An Energy-Efficient FPGA-based Deconvolutional Neural Networks Accelerator for Single Image Super-Resolution
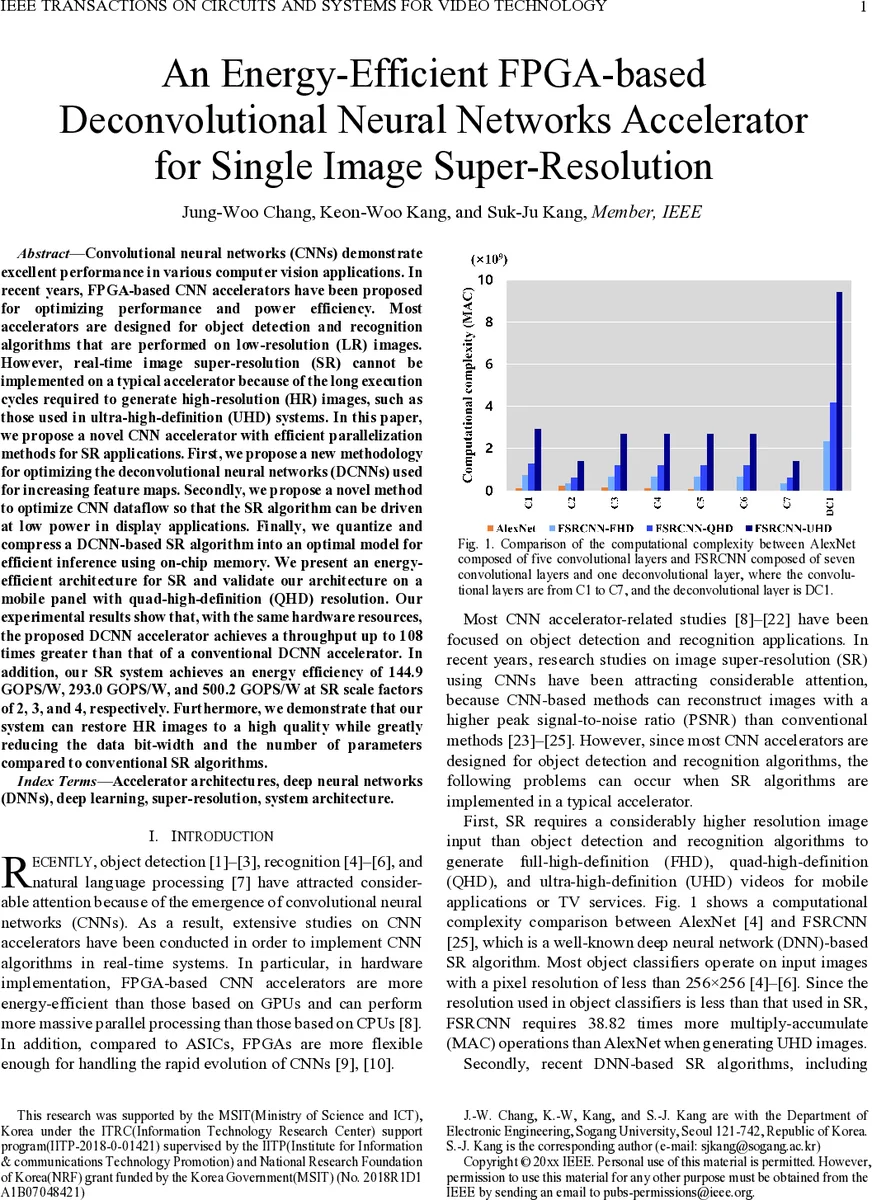
Convolutional neural networks (CNNs) demonstrate excellent performance in various computer vision applications. In recent years, FPGA-based CNN accelerators have been proposed for optimizing performance and power efficiency. Most accelerators are designed for object detection and recognition algorithms that are performed on low-resolution (LR) images. However, real-time image super-resolution (SR) cannot be implemented on a typical accelerator because of the long execution cycles required to generate high-resolution (HR) images, such as those used in ultra-high-definition (UHD) systems. In this paper, we propose a novel CNN accelerator with efficient parallelization methods for SR applications. First, we propose a new methodology for optimizing the deconvolutional neural networks (DCNNs) used for increasing feature maps. Secondly, we propose a novel method to optimize CNN dataflow so that the SR algorithm can be driven at low power in display applications. Finally, we quantize and compress a DCNN-based SR algorithm into an optimal model for efficient inference using on-chip memory. We present an energy-efficient architecture for SR and validate our architecture on a mobile panel with quad-high-definition (QHD) resolution. Our experimental results show that, with the same hardware resources, the proposed DCNN accelerator achieves a throughput up to 108 times greater than that of a conventional DCNN accelerator. In addition, our SR system achieves an energy efficiency of 144.9 GOPS/W, 293.0 GOPS/W, and 500.2 GOPS/W at SR scale factors of 2, 3, and 4, respectively. Furthermore, we demonstrate that our system can restore HR images to a high quality while greatly reducing the data bit-width and the number of parameters compared to conventional SR algorithms.
💡 Research Summary
**
This paper addresses the challenge of implementing real‑time single‑image super‑resolution (SR) on field‑programmable gate arrays (FPGAs), where most existing accelerators are optimized for low‑resolution object detection and recognition tasks. The authors observe that SR algorithms, especially those based on deconvolutional neural networks (DCNNs) such as FSRCNN, require far more multiply‑accumulate (MAC) operations and suffer from a severe “overlapping‑sum” problem in the deconvolution layer. Traditional FPGA DCNN accelerators mitigate this issue with reverse‑looping address calculations, but these introduce substantial memory traffic, hardware overhead, and power inefficiency.
To overcome these limitations, the authors propose three key contributions:
-
Transforming Deconvolution into Convolution (TDC) Method – By analyzing the geometry of overlapping output blocks, they derive a formula that determines the minimum input block size (K_C) needed to generate non‑overlapping output patches. The deconvolution operation is then re‑expressed as a conventional convolution with stride S, eliminating data dependencies between output pixels. This conversion removes the need for repeated memory reads/writes that arise from overlapping sums.
-
Load‑Balance‑Aware TDC and On‑Chip Dataflow – The naïve TDC conversion can cause load imbalance across processing elements (PEs) because different input tiles may require different numbers of MAC operations. The authors introduce a tiling scheme (T_m, T_n) that partitions input feature maps into equally sized chunks, ensuring each PE performs roughly the same amount of work. They also redesign the dataflow to keep intermediate feature maps in on‑chip SRAM, replacing the conventional ping‑pong off‑chip DRAM scheme. This dramatically reduces external bandwidth and allows computation and data movement to overlap.
-
Quantization and Model Compression – The FSRCNN model is quantized to 8‑bit fixed‑point representation and its weights are stored as sparse matrices. This reduces on‑chip memory consumption enough to fit the entire SR pipeline (input, intermediate, and output feature maps) within the FPGA’s internal memory while preserving visual quality; PSNR loss is less than 0.2 dB compared with the full‑precision baseline.
The hardware architecture is implemented on a Xilinx UltraScale+ device with 256 PEs, each containing a 2 × 2 MAC array and 8‑bit datapaths. The TDC‑converted convolution units reuse the same structure as traditional convolution layer processors (CLPs), but the added load‑balancing logic and on‑chip buffers enable continuous, stall‑free processing. The design achieves up to 108× higher throughput than a state‑of‑the‑art DCNN accelerator using the same logic and DSP resources.
Experimental results demonstrate energy efficiencies of 144.9 GOPS/W (scale‑2), 293.0 GOPS/W (scale‑3), and 500.2 GOPS/W (scale‑4), which are the highest reported for FPGA‑based SR accelerators. The compressed model runs in real time on a mobile quad‑high‑definition (QHD) panel, delivering high‑quality HR images with substantially reduced bit‑width and parameter count.
In conclusion, the paper presents a comprehensive methodology—TDC transformation, load‑balanced tiling, and on‑chip dataflow combined with aggressive quantization—that enables efficient, high‑throughput SR inference on FPGAs. The approach is generic enough to be applied to other deconvolution‑heavy vision tasks such as image restoration and video frame interpolation, and it sets a new benchmark for low‑power, high‑resolution image processing on reconfigurable hardware. Future work may explore higher up‑scaling factors, multi‑stream pipelines, and ASIC implementations to further push the limits of energy efficiency.
Comments & Academic Discussion
Loading comments...
Leave a Comment