel features with both 1D and 2D conv olutions from the wa veform (Figure 1): F wav ef orm = 2 D C onv (1 D C onv ( x raw )) (1) where x raw is the 1D wa veform. 2 D C onv and 1 D C onv Con v denote the corresponding con volutional operations. The F wav ef orm is the representation learned from x raw , which has three-dimensions (feature, temporal, channel). A 2D CNN was used to learn features F S T F T and F Del ta from the STFT set and the delta spectrogram as: F S T F T /D elta = 2 D C onv ( x S T F T /D elta ) (2) where x S T F T /D elta are the 3D stacked STFT or delta spec- trogram features. W e used 3 × 3 filters for the 2D con volution with batch normalization and ReLU activ ation. Larger filters (128, 64 and 16) were used for 1D conv olution with large strides for fast feature dimension reeduction. Since the con volution and pooling operations do not compromise spatial association we applied the same number of pooling operations to all three streams ov er time. This results in feature representations learned from different streams that are synchronized in the temporal dimension, and that can be merged by concatenating along time (Figure 1). 3.2. T emporal Attention Different environmental sounds can have a v ery different tem- poral structure, e.g. bell rings are different from water drops or sea wa ves. Most previous studies have ignored fine-grained temporal structure and have extracted features at the global signal level [8, 10, 3]. In other domains temporal structure is typically addressed by sequence models such as long short- term memory (LSTM) networks with temporal attention [5]. For ESC, recent studies hav e proposed temporal modeling by subsampling and averaging outputs from RNN layers ov er time [12]; howe ver , this is not equiv alent to weighting differ - ent parts of the signal differentially . A CNN-BLSTM model with temporal attention was proposed in [16]; howe ver , at- tention was calculated within the BLSTM based on features extracted from the CNN; it thus did not influence feature ex- traction itself. W e integrate an attention function into our multi-stream CNN (Figure 1) that is calculated from the delta spectrogram features and directly affects the CNN layers themselves. This representation provides information about dynamic changes in energy , which we assume is beneficial for extracting tem- poral structure. Our initial experiments also showed that attention calculated from delta features has better perfor- mance relativ e to attention calculated from all three inputs. T emporal attention weights are calculated in two steps: 1. Repeat conv olution and 1D pooling along the feature dimen- sion ( pooling k er nel = [ N , 1] ), until the feature dimension equals one (Figure 1, temporal attention block). Because the con volution and pooling operations do not compromise the temporal association of the data, the generated attention vector is temporally aligned with the inputs from all three streams. 2. Pooling along time ( pooling k er nel = [1 , N ] ), which aligns our temporal attention with the features learned by the CNN after each pooling operation. The same atten- tion vector is shared by all three input streams since all three branches are synchronized in time. The attention is applied to the learned features via dot-product operations along the time dimension (Figure 1): F f c = C f c · A , f ∈ [1 , F ] & c ∈ [1 , C ] (3) where C is the output from the con volutional layer with shape ( F , T , C ) and A is the attention vector with shape (1 , T ) . The attention is applied by multiplying the attention vector A to each of the feature vectors in C along feature dimension and channel dimension as C f c · A . The F is the same feature after applying attention that has the same shape as C . 3.3. Decision Fusion With Uncertainty In order to handle audio signals of different lengths with a net- work structure that requires fixed-length inputs we propose a late fusion strategy that computes classification outputs for each input window and then fuses the softmax layer outputs Fig. 1 . System Architecture. for each window by av eraging. Instead of simply av eraging the softmax probabilities over time [3], we further augment the training data with white-noise segments and use a uni- form probability distrib ution over all classes as the target dis- tributions for these segments. Enriching the training data with these maximally uncertain segments biases the system to pre- dict high-entropy softmax outputs when the input does not contain useful information. This is critical in order to prev ent the final decision from being overly influenced by noise or silence segments. 3.4. Data A ugmentation T o av oid possible overfitting caused by limited training data, we adopt the between-class training approach to data augmen- tation [3] and modify it as follows. W e create mixed training samples mix ( x ai , x bj , r ) = r x ai + (1 − r ) x bj (4) where a and b are two randomly selected clips from the training data and i and j are two randomly selected starting points in time. Fixed-length audio segments are selected from each clip based on the start times. The r parameter is a random mixture ratio between 0 and 1 used for mixing the two segments. x denotes the combined three input vectors (wa v , STFT , delta spectrogram). The class labels used for the mixed samples are chosen with the same proportion. W e use this procedure instead of the gain-based mixture (calculating the mixture ratios based on the signal amplitude) suggested in [3] for two reasons: 1. The gain-based mixture is sub- stantially ( ∼ 20 times) slower than our approach, and 2. The gain-based mixture does not apply to 3D features. W e rerun data augmentation at each epoch of neural network training. 4. EXPERIMENT AL RESUL TS 4.1. Datasets and T raining Procedure W e tested our system on three commonly used datasets: ESC-10 and ESC-50 : ESC-50 is a collection of 2,000 en- vironmental sound recordings. The dataset consists of 5- second-long recordings org anized into 50 semantic classes (40 examples per class). The data is split into 5 groups for training and testing. W e use 5-fold cross-v alidation and re- port the av erage accuracy . ESC-10 is a subset of ESC-50 that contains 10 labels. TUT Acoustic scenes 2016 dataset (DCASE) : This data set consists of recordings from various acoustic scenes, all hav- ing distinct recording locations. For each recording location, a 3 to 5 minute-long audio recording was captured. The orig- inal recordings were then split into 30-second segments. The data set comes with an official training and testing split. W e report the av erage accuracy score on four training and testing configurations in line with as previous research. W e implemented our model in Keras with a T ensorFlow backend. The Adam optimizer with an initial learning rate of 0.001 was used; the learning rate decays by a factor of 10 after ev ery 100 epochs. W e used the mean absolute error instead of categorical cross-entropy as a loss function. 4.2. Results and Comparison T able 1 compares our results against pre vious outcomes re- ported in the literature; note that we used the same feature representation and model structure for all datasets. Results show that our model achie ves state-of-the-art or better perfor- mance on all three datasets (T able 1) while most previously ESC 10 DCASE ESC 50 KNN [1] 0.667 0.831 0.322 SVM [1] 0.675 0.821 0.396 Random Forest [1] 0.727 / 0.443 AlexNet [10] 0.784 0.84 0.787 Google Net [10] 0.632 / 0.678 W av eMSNet [13] 0.937 / 0.793 SoundNet [2] 0.922 0.88 0.742 En vNet&BC Training [3] 0.894 / 0.818 0.849* Gammatone [4] / / 0.819 ProCNN [15] 0.921 / 0.828 CNN mixup [14] 0.917 / 0.839 CNN-LSTM [16] / 0.762 / Human [1] 0.957 / 0.813 Ours (A verage) Ours (Best) 0.937 0.942* 0.875 0.882 * 0.835 0.840* T able 1 . Experimental results and comparison. * best score from multiple runs of experiments. proposed approaches show highly div erging performance on different datasets (T able 1, gray shaded rows). Also note that the SoundNet system [2] shows high performance on the DCASE dataset but has been pre-trained on video and audio data, whereas our network is trained purely on audio. W e further analyzed the contribution of each component in our system: the three input streams, the temporal atten- tion and the decision fusion mechanism. The results (T able 2) show that: 1. The three-stream network works better than using a combination of any two of the input streams (T able 2 first three rows). 2. T emporal attention improves the per- formance on all three datasets, which demonstrates the effec- tiv eness of our method. 3. Decision fusion leads to roughly 2.5% accuracy gain across all datasets. 4. Noise augmenta- tion for decision fusion lead to roughly 1% performance gain on all datasets. 5. The data augmentation is necessary for all three dataset, without augmentation, the netw ork will quickly ov erfit to the relatively limited training data. 5. VISU ALIZE AND UNDERST AND A TTENTION En vironmental sounds hav e different temporal structures. Sounds m ay be continuous (e.g. rain and sea wa ves), periodic (e.g., clock tics and crackling fire), or non-periodic (e.g., dog, rooster). T o hav e a better understanding how temporal atten- tion helps with recognizing different sounds, we visualized the attention weights generated for sounds with dif ferent tem- poral structures (Figure 2). From the visualization we can see Fig. 2 . Comparison of generated attention on en viornmetnal sound with different temporal structure. Black line: audio wa veform, Red line: generated attention. that the proposed attention is able to locate important tempo- ral events while de-weighting the background noise (Figure 2, top ro w). The attention curv e has a periodic shape for peri- odic sounds ((Figure 2, middle row) while being continuous for continuous sounds ((Figure 2, bottom row), regardless of sound volume changes ((Figure 2, sea w aves). 6. CONCLUSION W e have described a multi-stream CNN with temporal atten- tion and decision fusion for ESC. Our system was ev aluated on three commonly used benchmark data sets and achie ved state-of-the-art or better performance with a single network architecture. In the future we will extend this work to larger data sets such as Audioset and incorporate mechanisms to handle ov erlapping sounds. ESC 10 DCASE ESC 50 W ithout spectrogram 0.816 0.793 0.715 W ithout delta spectrogram 0.821 0.825 0.697 W ithout raw audio 0.792 0.781 0.745 W ithout attention 0.917 0.853 0.823 W ithout decision fusion 0.915 0.857 0.812 W ithout uncertainty 0.930 0.865 0.825 W ithout data augmentation 0.815 0.770 0.712 Complete Model 0.937 0.875 0.835 T able 2 . Contributions of dif ferent system components. 7. REFERENCES [1] Karol J Piczak, “ESC: dataset for en vironmental sound classification, ” in Pr oceedings of the 23r d A CM in- ternational confer ence on Multimedia . A CM, 2015, pp. 1015–1018. [2] Y usuf A ytar , Carl V ondrick, and Antonio T orralba, “Soundnet: Learning sound representations from unla- beled video, ” in Advances in Neural Information Pr o- cessing Systems , 2016, pp. 892–900. [3] Y uji T okozume, Y oshitaka Ushiku, and T atsuya Harada, “Learning from between-class examples for deep sound recognition, ” arXiv preprint , 2017. [4] Dharmesh M Agrawal, Hardik B Sailor , Meet H Soni, and Hemant A Patil, “Nov el TEO-based gammatone features for en vironmental sound classification, ” in Sig- nal Processing Confer ence (EUSIPCO), 2017 25th Eu- r opean . IEEE, 2017, pp. 1809–1813. [5] Baskaran Sankaran, Haitao Mi, Y aser Al-Onaizan, and Abe Ittycheriah, “T emporal attention model for neural machine translation, ” arXiv pr eprint arXiv:1608.02927 , 2016. [6] Jia-Ching W ang, Jhing-Fa W ang, Kuok W ai He, and Cheng-Shu Hsu, “En vironmental sound classification using hybrid SVM/KNN classifier and MPEG-7 au- dio low-le vel descriptor , ” in Neural Networks, 2006. IJCNN’06. International Joint Conference on . IEEE, 2006, pp. 1731–1735. [7] Selina Chu, Shrikanth Narayanan, and C-C Jay Kuo, “En vironmental sound recognition with time–frequenc y audio features, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 17, no. 6, pp. 1142– 1158, 2009. [8] Nicholas D Lane, Petko Georgie v , and Lorena Qendro, “DeepEar: robust smartphone audio sensing in uncon- strained acoustic en vironments using deep learning, ” in Pr oceedings of the 2015 ACM International Joint Con- fer ence on P ervasive and Ubiquitous Computing . A CM, 2015, pp. 283–294. [9] Alex Krizhevsk y , Ilya Sutske ver , and Geof frey E Hin- ton, “Imagenet classification with deep con volutional neural networks, ” in Advances in neural information pr ocessing systems , 2012, pp. 1097–1105. [10] V enkatesh Boddapati, Andrej Petef, Jim Rasmusson, and Lars Lundberg, “Classifying environmental sounds using image recognition networks, ” Pr ocedia Computer Science , vol. 112, pp. 2048–2056, 2017. [11] Muhammad Huzaifah, “Comparison of time-frequency representations for en vironmental sound classification using con volutional neural networks, ” arXiv preprint arXiv:1706.07156 , 2017. [12] W eiran W ang, Chieh-Chi Kao, and Chao W ang, “ A sim- ple model for detection of rare sound events, ” Pr oc. In- terspeech 2018 , pp. 1344–1348, 2018. [13] Boqing Zhu, Changjian W ang, Feng Liu, Jin Lei, Zengquan Lu, and Y uxing Peng, “Learning environmen- tal sounds with multi-scale conv olutional neural net- work, ” arXiv pr eprint arXiv:1803.10219 , 2018. [14] Zhichao Zhang, Shugong Xu, Shan Cao, and Shunqing Zhang, “Deep conv olutional neural network with mixup for en vironmental sound classification, ” arXiv pr eprint arXiv:1808.08405 , 2018. [15] Shaobo Li, Y ong Y ao, Jie Hu, Guokai Liu, Xuemei Y ao, and Jianjun Hu, “ An ensemble stacked con volutional neural network model for en vironmental ev ent sound recognition, ” Applied Sciences , vol. 8, no. 7, pp. 1152, 2018. [16] Jinxi Guo, Ning Xu, Li-Jia Li, and Abeer Alwan, “ At- tention based cldnns for short-duration acoustic scene classification, ” Pr oc. Interspeech 2017 , pp. 469–473, 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment