Transfer Learning in Brain-Computer Interfaces with Adversarial Variational Autoencoders
We introduce adversarial neural networks for representation learning as a novel approach to transfer learning in brain-computer interfaces (BCIs). The proposed approach aims to learn subject-invariant representations by simultaneously training a cond…
Authors: Ozan Ozdenizci, Ye Wang, Toshiaki Koike-Akino
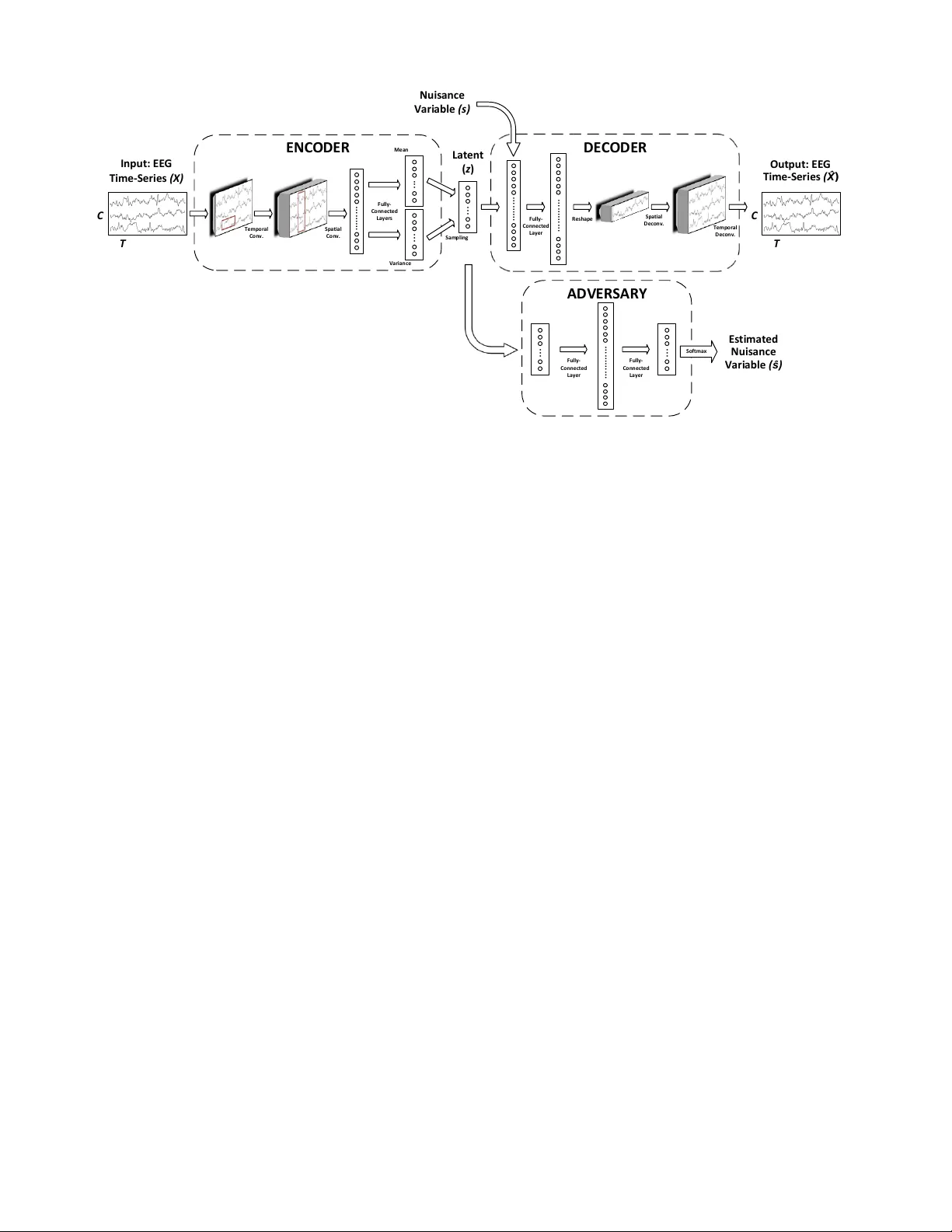
T ransfer Learning in Brain-Computer Interfaces with Adv ersarial V ariational A utoencoders Ozan ¨ Ozdenizci ? , Y e W ang † , T oshiaki K oike-Akino † , Deniz Erdo ˘ gmus ¸ ? Abstract — W e introduce adversarial neural networks f or r ep- resentation learning as a novel approach to transfer learning in brain-computer interfaces (BCIs). The proposed approach aims to learn subject-in variant r epresentations by simultaneously training a conditional variational autoencoder (cV AE) and an adversarial netw ork. W e use shallow con volutional architectures to realize the cV AE, and the learned encoder is transferred to extract subject-in variant features from unseen BCI users’ data for decoding. W e demonstrate a proof-of-concept of our approach based on analyses of electroencephalographic (EEG) data recorded during a motor imagery BCI experiment. Index T erms — repr esentation learning, transfer lear ning, adversarial networks, variational autoencoders, convolutional neural networks, EEG, brain-computer interfaces. I . I N T R O D U C T I O N T ransfer learning often describes an approach to discov er and e xploit some shared structure in the data that is in- variant across data sets. In the conte xt of brain-computer interfaces (BCIs), where the aim is to provide a direct neural communication and control channel for individuals, e.g., with se vere neuromuscular disorders, the concept of transfer learning gains significant interest giv en its potential benefit in reducing BCI system calibration times by exploiting neural data recorded from other subjects. Gi ven the limited data collection times under adequate concentration and conscious- ness with patients, this becomes essential for a potential patient end-user of the BCI system. Several pieces of work in this domain aim to find neural features (representations) that are inv ariant across subjects or sessions to calibrate BCIs [1– 3], or learn a structure for the set of decision rules and how they differ across subjects and sessions [4], [5]. Going beyond neural interfaces, significant progress was recently achieved in domain transfer learning by adversar - ially censored in v ariant representations within the growing field of deep learning in computer vision and image pro- cessing [6–13]. These methods rely on learning generati ve models of the data that allow synthesis of data samples from latent representations, which can be achie ved with v ariational autoencoders (V AEs) [14] for unsupervised feature learning, or generativ e adversarial networks (GANs) [15], where the supervision is alleviated by penalizing inaccurate samples using an adversarial game. Consistently , these are trained with adversarial censoring to learn representations that are ? Department of Electrical and Computer Engineering, Northeastern Uni- versity , Boston, MA, USA, E-mail: { oozdenizci, erdogmus } @ece.neu.edu. † Mitsubishi Electric Research Laboratories (MERL), Cambridge, MA, USA. E-mail: { yewang, koike } @merl.com. D. Erdo ˘ gmus ¸ is partially supported by NSF (IIS-1149570, CNS- 1544895), NIDLRR (90RE5017-02-01), and NIH (R01DC009834). O. ¨ Ozdenizci was an intern at MERL during this work. aimed to be independent from some nuisance variables (e.g., a representativ e variable for factors of v ariations across data sets). In the light of these recent work, we introduce this progress in adversarial representation learning as a novel approach for transfer learning in BCIs. V arious aspects of deep con volutional neural networks (CNNs) in computer vision ha ve been already introduced to extract features for task-specific decoding in electoen- cephalogram (EEG) based BCIs [16], [17], as well as for recent attempts to learn deep generativ e models for EEG [18–20]. In the present study , we extend these lines of work and propose a transfer learning approach for BCIs based on the exploitation of adv ersarial training for subject- in variant representation learning. Particularly , the proposed approach [9], [13] aims to learn subject-in variant repre- sentations by simultaneously training a conditional V AE and an adversarial network to enforce in variance of the learned data representations with respect to subject identity . This adversarial training procedure, with V AEs based on CNN architectures, yields data representations that work as features that are disentangled from subject-specific nuisance variations, which enables decoding for unseen BCI subjects. Our results demonstrate the advantage of this approach with a proof-of-concept based on analyses of EEG data recorded from 103 subjects during a motor imagery BCI experiment. I I . M E T H O D S A. Notation Let { ( X s i , y s i ) } n s i =1 denote the data set for subject s con- sisting of n s trials, where X s i ∈ R C × T is the raw EEG data at trial i recorded from C channels for T discretized time samples, and y s i is the corresponding class label from a set of L class labels. In a subject-to-subject transfer learning problem, the aim is to learn a parametric encoder q φ ( z | X ) which can be generalized across subjects, and extracts latent representations z ∈ R d z from the data X that are useful in discriminating dif ferent tasks or brain states indicated by their corresponding class labels y . Accordingly , let s denote the one-hot encoded subject identifier vector for subject s (i.e., an S -dimensional vector with a v alue of 1 at the s ’th index and zero in other indices), which represents the nuisance variable in our adversarial representation learning framew orks that z will be enforced to be independent of. B. Conditional V ariational Autoencoder (cV AE) V AEs [14] learn a generati ve model as a pair of en- coder and decoder networks. The encoder learns a latent representation z from the data X , while the decoder aims I n p u t : E E G T i m e - S e r i e s ( X ) C T O u t p u t : E E G T i m e - S e r i e s ( ) C T L a t e n t ( z ) E N CO D E R D E CO D E R T e m p o r a l C o n v . S p a t i a l C o n v . F u l l y - C o n n e ct e d L a y e r s F u l l y - C o n n e ct e d L a y e r N u i s a n ce V a r i a b l e ( s ) S a m p li n g T e m p o r a l D e c o n v . S p a t i a l D e co n v . R e s h a p e A D V E RS A RY E s t i m a t e d N u i s a n ce V a r i a b l e ( ) M e a n V a r i a n ce F u l l y - C o n n e ct e d L a y e r F u l l y - C o n n e ct e d L a y e r ... ... ... ... ... S o f t m a x Fig. 1. Adversarial cV AE (A-cV AE) architecture with a stochastic encoder and a deterministic decoder with conditioning on s . A-cV AE is trained to minimize the loss function in Eq. (2), while the adversary is also individualy trained to minimize its softmax cross-entropy loss. Parameter updates were performed alternatingly among the A-cV AE and the adversary once per batch. to reconstruct the data X from the learned representation z . In this variational framework the encoder is stochastic, meaning that the decoder uses a learned posterior q φ ( z | X ) ∼ N ( µ z , σ z ) , whose parameters are given by the encoder network. The decoder is pro vided with samples from this posterior distrib ution as input z . In the conditional V AE (cV AE) framework [21], the decoder is conditioned on a nuisance variable s as an additional input besides z , and the encoder is expected to learn representations z that are in variant of s , since s is already giv en as input to the decoder . The loss function to be minimized in this cV AE framework, which is also known as the e vidence lo wer bound (ELBO), is giv en by: L cV AE ( X s i ; θ , φ ) = − E log p θ ( X s i | z , s i ) + D KL q φ ( z | X s i ) || p ( z ) , (1) where the first term is the reconstruction loss of the decoder, and the second term is the encoder variational posterior loss. This frame work implicitly enforces in v ariance for z with respect to s . Howe ver this is known to be not perfectly achiev ed in practice, which pav es the way for adversarial training methods in representation learning [13]. C. Adversarial Conditional V AE (A-cV AE) In the proposed adversarial cV AE (A-cV AE) frame- work [9], [13], a conditional V AE and an adversary to enforce in variance with respect to s (i.e., subject identifiers) are simultaneously trained. Specifically , alongside a cV AE that takes EEG time-series data X as input to the encoder and estimates ˆ X at the decoder , an adversary is trained that takes learned representations z as input, and estimates ˆ s . W e extend Eq. (1) to obtain the A-cV AE loss function. For the deterministic decoder , reconstruction loss is determined by the mean squared error of the estimated time-series EEG data. Furthermore, softmax cross-entropy loss of the adversary network is inv ersely added to the loss function for A-cV AE which is then denoted as: L A-cV AE ( X s i ; θ , φ, Ψ ) = k X s i − ˆ X s i k 2 + D KL q φ ( z | X s i ) || p ( z ) + λ E log q Ψ ( s i | z ) , (2) where λ > 0 is a weight parameter to adjust the impact of adversarial censoring on learned representations. Alternat- ingly once per batch with A-cV AE parameter updates, the adversary is also individually trained to minimize its softmax cross-entropy loss L A ( z ; Ψ ) = E [ − log q Ψ ( s i | z )] . D. Model Ar c hitecture and Classifier T raining In our implementations, the encoder and decoder hav e con- volutional architectures embedding temporal and spatial fil- terings motiv ated by the results achiev ed with EEGNet [16], Deep ConvNet and Shallow ConvNet [17]. Parameteriza- tion and details of the conv olutional cV AE architecture are broadly illustrated in Fig. 1, and provided in detail in T able I. The two fully connected layers at the output of the encoder generate two d z -dimensional parameter vectors µ z and σ z , which are then used to sample z . The nuisance variable vector s is then concatenated to the sampled z as the input for the decoder . W e used temporal con v olution kernels of size W = 100 , and spatial conv olution kernels of size C = 64 , and a latent vector dimensionality of d z = 100 . Adjacent to the cV AE, the adversary is realized as a single hidden layer multilayer perceptron (MLP) with ReLU nonlinearity after the first layer , and we fixed adversarial censoring weight parameter λ = 1 . 0 in all experiments. Follo wing adversarial representation learning using a set of training data samples, the encoder is kept static and then using the same training data samples, a classifier is trained T ABLE I A - C V A E E N C O DE R A ND D E C OD E R A R C HI T E C TU R E S Layer Input Dim. Operation Encoder 1 C × T 40 × T emporal Con v1D ( 1 × W ) 40 × C × T BatchNorm + ReLU + Dropout (0.25) Encoder 2 40 × C × T 40 × Spatial Conv1D ( C × 1 ) 40 × 1 × T BatchNorm + ReLU + Dropout (0.25) Encoder 3 40 × 1 × T Reshape (Flatten) 40 T × 1 2 × Fully-Connected Layers Latent ( z ) d z Sample z with estimated parameters Decoder 1 ( d z + S ) × 1 Fully-Connected Layer 40 T × 1 ReLU + Reshape Decoder 2 40 × 1 × T 40 × Spatial Deconv1D ( C × 1 ) 40 × C × T BatchNorm + ReLU + Dropout (0.25) Decoder 3 40 × C × T 40 × T emporal Decon v1D ( 1 × W ) C × T BatchNorm + ReLU + Dropout (0.25) that is connected to the output of the encoder . Specifically , all training data samples were again used as input to the static encoder that was previously optimized, and using the obtained parameters at the output of the encoder, a latent vector z is sampled which was then used as an input to a classifier . The classifier was also realized as a single hidden layer MLP with ReLU nonlinearity after the first layer . Classifier training was performed to minimize its softmax cross-entropy loss L C ( z ; Ω ) = E [ − log q Ω ( y | z )] . The adv ersary network had output dimensionality of S , and the classifier had an output dimensionality of L . Both the adversary and the classifier hidden layers had 100 nodes. E. Dataset and Implementation W e used the publicly av ailable PhysioNet EEG Motor Mov ement/Imagery Dataset [22], which w as collected us- ing the BCI2000 instrumentation system [23]. The dataset consists of over 1500 one- and two-minute EEG recordings, obtained from 109 subjects. Throughout the experiments, subjects were placed in front of a computer screen and were instructed to perform cue-based motor execution/imagery tasks while 64-channel EEG were recorded at a sampling rate of 160 Hz. These tasks included e xecuting the mo vement of the right or left hand, opening and closing of both fists or legs; or just the imagination of these movements. Each trial lasted four-seconds with inter-trial resting periods of same length. At the beginning of the experiments, eyes-open and eyes-closed resting-state EEG were also recorded. Each subject participated in the experiment for a single session. From this data set, six subjects’ data were discarded due to irregular timestamp alignments, resulting in a total of 103 subjects. W e used trials that correspond to right and left hand motor imagination to ev aluate our proposed approach on a con ventional BCI paradigm [24]. This resulted in a total of 45 four-second trials per subject, with binary class labels y s i corresponding to right or left hand imagery . W e randomly selected 13 subjects to hold-out for further across- subjects transfer learning experiments. Using the remaining 90 subjects’ data, the networks were trained over a training set of 3240 trials, while validations were performed with the remaining 810 trials including data from all subjects. W e implemented all analyses with the Chainer deep learning framew ork [25]. Networks were trained with 100 trials per batch for 750 epochs ( ∼ 25,000 iterations), and parameter updates were performed once per batch with Adam [26]. I I I . E X P E R I M E N TA L R E S U L T S A. EEG Pr e-Pr ocessing and Model Evaluation All subjects’ data were epoched into the time-interv al where the neural changes induced by motor imagery are emphasized [24]. Specifically , from the four second duration, the 1-to-3 seconds interv al after the imagery cue onset were extracted to be used in experiments, resulting in a time-series length of T = 320 . Raw EEG data were normalized to hav e zero mean. Note that this pre-processing statistics (i.e., data mean) is only computed on the training data, and then applied to v alidation and transfer subjects’ data. W e e valuate adversarial representation learning with the following framew orks: (1) A-cV AE, (2) cV AE, (3) adver - sarially censored V AE without conditioning (A-V AE), (4) basic con volutional encoder (CNN). Implementation of (1) corresponds to the Sections II-C and II-D. The approach in (2) is expected to re veal the practical deficiencies of only using decoder conditioning for representation inv ariance. In that case, we still train an adversary in parallel but do not feed the adversarial loss to the overall training objectiv e, i.e., using Eq. (1). Method (3) is expected to re veal the tradeoff between enforcing in variance with an adversary but still pre- serving enough information in z to allo w suf ficient decoder learning (c.f. a similar approach in [6]). This corresponds to using the same objective as A-cV AE, but not pro viding s at the decoder input. Finally , (4) depicts a baseline case that uses the same CNN encoder architecture in combination with an MLP classifier but only trained end-to-end from scratch (via softmax cross-entropy loss for classification) rather first training the encoder within a V AE. B. Acr oss-Subjects T ransfer Learning T o observe representation inv ariance, accuracies of the adversary network over 90 subjects after training are pre- sented in T able II. In this context, a higher accuracy indicates more subject-specific information remaining in the learned representations z , which results in better decoding of s by the adversary . Therefore a lo wer adversary accuracy is representativ e of better in variant representation learning, as observed through the least leakage with A-cV AE. Distributions of transfer learning classification accuracies for the 13 held-out subjects are shown in Fig. 2. Using zero subject-specific training or fine-tuning data, we observe accuracies up to 73% with A-cV AE. Consistently with the results in T able II, we observe a decrease of accuracies in cV AE and A-V AE with respect to A-cV AE. For baseline CNN, the model tends to memorize the training data without any subject-in variance attempt, resulting in high variation of accuracies across the 13 subjects as intuiti vely e xpected. T ABLE II A DV E RS A RY A CC U R AC I ES A F T ER M O DE L T RA I N I NG T raining Data V alidation Data A-cV AE cV AE A-V AE A-cV AE cV AE A-V AE 0 . 48 0 . 56 0 . 68 0 . 13 0 . 15 0 . 21 A-cVAE cVAE A-VAE CNN 0.45 0.5 0.55 0.6 0.65 0.7 0.75 Classification Accuracy Fig. 2. T ransfer learning classification accuracies for the 13 held-out subjects with learned features by: (1) A-cV AE, (2) cV AE, (3) A-V AE (i.e., no conditioning on s ), (4) CNN as a baseline. Central line mark represents the median across 13 subjects. Upper and lower bounds of the box represents the first and third quartiles. Dashed lines represent the e xtreme samples. Mean accuracies are: (1) 63.8%, (2) 61.2%, (3) 56.9%, (4) 59.8%. I V . D I S C U S S I O N In this work we introduced adversarial in variant repre- sentation learning as a novel approach to transfer learning in BCIs. W e rev ealed that learning subject-in variant repre- sentations by adversarial censoring can be a significantly useful tool for subject-transfer learning. W e demonstrated an empirical proof-of-concept with EEG data recorded from 103 subjects during a motor imagery BCI e xperiment. Hereby , we mainly focused on the results regarding the in variance of representations and the across-subjects transfer learning capability of the models. Howe ver the proposed approach can be further extended in the context of semi- supervised transfer learning in BCIs, such as using a short calibration time for fine-tuning and semi-supervised transfer , learning session-inv ariant representations to reduce user- oriented BCI system calibration times, or learning disen- tangled representations that exploit adversarial censoring to learn partly subject-in variant, and partly subject-v ariant representations. W e highlight that these framew orks should be of significant interest in the field of neural interfaces. R E F E R E N C E S [1] M. Krauledat, M. T angermann, B. Blankertz, and K.-R. M ¨ uller , “T o- wards zero training for brain-computer interfacing, ” PloS one , vol. 3, no. 8, p. e2967, 2008. [2] H. Kang, Y . Nam, and S. Choi, “Composite common spatial pattern for subject-to-subject transfer , ” IEEE Signal Processing Letters , vol. 16, no. 8, pp. 683–686, 2009. [3] W . Samek, F . C. Meinecke, and K.-R. M ¨ uller , “Transferring subspaces between subjects in brain–computer interfacing, ” IEEE T ransactions on Biomedical Engineering , vol. 60, no. 8, pp. 2289–2298, 2013. [4] M. Alamgir , M. Grosse-W entrup, and Y . Altun, “Multitask learning for brain-computer interfaces, ” in Pr oceedings of the 13th International Confer ence on Artificial Intelligence and Statistics , 2010, pp. 17–24. [5] V . Jayaram, M. Alamgir, Y . Altun, B. Sch ¨ olkopf, and M. Grosse- W entrup, “Transfer learning in brain-computer interfaces, ” IEEE Com- putational Intelligence Magazine , vol. 11, no. 1, pp. 20–31, 2016. [6] H. Edw ards and A. Stork ey , “Censoring representations with an adversary , ” arXiv preprint , 2015. [7] A. Makhzani, J. Shlens, N. Jaitly , I. Goodfello w , and B. Frey , “ Ad- versarial autoencoders, ” arXiv preprint , 2015. [8] M. F . Mathieu, J. J. Zhao, J. Zhao, A. Ramesh, P . Sprechmann, and Y . LeCun, “Disentangling factors of variation in deep representation using adv ersarial training, ” in Advances in Neural Information Pr o- cessing Systems , 2016, pp. 5040–5048. [9] G. Lample, N. Zeghidour , N. Usunier, A. Bordes, L. Denoyer et al. , “Fader networks: Manipulating images by sliding attributes, ” in Ad- vances in Neural Information Processing Systems , 2017. [10] A. Creswell, A. A. Bharath, and B. Sengupta, “Conditional au- toencoders with adversarial information factorization, ” arXiv preprint arXiv:1711.05175 , 2017. [11] E. Tzeng, J. Hoffman, K. Saenko, and T . Darrell, “ Adversarial discriminativ e domain adaptation, ” in Computer V ision and P attern Recognition , vol. 1, no. 2, 2017, p. 4. [12] J. Shen, Y . Qu, W . Zhang, and Y . Y u, “ Adversarial representation learning for domain adaptation, ” arXiv preprint , 2017. [13] Y . W ang, T . K oike-Akino, and D. Erdogmus, “In variant represen- tations from adv ersarially censored autoencoders, ” arXiv preprint arXiv:1805.08097 , 2018. [14] D. P . Kingma and M. W elling, “ Auto-encoding variational Bayes, ” arXiv pr eprint arXiv:1312.6114 , 2013. [15] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farle y , S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial nets, ” in Advances in Neural Information Processing Systems , 2014. [16] V . J. Lawhern, A. J. Solon, N. R. W aytowich, S. M. Gordon, C. P . Hung, and B. J. Lance, “EEGNet: A compact conv olutional network for EEG-based brain-computer interfaces, ” arXiv pr eprint arXiv:1611.08024 , 2016. [17] R. T . Schirrmeister , J. T . Springenber g, L. D. J. Fiederer, M. Glasstet- ter , K. Eggensperger, M. T angermann, F . Hutter, W . Burgard, and T . Ball, “Deep learning with conv olutional neural networks for EEG decoding and visualization, ” Human Brain Mapping , vol. 38, no. 11, pp. 5391–5420, 2017. [18] P . Bashivan, I. Rish, M. Y easin, and N. Codella, “Learning represen- tations from EEG with deep recurrent-conv olutional neural networks, ” arXiv pr eprint arXiv:1511.06448 , 2015. [19] Y . Luo and B.-L. Lu, “EEG data augmentation for emotion recognition using a conditional W asserstein GAN, ” in International Conference of the IEEE Engineering in Medicine and Biology Society , 2018. [20] K. G. Hartmann, R. T . Schirrmeister , and T . Ball, “EEG-GAN: Gen- erativ e adversarial networks for electroencephalograhic (EEG) brain signals, ” arXiv preprint , 2018. [21] K. Sohn, H. Lee, and X. Y an, “Learning structured output representa- tion using deep conditional generati ve models, ” in Advances in Neural Information Pr ocessing Systems , 2015, pp. 3483–3491. [22] A. L. Goldberger , L. A. Amaral, L. Glass, J. M. Hausdorff, P . C. Ivano v , R. G. Mark, J. E. Mietus, G. B. Moody , C.-K. Peng, and H. E. Stanley , “Physiobank, physiotoolkit, and physionet: components of a new research resource for complex physiologic signals, ” Circulation , vol. 101, no. 23, pp. e215–e220, 2000. [23] G. Schalk, D. J. McFarland, T . Hinterberger , N. Birbaumer , and J. R. W olpaw , “BCI2000: a general-purpose brain-computer interface (BCI) system, ” IEEE T ransactions on Biomedical Engineering , v ol. 51, no. 6, pp. 1034–1043, 2004. [24] G. Pfurtscheller and C. Neuper, “Motor imagery and direct brain- computer communication, ” Pr oceedings of the IEEE , vol. 89, no. 7, pp. 1123–1134, 2001. [25] S. T okui, K. Oono, S. Hido, and J. Clayton, “Chainer: a next- generation open source framework for deep learning, ” in Pr oceedings of W orkshop on Machine Learning Systems in the 29th Annual Confer ence on Neural Information Pr ocessing Systems , 2015. [26] D. P . Kingma and J. B. Adam, “ A method for stochastic optimization, ” in International Confer ence on Learning Repr esentations , vol. 5, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment