Binaural Source Localization based on Modulation-Domain Features and Decision Pooling
In this work we apply Amplitude Modulation Spectrum (AMS) features to the source localization problem. Our approach computes 36 bilateral features for 2s long signal segments and estimates the azimuthal directions of a sound source through a binaural…
Authors: Semih Au{g}caer, Rainer Martin
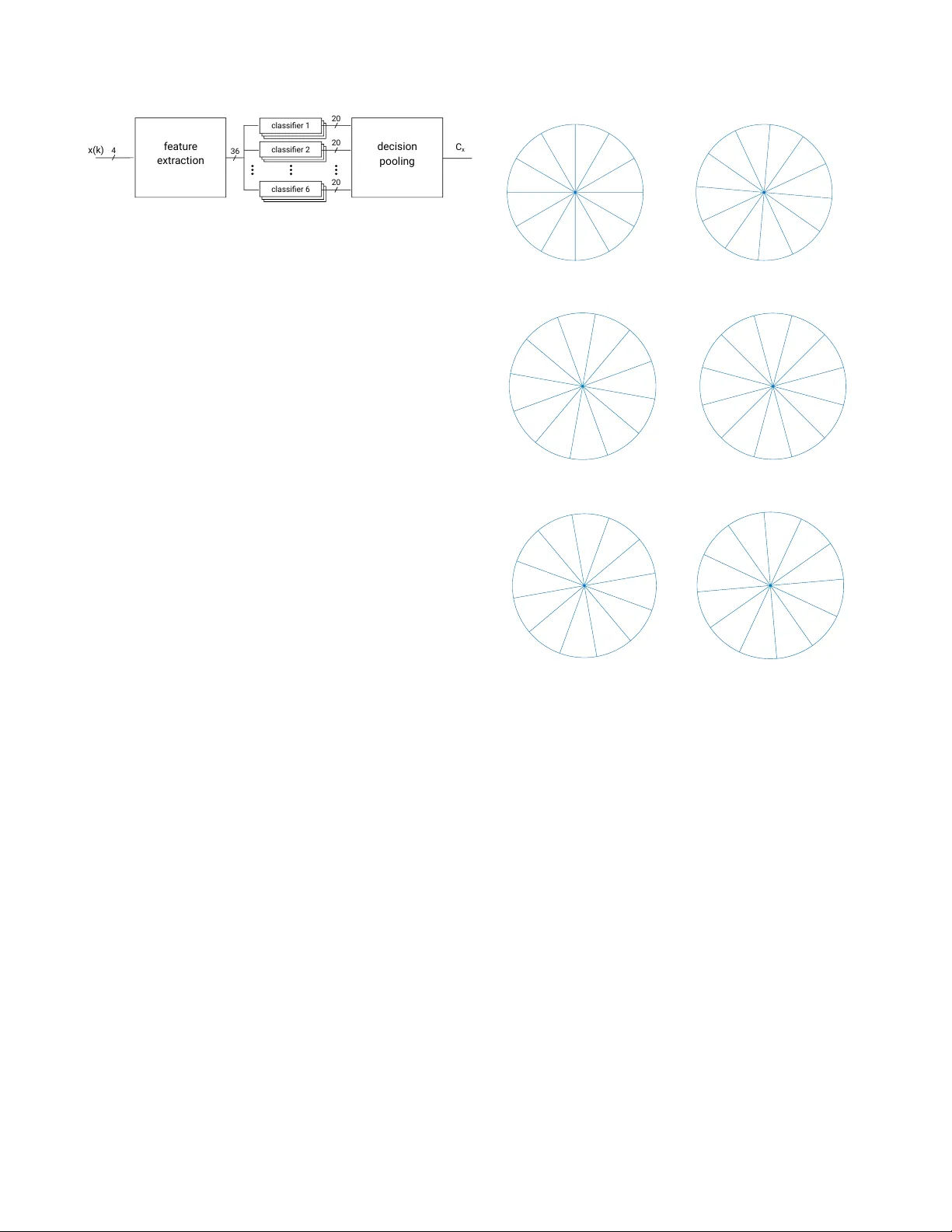
LOCA T A Challenge W orkshop, a satellite ev ent of IW AENC 2018 September 17-20, 2018, T okyo, Japan BINA URAL SOURCE LOCALIZA TION B ASED ON MODULA TION-DOMAIN FEA TURES AND DECISION POOLING Semih A ˘ gcaer and Rainer Martin Ruhr-Uni versit ¨ at Bochum, Institute of Communication Acoustics, Bochum, Germany { semih.agcaer , rainer .martin } @rub.de ABSTRA CT In this work we apply Amplitude Modulation Spectrum (AMS) features to the source localization problem. Our approach computes 36 bilateral features for 2s long signal segments and estimates the azimuthal directions of a sound source through a binaurally trained classifier . This direc- tional information of a sound source could be e.g. used to steer the beamformer in a hearing aid to the source of interest in order to increase the SNR. W e ev aluated our ap- proach on the de velopment set of the IEEE-AASP Challenge on sound source localization and tracking (LOCA T A) and achiev ed a 4.25 ◦ smaller MAE than the baseline approach. Additionally , our approach is computationally less complex. Index T erms — localization, model-based optimization, amplitude modulation spectrum 1. INTR ODUCTION Source localization is an important task in man y acoustic sig- nal processing applications. An estimated azimuthal source direction could be e.g. incorporated in an acoustic signal processing system using an adapti ve beamformer to steer the beamformer into the direction of the source and thus to im- prov e the SNR. In our pre vious work, we proposed an Amplitude Modu- lation Spectrum (AMS) based feature extraction algorithm which we successfully used for acoustic scene classification [1]. The feature e xtraction is based mainly on two succes- siv e filter banks, non-linear operations, and a final av eraging step. In this paper , we apply these amplitude modulation fea- tures to the speaker localization task. For this we e xtract 4x9 features from the four cardioid signals of hearing aid micro- phones. W ith these 36 features a source azimuth is estimated for each 2s long signal segment by pooling decisions from a set of six classifiers. In contrast to other common approaches, we do not compute any interaural phase/time difference (IPD/ITD) and/or inter- aural lev el differences (ILD) explicitly like in [2, 3, 4, 5]. W e compute nine AMS-based features separately for each cardioid signal and then concatenate them to a feature vec- tor with a length of 36. Ho wev er, the 36 AMS features will spectr al ana lysis x(k) 4 modulation ana lysis N f Figure 1: AMS based modulation-domain feature extraction system implicitly contain ILD information. It should be noted that AMS-based features are inspired by the human auditory sys- tem and are successfully used for acoustic scene classifica- tion tasks [1, 6, 7, 8, 9]. W e ev aluate the performance of the proposed method on the dev elopment set of the LOCA T A Challenge [10]. The LO- CA T A Challenge of fers six different tasks from which we chose the first one, which is localization of a single static source with a static microphone array . In the next sections of this paper, we will recap our AMS- based features, describe our classification system and our training data. Then, in Section 3, we ev aluate our proposed approach on the LOCA T A Challenge corpus and present the results. Section 4 concludes this paper with a discussion of these results. 2. METHODS 2.1. Modulation-Domain Featur e Extraction Our feature extraction approach is similar to the approach we proposed for the DCASE Challenge 2013 [11] which is described in detail in [1]. The feature extraction is depicted in Figure 1 and it mainly consist of tw o blocks. First, the input signals are spectrally analyzed by N s bandpass filters and then the amplitude modulation in each spectral bins are analyzed by N m different filters and a veraged over the frame length T s . For the LOCA T A Challenge we set N s = 3 and N m = 3 to three and the frame length T s = 2 s. Instead of using a sin- gle microphone signal for the DCASE challenge we use the microphone signals of hearing aid dummies and extract four cardioid signals (front left, front right, back left and back LOCA T A Challenge W orkshop, a satellite ev ent of IW AENC 2018 September 17-20, 2018, T okyo, Japan classi fi er 1 classi fi er 2 classi fi er 6 f eatur e extr action x(k) 4 36 decision pooling 20 20 20 C x Figure 2: Classification system based on decision pooling. right) by feeding the microphone signals into the respectiv e beamformers. These four cardiod signals are then fed in parallel into the AMS feature extraction algorithm which outputs N f = 4 · N s · N m = 36 features for one frame. The passband range of each filter in the filterbanks is found by an iterativ e optimization method. W e optimize the pass- band ranges by a model-based optimization (MBO) ap- proach. The MBO is an iterative approach for the optimiza- tion of a black box objective function. It is used when the ev aluation of an objectiv e function, in our case the classifi- cation error depending on different filter bank parameters, is expensi ve in terms of av ailable resources (computational time). MBO tries to construct an approximation model, a so called surrogate model, of this expensiv e objective function to find the optimal parameter for a giv en problem. The ev al- uation of the surrogate model is cheaper than the original objectiv e function. For a more detailed description of MBO we refer to [12, 13]. 2.2. Classification and Decision Pooling Our classification system, which is depicted in Figure 2, con- sist of six classifier sets each with a resolution of 30 ◦ . Any individual classifier can therefore distinguish between 12 dif- ferent classes. The class definitions for each set is dif ferent and is depicted in Figure 3. The six class definitions differ by 5 ◦ shifts leading to 72 discrete speaker directions and a the- oretical final speaker localization resolution of 5 ◦ if all six classifiers results are combined. The classifier used in our system is a Linear Discriminant Analysis (LD A) classifier . For each 2s signal frame we run fi ve 4-fold cross-v alidations for each classifier set leading to 20 · 6 = 120 classifiers in total. In all classifiers we fed in the same 36 AMS features we extracted before. The final speaker localization for one recording was determined by pooling the classification deci- sion for each of the 72 azimuth bins over all 120 classification results for each frame in one recording and av erage the two most frequent azimuth estimates. 2.3. T raining Data For training our classification system we created a data set with a speaker from 72 directions spaced in 5 ◦ steps i.e. from 0 ◦ , 5 ◦ , . . . , 355 ◦ . The data set was rendered using the Old- 0 30 60 90 120 150 180 210 240 270 300 330 1 2 3 4 5 6 7 8 9 10 11 12 (a) classifier set 1 25 55 85 115 145 175 205 235 265 295 325 355 1 2 3 4 5 6 7 8 9 10 11 12 (b) classifier set 2 20 50 80 110 140 170 200 230 260 290 320 350 1 2 3 4 5 6 7 8 9 10 11 12 (c) classifier set 3 15 45 75 105 135 165 195 225 255 285 315 345 1 2 3 4 5 6 7 8 9 10 11 12 (d) classifier 4 10 40 70 100 130 160 190 220 250 280 310 340 1 2 3 4 5 6 7 8 9 10 11 12 (e) classifier set 5 5 35 65 95 125 155 185 215 245 275 305 335 1 2 3 4 5 6 7 8 9 10 11 12 (f) classifier set 6 Figure 3: Class definition of the 6 classifier sets in de- grees. Each classifier can distinguish between12 classes, where each class cov ers a range of 30 ◦ . enbur g HR TF data set (behind-the-ear hearing aids)[14] and various speech and noise data sets. For each direction we cre- ated 18 x 10s audio files with v ariation in SNR le vel, speaker and noise type, which led to training set with a total duration of 3h 36min. 3. RESUL TS The development data set of the LOCA T A Challenge consists of three recordings for the hearing aid microphone configura- tion. The audio signals have a sampling frequency of 48kHz which were decimated to 20kHz. The left front, left back, right front and right back microphones of the hearing aid were fed into a beamformer leading to four cardioid signals. From this four cardioid signals we compute our 36 features. LOCA T A Challenge W orkshop, a satellite ev ent of IW AENC 2018 September 17-20, 2018, T okyo, Japan Recording Azimuth error in degree 4 -9.86 ◦ 5 -2.61 ◦ 6 +2.39 ◦ MAE 4.95 ◦ T able 1: Azimuth error for each recording and the mean ab- solute error (MAE) for the dev elopment set. W e run our experiments on a PC with Intel(R) Core(TM) i5- 3470 CPU @ 3.20GHz with 12GB RAM and Matlab 2017b 64-Bit. T able 1 sho ws the azimuth error for each recording in the dev elopment data set. W e compute a single estimate for each whole audio file by pooling o ver 2s long frames and assigned these to the required time stamps of the audio database. The achie ved mean absolute error (MAE) is 4.95 ◦ , which is 4.25 ◦ better than the baseline MUSIC algorithm. In order to compare the computational efficienc y of our ap- proach to the baseline MUSIC algorithm we used the real time factor (R TF) as a measure, which is defined as the com- putation time for one recording divided by the duration of the recording. The mean R TF for the baseline MUSIC algorithm is 9.1 on our hardware setup, which means that it is not real time capable. In contrast, our proposed speaker localization approach has a mean R TF of 0.7 and is thus real time capable. It is 13 times faster than the baseline MUSIC algorithm. 4. DISCUSSION AND CONCLUSION In this paper, we sho wed that our AMS feature extraction algorithm, which was used for audio scene classification be- fore [1], could be also adapted for speaker localization. W e trained our system with a training set rendered with the Old- enbur g HR TF set and ev aluated our trained system on the publicly av ailable LOCA T A challenge de velopment data set with one static speaker . The mean absolute azimuth estima- tion error of 4.95 ◦ is by 4.25 ◦ lower than the baseline with the additional advantage of being computationally less com- plex. It is up to 13 times faster and with a R TF of 0.7 real time capable on PC hardware. Our system does not explicitly computed any IPD, ITD or ILD informations. This makes it less dependent on the head- size and also eliminates the problem of phase synchroniza- tion which is required for computing IPD/ITD. Howe ver , we assume that our features implicitly contain ILD information in the modulation patterns. 5. REFERENCES [1] S. A ˘ gcaer , A. Schlesinger, F . Hoffmann, and R. Mar- tin, “Optimization of amplitude modulation features for low-resource acoustic scene classification, ” in 2015 23r d Eur opean Signal Pr ocessing Conference (EU- SIPCO) , Aug 2015, pp. 2556–2560. [2] H. Puder , E. Fischer , and J. Hain, “Optimized direc- tional processing in hearing aids with integrated spa- tial noise reduction, ” in IW AENC 2012; International W orkshop on Acoustic Signal Enhancement , Sept 2012, pp. 1–4. [3] D. Y ing and Y . Y an, “Robust and f ast localization of single speech source using a planar array , ” IEEE Signal Pr ocessing Letters , vol. 20, no. 9, pp. 909–912, Sept 2013. [4] S. Lee, Y . Park, and Y . Park, “Cleansed phat gcc based sound source localization, ” in ICCAS 2010 , Oct 2010, pp. 2051–2054. [5] M. Zohourian, G. Enzner, and R. Martin, “Binaural speaker localization integrated into an adaptive beam- former for hearing aids, ” IEEE/A CM T ransactions on Audio, Speech, and Language Pr ocessing , v ol. 26, no. 3, pp. 515–528, March 2018. [6] J. Anem ¨ uller , D. Schmidt, and J. Bach, “Detection of speech embedded in real acoustic background based on amplitude modulation spectrogram features, ” in In- terspeech 2008 9th Annual Confer ence of the Inter- national Speech Communication Association . Inter- speech, 2008, pp. 2582–2585. [7] J. Bach, J. Anem ¨ uller , and B. Kollmeier , “Robust speech detection in real acoustic backgrounds with perceptually moti vated features, ” Speech Communi- cation , vol. 53, no. 5, pp. 690 – 706, 2011, perceptual and Statistical Audition. [Online]. A v ail- able: http://www .sciencedirect.com/science/article/pii/ S0167639310001305 [8] G. Langner , M. Sams, P . Heil, and H. Schulze, “Fre- quency and periodicity are represented in orthogonal maps in the human auditory cortex: evidence from magnetoencephalography . ” J Comp Physiol A , v ol. 181, no. 6, pp. 665 – 676, 1997. [9] N. Moritz, J. Anem ¨ uller , and B. Kollmeier , “ Ampli- tude modulation spectrogram based features for ro- bust speech recognition in noisy and rev erberant en- vironments, ” in 2011 IEEE International Conference on Acoustics, Speech and Signal Pr ocessing (ICASSP) , May 2011, pp. 5492–5495. [10] H. W . L ¨ ollmann, C. Evers, A. Schmidt, H. Mellmann, H. Barfuss, P . A. Naylor , and W . K ellermann, “The LO- CA T A challenge data corpus for acoustic source local- ization and tracking, ” in IEEE Sensor Array and Multi- channel Signal Pr ocessing W orkshop (SAM) , Sheffield, UK, July 2018. LOCA T A Challenge W orkshop, a satellite ev ent of IW AENC 2018 September 17-20, 2018, T okyo, Japan [11] D. Giannoulis, E. Benetos, D. Stowell, M. Rossignol, M. Lagrange, and M. Plumbley , “Detection and classi- fication of acoustic scenes and ev ents: An IEEE AASP challenge, ” in 2013 IEEE W orkshop on Applications of Signal Pr ocessing to A udio and Acoustics (W ASP AA) , Oct 2013, pp. 1–4. [12] A. Forrester , A. Sobester , and A. K eane, Engineering Design via Surr ogate Modelling: A Practical Guide . W iley , September 2008. [Online]. A v ailable: http: //amazon.com/o/ASIN/0470060689/ [13] C. W eihs, S. Herbrandt, N. Bauer , K. Friedrichs, and D. Horn, “Efficient global optimization: Motiv ation, variations, and applications, ” in ARCHIVES OF D AT A SCIENCE , 2016. [14] H. Kayser , S. D. Ewert, J. Anem ¨ uller , T . Rohden- bur g, V . Hohmann, and B. K ollmeier , “Database of multichannel in-ear and behind-the-ear head-related and binaural room impulse responses, ” EURASIP Journal on Advances in Signal Pr ocessing , vol. 2009, no. 1, p. 298605, Jul 2009. [Online]. A v ailable: https://doi.org/10.1155/2009/298605
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment