Integrating Local Context and Global Cohesiveness for Open Information Extraction
Extracting entities and their relations from text is an important task for understanding massive text corpora. Open information extraction (IE) systems mine relation tuples (i.e., entity arguments and a predicate string to describe their relation) from sentences. These relation tuples are not confined to a predefined schema for the relations of interests. However, current Open IE systems focus on modeling local context information in a sentence to extract relation tuples, while ignoring the fact that global statistics in a large corpus can be collectively leveraged to identify high-quality sentence-level extractions. In this paper, we propose a novel Open IE system, called ReMine, which integrates local context signals and global structural signals in a unified, distant-supervision framework. Leveraging facts from external knowledge bases as supervision, the new system can be applied to many different domains to facilitate sentence-level tuple extractions using corpus-level statistics. Our system operates by solving a joint optimization problem to unify (1) segmenting entity/relation phrases in individual sentences based on local context; and (2) measuring the quality of tuples extracted from individual sentences with a translating-based objective. Learning the two subtasks jointly helps correct errors produced in each subtask so that they can mutually enhance each other. Experiments on two real-world corpora from different domains demonstrate the effectiveness, generality, and robustness of ReMine when compared to state-of-the-art open IE systems.
💡 Research Summary
The paper “Integrating Local Context and Global Cohesiveness for Open Information Extraction” presents ReMine, a novel framework designed to overcome key limitations in existing Open Information Extraction (Open IE) systems. Traditional Open IE systems operate by first identifying entity phrases within a sentence (often using pre-trained tools like Named Entity Recognizers or NP chunkers) and then discovering relational phrases between them, relying primarily on local sentence context and structure. This pipeline approach suffers from error propagation, domain sensitivity of the pre-trained tools, and a failure to leverage the redundant information present across a large corpus.
ReMine’s core innovation is a unified, joint optimization framework that integrates local contextual signals with global corpus-level statistics. It operates without relying on domain-specific NLP tools, using distant supervision from external knowledge bases to guide the learning process. The framework consists of three interconnected modules:
-
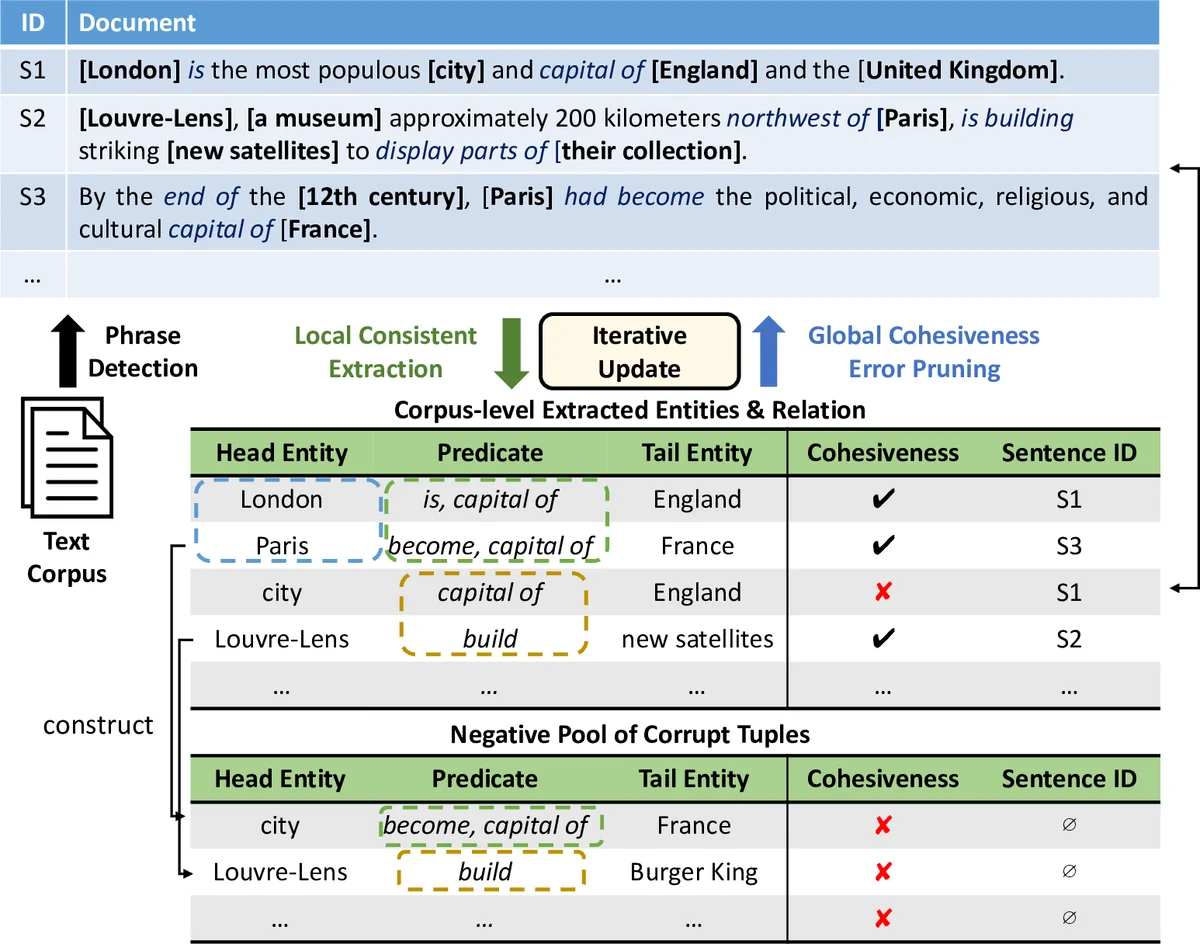
Phrase Extraction Module: This module reframes entity and relation phrase identification as a multi-type phrasal segmentation problem. Instead of relying on a pre-trained chunker, it probabilistically segments a sentence into chunks and classifies each chunk as an entity phrase, relation phrase, or background text. A random forest classifier, trained with positive samples from a knowledge base and carefully drawn negative samples from the corpus, assigns a type and a quality score to each segment. This allows ReMine to discover domain-relevant phrases directly from the target corpus.
-
Tuple Generation Module: Given the segmented phrases in a sentence, this module generates candidate relation tuples (head entity, predicate phrase, tail entity). It uses heuristics based on dependency parse shortest paths to initially pair likely subject and object entities. Crucially, it does not finalize these tuples based on local context alone.
-
Global Cohesiveness Module: This is the key component that leverages corpus-wide statistics. It learns low-dimensional vector embeddings for all entity and relation phrases appearing in the candidate tuples from the entire corpus. The learning objective is based on a translating principle (similar to TransE), where a good tuple should satisfy the equation: embedding(head entity) + embedding(relation) ≈ embedding(tail entity). By optimizing this objective, the module learns to cluster semantically similar entities and relations in the embedding space. It calculates a “cohesiveness score” for each candidate tuple, reflecting its consistency with global patterns in the corpus (e.g., “London” and “Paris” are similar because they both co-occur with phrases like “capital of”).
The power of ReMine lies in the joint training of these modules. The process is iterative: the Tuple Generation Module produces candidate tuples, which are fed to the Global Cohesiveness Module for scoring. The cohesiveness scores are then fed back to refine the tuple generation process, pruning out locally plausible but globally inconsistent extractions (e.g., “city – capital of – England”). Simultaneously, the improved extractions help train better phrase segmentations and embeddings. This closed-loop system allows the local and global signals to correct each other’s errors, leading to more accurate and robust extractions.
The authors evaluated ReMine on two real-world corpora from different domains (news and scientific abstracts). Experiments demonstrated that ReMine significantly outperformed state-of-the-art Open IE systems (like OLLIE and ClausIE) in standard extraction metrics. It also showed superior performance in the auxiliary task of entity phrase extraction compared to phrase mining baselines like AutoPhrase. The results validated the system’s effectiveness, its generality across domains (due to distant supervision and lack of domain-specific tools), and its robustness in handling noisy or domain-specific text. ReMine represents a significant step towards schema-agnostic, domain-adaptive, and accurate open-domain knowledge acquisition from text.
Comments & Academic Discussion
Loading comments...
Leave a Comment