Convolutional Neural Networks to Enhance Coded Speech
Enhancing coded speech suffering from far-end acoustic background noise, quantization noise, and potentially transmission errors, is a challenging task. In this work we propose two postprocessing approaches applying convolutional neural networks (CNN…
Authors: Ziyue Zhao, Huijun Liu, Tim Fingscheidt
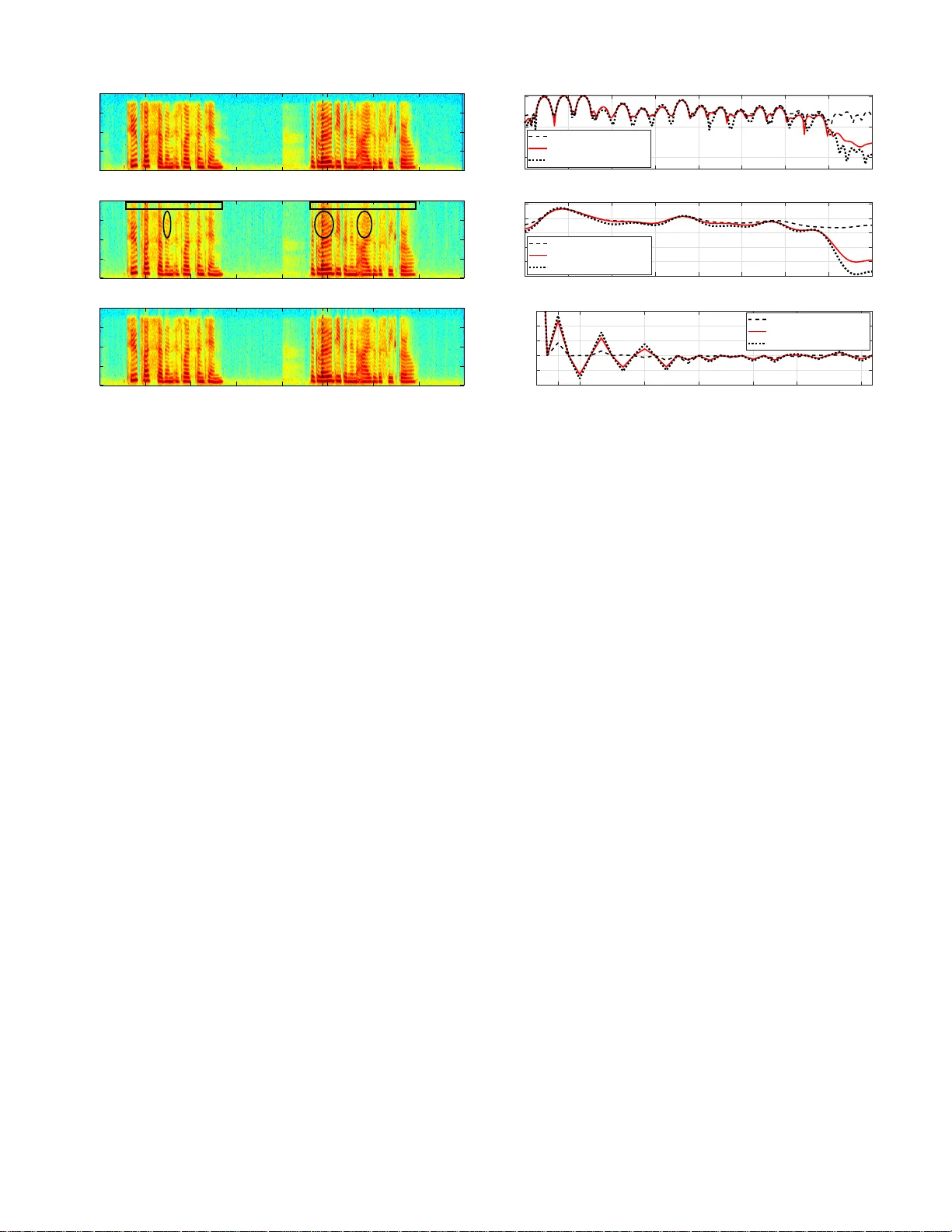
1 Con v olutional Neural Networks to En h ance Coded Sp eech Ziyue Zhao, Huijun Liu, T im Fingsch eidt, Senior Member , I EEE, Abstract —Enhancing coded speech suffering from far -end acoustic background noise, quantization noise, a nd p otentially transmission errors , is a challenging task. In th i s w ork we propose two postprocessing approac hes app l ying con volutional neural n et- works (CNNs) either in the time domain or th e cepstral domain to enhance th e coded sp eech withou t any modification of the codecs. The time domain approach follo ws an end-to-end fashion, while the cepstral domain approach uses analysis-synthesis with cepstral domain features. The proposed postprocessors in both domains ar e eva lu ated for various narro wband and wideband speech codecs in a wide range o f conditi ons. The propose d postprocessor improve s speech quality (PESQ) by up to 0.25 MOS-LQO points f or G.711, 0.30 points for G.726, 0.82 poin ts fo r G.722, and 0.26 points for adaptive multirate w i deband codec (AMR-WB). In a subjective CCR li stening test, the p roposed postprocessor on G.711-coded speech exceeds th e speech qu ali ty of an ITU-T -standardized postfilter by 0.36 CMOS points, and obtains a clear p refer ence of 1.77 CMOS p oints compar ed to legacy G.711, even better than uncoded speech with statistical significance . Th e source code f or the cepstral domain ap p roach to en h ance G. 711-coded speech is made av ailable 1 . Index T erms —conv olutional neural n etworks, speech codecs, speech enhancement. I . I N T RO D U C T I O N S PEECH signals be ing subject to speech enco ding, trans- mission, an d decod ing are often called tr anscoded s pe e ch, or simply: coded speech. Coded speech often suffers from far -en d acoustic b ackgro und n oise, quantiza tio n noise, and potentially transmission e r rors. T o enhance the qu a lity of coded speech , postproc essing metho ds, operatin g just after speech decod ing can be ad vantageously emp loyed . T o combat quantization n oise at the receiver , a postfilter based on classical W iener theory o f optimal filtering has been standardiz e d for the logarith mic p ulse code modulatio n (PCM) G.71 1 co dec [ 1 ]. It is p art of the G. 711 audio qu ality enhancem ent toolbo x [2], described in detail in the append ix of G.711.1 [3], a wideband e xten sion o f G.711 . This postfilter uses a priori info rmation on the A- or µ -law pr operties to estimate the q u antization n oise power sp ectral de nsity (PSD), assuming the quantiza tio n noise to be spectrally wh ite [4], [5]. Then, a Wiener filter is der iv ed by the e stimation of the a priori sign al-to-no ise-ratio ( SNR) b ased on a two-step noise reduction ap p roach [6]. After the filtering pro cess, a limitation of distortions is performed to contr ol the waveform difference between the orig inal signal and th e p ostprocessed co ded signal. Howe ver , as the b itrates go down for m ost of the mode r n codecs, it becomes more d ifficult for the classical W iener filter to effectively suppress th e q uantization noise, wh ile 1 https:/ /github .com/ifnspaml/Enhan ceme nt-Coded-Speech maintaining th e sp e e ch perceptually undistorted , since the SNR drop s and more impor tantly , only the mean squared err o r (MSE) is min imized in the W iener filter [ 7 ]. T h erefore , some perceptu a lly-based postfilters h av e been pr oposed to red uce the perceptu a l d egradation caused by low bitrate codecs. Formant enhancem ent postfilters [8], [9] emph asize th e peaks of the spectral envelope while fu rther supp ressing the v alleys to reduce the imp act of qu antization noise in coded speech, since the form ants are perce p tually mor e imp o rtant than th e spectral valle ys. This type of po stfilter typically consists of three parts [9]: T he core short-te r m postfilter to enhan ce the forman ts, a tilt c orrection filter to c ompensate the lo w-pass tilt caused b y the core postfilter , and an adaptive g ain co n trol to compen sate the g a in misadjustment caused by par ts one and two. In additio n to m odifyin g the spectral envelope of the speech signal, th e spectra l fin e s tru cture of voiced speech is improved by a pitch enhance m ent postfilter , a iming to emphasize the h ar- monic peaks and attenu a te th e g aps between the harmon ics [9]. In practice, this lon g -term p ostfilter is always applied to lo w frequen cies, wher e harmo n ic peak s are m o re promine nt, which actually for ms a bass po stfilter [10]. This ba ss postfilter and the f ormant e nhancem e nt postfilter ar e used eith er to gether or separately in the d ecoders of some stand ard codecs, e.g., in adaptive mu lti-rate (AMR) [11], wideband AMR (AMR- WB) [12] an d enhanc e d voice serv ices (EVS) [1 3]. For speech codecs using th e so-called algebr a ic code-excited linear p rediction (A CELP) codebook s, e.g., AMR and AMR- WB, an a n ti-sparseness postpr ocessing pro cedure is applied, aiming to suppr ess the perceptual artifacts c aused by the sparseness of the algebraic fix ed codebook vectors with only a few non-z e r o pulses p er subfram e , especially in lo w bitrate modes [11], [12]. A modificatio n of the fixed codebo ok vector is adaptively selected based on the quantized adaptive codebo ok gain [14]. In an attem pt to combat quantization noise, it has been shown that if residu al corr elation exists in coded signals [15]– [17] or m ore specifically , coded speech [18], a time- variant receiver -sided c odeboo k or a shallow neural n etwork can provide some gains in a system - compatib le fashion. Apart from the aforementioned quantization n oise, also far - end acoustic backg round noise can degrade the q uality and intelligibility of coded speech . In mo st ca ses, noise redu ction approa c h es are conducted as a transmitter-sided prepro cessing step to suppr ess the back groun d no ise before the speech sign al is coded and transmitted [1 9]. H owever , since the n oise u sually cannot be entirely suppressed and therefore speech with some residual noise is co ded and transmitted to the receiver side, 2 one can aim to further red u ce the noise of th e cod ed speech in the po stprocessing proced ure. T o acco mplish this, a modified postfilter has been proposed fo r speech quality enh ancemen t, where the parameters cor respond ing to the formant an d pitch emphasis are adaptively updated based on the statistics of the backgroun d no ise [20]. Fu rthermor e, in adverse no ise condition s, also po stfilterin g meth ods to improve the speec h intelligibility have been studied [21]. Additiona lly , a kind of postproce ssing to en hance the coded speech in tr ansmitter- sided no isy environments by restoring the distorted back- groun d n oise wh ile m asking main codin g artifacts fo r low bitrate speech co ding is prop osed and standardized in EVS as co mfort no ise add ition [13]. An artificial comfo rt noise is ge n erated and add ed to th e cod ed spee c h signal after the lev el and the spectral shape of the back groun d noise are estimated [22]. Recently , sp eech en hancemen t based on n e ural ne twork s has been intensively studied [ 23]–[37]. Dee p neural networks (DNNs) are used as a classification method to estimate the ideal binary m ask [23] or sm o othed idea l ratio m ask [24] for no ise reduction . Also, som e regression appro a ches b ased on DNNs to learn a mapping functio n from noisy to c lea n speech features have b een p roposed [ 25], [26]. Fur thermor e, a deep denoising auto encoder is applied for n oise redu ction, with either both clean pairs [2 7] or n oisy an d clean pa irs [28] as inputs and targets to train the au toencod er . Besides, recurre n t neural networks (RNNs) are used for speech enhan c ement, e.g., a r e c urrent de n oising auto encoder f or r o bust autom atic speech reco g nition (ASR) [2 9] a nd long short- term memo ry (LSTM) structur e fo r noise reduction [30], [31]. In ad dition to the DNNs and RNNs, con volutional neu ral networks (CNNs) are achieving increasing atten tio n for the speech enha n cement task [32]–[37]. The CNNs are trained to learn a m apping between the no isy sp e ech features and the clean spe e ch features, e.g ., log -power spectru m [3 2]–[34] or co mplex spectrogr a m [35], or a mapp ing directly between the noisy raw sp eech w aveform and clean raw speech wa ve- form [3 6], [37]. The c o n volutional layers in th e CNNs have the prop erty o f local filtering, i.e., the inp ut features share the same network weights, resu ltin g in translation inv ariance for the o u tput of th e network , which is a d esired pro perty for th e modeling of speech [3 8]. This local filtering pr operty makes the CNNs ha ve the ab ility to characterize lo cal information of the speech sign al, which clear ly provides benefits for th e task of spe ech en hancemen t. It is also because of this property that the number of the train able weig hts is r educed in a large scale compare d to DNNs and RNNs with fu lly-conn ected struc tures, making it mo r e efficient to train the n e twork [32 ]. In this work, we u se CNNs to enhan ce coded speech, so that this ope r ation can be seen as a po stprocessor a f ter speech decoding (or an ywh ere later in the transmission chain) aiming at im p roving speech quality at th e far-end, which is different to the afo remention ed noise red uction appr o aches. Fig. 1 shows the genera l flow cha r t o f postprocessing f or coded speech. Motiv ated b y the su c c essful app lication of CNNs to the image super-resolution prob lem in computer vision [39]– [42], aim in g at restor ing the m issing info r mation from the low-resolution im age, we propo se to use similar con volutional P S f r a g r e p l a c e m e n t s ˜ s ( n ) s ( n ) ˆ s ( n ) Source Speech Bitstre am Coded Speech Enhanced Speech Speech Encoder Speech Decoder Post- processor Fig. 1. General flow chart of postprocessing for enhance ment of coded speech. network structu res to restore improved speech f rom spee c h being subject to encoding and decoding . I n terms of the topolog y , we ado pt the deep conv olutiona l encode r-decoder network to pology [4 0], wh ich is a symmetr ic stru cture with multiple layer s of c o n volution and de c on volution [43], [44], in order to firstly preserve the major infor mation of the inpu t features and m e anwhile red u ce the corru ption a nd then recover the details of the features [40], [41]. Furthermore, skip-layer connectio ns are added symmetrically between the conv olutio n and deconv olution layers to form a residual network for an effecti ve train in g [4 2], [45]. The contr ibution of this work is threefo ld: First, based on the CNN topo logy , we prop ose two d ifferent postprocessing approa c h es in the time domain and the cepstral domain to restore the speech either in an end - to-end fashion or in an analysis-synthe sis fashion with ce p stral domain features. T o our knowledge, it is the first time that deep learn in g m e thods are used to enhance coded spee ch. Secon d, we show by objective and subjective listening quality assessment that both propo sed a pproach es show superior p erforma nce com pared to the state of the ar t G.711 postproc e ssing. Finally , both propo sed app roaches are system- c o mpatible for different kinds of codecs w ith out a ny modification of the encoder or decoder . The simulation resu lts in c lea n and n o isy speech cond itio ns, tandeming , and frame loss condition s show their ef fectiveness for some widely used sp e e ch codec s in nar rowband a nd wideband . The article is structured as follows: In Section II we br ie fly sketch state of the art G. 7 11 p ostprocessing, which serves as a baseline method in the evaluation part. Next, we describe the prop o sed CNN po stprocessing ap proach es in both time domain and cep stral dom a in in Section II I. Subseque n tly , the experimental setup and the instrumen tal metr ics for speech quality ev aluation are explained in Sectio n I V. Then, in Section V, we present th e ev aluation results and d iscussion. Finally , we co nclude our work in Section VI. I I . T H E G . 7 1 1 P O S T P RO C E S S I N G B A S E L I N E In Fig. 2 the G.7 11 postpro cessing aiming at attenuation of quantization noise is depicted. It ha s originally b een propo sed in [4] and standardized in [2], basically following th e cla s- sical framework of no ise reduction, comprising: quantization noise power spec tral d ensity (PSD) estimation, a priori SNR estimation, spectra l weightin g rule using th e W iener filter, and finally a quantization con straint. In the following subsections, this G.711 po stprocessing is briefly revie wed as our b aseline for enha ncement o f G.711-coded speech . A. Qua ntization Noise PSD Estimation At first th e coded speech s ( n ) is subject to a periodic Hann window and then being transforme d to the fr equency do main 3 P S f r a g r e p l a c e m e n t s s ( n ) S ( ℓ, k ) ˆ ξ 2 ( ℓ, k ) G 2 ( ℓ, k ) ˆ σ 2 n ( ℓ ) g 2 ( n ) ˆ s ( n ) W indo wing and FFT A priori SNR Estimation Spectra l Gain Function IFFT and W indo wing Quantiz ation Noise PSD Estimation Filteri ng and OLS Quantiz ation Constrai nt ˆ s 2 ( n ) Fig. 2. The postprocessing flow chart of the G.711 Amendment 2: New Appendix III audi o qualit y enhance ment toolbox (see [2 ]). representatio n S ( ℓ, k ) via the fast Fourier transform (FFT), with ℓ being the fram e index and k being the f requency bin index. Since the qu antization noise o f G.7 11 is a ssumed to be spectrally white, the estimate of the q u antization noise variance σ 2 n ( ℓ ) is suf ficient for the qu antization noise PSD es- timation. T o ach iev e this, an estimate of the (un coded) source speech signal variance ˆ σ 2 ˜ s ( ℓ ) is need e d first, and subsequ ently an estimate of th e load factor, defined as ˆ Γ( ℓ ) = 1 / ˆ σ ˜ s ( ℓ ) denoting how the sign al exploits the qua ntizer dy n amic, is achieved. Interestingly , the estimate of the unco ded signal vari- ance ˆ σ 2 ˜ s ( ℓ ) is actu ally obtained by estimating the co ded sig nal variance ˆ σ 2 s ( ℓ ) , assuming the variance o f the qu a n tization noise to be very low comp ared to the unc oded signal most of the time [4]: ˆ σ 2 ˜ s ( ℓ ) ≈ ˆ σ 2 s ( ℓ ) = 1 |N ℓ | X n ∈N ℓ s 2 ( n ) . (1) The set N ℓ contains all sample ind ices n belonging to frame ℓ and |N ℓ | is the number of samp les in the fram e. Then the signal-to-q uantization -noise ratio is obtained ac c ording to the estimated load f acto r ˆ Γ( ℓ ) and the A- or µ -law function. Finally , the estimate of th e ( spectrally wh ite) q uantization noise variance ˆ σ 2 n ( ℓ ) is obtained. B. A priori S NR E stimation and W iener F iltering After estimatio n of the noise PSD, the a priori SNR is obtained by a two-step noise reductio n techn ique [6] and subsequen tly the W iener filter results. In or d er to estimate the a priori SNR, the a posteriori SNR is c omputed first as γ ( ℓ, k ) = | S ( ℓ, k ) | 2 ˆ σ 2 n ( ℓ ) . (2) Then, the first-step spectral gain f unction G 1 ( ℓ, k ) from the W iener filter ca n be expressed as G 1 ( ℓ, k ) = ˆ ξ 1 ( ℓ, k ) 1 + ˆ ξ 1 ( ℓ, k ) , (3) where the first-step a priori SNR estimate ˆ ξ 1 ( ℓ, k ) fr om th e decision-d ir ection app roach [4 6] is ˆ ξ 1 ( ℓ, k ) = β | ˆ S 1 ( ℓ − 1 , k ) | 2 ˆ σ 2 n ( ℓ − 1) + (1 − β ) max γ ( ℓ, k ) − 1 , 0 , (4) P S f r a g r e p l a c e m e n t s s ( n ) W indo wing s ( ℓ ) s ( n ) W indo wing s ( ℓ ) Time Domain Processing Cepstral Domain Processing ˆ s t ( ℓ ) ˆ s c ( ℓ ) Concat enation ˆ s ( n ) W a veform Reconstr uction ˆ s ( n ) Fig. 3. CNN-based postproce ssing for time domain appr oach (upper) and c epstral domain approac h (lo wer). More details of the cepstral domain processing can be found in Figs. 4, 5, and 6. with ˆ S 1 ( ℓ − 1 , k ) = G 1 ( ℓ − 1 , k ) S ( ℓ − 1 , k ) and β bein g a weighting factor . In the second step, an u pdated spe ctral gain function is com puted as G 2 ( ℓ, k ) = m ax ˆ ξ 2 ( ℓ, k ) 1 + ˆ ξ 2 ( ℓ, k ) , G min ! , (5) where G min is the lower limit to av oid ov er-attenuation and ˆ ξ 2 ( ℓ, k ) = | G 1 ( ℓ, k ) S ( ℓ, k ) | 2 ˆ σ 2 n ( ℓ ) (6) is the up dated a priori SNR estimate. Finally , a causal filter impulse response g 2 ( n ) is obtained from this up dated spectral gain fun ction (5) by in verse FFT (IFFT) and imp osing a linear phase, and the coded speech s ( n ) is time-dom ain-filtered and the overlap and save (OLS) method provides the enhanced speech ˆ s 2 ( n ) . No te that d ue to its frame structure, th e G.711 postfilter baseline has an algo rithmic delay of 2 ms. C. Quan tiza tio n Con straint In ord er to avoid extra distortion intro duced by th e above postproce ssing, finally a limitation of potential distortio ns is perfor m ed. Since th e quantization interval of each co ded speech sample s ( n ) is known, this idea is to limit the post- processed samples ˆ s ( n ) to lie within the respective inter val. I f an o utlier sample (outside the certain quan tization interval) is detected, the co nstraint will rep lac e it by th e closest d ecision bound ary of th is respecti ve quan tiza tion interval. After appli- cation of this con straint, the final postprocessed speech ˆ s ( n ) is obtained . I I I . C O N VO L U T I O NA L N E U R A L N E T W O R K ( C N N ) P O S T P RO C E S S I N G In this sectio n, we p resent the pr oposed CNN-based post- processing fo r cod ed speech alternatively in th e time domain and in the cepstra l d omain. Fig. 3 depicts the high-level block diagram. A t first, fo r both appr o aches, the coded speech s ( n ) is assembled to fr ames s ( ℓ ) , applying a window function. Then, the fra m e is processed eith er in the time dom ain r e su lting in ˆ s t ( ℓ ) , or in the cepstral dom ain resultin g in ˆ s c ( ℓ ) . Finally , the enhanced sp eech ˆ s ( n ) is obtained v ia eith e r a dire ct concatenatio n of the proc essed frames ˆ s t ( ℓ ) fo r the time domain ap proach , or some waveform reconstru ction of the processed fr ames ˆ s c ( ℓ ) for the cep stral domain a pproach , as outlined in th e f ollowing. A. T ime Domain A p pr oach: Pr ocessing For th e time d omain app roach, we choose a quite straig h t- forward fra m ew ork structu re (i. e . , wind owing and wa vefor m 4 1 6 . 0 5 . 2 0 1 7 | Z i y u e Z h a o | C N N b a s e d P o s t P r o c e s s i n g f o r G . 7 1 1 C o d e d S p e e c h E n h a n c e m e n t D N N b a s e d Po s t Pr o c e s s o r P S f r a g r e p l a c e m e n t s W indo wing Processing Approache s W a veform Reconstr uction ˆ s ( n ) ˆ s ( n ) ˆ s ( n ) s ( n ) 0 · · · 0 0 ... 0 0 ... 0 0 . . . 0 0 0 . . . 0 Processing Processing Processing Drop Past OLA OLA D r o p P a s t O L A O L A I II III I V V V I 10 ms 10 ms 10 ms 2 0 m s 2 0 m s 1 6 m s Frame work Structure Num. 1 6 . 0 5 . 2 0 1 7 | Z i y u e Z h a o | C N N b a s e d P o s t P r o c e s s i n g f o r G . 7 1 1 C o d e d S p e e c h E n h a n c e m e n t D N N b a s e d Po s t Pr o c e s s o r P S f r a g r e p l a c e m e n t s W i n d o w i n g P r o c e s s i n g A p p r o a c h e s W a v e f o r m R e c o n s t r u c t i o n ˆ s ( n ) ˆ s ( n ) ˆ s ( n ) s ( n ) 0 · · · 0 0 . . . 0 0 . . . 0 0 ... 0 0 0 ... 0 Processing Processing Processing D r o p P a s t O L A O L A Drop Past OLA OLA I I I I I I IV V VI 1 0 m s 1 0 m s 1 0 m s 20 ms 20 ms 16 ms F r a m e w o r k S t r u c t u r e N u m . Fig. 4. Framework structures for windowing, ( cepstra l dom ain ) processing, and wav eform reconstructi on. In the upper part of the figure, all signal portions necessary to be ava ilable for computing the first frame ℓ of ˆ s ( n ) are marked as white boxes , as is the current output frame ˆ s ( n ) , n ∈ N ℓ , in the bottom part of th e figure. OLA st ands for ove rlap-add of all upp er-part white windo wing box es for current frame ℓ . Frame work Stru cture I II III IV V VI W indo w length N w [ms] 32 15 20 32 25 32 Processing length [ms] 32 16 32 32 32 32 Processing shift N s [ms] 10 5 10 20 20 16 Output ove rlap ratio 0 66.7% 50% 0 20% 50% Addition al delay [ms] 0 10 10 0 5 16 T ABLE I D E TA I L E D S E T T I N G S O F T H E F R A M E W O R K S T RU C T U R E S F O R T H E C E P S T R A L D O M A I N A P P R OA C H . reconstruc tion) which fits to most speech decoders: a 10 ms rectangu la r window without overlapping. The windowed fram e s ( ℓ ) then serves directly as the input of the CNN with the target b eing ˜ s ( ℓ ) , which is the n o ise-free undistorted (uncod ed) windowed sp eech frame. Details of the CNN topolo gy will be presented in Sec tion V -A. After CNN processing, the enhanced frame ˆ s t ( ℓ ) is directly concatenated to reconstruct the wa veform ˆ s ( n ) . The motiv ation of this end-to- end tim e domain approach is to learn a ma pping fro m the coded speech fram e to the un distorted speech fr ame v ia the CNN, exploiting the temporal r edunda n cy in term s of speech sign al correlation in the decod er , to directly en h ance the waveform of the cod ed speech. Beyond f raming, no additional alg orithmic delay is incur red. Note that this allows e ffectively latency-fr ee postfiltering if th e f rame size m atches the frame size of the speech deco der or if it matches the voice-over-IP pa cket size. B. Cepstral Doma in App r oach: F ramework Structures This subsectio n presents the various fram ew ork structures for the cep stral domain ap p roach, shown in Fig. 4. On the one hand, since FFT and discrete cosine tr ansform (DCT) are perfo rmed in the cepstral do main approach to ob tain the cepstral coeffi cien ts (explained in detail in Section III -C), an approp riate fr ame len gth and overlapping setting are impo r- tant. On the othe r han d, since the po stprocessor follows the speech decoder, the frame lengths of typical deco ders ar e also taken in to con sideration to design the fra m ew ork structures. As a result, we in vestigate six framew or k structure s to of fer broa d selections for v ario u s possible application scen arios. These structures can be d ivided into three gr o ups: Structures I, II and III a r e design ed fo r co d ecs with 10 ms f rames, IV and V are design e d for co decs with 20 ms fr ames, while structure VI is for d elay-insensitive off-line usage with 16 ms f rames, one fram e look ahead, an d 50% overlap. First of a ll, windowing of the co ded speech s ( n ) is imple- mented to fo rm frames fo r processing, which can b e denoted as s ( ℓ ) = s ( ℓ − 1) N s , . . . , s ( ℓ − 1) N s + N w − 1 ◦ w , ( 7 ) where N s is the frame shift, N w is the length of window function , w is the window fu nction vector, and ◦ d enotes the sample-wise mu ltip lication. As shown in Fig. 4, all six frameworks req uire a few initial zero s to be p added to th e coded input speech. The detailed setting s of the framew ork structures are listed in T able I. It is worth noting that if the processing length is lon ger that the win dow length , a zero- padding is pe rformed also after win dowing. After p rocessing of the windowed fram es, the speech wav e- form needs to be recon structed, which is also illustrated in Fig. 4. I n structure I a n d structure I V , only the latest samples of the pr ocessed fram e are kept and the o ther samp les a r e dropp ed, wh ich means that beyond framing (10 ms and 2 0 ms, respectively) n o additional algor ithmic delay coccu s. If used in co njunction with speech d ecoders operatin g with this frame size, or if used in conjunction with, e.g., G.711, G.726, or G. 722, assemb led to 10 ms voice-over IP p ackets, the en tire postproce ssing is effectively free of algo rithmic delay (as is the case in the time dom a in ap proach, cf. Section III- A). In structures II, III and VI , since p eriodic Han n win dows are employed, th e processed f rames ov erlap and need to be added after time alignmen t. As a result, addition al a lg orithmic delay is intr oduced for each of these three stru ctures. Structu r e V aims at low comp lexity by using a flat-top periodic Hann window with low overlap ratio. In this structure, the output signal will be delayed by on ly 5ms, i.e., the outp ut starts with 5 ms of zeros. 5 1 6 . 0 5 . 2 0 1 7 | Z i y u e Z h a o | C N N b a s ed P o s t P r o c es s i n g f o r G . 7 1 1 C o d e d S p e e c h E n h a n c em e n t D N N b a s e d P o s t P r o c e s s o r P S f r a g r e p l a c e m e n t s FFT log 10 | · | DCT -II Separat ion CNN Combinati on IDCT -II 10 ( · ) e j ( · ) IFFT arg ( · ) Cepstral Domain Proce ssing s ( ℓ ) S ( ℓ ) c ( ℓ ) c env ( ℓ ) c res ( ℓ ) α ( ℓ ) ˆ c env ( ℓ ) ˆ c ( ℓ ) ˆ S ( ℓ ) ˆ s c ( ℓ ) Fig. 5. P roc essing structur e of the cepstral domain approach . The topology of the C NN block is identical in the ti me domain and the cepstral domain approac h and is depicted in Fig. 6. P S f r a g r e p l a c e m e n t s Con v ( F,N × 1) Con v ( F,N × F ) Max Pooling (2 × 1) Con v (2 F,N × F ) Con v (2 F,N × 2 F ) Max Pooling (2 × 1) Con v ( F,N × 2 F ) Upsampling ( 2 × 1) Con v (2 F,N × F ) Con v (2 F,N × 2 F ) Upsampling ( 2 × 1) Con v ( F,N × 2 F ) Con v ( F,N × F ) Con v (1 ,N × F ) L × 1 L × F L × F L/ 2 × F L/ 2 × 2 F L/ 2 × 2 F L/ 4 × 2 F L/ 4 × F L/ 2 × F L/ 2 × 2 F L/ 2 × 2 F L/ 2 × 2 F L × 2 F L × F L × F L × F L × 1 s ( ℓ ) or c env ( ℓ ) ˆ s t ( ℓ ) or ˆ c env ( ℓ ) CNN (skip) (skip) Fig. 6. Detailed view of the CNN structur e in both time domain ( L equals 10 ms of speech samples) and cepstral domai n ( L = |M env | ). The operation Con v() sta nds for conv olutiona l layers containing two parameters, whi ch are the number of feature maps (filter ke rnels) F or 2 F , and th e kernel size ( a × b ). The m ax po oling and up sampling layers ar e describe d by the kernel size ( 2 × 1 ). The input and output dimensions of each layer are also gi ven. The light gray areas contain t wo symmetric procedur es. C. Cepstral Domain Ap pr oach: Pr ocessing As we h av e lear nt from th e aforem entioned formant post- filters, an emph a sis of the spec tr al envelope pe a ks can r educe the imp act of the codin g d istor tion. By using cepstra l domain en velope features, th e d im ension of th e inp ut vector to the CNN will be largely reduced compared to the time do m ain approa c h , which makes the CNN able to conce n trate on the mo re percep tually relev ant in formation , i.e., the fo r mant structure. Our ce p stral do m ain ap proach uses a CNN to restore the cepstral coefficients r esponsible for the spectral envelope and then synthesizes the speech frame using the enhan ced envelope cepstral coefficients, as well a s the residual cepstra l coeffi- cients and the phase infor mation, the two latter bo th being acquired fro m the cod ed speech f rame. The whole pro cessing structure is shown in Fig. 5. At first, the windowed fram e is transfor med to the frequen cy domain as vector S ( ℓ ) u sin g the K - point FFT . Su bsequently , the cep strum (cep stra l coefficients) is compu te d by applyin g the d iscrete co sin e tran sf o rm of type II (DCT - II) to the logarithm ic magnitud e spectru m, wh ich can be exp ressed as c ( ℓ, m ) = X k ∈K log ( | S ( ℓ, k ) | ) · co s π m ( k + 0 . 5) /K , (8) where k ∈ K = { 0 , · · · ,K − 1 } is th e frequ e n cy bin index and m ∈ M = { 0 , 1 , · · · ,K − 1 } is the ind ex of cepstral coe fficients. Then, the cep strum is lowpass liftered (i.e., taking only the lower part o f the cepstru m) to o btain the cepstral co efficients responsible for the spec tr al en velope, which is deno ted as c env ( ℓ, m ) with m ∈ M env . In this work, we regard the first 6 . 25% c epstral coefficients as the coefficients responsib le f or the spectral envelope 2 , resulting in |M env | = 6 . 25% · |M| . This vector c env ( ℓ ) serves as the inpu t to th e CNN, wh ich then provides the re stored cepstral coefficients respo nsible for the spectral envelope ˆ c env ( ℓ ) . After that, the residual cepstral co efficients fr om th e liftering , den oted as c res ( ℓ, m ) with m ∈ M res , are co ncatenated to ˆ c env ( ℓ ) to constitute the complete cepstral co e fficient vector ˆ c ( ℓ ) . Then the loga r ithmic magnitud e o f th e processed spectr um ˆ S ( ℓ ) is calculated by in verse DCT -II ( IDCT -I I) as log ˆ S ( ℓ, k ) = 1 K " ˆ c ( ℓ, 0) + 2 K − 1 X m =1 ˆ c ( ℓ, m ) · cos π m ( k + 0 . 5) K # . (9) Finally , th e elem ents of ˆ S ( ℓ ) ar e subsequently obtain ed b y ˆ S ( ℓ, k ) = ˆ S ( ℓ, k ) exp ( j · α ( ℓ, k )) , (10) 2 As we have K = 512 for narrowband speech, the 0 . 0625 · K -th = 32 nd cepstra l coef ficient represents t he frequenc y 1 / (32 × 1 16 ms ) = 50 0 Hz (check (8) !). Usin g 500Hz as cepstral lo wpass liftering cutof f fre quency , the fu nda- mental frequenc y (F0) wil l be excluded in m ost cases. This is because the fundamenta l frequenc y can va ry from 40 Hz for a v ery low-pi tched male voic e to 600 Hz for a very hi gh-pitched female or chil d voice [47]. As a result, the pitch periodic ity fro m speech is remove d, while the informati on of the spectral env elope representing the formants is kept for further processing. 6 P S f r a g r e p l a c e m e n t s T e s t S e t I n i t i a l Filteri ng Lev el Adjustment C o n c a t e n a t i o n Do wn- Sampling R e f e r e n c e S p e e c h S e g m e n t a t i o n C o d e d S p e e c h S e g m e n t a t i o n D E C C o n v e r s i o n B i t C o n v e r - s i o n & E N C E n h a n c e d S p e e c h S e g m e n t a t i o n P o s t - p r o c e s s o r D E C & B i t C o n v e r s i o n B i t C o n v e r - s i o n & E N C V AD Tra ining& V alidat ion T ar get Data Preparat ion Tra ining& V alidat ion Input Data Preparat ion DEC B i t C o n v . & D e l a y C o m p . D e l a y C o m p . & B i t C o n v . ENC Tra ining& V alidat ion Set R M S L e v e l N o i s e D a t a E I D N o i s y C o n d i t i o n E r r o r - P r o n e C o n d i t i o n Fig. 7. T raining and v alidation prepro cessing. where α ( ℓ ) is the phase inform ation from S ( ℓ ) . The pro cessed frame ˆ s c ( ℓ ) is obtained b y performing the IFFT of ˆ S ( ℓ ) . D. Both A ppr oaches: CNN T opology The CNN to pology , both in the time domain app roach or in the cep stral domain ap p roach, is a deep conv olution al encoder- decoder network, which is shown in Fig. 6. This top ology is motiv ated fr o m [4 0] an d thre e different kin ds of layers are used in this to pology which will be explained in the f ollowing. The convolutional layers are d efined by the numb er F or 2 F of feature maps (filter kernels) and the kernel size ( a × b ). The number of trainable weights, including the bias, of a conv olu- tional layer denoted as, e.g., the first layer (Conv ( F,N × 1) ), results in F × ( N × 1) + F . It is worth n o ting that in each conv olutiona l layer , the stride is 1 and ze ro-pad ding of the layer input is always per formed to gua rantee that the first dimension of the layer outp ut is th e same as that for the layer input. In max poolin g layers , a 2 × 1 ma ximum filter is applied in a non-overlapp ing fashion, resulting in a 50% reductio n of the lay er inp ut along the first dimen sion. On the contr ary , the upsampling la y ers simply co py each element of the layer input into a 2 × 1 vector and stack these vectors just following the original o rder, which actually d oubles the first dim ension of the layer in put. As can be seen in Fig. 6, two light g r ay areas include two sym m etric proc e d ures, respectively . In the first procedure, the con volutional layers and the max poo ling layers are used together to extract the relev ant in formation an d to d iscard th e corrup ted par ts of the CNN input f eature vector , resulting in a compression of the vector length. The second procedure is designed to recover the detail info r mation via th e com bination of upsamping lay e rs a n d con volutional layers. Meanwhile, the vector length is increased back to the or ig inal dimen sio n b y using two time s th e upsampling layer . I n th e last conv olutio nal layer, a linear acti vation fu nction is used and the final output has exactly the same d imension L as th e inp ut of the CNN. Furthermo re, two skip co n nections are utilized to a d d up the P S f r a g r e p l a c e m e n t s T est Set I n i t i a l Filteri ng Filteri ng Lev el Adjustment Adjustment Concat enation Do wn- Do wn- Sampling Sampling Referen ce Speech Segment ation Coded Speech Segment ation D E C C o n v e r s i o n B i t C o n v e r - s i o n & E N C Enhanced Speech Segment ation Post- processor D E C & B i t C o n v e r s i o n B i t C o n v e r - s i o n & E N C V A D T r a i n i n g & V a l i d a t i o n T a r g e t D a t a P r e p a r a t i o n T r a i n i n g & V a l i d a t i o n I n p u t D a t a P r e p a r a t i o n DEC DEC B i t C o n v . & D e l a y C o m p . D e l a y C o m p . & B i t C o n v . ENC ENC T r a i n i n g & V a l i d a t i o n S e t RMS Lev el Noise Data EID EID Noisy Condition Error-Prone Conditi on Fig. 8. T est processing for vario us codecs and postproce ssors in clean, error- prone transmission, an d noisy conditi ons. correspo n ding layer ou tputs, in order to ease the vanishing gradient prob lem d uring the training of this d eep CNN [40]. I V . E X P E R I M E N TA L S E T U P A N D M E T R I C S A. Sp eech Datab ase Speech data used in this work is from the NT T wideband speech datab ase [48], con ta in ing 21 different languages, and 4 fem a le and 4 m ale speakers for eac h language. Each of the speakers is represented by 1 2 speec h u tterances of about 8 secon ds duratio n. American En g lish and German a r e used for test, and fo r each lang uage, the test set contains 30 speech utterances, in which 3 female speakers and the 3 male speakers are represen te d by 5 different speech utteranc es, r espectively . For the train ing set, all speech utterances from 3 female speakers and 3 male sp eakers in all other 1 9 langu ages ar e chosen, while 9 speech utter ances fr om e a c h of the rem a in - ing speakers (female sp e aker f4 a n d m ale spea ker m4 pe r languag e ) in the same 1 9 lan guages ar e used a s validation set. Th e r eby we provid e ( partly 3 ) langu age-indep endent but completely speaker-independ ent results th rough out. B. Prepr o cessing for T raining and V alidatio n The tr aining and validation d a ta p airs (i.e. , inpu t and target) are obtained following the trainin g and validation prepro- cessing illustrated in Fig . 7, and th e test experimen ts follow the test pr ocessing in Fig. 8. Our training and validation prepro cessing and test pr o cessing are based upo n the orig in al quality asses smen t plans [49]–[ 52] fo r the c odecs e valuated in this work and the respecti ve p rocessing functions employed in Figs. 7 and 8 are fro m the IT U - T sof tware tool libra ry G.191 [53]. 3 It should be mentioned that British English is one of the 19 traini ng and val idation languages, whil e American English is used in the test. The subject iv e listening test, ho wev er , will be conducte d with German samples only , thus being c ompletely langua ge-independe nt. 7 The speech utter ances are firstly processed b y d ifferent filters ( i.e., FLA T for n arrowband codecs 4 and P .341 for wide- band co decs). Then , for narrowband codecs the speec h signal is decimated from 16 kHz to 8 kHz using the high quality finite impulse r e sponse (FIR) low-pass filter HQ2 fro m [53], wh ile for wideband codecs this downsampling function is bypassed. Then, the active speech le vel is adjusted to -26 dBov [5 4]. After this, to obtain th e frame indices for the trainin g and validation a very simp le f rame-based v oice activity detectio n (V AD) is executed as V AD ( ℓ ) = 1 , if 1 |N ℓ | P n ∈N ℓ ˜ s 2 ( n ) 1 |N | P n ∈N ˜ s 2 ( n ) > θ V AD 0 , else , (11) where θ V AD is the V AD threshold, N ℓ and N are the sets of sample in dices b e longing to f r ame ℓ and the whole speech file, respectively . T he fram e s m arked with V AD ( ℓ ) = 1 ar e regarded as activ e speech frames and the corr espondin g fr ame indices are deno ted as a set L V AD = { ℓ | V AD ( ℓ ) = 1 } . These acti ve speech f rames are further used for trainin g and validation, while the o ther fr ames are r egarded as speech pa u se an d not used in th is stage. Th en, th e target an d input for train in g an d validation are obtained as follows : The targ et d ata is o btained after the d ata prepar ation, in wh ich the windowing w .r .t. th e selected time domain or cepstral domain approach is ap p lied to the active speech frames ℓ ∈ L V AD . For the in p ut data of training and v alidation , the le vel- adjusted speech is subjec t to coding. W e examine in total four different sp eech codecs: two n arrowband c o decs, which are G.711 [1] and the adaptive differential pulse-co de modulation (ADPCM) Recomm endation G.726 used f or digital e nhanced cordless telephony (DECT) at 3 2 kbp s [55], two wideband codecs, which ar e the wid eband ADPCM G . 722 used fo r wideband DE CT at 64 kb p s [56], and AMR-WB at 12.65 kbps [12] in fixed-point implementation [57] without DTX. The f unction “ENC” compr ises a delay comp ensation func tio n in case of wideb and codecs (cf . assessment plan [52]), a bit conv ersion functio n from 16 bits to 14 bits (on ly fo r wid e band codecs) and the speech enco d er f r om any of the above fou r codecs. Then, the c orrespon ding fu n ction “ D E C” is cond ucted, which com prises the speech d ecoder, a bit conversion fun ction from 1 6 bits to 14 bits (o nly for wideband co decs), and a delay compen satio n function (only fo r wideban d codecs). Fin a lly , the coded fr ames with ℓ ∈ L V AD form the input data to the data prepara tio n functio n, wh ich ag ain p e rforms windowing and poten tial tr ansformatio n to the c epstral domain . C. Pr ocessing fo r T r ain ing and V alid ation In th e training processing, we always train codec - individual CNN mod els wh ic h are then used later on in test. T h e prepa r ed input data in the respec tive do main according to Fig. 7 is at first normalized tow ard s zero mean an d unit variance, then this n ormalized inp ut data and target d ata is fed in to the 4 Note that for bandwidth consistenc y reasons, we decide d to use the FLA T filter also for G.726 transmission, although typicall y here an MSIN filter response is use d [51], [52]. CNN to train the weigh ts in e ach conv olution al layer . This is achieved by minimizin g the co st functio n, wh ich is the m ean squared error (MSE) between the outputs of the CNN an d the target data. Instead of using the tra ditional stochastic grad ient descent ( SGD) algorithm for the trainab le weigh ts u p dating, Adam [58] is used as the lear ning method to o btain a faster training conver ge n ce [4 0]. In this work, the weights u pdate is perfor med in each minib atch co nsisting of 16 fram es, bein g a goo d trad e-off between tr aining speed and p e rforman ce. At the beginning of each epo ch, the training da ta is shuffled so that the 1 6 frames of eac h minibatch are ran domly selected from the train ing d ata. In or der to tr ain the CNN in an efficient way an d to a void overfitting, the strategies for the learning rate an d the sto p criteria a r e the fo llowing: The initial learn ing rate is 5 × 10 − 4 and it is halved once the MSE on the validation set do es not decrease for two epochs. The training stop criterion is checked after ea c h epoc h , i.e., after all minibatches ha ve be e n used , and the training stops if eith er the MSE on the validation set does not de c rease f or 16 ep ochs, or if the number of ep ochs approa c h es 100. Finally , the weights are sa ved as the result of that epo ch, after which the lo west MSE on the validation set has been achieved. D. Pr ocessing for T est In Fig . 8, the test p rocessing func tions of filtering, down- sampling, level adjustment, “E NC” and “DEC” are identical to those in Fig. 7. Since the proposed postprocessing approaches are evaluated in fou r cond itions, i.e., clean, noisy , tandeming , and error-prone transmission conditions, the test processing is also described fo r these four con ditions. W e always select the CNN model that refers to the last employed speech d ecoder . In m ost pra c tica l applicatio ns the last decod er can be assumed to be k nown, even if in many cases tand em condition s are observed w ith G . 711 being such “last employed decod er”. Please no te that for the sake of conciseness, we d id no t include in our simulation the cond ition when the last d ecoder is u n known; this could be practically solved by a multi-co dec- trained CNN mo del. For the clean condition , the level-adjusted sp eech utter- ances are co ncatenated to a long speech signal, in which the utterances f r om female an d male speakers are alternately concatenate d . After this, the refer ence speech, cod ed speec h and enha n ced speech ar e obtain ed as follo ws: The refer ence speech is obtain ed after segmentation, which cuts the conc atenated speech signal back to the o r iginal sign al portion s/d urations. Note that this reference spee c h is a lso used for the oth e r three co nditions. T o obtain co ded speech, th e fun ction “ENC” an d “DEC” are condu c te d and then the coded sp e ech results after se gm enta- tion. T o o b tain enh anced speech, the fu nctions “ ENC” and “DEC” are conducted an d then any of the postpro cessors afterwards. Finally the en hanced spee c h files r esults af te r segmentation. In the noisy c onditions , three types of noise fro m the ETSI backgr o und noise database [ 59] are applied in the ev alua tio n part, which are caf eteria noise, car noise at the veloc ity 8 Number of fe ature maps F 20 22 24 26 Leaky ReLU SELU Leaky ReLU SELU Leaky ReLU SELU Leaky ReLU SELU 2 10.77 10.98 10.79 10.76 10.57 10.44 1 0.74 10.53 N 4 8.50 8.65 8.54 8.44 8.37 8.65 8.53 8.52 6 8.30 8.44 8.29 8.61 8.30 8.42 8.39 8.30 8 8.38 8.44 8.46 8.56 8.45 8.50 8.41 8.47 10 8 .46 8.37 8.49 8.44 8.41 8.38 8.41 8.50 T ABLE II M E A N L O G A R I T H M I C S P E C T R A L D I S TA N C E ( L S D) [ D B ] O N T H E V A L I D AT I O N S E T . T H E B E S T S E T T I N G I S W R I T T E N I N B O L D FAC E . of 100 km /h, and outside traffic road noise. Similar to the processing of speech utterances in Fig. 8, the noise data is filtered and downsampled o r bypa ssed dep ending on the code c bandwidth . Then the roo t m ean square (RMS) le vel of noise is adjusted based on the desired SNR in d B [54]. After th is, the adjusted noise is added to the concaten ated speech for further pro cessing. Finally , the coded and enhance d spee c h in the noisy co ndition ar e obtained with the same f unctions as in the clean co ndition. In err or-pr one transmission condition s , e.g., mob ile and wireless systems, fram e losses are inserted to the bitstream after the en coder by using error insertio n device (EID) [53], which is p laced between the “ENC” and “DEC” in Fig. 8. The coded and enhanced speech in the error-prone transmission condition s are o btained with the other functio ns being the same as in the clean condition. T wo kinds of frame losses are taken into co nsideration : r andom f rame erasure, wh ich is based on a Gilbert model and burst frame erasu r e, in which the occu r rence of the bursts is mo d eled b y the Bellcore mod el [53], [6 0]. Both kinds of frame erasures are characterized b y th e frame erasure ratio (FER), which is the ratio o f the number of distorted frames vs. th e number of all transmitted frames. In tand eming condition s we employ a r eceiv er-sided post- processor for G.711 A-law (narrowband) or the AMR-WB, with various previously mention ed code c s as fo rmer cod ecs, but also the narrowband AMR codec at 12 .2 kbps [11], wideband co decs G.711 . 1 with mod e R3 at 96 kbp s [3], and EVS-WB at 13.2 kbp s [1 3]. The “EID” blo c k in Fig. 8 is simp ly replaced by “ DEC” and the subsequent “E NC”, resulting in a serial co nnection of two codecs. E. Metrics of Sp eech Quality T o instrumentally evaluate th e e n hanced sp eech ˆ s ( n ) , the mean logarithmic sp ectral distance (LSD) averaged over frames is emp loyed [6 1]. The LSD is calculated as LSD ( ℓ ) = v u u t 1 k high − k low k high X k = k low 10 log 10 | ˜ S ( ℓ,k ) | 2 | ˆ S ( ℓ,k ) | 2 2 , (12) where ˜ S ( ℓ, k ) and ˆ S ( ℓ, k ) and the k -th FFT coefficient of the uncod e d and the processed (can be either code d or postpro - cessed) spee ch sign a l in fram e ℓ , respectively , and k high and k low are the indices of the upp er and lo wer frequency b in bound s taken into account. The fr a mes used for the m ean L SD Time Domain Cepstral Domain T opolo gy r # of Param. LSD [dB] T opolo gy r # of Param. LSD [dB] CNN - 0.82M 11.03 CNN - 52.82K 8.29 ( F opt , N opt ) ( F opt , N opt ) 1024-1024 0 1.21M 12.12 256-256 0 82.46K 9.59 0.1 14.71 0.1 9.54 512-512-102 4 0 0.91M 12.33 128-128-256 0 61.98K 9.89 0.1 28.90 0.1 9.63 512-512-512 0 0.87M 13.08 128-128-128 0 57.89K 9.70 -512 0.1 30.68 -128 0.1 11 .14 512-512-256 0 0.87M 12.03 128-128 -64 0 57.95K 9.24 -512-512 0.1 55.03 -128-128 0.1 15.53 T ABLE III L S D [ D B ] VA L U E S O N T H E V A L I DAT I O N S E T A N D T H E N U M B E R O F T R A I NA B L E PA R A M E T E R S ( # O F P A R A M . ) F O R T H E O P T I M A L C N N W I T H ( F opt , N opt ) A N D F O U R D I FF E R E N T F U L L Y - C O N N E C T E D N E U R A L N E T W O R K S W I T H O R W I T H O U T D RO P O U T ( D RO P O U T R A T E r ) I N T I M E D O M A I N A N D C E P S T R A L D O M A I N . T H E T O P O L O G I E S Y I E L D I N G T H E L O W E S T L S D VAL U E S A R E W R I T T E N I N B O L D FAC E . are from the active speech frame set L V AD (from equation (11)) and each fr a m e is formed by em ploying a 32 ms p eriodic Hann window with 5 0% overlap. T o measure the speech distortion, the segmental speech -to- speech-distor tion (SSDR seg ) [62] is ca lc u lated as SSDR seg = 1 |L V AD | X ℓ ∈L V AD SSDR ( ℓ ) , (13) where SSDR ( ℓ ) is limited from R min = − 1 0 dB to R max = 40 d B by SSDR ( ℓ ) = max min SSDR ′ ( ℓ ) ,R max ,R min . The term SSDR ′ ( ℓ ) is actually calcu lated as SSDR ′ ( ℓ ) = 1 0 log 10 P n ∈N ℓ ˜ s 2 ( n ) P n ∈N ℓ (ˆ s ( n ) − ˜ s ( n )) 2 , (14) where N ℓ is the set of sam p le indices n belo nging to frame ℓ , ˜ s ( n ) an d ˆ s ( n ) ar e the uncod ed and time- aligned processed (can be either coded o r postproce ssed ) speech signal, respec- ti vely . Each frame is a lso 3 2 m s with 5 0% overlap. Note that at some poin t we will also repor t on a globa l SSDR measur e, which is sim p ly obtained b y (14) with setting N ℓ = N , meaning that all samples in each file contribute to each of the sums in (14). W e will call this m easure sim p ly SSDR. For instru mental assessment of speech q uality , perce p tual ev aluation of spee c h qu ality (PESQ) [6 3], [64] f or the narrow- band speech and WB-PESQ [65] for the wideban d speech are used. The output of the tw o metrics is the mean opinion score (MOS) listening quality objective (LQO), which is d e noted as MOS-LQO. A m ean value over all test speech utter ances for each r espectiv e language is rep orted in the ev aluation. In addition to (WB-)PESQ, we also perform perceptual objective listening quality pr ediction ( POL QA) [6 6]. This is done in only a f ew con ditions, checking , wheth er both measu res lead to similar con clusions. In addition, for the most pr omising ap proaches, w e condu ct an semi-form al co mparison category ra tin g (CCR) subjec- ti ve listening test according to the ITU-T Recommenda tion P .800 [ 67]. In a CCR test, a pair of two speech samples is presented to the listeners, and the qu ality jud g ment of the 9 American English German G.711 A-law G.726 G.722 AMR-WB G.711 A-law G.726 G.722 AMR-WB no Constr . Constr . no Constr . Constr . Legac y Co dec MOS-LQO 4.21 3.96 3.72 3.60 4.15 4.01 3.61 3.53 Postfilter [2] MOS-LQO 4.32 - - - 4.25 - - - ∆ MOS-LQO 0.11 0.10 Time Dom ain MOS-LQO 4.32 4 .32 4.21 4.32 3.61 4.30 4 .30 4.26 4.29 3.62 ∆ MOS-LQO 0.11 0.11 0.25 0.60 0.01 0.15 0.15 0.25 0.68 0.09 I MOS-LQO 4.24 4.27 3.99 4.13 3.45 4.13 4.18 4.01 4.07 3.29 ∆ MOS-LQO 0.03 0.06 0.03 0.41 -0.15 -0.02 0.03 0 0.46 -0.24 II MOS-LQO 4.40 4.30 4.15 4.47 3.78 4.39 4.24 4.26 4.46 3.73 ∆ MOS-LQO 0.19 0.09 0.19 0.75 0.18 0.24 0.09 0.25 0.85 0.20 Cepstral Domain III MOS-LQO 4.43 4.33 4.20 4.47 3.79 4.42 4.26 4.29 4.48 3.74 ∆ MOS-LQO 0.22 0.12 0.24 0.75 0.19 0.27 0.11 0.28 0.87 0.21 IV MOS-LQO 4.27 4.27 4.01 4.17 3.52 4.17 4.19 4.04 4.12 3.41 ∆ MOS-LQO 0.06 0.06 0.05 0.45 -0.08 0.02 0.04 0.03 0.51 -0.12 V MOS-LQO 4.42 4.31 4.21 4.45 3.74 4.41 4.26 4.30 4.44 3.67 ∆ MOS-LQO 0.21 0.10 0.25 0.73 0.14 0.26 0.11 0.29 0.83 0.14 VI MOS-LQO 4.44 4.31 4.25 4.50 3.85 4.42 4.23 4.32 4.47 3.79 ∆ MOS-LQO 0.23 0.10 0.29 0.78 0.25 0.27 0.08 0.31 0.86 0.26 T ABLE IV M O S - L Q O ( P E S Q A N D W B - P E S Q ) F O R L E G AC Y C O D E C S A N D C O D E C S W I T H V A R I O U S P O S T P R O C E S SO R S . T H E T O P T W O R E S U LT S I N E A C H C O L U M N A R E W R I T T E N I N B O L D FAC E . second sample compa r ed to that of the first is made and rated on the co mparison MOS (CMOS) scale ran ging from -3 (much worse) to +3 (m u ch b etter). V . E X P E R I M E N TA L E V A L U A T I O N A N D D I S C U S S I O N In Section V -A, a p reliminary experiment is imp lemented to in vestigate the CNN topolog y on the validation set. Then, th e optimal setting will be u sed for the subsequent exper iments. A. Preliminary Expe rimen t o n CNN P arameters In a pr eliminary experim ent the op timal CNN topolo gy settings with the framework structure I I I of the cepstral dom ain approa c h for G.711 postprocessing ar e selected . The number of feature maps F , the length of the CNN kernels N , and the activati on function (the last layer is alw ays linear) are examined. W e investi ga te both leaky rectified linear u n it (ReLU) [6 8] an d scaled exponential linear unit (SELU) [69]. Since narrowband speech is used in this preliminary exper - iment, a fr equency region f rom 50 Hz to 3.4 KHz is taken into accou nt, resulting in k high = K 8000 · 3400 Hz = 217 and k low = K 8000 · 50 Hz = 3 in equation (12) with the 512 -point FFT . The results are sh own in T ab. II, in wh ich we c a n see th at th e perfor mance of the CNN in o ur p roposed approach is mainly depend ing o n the kernel length N , and only weakly on the choice of the activ ation function a n d the nu mber of feature maps F . Note tha t only a small fraction of the actually used ( N , F ) search sp a ce is shown in T a b. II: The depen dence on F regarding to the op timum is rath er flat, ho wever , for mu ch smaller v alues of F th e perfor mance deterior ates sig n ificantly . As a r esult, the CNN topo logy with the minimu m mean LSD value of 8.2 9 dB r ecommen d s th e cho ices F opt = 22 , N opt = 6 , and the leaky ReLU acti vation function . It is interesting to know that the legacy G.711 has a mea n LSD being 16 .15 dB which is almost h alved by applying this optimal topolog y . Note that F opt and N opt selected from the above preliminary experiment are specific to the framework structure III with the len gth L = 32 of the CNN inp ut vector . In o rder to obtain also reason able p arameter settings fo r th e other f ramework structures, we no te th at the length L chang es for the v ario us postproce ssing app roaches with L = |M env | = 6 . 25% · K in the cep stral do m ain appr oaches, and L = 80 for narrowband codecs an d L = 160 for wideband cod e c s in the time domain approa c h . Note that for simplicity of presentation , whenever L chang es with a certain framework structure (time domain, cepstral domain I–VI) , the v alue of F opt and N opt are simply increased or d ecreased propo rtionally at the same time. Now , as we have fixed the n u mber o f traina b le parameter s, we briefly want to che ck whether a straight-forward fully- connected neural network (FCNN) p erform s equally well. As sho wn in T ab. II I, we simulated four dif fer e n t FCNN topolog ies without dr opout or a dro p out rate r = 0 . 1 for both the time do main approa c h and th e cep stral do m ain approa c h of structur e I II, while keeping the sam e n umber of inpu t node s ( L = 80 for the time domain appr oach and L = 32 for the cepstral domain approach ). The nu mber o f trainable parameters is about the same as (or a bit h igher than) the o ptimal CNN topology with ( F opt , N opt ). It can be seen that the optimal CNN topolog y ach iev es the best L SD perfor mance compar ed to all listed FCNN struc tures for both the time domain ap proach and the cepstral dom ain appro a ch. According ly , in the following we stick to the CNN topo logy as it seems to be an advantageou s choice. 10 American English German G.711 A-law G.726 G.722 AMR-WB G.711 A-law G.726 G.722 AMR-WB no Constr . Constr . no Constr . Constr . Legac y Co dec MOS-LQO 4.29 4.03 3.78 3. 64 4.14 4.03 3.71 3.65 Postfilter [2] MOS-LQO 4.46 - - - 4.33 - - - ∆ MOS-LQO 0.17 0.19 Structure III MOS-LQO 4.49 4.40 4.31 4.73 3.97 4.45 4.27 4.38 4.56 3.93 Cepstral Domain ∆ MOS-LQO 0.20 0.11 0.28 0.95 0.33 0.31 0.13 0.35 0.85 0.28 T ABLE V M O S - L Q O ( P O L Q A ) F O R L E G AC Y C O D E C S A N D C O D E C S W I T H I T U - T P O S T F I LTE R [ 2 ] A N D T H E S T RU C T U R E I I I C E P S T R A L D O M A I N P O S T P R O C E S S O R . T H E B E S T R E S U LT S I N E AC H C O L U M N A R E W R I T T E N I N B O L D FAC E . C O M PA R E T O T H E R E S P E C T I V E ( W B - ) P E S Q R E S U LT S I N T AB . I V . American English German no Constr . Const r . no Constr . Constr . Legac y Co dec 37.12 37.11 Postfilter [2] 17.27 15.65 Time Domain 38.07 38.08 38.15 38.15 I 29.37 29.98 29.42 29.99 Cepstral Domain II 21.55 29.93 21.80 29.94 III 25.85 29.96 26.23 29.97 IV 29 .36 29.98 29.42 29.98 V 26 .67 29.97 26.91 29.98 VI 23 .75 29.95 24.33 29.95 T ABLE VI T H E S S D R SE G [ D B ] V A L U E S F O R T H E G . 7 1 1 L E G AC Y C O D E C A N D G . 7 1 1 C O D E C W I T H V A R I O U S P O S T P R O C E S S O R S . T H E B E S T A P P RO A C H I S W R I T T E N I N B O L D FAC E . B. Major Instrumental Exp eriments In th is sub section, the e xp eriments of the pro p osed postpro- cessing approaches f or the various cod ecs in different con di- tions are implemented and evaluated instrumentally following the test p rocessing in Fig. 8. 1) Clean Condition : A comp rehensive ev aluation o f all the propo sed postpro cessors is con ducted f o r f o ur different codecs in both American English and German langu age, in wh ich legacy codecs and th e postfilter for G. 7 11 serve as b aselines. PESQ results are sho wn in T ab. IV with ∆ MOS-LQO being the MOS-L QO difference between the p o stfilter or th e po st- processor and the respective legacy codec. W e find that most of our prop osed postprocessor s perform b e tter than the r espective legacy codecs. For G.711 ou r prop osed postpr ocessors in most cases show better per forman ce when no quantizatio n constraint is perfo rmed. Comparing the various proposed postprocessors with no quan tization constraint, the time do m ain postpr ocessor and the cepstral do main postprocessor s with structu res II, III, V , and VI (the on es with delay , see T ab. I) show be tter performance than all legacy cod ecs an d they all perform better than or equal to the G.7 11 postfilter [2] fo r bo th lang uages (only the time dom a in postpro c e ssor has th e same MOS- LQO as th e p ostfilter f or Am e rican En glish). T he cepstral domain postpr ocessor with structure VI performs best for both languag e s and f or all codecs, exceedin g the legacy codecs on av erag e over both langua ges by 0.25 MOS po ints for G.711, 0.3 MOS points for G.726 , and 0.26 MOS points for AMR- American Engl ish German no Constr . Constr . no Con str . Constr . Legac y Co dec 37.30 37.35 Postfilter [2] 17.79 15.70 Time Domain 38.33 38.34 38.49 38.50 I 29.98 34.15 30.05 34.17 Cepstral Domain II 19.94 32.36 20.54 32.35 III 24.58 33.04 25.14 33.03 IV 29.93 34.11 30.11 34.15 V 25.39 32.97 25.83 32.93 VI 21.80 32.66 23.26 32.71 T ABLE VII T H E S S D R [ D B ] V A L U E S F O R T H E G . 7 1 1 L E G AC Y C O D E C A N D G . 7 1 1 C O D E C W I T H V A R I O U S P O S T P R O C E S S O RS . T H E B E S T A P P RO A C H I S W R I T T E N I N B O L D FAC E . WB. Note that struc ture VI exceeds the G.722 legacy codec by an impressi ve 0.8 2 MOS p o ints, where ro ughly 0. 3 MOS points can be d edicated to the r ather simple suppression of frequen cies b eyond 7 kHz, and the major rest can be dedicated indeed to the improvement of the early cepstral coefficients (details are g iven in the App endix). For a limited set of conditions in T ab. I V, we pr ovide also POLQA [66] resu lts in T ab . V . Note that very similar improvements of our postprocessor (structur e III) w .r .t. all legacy codecs in both langu ages can be seen, with the AMR- WB postpr ocessor perform ing even better in POLQ A than in WB-PESQ. Howe ver, since simulatio n o f PESQ was m uch easier to p erform due to the availability of a batch mo d e to us, the rem ainder of our work uses PESQ and WB-PESQ. In o r der to obtain a b etter unde r standing of how the coded speech signal is enhanc e d by the cepstral do main approa c h , spectral and cepstral analysis examples o f the en - hanced sp eech, along with the co ded and referen ce speech , ar e presented for inter ested readers in the Appendix. Since the alg orithmic delay might be c r itical in prac tical applications, w e see that the z e r o-latency time d omain po st- processors can improve the speech quality f o r all listed codecs in both languag es. For cepstral domain po stprocessors, the zero-latency structures I an d IV still can consistently imp r ove speech q uality o f G.72 6 an d particu la r ly of G.722 . Since G. 7 11 and AM R-WB ask for some delay in the postprocessor, a good comp romise for these cod ecs would be the stru cture III, providing second ranked speech quality in both langu a g es. At 11 P S f r a g r e p l a c e m e n t s 4 . 1 4 . 15 4 . 2 4 . 25 4 . 3 4 . 35 4 . 4 4 . 45 4 . 5 0 0 0 2 5 10 10 16 MOS-LQO Addition al Delay (m s) Legac y G.711 I IV Domain Time ITU-T Postfilter [2] V III VI II Fig. 9. The MOS-LQO ( PESQ ) of vario us postprocessors for G.711 with dif ferent amounts of additional delay . Note that structure II has a differ ent model topology than the other cepstral domain structures I, III-VI; see T ab . XII. the cost o f only 10 ms algorithmic de lay , structure III exceeds the legacy co d ecs on average over both langua g es by 0.25 MOS po ints for G.7 11, 0.25 MOS points fo r G.726 , 0.81 MOS points for G.7 22, and 0.2 MO S points f or AMR-WB. T o further illustrate the influ ence of the additiona l delay on th e per forman ce improvement, we comp are in Fig. 9 the MOS-LQO of the postfilter and the postprocessor s both in time domain an d cepstral do main for G.71 1, sorted by th e ad ditional delay . Th e MOS-LQO is an average o f American English and German. F or the propo sed postp rocessors in the cepstral domain, it become s obvious that the p erforma n ce improvement grows with the increase o f the additional delay , as th e model topolog y is exactly the same (except fo r structur e II 5 , see T ab. XII). W ith longer addition al delay for the po stfilter [ 2], it may also achieve some further perfo rmance gains. Howe ver, our pr o posed zero-laten cy postpr ocessor in the time domain already shows super ior perf o rmance comp ared to the I TU-T postfilter with 2 ms add itional delay . Comparing the bold face ( i.e., top-two) re sults in T ab . IV, we see that there is hard ly a language d ependen cy in the rank order of the best a pproach es. T o intuiti vely sh ow the poten tial of the p ostprocessor with structure II I we p erform e d a comparison to different modes (i.e., bitrates) for the AMR-WB codec in Fig . 10. One can easily see that the MOS-LQO of the postpr ocessor after the AMR-WB co dec at 1 2.65 kb ps fo r b o th American English and German exceeds the legacy AMR-WB at 15.85 kbps and it even app roaches a co m parable quality for German at 18.25 kbps. Therefo re, the postpro cessor with structu r e III shows its ability to sign ifican tly improve the speech qu ality du ring transmission with a relative low b itrate towards a much higher bitrate transmission. In order to see th e wa vefor m distortio n of speech after 5 This is because structure II has a differe nt topology in terms of the number of input no des L , feature map s F , and k ernel size N (see T ab . XII). P S f r a g r e p l a c e m e n t s 1 0 3 . 5 3 . 55 3 . 6 3 . 65 3 . 7 3 . 75 3 . 8 3 . 85 3 . 9 3 . 95 4 12 . 65 14 . 25 15 . 85 18 . 25 19 . 85 23 . 05 23 . 85 G p [ d B ] N p Postprocessor a fter AMR-WB at 12 . 65 kbps with s tructure III AMR-WB at vari ous bitrate s American English German Bitrat e [ kbps ] MOS-LQO Fig. 10. MOS-LQO ( WB-PESQ ) points of the test speech utteranc es for the leg acy AMR-WB at v arious bitrates (solid curv es from 12.65 to 23.85 kbps) as well as for our postprocessor with structure III at 12.65 kbps (dashed lines). Results are sho wn for America n English ( ∗ ) and Ger man ( ◦ ). the postproce ssing , SSDR seg measure (13) for G.71 1 A-law in American En glish and Germa n is shown in T ab . VI. It is straig htforward that the legacy G. 711 alr e a dy achieves a relativ ely high SSDR seg , with 3 7.12 dB f or America n En glish and 37 .11 dB for Germ an, since it is a hig h b itr ate wa veform coding. For th e time domain po stprocessor, it achieves even higher SSDR seg which is the best performan ce among a ll the propo sed p o stprocessors, since it focuses on the waveform domain. All prop o sed postpro cessors with quantization con- straint sho w equal or better SSDR seg than without it, but it brings no p o siti ve effect to speech qua lity for the proposed postproce ssors in terms o f M OS-LQO (see T ab. IV). For the p o stprocessor with structure VI, which achieves the best speech quality (see T ab. IV), a mea n SSDR seg of only 24.04 dB o ver bo th lang uages is m easured. Com paring SSDR seg and MOS-LQO, we once again see that waveform similarity and speech quality ar e not necessarily po siti vely correlated, in this case also q uestioning the qua n tization con straint. Evaluating the global SSDR measure in T ab . VII, it turns out th at th e rank order of approach es is very similar to the SSDR seg in T ab . VI: The prop o sed time dom ain appro ach is the best, follo wed by the G.711 legacy codec, the cepstral domain approa c h es, and finally the ITU-T postfilter [2]. I n terestingly , the advantage of using the constraint is higher with the SSDR measure, which might be due to some very slight residual noise for the cepstral dom a in approaches in spee c h pau ses; an ef fect that has bee n disregarded in SSDR seg throug h the in herent voice activity detection in (13), and which will motivate some small extra proce ssing in Section V -C. 2) T ande ming Condition s: In order to e valuate the perfor- mance of the pro posed p o stprocessors in tandeming condi- tions, G.7 11 A-law and AMR-WB are selected as the last codec for narrowband a n d wideb and, respectively , while se v- eral other cod ecs form some common tandeming conditio ns. The CNN mod el matches the last co d ec since only this co dec is k nown at the receiving point. I t is worth no ting that all 12 Narro wband T and eming W ideband T andeming µ -la w + A-law G.726 + A-law AMR + A-law G.711.1 (A-la w) + AMR-WB G.722 + AMR-WB EVS-WB + AMR-WB Legac y Co dec MOS-LQO 4.18 3.96 4.01 3.37 3.34 3.28 Postfilter [2] MOS-LQO 4.20 4.01 4.07 - - - ∆ MOS-LQO 0.02 0.05 0.06 Time Dom ain MOS-LQO 4.28 4.03 4.09 3.39 3.49 3.29 ∆ MOS-LQO 0.10 0.07 0.08 0.02 0.15 0.01 Structure III MOS-LQO 4.38 4.13 4.12 3.70 3.71 3.48 Cepstral Domain ∆ MOS-LQO 0.20 0.17 0.11 0.33 0.37 0.20 Structure VI MOS-LQO 4.41 4.18 4.13 3.78 3.75 3.53 Cepstral Domain ∆ MOS-LQO 0.23 0.22 0.12 0.41 0.41 0.25 T ABLE VIII M O S - L Q O ( P E S Q A N D W B - P E S Q ) F O R L E G AC Y C O D E C S A N D C O D E C S W I T H D I FF E R E N T P O S T P RO C E S S O R S I N TA N D E M I N G C O N D I T I O N S . T H E R E S U LT S O F T H E B E S T A P P RO A C H I S W R I T T E N I N B O L D FAC E . G.711 AMR-WB Random Burst Random Burst 3 % 6 % 3 % 6 % 3 % 6 % 3 % 6 % Legac y Co dec MOS-LQO 3.67 3.31 3.60 3.07 2.75 2.30 2.80 2.39 Postfilter [2 ] MOS-LQO 3.71 3.34 3.66 3.12 - - - - ∆ MOS-LQO 0.04 0.03 0.06 0.05 Time Domain MOS-LQO 3.71 3.35 3.67 3.12 2.78 2.32 2.83 2.41 ∆ MOS-LQO 0.04 0.04 0.07 0.05 0.03 0.02 0.03 0.02 Structure III MOS-LQO 3.74 3. 37 3.76 3.19 2.94 2.44 2.99 2.54 Cepstral Domain ∆ MOS-LQO 0.07 0.06 0.16 0.12 0. 19 0.14 0.19 0. 15 Structure VI MOS-LQO 3.76 3.41 3. 73 3.16 3.03 2.51 3.09 2.62 Cepstral Domain ∆ MOS-LQO 0.09 0.10 0.13 0.09 0.28 0.21 0.29 0.23 T ABLE IX M O S - L Q O ( P E S Q A N D W B - P E S Q ) F O R G . 7 1 1 A N D A M R - W B L E G AC Y C O D E C S A N D C O D E C S W I T H D I FFE R E N T P O S T P R O C E S S O R S I N E R RO R - P RO N E T R A N S M I S S I O N C O N D I T I O N S . T H E R E S U LT S O F T H E B E S T A P P RO AC H I S W R I T T E N I N B O L D FAC E . G.711 AMR-WB Cafete ria Ca r Road Mean Clean Cafete ria Car Road Mean Clean SNR [dB] 15 20 15 20 15 20 15 20 15 20 15 20 Legac y Codec MOS-LQO 2.29 2. 67 2.40 2.75 2.06 2.43 2.43 4.21 1.69 2.10 2.12 2.52 1.59 1.99 2.00 3.60 Postfilter [2] MOS-LQO 2.31 2.70 2.41 2.76 2.07 2.45 2. 45 4.32 - - - - - - - - ∆ MOS-LQO 0.02 0.03 0.01 0.01 0.01 0.02 0. 02 0.11 Time Domain MOS-LQO 2.31 2.69 2.41 2.76 2.06 2.45 2. 45 4.32 1.73 1.74 1.98 2.39 1.63 2 .05 1.92 3 .61 ∆ MOS-LQO 0.02 0.02 0.01 0.01 0 0.02 0.02 0.11 0.04 -0.36 -0.14 -0.13 0.04 0.06 -0.08 0.01 Structure III MOS-LQO 2.29 2.68 2.39 2.75 2.05 2.43 2.43 4.43 1.68 2.13 2.25 2.68 1.56 1.99 2.05 3.79 Cepstral Domain ∆ MOS-LQO 0 0.01 -0.01 0 -0.01 0 0 0.22 -0.01 0.03 0. 13 0.16 -0.03 0 0.05 0.19 Structure III MOS-LQO 2.31 2.73 2.38 2.70 2.19 2.60 2.49 4.32 1.75 2.19 2.24 2.63 1.80 2.22 2.14 3.66 Cepstral Domain ∆ MOS-LQO 0.02 0.06 -0.02 -0.05 0.13 0.17 0.06 0.11 0.06 0. 09 0.12 0.11 0.21 0.23 0.14 0.06 Structure VI MOS-LQO 2.30 2.69 2.40 2.75 2.06 2.45 2.44 4.44 1.71 2.17 2.29 2.76 1.59 2.05 2.10 3.85 Cepstral Domain ∆ MOS-LQO 0.01 0.02 0 0 0 0.02 0.01 0. 23 0. 02 0.07 0.17 0.24 0 0.06 0.10 0.25 T ABLE X M O S - L Q O ( P E S Q A N D W B - P E S Q ) F O R G . 7 1 1 A N D A M R - W B L E G AC Y C O D E C S A N D C O D E C S W I T H D I FFE R E N T P O S T P R O C E S S O R S I N N O I S Y S P E E C H C O N D I T I O N S . T H E R E S U LTS O F T H E B E S T A P P R OA C H I S W R I T T E N I N B O L D FAC E A N D T H E M O D E L T R A I N E D W I T H 2 0 D B ( U N S E E N ) N O I S Y D AT A I S G R E Y - S H A D E D . further exper iments in this subsection ar e only conducted in Am erican En g lish. The PESQ r esults are shown in T ab. VIII and we can see the per f ormanc e of our time domain postproce ssor and the p o stprocessor in the c e pstral domain with structure s III and VI. While in narrowband tandem condition s structure III achieves a MOS-LQO im provement in the range 0 . 11 ... 0 . 2 0 p oints (in all cases the po stprocessor has been just train ed for the rec e i vin g-sided A-law G.7 1 1), the structure III in wid eband tandeming conditio n s imp roves by 0 . 20 ... 0 . 3 7 PESQ MOS poin ts (the postprocessor has b een 13 CCR Cases CMOS C I 95 Legac y G.711 vs. Direct 1. 76 [1 . 61; 1 . 92] Postfilter [2] vs. Dire ct 0.28 [0 . 13; 0 . 43] Proposed Postprocessor vs. Direc t -0.18 [ - 0 . 33; - 0 . 02] Legac y G.711 vs. Postfilter [2] 1.45 [1 . 27; 1 . 64] Legac y G.711 vs. Pr oposed Postpr ocessor 1.77 [1 . 60; 1 . 95] Postfilter [2] vs. Proposed Postprocessor 0.36 [0 . 23; 0 . 50] T ABLE XI C C R S U B J E C T I V E L I S T E N I N G T E S T R E S U LT S W I T H T H E B A S E L I N E P O S T FI LT E R [ 2 ] , T H E P R O P O S E D P O S T P R O C E S S O R O F S T RU C T U R E I I I , T H E L E G A C Y G . 7 1 1 C O D E C A N D T H E D I R E C T C O N D I T I O N . T H E W I N N I N G C O N D I T I O N I S W R I T T E N I N B O L D FAC E . only train ed for th e receiving-sided AMR-WB). Note th at the G711.1 A-law + AMR-WB tan deming and the G.722 + AMR- WB tandemin g, f o llowed by structure I II both achieve ar ound 3.7 PESQ MOS points, which is even more than o nly AM R- WB with 3 .6 p oints (see T ab. IV). W ith the best postprocessor of structure VI from T ab. IV, even slightly better speech quality is ach iev ed in all cases for th e price of a large algorithm ic delay . All o f th e po stpr ocessors in T ab. VIII exceed the shown legacy codecs und e r tan deming, even if the le gacy codec (G.7 11 A -law) is followed by the p ostfilter fr om [2] . 3) Err or-Pr one T ransmission Conditions: For the evalu- ation o f th e pro posed postproce ssors in error-prone tr a n s- mission, ran dom and burst frame losses are in serted to the bitstream of G.711 and AMR-WB with the FER being 3% and 6% and the PESQ results are shown in T ab . IX. It is worth no ting that the err or conc e alment measur es are app lied in all co nditions for both cod ecs: the packet loss conc e alment for G.711 from App endix I [ 70] and th e error concealm ent of erroneou s or lost frames fo r AMR-WB from 3 G PP TS 26.19 1 [7 1]. Note that AMR-WB in this condition require s DTX to be switched on. The time domain postprocessor has better o r eq ual pe rforman ce compared to the postfilter [2] for G.711 for both r andom an d b urst fram e losses, and is very slightly be tter in th e case of AMR-WB. The cepstral d omain postproce ssors with structures III and VI both perf orm even better in all cases and stru cture III with less delay im proves the legacy codecs by 0 . 06 ... 0 . 16 PESQ MOS po ints in narrowband frame lo ss and 0 . 14 ... 0 . 19 PESQ M OS poin ts in wideban d frame loss. Accordingly , a ll of the p ostpr ocessors in T a b . IX can be a dvantageously employed after the legacy code c s in frame loss cond itions . 4) Noisy Sp eech Conditio n s: In ord er to e valuate the per- forman ce of the proposed p ostprocessing a pproach es for no isy speech, different typ es of back groun d noise are added to the speech signals at an SNR of 1 5 dB or 20 dB, fo llowed b y G.711 and AMR-WB. The PE SQ results are shown in T ab. X, while the mean of the n oisy condition s and also the clea n condition s for bo th codecs are listed. F or the G.711-based nar- rowband experimen ts with noisy speech, b oth the po stfilter [2] and the pro posed postproc e ssor s har dly hav e an influ ence on the co ded speech, with MOS-LQO d ifferences being less than 0.04, and two insign ificant degrad ations of only 0.01 MOS po ints being ob served. On average, the postfilter and the proposed postprocessors ha ve a MOS-LQ O impr ovement Frames per second L N F MIPS Time Domain 100 80 15 55 3820 (!) I 100 32 6 22 98 . 4 Cepstral Domain II 200 16 3 11 12 . 4 III 100 32 6 22 98 . 4 IV 50 32 6 22 49 . 2 V 50 32 6 22 49 . 2 VI 62.5 32 6 22 61 . 5 T ABLE XII C O M P U TATI O NA L C O M P L E X I T Y I M M I P S F O R T H E D O M I N A N T C O N V O L U T I O NA L O P E R AT I O N S I N T H E C N N O F E AC H P R O P O S E D F R A M E W O R K S T R U C T U R E I N N A R RO W B A N D . T H E N U M B E R O F F R A M E S P E R S E C O N D A N D T H E PA R A M E T E R S O F T H E C N N F O R A L L T H E P RO P O S E D F R A M E W O R K S T RU C T U R E S ( L , N , A N D F ) A R E A L S O L I S T E D . in the ran ge 0 ... 0 . 02 points. For AMR-WB in no isy c ondition s, the cepstral domain po stprocessors can impr ove or m aintain the speech quality for most of the cases, with two exception s: cafeteria no ise (0.01 MOS poin ts decr e ase) and road noise (0.03 MOS po ints decr ease) bo th at 15 dB SNR. For car noise at both 15 and 20 dB obviou sly a speech quality improvement has been observed: 0.13 an d 0.1 6 MOS points for stru cture III, 0.1 7 and 0.24 MOS points for stru cture VI. The m eans over the no isy con ditions show a M O S- LQO imp r ovement of 0.05 points fo r structure III and 0.10 po ints f o r structure VI . In summary and on a verage, b oth the G.711 postfilter and our pr oposed postpr ocessors do neither significantly imp r ove nor distort noisy speech qu a lity at the r eceiver . Finally , in order to increase the robustness of the approach , we also trained th e structure III mod el jointly with clean and noisy sp eech d ata. F our noise typ es 6 from the QUT -NOISE database [72] (noise type s are different to the test data) are used to generate the 2 0 dB noisy tr aining data, with the amount of the noisy data b eing o ne quarter of the clean da ta . As can be seen in T ab . X, the model trained with noisy d ata ( in the grey-shaded ro ws) achieves be st p erforma n ce on average and over the noisy c o nditions for both G.71 1 and AMR- WB. A test on clean data expected ly shows some redu ced perfor mance impr ovement. In summary an d on average, th e pr oposed postpr ocessor trained with a dditional noisy data can pr ovide even some impr ovements in no isy conditio ns . C. Sub jec tive Experiment In our CCR subjective listening test, 2 female and 12 male listeners p articipated, who are nati ve German speakers stating to hav e no hearing impairment. An am o unt o f 1 6 utterances from 4 speakers (2 f emale and 2 male) of the NTT speech database in German are subject to four test condition s following the processing p la n in clean condition of Fig. 8 : Th e first is the d ir ect condition , resulting in the referenc e speech . The second is the legacy G.711 c o ndition, providing speech transcod ed by the G.711 codec. The third is the po stfilter condition, whe r e G.711-transcod ed speech has been enhanced by the ITU-T postfilter [2]. The fourth is the 6 The fo ur noise t ypes are: HOME-KITCHEN, HOME-LIVINGB, REVERB-POOL, and RE V E RB-CARP ARK. 14 P S f r a g r e p l a c e m e n t s 100 100 100 200 200 200 300 300 300 400 400 400 500 500 500 600 600 600 700 700 700 0 0 0 64 64 64 128 128 128 192 192 192 256 256 256 Frame ℓ Frame ℓ Frame ℓ Frequenc y bins k Freque ncy bins k Frequency bi ns k Fig. 11. Narrowband spectrograms of an utteranc e: refere nce speech (top), G.726-coded spe ech (cen ter), and postpro cessed speech (bottom). Chara cter- istic time-frequenc y regions and frame ℓ = 490 are marked . pr oposed postpr ocessor condition, wher e G.711 -transcod ed speech has be en enhanced by ou r prop o sed postprocessor of structure III in the cepstral dom ain. Finally , all speech signals are co n verted to 48 k Hz samp lin g rate. These f our con ditions result in six co mparison cases in the sub jectiv e listening test (cf. T ab. XI). In a preliminar y inf ormal subjec tive listening test we ob- served that an ideally very low 0-th cepstral coefficient turns out to assume slightly h igher values after the CNN e stima tio n, resulting in somewhat noisy speech pauses. Therefore, for the subjective listening test, we very slightly manipulate the CNN output as follo ws 7 ˆ c env ( ℓ, 0) → ( ˆ c env ( ℓ, 0) , if ˆ c env ( ℓ, 0) > C 0 ˆ c env ( ℓ, 0) − γ 0 , else , (15) with C 0 = − 1650 and γ 0 = 1000 . The participants of the sub jectiv e listening test ra ted th e speech using an AKG K-271 MKII headp hone f rom a com- puter with external RME Fireface 400 sou nd card. The participants were eq u ally assigned to one of two d isjoint sets, where the speech is balan ced over the com parison cases and the speakers. Each participant familiarized himself with all th e compariso n cases and was asked to choo se a prope r volume on the b a sis of 12 sample pairs in the familiarizatio n p h ase. Then, each participant ev aluated 72 samp le pairs in the m ain test p hase, wh ere 36 sample pairs are presented in both sam ple orders. In T ab. XI, the CMOS and respective 95% confidence interval ( C I 95 ) for the six CCR c omparison cases are shown. All r esults turne d out to be signific ant . W e can see a clear 1.7 6 7 Note that this m anipul ation naturally also degrade s the instrumen tal valu es as gi ven in Section V -B1. For structure III in T ab . IV, e.g., we obse rved de viations in the range [ − 0 . 12 ... + 0 . 02] over languages and codecs, howe ve r, still exce eding all legac y codecs and the postfilter [2] in instrumental metrics. P S f r a g r e p l a c e m e n t s 100 100 100 50 80 60 40 20 0 0 0 − 2 0 0 0 0 300 200 − 100 − 200 32 32 64 64 96 96 128 128 160 160 192 192 224 224 256 256 2 4 10 15 20 24 30 10 log ( | S | 2 ) 10 log ( | S | 2 ) Frequenc y bins k Frequenc y bins k Cepstral coeffici ents Cepstral coef ficient indice s m Reference Speech Reference Speech Reference Speech G.726-Coded Speech G.726-Coded Speech G.726-Coded Speech Postprocessed Speech Postprocessed Speech Postprocessed Speech Fig. 12. Amplitude spectrum (top), spectral en ve lope (center), both on a logarit hmic scale, and DCT -II type of cepstral coef ficients (bottom) for frame ℓ = 490 (see Fig. 11) of the narro wband reference speech, G.726-coded speech, and postpr ocessed speec h, respecti ve ly . CMOS points advantage fo r the comparison of legacy G.71 1 vs. direct. For the cases whe r e th e direct co ndition is co mpared to the po stfilter [ 2] and the p roposed po stprocessor of stru cture III in the cepstral doma in , 0.28 and -0 . 18 CMOS points are obtained, respec ti vely . This me a ns that the speech enhanced by the p roposed po stp r ocessor is more similar to the uncod ed speech (in direct con d ition), and e ven slightly b ut si gn ificantly pr eferr ed to unco ded sp eech . T o th e best knowledge o f th e authors, such a result has never been reported b e fore. For details, ho wever , see [73]. Ou r on ly explanation is the very low-energy in speech pause du ring the direc t condition , which, of cour se, we are not allowed to manip ulate. Relati ve to the legacy G.711 conditio n , the ITU-T postfilter [2] alre ady shows a significant 1.4 5 CMOS po ints advantage, while th e proposed postproce ssor perf o rms e ven better , ob taining 1.77 CMOS points above the legacy G.711 con dition. When the prop osed postproce ssor is directly compar ed to the ITU-T postfilter [2], a better perfo rmance of 0. 36 CMOS points is obtained . Finally , we conclude th at the p roposed postproc e ssor improves the quality of G.711 -coded speech mor e effectiv ely a s the I T U-T postfilter [2] do es. D. Complexity Analysis The complexity of the time domain approach b asically lies in the comp utations for the CNN. Neglecting the op- erations in Fig . 6 of m ax poo ling, upsampling and skip connectio n ad dition, the complexity- dominan t co n volutional operation s of the CNN amoun t to about 10 . 5 · N LF 2 +2 · N LF multiply/accu mulates (MA Cs) p er fr ame of the tim e domain approa c h , with L b e ing the fr a me len g th (i.e., 1 0 m s of spe e ch samples) and N , F being the par a meters of CNN. For the cepstral dom ain ap proache s, the n u mber o f MACs in the CNN follows the same expr ession as the time doma in app roach, with L = |M env | = 6 . 2 5% · K . Mo reover , some op erations are required b esides the computation s in the CNN: FFT , IFFT , 15 P S f r a g r e p l a c e m e n t s 100 100 100 200 200 200 300 300 300 400 400 400 500 500 500 600 600 600 700 700 700 0 0 0 128 128 128 256 256 256 384 384 384 512 512 512 Frame ℓ Frame ℓ Frame ℓ Frequenc y bins k Frequenc y bins k Frequency bi ns k Fig. 13. W ideband spectrograms of an utterance: reference speech (top), G.722-coded speech (c enter), and postprocesse d speech (bottom). Frame ℓ = 490 is mark ed. DCT -II , a n d IDCT -I I all hav e a computation al complexity of O ( K log K ) [74], [7 5]. In ord er to show th e complexity of the p r oposed CNN-based postproce ssors, the million instructio ns ( = MA Cs) p er second (MIPS) for the con volutional op erations in the CNN of each propo sed framework structure in n arrowband are shown in T ab . XII. Note that the values of L , N , a n d F ar e dou bled in wideband , resulting in a larger number of MA Cs per second compare d to that in narrowband. W e see th at the time domain postproce ssor requ ires a lot of compu tations, wh ile the cepstral domain postpr o cessors have mod erate co mplexity in terms of MIPS, ro ughly in the ord e r of mag nitude of a moder n spee c h codec. As an o utlook to futu re work, howe ver , it might be attractive to re d uce the com plexity of the m odels f urther b y methods such as teacher-student learning. V I . C O N C L U S I O N S In th is w or k, we propose two dif feren t CNN-based postpro- cessing ap p roaches in the time d omain an d the cepstral do- main, inclu ding six d ifferent framework structures for the lat- ter , to enhance co ded speech in a system-compatible m a nner . The proposed postprocessors in b oth domains are evaluated for v ario us narrowband an d wideband speech codecs in clean, tandeming , error-pron e transmission an d noisy co nditions, an d they are comp ared to an ITU-T postfilter [2] a s postprocessing baseline for G.711 . T he pro p osed p ostprocessor improves speech q uality in terms of PESQ by up to 0.2 5 MOS-LQO points for G.7 1 1, 0.3 0 p o ints fo r G.7 26, 0.82 poin ts for G.72 2, and 0.26 points fo r AMR-WB. I n a subjective CCR listening test, th e pro posed postpro c essor on G.711-coded speech ex- ceeds the speech qu ality of an ITU- T -stand ardized p ostfilter by 0 .36 CMOS p oints, a n d o btains a clear prefe r ence of 1.77 CMOS points co mpared to G.7 11, even significan tly exceeding the quality of un coded speech. The sou r ce code for the cepstral domain a p proach to enhan ce G.711 - coded speech is av ailable at https://github.com/ifnspaml/En hancement-Coded-Speech . P S f r a g r e p l a c e m e n t s 100 100 100 50 80 60 40 20 0 0 0 − 2 0 0 0 0 300 200 − 100 − 200 3 2 64 64 9 6 128 128 1 6 0 192 192 2 2 4 256 256 320 320 384 384 448 448 512 512 5 2 0 40 50 60 10 15 20 2 5 30 25 35 45 55 10 log ( | S | 2 ) 10 log ( | S | 2 ) Frequenc y bins k Frequenc y bins k Cepstral coeffici ents Cepstral coef ficient indice s m Reference Speech Reference Speech Reference Speech G.722-Coded Speech G.722-Coded Speech G.722-Coded Speech Postprocessed Speech Postprocessed Speech Postprocessed Speech Fig. 14. Amplitude spectrum (top), spectral en ve lope (center), both on a logarit hmic scale, and DCT -II type of cepstral coef ficients (bottom) for frame ℓ = 490 (see Fig. 13) of the wideband reference speech, G.722-coded speech, and postprocessed spee ch, respe ctiv ely . A P P E N D I X In this App endix we will provide som e further detailed analysis of o ur p ostprocessor in ce r tain conditio n s. W e take the speech file am02f065 from th e NT T speech database in American E nglish as a n example, and plot the spectrogra ms for prepro cessed speech (i.e., reference speech, see Fig. 8 ), G.726-co d ed speech, and enhanced speech by the cepstra l domain approach with structure III in Fig . 11. The sp e ctral analysis setting s a r e iden tical to the f ramework structure III (see T ab. I ) . Compa ring top and center sub plots, the G.726 coding adds sign a l contents to the high frequen cies (marked by rectangles) and distorts/weakens spectral e nvelope (marked by ov als). For the enhanced speec h in the b ottom, the high frequ ency coding noise is effectiv ely eliminated , and the spectral en velope is somewhat b e in g restored and en hanced tow ards the r e ference speech spectral envelope. In order to show that th e improvement of the postpr ocessor is not only based on a trivial postfilter simply suppressing frequen cies b eyond 3 . 5 kHz, we d id a brief PESQ MOS measuremen t o f co d ed speech with hig h frequ encies simply removed: A lowpass filter cutting off at 3.5 kHz is app lied to the co ded speech. Th e FLA T filter is used here, along with the up- and downsampling, since the FLA T filter w ork s at 1 6 k Hz. It turns out that the PESQ MOS scores did not ev en chan ge after this trivial postfiltering for both na r rowband cod ecs (G.711 and G.726 ) for bo th languages. This maybe surprising result shows th at the m ajor sp eech qu ality imp rovement does not at all come f rom th e tr i vial filtering, but suppor ts o ur propo sed postprocessor which also acts on lower f requenc ie s. As the pro posed cepstral dom ain ap proach intends to im- prove th e sp ectral en velope, we zoom into the f rame ℓ = 490 (dashed line in Fig. 11) to have a clear view of the spectral en velope. In Fig. 12, th e logarithmic spectrum 10 log ( | S ( k ) | 2 ) of the selected frame is drawn in the top, and of the spectral en velope in the mid dle, ob tained by keeping the first 32 cepstral coefficients and setting th e other cepstral coefficients to zer o, i.e., lowpass lifter in g. As we can see, th e spectral 16 en velope of the enhance d speech is closer to the referen ce speech as is the co ded speech. This holds particularly f or higher frequ encies, wh ich shows the ef ficacy of the proposed cepstral do main ap proach . Fin a lly , we take a look on the cepstral coefficients in the bottom of Fig. 12. It can b e seen that the cepstrum of the postprocessed speech is also clo ser to the reference speech, enhancing the c e p strum of cod ed speech not only into the sam e direction (e.g., m = 2 and m = 4 ), but even reversing the sign to b etter appro ach th e refe r ence cepstrum (e.g., m = 10 and m = 24 ). W e also conduc t the same ana ly sis as we did for G.72 6 above for G.7 2 2-cod e d speech (wideb and speech) and th e results are presented in Fig. 1 3 and Fig. 14. I t can be seen that a similar trend h olds: The spec tr al envelope and particularly the cep stral coefficients of the postpr ocessed sp eech ar e closer to those o f the r eference speech. In or der to explain the r eason of th e im pressiv e MOS score imp rovement of G.722 -coded speech (T ab . IV) after the pro posed postpro c essing, we also con ducted a similar experiment as fo r G.726 above, to identif y the impr ovement of using a simple P .341 filter af ter G.722-co ded speech cutting off at around 7 kHz for wideband speech. It turns ou t that the im - provements o f this simple filtering are alr eady non-negligible, which are 0.32 an d 0.31 PE SQ MOS fo r American Eng lish and German, respectively 8 . This result only p a r tly explain s the reason of the imp rovement, since th e postproc essed speech shows a similar cu tting-off ef fect at aroun d 7 k H z (see Fig. 13). The further improvement of the p ostprocessing in the cepstral domain being r oughly 0.5 MOS p oints now can b e dedicated to the enh anced spectral envelope. A C K N OW L E D G M E N T The authors w ou ld like to thank S. Elsham y for pr oviding an implem e n tation of bo th DCT -II and the IDCT -II an d J. Ab el for adv ice concern ing the setu p of the subjectiv e listening test. R E F E R E N C E S [1] ITU, Rec. G.711: P ulse Code Modulation (PCM) of V oice F requen cies , Interna tional T elecommunica tion Union, T elec ommunication Standard- izati on Sector (ITU-T), Nov . 1988. [2] ——, Rec. G. 711 Amendment 2: New A ppendix III Audio Quality En- hancemen t T oolbox , Internati onal T elecommunic ation Union, T el ecom- municati on Standardiz ation Sector (ITU-T), Nov . 2009. [3] ——, Rec. G.711.1: W ideban d Embedded Extension for ITU-T G.711 P ulse Code Modulati on , Internat ional T elec ommunication Union, T ele communication Standardi zation Sector (ITU-T), Sep. 2012. [4] J.-L . Garcia, C. Marro, and B. K ¨ ovesi , “A PCM Coding Noise Reduction for ITU-T G.711.1, ” in Proc. of INTERSPEE CH , Brisbane, Australia, Sep. 2008, pp. 57–60. [5] Y . Hiwasaki, S. Sasaki, H. Ohmuro, T . Mori et al. , “G.711.1: A W ideband Extension to IT U-T G. 711, ” in Proc. of E USIPCO , L ausanne, Switzerl and, Aug. 2008, pp. 1–5. [6] C. Plapous, C. Marro, L. Ma uuary , and P . Scalart , “A T wo-St ep Noise Reduct ion T echni que, ” in Pr oc. of ICASSP , Montreal, QC, Canada, May 2004, pp. I–289 –292. 8 This ∼ 0. 3 MOS score improve ment by s imple P . 341 filtering is due to the reference signa l we used, whi ch is also a P .341 filt er output with simila r frequenc y conten t. Accordingly , from an informal subjecti ve listening, there is no big differe nce between G.722-coded spee ch and G.722-coded speech follo wed by this simple P . 341 filter , meaning that P .341 postfiltering in our setup is no practic ally val id postprocessor . [7] V . Ramamoort hy and N. Jayant, “Enhancement of ADPCM Speech by Adap tiv e Postfilteri ng, ” AT&T Bell Laboratorie s T echnica l Journal , vol. 63, no. 8, pp. 1465–1 475, Oct. 1984. [8] V . Ramamoorthy , N. Jayant, R. Cox, an d M. Sondhi, “Enhance ment of ADPCM Spee ch Coding Wi th Backward-Ada ptiv e Algorit hms for Postfilteri ng and Noise Feedbac k, ” IEE E J ournal on Sele cted Areas in Communicat ions , vol. 6, no. 2, pp. 364–382, Feb . 1988. [9] J.-H. Chen and A. Gersho, “ Adapti ve Postfilterin g for Quality E n- hancemen t of Coded Speech, ” IEEE T ransact ions on Speec h and A udio Pr ocessing , vol. 3, no. 1, pp. 59–71, Jan. 1995. [10] T . B ¨ ackstr ¨ om, Speech Coding: Code Excited Linear Predic tion . Springer , 201 7. [11] 3GPP, Mandatory Speech Codec Speech Proc essing Functions; Adaptiv e Multi-Rat e (AMR) Speec h Codec; T ranscodi ng Functions (3GPP TS 26.090, Rel. 14) , 3GPP; TSG SA, Mar . 2017. [12] ——, Speech Codec Speec h Pr ocessing Functions; Adaptive Multi-Rate- W ideba nd (A MR-WB) Speech Codec; T ranscoding Functions (3GPP TS 26.190, Rel. 14) , 3GPP; TSG SA, Mar . 2017. [13] ——, Code c for Enhanced V oic e Serv ices (EVS); Detailed Algorit hmic Descripti on (3GPP TS 26.445, Rel. 14) , 3GPP; TSG SA, Mar . 2017 . [14] R. Hag en, E. Ekudde n, B. Johansson, and W . Kleijn, “Re mova l of Sparse-Excit ation Arti facts in CELP, ” in Pr oc. of ICASSP , Seattle, W A, USA, May 1998, pp. 145–148. [15] S. Han and T . Fingschei dt, “Improvin g Scalar Quantiz ation for Corre- lated Processes Using Adapti ve Codeboo ks Only at the Recei ver , ” in Pr oc. of EUSIPCO , Lisbon, P ortugal, Sep . 2014, pp. 386 –390. [16] ——, “Lloyd-Max Quanti zation of Correlated Processes: How to Obtain Gains by Recei ver -Sided Time-V ariant Codebooks, ” in P r oc. of 10th Internati onal ITG Confe rence on Systems, Communic ations and Coding , Hambur g, Ge rmany , Feb. 2015, pp. 1–6. [17] Z. Zhao, S. Han, an d T . Fingsc heidt, “Improving V ector Quanti zation- Based Decode rs for Correlated Processes in Error-Fre e Transmission, ” in Pr oc. of the 12th ITG Confe rence on Speec h Communic ation , Paderbo rn, Germany , Oct. 2016, pp. 70–7 4. [18] S. Han and T . Fingscheid t, “An Improv ed ADPCM Decoder by Adap- ti vely Controlle d Quantization Interv al Centroids, ” in Proc. of E U- SIPCO , Nice, Fra nce, Sep. 2015, pp . 335–3 39. [19] P . V ary and R. Martin, Digital Speech T r ansmission: Enhanceme nt, Coding and Err or Conceal ment . John Wil ey & Sons, 2006. [20] V . Grancharov , J. Plasberg, J. Samuelsson, and W . Kleijn, “Generali zed Postfilter for Speech Qualit y Enhancemen t, ” IEEE T ransacti ons on Audio, Speech, and Language Pr ocessing , vol. 16, no. 1, pp. 57– 64, Dec. 2008. [21] E. J okinen, M. T akane n, M. V ainio, and P . Alku, “An Adapti ve Post- Filteri ng Method Producing an Artificial Lombard-Like Effe ct for In- telli gibility Enhan cement of Narrowba nd T elephone Speech, ” Computer Speec h & Languag e , vol. 28, no. 2, pp. 619 –628, Mar . 2014. [22] G. Fuch s, A. Lombard, E . Rav elli, and M. Dietz, “A Comfort Noise Addition Post-Processor for Enhancing Low Bit-R ate Speech Coding in Noisy En vironments, ” in Pr oc. of IEEE Global Confer ence on Signal and Inf ormation (GlobalSI P) , Orlando, FL, USA, Dec . 2015, pp. 498– 502. [23] Y . W ang and D. W ang, “T o wards Scaling up Classification -Based Speech Separ ation, ” IEEE Tr ansactions on Audio, Speec h, and Languag e Pr ocessing , vol. 21, no. 7, pp. 1381– 1390, Mar . 2013. [24] A. Narayanan and D. W ang, “Ideal Ratio Mask E s timati on Usin g De ep Neural Networks for Robust Speech Recogniti on, ” in Proc . of ICASSP , V ancouv er , BC, Ca nada, May 2013, pp. 7092–70 96. [25] Y . Xu, J. Du, L.-R. Dai, and C.-H. L ee, “An Experimenta l Study on Speech Enhancemen t Based on Deep Neural Networks, ” IEEE Signal Pr ocessing Letters , v ol. 21, no. 1, pp. 65–68, Nov . 2013. [26] ——, “A Regression Approach to Speech Enhancement Based on Deep Neural Network s, ” IEEE /AC M T ransact ions on Audio, Speec h and Languag e Pr ocessing , vol. 23, no. 1, pp. 7–19, Oct. 2014. [27] X. Lu, S. Matsuda , C. Hori, and H. Kashioka , “Speech Restoration Based on Deep Learning Autoencod er with L ayer -Wise d Pretraini ng, ” in Proc . of INTERSPE ECH , Portland, OR, USA, Se p. 2012, pp. 15 04–1507. [28] X. Lu, Y . Tsao, S. Matsuda, and C. H ori, “Speech Enhan cement Ba sed on Deep Denoising Autoencode r, ” in Pr oc. of INTERSP EECH , Lyon , France, Aug. 2013, pp. 436–440. [29] A. L. Maa s, Q. Le, T . O’Neil, O. V inyals, P . Nguyen, and Y . Andre w , “Recur rent Neural Networks for Noise Reduct ion in Robust ASR, ” in Pr oc. of INTERSPEECH , Portland, OR, USA, Sep. 20 12, pp. 22–25. [30] F . W ening er , H. Erdogan, S. W atanabe , E. V ince nt, J. Roux, J. Hershey , and B. Schuller , “Speech Enhancement with LST M Recurrent Neural Networ ks an d its Applicati on to Noise-Rob ust AS R, ” in International 17 Confer ence on Latent V ariable Analysis and Signal Separation , Liberec, Czech Republic, Aug. 2015, pp. 91–99. [31] J. L ee, K. Kim, T . Shabestary , and H.-G. Kang, “Deep Bi-Directio nal Long Short-T erm Memory Based Speech Enha ncement for Wi nd Noise Reduct ion, ” in Pr oc. of Hands-f ree Speec h Communication s and Mi- cr ophone A rrays (HSCMA) , San Francisco, CA, USA, Mar . 2017, pp. 41–45. [32] S. Park and J. Lee, “A Fully Con volutio nal Neural Network for Speech Enhancement , ” arXiv preprint , Sep. 2016 . [33] S.-W . Fu, Y . Tsao, and X. Lu, “SNR-A ware Con volution al Neural Net- work Modeling for Speech Enhancement, ” in Proc. of INTERSPE ECH , San Francisco, CA, US A , Sep. 2016, pp. 3768–3 772. [34] T . Kouno vsky and J. Male k, “Single Channe l Speech Enhancemen t Using Con volutiona l Neural Network, ” in Proc. of Electr onics, Contr ol, Measur ement, Signals and their Applicati on to Mechatr onic s (ECMSM) , Donostia-Sa n Sebastian, Spain, May 2017, pp . 1–5. [35] S.-W . Fu, T .-Y . Hu, Y . Tsao, and X. Lu, “Comple x Spectr ogram Enhancement by Con v olutional Neural Netwo rk W ith Multi-Me trics Learning, ” in Proc . of Machi ne Learning for Signal Pr ocessing (MLSP) , Roppongi, T okyo, Japan, Sep. 2017, pp. 1–6. [36] S.-W . Fu, Y . Tsao, X. Lu, and H. Kawa i, “Raw W av eform-Based Speech Enhancement by Fully Conv olutiona l Netwo rks, ” arX iv pre print arXiv:1703.02205 , Mar . 201 7. [37] ——, “End-to-End W av eform Uttera nce Enhancement for Dire ct Eval - uation Metrics Optimizatio n by Fully Con v olutional Neura l Netw orks, ” arXiv preprint arXiv:1709.03658 , S ep. 2017. [38] O. Abdel-Hamid, A.-R. Mohamed, H. Jiang, and G. Penn, “Applying Con volu tional Neural Networks Concept s to Hybrid NN-HMM Model for Speech Recogni tion, ” in P r oc. of ICASSP , Kyot o, Japan, Mar . 2012, pp. 4277–4280. [39] C. Dong , C. Loy , K. He, and X. T ang, “Image Sup er-Resolut ion Using Deep Conv olutional Networks, ” IEEE T ransactions on P atte rn Anal ysis and Machine Intellige nce , vol. 38 , no. 2, pp. 295–307, Feb . 2016. [40] X.-J. Mao, C. Shen, and Y .-B. Y ang, “Image Restoration Using V ery Deep Con volu tional Encoder-Dec oder Networks Wi th Symmetric Skip Connect ions, ” in P r oc. of Advances in Neura l Information Proce ssing Systems (NIPS) , Bar celona, Spain, Dec. 201 6, pp. 2802–2810. [41] W . Shi, J. Caballero, F . Husz ´ ar , J. T otz , A. Aitken, R. Bishop, D. Rueck- ert, and Z. W ang, “Real-T ime Single Image and V ideo Super-Re solution Using an Effic ient Sub-Pixel Con voluti onal Neural Network, ” in Pr oc. of the IEEE Confer ence on Computer V ision and P attern Recog nition (CVPR) , Las V egas, NV , USA, Jun. 2016, pp. 1874– 1883. [42] J. Kim, J. K. L ee, and K. M. Lee, “ Accura te Im age Super-Resol ution Using V ery Deep Con vol utional Networks, ” in Proc. of the IEEE Confer ence on Computer V isi on and P attern Rec ognition (CVPR) , Las V egas, NV , USA, Jun. 201 6, pp. 1646–1654. [43] H. Noh, S. Hong, and B. Han, “Learning Decon voluti on Netwo rk for Semantic Segmentat ion, ” in Pro c. of the IEEE International Confer ence on Compute r V ision (ICCV) , Santiago, Chile, Dec. 2015, pp. 1520–1528. [44] E. Shelhamer , J. Long, and T . Darre ll, “Fully Con volutio nal Networks for Semantic Segment ation, ” IEEE T ransactions on P atte rn Analysis and Mach ine Intelli gence , vol. 39, no. 4, pp. 640–651, Apr . 2017. [45] K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recogni tion, ” in P r oc. of the IEEE Confere nce on Computer V ision and P att ern Recogn ition (CVP R ) , Las V ega s, NV , USA, Jun. 2016, pp. 770– 778. [46] Y . E phraim and D. Mal ah, “Speec h Enhancement Using A Minimum- Mean Squar e Error Short-T ime Spectral Amplit ude Estimator, ” IEEE T ransac tions on Acoustics, Speec h, and Signal Pr ocessing , vol. 32, no. 6, pp. 1109–1121, Dec . 1984. [47] X. Huang , A. Acero, H.-W . Hon, and R. Reddy , Spok en Langua ge Pr ocessing: A Guide to Theory , Algorithm, and System Develop ment . Prentic e hall PTR Upper Saddl e Ri ver , 2001. [48] “Multi-Lingua l Speech Database for T elephonomet ry, ” NTT Adv anced T ech nology Corporati on (NTT -A T), 19 94. [49] ITU, Proc essing Plan for G.711-Plus (Fi nal V ersion) , Internationa l T ele communication Union, T elecommuni cation Standardiza tion Sector (ITU-T); Rapporteurs Q10/ 16, Gene v a, Switzerland, Oct . 2009. [50] 3GPP, Draft AMR-WB Charact erisation P r ocessing Plan (WB-7c) V ersion 1.0 , 3GPP; TSG SA, E rlange n, Germany , Sep. 2001. [51] A. R ¨ am ¨ o and H. T oukomaa, “On Comparing Speech Quality of V arious Narro w- and W ideband Speech Codecs, ” in Proc. of Inte rnational Symposium on Signal Pr ocessing and Its Applic ations , vol. 2, S ydney , Australia , Aug. 2005 , pp. 603–606. [52] 3GPP, EV S P ermanent Document EVS-7c: Processi ng F unction s for Charac terization Phase, v1.0.0 , 3GPP; TSG SA, Helsinki , Finland, Aug. 2014. [53] ITU, Rec. G.191: Software T ools for Speech and Audio Coding Standard- ization , Internation al T ele communication Union, T ele communication Standard ization Sector (ITU-T), Mar . 2010 . [54] ——, Rec. P .56: Objec tive Measur ement of Active Spee ch Leve l , Inter - nationa l T elecommunica tion Union, T elecommunica tion Standardiza tion Sector (ITU-T), De c. 2011. [55] ——, Rec. G.726: 40, 32, 24, 16 kbit/s Adaptive Differ ential Pulse Code Modulation (ADPCM) , Inte rnational T elec ommunication Union, T ele communication Standardi zation Sector (ITU-T), Aug. 1990. [56] ——, R ec. G.722: 7 kHz Audio-Codi ng W ithin 64 kbit/s , Internat ional T ele communication Union, T elecommuni cation Standardiza tion Sector (ITU-T), Sep. 2012 . [57] 3GPP, ANSI-C Code for the Adaptive Multi-Rat e - W ideband (AMR-WB) Speec h codec (3GPP TS 26.173, Rel. 14) , 3GPP; TSG SA, Apr . 2017 . [58] D. P . Kingma and J. L. Ba, “Adam: A Method for Stochastic Optimiza- tion, ” in Pro c. of Internation al Confer ence for Learning Repre sentations (ICLR) , San Die go, CA, USA, May 2015, pp. 1–15. [59] “Speech Processing, T ransmission and Quality Aspects (STQ); S peech Quality Performanc e in the Presence of Background Noise; Part 1: Back- ground Noise Simulati on T echnique and Background Noise Database (ETSI E G 20 2 396-1, V ersion 1.2.2), ” ETSI, Sep. 2008 . [60] E. N. Gilber t, “Capaci ty of a burst-noise channel, ” Bell Labs T echnical J ournal , vol . 39, no. 5, pp. 12 53–1265, Sep. 1960. [61] J. Abel, M. Kanie wska, C. Guillaume, W . Tirry , and T . Fingscheidt, “An Instrumental Quality Mea sure for Art ificially Bandwidth-Exten ded Speech Signal s, ” IEEE/ACM T ransactions on Audi o, Speec h, and Lan- guag e Pr ocessing , vol. 25, no. 2, pp. 384–396, Feb . 2017. [62] S. Elshamy , N. Madhu, W . Tirry , and T . Fingscheidt, “Inst antaneous A Priori SNR Estimation by Cepstral Excita tion Manipulation , ” IEEE/ACM T ransac tions on Audio, Speec h, and Languag e Pr ocessing , vol . 25, no. 8, pp. 1592–1605, May 2017. [63] ITU, Rec. P .862: P erc eptual Evaluation of Speec h Qualit y (PESQ) , Inter- nationa l T elecommunica tion Union, T elecommunica tion Standardiza tion Sector (ITU-T), Fe b. 2001. [64] ——, Rec. P .862.1: Mapping Function for T ransformin g P .862 Raw Result Scor es to MOS-LQO , Internatio nal T elecommunica tion Union, T ele communication Standardi zation Sector (ITU-T), Nov . 2003. [65] ——, Rec. P .862.2: W ideband Extensi on to Rec ommendation P .862 for the Assessment of W ideband T elephone Networks and Speech Codecs , Interna tional T elecommunica tion Union, T elecommunicati on Standard- izati on Sector (ITU-T), Nov . 2007. [66] ——, Rec. P .863: P erc eptual Objective Listening Quality Pr ediction (POLQA) , Internat ional T elec ommunication Union, T ele communication Standard ization Sector (ITU-T), Mar . 2018 . [67] ——, Rec. P .800: Metho ds for Subjec tive Determin ation of T ransmission Quality , Internati onal T elecommunic ation Union, T ele communication Standard ization Sector (ITU-T), Aug. 1996. [68] A. L. Maas, A. Y . Hannun, and A. Y . Ng, “Rectifier Nonlinea rities Improv e Neur al Net work Acoust ic Models, ” in P r oc. of International Confer ence on Machi ne Learning (ICML) , vol. 30, no . 1, Long Beach, CA, USA, Jun. 2013, pp. 1–6. [69] G. Klambauer , T . Unterthiner , A. Mayr , and S. Hochreiter , “Self- Normalizi ng N eural Networks, ” arXiv pre print arX iv:1706.025 15 , 2017. [70] ITU, R ec. G.711 A ppendix I: A High Quality Low-Complex ity A lgorithm for P ack et Loss Concealment with G.711 , Internat ional T elec ommuni- catio n Union, T elecommunica tion Standard ization Sector (ITU-T), Sep. 1999. [71] 3GPP, Adaptive Mult i-Rate - W ideband (AMR-WB) Speec h Codec; E rr or Conceal ment of Erroneo us or Lost F rames (3GP P TS 26.191 Rel. 14) , 3GPP; TSG SA, Apr . 2017. [72] D. Dean, S. Sridharan, R. V ogt, and M. Mason, “The QUT -NOISE- TIMIT Corpus for the E v aluation of V oice Acti vity Detectio n Algo - rithms, ” in P roc. of INTERSPE E CH , Makuhari, Chiba, Japan, Sep. 2010, pp. 3110–3113. [73] Z. Zhao, H. L iu, and T . Fingscheidt, “Enhancements of G. 711-Coded Speech Pro viding Qual ity Higher Than Uncoded, ” in Pr oc. of the 13t h ITG Conf erence on Sp eech Communicat ion (accept ed for public ation) , Oldenb urg, Germany , Oct. 2018. [74] J. W . Coole y and J. W . T ukey , “An Algorithm for the Machine Calcul ation of Complex Fouri er Series, ” Mathemat ics of Computatio n , vol. 19, no. 90, pp. 297–3 01, Apr . 1965. [75] M. Narasimha and A. Peterson, “On the Computat ion of the Discrete Cosine Transform, ” IEEE T ransact ions on Communicatio ns , vol. 26, no. 6, pp . 934–936, Jun. 19 78.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment