Pseudo-Implicit Feedback for Alleviating Data Sparsity in Top-K Recommendation
We propose PsiRec, a novel user preference propagation recommender that incorporates pseudo-implicit feedback for enriching the original sparse implicit feedback dataset. Three of the unique characteristics of PsiRec are: (i) it views user-item interactions as a bipartite graph and models pseudo-implicit feedback from this perspective; (ii) its random walks-based approach extracts graph structure information from this bipartite graph, toward estimating pseudo-implicit feedback; and (iii) it adopts a Skip-gram inspired measure of confidence in pseudo-implicit feedback that captures the pointwise mutual information between users and items. This pseudo-implicit feedback is ultimately incorporated into a new latent factor model to estimate user preference in cases of extreme sparsity. PsiRec results in improvements of 21.5% and 22.7% in terms of Precision@10 and Recall@10 over state-of-the-art Collaborative Denoising Auto-Encoders. Our implementation is available at https://github.com/heyunh2015/PsiRecICDM2018.
💡 Research Summary
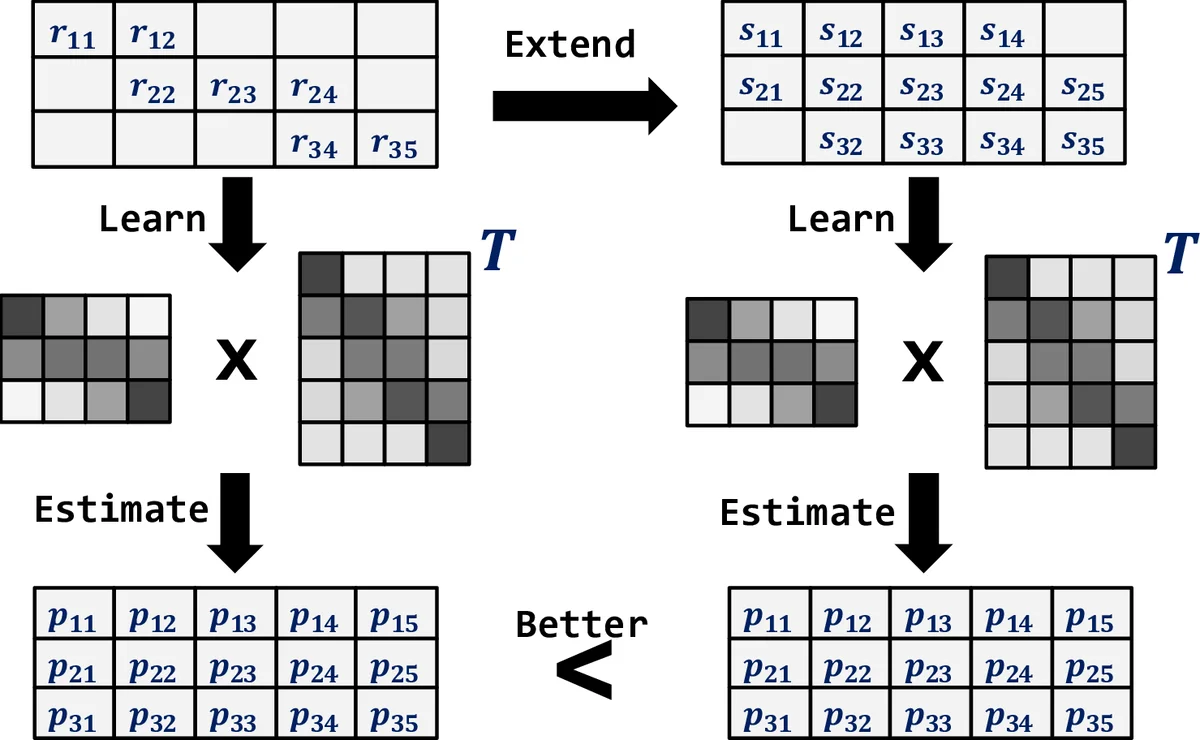
The paper tackles the pervasive problem of extreme sparsity in implicit feedback recommender systems by introducing a novel framework called PsiRec (Pseudo‑Implicit Feedback Recommendation). Traditional collaborative filtering methods, especially latent factor models such as matrix factorization, struggle when the user‑item interaction matrix contains only a handful of positive entries. Graph‑based propagation techniques can exploit indirect relationships, but they often lack a principled way to quantify the confidence of those transitive links. PsiRec bridges these two worlds: it first represents the interaction data as a bipartite graph (users on one side, items on the other) and then performs truncated random walks from every node. By sliding a window over each walk, the algorithm extracts both direct and indirect user‑item pairs, effectively sampling the “neighborhood” of each user in the graph.
Two strategies are proposed to turn the sampled pairs into a pseudo‑implicit feedback matrix S. The first, a simple co‑occurrence count, merely records how many times a pair appears in the walk corpus. This approach, however, is heavily biased toward high‑degree users and items. The second, and the paper’s main contribution, adapts the Skip‑gram with Negative Sampling (SGNS) objective from word embedding literature. By reformulating the SGNS loss for the user‑item setting, the authors show that the optimal inner product between a user embedding and an item embedding equals the pointwise mutual information (PMI) of that pair, shifted by a constant log k (k being the number of negative samples). Consequently, each entry s′ui = log( #(u,i)·|C| / ( #(u)·#(i) ) ) – log k, where C is the corpus of sampled pairs, is precisely the PMI value. To avoid negative or undefined scores, they clamp the values at zero, yielding a non‑negative matrix S that satisfies their definition of pseudo‑implicit feedback.
With S in hand, PsiRec proceeds to a standard matrix factorization step. The predicted preference p̂ui is modeled as the dot product of user and item latent vectors (x_u, y_i). The loss function combines a squared error term (s_ui – p̂ui)^2 with L2 regularization, and the model is optimized using Alternating Least Squares (ALS). Closed‑form updates for x_u and y_i are derived, allowing efficient training even for large datasets.
Empirical evaluation is conducted on two real‑world, highly sparse datasets: Amazon (multiple product categories) and Tmall (Chinese e‑commerce). Baselines include classic MF, graph‑based methods such as ItemRank and P3, and the state‑of‑the‑art Collaborative Denoising Auto‑Encoder (CDAE). PsiRec‑PMI (the PMI‑based variant) achieves relative improvements of 21.5 % in Precision@10 and 22.7 % in Recall@10 over CDAE, with the gains being more pronounced as sparsity increases. The co‑occurrence variant (PsiRec‑CO) also outperforms baselines but lags behind the PMI version, confirming that PMI’s bias correction is crucial.
The authors highlight several key insights: (1) Random walks on the bipartite graph effectively capture transitive user‑item relationships; (2) PMI provides a statistically sound confidence measure that mitigates popularity bias; (3) Integrating graph‑derived feedback with latent factor models yields a synergistic effect, where the graph enriches the data and the factor model ensures scalable inference.
Limitations are acknowledged. The random walk hyper‑parameters (number of walks β, walk length γ, window size σ) influence performance and currently require manual tuning. Sampling many walks can be computationally intensive for massive graphs, suggesting a need for distributed or more efficient sampling strategies. Moreover, the binary clamping of low PMI values may discard potentially useful weak signals; future work could explore smoother weighting schemes or Bayesian smoothing. Extending the method to dynamic, time‑evolving interaction graphs is also proposed.
In conclusion, PsiRec presents a compelling solution to the data sparsity dilemma by converting indirect graph connectivity into a mathematically grounded pseudo‑implicit feedback signal and feeding it into a conventional latent factor recommender. The approach not only delivers substantial empirical gains but also opens a new research direction that unifies graph‑based propagation and embedding‑based confidence estimation for recommender systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment