Multi-talker Speech Separation with Utterance-level Permutation Invariant Training of Deep Recurrent Neural Networks
In this paper we propose the utterance-level Permutation Invariant Training (uPIT) technique. uPIT is a practically applicable, end-to-end, deep learning based solution for speaker independent multi-talker speech separation. Specifically, uPIT extend…
Authors: Morten Kolb{ae}k, Dong Yu, Zheng-Hua Tan
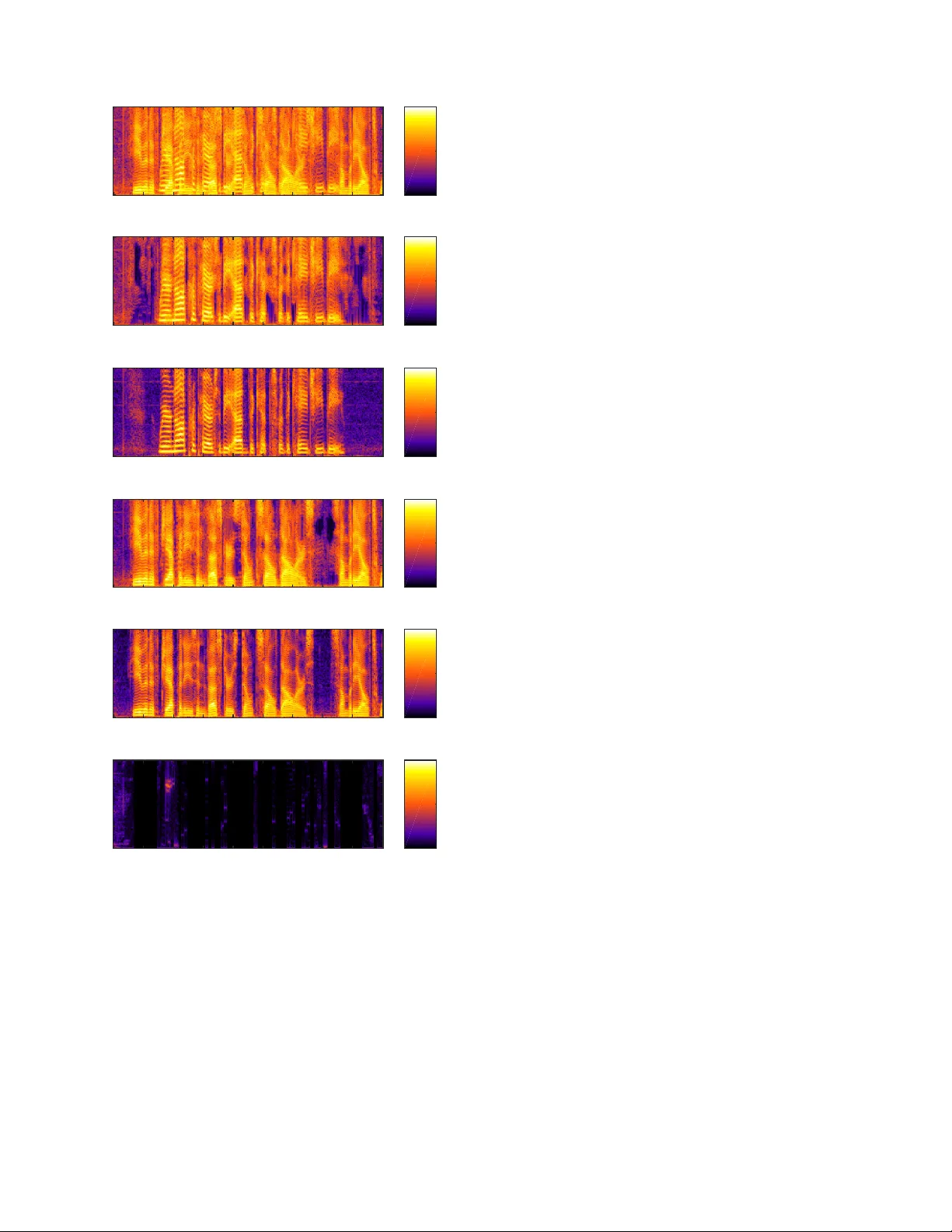
1 Multi-talker Speech Separation with Utterance-le v el Permutation In v ariant T raining of Deep Recurrent Neural Networks Morten K olbæk, Student Member , IEEE , Dong Y u, Senior Member , IEEE , Zheng-Hua T an, Senior Member , IEEE , and Jesper Jensen. Abstract —In this paper we pr opose the utterance-level Permu- tation Invariant T raining (uPIT) technique. uPIT is a practically applicable, end-to-end, deep learning based solution for speaker independent multi-talker speech separation. Specifically , uPIT extends the recently pr oposed Permutation In variant T rain- ing (PIT) technique with an utterance-level cost function, hence eliminating the need for solving an additional permutation prob- lem during inference, which is otherwise requir ed by frame-lev el PIT . W e achieve this using Recurrent Neural Networks (RNNs) that, during training, minimize the utterance-level separation error , hence for cing separated frames belonging to the same speaker to be aligned to the same output stream. In practice, this allows RNNs, trained with uPIT , to separate multi-talker mixed speech without any prior knowledge of signal duration, number of speakers, speaker identity or gender . W e evaluated uPIT on the WSJ0 and Danish two- and three-talk er mixed-speech separation tasks and found that uPIT outperforms techniques based on Non-negative Matrix F actoriza- tion (NMF) and Computational A uditory Scene Analysis (CASA), and compares fav orably with Deep Clustering (DPCL) and the Deep Attractor Network (DANet). Furthermore, we found that models trained with uPIT generalize well to unseen speakers and languages. Finally , we found that a single model, trained with uPIT , can handle both tw o-speaker , and three-speaker speech mixtures. Index T erms —Permutation In variant T raining, Speech Separa- tion, Cocktail Party Problem, Deep Learning, DNN, CNN, LSTM. I . I N T R O D U C T I O N H A VING a conv ersation in a complex acoustic envi- ronment, with multiple noise sources and competing background speakers, is a task humans are remarkably good at [1], [2]. The problem that humans solve when they focus their auditory attention to wards one audio signal in a complex mixture of signals is commonly known as the cocktail party problem [1], [2]. Despite intense research for more than half a century , a general machine based solution to the cocktail party problem is yet to be discovered [1]–[4]. A machine solution to the cocktail party problem is highly desirable for a vast range of applications. These include automatic meeting M. Kolbæk and Z.-H. T an are with the Department of Electronic Sys- tems, Aalborg University , Aalborg 9220, Denmark (e-mail: mok@es.aau.dk; zt@es.aau.dk). D. Y u, corresponding author, is with T encent AI Lab, Belle vue W A, USA. Part of work was done while he was at Microsoft Research (e-mail: dongyu@ieee.org). J. Jensen is with the Department of Electronic Systems, Aalborg Univ ersity , Aalborg 9220, Denmark, and also with Oticon A/S, Smørum 2765, Denmark (e-mail: jje@es.aau.dk; jesj@oticon.com). transcription, automatic captioning for audio/video recordings (e.g., Y ouT ube), multi-party human-machine interaction (e.g., in the world of Internet of things (IoT)), and advanced hearing aids, where overlapping speech is commonly encountered. Since the cocktail party problem was initially formalized [3], a large number of potential solutions have been proposed [5], and the most popular techniques originate from the field of Computational Auditory Scene Analysis (CASA) [6]–[10]. In CASA, different segmentation and grouping rules are used to group Time-Frequenc y (T -F) units that are believed to belong to the same speaker . The rules are typically hand-engineered and based on heuristics such as pitch trajectory , common onset/offset, periodicity , etc. The grouped T -F units are then used to extract a particular speaker from the mixture signal. Another popular technique for multi-talker speech separation is Non-neg ativ e Matrix F actorization (NMF) [11]–[14]. The NMF technique uses non-negati ve dictionaries to decompose the spectrogram of the mixture signal into speaker specific activ ations, and from these activ ations an isolated target signal can be approximated using the dictionaries. For multi-talker speech separation, both CASA and NMF hav e led to limited success [4], [5] and the most successful techniques, before the deep learning era, are based on probabilistic models [15]–[17], such as factorial GMM-HMM [18], that model the temporal dynamics and the complex interactions of the target and competing speech signals. Unfortunately , these models assume and only work under closed-set speaker conditions, i.e. the identity of the speakers must be known a priori . More recently , a large number of techniques based on deep learning [19] ha ve been proposed, especially for Automatic Speech Recognition (ASR) [20]–[25], and speech enhance- ment [26]–[34]. Deep learning has also been applied in the context of multi-talker speech separation (e.g., [30]), although successful work has, similarly to NMF and CASA, mainly been reported for closed-set speaker conditions. The limited success in deep learning based speaker in- dependent multi-talker speech separation is partly due to the label permutation problem (which will be described in detail in Sec. IV). T o the authors knowledge only four deep learning based works [35]–[38] exist, that hav e tried to address and solve the harder speaker independent multi-talker speech separation task. In W eng et al. [35], which proposed the best performing system in the 2006 monaural speech separation and recog- nition challenge [4], the instantaneous energy was used to 2 determine the training label assignment, which alleviated the label permutation problem and allowed separation of unknown speakers. Although this approach works well for two-speaker mixtures, it is hard to scale up to mixtures of three or more speakers. Hershey et al. [36] hav e made significant progress with their Deep Clustering (DPCL) technique. In their work, a deep Recurrent Neural Network (RNN) is used to project the speech mixture into an embedding space, where T -F units belonging to the same speaker form a cluster . In this embedding space a clustering algorithm (e.g. K-means) is used to identify the clusters. Finally , T -F units belonging to the same clusters are grouped together and a binary mask is constructed and used to separate the speakers from the mixture signal. T o further improv e the model [39], another RNN is stacked on top of the first DPCL RNN to estimate continuous masks for each target speaker . Although DPCL show good performance, the technique is potentially limited because the objective function is based on the affinity between the sources in the embedding space, instead of the separated signals themselves. That is, low proximity in the embedding space does not necessarily imply perfect separation of the sources in the signal space. Chen et al. [37], [40] proposed a related technique called Deep Attractor Netw ork (DANet). F ollowing DPCL, the D ANet approach also learns a high-dimensional embedding of the mixture signals. Different from DPCL, howe ver , it creates attractor points (cluster centers) in the embedding space, which attract the T -F units corresponding to each target speaker . The training is conducted in a way similar to the Expectation Maximization (EM) principle. The main disadvantage of DANet ov er DPCL is the added complexity associated with estimating attractor points during inference. Recently , we proposed the Permutation In variant Train- ing (PIT) technique 1 [38] for attacking the speaker indepen- dent multi-talker speech separation problem and sho wed that PIT ef fecti vely solves the label permutation problem. Ho we ver , although PIT solves the label permutation problem at training time, PIT does not effecti vely solve the permutation problem during inference, where the permutation of the separated signals at the frame-lev el is unknown. W e denote the challenge of identifying this frame-level permutation, as the speaker tracing pr oblem . In this paper, we extend PIT and propose an utterance- lev el Permutation In v ariant T raining (uPIT) technique, which is a practically applicable, end-to-end, deep learning based solution for speaker independent multi-talker speech separa- tion. Specifically , uPIT extends the frame-level PIT technique [38] with an utterance-lev el training criterion that effecti vely eliminates the need for additional speaker tracing or very large input/output contexts, which is otherwise required by the original PIT [38]. W e achiev e this using deep Long Short-T erm Memory (LSTM) RNNs [41] that, during training, minimize the utterance-level separation error , hence forcing separated frames belonging to the same speaker to be aligned to the same output stream. This is unlike other techniques, such as DPCL 1 In [36], a related permutation free technique, which is similar to PIT for exactly two-speakers, was ev aluated with negativ e results and conclusion. and DANet, that require a distinct clustering step to separate speakers during inference. Furthermore, the computational cost associated with the uPIT training criterion is negligible compared to the computations required by the RNN during training and is zero during inference. W e ev aluated uPIT on the WSJ0 and Danish two- and three-talker mixed-speech separation tasks and found that uPIT outperforms techniques based on NMF and CASA, and compares fav orably with DPCL and D ANet. Furthermore, we show that models trained with uPIT generalize well to unseen speakers and languages, and finally , we found that a single model trained with uPIT can separate both two-speaker , and three-speaker speech mixtures. The rest of the paper is organized as follo ws. In Sec. II we describe the monaural speech separation problem. In Sec. III we extend popular optimization criteria used in separating single-talker speech from noises, to multi-talker speech separa- tion tasks. In Sec. IV we discuss the label permutation problem and present the PIT framew ork. In Sec. V we introduce uPIT and show how an utterance-lev el permutation criterion can be combined with PIT . W e report series of experimental results in Sec. VI and conclude the paper in Sec. VII. I I . M O N AU R A L S P E E C H S E P A R A T I O N The goal of monaural speech separation is to estimate the individual source signals x s [ n ] , s = 1 , · · · , S in a linearly mixed single-microphone signal y [ n ] = S X s =1 x s [ n ] , (1) based on the observed signal y [ n ] only . In real situations, the receiv ed signals may be rev erberated, i.e., the underlying clean signals are filtered before being observed in the mixture. In this condition, we aim at reco vering the re verberated source signals x s [ n ] , i.e., we are not targeting the derev erberated signals. The separation is usually carried out in the T -F domain, in which the task can be cast as recovering the Short-T ime discrete Fourier T ransformation (STFT) of the source signals X s ( t, f ) for each time frame t and frequency bin f , gi ven the mixed speech Y ( t, f ) = N − 1 X n =0 y [ n + tL ] w [ n ] exp( − j 2 π nf / N ) , (2) where w [ n ] is the analysis window of length N , the signal is shifted by an amount of L samples for each time frame t = 0 , · · · , T − 1 , and each frequency bin f = 0 , · · · , N − 1 is corresponding to a frequency of ( f / N ) f s [Hz] when the sampling rate is f s [Hz]. From the estimated STFT ˆ X s ( t, f ) of each source signal, an inv erse Discrete Fourier T ransform (DFT) ˆ x s,t [ n ] = 1 N N − 1 X f =0 ˆ X s ( t, f ) exp( j 2 πnf / N ) (3) can be used to construct estimated time-domain frames, and the overlap-add operation ˆ x s [ n ] = T − 1 X t =0 v [ n − tL ] ˆ x s,t [ n − tL ] (4) 3 can be used to reconstruct the estimate ˆ x s [ n ] of the original signal, where v [ n ] is the synthesis window . In a typical setup, ho wev er , only the STFT magnitude spectrum A s ( t, f ) , | X s ( t, f ) | is estimated from the mixture during the separation process, and the phase of the mixed speech is used directly , when recovering the time domain wa veforms of the separated sources. This is because phase es- timation is still an open problem in the speech separation setup [42], [43]. Obviously , giv en only the magnitude of the mixed spectrum, R ( t, f ) , | Y ( t, f ) | , the problem of recovering A s ( t, f ) is under-determined, as there are an infinite number of possible A s ( t, f ) , s = 1 , . . . , S combinations that lead to the same R ( t, f ) . T o overcome this problem, a supervised learning system has to learn from some training set S that contains corresponding observations of R ( t, f ) and A s ( t, f ) , s = 1 , . . . , S . Let a s,i = A s ( i, 1) , A s ( i, 2) , . . . A s ( i, N 2 + 1) T ∈ R N 2 +1 denote the single-sided magnitude spectrum for source s at frame i . Furthermore, let A s ∈ R ( N 2 +1 ) × T be the single- sided magnitude spectrogram for source s and all frames i = 1 , . . . , T , defined as A s = [ a s, 1 , a s, 2 , . . . , a s,T ] . Similarly , let r i = R ( i, 1) , R ( i, 2) , . . . R ( i, N 2 + 1) T be the single- sided magnitude spectrum of the observed signal at frame i and let R = [ r 1 , r 2 , . . . , r T ] ∈ R ( N 2 +1 ) × T be the single- sided magnitude spectrogram for all frames i = 1 , . . . , T . Furthermore, let us denote a supervector z i = a T 1 ,i a T 2 ,i . . . a T S,i T ∈ R S ( N 2 +1 ) , consisting of the stacked source magnitude spectra for each source s = 1 , . . . , S at frame i and let Z = [ z 1 , z 2 , . . . , z T ] ∈ R S ( N 2 +1 ) × T denote the matrix of all T supervectors. Finally , let y i = Y ( i, 1) , Y ( i, 2) , . . . Y ( i, N 2 + 1) T ∈ C N 2 +1 be the single-sided STFT of the observed mixture signal at frame i and Y = [ y 1 , y 2 , . . . , y T ] ∈ C ( N 2 +1 ) × T be the STFT of the mixture signal for all T frames. Our objective is then to train a deep learning model g ( · ) , parameterized by a parameter set Φ , such that g ( d ( Y ) ; Φ ) = Z , where d ( Y ) is some feature representation of the mixture signal: In a particularly simple situation, d ( Y ) = R , i.e., the feature representation is simply the magnitude spectrum of the observed mixture signal. It is possible to directly estimate the magnitude spectra Z of all sources using a deep learning model. Ho wev er , it is well- known (e.g., [27], [43]), that better results can be achie ved if, instead of estimating Z directly , we first estimate a set of masks M s ( t, f ) , s = 1 , . . . , S . Let m s,i = M s ( i, 1) , M s ( i, 2) , . . . M s ( i, N 2 + 1) T ∈ R N 2 +1 be the ideal mask (to be defined in detail in Sec. III) for speaker s at frame i , and let M s = [ m s, 1 , m s, 2 , . . . , m s,T ] ∈ R ( N 2 +1 ) × T be the ideal mask for all T frames, such that A s = M s ◦ R , where ◦ is the Hadamard product, i.e. element-wise product of two operands. Furthermore, let us introduce the mask supervector u i = m T 1 ,i m T 2 ,i . . . m T S,i T ∈ R S ( N 2 +1 ) and the corresponding mask matrix U = [ u 1 , u 2 , . . . , u T ] ∈ R S ( N 2 +1 ) × T . Our goal is then to find an estimate ˆ U of U , using a deep learning model, h ( R ; Φ ) = ˆ U . Since, ˆ U = [ ˆ u 1 , ˆ u 2 , . . . , ˆ u T ] and ˆ u i = ˆ m T 1 ,i ˆ m T 2 ,i . . . ˆ m T S,i T , the model output is easily divided into output streams corresponding to the estimated masks for each speaker ˆ m s,i , and their resulting magnitudes are estimated as ˆ a s,i = ˆ m s,i ◦ r i . The estimated time-domain signal for speaker s is then computed as the in verse DFT of ˆ a s,i using the phase of the mixture signal y i . I I I . M A S K S A N D T R A I N I N G C R I T E R I A Since masks are to be estimated as an intermediate step tow ards estimating magnitude spectra of source signals, we extend in the following three popular masks defined for separating single-talker speech from noises to the multi-talker speech separation task at hand. A. Ideal Ratio Mask The Ideal Ratio Mask (IRM) [27] for each source is defined as M irm s ( t, f ) = | X s ( t, f ) | P S s =1 | X s ( t, f ) | . (5) When the phase of Y is used for reconstruction, the IRM achiev es the highest Signal to Distortion Ratio (SDR) [44], when all sources have the same phase, (which is an in- valid assumption in general). IRMs are constrained to 0 ≤ M irm s ( t, f ) ≤ 1 and P S s =1 M irm s ( t, f ) = 1 for all T -F units. This constraint can easily be satisfied using the softmax activ ation function. Since Y is the only observed signal in practice and P S s =1 | X s ( t, f ) | is unkno wn during separation, the IRM is not a desirable target for the problem at hand. Nev ertheless, we report IRM results as an upper performance bound since the IRM is a commonly used training target for deep learning based monaural speech separation [31], [32]. B. Ideal Amplitude Mask Another applicable mask is the Ideal Amplitude Mask (IAM) (known as FFT -mask in [27]), or simply Amplitude Mask (AM), when estimated by a deep learning model. The IAM is defined as M iam s ( t, f ) = | X s ( t, f ) | | Y ( t, f ) | . (6) Through IAMs we can construct the exact | X s ( t, f ) | giv en the magnitude spectra of the mixed speech | Y ( t, f ) | . If the phase of each source equals the phase of the mixed speech, the IAM achie ves the highest SDR. Unfortunately , as with the IRM, this assumption is not satisfied in most cases. IAMs satisfy the constraint that 0 ≤ M iam s ( t, f ) ≤ ∞ , although we found empirically that the majority of the T -F units are in the range of 0 ≤ M iam s ( t, f ) ≤ 1 . For this reason, softmax, sigmoid and ReLU are all possible output activ ation functions for estimating IAMs. 4 C. Ideal Phase Sensitive Mask Both IRM and IAM do not consider phase differences between source signals and the mixture. This leads to sub- optimal results, when the phase of the mixture is used for reconstruction. The Ideal Phase Sensitive Mask (IPSM) [43], [45] M ipsm s ( t, f ) = | X s ( t, f ) | cos( θ y ( t, f ) − θ s ( t, f )) | Y ( t, f ) | , (7) howe ver , takes phase differences into consideration, where θ y and θ s are the phases of mixed speech Y ( t, f ) and source X s ( t, f ) , respecti vely . Due to the phase-correcting term, the IPSM sums to one, i.e. P S s =1 M ipsm s ( t, f ) = 1 . Note that since | cos( · ) | ≤ 1 the IPSM is smaller than the IAM, espe- cially when the phase difference between the mixed speech and the source is large. Even-though the IPSM in theory is unbounded, we found empirically that the majority of the IPSM is in the range of 0 ≤ M ipsm s ( t, f ) ≤ 1 . Actually , in our study we ha ve found that approximately 20% of IPSMs are neg ativ e. How- ev er , those negati ve IPSMs usually are very close to zero. T o account for this observation, we propose the Ideal Non- negati ve PSM (INPSM), which is defined as M inpsm s ( t, f ) = max (0 , M ipsm s ( t, f )) . (8) For estimating the IPSM and INPSM, Softmax, Sigmoid, tanh, and ReLU are all possible activ ation functions, and similarly to the IAM, when the IPSM is estimated by a deep learning model we refer to it as PSM. D. T r aining Criterion Since we first estimate masks, through which the magni- tude spectrum of each source can be estimated, the model parameters can be optimized to minimize the Mean Squared Error (MSE) between the estimated mask ˆ M s and one of the target masks defined above as J m = 1 B S X s =1 k ˆ M s − M s k 2 F , (9) where B = T × N × S is the total number of T -F units ov er all sources and k · k F is the Frobenius norm. This approach comes with two problems. First, in silence segments, | X s ( t, f ) | = 0 and | Y ( t, f ) | = 0 , so that the target masks M s ( t, f ) are not well defined. Second, what we really care about is the error between the reconstructed source signal and the true source signal. T o overcome these limitations, recent works [27] directly minimize the MSE J a = 1 B S X s =1 k ˆ A s − A s k 2 F = 1 B S X s =1 k ˆ M s ◦ R − A s k 2 F (10) between the estimated magnitude, i.e. ˆ A s = ˆ M s ◦ R and the true magnitude A s . Note that in silence se gments A s ( t, f ) = 0 and R ( t, f ) = 0 , so the accuracy of mask estimation does not affect the training criterion for those segments. Furthermore, using Eq. (10) the IAM is estimated as an intermediate step. When the PSM is used, the cost function becomes J psm = 1 B S X s =1 k ˆ M s ◦ R − A s ◦ cos( θ y − θ s ) k 2 F . (11) In other words, using PSMs is as easy as replacing the original training targets with the phase discounted targets. Furthermore, when Eq. (11) is used as a cost function, the IPSM is the upper bound achiev able on the task [43]. I V . P E R M U T A T I O N I N V A R I A N T T R A I N I N G A. Con ventional Multi-T alker Separation A natural, and commonly used, approach for deep learning based speech separation is to cast the problem as a multi-class [30], [35], [46] regression problem as depicted in Fig. 1. For this conv entional two-talker separation model, J frames of feature vectors of the mixed signal Y are used as the input to some deep learning model e.g. a feed-forward Deep Neural Network (DNN), Con volutional Neural Network (CNN), or LSTM RNN, to generate M frames of masks for each talker . Specifically , if M = 1 , the output of the model can be described by the vector ˆ u i = ˆ m T 1 ,i ˆ m T 2 ,i T and the sources are separated as ˆ a 1 ,i = ˆ m 1 ,i ◦ r i and ˆ a 2 ,i = ˆ m 2 ,i ◦ r i , for sources s = 1 , 2 , respectiv ely . DNN/CN N/LS TM Mask 1 (M frames) Clea ned spee ch 1 (M frames) Mask 2 (M frames) Mixed speech (M frames) Clea ned spee ch 2 (M frames) X X outp ut1 ou tput2 Error 1 input Fea ture (J frame s) input Inpu t S1 Inpu t S2 Error 2 + Error Clea n speech 1 (M frames) Clea n speech 2 (M frames) Fig. 1. The con ventional two-talker speech separation model. B. The Label P ermutation Pr oblem During training, the error (e.g. using Eq. (11)) between the clean magnitude spectra a 1 ,i and a 2 ,i and their estimated coun- terparts ˆ a 1 ,i and ˆ a 2 ,i needs to be computed. Howe ver , since the model estimates the masks ˆ m 1 ,i and ˆ m 2 ,i simultaneously , and they depend on the same input mixture, it is unknown in advance whether the resulting output vector ˆ u i is ordered as ˆ u i = ˆ m T 1 ,i ˆ m T 2 ,i T or ˆ u i = ˆ m T 2 ,i ˆ m T 1 ,i T . That is, the permutation of the output masks is unknown. A na ¨ ıve approach to train a deep learning separation model, without exact knowledge about the permutation of the output 5 masks, is to use a constant permutation as illustrated by Fig. 1. Although such a training approach works for simple cases e.g. female speakers mixed with male speakers, in which case a priori con vention can be made that e.g. the first output stream contains the female speaker , while the second output stream is paired with the male speaker , the training fails if the training set consists of many utterances spoken by many speakers of both genders. This problem is referred to as the label permutation (or am- biguity) problem in [35], [36]. Due to this problem, prior arts perform poorly on speaker independent multi-talker speech separation. C. P ermutation Invariant T raining Our solution to the label permutation problem is illustrated in Fig. 2 and is referred to as Permutation In variant T rain- ing (PIT) [38]. DNN/CN N/LS TM Mask 1 (M frames) Clea ned spe ech 1 (M frames) Mask 2 (M frames) Mixed speech (M frames) Clea ned spee ch 2 (M frames) X X ou tput1 outp ut2 Clea n speech 1 (M frames) Clea n speech 2 (M frames) Pairwi se score s Error assignm ent 1 Error assignm ent 2 Min imum error input Fea ture (J fram es) input Inpu t S1 Inpu t S2 Pai rwise score s: Error Assig nment: (summa tion) (distan ce) O(S 2 ) O(S !) Fig. 2. The two-talker speech separation model with permutation in variant training. In the model depicted in Fig. 2 (and unlike the con ventional model in Fig. 1) the reference signals are giv en as a set instead of an ordered list. In other words, the same training result is obtained, no matter in which order these references are listed. This behavior is achieved with PIT highlighted inside the dashed rectangle in Fig. 2. Specifically , following the notation from Sec. II, we associate the reference signals for speaker one and two, i.e. a 1 ,i and a 2 ,i , to the output masks ˆ m 1 ,i and ˆ m 2 ,i , by computing the (total of S 2 ) pairwise MSE’ s between each reference signal a s,i and each estimated source ˆ a s,i . W e then determine the (total of S ! ) possible permutations between the references and the estimated sources, and compute the per- permutation-loss for each permutation. That is, for the two- speaker case in Fig. 2 we compute the per -permutation-loss for the two candidate output vectors ˆ u i = ˆ m T 1 ,i ˆ m T 2 ,i T and ˆ u i = ˆ m T 2 ,i ˆ m T 1 ,i T . The permutation with the lowest MSE is chosen and the model is optimized to reduce this least MSE. In other words, we simultaneously conduct label assignment and error ev aluation. Similarly to prior arts, we can use J , and M successiv e input, and output frames, respectively , (i.e., a meta- frame ) to exploit the contextual information. Note that only S 2 pairwise MSE’ s are required (and not S ! ) to compute the per-permutation-loss for all S ! possible permutations. Since S ! grows much faster than S 2 , with respect to S , and the computational complexity of the pairwise MSE is much larger than the per-permutation-loss (sum of pairwise MSE’ s), PIT can be used with a large number of speakers, i.e. S 2 . During inference, the only information av ailable is the mixed speech, but speech separation can be directly carried out for each input meta-frame, for which an output meta- frame with M frames of speech is estimated. Due to the PIT training criterion, the permutation will stay the same for frames inside the same output meta-frame, but may change across output meta-frames. In the simplest setup, we can just assume that permutations do not change across output meta- frames, when reconstructing the target speakers. Howe ver , this usually leads to unsatisfactory results as reported in [38]. T o achiev e better performance, speaker tracing algorithms, that identify the permutations of output meta-frames with respect to the speakers, need to be developed and integrated into the PIT framework or applied on top of the output of the network. V . U T T E R A N C E - L E V E L P I T Sev eral ways exist for identifying the permutation of the output meta-frames, i.e. solving the tracing problem. For example, in CASA a related problem referred to as the Sequential Organization Problem has been addressed using a model-based sequential grouping algorithm [9]. Although moderately successful for co-channel speech separation, where prior knowledge about the speakers is av ailable, this method is not easily extended to the speaker independent case with multiple speakers. Furthermore, it is not easily integrated into a deep learning framework. A more straight-forw ard approach might be to determine a change in permutation by comparing MSEs for different permutations of output masks measured on the o verlapping frames of adjacent output meta-frames. Howe ver , this ap- proach has two major problems. First, it requires a separate tracing step, which may complicate the model. Second, since the permutation of later frames depends on that of earlier frames, one incorrect assignment at an earlier frame w ould completely switch the permutation for all frames after it, even if the assignment decisions for the remaining frames are all correct. In this work we propose utterance-level Permutation In vari- ant Training (uPIT), a simpler yet more effecti ve approach to solve the tracing problem and the label permutation problem than original PIT . Specifically , we extend the frame-lev el PIT technique with the following utterance-lev el cost function: J φ ∗ = 1 B S X s =1 k ˆ M s ◦ R − A φ ∗ ( s ) ◦ cos( θ y − θ φ ∗ ( s ) ) k 2 F , (12) where φ ∗ is the permutation that minimizes the utterance-level separation error defined as φ ∗ = argmin φ ∈P S X s =1 k ˆ M s ◦ R − A φ ( s ) ◦ cos( θ y − θ φ ( s ) ) k 2 F , (13) 6 and P is the symmetric group of degree S , i.e. the set of all S ! permutations. In original PIT , the optimal permutation (in MSE sense) is computed and applied for each output meta-frame. This implies that consecuti ve meta-frames might be associated with different permutations, and although PIT solves the label permutation problem, it does not solve the speaker tracing problem. W ith uPIT , howe ver , the permutation corresponding to the minimum utterance-lev el separation error is used for all frames in the utterance. In other words, the pair-wise scores in Fig. 2 are computed for the whole utterance assuming all output frames follow the same permutation. Using the same permutation for all frames in the utterance might imply that a non-MSE-optimal permutation is used for indi vidual frames within the utterance. Ho we ver , the intuition behind uPIT is that since the permutation resulting in the minimum utterance-lev el separation error is used, the number of non-optimal permuta- tions is small and the model sees enough correctly permuted frames to learn an efficient separation model. F or example, the output vector ˆ u i of a perfectly trained two-talker speech separation model, given an input utterance, should ideally be ˆ u i = ˆ m T 1 ,i ˆ m T 2 ,i T , or ˆ u i = ˆ m T 2 ,i ˆ m T 1 ,i T ∀ i = 1 , . . . , T , i.e. the output masks should follow the same permutation for all T frames in the utterance. Fortunately , using Eq. (12) as a training criterion, for deep learning based speech separation models, this seems to be the case in practice (See Sec. VI for examples). Since utterances hav e variable length, and effecti ve sepa- ration presumably requires exploitation of long-range signal dependencies, models such as DNNs and CNNs are no longer good fits. Instead, we use deep LSTM RNNs and bi-directional LSTM (BLSTM) RNNs together with uPIT to learn the masks. Different from PIT , in which the input layer and each output layer has N × T and N × M units, respectiv ely , in uPIT , both input and output layers have N units (adding conte xtual frames in the input does not help for LSTMs). W ith deep LSTMs, the utterance is ev aluated frame-by-frame exploiting the whole past history information at each layer . When BLSTMs are used, the information from the past and future (i.e., across the whole utterance) is stacked at each layer and used as the input to the subsequent layer . W ith uPIT , during inference we don’t need to compute pairwise MSEs and errors of each possible permutation and no additional speaker tracing step is needed. W e simply assume a constant permutation and treat the same output mask to be from the same speaker for all frames. This makes uPIT a simple and attractive solution. V I . E X P E R I M E N TA L R E S U LT S W e ev aluated uPIT on various setups and all models were implemented using the Microsoft Cognitive T oolkit (CNTK) [47], [48] 2 . The models were e valuated on their potential to improv e the Signal-to-Distortion Ratio (SDR) [44] and the Perceptual Evaluation of Speech Quality (PESQ) [49] score, both of which are metrics widely used to ev aluate speech enhancement performance for multi-talker speech separation tasks. 2 A vailable at: https://www .cntk.ai/ A. Datasets W e ev aluated uPIT on the WSJ0-2mix, WSj0-3mix 3 and Danish-2mix datasets using 129-dimensional STFT magnitude spectra computed with a sampling frequency of 8 kHz, a frame size of 32 ms and a 16 ms frame shift. The WSJ0-2mix dataset was introduced in [36] and w as deriv ed from the WSJ0 corpus [50]. The 30h training set and the 10h validation set contain two-speaker mixtures gen- erated by randomly selecting from 49 male and 51 female speakers and utterances from the WSJ0 training set si tr s, and mixing them at various Signal-to-Noise Ratios (SNRs) uniformly chosen between 0 dB and 5 dB. The 5h test set was similarly generated using utterances from 16 speakers from the WSJ0 validation set si dt 05 and ev aluation set si et 05. The WSJ0-3mix dataset was generated using a similar approach but contains mixtures of speech from three talkers. The Danish-2mix dataset is based on a corpus 4 with ap- proximately 560 speakers each speaking 312 utterances with av erage utterance duration of approximately 5 sec. The dataset was constructed by randomly selecting a set of 45 male and 45 female speakers from the corpus, and then allocating 232 and 40 utterances from each speaker to generate mixed speech in the training, and validation set, respectively . A number of 40 utterances from each of another 45 male and 45 female speakers were randomly selected to construct the open- condition (OC) (unseen speaker) test set. Speech mixtures were constructed similarly to the WSJ0-2mix with SNRs selected uniformly between 0 dB and 5 dB. Similarly to the WSJ0-2mix dataset we constructed 20k and 5k mixtures in total in the training and v alidation set, respectively , and 3k mixtures for the OC test set. In our study , the val idation set is used to find initial hyperparameters and to e valuate closed-condition (CC) (seen speaker) performance, similarly to [36], [38], [39]. B. P ermutation Invariant T raining W e first ev aluated the original frame-level PIT on the two- talker separation dataset WSJ0-2mix, and differently from [38], we fixed the input dimension to 51 frames, to isolate the effect of a varying output dimension. In PIT , the input window and output windo w sizes are fixed. For this reason, we can use DNNs and CNNs. The DNN model has three hidden layers each with 1024 ReLU units. In (inChannel, outChannel)-(strideW , strideH) format, the CNN model has one (1 , 64) − (2 , 2) , four (64 , 64) − (1 , 1) , one (64 , 128) − (2 , 2) , two (128 , 128) − (1 , 1) , one (128 , 256) − (2 , 2) , and two (256 , 256) − (1 , 1) conv olution layers with 3 × 3 kernels, a 7 × 17 av erage pooling layer and a 1024-unit ReLU layer . The input to the models is the stack (ov er multiple frames) of the 129-dimensional STFT spectral magnitude of the speech mixture. The output layer ˆ u i is divided into S output masks/streams for S -talker mixed speech as ˆ u i = [ ˆ m 1 ,i ; ˆ m 2 ,i ; . . . ; ˆ m S,i ] T . Each output mask vector ˆ m s,i has a dimension of 129 × M , where M is the number of frames in the output meta-frame. 3 A vailable at: http://www .merl.com/demos/deep-clustering 4 A vailable at: http://www .nb .no/sbfil/dok/nst taledat dk.pdf 7 0 5 10 15 20 25 30 35 40 Epochs 0 10 20 30 40 MSE CONV-DNN-RAND: Val CONV-DNN: Val PIT-DNN: Val CONV-DNN-RAND: Train CONV-DNN: Train PIT-DNN: Train Fig. 3. MSE over epochs on the WSJ0-2mix training and validation sets with con ventional training and PIT . T ABLE I S D R I M P ROV E M E N T S ( D B ) F O R D I FFE R E N T SE P A R A T I O N ME T H O DS O N T H E W S J 0 - 2 M I X DA TA S E T U S I N G P I T . Method Input \ Output Opt. Assign. Def. Assign. window CC OC CC OC PIT -DNN 51 \ 51 6.8 6.7 5.2 5.2 PIT -DNN 51 \ 5 10.3 10.2 -0.8 -0.8 PIT -CNN 51 \ 51 9.6 9.6 7.6 7.5 PIT -CNN 51 \ 5 10.9 11.0 -1.0 -0.9 IRM - 12.4 12.7 12.4 12.7 IPSM - 14.9 15.1 14.9 15.1 In Fig. 3 we present the DNN training progress as mea- sured by the MSE on the training and validation set with con ventional training (CONV -DNN) and PIT on the WSJ0- 2mix datasets described in subsection VI-A. W e also included the training progress for another con ventionally trained model but with a slightly modified version of the WSJ0-2mix dataset, where speaker labels hav e been randomized (CONV -DNN- RAND). The WSJ0-2mix dataset, used in [36], was designed such that speaker one was always assigned the most energy , and consequently speaker two the lo west, when scaling to a gi ven SNR. Previous work [35] has shown that such speaker energy patterns are an ef fecti ve discriminati ve feature, which is clearly seen in Fig. 3, where the CONV -DNN model achiev es con- siderably lower training and validation MSE than the CONV - DNN-RAND model, which hardly decreases in either training or validation MSE due to the label permutation problem [35], [36]. In contrast, training con verges quickly to a very lo w MSE when PIT is used. In T able I we summarize the SDR improv ement in dB from different frame-lev el PIT separation configurations for two- talker mixed speech in closed condition (CC) and open condi- tion (OC). In these experiments each frame was reconstructed by av eraging over all output meta-frames that contain the same frame. In the default as signment (def. assign.) setup, a constant output mask permutation is assumed across frames (which is an inv alid assumption in general). This is the maximum achiev able SDR improvement using PIT without the utterance- lev el training criterion and without an additional tracing step. T ABLE II S D R I M P ROV E M E N T S ( D B ) F O R D I FFE R E N T SE P A R A T I O N ME T H O DS O N T H E W S J 0 - 2 M I X DA TA S E T U S I N G U P IT. Method Mask Activation Opt. Assign. Def. Assign. T ype Function CC OC CC OC uPIT -BLSTM AM softmax 10.4 10.3 9.0 8.7 uPIT -BLSTM AM sigmoid 8.3 8.3 7.1 7.2 uPIT -BLSTM AM ReLU 9.9 9.9 8.7 8.6 uPIT -BLSTM AM T anh 8.5 8.6 7.5 7.5 uPIT -BLSTM PSM softmax 10.3 10.2 9.1 9.0 uPIT -BLSTM PSM sigmoid 10.5 10.4 9.2 9.1 uPIT -BLSTM PSM ReLU 10.9 10.8 9.4 9.4 uPIT -BLSTM PSM T anh 10.4 10.3 9.0 8.9 uPIT -BLSTM NPSM softmax 8.7 8.6 7.5 7.3 uPIT -BLSTM NPSM sigmoid 10.6 10.6 9.4 9.3 uPIT -BLSTM NPSM ReLU 8.8 8.8 7.6 7.6 uPIT -BLSTM NPSM T anh 10.1 10.0 8.9 8.8 uPIT -LSTM PSM ReLU 9.8 9.8 7.0 7.0 uPIT -LSTM PSM sigmoid 9.8 9.6 7.1 6.9 uPIT -LSTM NPSM ReLU 9.8 9.8 7.1 7.0 uPIT -LSTM NPSM sigmoid 9.2 9.2 6.8 6.8 PIT -BLSTM PSM ReLU 11.7 11.7 -1.7 -1.9 PIT -BLSTM PSM sigmoid 11.7 11.7 -1.7 -1.7 PIT -BLSTM NPSM ReLU 11.7 11.7 -1.7 -1.8 PIT -BLSTM NPSM sigmoid 11.6 11.6 -1.6 -1.7 IRM - - 12.4 12.7 12.4 12.7 IPSM - - 14.9 15.1 14.9 15.1 In the optimal assignment (opt. assign.) setup, the output-mask permutation for each output meta-frame is determined based on the true tar get, i.e. oracle information. This reflects the separation performance within each segment (meta-frame) and is the improv ement achiev able when the speakers are correctly separated. The gap between these two values indicates the possible contribution from speaker tracing. As a reference, we also provided the IRM and IPSM results. From the table we can make several observ ations. First, PIT can already achiev e 7.5 dB SDR improvement (def. assign.), e ven though the model is very simple. Second, as we reduce the output window size, we can improv e the separation performance within each window and achiev e better SDR improv ement, if speak ers are correctly traced (opt. assign.). Howe ver , when output window size is reduced, the output mask permutation changes more frequently as indicated by the poor default assignment performance. Speaker tracing thus becomes more important giv en the larger gap between the optimal assignment and default assignment. Third, PIT generalizes well to unseen speakers, since the performances on the open and closed conditions are very close. F ourth, po werful models such as CNNs consistently outperform DNNs, but the gain diminishes when the output window size is small. C. Utterance-level P ermutation Invariant T raining As indicated by T able I, an accurate output mask permu- tation is critical to further improve the separation quality . In this subsection we ev aluate the uPIT technique as discussed in Sec. V and the results are summarized in T able II. Due to the formulation of the uPIT cost function in Eq. (12) and Eq. (13), and to utilize long-range context, RNNs are the 8 natural choice, and in this set of experiments, we used LSTM RNNs. All the uni-directional LSTMs (uPIT -LSTM) ev aluated hav e 3 LSTM layers each with 1792 units and all the bi- directional LSTMs (uPIT -BLSTM) have 3 BLSTM layers each with 896 units, so that both models have similar number of parameters. All models contain random dropouts when fed from a lo wer layer to a higher layer and were trained with a dropout rate of 0.5. Note that, since we used Nvidia’ s cuDNN implementation of LSTMs, to speed up training, we were unable to apply dropout across time steps, which was adopted by the best DPCL model [39] and is known to be more effecti ve, both theoretically and empirically , than the simple dropout strategy used in this work [51]. In all the experiments reported in T able II the maximum epoch is set to 200 although we noticed that further per- formance improv ement is possible with additional training epochs. Note that the epoch size of 200 seems to be signif- icantly lar ger than that in PIT as indicated in Fig. 3. This is likely because in PIT each frame is used by T ( T = 51 ) training samples (input meta-frames) while in uPIT each frame is used just once in each epoch. The learning rates were set to 2 × 10 − 5 per sample initially and scaled down by 0 . 7 when the training objectiv e function value increases on the training set. The training w as terminated when the learning rate got below 10 − 10 . Each minibatch contains 8 randomly selected utterances. As a related baseline, we also include PIT -BLSTM results in T able II. These models were also trained using LSTMs with whole utterances instead of meta-frames. The only difference between these models and uPIT models is that uPIT models use the utterance-lev el training criterion defined in Eqs. (12) and (13), instead of the meta-frame based criterion used by PIT . 0 50 100 150 200 Epochs 0 5 10 15 20 MSE uPIT-BLSTM SIGMOID: Train MSE uPIT-BLSTM SIGMOID: Val MSE uPIT-BLSTM ReLU: Train MSE uPIT-BLSTM ReLU: Val MSE Fig. 4. MSE over epochs on the WSJ0-2mix PSM training and validation sets wit uPIT . 1) uPIT T raining Pr ogr ess: In Fig. 4 we present a represen- tativ e example of the BLSTM training progress, as measured by the MSE of the two-talker mixed speech training and validation set, using Eq. (12). W e see that the training and validation MSE’ s are both steadily decreasing as function of epochs, hence uPIT , similarly to PIT , ef fectiv ely solves the label permutation problem. 2) uPIT P erformance for Differ ent Setups: From T able II, we can notice sev eral things. First, with uPIT , we can signifi- cantly improv e the SDR with default assignment over original PIT . In fact, a 9.4 dB SDR improvement on both CC and OC sets can be achiev ed by simply assuming a constant output mask permutation (def. assign.), which compares fav orably to 7.6 dB (CC) and 7.5 dB (OC) achieved with deep CNNs combined with PIT . W e want to emphasize that this is achie ved through Eqs. (12) and (13), and not by using BLSTMs because the corresponding PIT -BLSTM default assignment results are so much worse, e ven though the optimal assignment results are the best among all models. The latter may be explained from the PIT objectiv e function that attempts to obtain a constant output mask permutation at the meta-frame-level, which for small meta-frames is assumed easier compared to the uPIT objectiv e function, that attempts to obtain a constant output mask permutation throughout the whole utterance. Second, we can achiev e better SDR improvement over the AM using PSM and NPSM training criteria. This indicates that including phase information does improv e performance, ev en- though it was used implicitly via the cosine term in Eq. (12). Third, with uPIT the gap between optimal assignment and default assignment is always less than 1.5 dB across different setups, hence additional improvements from speaker tracing algorithms is limited to 1.5 dB. 3) T wo-stage Models and Reduced Dr opout Rate: It is well known that cascading DNNs can improve performance for certain deep learning based applications [39], [52]–[54]. In T able III we sho w that a similar principle of cascading two BLSTM models into a two-stage model (-ST models in T able III) can lead to improved performance over the models presented in T able II. In T able III we also sho w that improved performance, with respect to the same models, can be achie ved with additional training epochs combined with a reduced dropout rate (-RD models in T able III). Specifically , if we continue the training of the two best performing models from T able II (i.e. uPIT -BLSTM-PSM-ReLU and uPIT -BLSTM- NPSM-Sigmoid) with 200 additional training epochs at a reduced dropout rate of 0.3, we see an improvement of 0 . 1 dB. Even larger improvements can be achieved with the two-stage approach, where an estimated mask is computed as the a verage mask from two BLSTM models as ˆ M s = ˆ M (1) s + ˆ M (2) s 2 . (14) The mask ˆ M (1) s is from an -RD model that serves as a first- stage model, and ˆ M (2) s is the output mask from a second- stage model. The second-stage model is trained using the original input features as well as the mask ˆ M (1) s from the first- stage model. The intuition behind this architecture is that the second-stage model will learn to correct the errors made by the first-stage model. T able III shows that the two-stage models (-ST models) always outperform the single-stage models (- RD models) and overall, a 10 dB SDR improvement can be achiev ed on this task using a two-stage approach. 4) Opposite Gender vs. Same Gender .: T able IV reports SDR (dB) improvements on test sets of WSJ0-2mix divided into opposite-gender (Opp.) and same-gender (Same). From this table we can clearly see that our approach achie ves much better SDR improvements on the opposite-gender mixed 9 T ABLE III F U R T H E R I M P ROV E ME N T O N T HE W S J 0 - 2 M I X DAT A S ET W I T H A D D I T I ON A L T R A I N I N G E P O CH S W I T H RE D U C ED D RO P OU T ( - R D ) O R S TAC K ED M O D E L S ( - S T ) Method Mask Activation Opt. Assign. Def. Assign. T ype Function CC OC CC OC uPIT -BLSTM-RD PSM ReLU 11.0 11.0 9.5 9.5 uPIT -BLSTM-ST PSM ReLU 11.7 11.7 10.0 10.0 uPIT -BLSTM-RD NPSM Sigmoid 10.7 10.7 9.5 9.4 uPIT -BLSTM-ST NPSM Sigmoid 11.5 11.5 10.1 10.0 IRM - - 12.4 12.7 12.4 12.7 IPSM - - 14.9 15.1 14.9 15.1 T ABLE IV S D R ( D B ) I M P ROV E ME N T S O N TE S T S E TS O F W S J 0 - 2 M I X D I VI D E D I NT O S A M E A N D O P P O S I T E G EN D E R M IX T U R E S Method Config CC OC Same Opp. Same Opp. uPIT -BLSTM-RD PSM-ReLU 7.5 11.5 7.1 11.6 uPIT -BLSTM-ST PSM-ReLU 7.8 12.1 7.5 12.2 uPIT -BLSTM-RD NPSM-Sigmoid 7.5 11.5 7.0 11.5 uPIT -BLSTM-ST NPSM-Sigmoid 8.0 12.1 7.5 12.1 IRM - 12.2 12.7 12.4 12.9 IPSM - 14.6 15.1 14.9 15.3 speech than the same-gender mixed speech, although the gender information is not explicitly used in our model and training procedure. In fact, for the opposite-gender condition, the SDR improvement is already very close to the IRM result. These results agree with breakdowns from other works [36], [39] and generally indicate that same-gender mixed speech separation is a harder task. 5) Multi-Language Models: T o further understand the prop- erties of uPIT , we ev aluated the uPIT -BLSTM-PSM-ReLU model trained on WSJ0-2mix (English) on the Danish-2mix test set. The results of this is reported in T able V. An interesting observation, is that although the system has nev er seen Danish speech, it performs remarkably well in terms of SDR, when compared to the IRM (oracle) values. These results indicate, that the separation ability learned with uPIT generalizes well, not only across speakers, but also across languages. In terms of PESQ, we see a somewhat larger performance gap with respect to the IRM. This might be explained by the f act that SDR is a wav eform matching criteria and does not necessarily reflect perceived quality as well as PESQ. Furthermore, we note that the PESQ improv ements are similar to what hav e been reported for DNN based speech enhancement systems [32]. W e also trained a model with the combination of English and Danish datasets and e v aluated the models on both lan- guages. The results of these experiments are summarized in T able V. T able V, indicate that by including Danish data, we can achie ve better performance on the Danish dataset, at the cost of slightly worse performance on the English dataset. Note that while doubling the training set, we did not change the model size. Had we done this, performance would likely improv e on both languages. T ABLE V S D R ( D B ) A N D P ES Q I M P ROV E M E N T S O N W S J 0 - 2 M I X A ND D A N I S H -2 M I X W IT H U P I T - B L S TM - P S M- R E L U T R A I NE D O N W S J 0 - 2 MI X A N D A C O M B IN ATI O N O F T WO L AN G UA G E S . T rained on WSJ0-2mix Danish-2mix SDR PESQ SDR PESQ WSJ0-2mix 9.4 0.62 8.1 0.40 +Danish-2mix 8.8 0.58 10.6 0.51 IRM 12.7 2.11 15.2 1.90 IPSM 15.1 2.10 17.7 1.90 T ABLE VI S D R ( D B ) A N D P ES Q I M P ROV E M E N T S F O R D IFF E R E NT S E PAR A T I O N M E T H O D S ON T H E W S J 0 - 2 M I X DA TAS E T W I TH O U T A DD I T I ON A L T R A C I NG ( I . E . , D E F . A S S I G N . ) . ‡ I N D I C ATE S C U R RI C U L UM T R A I NI N G . Method Config PESQ Imp. SDR Imp. CC OC CC OC Oracle NMF [36] - - - 5.1 - CASA [36] - - - 2.9 3.1 DPCL [36] - - - 5.9 5.8 DPCL+ [37] - - - - 9.1 D ANet [37] - - - - 9.6 D ANet ‡ [37] - - - - 10.5 DPCL++ [39] - - - - 9.4 DPCL++ ‡ [39] - - - - 10.8 PIT -DNN 51 \ 51 0.24 0.23 5.2 5.2 PIT -CNN 51 \ 51 0.52 0.50 7.6 7.6 uPIT -BLSTM PSM-ReLU 0.66 0.62 9.4 9.4 uPIT -BLSTM-ST PSM-ReLU 0.86 0.82 10.0 10.0 IRM - 2.15 2.11 12.4 12.7 IPSM - 2.14 2.10 14.9 15.1 6) Summary of Multiple 2-Speaker Separation T echniques: T able VI summarizes SDR (dB) and PESQ improvements for different separation methods on the WSJ0-2mix dataset. From the table we can observe that the models trained with PIT already achiev e similar or better SDR than the original DPCL [36], respectiv ely , with DNNs and CNNs. Using the uPIT training criteria, we improv e on PIT and achieve comparable performance with DPCL+, DPCL++ and DANet models 5 reported in [37], [39], which used curriculum training [55], and recurrent dropout [51]. Note that, both uPIT and PIT models are much simpler than DANet, DPCL, DPCL+, and DPCL++, because uPIT and PIT models do not require any clustering step during inference or estimation of attractor points, as required by DANet. D. Thr ee-T alker Speech Separation In Fig. 5 we present the uPIT training progress as measured by MSE on the three-talker mixed speech training and valida- tion sets WSJ0-3mix. W e observe that similar to the two-talker scenario in Fig. 4, a low training MSE is achiev ed, although the v alidation MSE is slightly higher . A better balance between the training and validation MSEs may be achie ved by hyperpa- rameter tuning. W e also observe that increasing the model size decreases both training and validation MSE, which is expected due to the more variability in the dataset. 5 [37], [39] did not use the SDR measure from [44]. Instead a related variant called scale-in variant SNR was used. 10 0 50 100 150 200 Epochs 0 10 20 30 MSE uPIT-BLSTM SIGMOID 896 units: Train MSE uPIT-BLSTM SIGMOID 896 units: Val MSE uPIT-BLSTM SIGMOID 1280 units: Train MSE uPIT-BLSTM SIGMOID 1280 units: Val MSE Fig. 5. MSE over epochs on the WSJ0-3mix NPSM training and validation sets wit uPIT . T ABLE VII S D R I M P ROV E M E N T S ( D B ) F O R D I FFE R E N T SE P A R A T I O N ME T H O DS O N T H E W S J 0 - 3 M I X DA TA S E T . ‡ I N D I C ATE S C U R RI C U L UM T R A I NI N G . Method Units/ Activ ation Opt. Assign. Def. Assign. layer function CC OC CC OC Oracle NMF [36] - - 4.5 - - - DPCL++ ‡ [39] - - - - - 7.1 D ANet [40] - - - - - 7.7 D ANet ‡ [37] - - - - - 8.8 uPIT -BLSTM 896 Sigmoid 10.0 9.9 7.4 7.2 uPIT -BLSTM 1280 Sigmoid 10.1 10.0 7.5 7.4 uPIT -BLSTM-RD 1280 Sigmoid 10.2 10.1 7.6 7.4 uPIT -BLSTM-ST 1280 Sigmoid 10.7 10.6 7.9 7.7 IRM - - 12.6 12.8 12.6 12.8 IPSM - - 15.1 15.3 15.1 15.3 In T able VII we summarize the SDR improv ement in dB from different uPIT separation configurations for three- talker mixed speech, in closed condition (CC) and open condi- tion (OC). W e observe that the basic uPIT -BLSTM model (896 units) compares fav orably with DPCL++. Furthermore, with additional units, further training and two-stage models (based on uPIT -BLSTM), uPIT achieves higher SDR than DPCL++ and similar SDR as D ANet, without curriculum training, on this three-talker separation task. E. Combined T wo- and Three-T alker Speech Separation T o illustrate the flexibility of uPIT , we summarize in T a- ble VIII the performance of the three-speaker uPIT -BLSTM, and uPIT -BLSTM-ST models (from T able VII), when they are trained and tested on both the WSJ0-2mix and WSJ0-3mix datasets, i.e. on both two- and three-speaker mixtures. T o be able to train the three-speaker models with the two- speaker WSJ0-2mix dataset, we extended WSJ0-2mix with a third ”silent” channel. The silent channel consists of white Gaussian noise with an energy lev el 70 dB below the av erage energy lev el of the remaining two speakers in the mixture. When we ev aluated the model, we identified the two speaker- activ e output streams as the ones corresponding to the signals with the most energy . W e see from T able VIII that uPIT -BLSTM achieves good, but slightly worse, performance compared to the correspond- ing two-speaker (T able VI) and three-speaker (T able VII) T ABLE VIII S D R I M P ROV E M E N T S ( D B ) F O R T H RE E - S PE A K E R MO D E L S TR A I N ED O N B O T H T H E W S J 0- 2 M I X A N D W S J 0 - 3 M I X P S M DAT A S ET S . B O T H M OD E L S H A V E 1 28 0 U N I TS P E R L A Y E R A N D R E LU O U T P UT S . Method 2 Spkr . 3 Spkr . Def. Assign. Def. Assign. CC OC CC OC uPIT -BLSTM 9.4 9.3 7.2 7.1 uPIT -BLSTM-ST 10.2 10.1 8.0 7.8 IRM 12.4 12.7 12.6 12.8 IPSM 14.9 15.1 15.1 15.3 models. Surprisingly , the uPIT -BLSTM-ST model outperforms both the two-speaker (T able III) and three-speaker uPIT - BLSTM-ST (T able VII) models. These results indicate that a single model can handle a varying, and more importantly , unknown number of speakers, without compromising perfor - mance. This is of great practical importance, since a priori knowledge about the number of speakers is not needed at test time, as required by competing methods such as DPCL++ [39] and DANet [37], [40]. During ev aluation of the 3000 mixtures in the WSJ0-2mix test set, output stream one and two were the output streams with the most energy , i.e. the speaker -activ e output streams, in 2999 cases. Furthermore, output stream one and two had, on av erage, an energy level approximately 33 dB higher than the silent channel, indicating that the models successfully keep a constant permutation of the output masks throughout the test utterance. As an example, Fig. 6 shows the spectrogram for a single two-speaker (male-vs-female) test case along with the spectrograms of the three output streams of the uPIT - BLSTM model, as well as the clean speech signals from each of the two speakers. Clearly , output streams one and two contain the most energy and output stream three consists primarily of a lo w energy signal without any clear structure. Furthermore, by comparing the spectrograms of the clean speech signals (”Speaker 1” and ”Speaker 2” in Fig. 6) to the spectrogram of the corresponding output streams, it is observed that they share many similarities, which indicate that the model kept a constant output-mask permutation for the entire mixture and successfully separated the two speakers into two separate output streams. This is also supported by the SDR improv ements, which for output stream one (”Speaker 1”) is 13.7 dB, and for output stream two (”Speaker 2”) is 12.1 dB. V I I . C O N C L U S I O N A N D D I S C U S S I O N In this paper, we hav e introduced the utterance-lev el Per- mutation In variant Training (uPIT) technique for speaker in- dependent multi-talker speech separation. W e consider uPIT an interesting step tow ards solving the important cocktail party problem in a real-world setup, where the set of speakers is unknown during the training time. Our experiments on two- and three-talker mixed speech separation tasks indicate that uPIT can indeed effecti vely deal with the label permutation problem. These experiments show that bi-directional Long Short-T erm Memory (LSTM) 11 2-S p ea ker I npu t Mix tu re 0 0.4 0.9 1.3 1.8 2.2 2.7 3.1 3.6 4 0 1 2 3 4 Frequency [kHz] 0 0.5 1 Ou tpu t Stre am 1 0 0.4 0.9 1.3 1.8 2.2 2.7 3.1 3.6 4 0 1 2 3 4 Frequency [kHz] 0 0.5 1 Sp e aker 1 0 0.4 0.9 1.3 1.8 2.2 2.7 3.1 3.6 4 0 1 2 3 4 Frequency [kHz] 0 0.5 1 Ou tpu t Stre am 2 0 0.4 0.9 1.3 1.8 2.2 2.7 3.1 3.6 4 0 1 2 3 4 Frequency [kHz] 0 0.5 1 Sp e aker 2 0 0.4 0.9 1.3 1.8 2.2 2.7 3.1 3.6 4 0 1 2 3 4 Frequency [kHz] 0 0.5 1 Ou tpu t Stre am 3 0 0.4 0.9 1.3 1.8 2.2 2.7 3.1 3.6 4 Time [s] 0 1 2 3 4 Frequency [kHz] 0 0.5 1 SD R Im pr .: 1 3. 7 dB SD R Im pr .: 1 2. 1 dB Fig. 6. Spectrograms showing how a three-speaker BLSTM model trained with uPIT can separate a tw o-speaker mixture while keeping a constant output- mask permutation. The energy in output stream three is 63 dB lower than the energy in output stream one and two. Recurrent Neural Networks (RNNs) perform better than uni- directional LSTMs and Phase Sensiti ve Masks (PSMs) are bet- ter training criteria than Amplitude Masks (AM). Our results also suggest that the acoustic cues learned by the model are largely speaker and language independent since the models generalize well to unseen speakers and languages. More im- portantly , our results indicate that uPIT trained models do not require a priori kno wledge about the number of speakers in the mixture. Specifically , we show that a single model can handle both two-speaker and three-speaker mixtures. This indicates that it might be possible to train a univ ersal speech separation model using speech in various speaker , language and noise conditions. The proposed uPIT technique is algorithmically simpler yet performs on par with DPCL [36], [39] and comparable to D ANets [37], [40], both of which inv olve separate embedding and clustering stages during inference. Since uPIT , as a training technique, can be easily integrated and combined with other advanced techniques such as complex-domain separation and multi-channel techniques, such as beam-forming, uPIT has great potential for further improvement. A C K N OW L E D G M E N T W e would like to thank Dr . John Hershey at MERL and Zhuo Chen at Columbia University for sharing the WSJ0- 2mix and WSJ0-3mix datasets and for valuable discussions. W e also thank Dr . Hakan Erdogan at Microsoft Research for discussions on PSM. R E F E R E N C E S [1] S. Haykin and Z. Chen, “The Cocktail Party Problem, ” Neural Comput. , vol. 17, no. 9, pp. 1875–1902, 2005. [2] A. W . Bronkhorst, “The Cocktail Party Phenomenon: A Revie w of Research on Speech Intelligibility in Multiple-T alker Conditions, ” Acta Acust united Ac , vol. 86, no. 1, pp. 117–128, 2000. [3] E. C. Cherry , “Some Experiments on the Recognition of Speech, with One and with T wo Ears, ” J. Acoust. Soc. Am. , vol. 25, no. 5, pp. 975– 979, Sep. 1953. [4] M. Cooke, J. R. Hershe y , and S. J. Rennie, “Monaural Speech Separation and Recognition Challenge, ” Comput. Speech Lang. , vol. 24, no. 1, pp. 1–15, Jan. 2010. [5] P . Diven yi, Speech Separation by Humans and Machines . Springer , 2005. [6] D. P . W . Ellis, “Prediction-driv en computational auditory scene analy- sis, ” Ph.D. dissertation, Massachusetts Institute of T echnology , 1996. [7] M. Cooke, Modelling Auditory Pr ocessing and Organisation . Cam- bridge University Press, 2005. [8] D. W ang and G. J. Brown, Computational Auditory Scene Analysis: Principles, Algorithms, and Applications . Wiley-IEEE Press, 2006. [9] Y . Shao and D. W ang, “Model-based sequential organization in cochan- nel speech, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 14, no. 1, pp. 289–298, Jan. 2006. [10] K. Hu and D. W ang, “ An Unsupervised Approach to Cochannel Speech Separation, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 21, no. 1, pp. 122–131, Jan. 2013. [11] M. N. Schmidt and R. K. Olsson, “Single-Channel Speech Separation using Sparse Non-Negati ve Matrix Factorization, ” in Pr oc. INTER- SPEECH , 2006, pp. 2614–2617. [12] P . Smaragdis, “Conv olutiv e Speech Bases and Their Application to Supervised Speech Separation, ” IEEE/ACM Tr ans. A udio, Speech, Lang. Pr ocess. , vol. 15, no. 1, pp. 1–12, Jan. 2007. [13] J. L. Roux, F . W eninger , and J. R. Hershey , “Sparse NMF – half-baked or well done?” Mitsubishi Electric Research Labs (MERL), T ech. Rep. TR2015-023, 2015. [14] D. D. Lee and H. S. Seung, “ Algorithms for Non-ne gativ e Matrix Factorization, ” in NIPS , 2000, pp. 556–562. [15] T . T . Kristjansson et al. , “Super-human multi-talker speech recognition: the IBM 2006 speech separation challenge system, ” in Proc. INTER- SPEECH , 2006, pp. 97–100. [16] T . V irtanen, “Speech Recognition Using Factorial Hidden Markov Mod- els for Separation in the Feature Space, ” in Pr oc. INTERSPEECH , 2006. [17] M. Stark, M. W ohlmayr, and F . Pernkopf, “Source-Filter-Based Single- Channel Speech Separation Using Pitch Information, ” IEEE/A CM Tr ans. Audio, Speech, Lang. Pr ocess. , vol. 19, no. 2, pp. 242–255, Feb . 2011. [18] Z. Ghahramani and M. I. Jordan, “Factorial Hidden Markov Models, ” Machine Learning , vol. 29, no. 2-3, pp. 245–273, 1997. [19] I. Goodfellow , Y . Bengio, and A. Courville, Deep Learning . MIT Press, 2016. [Online]. A vailable: http://www .deeplearningbook.org 12 [20] D. Y u, L. Deng, and G. E. Dahl, “Roles of Pre-Training and Fine- T uning in Context-Dependent DBN-HMMs for Real-W orld Speech Recognition, ” in NIPS W orkshop on Deep Learning and Unsupervised F eature Learning , 2010. [21] G. E. Dahl, D. Y u, L. Deng, and A. Acero, “Context-Dependent Pre- T rained Deep Neural Networks for Large-V ocabulary Speech Recogni- tion, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 20, no. 1, pp. 30–42, Jan. 2012. [22] F . Seide, G. Li, and D. Y u, “Conversational speech transcription using context-dependent deep neural networks, ” in Pr oc. INTERSPEECH , 2011, pp. 437–440. [23] G. Hinton et al. , “Deep Neural Networks for Acoustic Modeling in Speech Recognition: The Shared V iews of Four Research Groups, ” IEEE Sig. Pr ocess. Mag. , vol. 29, no. 6, pp. 82–97, Nov . 2012. [24] W . Xiong et al. , “ Achieving Human Parity in Conv ersational Speech Recognition, ” arXiv:1610.05256 [cs] , 2016. [25] G. Saon et al. , “English Conv ersational T elephone Speech Recognition by Humans and Machines, ” arXiv:1703.02136 [cs] , 2017. [26] Y . W ang and D. W ang, “T owards Scaling Up Classification-Based Speech Separation, ” IEEE/ACM T rans. Audio, Speech, Lang. Process. , vol. 21, no. 7, pp. 1381–1390, Jul. 2013. [27] Y . W ang, A. Narayanan, and D. W ang, “On Training T argets for Supervised Speech Separation, ” IEEE/ACM Tr ans. A udio, Speech, Lang. Pr ocess. , vol. 22, no. 12, pp. 1849–1858, 2014. [28] Y . Xu, J. Du, L.-R. Dai, and C.-H. Lee, “ An Experimental Study on Speech Enhancement Based on Deep Neural Networks, ” IEEE Sig. Pr ocess. Let. , vol. 21, no. 1, pp. 65–68, Jan. 2014. [29] F . W eninger et al. , “Speech Enhancement with LSTM Recurrent Neural Networks and Its Application to Noise-Robust ASR, ” in L V A/ICA . Springer , 2015, pp. 91–99. [30] P .-S. Huang, M. Kim, M. Hasegawa-Johnson, and P . Smaragdis, “Joint Optimization of Masks and Deep Recurrent Neural Networks for Monaural Source Separation, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 23, no. 12, pp. 2136–2147, 2015. [31] J. Chen et al. , “Large-scale training to increase speech intelligibility for hearing-impaired listeners in novel noises, ” J . Acoust. Soc. Am. , vol. 139, no. 5, pp. 2604–2612, 2016. [32] M. K olbæk, Z. H. T an, and J. Jensen, “Speech Intelligibility Potential of General and Specialized Deep Neural Network Based Speech En- hancement Systems, ” IEEE/A CM T rans. Audio, Speech, Lang. Pr ocess. , vol. 25, no. 1, pp. 153–167, 2017. [33] J. Du et al. , “Speech separation of a target speaker based on deep neural networks, ” in ICSP , 2014, pp. 473–477. [34] T . Goehring et al. , “Speech enhancement based on neural networks improves speech intelligibility in noise for cochlear implant users, ” Hearing Researc h , vol. 344, pp. 183–194, 2017. [35] C. W eng, D. Y u, M. L. Seltzer, and J. Droppo, “Deep Neural Net- works for Single-Channel Multi-T alker Speech Recognition, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 23, no. 10, pp. 1670–1679, 2015. [36] J. R. Hershey , Z. Chen, J. L. Roux, and S. W atanabe, “Deep clustering: Discriminativ e embeddings for segmentation and separation, ” in Proc. ICASSP , 2016, pp. 31–35. [37] Z. Chen, Y . Luo, and N. Mesgarani, “Deep attractor network for single- microphone speaker separation, ” in Proc. ICASSP , 2017, pp. 246–250. [38] D. Y u, M. K olbæk, Z.-H. T an, and J. Jensen, “Permutation Inv ariant T raining of Deep Models for Speaker-Independent Multi-talker Speech Separation, ” in Pr oc. ICASSP , 2017, pp. 241–245. [39] Y . Isik et al. , “Single-Channel Multi-Speaker Separation Using Deep Clustering, ” in Pr oc. INTERSPEECH , 2016, pp. 545–549. [40] Z. Chen, “Single Channel Auditory Source Separation with Neural Network, ” Ph.D., Columbia Uni versity , United States – New Y ork, 2017. [41] S. Hochreiter and J. Schmidhuber , “Long short-term memory, ” Neural Comput , vol. 9, no. 8, pp. 1735–1780, 1997. [42] D. S. W illiamson, Y . W ang, and D. W ang, “Complex Ratio Masking for Monaural Speech Separation, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 24, no. 3, pp. 483–492, Mar . 2016. [43] H. Erdogan, J. R. Hershey , S. W atanabe, and J. L. Roux, “Deep Recurrent Networks for Separation and Recognition of Single Channel Speech in Non-stationary Background Audio, ” in New Era for Robust Speech Recognition: Exploiting Deep Learning . Springer, 2017. [44] E. V incent, R. Gribonv al, and C. Fevotte, “Performance measurement in blind audio source separation, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 14, no. 4, pp. 1462–1469, 2006. [45] H. Erdogan, J. R. Hershey , S. W atanabe, and J. L. Roux, “Phase-sensitiv e and recognition-boosted speech separation using deep recurrent neural networks, ” in Pr oc. ICASSP , 2015, pp. 708–712. [46] Y . T u et al. , “Deep neural network based speech separation for robust speech recognition, ” in ICSP , 2014, pp. 532–536. [47] D. Y u, K. Y ao, and Y . Zhang, “The Computational Network T oolkit, ” IEEE Sig. Process. Mag. , vol. 32, no. 6, pp. 123–126, Nov . 2015. [48] A. Agarwal et al. , “ An introduction to computational networks and the computational network toolkit, ” Microsoft T echnical Report { MSR- TR } -2014-112, T ech. Rep., 2014. [49] A. Rix, J. Beerends, M. Hollier , and A. Hekstra, “Perceptual ev aluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, ” in Pr oc. ICASSP , vol. 2, 2001, pp. 749–752. [50] J. Garofolo, D. Graf f, P . Doug, and D. Pallett, “CSR-I (WSJ0) Complete LDC93s6a, ” 1993, philadelphia: Linguistic Data Consortium. [51] Y . Gal and Z. Ghahramani, “ A Theoretically Grounded Application of Dropout in Recurrent Neural Networks, ” , Dec. 2015. [52] X. L. Zhang and D. W ang, “ A Deep Ensemble Learning Method for Monaural Speech Separation, ” IEEE/ACM T rans. Audio, Speech, Lang. Pr ocess. , vol. 24, no. 5, pp. 967–977, May 2016. [53] S. Nie, H. Zhang, X. Zhang, and W . Liu, “Deep stacking networks with time series for speech separation, ” in Pr oc. ICASSP , 2014, pp. 6667– 6671. [54] Z.-Q. W ang and D. W ang, “Recurrent Deep Stacking Networks for Supervised Speech Separation, ” in Pr oc. ICASSP , 2017, pp. 71–75. [55] Y . Bengio, J. Louradour, R. Collobert, and J. W eston, “Curriculum Learning, ” in ICML , 2009, pp. 41–48. Morten Kolbæk received the B.Eng. degree in electronic design at Aarhus University , Business and Social Sciences, AU Herning, Denmark, in 2013 and the M.Sc. in signal processing and computing from Aalborg University , Denmark, in 2015. He is cur- rently pursuing his PhD degree at the section for Sig- nal and Information Processing at the Department of Electronic Systems, Aalborg University , Denmark. His research interests include speech enhancement, deep learning, and intelligibility improv ement of noisy speech. Dong Y u (M’97-SM’06) is a distinguished scientist and vice general manager at T encent AI Lab . Before joining T encent, he was a principal researcher at Microsoft Research where he joined in 1998. His pioneer works on deep learning based speech recog- nition have been recognized by the prestigious IEEE Signal Processing Society 2013 and 2016 best paper award. He has served in various technical commit- tees, editorial boards, and conference organization committees. Zheng-Hua T an (M’00–SM’06) is an Associate Professor and a co-head of the Centre for Acoustic Signal Processing Research (CASPR) at Aalborg Univ ersity , Denmark. He was a Visiting Scientist at MIT , USA, an Associate Professor at SJTU, China, and a postdoctoral fellow at KAIST , K orea. His research interests include speech and speaker recognition, noise-robust speech processing, multi- modal signal processing, social robotics, and ma- chine learning. He has served as an Associate/Guest Editor for several journals. Jesper Jensen is a Senior Researcher with Oticon A/S, Denmark, where he is responsible for scouting and dev elopment of signal processing concepts for hearing instruments. He is also a Professor in Dept. Electronic Systems, Aalborg Uni versity . He is also a co-head of the Centre for Acoustic Signal Processing Research (CASPR) at Aalborg Univ ersity . His work on speech intelligibility prediction receiv ed the 2017 IEEE Signal Processing Society’ s best paper award. His main interests are in the area of acoustic signal processing, including signal retrieval from noisy observations, intelligibility enhancement of speech signals, signal processing for hearing aid applications, and perceptual aspects of signal processing.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment