Adaptive and optimal online linear regression on $ell^1$-balls
We consider the problem of online linear regression on individual sequences. The goal in this paper is for the forecaster to output sequential predictions which are, after $T$ time rounds, almost as good as the ones output by the best linear predicto…
Authors: Sebastien Gerchinovitz (DMA, CLASSIC), Jia Yuan Yu
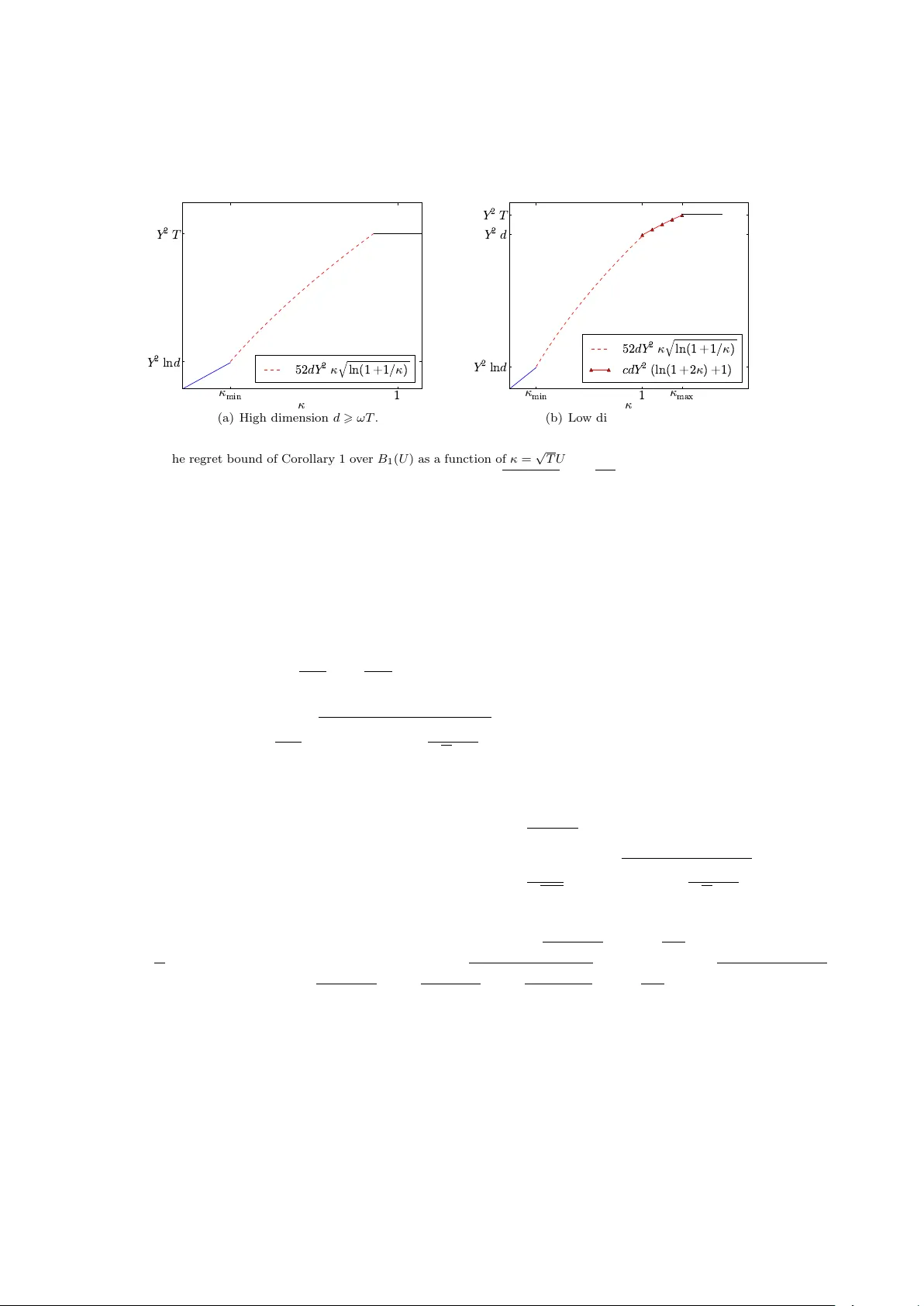
Adaptiv e and optimal online linear regression on ` 1 -balls S ´ ebastien Gerc hinovitz a,1, ∗ , Jia Y uan Y u b a ´ Ec ole Normale Sup´ erieur e, 45 rue d’Ulm, 75005 Paris, F r anc e b IBM R ese ar ch, Damastown T e chnolo gy Campus, Dublin 15, Ir eland Abstract W e consider the problem of online linear regression on individual sequences. The goal in this pap er is for the forecaster to output sequen tial predictions whic h are, after T time rounds, almost as goo d as the ones output b y the best linear predictor in a giv en ` 1 -ball in R d . W e consider b oth the cases where the dimension d is small and large relative to the time horizon T . W e first present regret b ounds with optimal dep endencies on d , T , and on the sizes U , X and Y of the ` 1 -ball, the input data and the observ ations. The minimax regret is shown to exhibit a regime transition around the p oin t d = √ T U X/ (2 Y ). F urthermore, we present efficien t algorithms that are adaptiv e, i.e., that do not require the knowledge of U , X , Y , and T , but still ac hieve nearly optimal regret b ounds. Keywor ds: Online learning, Linear regression, Adaptiv e algorithms, Minimax regret 1. Introduction In this pap er, we consider the problem of online linear regression against arbitrary sequences of input data and observ ations, with the ob jectiv e of b eing comp etitive with respect to the b est linear predictor in an ` 1 -ball of arbitrary radius. This extends the task of conv ex aggregation. W e consider b oth low- and high-dimensional input data. Indeed, in a large num b er of contemporary problems, the a v ailable data can b e high-dimensional—the dimension of each data p oint is larger than the n umber of data p oints. Examples include analysis of DNA sequences, collaborative filtering, astronomical data analysis, and cross-country gro wth regression. In suc h high-dimensional problems, p erforming linear regression on an ` 1 -ball of small diameter ma y be helpful if the b est linear predictor is sparse. Our goal is, in both lo w and high dimensions, to pro vide online linear regression algorithms along with b ounds on ` 1 -balls that characterize their robustness to w orst-case scenarios. 1.1. Setting W e consider the online version of linear regression, whic h unfolds as follo ws. First, the en vironment c ho oses a sequence of observ ations ( y t ) t > 1 in R and a sequence of input vectors ( x t ) t > 1 in R d , b oth initially hidden from the forecaster. At each time instant t ∈ N ∗ = { 1 , 2 , . . . } , the environmen t reveals the data x t ∈ R d ; the forecaster then gives a prediction b y t ∈ R ; the en vironmen t in turn rev eals the observ ation y t ∈ R ; and finally , the forecaster incurs the square loss ( y t − b y t ) 2 . The dimension d can b e either small or large relativ e to the num ber T of time steps: we consider b oth cases. In the sequel, u · v denotes the standard inner pro duct b et ween u , v ∈ R d , and we set k u k ∞ , max 1 6 j 6 d | u j | and k u k 1 , P d j =1 | u j | . The ` 1 -ball of radius U > 0 is the following b ounded subset of R d : B 1 ( U ) , u ∈ R d : k u k 1 6 U . ∗ Corresponding author Email addr esses: sebastien.gerchinovitz@ens.fr (S´ ebastien Gerchino vitz), jiayuanyu@ie.ibm.com (Jia Y uan Y u) 1 This research was carried out within the INRIA pro ject CLASSIC hosted by ´ Ecole Normale Sup ´ erieure and CNRS. Pr eprint submitte d to Elsevier April 25, 2013 Giv en a fixed radius U > 0 and a time horizon T > 1, the goal of the forecaster is to predict almost as well as the best linear forecaster in the reference set x ∈ R d 7→ u · x ∈ R : u ∈ B 1 ( U ) , i.e., to minimize the regret on B 1 ( U ) defined b y T X t =1 ( y t − b y t ) 2 − min u ∈ B 1 ( U ) ( T X t =1 ( y t − u · x t ) 2 ) . W e shall present algorithms along with b ounds on their regret that hold uniformly ov er all sequences 2 ( x t , y t ) 1 6 t 6 T suc h that k x t k ∞ 6 X and | y t | 6 Y for all t = 1 , . . . , T , where X , Y > 0. These regret b ounds dep end on four imp ortan t quantities: U , X , Y , and T , which may be kno wn or unkno wn to the forecaster. 1.2. Contributions and r elate d works In the next paragraphs we detail the main contributions of this pap er in view of related works in online linear regression. Our first contribution (Section 2) consists of a minimax analysis of online linear regression on ` 1 -balls in the arbitrary sequence setting. W e first pro vide a refined regret b ound expressed in terms of Y , d , and a quantit y κ = √ T U X/ (2 d Y ). This quan tity κ is used to distinguish tw o regimes: we show a distinctive regime transition 3 at κ = 1 or d = √ T U X/ (2 Y ). Namely , for κ < 1, the regret is of the order of d Y 2 κ (prop ortional to √ T ), whereas it is of the order of d Y 2 ln κ (prop ortional to ln T ) for κ > 1. The deriv ation of this regret b ound partially relies on a Maurey-type argument used under v arious forms with i.i.d. data, e.g., in [1, 2, 3, 4] (see also [5]). W e adapt it in a straigh tforw ard wa y to the deterministic setting. Therefore, this is yet another technique that can b e applied to b oth the sto chastic and individual sequence settings. Unsurprisingly , the refined regret bound mentioned abov e matc hes the optimal risk b ounds for stochastic settings 4 [6, 2] (see also [7]). Hence, linear regression is just as hard in the sto chastic setting as in the arbi- trary sequence setting. Using the standard online to batc h con v ersion, w e mak e the latter statemen t more precise b y establishing a low er bound for all κ at least of the order of √ ln d/d . This lo wer b ound extends those of [8, 9], whic h only hold for small κ of the order of 1 /d . The algorithm achieving our minimax regret b ound is b oth computationally inefficient and non-adaptive (i.e., it requires prior kno wledge of the quantities U , X , Y , and T that ma y be unknown in practice). Those tw o issues were first ov ercome by [10] via an automatic tuning termed self-c onfident (since the forecaster someho w trusts himself in tuning its parameters). They indeed prov ed that the self-confident p -norm algorithm with p = 2 ln d and tuned with U has a cum ulative loss b L T = P T t =1 ( y t − b y t ) 2 b ounded by b L T 6 L ∗ T + 8 U X q ( e ln d ) L ∗ T + (32 e ln d ) U 2 X 2 6 8 U X Y √ eT ln d + (32 e ln d ) U 2 X 2 , where L ∗ T , min { u ∈ R d : k u k 1 6 U } P T t =1 ( y t − u · x t ) 2 6 T Y 2 . This algorithm is efficient, and our low er b ound in terms of κ shows that it is optimal up to logarithmic factors in the regime κ 6 1 without prior knowledge of X , Y , and T . Our second contribution (Section 3) is to sho w that similar adaptivity and efficiency properties can b e obtained via exponential w eighting. W e consider a v arian t of the EG ± algorithm [9]. The latter has a manageable computational complexity and our lo wer bound shows that it is nearly optimal in the regime 2 Actually our results hold whether ( x t , y t ) t > 1 is generated by an oblivious environmen t or a non-oblivious opp onent since we consider deterministic forecasters. 3 In high dimensions (i.e., when d > ω T , for some absolute constant ω > 0), we do not observe this transition (cf. Figure 1). 4 F or example, ( x t , y t ) 1 6 t 6 T may b e i.i.d. , or x t can b e deterministic and y t = f ( x t ) + ε t for an unknown function f and an i.i.d. sequence ( ε t ) 1 6 t 6 T of Gaussian noise. 2 κ 6 1. Ho wev er, the EG ± algorithm requires prior kno wledge of U , X , Y , and T . T o ov ercome this adaptivit y issue, we study a mo dification of the EG ± algorithm that relies on the v ariance-based automatic tuning of [11]. The resulting algorithm – called adaptive EG ± algorithm – can b e applied to general con vex and differentiable loss functions. When applied to the square loss, it yields an algorithm of the same computational complexity as the EG ± algorithm that also achiev es a nearly optimal regret but without needing to kno w X , Y , and T b eforehand. Our third contribution (Section 3.3) is a generic technique called loss Lipschitzific ation . It transforms the loss functions u 7→ ( y t − u · x t ) 2 (or u 7→ y t − u · x t α if the predictions are scored with the α -loss for a real num ber α > 2) into Lipsc hitz con tinuous functions. W e illustrate this technique b y applying the generic adaptiv e EG ± algorithm to the mo dified loss functions. When the predictions are scored with the square loss, this yields an algorithm (the LEG algorithm) whose main regret term slightly impro ves on that derived for the adaptive EG ± algorithm without Lipsch tizification. The b enefits of this tec hnique are clearer for loss functions with higher curv ature: if α > 2, then the resulting regret b ound roughly grows as U instead of a naiv e U α/ 2 . Finally , in Section 4, w e pro vide a simple w a y to achiev e minimax regret uniformly o ver all ` 1 -balls B 1 ( U ) for U > 0. This metho d aggregates instances of an algorithm that requires prior knowledge of U . F or the sak e of simplicity , we assume that X , Y , and T are known, but explain in the discussions how to extend the metho d to a fully adaptiv e algorithm that requires the knowledge neither of U , X , Y , nor T . This paper is organized as follo ws. In Section 2, w e establish our refined upper and lo wer bounds in terms of the in trinsic quan tit y κ . In Section 3, we present an efficien t and adaptive algorithm — the adaptive EG ± algorithm with or without loss Lipschitzification — that ac hiev es the optimal regret on B 1 ( U ) when U is known. In Section 4, we use an aggregating strategy to ac hieve an optimal regret uniformly ov er all ` 1 -balls B 1 ( U ), for U > 0, when X , Y , and T are known. Finally , in Section 5, we discuss as an extension a fully automatic algorithm that requires no prior kno wledge of U , X , Y , or T . Some proofs and additional to ols are p ostponed to the app endix. 2. Optimal rates In this section, we first present a refined upp er bound on the minimax regret on B 1 ( U ) for an arbitrary U > 0. In Corollary 1, we express this upper b ound in terms of an intrinsic quantit y κ , √ T U X/ (2 d Y ). The optimalit y of the latter b ound is shown in Section 2.2. W e consider the following definition to av oid any am biguity . W e call online for e c aster any sequence F = ( e f t ) t > 1 of functions such that e f t : R d × ( R d × R ) t − 1 → R maps at time t the new input x t and the past data ( x s , y s ) 1 6 s 6 t − 1 to a prediction e f t x t ; ( x s , y s ) 1 6 s 6 t − 1 . Depending on the context, the latter prediction ma y b e simply denoted by e f t x t ) or b y b y t . 2.1. Upp er b ound Theorem 1 (Upp er b ound) . L et d, T ∈ N ∗ , and U, X , Y > 0 . The minimax r e gr et on B 1 ( U ) for b ounde d b ase pr e dictions and observations satisfies inf F sup k x t k ∞ 6 X, | y t | 6 Y ( T X t =1 ( y t − b y t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) 6 3 U X Y p 2 T ln(2 d ) if U < Y X q ln(1+2 d ) T ln 2 , 26 U X Y r T ln 1 + 2 d Y √ T U X if Y X q ln(1+2 d ) T ln 2 6 U 6 2 d Y √ T X , 32 d Y 2 ln 1 + √ T U X d Y + d Y 2 if U > 2 d Y X √ T , wher e the infimum is taken over al l for e c asters F and wher e the supr emum extends over al l se quenc es ( x t , y t ) 1 6 t 6 T ∈ ( R d × R ) T such that | y 1 | , . . . , | y T | 6 Y and k x 1 k ∞ , . . . , k x T k ∞ 6 X . 3 Theorem 1 impro ves the b ound of [9, Theorem 5.11] for the EG ± algorithm. First, our b ound dep ends logarithmically—as opposed to linearly—on U for U > 2 d Y / ( √ T X ). Secondly , it is smaller by a factor ranging from 1 to √ ln d when Y X r ln(1 + 2 d ) T ln 2 6 U 6 2 d Y √ T X . (1) Hence, Theorem 1 provides a partial answer to a question 5 raised in [9] ab out the gap of p ln(2 d ) b etw een the upp er and lo wer b ounds. Before proving the theorem (see below), we state the following immediate corollary . It expresses the upp er b ound of Theorem 1 in terms of an in trinsic quantit y κ , √ T U X/ (2 d Y ) that relates √ T U X/ (2 Y ) to the am bient dimension d . Corollary 1 (Upp er bound in terms of an in trinsic quan tit y) . L et d, T ∈ N ∗ , and U, X , Y > 0 . The upp er b ound of The or em 1 expr esse d in terms of d , Y , and the intrinsic quantity κ , √ T U X/ (2 d Y ) r e ads: inf F sup k x t k ∞ 6 X, | y t | 6 Y ( T X t =1 ( y t − b y t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) 6 6 d Y 2 κ p 2 ln(2 d ) if κ < √ ln(1+2 d ) 2 d √ ln 2 , 52 d Y 2 κ p ln(1 + 1 /κ ) if √ ln(1+2 d ) 2 d √ ln 2 6 κ 6 1 , 32 d Y 2 ln(1 + 2 κ ) + 1 if κ > 1 . The parametrization b y ( d, Y , κ ) helps to unify the different upp er bounds of Theorem 1: on both regimes κ 6 1 and κ > 1, the regret b ound scales as d Y 2 , the only difference lies in the dep endence in κ (linear v ersus logarithmic). The upp er b ound of Corollary 1 is shown in Figure 1. Observe that, in lo w dimension (Figure 1(b)), a clear transition from a regret of the order of √ T to one of ln T o ccurs at κ = 1. This transition is absen t for high dimensions: for d > ω T , where ω , 32(ln(3) + 1) − 1 , the regret b ound 32 d Y 2 ln(1 + 2 κ ) + 1 is w orse than a trivial b ound of T Y 2 when κ > 1. W e no w prov e Theorem 1. The main part of the pro of relies on a Maurey-t yp e argument. Although this argumen t w as used in the stochastic setting [1, 2, 3, 4], we adapt it to the deterministic setting. This is y et another tec hnique that can b e applied to b oth the sto chastic and individual sequence settings. Pro of (of Theorem 1): First note from Lemma 5 in App endix B that the minimax regret on B 1 ( U ) is upp er b ounded 6 b y min ( 3 U X Y p 2 T ln(2 d ) , 32 d Y 2 ln 1 + √ T U X d Y ! + d Y 2 ) . (2) Therefore, the first case U < Y X q ln(1+2 d ) T ln 2 and the third case U > d Y X √ T are straigh tforward. Therefore, w e assume in the sequel that Y X q ln(1+2 d ) T ln 2 6 U 6 2 d Y √ T X . W e use a Maurey-t yp e argumen t to refine the regret b ound (2). This technique was used under v arious 5 The authors of [9] asked: “F or large d there is a significant gap b etw een the upp er and low er b ounds. W e would like to know if it p ossible to improv e the upper bounds by eliminating the ln d factors.” 6 As prov ed in Lemma 5, the regret bound (2) is achiev ed either by the EG ± algorithm, the algorithm SeqSEW B ,η τ of [12] (we could also get a slightly worse b ound with the sequential ridge regression forecaster [13, 14]), or the trivial null forecaster. 4 1 mi n Y 2 T Y 2 l n d 52 dY 2 l n ( 1 + 1 / ) (a) High dimension d > ω T . max 1 mi n Y 2 T Y 2 d Y 2 l n d 52 dY 2 l n ( 1 + 1 / ) c dY 2 ( l n ( 1 + 2 ) + 1) (b) Lo w dimension d < ω T . Figure 1: The regret b ound of Corollary 1 ov er B 1 ( U ) as a function of κ = √ T U X / (2 d Y ). The constant c is chosen to ensure contin uit y at κ = 1, and ω , 32(ln(3) + 1) − 1 . W e define: κ min = p ln(1 + 2 d ) / (2 d √ ln 2) and κ max = ( e ( T /d − 1) /c − 1) / 2. forms in the sto chastic setting, e.g., in [1, 2, 3, 4]. It consists of discretizing B 1 ( U ) and lo oking at a random p oin t in this discretization to study its approximation properties. W e also use clipping to get a regret b ound gro wing as U instead of a naive U 2 . More precise ly , we first use the fact that to b e comp etitive against B 1 ( U ), it is sufficien t to b e comp et- itiv e against its finite subset e B U,m , k 1 U m , . . . , k d U m : ( k 1 , . . . , k d ) ∈ Z d , d X j =1 | k j | 6 m ⊂ B 1 ( U ) , where m , b α c with α , U X Y s T (ln 2) / ln 1 + 2 d Y √ T U X . By Lemma 7 in App endix C, and since m > 0 (see b elow), we indeed hav e inf u ∈ e B U,m T X t =1 ( y t − u · x t ) 2 6 inf u ∈ B 1 ( U ) T X t =1 ( y t − u · x t ) 2 + T U 2 X 2 m 6 inf u ∈ B 1 ( U ) T X t =1 ( y t − u · x t ) 2 + 2 √ ln 2 U X Y s T ln 1 + 2 d Y √ T U X , (3) where (3) follo ws from m , b α c > α/ 2 since α > 1 (in particular, m > 0 as stated abov e). T o see why α > 1, note that it suffices to sho w that x p ln(1 + x ) 6 2 d √ ln 2 where we set x , 2 d Y / ( √ T U X ). But from the assumption U > ( Y /X ) p ln(1 + 2 d ) / ( T ln 2), w e hav e x 6 2 d p ln(2) / ln(1 + 2 d ) , y , so that, by monotonicity , x p ln(1 + x ) 6 y p ln(1 + y ) 6 y p ln(1 + 2 d ) = 2 d √ ln 2. Therefore it only remains to exhibit an algorithm which is comp etitive against e B U,m at an aggregation price of the same order as the last term in (3). This is the case for the standard exp onentially weigh ted a verage forecaster applied to the clipp ed predictions u · x t Y , min n Y , max − Y , u · x t o , u ∈ e B U,m , 5 and tuned with the inv erse temp erature parameter η = 1 / (8 Y 2 ). More formally , this algorithm predicts at eac h time t = 1 , . . . , T as b y t , X u ∈ e B U,m p t ( u ) u · x t Y , where p 1 ( u ) , 1 / e B U,m (denoting by e B U,m the cardinality of the set e B U,m ), and where the weigh ts p t ( u ) are defined for all t = 2 , . . . , T and u ∈ e B U,m b y p t ( u ) , exp − η P t − 1 s =1 y s − [ u · x s ] Y 2 P v ∈ e B U,m exp − η P t − 1 s =1 y s − [ v · x s ] Y 2 . By Lemma 6 in App endix B, the ab o ve forecaster tuned with η = 1 / (8 Y 2 ) satisfies T X t =1 ( y t − b y t ) 2 − inf u ∈ e B U,m T X t =1 ( y t − u · x t ) 2 6 8 Y 2 ln e B U,m 6 8 Y 2 ln e(2 d + m ) m m (4) = 8 Y 2 m 1 + ln(1 + 2 d/m ) 6 8 Y 2 α 1 + ln(1 + 2 d/α ) (5) = 8 Y 2 α + 8 Y 2 α ln 1 + 2 d Y √ T U X s ln 1 + 2 d Y / ( √ T U X ) ln 2 6 8 Y 2 α + 16 Y 2 α ln 1 + 2 d Y √ T U X (6) 6 8 √ ln 2 + 16 √ ln 2 U X Y s T ln 1 + 2 d Y √ T U X . (7) T o get (4) w e used Lemma 8 in App endix C. Inequality (5) follows by definition of m 6 α and the fact that x 7→ x 1 + ln(1 + A/x ) is nondecreasing on R ∗ + for all A > 0. Inequality (6) follo ws from the assumption U 6 2 d Y / ( √ T X ) and the elementary inequality ln 1 + x p ln(1 + x ) / ln 2 6 2 ln(1 + x ) whic h holds for all x > 1 and was used, e.g., at the end of [3, Theorem 2-a)]. Finally , elementary manipulations combined with the assumption that 2 d Y / ( √ T U X ) > 1 lead to (7). Putting Eqs. (3) and (7) together, the previous algorithm has a regret on B 1 ( U ) which is b ounded from ab o ve by 10 √ ln 2 + 16 √ ln 2 U X Y s T ln 1 + 2 d Y √ T U X , whic h concludes the pro of since 10 / √ ln 2 + 16 √ ln 2 6 26. 2.2. L ower b ound Corollary 1 gives an upp er b ound on the regret in terms of the quantities d , Y , and κ , √ T U X/ (2 d Y ). W e now show that for all d ∈ N ∗ , Y > 0, and κ > p ln(1 + 2 d ) / (2 d √ ln 2), the upp er bound can not b e impro ved 7 up to logarithmic factors. 7 F or T sufficiently large, w e may ov erlo ok the case κ < p ln(1 + 2 d ) / (2 d √ ln 2) or √ T < ( Y / ( U X )) p ln(1 + 2 d ) / ln 2. Observe that in this case, the minimax regret is already of the order of Y 2 ln(1 + d ) (cf. Figure 1). 6 Theorem 2 (Lo wer b ound) . F or al l d ∈ N ∗ , Y > 0 , and κ > √ ln(1+2 d ) 2 d √ ln 2 , ther e exist T > 1 , U > 0 , and X > 0 such that √ T U X/ (2 d Y ) = κ and inf F sup k x t k ∞ 6 X, | y t | 6 Y ( T X t =1 ( y t − b y t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) > c 1 ln 2+16 d 2 d Y 2 κ p ln (1 + 1 /κ ) if √ ln(1+2 d ) 2 d √ ln 2 6 κ 6 1 , c 2 ln 2+16 d 2 d Y 2 if κ > 1 , wher e c 1 , c 2 > 0 ar e absolute c onstants. The infimum is taken over al l for e c asters F and the supr emum is taken over al l se quenc es ( x t , y t ) 1 6 t 6 T ∈ ( R d × R ) T such that | y 1 | , . . . , | y T | 6 Y and k x 1 k ∞ , . . . , k x T k ∞ 6 X . The ab ov e low er b ound extends those of [8, 9], which hold for small κ of the order of 1 /d . The pro of is p ostp oned to App endix A.1. W e perform a reduction to the sto c hastic batch setting—via the standard online to batc h conv ersion—and emplo y a version of a low er bound of [2]. Note that in the pro of of Theorem 2, we are free to choose the v alues of t wo parameters among T , U , and X , pro vided that √ T U X/ (2 d Y ) = κ . T his lib erty is p ossible since the problem is now parametrized by d , Y , and κ only (as shown in Corollary 1, these three parameters are sufficient to express the regret b ound of Theorem 1, and they actually help to unify the upper b ounds of the tw o regimes). A more ambitious lo wer b ound would consist in proving that the upp er b ound of Theorem 1 cannot b e substantially impro ved for an y fixed v alue of ( d, Y , T , U, X ). This question is left for future w ork. 3. Adaptation to unknown X , Y and T via exp onen tial weigh ts Although the pro of of Theorem 1 already giv es an algorithm that achiev es the minimax regret, the latter tak es as inputs U , X , Y , and T , and it is inefficien t in high dimensions. In this section, we present a new metho d that achiev es the minimax regret b oth efficien tly and without prior knowledge of X , Y , and T pro vided that U is known. Adaptation to an unknown U is considered in Section 4. Our metho d consists of mo difying an underlying efficien t linear regression algorithm such as the EG ± algorithm [9] or the sequen tial ridge reg ression forecaster [14, 13]. Next, we show that automatically tuned v ariants of the EG ± algorithm nearly achiev e the minimax regret for the regime d > √ T U X/ (2 Y ). A similar mo dification could b e applied to the ridge regression forecaster — with a total computational efficiency of the same order as that of the standard ridge algorithm — to achiev e a nearly optimal regret b ound of order d Y 2 ln 1 + d √ T U X d Y 2 in the regime d < √ T U X/ (2 Y ). The latter analysis is more technical and hence is omitted. 3.1. An adaptive EG ± algorithm for gener al c onvex and d iffer entiable loss functions The second algorithm of the proof of Theorem 1 is computationally inefficien t b ecause it aggregates appro ximately d √ T exp erts. In contrast, the EG ± algorithm has a manageable computational complexit y that is linear in d at each time t . Next we introduce a version of the EG ± algorithm — called the adaptive EG ± algorithm — that do es not require prior knowledge of X , Y and T (as opp osed to the original EG ± algorithm of [9]). This v ersion relies on the automatic tuning of [11]. W e first present a generic version suited for general con vex and differentiable loss functions. The application to the square loss and to other α -losses will b e dealt with in Sections 3.2 and 3.3. The generic setting with arbitrary conv ex and differentiable loss functions corresp onds to the online con- v ex optimization setting [15, 16] and unfolds as follows: at each time t > 1, the forecaster c ho oses a linear com bination b u t ∈ R d , then the environmen t c ho oses and reveals a conv ex and differentiable loss function ` t : R d → R , and the forecaster incurs the loss ` t ( b u t ). In online linear regression under the square loss, the loss functions are giv en by ` t ( u ) = ( y t − u · x t ) 2 . 7 P arameter : radius U > 0. Initialization : p 1 = ( p + 1 , 1 , p − 1 , 1 , . . . , p + d, 1 , p − d, 1 ) , 1 / (2 d ) , . . . , 1 / (2 d ) ∈ R 2 d . A t each time round t > 1, 1. Output the linear combination b u t , U d X j =1 p + j,t − p − j,t e j ∈ B 1 ( U ); 2. Receive the loss function ` t : R d → R and up date the parameter η t +1 according to (8); 3. Up date the weigh t v ector p t +1 = ( p + 1 ,t +1 , p − 1 ,t +1 , . . . , p + d,t +1 , p − d,t +1 ) ∈ X 2 d defined for all j = 1 , . . . , d and γ ∈ { + , −} b y a p γ j,t +1 , exp − η t +1 t X s =1 γ U ∇ j ` s ( b u s ) ! X 1 6 k 6 d µ ∈{ + , −} exp − η t +1 t X s =1 µU ∇ k ` s ( b u s ) ! . a F or all γ ∈ { + , −} , by a sligh t abuse of notation, γ U denotes U or − U if γ = + or γ = − respectively . Figure 2: The adaptive EG ± algorithm for general conv ex and differen tiable loss functions (see Prop osition 1). The adaptive EG ± algorithm for general conv ex and differentiable loss functions is defined in Figure 2. W e denote b y ( e j ) 1 6 j 6 d the canonical basis of R d , b y ∇ ` t ( u ) the gradien t of ` t at u ∈ R d , and b y ∇ j ` t ( u ) the j -th comp onen t of this gradien t. The adaptive EG ± algorithm uses as a blackbox the exp onentially w eighted ma jority forecaster of [11] on 2 d exp erts — namely , the v ertices ± U e j of B 1 ( U ) — as in [9]. It adapts to the unknown gradient amplitudes k∇ ` t k ∞ b y the particular choice of η t due to [11] and defined for all t > 2 by η t = min ( 1 b E t − 1 , C s ln(2 d ) V t − 1 ) , (8) where C , q 2( √ 2 − 1) / (e − 2) and where w e set, for all t = 1 , . . . , T , z + j,s , U ∇ j ` s ( b u s ) and z − j,s , − U ∇ j ` s ( b u s ) , j = 1 , . . . , d, s = 1 , . . . , t , b E t , inf k ∈ Z 2 k : 2 k > max 1 6 s 6 t max 1 6 j,k 6 d γ ,µ ∈{ + , −} z γ j,s − z µ k,s , V t , t X s =1 X 1 6 j 6 d γ ∈{ + , −} p γ j,s z γ j,s − X 1 6 k 6 d µ ∈{ + , −} p µ k,s z µ k,s 2 . Note that b E t − 1 appro ximates the range of the z γ j,s up to time t − 1, while V t − 1 is the corresp onding cumu- lativ e v ariance of the forecaster. 8 Prop osition 1 (The adaptiv e EG ± algorithm for general con vex and differentiable loss functions) . L et U > 0 . Then, the adaptive EG ± algorithm on B 1 ( U ) define d in Figur e 2 satisfies, for al l T > 1 and al l se quenc es of c onvex and differ entiable 8 loss functions ` 1 , . . . , ` T : R d → R , T X t =1 ` t ( b u t ) − min k u k 1 6 U T X t =1 ` t ( u ) 6 4 U v u u t T X t =1 k∇ ` t ( b u t ) k 2 ∞ ! ln(2 d ) + U 8 ln(2 d ) + 12 max 1 6 t 6 T k∇ ` t ( b u t ) k ∞ . In p articular, the r e gr et is b ounde d by 4 U max 1 6 t 6 T k∇ ` t ( b u t ) k ∞ p T ln(2 d ) + 2 ln(2 d ) + 3 . Pro of: The pro of follo ws straightforw ardly from a linearization argumen t and from a regret b ound of [11] applied to appropriately chosen loss vectors. Indeed, first note that by conv exit y and differentiabilit y of ` t : R d → R for all t = 1 , . . . , T , we get that T X t =1 ` t ( b u t ) − min k u k 1 6 U T X t =1 ` t ( u ) = max k u k 1 6 U T X t =1 ` t ( b u t ) − ` t ( u ) 6 max k u k 1 6 U T X t =1 ∇ ` t ( b u t ) · ( b u t − u ) = max 1 6 j 6 d γ ∈{ + , −} T X t =1 ∇ ` t ( b u t ) · ( b u t − γ U e j ) (9) = T X t =1 X 1 6 j 6 d γ ∈{ + , −} p γ j,t γ U ∇ j ` t ( b u t ) − min 1 6 j 6 d γ ∈{ + , −} T X t =1 γ U ∇ j ` t ( b u t ) , (10) where (9) follows b y linearity of u 7→ P T t =1 ∇ ` t ( b u t ) · ( b u t − u ) on the p olytop e B 1 ( U ), and where (10) follows from the particular c hoice of b u t in Figure 2. T o conclude the pro of, note that our c hoices of the weigh t vectors p t ∈ X 2 d in Figure 2 and of the time- v arying parameter η t in (8) corresp ond to the exp onen tially weigh ted av erage forecaster of [11, Section 4.2] when it is applied to the loss v ectors U ∇ j ` t ( b u t ) , − U ∇ j ` t ( b u t ) 1 6 j 6 d ∈ R 2 d , t = 1 , . . . , T . Since at time t the co ordinates of the last loss vector lie in an in terv al of length E t 6 2 U k∇ ` t ( b u t ) k ∞ , w e get from [11, Corollary 1] that T X t =1 X 1 6 j 6 d γ ∈{± 1 } p γ j,t γ U ∇ j ` t ( b u t ) − min 1 6 j 6 d γ ∈{± 1 } T X t =1 γ U ∇ j ` t ( b u t ) 6 4 U v u u t T X t =1 k∇ ` t ( b u t ) k 2 ∞ ! ln(2 d ) + U 8 ln(2 d ) + 12 max 1 6 t 6 T k∇ ` t ( b u t ) k ∞ . Substituting the last upp er b ound in (10) concludes the pro of. 3.2. Applic ation to the squar e loss In the particular case of the square loss ` t ( u ) = ( y t − u · x t ) 2 , the gradients are giv en by ∇ ` t ( u ) = − 2( y t − u · x t ) x t for all u ∈ R d . Applying Prop osition 1, we get the following regret b ound for the adaptive EG ± algorithm. 8 Gradients can b e replaced with subgradients if the loss functions ` t : R d → R are convex but not differentiable. 9 Corollary 2 (The adaptive EG ± algorithm under the square loss) . L et U > 0 . Consider the online line ar r e gr ession setting define d in the intr o duction. Then, the adaptive EG ± algorithm (se e Figur e 2) tune d with U and applie d to the loss functions ` t : u 7→ ( y t − u · x t ) 2 satisfies, for al l individual se quenc es ( x 1 , y 1 ) , . . . , ( x T , y T ) ∈ R d × R , T X t =1 ( y t − b u t · x t ) 2 − min k u k 1 6 U T X t =1 ( y t − u · x t ) 2 6 8 U X v u u t min k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ! ln(2 d ) + 137 ln(2 d ) + 24 U X Y + U 2 X 2 6 8 U X Y p T ln(2 d ) + 137 ln(2 d ) + 24 U X Y + U 2 X 2 , wher e the quantities X , max 1 6 t 6 T k x t k ∞ and Y , max 1 6 t 6 T | y t | ar e unknown to the for e c aster. Using the terminology of [17, 11], the first b ound of Corollary 2 is an impr ovement for smal l losses : it yields a small regret when the optimal cumulativ e loss min k u k 1 6 U P T t =1 ( y t − u · x t ) 2 is small. As for the second regret b ound, it indicates that the adaptive EG ± algorithm achiev es approximately the regret b ound of Theorem 1 in the regime κ 6 1, i.e., d > √ T U X/ (2 Y ). In this regime, our algorithm th us has a manageable computational complexit y (linear in d at each time t ) and it is adaptive in X , Y , and T . In particular, the ab o ve regret bound is similar 9 to that of the original EG ± algorithm [9, Theorem 5.11], but it is obtained without prior kno wledge of X , Y , and T . Note also that this b ound is similar to that of the self-confiden t p -norm algorithm of [10] with p = 2 ln d (see Section 1.2). The fact that w e w ere able to get similar adaptivity and efficiency prop erties via exp onen tial weigh ting corrob orates the similarity that was already observ ed in a non-adaptive context b et ween the original EG ± algorithm and the p -norm algorithm (in the limit p → + ∞ with an appropriate initial weigh t vector, or for p of the order of ln d with a zero initial w eight vector, cf. [18]). Pro of (of Corollary 2): W e apply Prop osition 1 with the square loss ` t ( u ) = ( y t − u · x t ) 2 . It yields T X t =1 ` t ( b u t ) − min k u k 1 6 U T X t =1 ` t ( u ) 6 4 U v u u t T X t =1 k∇ ` t ( b u t ) k 2 ∞ ! ln(2 d ) + U 8 ln(2 d ) + 12 max 1 6 t 6 T k∇ ` t ( b u t ) k ∞ . (11) Using the equalit y ∇ ` t ( u ) = − 2( y t − u · x t ) x t for all u ∈ R d , we get that, on the one hand, by the upp er b ound k x t k ∞ 6 X , k∇ ` t ( b u t ) k 2 ∞ 6 4 X 2 ` t ( b u t ) , (12) and, on the other hand, max 1 6 t 6 T k∇ ` t ( b u t ) k ∞ 6 2( Y + U X ) X (indeed, by H¨ older’s inequality , b u t · x t 6 k b u t k 1 k x t k ∞ 6 U X ). Substituting the last tw o inequalities in (11), setting b L T , P T t =1 ` t ( b u t ) as well as L ∗ T , min k u k 1 6 U P T t =1 ` t ( u ), w e get that b L T 6 L ∗ T + 8 U X q b L T ln(2 d ) + 16 ln(2 d ) + 24 U X Y + U 2 X 2 | {z } , C . 9 By Theorem 5.11 of [9], the original EG ± algorithm satisfies the regret bound 2 U X p 2 B ln(2 d ) + 2 U 2 X 2 ln(2 d ), where B is an upp er bound on min k u k 1 6 U P T t =1 ( y t − u · x t ) 2 (in particular, B 6 T Y 2 ). Note that our main regret term is larger by a multiplicativ e factor of 2 √ 2. How ever, contrary to [9], our algorithm do es not require the prior knowledge of X and B — or, alternatively , X , Y , and T . 10 Solving for b L T via Lemma 4 in App endix B, w e get that b L T 6 L ∗ T + C + 8 U X p ln(2 d ) p L ∗ T + C + 8 U X p ln(2 d ) 2 6 L ∗ T + 8 U X q L ∗ T ln(2 d ) + 8 U X p C ln(2 d ) + 64 U 2 X 2 ln(2 d ) + C . Using that U X p C ln(2 d ) = U X ln(2 d ) q 16 + 24 / ln(2 d ) U X Y + U 2 X 2 6 p U 2 X 2 + U X Y ln(2 d ) q 16 + 24 / ln(2) U X Y + U 2 X 2 = p 16 + 24 / ln(2) U X Y + U 2 X 2 ln(2 d ) and p erforming some simple upp er b ounds concludes the pro of of the first regret b ound. The second one follo ws immediately by noting that min k u k 1 6 U P T t =1 ( y t − u · x t ) 2 6 P T t =1 y 2 t 6 T Y 2 (since 0 ∈ B 1 ( U )). 3.3. A r efinement via Lipschitzific ation of the loss function In Corollary 2 we used the adaptive EG ± algorithm in conjunction with the square loss functions ` t : u 7→ ( y t − u · x t ) 2 . In this section we use y et another instance of the adaptive EG ± algorithm ap- plied to a mo dification e ` t : R d → R of the square loss (or the α -loss, see b elo w) which is Lipsc hitz contin uous with resp ect to k·k 1 . This leads to slightly refined regret b ounds; see Theorem 3 b elow and Corollaries 3 and 4 thereafter. W e first presen t the Lipsch tizification technique; its use with the adaptive EG ± algorithm is to b e addressed in a few paragraphs. Since our analysis is generic enough to handle b oth the square loss and other loss functions with higher curv ature, we consider b elow a slightly more general setting than online linear regression stricto sensu . Namely , we fix a real num ber α > 2 and assume that the predictions b y t of the forecaster and the base linear predictions u · x t are scored with the α -loss, i.e., with the loss functions x 7→ | y t − x | α for all t > 1. The particular case of the square loss ( α = 2) is considered in Corollary 3 b elow, while loss functions with higher curv ature ( α > 2) are addressed in Corollary 4. The Lipsc hitzification pro ceeds as follows. A t each time t > 1, w e set B t , 2 d log 2 (max 1 6 s 6 t − 1 | y s | α ) e 1 /α , where d x e , min { k ∈ Z : k > x } for all x ∈ R . Note that max 1 6 s 6 t − 1 | y s | 6 B t 6 2 1 /α max 1 6 s 6 t − 1 | y s | . The mo dified (or Lipschitzifie d ) loss function e ` t : R d → R is constructed as follows: • if | y t | > B t , then e ` t ( u ) , 0 for all u ∈ R d ; • if | y t | 6 B t , then e ` t is the conv ex function that coincides with the loss function u 7→ | y t − u · x t | α when u · x t 6 B t and is linear elsewhere. An example of such function is sho wn in Figure 3 in the case where α = 2. It can b e formally defined as e ` t ( u ) , y t − u · x t α if u · x t 6 B t , y t − B t α + α y t − B t α − 1 ( u · x t − B t ) if u · x t > B t , y t + B t α − α y t + B t α − 1 ( u · x t + B t ) if u · x t < − B t . Observ e that in b oth cases | y t | > B t and | y t | 6 B t , the function e ` t is con tinuously differentiable. By construction it is also Lipsc hitz con tinuous with resp ect to k·k 1 with an easy-to-control Lipschitz constant (see App endix A.2). Another key prop erty that we can glean from Figure 3 is that, when | y t | 6 B t , the 11 mo dified loss function e ` t : R d → R lies in b et ween the α -loss function u 7→ | y t − u · x t | α and its clipp ed v ersion: ∀ u ∈ R d , y t − [ u · x t ] B t α 6 e ` t ( u ) 6 y t − u · x t α , (13) where the clipping op erator [ · ] B is defined b y [ x ] B , min B , max {− B , x } for all x ∈ R and all B > 0. −2 0 2 4 0 5 10 15 u ⋅ x t ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● y t B t − B t ● Square loss Lipschitzified Clipped Figure 3: Example with the square loss ( α = 2) when | y t | 6 B t . The square loss ( y t − u · x t ) 2 , its clipped v ersion y t − [ u · x t ] B t 2 and its Lipsc hitzified version e ` t ( u ) are plotted as a function of u · x t . Next we illustrate the Lipsc hitzification tec hnique in tro duced abov e: we apply the adaptive EG ± algo- rithm to the Lipschitzified loss functions e ` t . The resulting algorithm is called the Lipschitzifying Exp onen- tiate d Gr adient (LEG) algorithm and is formally defined in Figure 4. Recall that ( e j ) 1 6 j 6 d denotes the canonical basis of R d and that ∇ j denotes the j -th comp onen t of the gradient. W e p oint out that this technique is not sp ecific to the pair of dual norms ( k·k 1 , k·k ∞ ) and to the EG ± algorithm; it could b e used with other pairs ( k·k q , k·k p ) (with 1 /p + 1 /q = 1) and other gradient-based algorithms, such as the p -norm algorithm [18, 10] and its regularized v arian ts (SMIDAS and COMID) [19, 20]. The next theorem b ounds the cum ulative α -loss of the LEG algorithm. The pro of is p ostp oned to App endix A.2. It follows from the bound on the adaptive EG ± algorithm for general con vex and differentiable loss functions that w e deriv ed in Prop osition 1 (Section 3.1). See Corollaries 3 and 4 b elo w for regret b ounds in the particular cases of the square loss ( α = 2) or of losses with higher curv ature ( α > 2). Theorem 3. Assume that the pr e dictions ar e sc or e d with the α -loss x 7→ | y t − x | α , wher e α > 2 is a r e al numb er. L et U > 0 . Then, the LEG algorithm define d in Figur e 4 and tune d with U satisfies, for al l T > 1 and al l individual se quenc es ( x 1 , y 1 ) , . . . , ( x T , y T ) ∈ R d × R , T X t =1 | y t − b y t | α 6 inf k u k 1 6 U T X t =1 e ` t ( u ) + a α U X Y α/ 2 − 1 v u u t inf k u k 1 6 U T X t =1 e ` t ( u ) ! ln(2 d ) + a 0 α ln(2 d ) + 12 b α U X Y α − 1 + a 00 α ln(2 d ) U 2 X 2 Y α − 2 + a 000 α Y α , wher e the Lipschitzifie d loss functions e ` t ar e define d ab ove, wher e the quantities X , max 1 6 t 6 T k x t k ∞ and Y , max 1 6 t 6 T | y t | ar e unknown to the for e c aster, and wher e, setting a α , 4 α 1 + 2 1 /α α/ 2 − 1 and 12 P arameter : radius U > 0. Initialization : B 1 , 0, p 1 = ( p + 1 , 1 , p − 1 , 1 , . . . , p + d, 1 , p − d, 1 ) , 1 / (2 d ) , . . . , 1 / (2 d ) ∈ R 2 d . A t each time round t > 1, 1. Compute the linear combination b u t , U d X j =1 p + j,t − p − j,t e j ∈ B 1 ( U ); 2. Get x t ∈ R d and output the clipp ed prediction b y t , b u t · x t B t ; 3. Get y t ∈ R and define the mo dified loss function e ` t : R d → R as ab ov e; 4. Up date the parameter η t +1 according to (8); 5. Up date the weigh t v ector p t +1 = ( p + 1 ,t +1 , p − 1 ,t +1 , . . . , p + d,t +1 , p − d,t +1 ) ∈ X 2 d defined for all j = 1 , . . . , d and γ ∈ { + , −} b y a p γ j,t +1 , exp − η t +1 t X s =1 γ U ∇ j e ` s ( b u s ) ! X 1 6 k 6 d µ ∈{ + , −} exp − η t +1 t X s =1 µU ∇ k e ` s ( b u s ) ! . 6. Up date the threshold B t +1 , 2 d log 2 (max 1 6 s 6 t | y s | α ) e 1 /α . a F or all γ ∈ { + , −} , by a sligh t abuse of notation, γ U denotes U or − U if γ = + or γ = − respectively . Figure 4: The Lipschitzifying Exp onentiated Gradient (LEG) algorithm. b α , α 1 + 2 1 /α α − 1 , the c onstants a 0 α , a 00 α , a 000 α > 0 ar e define d by a 0 α , a α q b α 4 + 6 / ln 2 + 2 1 + 2 − 1 /α α/ 2 / √ ln 2 + 8 b α a 00 α , a α q b α 4 + 6 / ln 2 + a α a 000 α , 4 1 + 2 − 1 /α α . Corollary 3 (Application to the square loss) . Consider the online line ar r e gr ession setting under the squar e loss (i.e., α = 2 ). L et U > 0 . Then, the LEG algorithm define d in Figur e 4 and tune d with U satisfies, for al l T > 1 and al l individual se quenc es ( x 1 , y 1 ) , . . . , ( x T , y T ) ∈ R d × R , T X t =1 ( y t − b y t ) 2 6 inf k u k 1 6 U T X t =1 e ` t ( u ) + 8 U X v u u t inf k u k 1 6 U T X t =1 e ` t ( u ) ! ln(2 d ) + 134 ln(2 d ) + 58 U X Y + U 2 X 2 + 12 Y 2 , wher e the Lipschitzifie d loss functions e ` t ar e define d ab ove and wher e the quantities X , max 1 6 t 6 T k x t k ∞ and Y , max 1 6 t 6 T | y t | ar e unknown to the for e c aster. Note that, in the case of the square loss, the first tw o terms of the b ound of Corollary 3 sligh tly improv e on those obtained without Lipsc hitzification (cf. Corollary 2) since we alwa ys ha ve inf k u k 1 6 U T X t =1 e ` t ( u ) 6 inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 , 13 where we used the k ey prop erty e ` t ( u ) 6 ( y t − u · x t ) 2 that holds for all u ∈ R d and all t = 1 , . . . , T (by (13) if | y t | 6 B t , obvious otherwise). In particular, the LEG algorithm is adaptiv e in X , Y , and T ; it ac hieves appro ximately — and efficien tly — the regret b ound of Theorem 1 in the regime κ 6 1, i.e., d > √ T U X/ (2 Y ). In the case of α -losses with a higher curv ature than that of the square loss ( α > 2), the improv emen t is more substan tial as indicated after the following corollary . Corollary 4 (Application to α -losses with α > 2) . Assume that the pr e dictions ar e sc or e d with the α -loss x 7→ | y t − x | α , wher e α > 2 . Then, the r e gr et of the LEG algorithm on B 1 ( U ) is at most of the or der of U X Y α − 1 p T ln(2 d ) + U X Y α − 1 + U 2 X 2 Y α − 2 ln(2 d ) + Y α , wher e X , max 1 6 t 6 T k x t k ∞ and Y , max 1 6 t 6 T | y t | ar e unknown to the for e c aster. The ab ove r e gr et b ound impr oves on the b ound we would have obtaine d via a similar analysis for the adaptive EG ± algorithm applie d to the original losses ` t ( u ) = | y t − u · x t | α (without Lipschitzific ation), namely, a b ound of the or der of U X ( Y + U X ) α/ 2 − 1 Y α/ 2 p T ln(2 d ) + U X ( Y + U X ) α − 1 + U 2 X 2 ( Y + U X ) α − 2 ln(2 d ) . The main difference b etw een the tw o regret b ounds ab ov e lies in the dep endence in U : our main regret term scales as U X Y α − 1 while the one obtained without Lipsc hitzification scales as U X ( Y + U X ) α/ 2 − 1 Y α/ 2 . The first term grows linearly in U while the second one grows as U α/ 2 , hence a clear improv emen t for α > 2. The last prop erty stems from the fact that, thanks to Lipschitzification, the gradients ∇ e ` t ∞ are b ounded as U → + ∞ (cf. (A.29) in App endix A.2). Remark 1 (Another b enefit of Lipsc hitzification) . A nother b enefit of Lipschitzific ation is that al l online c onvex optimization r e gr et b ounds expr esse d in terms of the maximal dual norm of the gr adients — i.e., max 1 6 t 6 T k∇ e ` t k ∞ in our c ase — c an b e use d fruitful ly with the Lipschitzifie d loss functions e ` t . F or instanc e, in the c ase of the squar e loss, using the very last b ound of Pr op osition 1, we get that T X t =1 ( y t − b y t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 6 c 1 U X Y p T ln(2 d ) + 8 ln(2 d ) + c 2 Y 2 , wher e c 1 , 8 √ 2 + 1 and c 2 , 4 1 + 1 / √ 2 2 . The b ound is no longer an impr ovement for smal l losses (as c omp ar e d to Cor ol lary 2), but it do es not r e quir e to solve any quadr atic ine quality. The c orr esp onding simple pr o of is p ostp one d to the end of App endix A.2. 4. Adaptation to unknown U In the previous section, the forecaster is given a radius U > 0 and asked to ensure a lo w worst-case regret on the ` 1 -ball B 1 ( U ). In this section, U is no longer given: the forecaster is ask ed to b e comp etitive against all balls B 1 ( U ), for U > 0. Namely , its worst-case regret on eac h B 1 ( U ) should be almost as go o d as if U were known b eforehand. F or simplicit y , we assume that X , Y , and T are kno wn: we explain in Section 5 ho w to simultaneously adapt to all parameters. Note that from now on, w e consider again the main framew ork of this pap er, i.e., online linear regression under the square loss (cf. Section 1.1). W e define R , d log 2 (2 T /c ) e + and U r , Y X 2 r p T ln(2 d ) , for r = 0 , . . . , R , (14) 14 P arameters : X , Y , η > 0, T > 1, and c > 0 (a constant). Initialization : R = d log 2 (2 T /c ) e + , w 1 = 1 R +1 , · · · , 1 R +1 ∈ R R +1 . F or time steps t = 1 , . . . , T : 1. F or exp erts r = 0 , . . . , R : • Run the sub-algorithm A ( U r ) on the ball B 1 ( U r ) and obtain the pre- diction b y ( r ) t . 2. Output the prediction b y t = P R r =0 w ( r ) t P R r 0 =0 w ( r 0 ) t b y ( r ) t Y . 3. Up date w ( r ) t +1 = w ( r ) t exp − η y t − b y ( r ) t Y 2 for r = 0 , . . . , R . Figure 5: The Scaling algorithm. where c > 0 is a known absolute constant and d x e + , min k ∈ N : k > x for all x ∈ R . The Scaling algorithm of Figure 5 w orks as follo ws. W e hav e access to a sub-algorithm A ( U ) which we run sim ultaneously for all U = U r , r = 0 , . . . , R . Eac h instance of the sub-algorithm A ( U r ) p erforms online linear regression on the ` 1 -ball B 1 ( U r ). W e employ an exp onen tially w eighted forecaster to aggregate these R + 1 sub-algorithms to p erform online linear regression simultaneously on the balls B 1 ( U 0 ) , . . . , B 1 ( U R ). The follo wing regret b ound follows by exp-concavit y of the square loss. Theorem 4. Supp ose that X , Y > 0 ar e known. L et c, c 0 > 0 b e two absolute c onstants. Supp ose that for al l U > 0 , we have ac c ess to a sub-algorithm A ( U ) with r e gr et against B 1 ( U ) of at most cU X Y p T ln(2 d ) + c 0 Y 2 for T > T 0 , (15) uniformly over al l se quenc es ( x t ) and ( y t ) b ounde d by X and Y . Then, for a known T > T 0 , the Sc aling algorithm with η = 1 / (8 Y 2 ) satisfies T X t =1 ( y t − b y t ) 2 6 inf u ∈ R d ( T X t =1 ( y t − u · x t ) 2 + 2 c k u k 1 X Y p T ln(2 d ) ) + 8 Y 2 ln d log 2 (2 T /c ) e + + 1 + ( c + c 0 ) Y 2 . (16) In p articular, for every U > 0 , T X t =1 ( y t − b y t ) 2 6 inf u ∈ B 1 ( U ) ( T X t =1 ( y t − u · x t ) 2 ) + 2 cU X Y p T ln(2 d ) + 8 Y 2 ln d log 2 (2 T /c ) e + + 1 + ( c + c 0 ) Y 2 . Remark 2. By R emark 1 the LEG algorithm satisfies assumption (15) with T 0 = ln(2 d ) , c , 9 c 1 = 72 √ 2 + 1 , and c 0 , c 2 = 4 1 + 1 / √ 2 2 . Pro of: Since the Scaling algorithm is an exp onentially weigh ted av erage forecaster (with clipping) applied 15 to the R + 1 exp erts A ( U r ) = b y ( r ) t t > 1 , r = 0 , . . . , R , we hav e, by Lemma 6 in App endix B, T X t =1 ( y t − b y t ) 2 6 min r =0 ,...,R T X t =1 b y ( r ) t − b y t 2 + 8 Y 2 ln( R + 1) 6 min r =0 ,...,R ( inf u ∈ B 1 ( U r ) ( T X t =1 ( y t − u · x t ) 2 ) + cU r X Y p T ln(2 d ) ) + z , (17) where the last inequalit y follows by assumption (15), and where we set z , 8 Y 2 ln( R + 1) + c 0 Y 2 . Let u ∗ T ∈ arg min u ∈ R d n P T t =1 ( y t − u · x t ) 2 + 2 c k u k 1 X Y p T ln(2 d ) o . Next, we pro ceed by considering three cases: U 0 < k u ∗ T k 1 < U R , k u ∗ T k 1 6 U 0 , and k u ∗ T k 1 > U R . Case 1 : U 0 < k u ∗ T k 1 < U R . Le t r ∗ , min r = 0 , . . . , R : U r > k u ∗ T k 1 . Note that r ∗ > 1 since k u ∗ T k 1 > U 0 . By (17) w e hav e T X t =1 ( y t − b y t ) 2 6 inf u ∈ B 1 ( U r ∗ ) ( T X t =1 ( y t − u · x t ) 2 ) + cU r ∗ X Y p T ln(2 d ) + z 6 T X t =1 ( y t − u ∗ T · x t ) 2 + 2 c k u ∗ T k 1 X Y p T ln(2 d ) + z , where the last inequality follows from u ∗ T ∈ B 1 ( U r ∗ ) and from the fact that U r ∗ 6 2 k u ∗ T k 1 (since, by defini- tion of r ∗ , k u ∗ T k 1 > U r ∗ − 1 = U r ∗ / 2). Finally , w e obtain (16) b y definition of u ∗ T and z , 8 Y 2 ln( R + 1) + c 0 Y 2 . Case 2 : k u ∗ T k 1 6 U 0 . By (17) we ha ve T X t =1 ( y t − b y t ) 2 6 ( T X t =1 ( y t − u ∗ T · x t ) 2 + cU 0 X Y p T ln(2 d ) ) + z , (18) whic h yields (16) by the equality cU 0 X Y p T ln(2 d ) = cY 2 (b y definition of U 0 ), by adding the nonnegative quan tity 2 c k u ∗ T k 1 X Y p T ln(2 d ), and by definition of u ∗ T and z . Case 3 : k u ∗ T k 1 > U R . By construction, we hav e b y t ∈ [ − Y , Y ], and by assumption, w e hav e y t ∈ [ − Y , Y ], so that T X t =1 ( y t − b y t ) 2 6 4 Y 2 T 6 T X t =1 ( y t − u ∗ T · x t ) 2 + 2 cU R X Y p T ln(2 d ) 6 T X t =1 ( y t − u ∗ T · x t ) 2 + 2 c k u ∗ T k 1 X Y p T ln(2 d ) , where the second inequalit y follo ws b y 2 cU R X Y p T ln(2 d ) = 2 cY 2 2 R > 4 Y 2 T (since 2 R > 2 T /c by definition of R ), and the last inequality uses the assumption k u ∗ T k 1 > U R . W e finally get (16) by definition of u ∗ T . This concludes the pro of of the first claim (16). The second claim follows by b ounding k u k 1 6 U . 16 5. Extension to a fully adaptive algorithm The Scaling algorithm of Section 4 uses prior knowledge of Y , Y /X , and T . In order to obtain a fully automatic algorithm, w e need to adapt efficiently to these quantities. Adaptation to Y is p ossible via a tec hnique already used for the LEG algorithm, i.e., b y up dating the clipping range B t based on the past observ ations | y s | , s 6 t − 1. In parallel to adapting to Y , adaptation to Y /X can be carried out as follo ws. W e replace the exp onential sequence { U 0 , . . . , U R } b y another exp onential sequence { U 0 0 , . . . , U 0 R 0 } : U 0 r , 1 T k 2 r p T ln(2 d ) , r = 0 , . . . , R 0 , (19) where R 0 , R + log 2 T 2 k = d log 2 (2 T /c ) e + + log 2 T 2 k , and where k > 1 is a fixed constan t. On the one hand, for T > T 0 , max ( X/ Y ) 1 /k , ( Y /X ) 1 /k , w e hav e (cf. (14) and (19)), [ U 0 , U R ] ⊂ [ U 0 0 , U 0 R 0 ] . Therefore, the analysis of Theorem 4 applied to the grid { U 0 0 , . . . , U R 0 } yields 10 a regret b ound of the order of U X Y √ T ln d + Y 2 ln( R 0 + 1). On the other hand, clipping the predictions to [ − Y , Y ] ensures the crude regret b ound 4 Y 2 T 0 for small T < T 0 . Hence, the ov erall regret for all T > 1 is of the order of U X Y √ T ln d + Y 2 ln( k ln T ) + Y 2 max ( X/ Y ) 1 /k , ( Y /X ) 1 /k . Adaptation to an unknown time horizon T can b e carried out via a standard doubling trick on T . Ho wev er, to a void restarting the algorithm rep eatedly , we can use a time-v arying exp onential sequence { U 0 − R 0 ( t ) ( t ) , . . . , U 0 R 0 ( t ) ( t ) } where R 0 ( t ) grows at the rate of k ln( t ). This gives 11 us an algorithm that is fully automatic in the parameters U , X , Y and T . In this case, we can show that the regret is of the order of U X Y √ T ln d + Y 2 k ln( T ) + Y 2 max n √ T X/ Y 1 /k , Y / ( √ T X ) 1 /k o , where the last t wo terms are negligible when T → + ∞ (since k > 1). Ac kno wledgments The authors would like to thank Gilles Stoltz for his v aluable commen ts and suggestions, as well as t wo anon ymous reviewers for their insightful feedbac k. This work was supp orted in part by F renc h National Researc h Agency (ANR, pro ject EXPLO-RA, ANR-08-COSI-004) and the P ASCAL2 Net w ork of Excellence under EC gran t no. 216886. J. Y. Y u was partly supp orted b y a fello wship from Le F onds qu ´ eb ´ ecois de la rec herche sur la nature et les technologies. An extended abstract of the presen t paper app eared in the Pr o c e e dings of the 22nd International Con- fer enc e on A lgorithmic L e arning The ory (AL T’11) . App endix A. Proofs App endix A.1. Pr o of of The or em 2 T o prov e Theorem 2, we p erform a reduction to the sto chastic batch setting (via the standard online to batc h trick), and employ a version of the low er b ound prov ed in [2] for conv ex aggregation. 10 The pro of remains the same by replacing 8 Y 2 ln( R + 1) with 8 Y 2 ln( R 0 + 1). 11 Each time the exp onential sequence ( U 0 r ) expands, the weights assigned to the existing p oints U 0 r are appropriately reassigned to the whole new sequence. 17 W e first need the follo wing notations. Let T ∈ N ∗ . Let ( S, µ ) b e a probabilit y space for which we can find an orthonormal family 12 ( ϕ j ) 1 6 j 6 d with d elements in the space of square-integrable functions on S , which w e denote by L 2 ( S, µ ) thereafter. F or all u ∈ R d and γ , σ > 0, denote by P γ ,σ u the join t law of the i.i.d. sequence ( X t , Y t ) 1 6 t 6 T suc h that Y t = γ ϕ u ( X t ) + σ ε t ∈ R , (A.1) where ϕ u , P d j =1 u j ϕ j , where the X t are i.i.d p oints in S dra wn from µ , and where the ε t are i.i.d standard Gaussian random v ariables such that ( X t ) 1 6 t 6 T and ( ε t ) 1 6 t 6 T are indep enden t. The next lemma is a direct adaptation of [2, Theorem 2], which we state with our notations in a slightly more precise form (w e make clear ho w the lo wer b ound dep ends on the noise level σ and the signal level γ ). Lemma 1 (An extension of Theorem 2 of [2]) . L et d, T ∈ N ∗ and γ , σ > 0 . L et ( S, µ ) b e a pr ob ability sp ac e for which we c an find an orthonormal family ( ϕ j ) 1 6 j 6 d in L 2 ( S, µ ) , and c onsider the Gaussian line ar mo del (A.1) . Then ther e exist absolute c onstants c 4 , c 5 , c 6 , c 7 > 0 such that inf b f T sup u ∈ R d + P j u j 6 1 ( E P γ ,σ u b f T − γ ϕ u 2 µ ) > c 4 dσ 2 T if d √ T 6 c 5 γ σ , c 6 γ σ r 1 T ln 1 + dσ √ T γ if c 5 γ σ < d √ T 6 c 7 γ d σ √ ln(1+ d ) , wher e the infimum is taken over al l estimators 13 b f T : S → R , wher e the supr emum is taken over al l nonne gative ve ctors with total mass at most 1 , and wher e k f k 2 µ , R S f ( x ) 2 µ (d x ) for al l me asur able functions f : S → R . Note that the low er b ound we stated in Theorem 2 is very similar to T times the ab ov e low er b ound with γ ∼ X and σ ∼ Y (recall that κ , √ T U X/ (2 d Y )). The main difference is that the latter holds for un b ounded observ ations, while we need b ounded observ ations y t , 1 6 t 6 T . A simple concentration argumen t will show that these observ ations lie in [ − Y , Y ] with high probabilit y , whic h will yield the desired lo wer b ound. The pro of of Theorem 2 thus consists of the following steps: • step 1: reduction to the sto chastic batch setting; • step 2: application of Lemma 1; • step 3: concentration argument. Pro of (of Theorem 2): W e first assume that p ln(1 + 2 d ) / 2 d √ ln 2 6 κ 6 1. The case when κ > 1 will easily follo w from the monotonicity of the minimax regret in κ (see the end of the pro of ). W e set T , 1 + (4 dκ ) 2 , U , 1 , and X , 2 dκY √ T , (A.2) so that T > 2, √ T U X/ (2 d Y ) = κ , and X 6 Y / 2 (since √ T > 4 dκ ). 12 An example is given by S = [ − π , π ], µ (d x ) = d x/ (2 π ), and ϕ j ( x ) = √ 2 sin( j x ) for all 1 6 j 6 d and x ∈ [ − π , π ]. W e will use this particular case later. 13 As usual, an estimator is a measurable function of the sample ( X t , Y t ) 1 6 t 6 T , but the dep endency on the sample is omitted. 18 Step 1 : reduction to the sto chastic batch setting. First note that b y clipping to [ − Y , Y ], we hav e inf ( e f t ) t sup k x t k ∞ 6 X | y t | 6 Y ( T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) = inf ( e f t ) t | e f t | 6 Y sup k x t k ∞ 6 X | y t | 6 Y ( T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) , (A.3) where the first infim um is taken ov er all online forecasters 14 ( e f t ) t , where the second infimum is restricted to online forecasters ( e f t ) t whic h output predictions in [ − Y , Y ], and where b oth suprema are taken ov er all individual sequences ( x t , y t ) 1 6 t 6 T ∈ ( R d × R ) T suc h that | y 1 | , . . . , | y T | 6 Y and k x 1 k ∞ , . . . , k x T k ∞ 6 X . Next we use the standard online to batch conv ersion to bound from b elow the righ t-hand side of (A.3) b y T times the lo wer b ound of Lemma 1, which we apply to the particular case where S = [ − π , π ], where µ (d x ) = d x/ (2 π ), and where ϕ j ( x ) = √ 2 sin( j x ) for all 1 6 j 6 d and x ∈ [ − π , π ]. Let γ , c 8 X and σ , c 9 Y √ ln T , (A.4) for some absolute constan ts c 8 , c 9 > 0 to b e chosen by the analysis. Let ( e f t ) t > 1 b e an y online forecaster whose predictions lie in [ − Y , Y ], and consider the estimator b f T defined for eac h sample ( X t , Y t ) 1 6 t 6 T and eac h new input X 0 b y b f T X 0 ; ( X t , Y t ) 1 6 t 6 T , 1 T T X t =1 e f t γ ϕ ( X 0 ); ( γ ϕ ( X s ) , Y s ) 1 6 s 6 t − 1 , (A.5) where ϕ , ( ϕ 1 , . . . , ϕ d ), and where w e explicitely wrote all the dep endencies 14 of the e f t , t = 1 , . . . , T . T ak e u ∗ ∈ R d + ac hieving the supremum 15 in Lemma 1 for the estimator b f T . Note that k u ∗ k 1 6 1. Besides, consider the i.i.d. random sequence ( x t , y t ) 1 6 t 6 T in R d × R defined for all t = 1 , . . . , T b y x t , γ ϕ 1 ( X t ) , . . . , γ ϕ d ( X t ) and y t , γ ϕ u ∗ ( X t ) + σ ε t , (A.6) where ϕ u ∗ , P d j =1 u ∗ j ϕ j (so that y t = u ∗ · x t + σ ε t for all t ), where the X t are i.i.d points in [ − π , π ] dra wn from the uniform distribution µ (d x ) = d x/ (2 π ), and where the ε t are i.i.d standard Gaussian random v ariables such that ( X t ) t and ( ε t ) t are indep endent. All the exp ectations b elow are thus taken with resp ect to the probabilit y distribution P γ ,σ u ∗ . By standard manipulations (e.g., using the to w er rule and Jensen’s inequalit y), w e get the follo wing lo w er b ound. A detailed pro of can b e found after the pro of of the present theorem (page 24). Lemma 2 (Reduction to the batc h setting) . With ( e f t ) 1 6 t 6 T , b f T , and u ∗ define d ab ove, we have E " T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 1 T X t =1 y t − u · x t 2 # > T E b f T − γ ϕ u ∗ 2 µ . 14 Recall that an online forecaster is a sequence of functions ( e f t ) t > 1 , where e f t : R d × ( R d × R ) t − 1 → R maps at time t the new input x t and the past data ( x s , y s ) 1 6 s 6 t − 1 to a prediction e f t x t ; ( x s , y s ) 1 6 s 6 t − 1 . How ev er, unless mentioned otherwise, w e omit the dependency in ( x s , y s ) 1 6 s 6 t − 1 , and only write e f t ( x t ). 15 If the supremum in Lemma 1 is not achieved, then w e can instead take an ε -almost-maximizer for any ε > 0. Letting ε → 0 in the end will conclude the pro of. 19 Step 2 : application of Lemma 1. Next w e use Lemma 1 to prov e that, for some absolute constan ts c 9 , c 11 > 0, T E b f T − γ ϕ u ∗ 2 µ > c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . (A.7) By Lemma 1 and b y definition of u ∗ , w e hav e E b f T − γ ϕ u ∗ 2 µ > c 4 dσ 2 T if d √ T 6 c 5 γ σ , c 6 γ σ r 1 T ln 1 + dσ √ T γ if c 5 γ σ < d √ T 6 c 7 γ d σ √ ln(1+ d ) . > c 4 c 2 9 T (ln T ) d Y 2 if d √ T 6 c 5 γ σ , c 6 c 8 c 9 √ ln T U X Y s 1 T ln 1 + c 9 d Y c 8 √ T (ln T ) U X if c 5 γ σ < d √ T 6 c 7 γ d σ √ ln(1+ d ) , (A.8) where the last inequalit y follows from (A.4) and from U = 1. The ab o ve low er bound is only meaningful if the following condition holds true: d √ T 6 c 7 γ d σ p ln(1 + d ) . (A.9) But, b y definition of T , 1 + (4 dκ ) 2 and b y the assumption p ln(1 + 2 d ) / 2 d √ ln 2 6 κ , elemen tary manip- ulations show that (A.9) actually holds true whenever 16 c 9 6 c 7 c 8 c 10 , where c 10 , 1 2 inf x > 2 √ ln 3 ln 2 x √ 1+ d x 2 e (note that c 10 > 0). Therefore, if c 9 6 c 7 c 8 c 10 , then (A.8) en tails that E b f T − γ ϕ u ∗ 2 µ > min c 4 c 2 9 T (ln T ) d Y 2 , c 6 c 8 c 9 √ ln T U X Y v u u t 1 T ln 1 + c 9 d Y c 8 p T (ln T ) U X ! . (A.10) Moreo ver, note that if c 9 6 c 8 2 √ ln 2, then c 8 > c 9 / (2 √ ln 2) > c 9 / (2 √ ln T ). In this case, since x 7→ x p ln(1 + A/x ) is nondecreasing on R ∗ + for all A > 0, we can replace c 8 with c 9 / (2 √ ln T ) in the next expression and get c 6 c 8 c 9 √ ln T U X Y v u u t 1 T ln 1 + c 9 d Y c 8 p T (ln T ) U X ! > c 6 c 2 9 2 ln T U X Y s 1 T ln 1 + 2 d Y √ T U X = c 6 c 2 9 T (ln T ) d Y 2 κ p ln(1 + 1 /κ ) , where w e used the definition of κ , √ T U X/ (2 d Y ). In the sequel w e will choose the absolute constants c 8 and c 9 suc h that c 9 6 c 7 c 8 c 10 and c 9 6 c 8 2 √ ln 2 . (A.11) 16 By definition of γ and σ , (A.9) is equivalen t to T ln T > c 2 9 / ( c 2 7 c 2 8 )( Y /X ) 2 ln(1 + d ). But by definition of X and by the assumption κ > p ln(1 + 2 d ) / (2 d √ ln 2), we hav e Y /X 6 1 /c 10 . Therefore, (A.9) is implied b y T ln T > c 2 9 / ( c 2 7 c 2 8 c 2 10 ) ln(1 + d ), which in turn is implied by the condition c 9 6 c 7 c 8 c 10 (by definition of T ). 20 Therefore, b y the abov e remarks, b y the fact that ln T , ln 1 + d (4 dκ ) 2 e 6 ln 2 + 16 d 2 (since κ 6 1 b y assumption), and m ultiplying b oth sides of (A.10) by T , we get T E b f T − γ ϕ u ∗ 2 µ > min ( c 4 c 2 9 ln 2 + 16 d 2 d Y 2 , c 6 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) ) > c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) , where w e set c 11 , min c 4 / √ ln 2 , c 6 , and where we used the fact that x 7→ x p ln(1 + 1 /x ) is nondecreasing on R ∗ + , so that its v alue at x = κ 6 1 is smaller than √ ln 2. This concludes the pro of of (A.7). Com bining Lemma 2 and (A.7), we get E " T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 1 T X t =1 y t − u · x t 2 # > c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . (A.12) Step 3 : concen tration argumen t. A t this stage it would b e tempting to conclude by using (A.12) that since the exp ectation is low er b ounded, then there is at least one individual sequence with the same low er bound. How ev er, we ha ve no boundedness guaran tee ab out such individual sequence since the random observ ations y t lie outside of [ − Y , Y ] with p ositiv e probability . Next w e prov e that the probability of the ev en t A , T \ t =1 | y t | 6 Y is actually close to 1, and that E " I A T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 1 T X t =1 y t − u · x t 2 !# > 1 2 c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . (A.13) (Note a missing factor of 2 betw een (A.12) and (A.13).) The last low er b ound will then enable us to conclude the pro of of this theorem. Set b L T , P T t =1 y t − e f t ( x t ) 2 and L T ( u ) , P T t =1 y t − u · x t 2 for all u ∈ R d . Denote by A c the complement of A , and b y I A and I A c the corresp onding indicator functions. By the equality I A = 1 − I A c , w e hav e E I A b L T − inf k u k 1 6 1 L T ( u ) = E b L T − inf k u k 1 6 1 L T ( u ) − E I A c b L T − inf k u k 1 6 1 L T ( u ) > c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) − E h I A c b L T i , (A.14) where the last inequality follo ws by (A.12) and by the fact that L T ( u ) > 0 for all u ∈ R d . The rest of the pro of is dedicated to upp er b ounding the ab ov e quantit y E I A c b L T b y half the term on its left. This wa y , w e will hav e pro ved (A.13). 21 First note that E h I A c b L T i , E " I A c T X t =1 y t − e f t ( x t ) 2 # 6 E " I A c T X t =1 4 Y 2 I {| y t | 6 Y } + y t − e f t ( x t ) 2 I {| y t | >Y } # (A.15) 6 4 T Y 2 P A c + T X t =1 E h y t − e f t ( x t ) 2 I { | ε t | > Y 2 σ } i , (A.16) where (A.15) follows from the fact that the online forecaster ( e f t ) t outputs its predictions in [ − Y , Y ]. As for (A.16), note by definition of y t that | y t | 6 k u ∗ k 1 γ k ϕ ( X t ) k ∞ + σ | ε t | 6 γ √ 2 + σ | ε t | since k u ∗ k 1 6 1 and | ϕ j ( x ) | , | √ 2 sin( j x ) | 6 √ 2 for all j = 1 , . . . , d and x ∈ R . Therefore, by definition of γ , c 8 X , and since X 6 Y / 2 (by definition of X ), we get | y t | 6 c 8 √ 2 Y / 2 + σ | ε t | 6 Y / 2 + σ | ε t | pro vided that c 8 6 1 √ 2 , (A.17) whic h we assume thereafter. The ab o ve remarks sho w that {| y t | > Y } ⊂ {| ε t | > Y / (2 σ ) } , which entails (A.16). By the same comments and since | e f t | 6 Y , w e hav e, for all t = 1 , . . . , T , E h y t − e f t ( x t ) 2 I { | ε t | > Y 2 σ } i 6 E h Y / 2 + σ | ε t | + Y 2 I { | ε t | > Y 2 σ } i 6 2 3 Y 2 2 P | ε t | > Y 2 σ + 2 σ 2 E h ε 2 t I { | ε t | > Y 2 σ } i (A.18) 6 9 Y 2 2 P | ε t | > Y 2 σ + 2 σ 2 √ 3 P 1 / 2 | ε t | > Y 2 σ (A.19) 6 9 Y 2 T − 1 / (8 c 2 9 ) + 2 c 2 9 Y 2 ln 2 √ 6 T − 1 / (16 c 2 9 ) , (A.20) where w e used the following arguments. Inequalit y (A.18) follows by the elemen tary inequalit y ( a + b ) 2 6 2( a 2 + b 2 ) for all a, b ∈ R . T o get (A.19) we used the Cauch y-Sc hw arz inequality and the fact that E ε 4 t = 3 (since ε t is a standard Gaussian random v ariable). Finally , (A.20) follows by definition of σ , c 9 Y / √ ln T 6 c 9 Y / √ ln 2 and from the fact that, since ε t is a standard Gaussian random v ariable 17 , P | ε t | > Y 2 σ 6 2 e − 1 2 ( Y 2 σ ) 2 = 2 e − 1 2 √ ln T 2 c 9 2 = 2 T − 1 / (8 c 2 9 ) . Using the fact that P A c 6 P T t =1 P | y t | > Y 6 P T t =1 P | ε t | > Y / (2 σ ) 6 2 T 1 − 1 / (8 c 2 9 ) b y the inequality ab o ve and substituting (A.20) in (A.16), we get E h I A c b L T i 6 8 Y 2 T 2 − 1 / (8 c 2 9 ) + 9 Y 2 T 1 − 1 / (8 c 2 9 ) + 2 c 2 9 √ 6 ln 2 Y 2 T 1 − 1 / (16 c 2 9 ) 6 8 Y 2 2 2 − 1 / (8 c 2 9 ) + 9 Y 2 2 1 − 1 / (8 c 2 9 ) + 2 c 2 9 √ 6 ln 2 Y 2 2 1 − 1 / (16 c 2 9 ) , (A.21) where the last inequality follows from the fact that T α 6 2 α for all α < 0 (since T > 2) and from a c hoice of c 9 suc h that c 9 < 1 / 4 (which we assume thereafter). 17 W e use a standard deviation inequality for subgaussian random v ariables; see, e.g., [21, Equation (2.5)] with σ 2 = 1. 22 In order to further upp er b ound E I A c b L T , we use the following technical lemma, whic h is prov ed after the pro of of the present theorem (see page 24). It relies on the following elemen tary argumen t: since d κ is large enough and since the left-hand side of the next inequality (Lemma 3) decreases exp onen tially fast as c 9 → 0, then this inequalit y holds true for all c 9 > 0 small enough. Lemma 3. Ther e exists an absolute c onstant c 13 > 0 such that, for al l c 9 ∈ (0 , c 13 ) , 8 Y 2 2 2 − 1 / (8 c 2 9 ) + 9 Y 2 2 1 − 1 / (8 c 2 9 ) + 2 c 2 9 √ 6 ln 2 Y 2 2 1 − 1 / (16 c 2 9 ) 6 1 2 c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . W e can now fix the v alues of the constants c 8 and c 9 and conclude the pro of. Cho osing c 9 and c 8 , max c 9 / (2 √ ln 2) , c 9 / ( c 7 c 10 ) suc h that c 8 < 1 / √ 2 (condition (A.17)), c 9 < 1 / 4, and c 9 < c 13 , then the condition (A.11) also holds, and (A.21) com bined with Lemma 3 entails that E h I A c b L T i 6 1 2 c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . Substituting the last inequalit y in (A.14), we get that E I A b L T − inf k u k 1 6 1 L T ( u ) > 1 2 c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . By the ab ov e low er b ound and the fact that, P γ ,σ u ∗ -almost surely , k x t k ∞ 6 γ √ 2 6 X for all t = 1 , . . . , T (since γ , c 8 X and c 8 6 1 / √ 2), w e get that sup k x 1 k ∞ ,..., k x T k ∞ 6 X y 1 ,...,y T ∈ R I A b L T − inf k u k 1 6 1 L T ( u ) > 1 2 c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . Therefore, b y definition of A , T T t =1 | y t | 6 Y , of b L T , P T t =1 y t − e f t ( x t ) 2 , and of L T ( u ) , P T t =1 ( y t − u · x t ) 2 , w e get that, for all online forecasters ( e f t ) t > 1 whose predictions lie in [ − Y , Y ], sup k x 1 k ∞ ,..., k x T k ∞ 6 X | y 1 | ,..., | y T | 6 Y ( T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) > 1 2 c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) . Com bining the last low er b ound with (A.3) and setting c 1 , c 11 c 2 9 / 2 concludes the pro of under the assump- tion p ln(1 + 2 d ) / 2 d √ ln 2 6 κ 6 1. Assume no w that κ > 1. The stated low er b ound follows from the case when κ = 1 and by monotonicit y of the minimax regret in κ (when d and Y are kept constan t). More formally , by the first part of this pro of (when κ = 1), we can fix T > 1, U 1 > 0, and X > 0 suc h that √ T U 1 X/ (2 d Y ) = 1 and inf ( e f t ) t sup k x t k ∞ 6 X | y t | 6 Y ( T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 U 1 T X t =1 ( y t − u · x t ) 2 ) > c 1 ln 2 + 16 d 2 d Y 2 √ ln 2 , where the infimum is taken ov er all online forecasters ( e f t ) t > 1 , and where the suprem um is taken ov er all individual sequences b ounded b y X and Y . 23 No w take κ > 1, and set U , κU 1 > U 1 , so that √ T U X/ (2 d Y ) = κ (since √ T U 1 X/ (2 d Y ) = 1). Moreo ver, for all individual sequences b ounded b y X and Y , the regret on B 1 ( U ) is at least as large as the regret on B 1 ( U 1 ) (since U > U 1 ). Combining the latter remark with the low er b ound ab o ve and setting c 2 , c 1 √ ln 2 concludes the pro of. Pro of (of Lemma 2): W e use the same notations as in Step 1 of the pro of of Theorem 2. Let ( X 0 , y 0 ) b e a random cop y of ( X 1 , y 1 ) indep enden t of the sample ( X t , y t ) 1 6 t 6 T , and define the random vector x 0 , γ ϕ 1 ( X 0 ) , . . . , γ ϕ d ( X 0 ) . By the tow er rule, w e hav e E ( y t − e f t ( x t ) 2 = E h E ( y t − e f t ( x t )) 2 ( x s , y s ) s 6 t − 1 i = E ( y 0 − e f t ( x 0 ) 2 , where we used the fact that e f t is built on the past data ( x s , y s ) s 6 t − 1 and that ( x 0 , y 0 ) and ( x t , y t ) are b oth indep enden t of ( x s , y s ) s 6 t − 1 and are iden tically distributed. Similarly E ( y t − u · x t ) 2 = E ( y 0 − u · x 0 ) 2 . Using the last equalities and the fact that E inf { . . . } 6 inf E { . . . } , w e get E " T X t =1 y t − e f t ( x t ) 2 − inf k u k 1 6 1 T X t =1 y t − u · x t 2 # > T 1 T T X t =1 E h y 0 − e f t ( x 0 ) 2 i − inf k u k 1 6 1 E h y 0 − u · x 0 2 i ! > T E h y 0 − b f T ( X 0 ) 2 i − inf k u k 1 6 1 E h y 0 − u · x 0 2 i (A.22) = T E h γ ϕ u ∗ ( X 0 ) − b f T ( X 0 ) 2 i (A.23) = T E b f T − γ ϕ u ∗ 2 µ . Inequalit y (A.22) follows by definition of b f T , T − 1 P T t =1 e f t (see (A.5)) and by Jensen’s inequality . As for Inequalit y (A.23), it follows by expanding the square y 0 − b f T ( X 0 ) 2 = γ ϕ u ∗ ( X 0 ) − b f T ( X 0 ) + y 0 − γ ϕ u ∗ ( X 0 ) 2 , b y noting that E y 0 − γ ϕ u ∗ ( X 0 ) X 0 = 0 (via (A.6)) and b y the fact that inf k u k 1 6 1 E h y 0 − u · x 0 2 i = E h y 0 − γ ϕ u ∗ ( X 0 ) 2 i , where w e used k u ∗ k 1 6 1 (by definition of u ∗ ) and u · x 0 = γ ϕ u ( X 0 ). This concludes the pro of. Pro of (of Lemma 3): W e use the same notations and assumptions as in the pro of of Theorem 2. Since the function x 7→ x p ln(1 + 1 /x ) is nondecreasing on R ∗ + and since κ > κ min , p ln(1 + 2 d ) / (2 d √ ln 2) by assumption, w e hav e c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ p ln(1 + 1 /κ ) > c 11 c 2 9 ln 2 + 16 d 2 d Y 2 κ min p ln(1 + 1 /κ min ) = c 11 c 2 9 2 √ ln 2 Y 2 p ln(1 + 2 d ) r ln h 1 + 2 d √ ln 2 / p ln(1 + 2 d ) i ln 2 + 16 d 2 (A.24) > c 11 c 2 9 2 √ ln 2 Y 2 c 12 , (A.25) 24 where c 12 denotes the infim um of the last fraction of (A.24) ov er all d > 1; in particular, c 12 > 0. It is now easy to see that by choosing the absolute constant c 13 > 0 small enough (where c 13 can b e expressed in terms of c 11 and c 12 ), w e hav e, for all c 9 ∈ (0 , c 13 ), 8 · 2 2 − 1 / (8 c 2 9 ) + 9 · 2 1 − 1 / (8 c 2 9 ) + 2 c 2 9 √ 6 ln 2 2 1 − 1 / (16 c 2 9 ) 6 c 11 c 2 9 2 √ ln 2 c 12 . Multiplying b oth sides of the last inequalit y by Y 2 and com bining it with (A.25) concludes the pro of. App endix A.2. Pr o ofs of The or em 3 and R emark 1 Pro of (of Theorem 3): The proof follo ws directly from P rop osition 1 and from the fact that the Lipsc hitz- ified losses are larger than their clipp ed versions. Indeed, first note that, b y definition of b y t and B t +1 > | y t | , w e hav e T X t =1 | y t − b y t | α 6 T X t =1 t : | y t | 6 B t y t − b u t · x t B t α + T X t =1 t : | y t | >B t ( B t +1 + B t ) α 6 T X t =1 t : | y t | 6 B t e ` t ( b u t ) + 1 + 2 − 1 /α α T X t =1 t : B t +1 >B t B α t +1 6 T X t =1 e ` t ( b u t ) + 4 1 + 2 − 1 /α α Y α , (A.26) where the second inequalit y follows from the fact that: • if | y t | 6 B t then | y t − [ b u t · x t ] B t | α 6 e ` t ( b u t ) b y Eq. (13); • if | y t | > B t , which is equiv alen t to B t +1 > B t b y definition of B t +1 , then B t 6 B t +1 / 2 1 /α , so that B t +1 + B t 6 1 + 2 − 1 /α B t +1 . As for the third inequality ab ov e, we used the non-negativit y of e ` t ( b u t ) and upp er b ounded the geometric sum P T t : B t +1 >B t B α t +1 in the same w ay as in [11, Theorem 6], i.e., setting K , log 2 max 1 6 t 6 T | y t | α , T X t : B t +1 >B t B α t +1 6 K X k = −∞ 2 k = 2 K +1 6 4 Y α . T o b ound (A.26) further from ab ov e, we now use the fact that, by construction, the LEG algorithm is the adaptiv e EG ± algorithm applied to the mo dified loss functions e ` t . Therefore, w e get from Prop osition 1 that T X t =1 e ` t ( b u t ) 6 inf k u k 1 6 U T X t =1 e ` t ( u ) + 4 U v u u t T X t =1 w w w ∇ e ` t ( b u t ) w w w 2 ∞ ! ln(2 d ) + U 8 ln(2 d ) + 12 max 1 6 t 6 T w w w ∇ e ` t ( b u t ) w w w ∞ . (A.27) W e can now follow the same lines as in Corollary 2, except that we use the particular shap e of the Lip- sc hitzified losses. W e first derive some prop erties of the gradients ∇ e ` t . Observe from the definition of e ` t in Section 3.3 that in b oth cases | y t | > B t and | y t | 6 B t , the function e ` t is contin uously differen tiable. Moreo ver, if | y t | 6 B t , then ∀ u ∈ R d , ∇ e ` t ( u ) = − α sgn y t − [ u · x t ] B t | y t − [ u · x t ] B t | α − 1 x t , 25 where for all x ∈ R , the quantit y sgn( x ) equals 1 (resp. − 1, 0) if x > 0 (resp. x < 0, x = 0). Therefore, in both cases | y t | > B t and | y t | 6 B t , the function e ` t is Lipschitz contin uous with resp ect to k·k 1 with Lipsc hitz constant sup u ∈ R d ∇ e ` t ∞ b ounded as follo ws: for all u ∈ R d , ∇ e ` t ( u ) ∞ 6 α | y t − [ u · x t ] B t | α − 1 k x t k ∞ (A.28) 6 α | y t | + B t α − 1 k x t k ∞ 6 α 1 + 2 1 /α α − 1 max 1 6 s 6 t | y s | α − 1 k x t k ∞ , (A.29) where w e used the fact that B t 6 2 1 /α max 1 6 s 6 t − 1 | y s | . W e can dra w several consequences from the inequalities ab ov e. First note that, by (A.29), max 1 6 t 6 T k∇ e ` t ( b u t ) k ∞ 6 α 1 + 2 1 /α α − 1 X Y α − 1 . (A.30) Moreo ver, using (A.28) and the definition of b y t in Figure 4, we can see that the gradien ts ∇ e ` t ( b u t ) satisfy w w w ∇ e ` t ( b u t ) w w w ∞ 6 α | y t − b y t | α − 1 k x t k ∞ 6 αX | y t − b y t | α − 1 . This entails that w w w ∇ e ` t ( b u t ) w w w 2 ∞ 6 α 2 X 2 y t − b y t 2 α − 2 = α 2 X 2 y t − b y t α − 2 y t − b y t α 6 α 2 X 2 (1 + 2 1 /α ) Y α − 2 y t − b y t α , (A.31) where we used the upp er b ounds | y t | 6 Y and | b y t | , b u t · x t B t 6 B t 6 2 1 /α Y . Substituting (A.30) and (A.31) in (A.27) and com bining the resulting b ound with (A.26), we get T X t =1 | y t − b y t | α 6 inf k u k 1 6 U T X t =1 e ` t ( u ) + a α U X Y α/ 2 − 1 v u u t T X t =1 | y t − b y t | α ! ln(2 d ) + 8 ln(2 d ) + 12 b α U X Y α − 1 | {z } , C 1 + 4 1 + 2 − 1 /α α Y α | {z } , C 2 , where w e set a α , 4 α 1 + 2 1 /α α/ 2 − 1 and b α , α 1 + 2 1 /α α − 1 . T o simplify the notations we also set b L T , P T t =1 | y t − b y t | α and e L ∗ T , min k u k 1 6 U P T t =1 e ` t ( u ), so that the previous inequalit y can b e rewritten as b L T 6 e L ∗ T + C 1 + C 2 + a α U X Y α/ 2 − 1 q b L T ln(2 d ) . Solving for b L T via Lemma 4 in App endix B (used with a = e L ∗ T + C 1 + C 2 and b = a α U X Y α/ 2 − 1 p ln(2 d )), w e get that b L T 6 e L ∗ T + C 1 + C 2 + a α U X Y α/ 2 − 1 p ln(2 d ) q e L ∗ T + C 1 + C 2 + a α U X Y α/ 2 − 1 p ln(2 d ) 2 6 e L ∗ T + a α U X Y α/ 2 − 1 q e L ∗ T ln(2 d ) + a α U X Y α/ 2 − 1 p ( C 1 + C 2 ) ln(2 d ) + a 2 α U 2 X 2 Y α − 2 ln(2 d ) + C 1 + C 2 . (A.32) T o conclude the pro of, it just suffices to b ound the term a α U X Y α/ 2 − 1 p ( C 1 + C 2 ) ln(2 d ) from ab ov e. First note that p ( C 1 + C 2 ) ln(2 d ) 6 p C 1 ln(2 d ) + p C 2 ln(2 d ) 6 p C 1 ln(2 d ) + 2 1 + 2 − 1 /α α/ 2 Y α/ 2 p ln(2 d ) , (A.33) 26 where the last inequality follows by definition of C 2 ab o ve. Now, to upp er b ound p C 1 ln(2 d ), we note that, b y definition of C 1 , p C 1 ln(2 d ) = ln(2 d ) q 8 + 12 / ln(2 d ) b α U X Y α − 1 6 ln(2 d ) q 8 + 12 / ln 2 b α U X Y α/ 2 − 1 + Y α/ 2 √ 2 , where w e used the elementary upp er bound √ ab 6 ( a + b ) / 2 with a = U X Y α/ 2 − 1 and b = Y α/ 2 . Substituting the last inequalit y in (A.33) and using p ln(2 d ) 6 ln(2 d ) / √ ln 2, we finally get that a α U X Y α/ 2 − 1 p ( C 1 + C 2 ) ln(2 d ) 6 a α ln(2 d ) q b α 4 + 6 / ln 2 + 2 1 + 2 − 1 /α α/ 2 / √ ln 2 U X Y α − 1 + a α ln(2 d ) q b α 4 + 6 / ln 2 U 2 X 2 Y α − 2 . Substituting the last inequalit y into (A.32) and rearranging terms concludes the pro of. Pro of (of Remark 1): Recall that in this remark, we fo cus on the square loss (i.e., α = 2) and that we set c 1 , 8 √ 2 + 1 and c 2 , 4 1 + 1 / √ 2 2 . By the key prop erty (13) that holds for all rounds t such that | y t | 6 B t (the other rounds accounting only for an additional total loss at most of c 2 Y 2 , see (A.26)), we get T X t =1 ( y t − b y t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 6 T X t =1 e ` t ( b u t ) − inf k u k 1 6 U T X t =1 e ` t ( u ) + c 2 Y 2 6 4 U max 1 6 t 6 T ∇ e ` t ( b u t ) ∞ p T ln(2 d ) + 2 ln(2 d ) + 3 + c 2 Y 2 (A.34) 6 c 1 U X Y p T ln(2 d ) + 8 ln(2 d ) + c 2 Y 2 , (A.35) where (A.34) follo ws from the remark in Prop osition 1 inv olving the uniform b ound max 1 6 t 6 T k∇ e ` t ( b u t ) k ∞ , and where (A.35) follows from max 1 6 t 6 T k∇ e ` t ( b u t ) k ∞ 6 2 1 + √ 2 X Y (by (A.29)) and from the elementary inequalit y 3 6 6 ln(2 d ). App endix B. Lemmas The next elemen tary lemma is due to [22, App endix I I I]. It is useful to compute an upp er b ound on the cum ulative loss b L T of a forecaster when b L T satisfies an inequalit y of the form (B.1). Lemma 4. L et a, b > 0 . Assume that x > 0 satisfies the ine quality x 6 a + b √ x . (B.1) Then, x 6 a + b √ a + b 2 . The next lemma is useful to prov e Theorem 1. At the end of this section, w e also pro vide an elementary lemma ab out the exp onen tially weigh ted av erage forecaster combined with clipping. 27 Lemma 5. L et d, T ∈ N ∗ , and U, X, Y > 0 . The minimax r e gr et on B 1 ( U ) for b ounde d b ase pr e dictions and observations satisfies inf F sup k x t k ∞ 6 X, | y t | 6 Y ( T X t =1 ( y t − b y t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 ) 6 min ( 3 U X Y p 2 T ln(2 d ) , 32 d Y 2 ln 1 + √ T U X d Y ! + d Y 2 ) , wher e the infimum is taken over al l for e c asters F and wher e the supr emum extends over al l se quenc es ( x t , y t ) 1 6 t 6 T ∈ ( R d × R ) T such that | y 1 | , . . . , | y T | 6 Y and k x 1 k ∞ , . . . , k x T k ∞ 6 X . Pro of: W e treat each of the tw o terms in the ab o ve minimum separately . Step 1 : W e pro ve that their exists a forecaster F whose worst-case regret on B 1 ( U ) is upp er b ounded by 3 U X Y p 2 T ln(2 d ). First note that if U > ( Y /X ) p T / (2 ln(2 d )), then the upp er bound 3 U X Y p 2 T ln(2 d ) > 3 T Y 2 > T Y 2 is trivial (b y choosing the forecaster F which outputs b y t = 0 at eac h time t ). W e can thus assume that U < ( Y /X ) p T / (2 ln(2 d )). Consider the EG ± algorithm as given in [9, Theorem 5.11], and denote by b u t ∈ B 1 ( U ) the linear combination it outputs at eac h time t > 1. Then, b y the aforementioned theorem, this forecaster satisfies, uniformly ov er all individual sequences b ounded b y X and Y , that T X t =1 ( y t − b u t · x t ) 2 − inf k u k 1 6 U T X t =1 ( y t − u · x t ) 2 6 2 U X Y p 2 T ln(2 d ) + 2 U 2 X 2 ln(2 d ) 6 2 U X Y p 2 T ln(2 d ) + 2 Y s T 2 ln(2 d ) ! U X ln(2 d ) (B.2) 6 3 U X Y p 2 T ln(2 d ) , where (B.2) follows from the assumption U X < Y p T / (2 ln(2 d )). This concludes the first step of this pro of. Step 2 : W e pro ve that their exists a forecaster F whose worst-case regret on B 1 ( U ) is upp er b ounded by 32 d Y 2 ln 1 + √ T U X d Y + d Y 2 . Suc h a forecaster is given by the sparsity-orien ted algorithm SeqSEW B ,η τ of [12] (we could also get a sligh tly w orse b ound with the sequen tial ridge regression forecaster of [13, 14]). Indeed, by [12, Prop osition 1], the cumulativ e square loss of the algorithm SeqSEW B ,η τ tuned with B = Y , η = 1 / (8 Y 2 ) and τ = Y / ( √ T X ) is upp er b ounded b y inf u ∈ R d ( T X t =1 y t − u · x t 2 + 32 k u k 0 Y 2 ln 1 + √ T X k u k 1 k u k 0 Y !) + d Y 2 6 inf k u k 1 6 U ( T X t =1 y t − u · x t 2 ) + 32 d Y 2 ln 1 + √ T X U d Y ! + d Y 2 , 28 where the last inequalit y follows by monotonicity 18 in k u k 0 and k u k 1 of the second term of the left-hand side. This concludes the pro of. Next w e recall a regret bound satisfied b y the standard exponentially w eigh ted av erage forecaster applied to clipp ed base forecasts. Assume that at each time t > 1, the forecaster has access to K > 1 base forecasts b y ( k ) t ∈ R , k = 1 , . . . , K , and that for some kno wn b ound Y > 0 on the observ ations, the forecaster predicts at time t as b y t , K X k =1 p k,t b y ( k ) t Y . In the equation ab ov e, [ x ] Y , min { Y , max {− Y , x }} for all x ∈ R , and the weigh t vectors p t ∈ R K are given b y p 1 = (1 /K, . . . , 1 /K ) and, for all t = 2 , . . . , T , by p k,t , exp − η P t − 1 s =1 y s − b y ( k ) s Y 2 P K j =1 exp − η P t − 1 s =1 y s − b y ( j ) s Y 2 , 1 6 k 6 K , for some inv erse temp erature parameter η > 0 to b e chosen b elow. The next lemma is a straigthforward consequence of Theorem 3.2 and Prop osition 3.1 of [17]. Lemma 6 (Exp onen tial w eighting with clipping) . Assume that the for e c aster knows b efor ehand a b ound Y > 0 on the observations | y t | , t = 1 , . . . , T . Then, the exp onential ly weighte d aver age for e c aster tune d with η 6 1 / (8 Y 2 ) and with clipping [ · ] Y satisfies T X t =1 y t − b y t 2 6 min 1 6 k 6 K T X t =1 y t − b y ( k ) t 2 + ln K η . Pro of (of Lemma 6): The pro of follows straightforw ardly from Theorem 3.2 and Prop osition 3.1 of [17]. T o apply the latter result, recall from [14, Remark 3] that the square loss is 1 / (8 Y 2 )-exp-conca ve on [ − Y , Y ] and th us η -exp-concav e 19 (since η 6 1 / (8 Y 2 ) b y assumption). Therefore, by definition of our forecaster ab o ve, Theorem 3.2 and Prop osition 3.1 of [17] yield T X t =1 y t − b y t 2 6 min 1 6 k 6 K T X t =1 y t − b y ( k ) t Y 2 + ln K η . T o conclude the pro of, note for all t = 1 , . . . , T and k = 1 , . . . , K that | y t | 6 Y b y assumption, so that clipping the base forecasts to [ − Y , Y ] can only impro ve prediction, i.e., y t − b y ( k ) t Y 2 6 y t − b y ( k ) t 2 . App endix C. Additional to ols The next appro ximation argument is originally due to Maurey , and was used under v arious forms, e.g., in [1, 2, 3, 4] (see also [5]). 18 Note that for all A > 0, the function x 7→ x ln(1 + A/x ) (continuously extended at x = 0) has a nonnegative first deriv ative and is th us nondecreasing on R + . 19 This means that for all y ∈ [ − Y , Y ], the function x 7→ exp − η ( y − x ) 2 is concav e on [ − Y , Y ]. 29 Lemma 7 (Approximation argument) . L et U > 0 and m ∈ N ∗ . Define the fol lowing finite subset of B 1 ( U ) : e B U,m , k 1 U m , . . . , k d U m : ( k 1 , . . . , k d ) ∈ Z d , d X j =1 | k j | 6 m ⊂ B 1 ( U ) . Then, for al l ( x t , y t ) 1 6 t 6 T ∈ R d × R T such that max 1 6 t 6 T k x t k ∞ 6 X , inf u ∈ e B U,m T X t =1 ( y t − u · x t ) 2 6 inf u ∈ B 1 ( U ) T X t =1 ( y t − u · x t ) 2 + T U 2 X 2 m . Pro of: The pro of is quite standard and follows the same lines as [1, Prop osition 5.2.2] or [3, Theorem 2] who addressed the aggregation task in the sto chastic setting. W e rewrite this argumen t below in our online deterministic setting. Fix u ∗ ∈ argmin u ∈ B 1 ( U ) P T t =1 ( y t − u · x t ) 2 . Define the probabilit y distribution π = ( π − d , . . . , π d ) ∈ R 2 d +1 + b y π j , ( u ∗ j ) + U if j > 1; ( u ∗ j ) − U if j 6 − 1; 1 − d X j =1 | u ∗ j | U if j = 0 . Let J 1 , . . . , J m ∈ {− d, . . . , d } b e i.i.d. random integers dra wn from π , and set e u , U m m X k =1 e J k , where ( e j ) 1 6 j 6 d is the canonical basis of R d , where e 0 , 0 , and where e − j , − e j for all 1 6 j 6 d . Note that e u ∈ e B U,m b y construction. Therefore, inf u ∈ e B U,m T X t =1 ( y t − u · x t ) 2 6 E " T X t =1 ( y t − e u · x t ) 2 # . (C.1) The rest of the pro of is dedicated to upp er b ounding the last exp ectation. Expanding all the squares ( y t − e u · x t ) 2 = ( y t − u ∗ · x t + u ∗ · x t − e u · x t ) 2 , first note that E " T X t =1 ( y t − e u · x t ) 2 # = T X t =1 ( y t − u ∗ · x t ) 2 + T X t =1 E ( u ∗ · x t − e u · x t ) 2 + 2 T X t =1 ( y t − u ∗ · x t ) E u ∗ · x t − e u · x t . (C.2) But b y definition of e u and π , E e u = U E e J 1 = U d X j = − d π j e j = U d X j =1 u ∗ j + U e j + u ∗ j − U ( − e j ) ! = U d X j =1 u ∗ j U e j = u ∗ , 30 so that E e u · x t = u ∗ · x t for all 1 6 t 6 T . Therefore, the last sum in (C.2) abov e equals zero, and E h u ∗ · x t − e u · x t 2 i = V ar e u · x t = U 2 m 2 m X k =1 V ar e J k · x t 6 U 2 X 2 m , where the second equality follows from e u · x t = ( U /m ) P m k =1 e J k · x t and from the indep endence of the J k , 1 6 k 6 m , and where the last inequality follows from | e J k · x t | 6 k e J k k 1 k x t k ∞ 6 X for all 1 6 k 6 m . Com bining (C.2) with the remarks ab ov e, we get E " T X t =1 ( y t − e u · x t ) 2 # 6 T X t =1 ( y t − u ∗ · x t ) 2 + T U 2 X 2 m = inf u ∈ B 1 ( U ) T X t =1 ( y t − u · x t ) 2 + T U 2 X 2 m , where the last line follows b y definition of u ∗ . Substituting the last inequality in (C.1) concludes the pro of. The com binatorial result b elo w (or v arian ts of it) is well-kno wn; see, e.g., [2, 3]. W e repro duce its pro of for the con venience of the reader. W e use the notation e , exp(1). Lemma 8 (An elemen tary combinatorial upp er b ound) . L et m, d ∈ N ∗ . Denoting by | E | the c ar dinality of a set E , we have ( k 1 , . . . , k d ) ∈ Z d : d X j =1 | k j | 6 m 6 e(2 d + m ) m m . Pro of (of Lemma 8): Setting ( k 0 − j , k 0 j ) , ( k j ) − , ( k j ) + for all 1 6 j 6 d , and k 0 0 , m − P d j =1 | k j | , we ha ve ( k 1 , . . . , k d ) ∈ Z d : d X j =1 | k j | 6 m 6 ( k 0 − d , . . . , k 0 d ) ∈ N 2 d +1 : d X j = − d k 0 j = m = 2 d + m m (C.3) 6 e(2 d + m ) m m . (C.4) T o get inequality (C.3), we used the (elementary) fact that the n umber of 2 d + 1 in teger-v alued tuples summing up to m is equal to the num ber of lattice paths from (1 , 0) to (2 d + 1 , m ) in N 2 , which is equal to 2 d +1+ m − 1 m . As for inequalit y (C.4), it follo ws straightforw ardly from a classical combinatorial result stated, e.g., in [21, Prop osition 2.5]. References [1] A. Nemirovski, T opics in Non-Parametric Statistics, Springer, Berlin/Heidelb erg/New Y ork, 2000. [2] A. B. Tsybak ov, Optimal rates of aggregation, in: Pro ceedings of the 16th Annual Conference on Learning Theory (COL T’03), 2003, pp. 303–313. [3] F. Bunea, A. Nobel, Sequen tial procedures for aggregating arbitrary estimators of a conditional mean, IEEE T rans. Inform. Theory 54 (4) (2008) 1725–1735. 31 [4] S. Shalev-Shw artz, N. Srebro, T. Zhang, T rading accuracy for sparsit y in optimization problems with sparsity constraints, SIAM J. Optim. 20 (6) (2010) 2807–2832. [5] Y. Y ang, Aggregating regression procedures to improv e p erformance, Bernoulli 10 (1) (2004) 25–47. [6] L. Birg´ e, P . Massart, Gaussian model selection, J. Eur. Math. Soc. 3 (2001) 203–268. [7] G. Raskutti, M. J. W ainwrigh t, B. Y u, Minimax rates of estimation for high-dimensional linear regression ov er ` q -balls, IEEE T rans. Inform. Theory 57 (10) (2011) 6976–6994. [8] N. Cesa-Bianchi, Analysis of tw o gradient-based algorithms for on-line regression, J. Comput. System Sci. 59 (3) (1999) 392–411. [9] J. Kivinen, M. K. W armuth, Exp onentiated gradient versus gradien t descent for linear predictors, Inform. and Comput. 132 (1) (1997) 1–63. [10] P . Auer, N. Cesa-Bianchi, C. Gentile, Adaptive and self-confiden t on-line learning algorithms, J. Comp. Sys. Sci. 64 (2002) 48–75. [11] N. Cesa-Bianchi, Y. Mansour, G. Stoltz, Impro ved second-order b ounds for prediction with exp ert advice, Mach. Learn. 66 (2/3) (2007) 321–352. [12] S. Gerchino vitz, Sparsity regret b ounds for individual sequences in online linear regression, JMLR W orkshop and Confer- ence Pro ceedings 19 (COL T 2011 Pro ceedings) (2011) 377–396. [13] K. S. Azoury , M. K. W arm uth, Relative loss b ounds for on-line density estimation with the exp onential family of distri- butions, Mach. Learn. 43 (3) (2001) 211–246. [14] V. V o vk, Comp etitive on-line statistics, In ternat. Statist. Rev. 69 (2001) 213–248. [15] M. Zinkevic h, Online conv ex programming and generalized infinitesimal gradient ascent, in: Pro ceedings of the 20th International Conference on Machine Learning (ICML’03), 2003, pp. 928–936. [16] S. Shalev-Shw artz, O. Shamir, N. Srebro, K. Sridharan, Sto chastic conv ex optimization, in: Pro ceedings of the 22nd Annual Conference on Learning Theory (COL T’09), 2009, pp. 177–186. [17] N. Cesa-Bianchi, G. Lugosi, Prediction, Learning, and Games, Cam bridge Univ ersity Press, 2006. [18] C. Gentile, The robustness of the p -norm algorithms, Mac h. Learn. 53 (3) (2003) 265–299. [19] S. Shalev-Shw artz, A. T ewari, Stochastic methods for ` 1 -regularized loss minimization, in: Pro ceedings of the 26th Annual International Conference on Machine Learning (ICML’09), 2009, pp. 929–936. [20] J. C. Duchi, S. Shalev-Sh wartz, Y. Singer, A. T ewari, Composite ob jective mirror descent, in: Pro ceedings of the 23rd Annual Conference on Learning Theory (COL T’10), 2010, pp. 14–26. [21] P . Massart, Concentration Inequalities and Mo del Selection, V ol. 1896 of Lecture Notes in Mathematics, Springer, Berlin, 2007. [22] N. Cesa-Bianc hi, G. Lugosi, G. Stoltz, Minimizing regret with label efficient prediction, IEEE T rans. Inform. Theory 51 (6) (2005) 2152–2162. 32
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment