Voice Disorder Detection Using Long Short Term Memory (LSTM) Model
Automated detection of voice disorders with computational methods is a recent research area in the medical domain since it requires a rigorous endoscopy for the accurate diagnosis. Efficient screening methods are required for the diagnosis of voice d…
Authors: Vibhuti Gupta
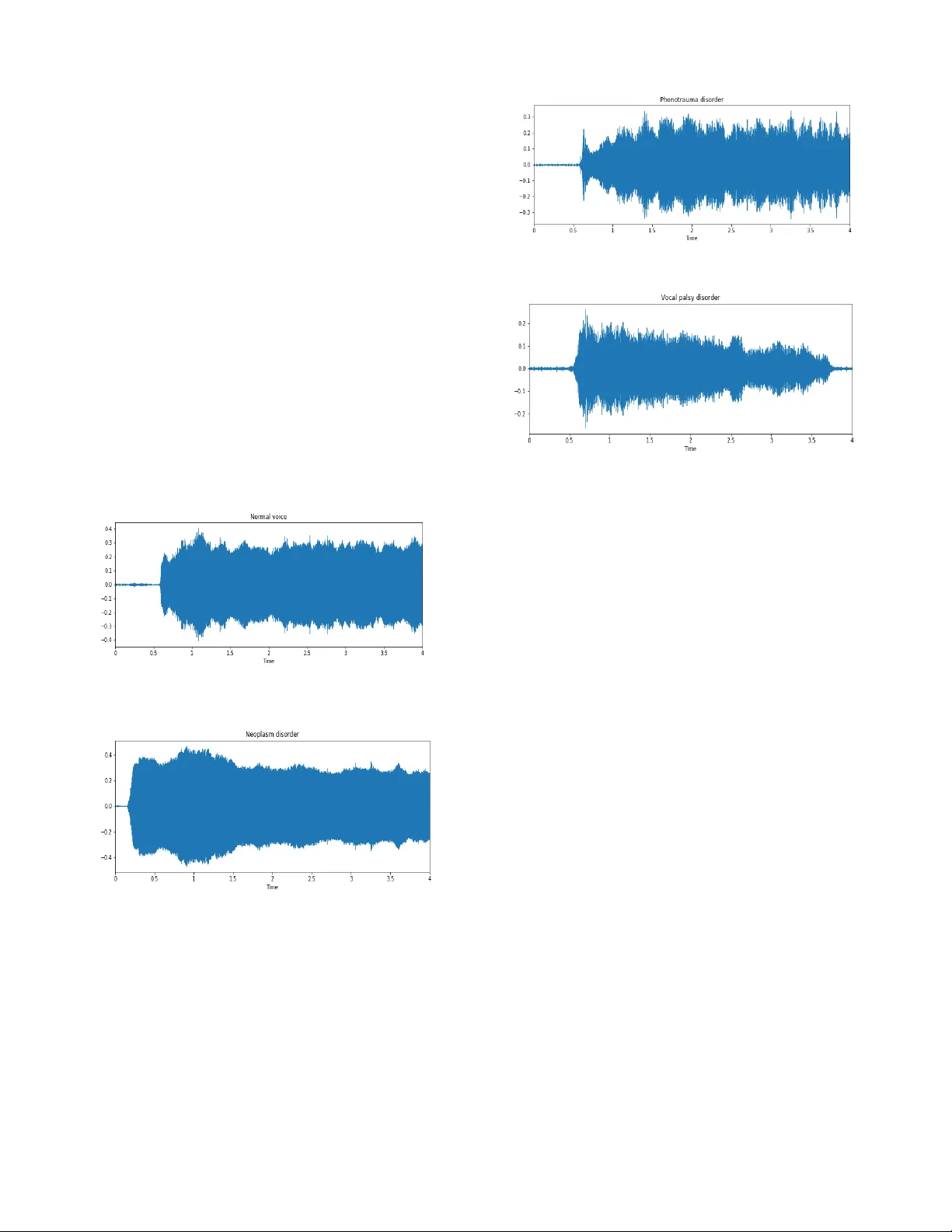
Voice Disorder Detection Using Long Short Term Memory (LSTM) Model Vibhuti Gupta Department of Co mputer Science Texas T ech University, Lubbock, TX 79415 Email: vibhuti.gupta@tt u.edu Abstract — Automated detection of voice disorders with computationa l m ethods is a recent research area in the medical domain since it requires a rigoro us endoscopy fo r the accurate dia gnosis. Efficient scree ning methods are required for the diagnosis of voice disorders so as to provid e timely medical facilities in minimal resources. Detecting Vo ice disorder using co m putational m ethods is a challenging proble m since audio data is co ntinuous due to which extracting relevant features a nd applying machi ne learning is hard and unreliable. This paper proposes a Long short term memory model (LSTM) to detect pathological voice disorde rs and evaluates its performance in a real 400 testing sa mples without any labels. Different feature extra ction methods are used to provide the best set of features before applying LSTM model for classification. The paper describes the a pproach and exper iment s that show promising results with 22 % sensitivity, 97% specificity and 56% unweighted av erage recall . Keywords — Neoplasm ; Phonotrauma ; Vocal Paralysis ; Lo ng Short Term Memory ; Mel frequency cepstral coefficient I. I NTRODU CTION A voice disor der occurs due to disturbance in respirator y, laryngeal, subglottal vocal tract or physiological imbalance among t he system which ca uses abnormal voice quality, p itch and loudness as co mpared to normal voice of a healthy person[2 1] . Major v oice disorders in clude vocal nodules polyps, and cysts (col lectiv ely referred as Phonotrau ma) , glottis neoplasm ; and unilateral vocal paraly sis . Voice disorders may affect a person ’ s socia l, professi onal and personal aspects of communicati on which hinder s i ts growth in all these aspects [ 2 ]. Current approaches f or v oice dis order detection requires rigorous endoscopy (i.e. lary ngeal endosco py) which is a multiste p examin ation includi ng mirror examin ation, rigi d and flexible lary ngoscopy and videostrobosc opy [1][ 22 ]. This rigorous examination requires a lot of expensive medical resources and delay s the diagnosis of voice disorde rs due to which treatment get delayed which worsen the se verity of the disease. Sometim es voice disorders remain un identified s ince they are consider ed as normal by most of the people d ue to inefficient an d slow screening meth ods. Accu racy in diagnosis is also im portant to cure th e c orrect disorder w ith proper treatm ent. Autom ated detection of voi ce disorder s is crucial t o mitig ate these p roblems since it m akes the diagn osis pro cess simpler, chea per and less time consumin g. Rec ent research on computeriz ed detect ion of voice diso rders has studie d variou s machin e learning te chniques and f ew deep lea rning t echniques [3-5, 6- 10 , 1 1-13 ]. Majo rity of th e previous work deals with machin e learn ing techniques for voice disorder detecti on [3, 4]. [3] use d rule based analy sis by analy zing vari ous acous tic measures such as Fundam ental Frequen cy, jitter , shimm er etc. and then ap plied logistic mod el t ree algorithm , instan ce based learning and SVM algorithm s while [4 ] used SVM and decision trees for detecting voice d isorders . Muhammad et. al [5] used gaussian mixture model ( GMM ) to classify 6 dif ferent types of voice dis orders . Deep learnin g is widely used now adays for image recognit ion, music genre cl assificati on and various other applicati ons. It is rec ently used f or voic e d isorder detection tasks [6-10 ] . Most recently [6] applied d eep neural networks ( DNN ) for voice diso rder detection using dataset of Far Eastern Memorial Hospital ( FEMH ) with 60 normal voice samples and 402 vari ous voice disorder s amples and ac hieved the highest accuracy as compared to other machin e learning approaches. Authors at [7] discussed the use of deep neu ral network s (DNN) in acousti c m odeling. T hey have ap plied DNN in various speech re cognition tasks and f ound t hat DNN ’ s are perform ing w ell . Wu et. al [8] used convolu tional ne ural netw ork (CNN) for vocal cord paralysis which is a challengi ng medical classif ication proble m. Alhussein et. al [ 9] applied deep learning into a mobile healthcare fram ework to detect voice dis order. Despite the success of above mention ed models, recu rrent neural netw orks (RNN) are not used for voice disorder tasks. Recurrent neura l networks are widely used for speech recognit ion, music genre classif ication, natural language processing and sequence predicti on problem s [1 1-12] . Long short te rm mem ory (LSTM) is a special type of recur rent neural n etwork which is widely used for l ong t erm dependencies . [1 1 ] used L STM for voice activity detection which sepa rates the inc oming spe ech with noise. Convolu tional neural networks are used along w ith LSTM in [12] to determ ine dysarthric speech disorde r. To the best of our knowledge, non e of the stu dies used LSTM for v oice dis order detecti on task. Our major contributions in this paper are: (1) t o propose a n approach to detect pathologi cal voice disorde rs using L ong short term memory (LST M) model. (2) to evaluate LSTM perform ance in differentiating normal and pathologi cal voice samples. The rest of the paper is o rganized as follo ws. Sect ion II discusses the material and methods. Sectio n I II describe s our experi mental setup along with results an d Sectio n I V concludes the paper . II . MET HOD Th is section provides a brief overview of our proposed approach with the general de scription of Long short Te rm memory Model (LSTM ) used in our exper iments and description of d ataset with prep rocessi ng par t . A. Overview of propose d approa ch Our proposed app roach starts b y loading the input voice samples provided by Fa r Eastern M emorial Hospital ( FEMH) voice disorder detection challen ge [1 6] as show n in Figure 1 which includes 50 normal voice samples and 150 samples o f common vo ice diso rders, including v ocal nodules, poly ps, and cysts (coll ectively referre d as Phonot rauma) ; glottis ne oplasm ; and unil ateral vocal paralys is, that compris es of our training dataset. Fig. 1 Overv iew of proposed approac h Feature extraction process is done after loading the data that includes Mel -frequency cepstr al coefficients (MFCC), spectral centroid, chrom a and spectral contrast fe atures comprisin g 33 features for each audi o sample . Details are provided in the fur ther secti ons. Then LS TM model is us ed to train the model w hich is use d for c lassification . B. Long Short Term Mem ory (LSTM) Model L on g Short term Memory Netw ork (LSTM) are the special type of Recurrent Neural netw orks capable of learning long term dependencies [ 17]. A typical LSTM network has 4 laye rs i.e. input lay er, 2 hidden l ayers and one output layer. It contains th ree gates forget gate , Input gat e and Out put gate . Fig . 2 L STM Networ k Forget gate layer decides what information has to be kept or thrown away fro m th e cell state. I t takes input as h t-1 and x t and outputs a number b etween 0 and 1 us ing f t as in the Eqn(1). Value of 0 indicates co mpletely remove a nd 1 to completely keep this. f t = σ (W f [h t-1 , x t ] + b f (1) Now we need to dec ide what information has to be stored in the cell state. It has two parts , firstly input gate la yer using to decide w hat val ues ha s to be updated and then tanh layer generates a vector of new ca ndidate values tha t has to b e added. i t is the f unction used by input gate layer and C is the vector of new ca ndidate valu es by tan h la yer as shown in the Eqn (2) and (3) . i t = σ (W i [h t-1 , x t ] + b i (2) C = tanh(W C [h t-1 , x t ] + b C (3) Updated state o f cell is shown in Eq n (4) C t = f t *C t-1 + i t * C (4) Finally, we need to decide what will be t he output usi ng output gate. First we r un the sigmoid la yer usin g o t as shown in the Eqn (5) and then its output is mu ltiplied by ta nh to get the output which is shown in Eq n. (6) o t = σ (W o [h t-1 , x t ] + b o (5) h t = o t *tanh(C t ) (6) output class = σ (h t * W outparameter ) (7) The o utput class o f the LSTM network i s det er mined b y the Eqn. (7) W f , W i , W C , W o , W outparameter are the weights , b f , b i , b C , b o are the biases, h t is the output at time t , x t are the input features and outp ut class is the classification o utput. Loading FEMH voice disorder Detection Dataset Feature Extraction Long Short Term Memory (LSTM) Training Trained LSTM model Classification C. Dataset and Pre processing The dataset comprises of 200 samples in the training se t and 400 samples in the testing set. Out of 150 co mmon voice disorder samples, 40 are for glottis neoplasm , 60 for Phonotraum a and 50 are for vocal palsy in the trainin g set. The labels of tr aining dataset inclu des gender, age , wheth er the speaker is healthy or not an d the co rresponding voice disease. Voice sam ples of a 3 -second sustained vowel sound were recorded at a comfortable lev el of loudness , w ith a microphone- to -m outh distance of approximately 15 – 20 cm, using a high-quality m icrophone (Mo del: SM5 8, SHUR E, IL), with a digital amplifier (Model: X2u, SHURE) under a backgroun d noise level between 40 and 45 dBA. T he samplin g rate was 44,100 Hz with a 1 6-bit resoluti on, and data were saved in an uncompressed .wav form at as used in [6]. Furt her dataset inf ormation is given in [6] [16]. Visualizat ion of voic e sam ples is done u sing the w aveform s as sh own in Figures 3,4,5,6. It shows wavef orm whose y-ax is represents the amplitu de of voice sample and x-axis as tim e duration. We pl otted 4 s ecs duration of each ty pe of voic e sample w ith a sam pling rate of 22050 H z. Fig . 3 Wave form of Normal Voice Sample Fig . 4 Wave form of N eo plasm Voice disorder Sam ple As shown in Figures 3 and 4 normal voice sample amplitude is fluctuating while neo plasm d isorder w aveform not . Wavefor ms for phonotrauma and vocal palsy a s sho wn in Figures 5 and 6 shows var iati ons as co mpared to nor mal and neoplasm voice samples. Amplit udes for Phonotrauma disorder are fluctuating and increasing while for voca l palsy , its decreasing. Nor mal v oice sample ca n be eas ily distinguishable with Phonotr auma and Vocal palsy disorder but not much with Ne oplasm disord er. Fig . 5 Wave form of Phonotraum a Voice disorder Sample Fig . 6 Wave form of Vocal Palsy Voi ce d isorde r Data preprocessing includes fea ture extraction using different methods such as Mel -frequency cepstra l coeffici ents (MFCC), spectral centr oid, chroma and spectra l contrast etc. Fo r each voice sample we extracte d 33 features combinin g all the featu re ext raction techniques. A brief overv iew o f vari ous feature extraction techniqu es are provide d in below sections. a) Mel Frequency cepstral Coefficients (MF CC) : MFCC features are widely used in mus ic genre classification, audio classifi cation and spee ch recogn ition tasks, so we use d it in thi s work. We extracted 13 MFCC f eatures from each voi ce sample. More details on ext racting MFCC features can be found at [18 ]. b) S pectral Centro id : Spectr al centroid p rovides the center of ma ss o f t he spectrum. It provides the a verage loudness in terms of aud io pr ocessing. One feature is extracted from each audio sample using spectral centroid. More details can be found at [1 9 ]. c) Ch roma : Chroma provides a chrom agram from a waveform. 12 features are extracted using chroma from each audio sample. Mor e details can be found at [ 20 ]. d) S pectral Contrast : Spectral contrast r epresents t he spectral characteristics o f audio sample. We extracted 1 3 features using spectral contrast from eac h audio sample. Mo re details can be found at [ 13] . I II . EXPERIME NTS AND RESUL TS This sectio n provides t he experi ments and result s t o evaluate the effectiveness o f our approach. The design of ou r LSTM network is shown in T able I sho wing one input la yer with all 33 features extracted from eac h voice sam ple,2 hidden layers out of which firs t hidden layer has 1 28 neu rons w hile second one has 32 neu rons and one o utput layer fo r pre dicting whether the voice sample is normal or having a voice disord er. We used the sam e ex perimental setup as [ 14 ] which w as used for m usic genre c lassificat ion as i t provide d prom ising result s. Table I : Design of L STM Network Input Layer 33 Input feature s extracted from audi o samples Hidden Layer I 128 neurons Hidden Layer II 32 neurons Output Layer 4 outputs correspo nding to 3 diffe rent voice disorders and 1 normal voice For training the LS TM model , optimize r used is Adam s [ 15 ] while d ifferen t batch s izes and ep ochs are use d to get t he best results . Categ orical cross entr opy is used as a loss function to m easure th e perf ormance o f classificat ion m odel at ea ch epoch. Increasing the num ber of epochs helps in improving the perform ance of the m odel. Table II : Results of tw o phases Result Ph ase Sensitivity Specificity UAR I 30% 95.7% 54% II 22% 97.1% 56% Ta ble II shows the results o btained in two phases o f results in FEMH Big data cup challenge. As we can see specificity is high in both the phases but sen sitivity is low. Se nsitivit y de termines the true positive rate while sp ecificity true negati ve rate. Results sh ow t hat normal voice people are correctly identified as normal as co mpared to the peo ple with the voice disorder but unweighted average rec all ( UAR) represents the mean o f recalls for both classes which increases with the number of epoch s. In phase I w e ru n the experi ment for 500 epochs but in Phase II we run it for 5000 epochs . Our r esults s how t hat our approach w orks fine but requires more optimization in the fut ure for better results. IV . CONCLUSION This study p resents a long short term memory ( LSTM) approach to detec t pathological voice d isorders. The results show that it works fine in detecting the disorders . Also, different feat ure extraction techniques s hows that th ese features can be b eneficial for voice disord er detection. Futu re work includes more experiments with di fferent hyperparameters to improve the results and u se other feature extraction tech niques too for further impro vement. REFERENCES [1] Schw artz SR, Cohen SM, Dailey SH , et al. Clinical practice guideline: hoarseness (dysphonia). O tolaryngol He ad Neck S urg. 2009; 141:S1 – S31. [2] He gde, S., Shetty, S., Rai, S., & Do dderi, T. (2018). A Surve y on Machine Learning Approa ches for Automatic Detection of Voice Disorders. Journal of Voice. [3] Cesari, U., De Pie tro, G ., Marciano, E., Niri, C., Sannino, G., & Ve rde, L. (2018). Voice Disorder Detection via an m -Healt h System: Design and Results o f a C linical Study to Evaluate Vox4Health. BioMed research interna tional, 2018. [4] Ve rde, L., De Pietro, G., & Sannino, G. (2018). Voice Disorder Identification by using Machine Learning Techniques. I EEE Access. [5] Muhamm ad G, M esallam TA, Malki KH, et al. Multidirectional regression (MDR)-based features for automatic voice d isorder detection. J Voice. 2012; 26. 817.e19−817.e 27. [6] F ang, S. H., Tsao, Y., Hsiao, M. J., Chen, J. Y., Lai, Y. H., Lin, F. C., & Wang, C. T. ( 2018). Detectio n of Patholog ical Voice Using Ceps trum Vectors: A Deep Learning A pproach. Journal of Voice. [7] Hinto n G, De ng L , Yu D , et al. Dee p neural networks for acoustic modeling in spe ech recognition. I EEE Signal Proc M ag. 2012;29:82 – 97. [8] W u, H., Sorag han, J., L owit, A., & Di Caterina, G. (2018). A deep learning method for pat hological voice detection using convolut ional deep belief networks. Interspee ch 2018. [9] Al hussein, M., & Muhamma d, G. (2 018). Vo ice Patholo gy Dete ction Using Deep Learning on Mobile Healthcare Framewor k. IEEE Access, 6, 41034-4 1041. [10] Harar, P., Alonso-Hernandezy , J. B., Mekyska, J., Galaz, Z., Burget, R., & Smekal, Z. (2017, July). Voice p athology detection using deep learning: a p reliminary study. In Bioinspired I ntelligence (IWOBI), 2017 I nternational Confere nce and Workshop on (pp. 1-4). IEEE. [11] Kim, J., Kim, J ., L ee, S., P ark, J., & Hahn, M. (2016, Nov ember). Vowel based voice activity detection with LSTM recurrent neural networ k. In Proceedings of the 8th International Co nference on Signal Processing Sy stems (pp. 134-137). A CM. [12] Kim, M., C ao, B. , An, K., & W ang, J . ( 2018). Dysarthric S peech Recognition Using Convolutional LSTM Neural Network. Proc. Interspeech 2 018 , 2948-2952. [13] Jiang, D. N., Lu, L., Zhang, H. J., Tao, J. H., & Cai, L. H. (2002). Music type classification by spectral contrast feature. In Multimedia and Expo, 2002. I CME'02. Procee dings. 2002 IEEE I nternational Confe rence on (Vol. 1, pp. 1 13-116). IEEE. [14] Tang, C. P., Chui , K. L ., Yu, Y. K., Zeng, Z., & Wong, K. H. (2018). Music G enre classificatio n us ing a hierarchical Long Sh ort T erm Memory (L STM) model. [15] Kingma, D. P., & Ba, J. (2014). A dam: A method for stochastic optimization. arXiv preprint arXiv: 1412.6980. [16] FEMH c halle nge, A ccessed A ugust 201 8, U R L: https://femh- challenge2018.w eebly.com/ [17] Christopher Olah. U nderstanding lstm n etwor ks. GITHU B blog, posted on August, 27, 20 15 [18] https://en.wikipedia.or g/wiki/Mel-frequency _cepstrum [19] https://en.wikipedia.or g/wiki/Spectral _centroid [20] https://labrosa.ee.col umbia.edu/matlab/ chroma-ansyn/ [21] https://www.asha.org /practice-portal/clinical-topics /voice-disor ders/ [22] https://voicefoundatio n.org/hea lth -science/voice-disorders/ove rview- of - diagnosis-treatme nt-prevention/
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment