An Empirical Study of Speculative Concurrency in Ethereum Smart Contracts
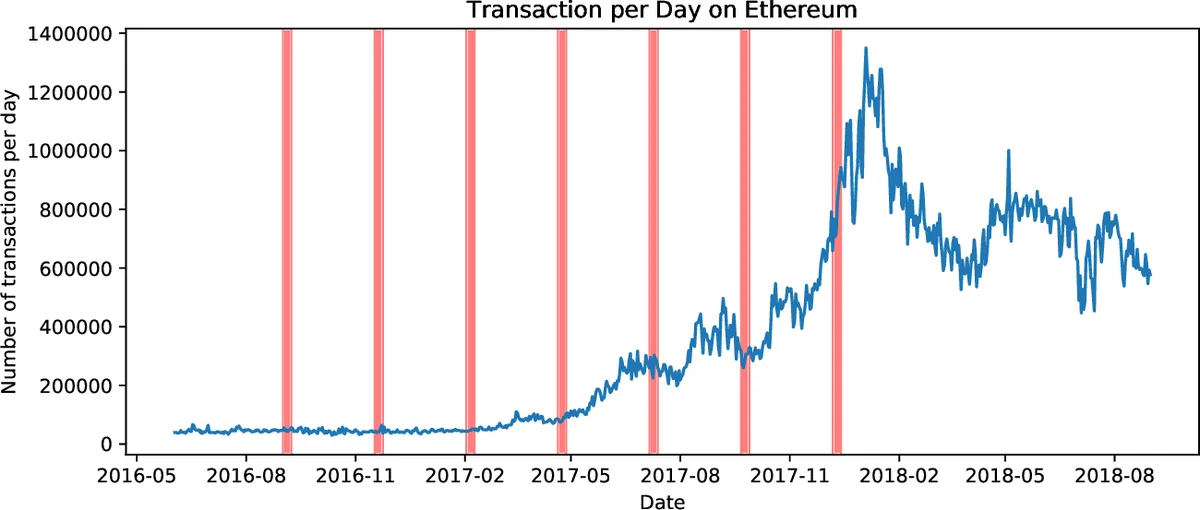
We use historical data to estimate the potential benefit of speculative techniques for executing Ethereum smart contracts in parallel. We replay transaction traces of sampled blocks from the Ethereum blockchain over time, using a simple speculative execution engine. In this engine, miners attempt to execute all transactions in a block in parallel, rolling back those that cause data conflicts. Aborted transactions are then executed sequentially. Validators execute the same schedule as miners. We find that our speculative technique yields estimated speed-ups starting at about 8-fold in 2016, declining to about 2-fold at the end of 2017, where speed-up is measured using either gas costs or instruction counts. We also observe that a small set of contracts are responsible for many data conflicts resulting from speculative concurrent execution.
💡 Research Summary
This paper investigates the practical benefits of speculative concurrency for executing Ethereum smart contracts. Because Ethereum contracts are written in a Turing‑complete language and may invoke one another through untyped function pointers, static analysis of dependencies is largely infeasible. Consequently, the authors adopt a dynamic “speculative execution” approach: each transaction is run in parallel while its read‑set and write‑set are recorded; if two transactions touch the same storage location and at least one performs a write, they are deemed to conflict. Conflicting transactions are immediately rolled back and later re‑executed sequentially. This two‑phase model is applied both by miners (who initially construct the block) and by validators (who re‑execute the block for consensus).
The empirical study replays historical transaction traces from the Ethereum blockchain between mid‑2016 and the end of 2017. To keep the workload tractable, the authors select seven one‑week windows spread across the period, sampling every tenth block within each window. This yields roughly 4 million blocks and 100 million transactions in total, but the analysis focuses on the sampled subset (≈ 10 % of blocks). Using the Go‑Ethereum client (geth) in archive mode, they retrieve bytecode traces and re‑execute each transaction in a simulated environment that records read/write accesses.
A “greedy concurrent EVM” is implemented for the simulation. For each block, execution proceeds in two phases: (1) a concurrent phase where a pool of worker threads (16, 32, or 64) picks transactions at random, executes them speculatively, and rolls back any that encounter a conflict; (2) a sequential phase where all rolled‑back transactions are re‑run one‑by‑one. Execution time is estimated in two ways: (a) total gas consumed by the transaction, and (b) the number of EVM bytecode instructions executed. Both metrics produce similar speed‑up curves.
Results show a clear time‑dependent trend. In 2016, when daily transaction volume was modest (≈ 30 k transactions per block), conflict rates were low and speculative execution achieved up to an 8× speed‑up compared with pure sequential execution. By late 2017, daily transaction volume had surged (≈ 550 k transactions per block), conflict rates rose sharply, and the observed speed‑up fell to roughly 2×. The authors note that a small fraction of contracts—about the top 5 % by call frequency—are responsible for more than 70 % of all conflicts. These “hot” contracts are typically token transfer contracts, decentralized exchange logic, or simple token‑minting contracts.
Additional experiments explore several variations. Treating the read‑set and write‑set as a single conflict set (i.e., ignoring the distinction between reads and writes) dramatically inflates conflict detection and reduces speed‑up, underscoring the importance of precise read/write tracking. Running multiple speculative phases (e.g., a second parallel phase after the first roll‑back) yields only marginal gains, suggesting diminishing returns once the bulk of conflicts have been identified. Scaling the number of simulated cores from 16 to 64 improves speed‑up, but adding more cores beyond 64 provides little benefit, indicating that the workload becomes I/O‑bound or limited by the inherent serial portion of the schedule. Finally, a simple static conflict analysis—pre‑filtering transactions that are guaranteed to conflict—offers only modest improvement, implying that most conflicts are data‑dependent and only observable at runtime.
The paper’s contributions are threefold. First, it demonstrates a methodology for replaying real blockchain history against alternative execution models, which can be reused for other platforms. Second, it provides empirical evidence that even a naïve speculative scheduler can achieve non‑trivial parallelism on existing Ethereum workloads, though the benefit erodes as transaction volume grows. Third, it highlights that conflict hot‑spots are concentrated in a few popular contracts, suggesting that economic incentives (e.g., gas discounts for conflict‑free contracts) or language‑level primitives (e.g., atomic credit/debit operations) could mitigate contention and enable higher parallelism.
Limitations include the reliance on a simulated EVM rather than a production‑grade parallel implementation, the simplification of rollback costs to gas or instruction counts, and the exclusion of network‑level factors such as block propagation latency. Moreover, sampling only every tenth block may miss rare but high‑conflict patterns. Nonetheless, the study offers valuable insights for future research directions: building a real parallel EVM, combining static analysis with runtime speculation, designing smart‑contract languages that expose commutative operations, and crafting incentive mechanisms to encourage developers to write low‑conflict contracts.
Comments & Academic Discussion
Loading comments...
Leave a Comment