Audiovisual speaker conversion: jointly and simultaneously transforming facial expression and acoustic characteristics
An audiovisual speaker conversion method is presented for simultaneously transforming the facial expressions and voice of a source speaker into those of a target speaker. Transforming the facial and acoustic features together makes it possible for th…
Authors: Fuming Fang, Xin Wang, Junichi Yamagishi
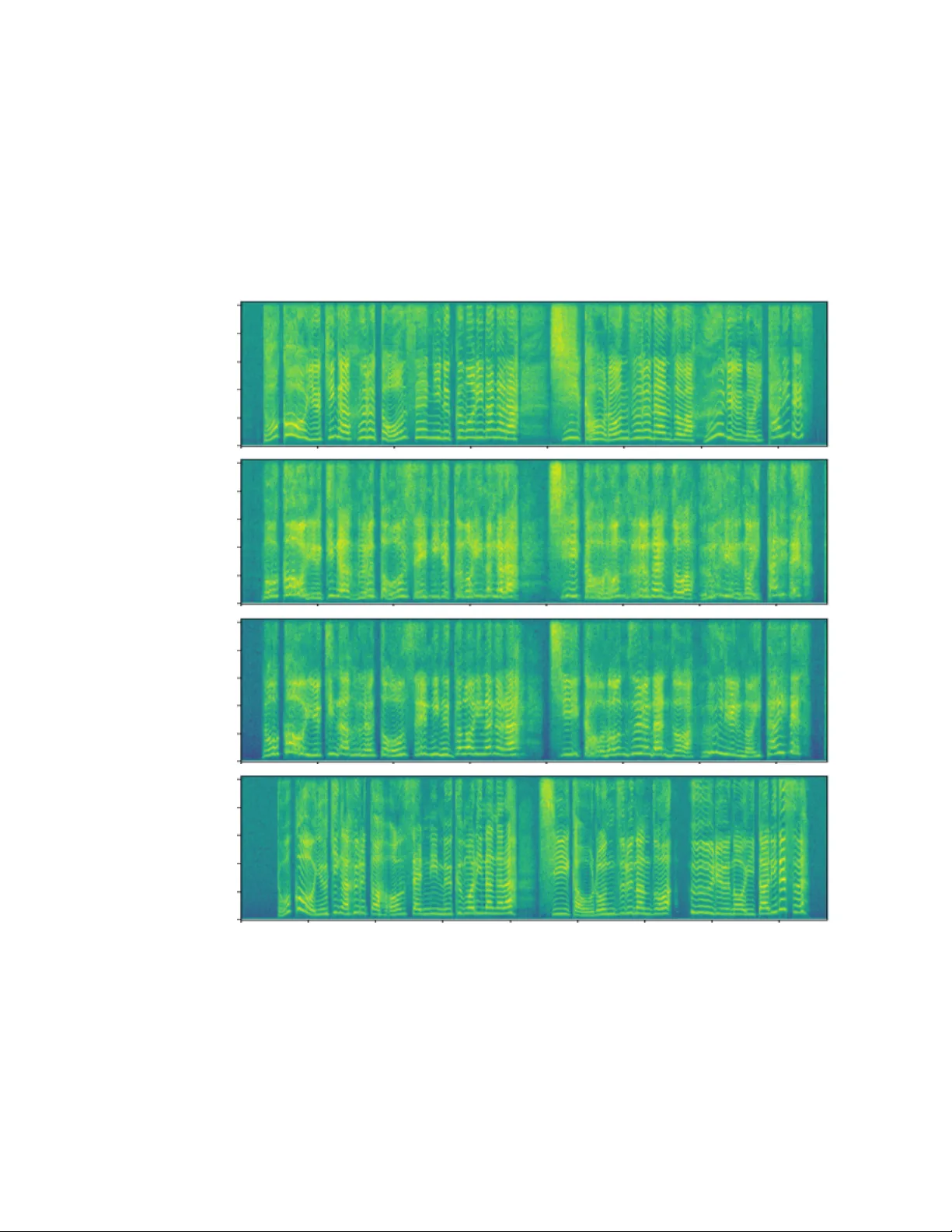
A UDIO VISU AL SPEAKER CONVERSION: JOINTL Y AND SIMUL T ANEOUSL Y TRANSFORMING F A CIAL EXPRESSION AND A COUSTIC CHARA CTERISTICS Fuming F ang 1 , Xin W ang 1 , J unichi Y amagishi 1 , 2 , Isao Echizen 1 1 National Institute of Informatics, T ok yo, Japan 2 The Uni versity of Edinb urgh, Edinb urgh, UK ABSTRA CT An audiovisual speaker conv ersion method is presented for simul- taneously transforming the facial expressions and voice of a source speaker into those of a target speaker . T ransforming the facial and acoustic features together makes it possible for the conv erted voice and facial expressions to be highly correlated and for the generated target speaker to appear and sound natural. It uses three neural net- works: a con version netw ork that fuses and transforms the facial and acoustic features, a wav eform generation network that produces the wa veform from both the con verted facial and acoustic features, and an image reconstruction network that outputs an RGB facial image also based on both the con verted features. The results of e xperiments using an emotional audiovisual database showed that the proposed method achiev ed significantly higher naturalness compared with one that separately transformed acoustic and facial features. Index T erms — Audiovisual speaker con version, multi-modality transformation, machine learning 1. INTR ODUCTION W ith the de velopment of information processing technology and the spread of Internet, voice and facial expression-based methods are being used more and more in our everyday liv es. T wo promi- nent methods are voice con version [1] and face transformation [2], which change a person’ s voice or facial expressions into that or those of another person. These methods can be used for priv acy protection, film/animation production, games, and other voice/facial signal-based transformations. Changing both v oice and facial e xpressions is important for cer - tain applications, such as video games. An obvious way to achiev e this is to separately transform the voice and facial e xpressions using two separate methods. This approach can result, howe ver , in loss of naturalness due to asynchronous v oice and facial movements due to transformation errors, delays (when considering context informa- tion), and other factors. Naturalness can be improved by using a synchronization method. Another way to improv e naturalness is to utilize the correlation between speech and facial movements [3] and jointly transform them so that the y are al ways associated together . W e hav e de veloped such a method, an audiovisual speaker con version (A VSC) method that simultaneously transforms acoustic and facial characteristics. It uses three neural networks: a conv ersion network that fuses and trans- forms the acoustic and facial features of a source speaker into those of a target speaker , a waveform generation network that produces the wa veform gi ven both the con verted acoustic and facial features, and an image generation network that outputs the RGB facial image also based on both the con verted features. W ith the proposed method, we observed higher naturalness and quality than when the acoustic and facial features were separately transformed. This appears to be the first ev er research on integrating voice con version and face transfor- mation in one system 1 . The rest of this paper is organized as follows. Section 2 dis- cusses the differences between the proposed method and related ones. Section 3 describes the proposed method. Section 4 describes the experimental conditions, and Section 5 presents and discusses the results. Finally , Section 6 summarizes the key points and men- tions future work. 2. RELA TED WORK The proposed method is related to work in four areas: audiovisual voice conv ersion, audiovisual speech enhancement, lip mov ement- to-speech synthesis, and speech-to-lip mov ement synthesis. T amura et al. [4] proposed an audiovisual voice conv ersion method that learns highly correlated acoustic and lip mo vement fea- tures by using deep canonical correlation analysis [5] and then ties them together as a new feature. They reported significant improve- ment in terms of speech quality under noisy conditions compared with using acoustic feature only . Gabbay et al. [6] proposed an audiovisual speech enhancement method that fuses lip feature and a noisy spectrum using a neural network and directly predicts a clean spectrum. Gogate et al. [7] and Afouras et al. [8] developed similar speech enhancement methods that predict a mask from lip images and noisy acoustic features using a neural network to filter out noise. A lip movement-to-speech synthesis system was developed by Kumar et al. [9] that pairs mouth image sequence obtained using multi-view cameras with the corresponding audio to learn a map- ping function. Kumar et al. [10] and Suwajanakorn et al. [11] de vel- oped similar speech-to-lip movement synthesis methods that gener- ate mouth keypoints from audio information and then render RGB images of the mouth from the mouth shape (represented by the ke y- points). T aylor et al. [12] used speech to control an av atar . The proposed method dif fers from these methods in that it uses not only lip mov ements but also facial expressions and mov ements. Furthermore, it transforms both audio and facial expressions. 3. PR OPOSED METHOD The main idea of the proposed A VSC method is to correlate acoustic and facial characteristics so that they can compensate for each other during transformation and achieve high naturalness. Figure 1 illus- trates an implementation of the proposed method, which uses three networks: an audiovisual transformation network, a W aveNet [13], and an image reconstruction network. The audiovisual transforma- tion network is used to conv ert acoustic and facial features from a 1 A demonstration is av ailable at https://nii- yamagishilab. github.io/avsc/index.html I mage reconstruction Mel - spectrum Waveform Video WaveNet Audiovisual transformation Sour ce speaker Targe t speaker Targe t speaker Mel - spectrum VG G fea t ur e face keypoi nt s VG G fea t ur e& face keypoi nt s VG G Ope nPos e Fig. 1 . An implementation of proposed audiovisual speaker con ver - sion method. source speaker to a target speaker . The W av eNet and the image re- construction network synthesize speech and RGB images from the transformed acoustic and facial features, respectively . Finally , a video of the target speaker is created using the synthesized speech and image sequence. 3.1. A udiovisual transformation network The acoustic feature is the mel-spectrum with 80 dimensions. It is extracted from the wav eform by setting the window size to 25 ms and the hop length to 5 ms. The facial feature is extracted using a pre-trained V GG-19 [14] netw ork. The 17th hidden layer’ s output is used (denoted as “VGG feature”). Because the VGG-19 is stacked by conv olutional neural network (CNN) [15] and max-pooling layers followed by fully connected layers, most of the original geometric information is lost, and only high-lev el features are preserved. T o en- able facial geometric information to be used, f acial k eypoints are ex- tracted from each video frame by using OpenPose [16]. These key- points describe the location and shape of a face. For example, they mark the contours of the jaw , mouth, nose, eyes, and eyebro ws. The VGG feature (4096 dimensions) and face ke ypoints ( 70 × 2 = 140 dimensions) are concatenated to create a new facial feature (4236 dimensions). In addition, since video data has a frame rate of 25 fps (40 ms per frame), a facial feature corresponds to eight mel-spectrum frames. Figure 2 sho ws the architecture of the audiovisual transforma- tion netw ork, which contains a stack of 1-D con volutional layers. Its design was inspired by the work of Afouras et al. [8]. The con vo- lutions are performed along the temporal dimension, and the feature dimension is treated as channel. This makes it possible to match the sampling rates for the acoustic and facial features by adjusting the stride. This design also enables context information to be taken into account and thereby generate more fluent audio and facial move- ments. The network consists of fi ve sub-networks and two output layers. Based on sampling rate of the facial feature, The lower left sub-network down-samples the acoustic feature by performing con- volution three time with a stride of two. The lower right one main- tains the facial feature sampling rate and reduces the feature dimen- sion. The middle one fuses acoustic and facial information and asso- ciates them together . The upper left one up-samples and transforms the fused features into the target speaker’ s acoustic feature domain using transposed con volution [17] layers. The upper right one trans- forms the fused features into target speaker’ s facial feature domain. In addition, the feature maps having the same shape are connected by a residual path [18]. Batch normalization [19] is performed in each hidden layer after rectified linear unit (ReLU) [20] activ ation. Conv1D ReLU BN Conv block Conv bl ock x 4 l ay er s C=[2 048 , 2 048 , 204 8, 204 8] S=[1 , 1, 1, 1 ] Mel -spectrum Length=400 , C =80 VGG feature & face keypoints Length=50 , C =423 6 Conv bl ock x 4 l ay er s C=[1 28, 25 6, 51 2, 102 4] S=[1 , 2, 2, 2 ] Conv bl ock x 4 l ay er s C=[4 000 , 3 000 , 200 0, 102 4] S=[1 , 1, 1, 1 ] Deco nv bl oc k x 4 l ay er s C=[1 024 , 5 12, 2 56, 12 8] S=[1 , 2, 2, 2 ] Conv bl ock x 4 l ay er s C=[1 024 , 2 000 , 300 0, 400 0] S=[1 , 1, 1, 1 ] Mel -spectrum Length = 400, C= 80 VGG feature & face keypoints Length = 50, C= 4236 Residual path Conv1D, C= 80, S=1 Conv1D, C= 423 6, S=1 Decon v1D ReLU BN Dec onv block Fig. 2 . Audiovisual transformation network. “BN” denotes batch normalization, “Conv1D” denotes 1-D CNN layer, “Decon v1D” means transposed 1-D CNN layer, “C” means number of channels for each layer , and “S” means stride for each layer . K ernel size for all con volution layers is fi ve. Activ ation function of hidden layers is ReLU and that of output layers is linear function. Batch normaliza- tion is performed in all hidden layers and not in output layer . Resid- ual path connects feature maps having same shape. The training data is truncated ev ery two seconds, so the mel- spectrum and facial feature hav e shapes of 400 × 80 and 50 × 4236 , respectiv ely . The L1 norm is used as the training objectiv e, and the acoustic part loss is weighted by 10. During the test phase, the entire length of test data was input to the network. 3.2. W av eNet The W av eNet is used to conv ert the transformed mel-spectrum and facial feature into the speech waveform. W aveNet is an autore- gressiv e [21] neural-network-based wav eform model that generates wa veform sampling points one by one. The W aveNet structure is the same as that of the one used in another study [22] except the condition module which takes in the mel-spectrum as input. It consists of a linear projection layer, 40 di- lated conv olution [23] layers, a post-processing block with a softmax output layer , and a condition module. The linear projection layer takes as input a waveform value generated in the previous time step while the condition module takes the transformed mel-spectrum and facial feature as input. Gi ven the outputs from the linear layer and the condition module, the dilated con volution layers compute hid- den features, which the post-processing module uses to compute the distribution waveform sampling point for the current time step. A wa veform value is generated from this distribution, and this process is repeated to generate the entire wa veform. 3.3. Image reconstruction network The image reconstruction network synthesizes an RGB image from the transformed acoustic and facial features. It contains nine stack ed layers: two fully connected layers and seven con volution layers, as shown on the left in Figure 3. Eight frames of acoustic features and one frame of facial feature are concatenated and input. The network first transforms the concatenated feature into a fused feature with 4096 dimensions using two fully connected layers. The fused feature is then reshaped into a 2-D image ( 64 × 64 × 1 ) and sent to the next con volution layer . Finally , an image ( 256 × 256 × 3 ) is generated by performing con volutions and transposed con volutions. T raining of the image reconstruction network is based on a least squares generative adversarial network (LSGAN) [24] consisting of Generator: Discriminator: C onv2D, K=31x31 C onv2D, K=31x31 Dec onv2D, K=5x5 C onv2D, K=5x5 Deconv 2D, K=5x 5 C onv2D, K=5x5 C onv2D, K=5x5 RGB image FC 4096 FC 4096 Acoustic & visual features C onv2D, K=9 x9 C onv2D, K=9x9 C onv2D, K=9 x9 max po ol i ng C onv2D , K= 9 x9 FC 256 FC Image (256x256x3) Real/fake 64x64x1 128x128x128 256x256x64 256x256x3 64x64x64 Fig. 3 . Image reconstruction network. Generator is used to recon- struct image from acoustic and visual features. Discriminator is an additional network used for training generator using adversarial loss. “Con v2D” means 2-D CNN layer , “Deconv2D” means transposed 2-D CNN layer , “FC” means fully connected layer , and “K” means kernel size. The conv olution layers in the generator have (from the bottom) 64, 64, 128, 128, 64, 64, and 3 channels. The Con v2D lay- ers have a stride of one, and the Decon v2D layers have a stride of two. The Conv2D layers in the discriminator have (from the bot- tom) 8, 16, 32, and 32 channels. Both the Con v2D and max pooling layers hav e a stride of two. Activ ation function of all hidden layers is ReLU. Batch normalization is performed in the generator before activ ation and not in the discriminator . a generator and a discriminator (Figure 3 right side). The discrim- inator maximizes the probability of data from training images and minimizes the probability of generated images from the generator . The generator striv es to generate images similar to the training data in order to maximize the probability and fool the discriminator . The L1 norm (weighted by 10) is used to stabilize the training process. 4. EXPERIMENT AL SETUP W e compared the performance of the proposed A VSC method with a baseline method that separately transforms acoustic and facial fea- tures. W e carried out an objectiv e and a subjective experiment. The objectiv e experiment ev aluated the correlation between speech and lip movements. The subjectiv e experiment evaluated the naturalness, quality , and speaker similarity of the con verted speech and video. 4.1. Database T o accurately ev aluate the correlation between audio and facial fea- tures, we created an emotional audiovisual database using input from two Japanese female actors. Sev en emotions were defined: neutral, normal happiness, st rong happiness, normal sadness, strong sadness, normal anger , and strong anger . For each emotion, we used 100 different sentences selected from dialogs in nov els. W e asked the two a ctors to utter each sentence while displaying the corresponding emotion. Four people monitored the recording sessions, and if any of them felt that the target emotion was not displayed in the speech or facial expression, the actor was instructed to repeat the recording of that sentence. The recording took place in a soundproof chamber . A con- denser microphone (NEUMANN87) and a video camera (Sony HDR-720V/B) were set at front of the actor . A green cloth sheet was used as the background. The audio was recorded at 96 kHz with 24-bit resolution. The video was recorded at 60 fps with 1920 × 1080 resolution. There were 17 recording sessions in total. A clapperboard was clapped shut at the beginning of each session to enable the audio to be synchronized with the video. Finally , the audio signal recorded by the video camera was replaced with that recorded using the condenser microphone. Since the two actors used the same sets of sentences, the database had parallel recordings (700 per actor). The duration was approximately 1h10min for each actor . The a verage sentence duration was 5.9 s. W e refer to the two actors as speakers F01 and F02. 4.2. T raining data and test data W e designated speaker F01 as the source speaker and F02 as the tar - get speaker . W e randomly selected 90 data samples for each emotion as training data (630 samples in total) for each speaker . The remain- ing 70 samples were used as test data. W e do wn-sampled the audio signal to 48 kHz with 16-bit resolution and then extracted the mel- spectrum. W e do wn-sampled the video signal to 25 fps, centered the speaker , and resized the video to 1080 × 1080 . W e then extracted the image and resized it to 224 × 224 for VGG feature extraction and 256 × 256 for face keypoint e xtraction as well as for use as training data for the image reconstruction network. 4.3. Proposed method setup For dynamic time warping (DTW)-based alignment, the distance be- tween features from the tw o speakers was calculated by summing the dimension-av eraged L2-norm of the acoustic feature and that of the facial feature (we tied ev ery eight acoustic features to match length of the facial feature). The learning rate for the audiovisual trans- formation network was 10 − 4 , the mini-batch size was 64, and the number of epochs was 600. The W aveNet was adapted from a pre-trained model [22] that was trained using 15 hours of Japanese speech data. W e fine tuned ov er 199 epochs using the F02 training data. The number of epochs was set on the basis of the results of a preliminary experiment. The image reconstruction network was trained using the F02 training data. The learning rates were set to 10 − 3 and 10 − 5 for the generator and discriminator, respectively , the mini-batch size was 64, and number of epochs was 30. 4.4. Baseline setup For the baseline method, we remov ed the acoustic-related or facial- related part from the proposed method. In addition, since it was not necessary for the baseline method to do wn- or up-sample acous- tic features, we changed the stride of the audiovisual transforma- tion network to one. From the results of a preliminary experiment on W aveNet adaptation, we set the number of epochs to 100. The other hyper-parameters (learning rate, mini-batch size, and number of epochs) were the same as for the proposed method. As additional information, we tuned the learning rate and number of epochs us- ing the baseline method and directly applied them to the proposed method. W e did not tune mini-batch size. 4.5. Evaluation setup W e ev aluated the correlation between the conv erted speech and lip mov ements using canonical correlation analysis, which calculates correlation coefficient r between two sequences. W e re-extracted the mel-spectrum and lip keypoints from the con verted speech and im- ages. W e set the window length and hop length for the mel-spectrum to 40 ms and 40 ms, respectiv ely . The naturalness and quality were evaluated on a 1-to-5 Likert mean opinion score (MOS) scale. The speaker similarity was ev alu- ated using a preference test. The evaluation was carried out by means of a crowdsourced web-based interface. On each web page, we pre- sented three questions about naturalness and quality for the audio- only ev aluation case, the visual-only ev aluation case, and the audio- visual ev aluation case. W e presented only audio or silent video for the audio-only evaluation case and the visual-only ev aluation case. For the audio visual ev aluation case, we asked the ev aluators to view 0 10 20 30 40 50 60 70 80 90 100 Distr ib ution (%) T arget speak er Proposed Baseline 0 ≤ r ≤ 0.6 0.6 < r ≤ 0.8 0.8 < r ≤ 1.0 Fig. 4 . Distribution of correlation coef ficient r between mel- spectrum and lip mov ements. a video and assess the quality of speech, image, and synchronization between speech and lip movement. W e also presented additional three questions about speaker similarity for the audio-only ev alu- ation case, visual-only e valuation case, and audiovisual ev aluation case. The ev aluators were limited to a maximum of 50 pages, and they had to listen/view all samples and answer all questions. There was a total of 186 valid ev aluators, and they produced 4995 page data points, which is equiv alent to 35.7 ev aluations per sample. The statistical significance analysis was based on an unpaired two-tail t -test with a 99% confidence interv al. 5. RESUL TS 5.1. Correlation between speech and lip movements Although our main intention is to correlate v oice and facial ex- pression, the proposed method includes synchronized generation of speech and lip mov ements. Figure 4 shows the distribution of correlation coef ficients between the mel-spectrum and lip mov e- ments. The correlation was higher for the proposed method than for the baseline. This suggests that acoustic and facial feature are more closely associated if they are jointly and simultaneously transformed. Howe ver , there was a gap between the results for the proposed method and for the target speak er . 5.2. Subjective evaluation As shown in T able 1, the MOS values with the proposed method were significantly better in both the audio-only and audiovisual ev al- uation cases achiev ed than with the baseline method. One reason was that the facial feature compensated for the acoustic feature and the proposed method achiev ed better synchronous. The slightly bet- ter performance of the proposed method in the visual-only ev alua- tion case is attributed to the facial feature dominating the fused fea- ture, making it difficult to take advantage of the acoustic feature. The scores for the emotional test samples were smaller than those for the neutral samples in almost case with the baseline method. It was possible to achiev e a higher or similar score as the neutral one by fusing both the acoustic and facial features. e.g., sadness in the audio-only ev aluation case and happiness in the audiovisual ev alu- ation case. This indicates that facial movements and some speech characteristics might help enhance emotion transformation. The preference test results (Figure 5) were similar . The proposed method achiev ed higher speaker similarity than the baseline method for the audio-only and audiovisual ev aluation cases. This might be because facial identity and voice identity helped to estimate accurate parameters of the networks. 6. SUMMAR Y AND FUTURE WORK Our proposed audiovisual speaker conv ersion method simultane- ously transforms voice and facial expression of a source speaker into those of a target speaker . W e implemented this method us- ing three networks: a con version network fuses and transforms the acoustic and facial features of the source speaker into those of T able 1 . MOS values for speech, visual, and audiovisual natural- ness/quality . “Pr” means proposed method, “Bs” means baseline method, and “+” indicates strong emotion. Emotion type Evaluation modality Audio-only V isual-only Audiovisual Pr Bs Pr Bs Pr Bs Neutral 2.70 2.33 3.79 3.65 3.37 2.98 Happiness 2.39 2.15 3.69 3.73 3.41 2.93 +Happiness 2.33 2.05 3.36 3.33 3.25 2.85 Sadness 2.72 2.24 3.32 3.40 3.21 2.95 +Sadness 2.24 2.01 3.46 3.45 3.31 3.16 Anger 2.46 2.08 3.42 3.35 3.22 2.99 +Anger 1.96 1.79 3.27 3.11 3.06 2.76 A verage 2.40 2.09 3.47 3.43 3.26 2.95 0 10 20 30 40 50 60 70 80 90 100 Distr ib ution (%) A v er age +Anger Anger +Sadness Sadness +Happiness Happiness Neutr al A v er age +Anger Anger +Sadness Sadness +Happiness Happiness Neutr al A v er age +Anger Anger +Sadness Sadness +Happiness Happiness Neutr al A udio visual e v aluation Visual-only e v aluation A udio-only e v aluation Baseline No pref erence Proposed Fig. 5 . Speaker similarity preference test results. “+” means strong emotion. the target speaker , a W aveNet synthesizes the waveform from the con verted features, and an image reconstruction network generates RGB images from the con verted features. Experiments using an emotional audiovisual database showed that the proposed method can achieve higher naturalness/quality and speaker similarity than a baseline method that separately transforms the acoustic and facial features. Since the facial features may dominate the transformation, we plan to improve our method to better balance the acoustic and facial features. The use of a parallel training approach makes it necessary to align training data, so we had to carefully balance the acoustic and facial features. W e will thus consider dev eloping a non-parallel training method [25] for audiovisual speaker con version. 7. A CKNO WLEDGEMENT This work w as supported by JSPS KAKENHI Grant Numbers (16H06302, 17H04687, 18H04120, 18H04112, 18KT0051) and by JST CREST Grant Number JPMJCR18A6, Japan. 8. REFERENCES [1] Masanob u Abe, Satoshi Nakamura, Kiyohiro Shikano, and Hisao Kuwabara, “V oice con version through vector quantiza- tion, ” Journal of the Acoustical Society of Japan (E) , vol. 11, no. 2, pp. 71–76, 1990. [2] Justus Thies, Michael Zollhofer , Marc Stamminger, Christian Theobalt, and Matthias Nießner , “Face2face: Real-time face capture and reenactment of RGB videos, ” in Proc. CVPR , 2016, pp. 2387–2395. [3] Gopal Ananthakrishnan, Olov Engwall, and Daniel Neiberg, “Exploring the predictability of non-unique acoustic-to- articulatory mappings, ” IEEE T ransactions on Audio, Speech, and Language Processing , v ol. 20, no. 10, pp. 2672–2682, 2012. [4] Satoshi T amura, K ento Horio, Hajime Endo, Satoru Hayamizu, and T omoki T oda, “ Audio-visual voice conv ersion using deep canonical correlation analysis for deep bottleneck features, ” in Pr oc. Interspeech , 2018, pp. 2469–2473. [5] Galen Andre w , Raman Arora, Jeff Bilmes, and Karen Liv escu, “Deep canonical correlation analysis, ” in International Con- fer ence on Machine Learning , 2013, pp. 1247–1255. [6] A viv Gabbay , Asaph Shamir , and Shmuel Peleg, “V isual speech enhancement using noise-in variant training, ” arXiv pr eprint arXiv:1711.08789 , 2017. [7] Mandar Gogate, Ahsan Adeel, Ricard Marxer , Jon Barker , and Amir Hussain, “DNN dri ven speaker independent audio-visual mask estimation for speech separation, ” in Pr oc. Interspeech , 2018, pp. 2723–2727. [8] T riantafyllos Afouras, Joon Son Chung, and Andrew Zisser- man, “The con versation: Deep audio-visual speech enhance- ment, ” in Proc. Interspeech , 2018, pp. 3244–3248. [9] Y aman Kumar , Mayank Aggarwal, Pratham Nawal, Shin’ichi Satoh, Rajiv Ratn Shah, and Roger Zimmerman, “Harness- ing ai for speech reconstruction using multi-view silent video feed, ” in 2018 ACM Multimedia Confer ence (MM ’18) , 2018. [10] Rithesh Kumar , Jose Sotelo, Kundan Kumar , Alexandre de Br ´ ebisson, and Y oshua Bengio, “Obamanet: Photo-realistic lip-sync from text, ” in 31st Conference on Neural Information Pr ocessing Systems (NIPS 2017) , 2017. [11] Supasorn Suwajanakorn, Stev en M Seitz, and Ira Kemelmacher -Shlizerman, “Synthesizing obama: learn- ing lip sync from audio, ” A CM T ransactions on Gr aphics (TOG) , v ol. 36, no. 4, pp. 95, 2017. [12] Sarah T aylor, T aehwan Kim, Y isong Y ue, Moshe Mahler, James Krahe, Anastasio Garcia Rodriguez, Jessica Hodgins, and Iain Matthews, “ A deep learning approach for generalized speech animation, ” ACM T ransactions on Graphics (TOG) , vol. 36, no. 4, pp. 93, 2017. [13] Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Si- monyan, Oriol V inyals, Alex Graves, Nal Kalchbrenner , An- drew Senior , and Koray Ka vukcuoglu, “W aveNet: A genera- tiv e model for raw audio, ” arXiv preprint , 2016. [14] Karen Simonyan and Andre w Zisserman, “V ery deep conv olu- tional networks for large-scale image recognition, ” in Interna- tional Confer ence on Learning Repr esentations (ICLR) , 2015. [15] Y ann LeCun, L ´ eon Bottou, Y oshua Bengio, and Patrick Haffner , “Gradient-based learning applied to document recog- nition, ” Pr oceedings of the IEEE , vol. 86, no. 11, pp. 2278– 2324, 1998. [16] Zhe Cao, T omas Simon, Shih-En W ei, and Y aser Sheikh, “Re- altime multi-person 2D pose estimation using Part Af finity Fields, ” in CVPR , 2017. [17] Matthe w D Zeiler , Dilip Krishnan, Graham W T aylor , and Rob Fergus, “Deconv olutional networks, ” in Pr oc. CVPR . 2010, pp. 2528–2535, IEEE. [18] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun, “Deep residual learning for image recognition, ” in Pr oc. CVPR , 2016, pp. 770–778. [19] Ser gey Ioffe and Christian Szegedy , “Batch normalization: Ac- celerating deep network training by reducing internal covariate shift, ” in Proc. ICML . 2015, pp. 448–456, JMLR.org. [20] Bing Xu, Naiyan W ang, Tianqi Chen, and Mu Li, “Empirical ev aluation of rectified acti vations in con volutional network, ” in ICML Deep Learning W orkshop , 2015. [21] Michael I Jordan, “Serial order: A parallel distributed pro- cessing approach, ” in Advances in psychology , vol. 121, pp. 471–495. Elsevier , 1997. [22] Hieu-Thi Luong, Xin W ang, Junichi Y amagishi, and Nob uyuki Nishizawa, “In vestigating accuracy of pitch-accent annota- tions in neural-network-based speech synthesis and denoising effects, ” in Pr oc. Interspeech , 2018, pp. 37–41. [23] Fisher Y u and Vladlen Koltun, “Multi-scale context aggrega- tion by dilated con volutions, ” in ICLR , 2016. [24] Xudong Mao, Qing Li, Haoran Xie, Raymond YK Lau, Zhen W ang, and Stephen Paul Smolley , “Least squares generativ e adversarial networks, ” in Proc. ICCV . IEEE, 2017, pp. 2813– 2821. [25] Fuming Fang, Junichi Y amagishi, Isao Echizen, and Jaime Lorenzo-T rueba, “High-quality nonparallel voice conv ersion based on cycle-consistent adversarial network, ” in Pr oc. ICASSP , 2018, pp. 5279–5283. 9. APPENDIX Examples of images con verted using the proposed and baseline methods are shown in Figure 6-7. It is difficult to tell which method generated higher quality images or which one generated images similar to the target speaker . Howe ver , when the audio and video were played together (the audiovisual e valuat ion case), the proposed method had better synchronization between the audio and facial mov ements than the baseline. This means that the proposed method achiev es better association between acoustic and facial features. Examples of spectrograms con verted using the proposed and baseline methods are shown in Figure 8-11. The horizontal direc- tion indicates temporal axis while the vertical direction is frequency axis with range of 0 to 8000Hz. It seems that the proposed method predicted better spectrogram than the baseline in most cases. Source speaker Baseline Proposed Target speaker Fig. 6 . Example of con verted images with neutral emotion. Source speaker Baseline Proposed Target speaker Fig. 7 . Example of con verted images with strong happiness emotion. Source speaker Baseline Proposed Target speaker Fig. 8 . Example of con verted spectrograms with neutral emotion. Source speaker Baseline Proposed Target speaker Fig. 9 . Example of con verted spectrograms with strong happiness emotion. Source speaker Baseline Proposed Target speaker Fig. 10 . Example of con verted spectrograms with strong sadness emotion. Source speaker Baseline Proposed Target speaker Fig. 11 . Example of con verted spectrograms with strong anger emotion.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment