Distributed Gradient Descent with Coded Partial Gradient Computations
Coded computation techniques provide robustness against straggling servers in distributed computing, with the following limitations: First, they increase decoding complexity. Second, they ignore computations carried out by straggling servers; and the…
Authors: Emre Ozfatura, Sennur Ulukus, Deniz Gunduz
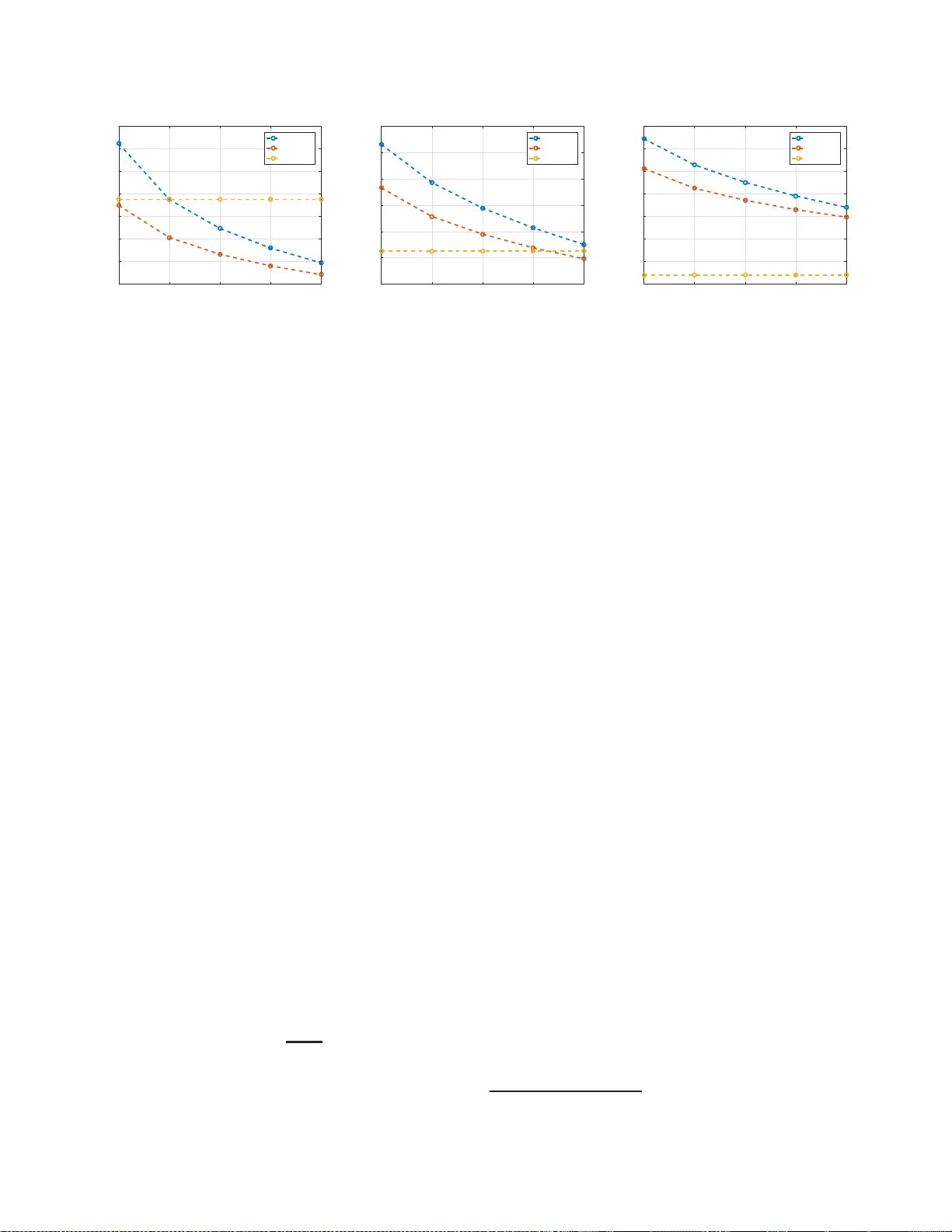
DISTRIBUTE D GRADI ENT DESCENT WITH CODED P AR TIAL GRADIENT COMPUT A TIONS E. Ozfatura † , S. Ulukus + and D. Gündüz † † Department of Electrical and Electronic Engineering, Imperial College Londo n , UK + Department of Electrical and Computer Engineering, University of Maryland, MD ABSTRA CT Coded computatio n techniques provide rob ustness against stra ggling servers in distributed co m puting , with the follow- ing limitations: First, they increase d ecoding co m plexity . Second, they ignore comp utations carried o ut by strag g ling servers; and th ey ar e typically design ed to recover the full gradient, and th us, can not provide a balance between the accuracy of th e gradient and per-iteration co mpletion time. Here we introdu ce a hyb rid ap proach , called coded partial gradient computatio n (CPGC) , that benefits from the advan- tages of both code d an d unco d ed com putation schemes, an d reduces both the computa tio n time and decoding complexity . Index T erms — Gradient descent, coded computation, maximum distance separable (MDS) codes, L T cod es. 1. INTR ODUCTION In many m a chine learning application s, the p r incipal com- putational task boils down to a matrix-vector m ultiplica- tion. Consider, fo r e xample, the minim ization of the em- pirical mean squa r ed error in linear regression L ( θ ) , 1 2 N Í N i = 1 ( y i − x T i θ ) 2 , wher e x 1 , . . . , x N ∈ R L are the d ata points with the co rrespon ding labels y 1 , . . . , y N ∈ R , and θ ∈ R L is the parameter vecto r . The optimal parameter vector can be obtained iteratively by g radient de scent (GD): θ t + 1 = θ t − η t ∇ θ L ( θ t ) , where η t is th e learning rate an d θ t is the param eter vector at the t th itera tio n. W e have ∇ θ L ( θ t ) = X T X θ t − X T y , where X = [ x 1 , . . . , x N ] T and y = [ y 1 , . . . , y N ] T . In the grad ient expression, only θ t changes over the iterations; hen ce, the ke y computatio n al task at each iteration is the matrix-vector multip lication W θ t , where W , X T X ∈ R L × L . T o speed up GD, execution o f this multiplica tio n can be distributed to K work er servers, by simply dividing W into K equ al-size disjoint submatrice s. Howe ver, the computatio n time will now b e limited by the stra ggling workers. Coded distributed comp utation has been intro duced to tolerate strag gling workers by introduc ing red u ndant com- putations [1 – 9]. Maximu m distance separab le (MDS) codes are used in [1], where m atrix W ∈ R L × L is di vided in to M disjoint submatr ices, W 1 , . . . , W M ∈ R r × L , which are th en encoded with an ( M , K ) MDS cod e, and each coded subma- trix is assigned to a different worker . Eac h worker multip lies θ t with the co ded submatrix assigned to it, and sends the result to the ma ster, wh ich can r ecover W θ t having rec eiv ed the results from any M workers. Up to K − M strag glers can be toler ated at th e expense of inc r easing the compu tation load of each worker by r = L / M [1]. Alternatively , uncoded computatio ns can be executed, and the results can be send as a cod e d messages [10–12]. H owever , th ese ap p roache s completely discard computations car ried o ut by straggling servers, and h ence, the overall computatio n al cap acity is underu tilized. Alternatively , w orkers ca n be allowed to send multiple messages to th e master per-iteration, corresp onding to partial computatio ns [2 , 5, 8, 13], which will be called multi-message communica tion ( MMC) . In [2] M M C is applied to MDS- coded co mputation utilizing th e statistics of stragglers. In- stead, rateless codes ar e proposed in [8] as they do not require the k nowledge o f th e stragg ler statistics, a n d also redu ce the decodin g comp lexity . Howe ver , rateless codes com e with an overhead, which vanishes only if the nu mber of cod ew ords goes to infinity . This, in tu rn, would increase the numb er of read/write opera tions at th e master at each iteration, limitin g the practicality in real app lications. Uncoded distributed comp u tation with MMC ( UC-MMC) is introdu ced in [5, 13, 14], and is shown to outperform coded computatio n in terms of average completion time, conclud- ing th a t code d compu tation is more effective aga inst persis- tent stragglers, and particularly when full gradient i s requir ed at each itera tion. Coded GD strategies are mainly designed for f u ll grad ient compu tation; and hen ce, the master needs to wait until all the g r adients ca n be recovered. UC-MMC, on the other h a nd, in add ition to exploitin g p artial computatio ns perfor med by straggling servers, also allows th e master t o up- date the parameter vector with only a subset o f the gradient computatio ns to l imit the per itera tion completion time. In this pa per, we introd uce a novel hybrid scheme, called coded pa rtial gradient computation (CPGC) , that brings to- gether the ad vantages o f uncoded computation, such as low decodin g com p lexity and partial g radient up dates, with those of coded comp utation, such as reduced per-iteration co mple- tion time and limited communicatio n load . Befo re presenting cumulati ve co mputation type MCC UC-MMC CPGC N 1 : N 2 = 4 , N 1 = 0 , N 0 = 0 1 1 1 N 2 : N 2 = 3 , N 1 = 1 , N 0 = 0 4 4 4 N 3 : N 2 = 3 , N 1 = 0 , N 0 = 1 4 4 4 N 4 : N 2 = 2 , N 1 = 2 , N 0 = 0 6 6 6 N 5 : N 2 = 2 , N 1 = 1 , N 0 = 1 12 8 12 N 6 : N 2 = 2 , N 1 = 0 , N 0 = 2 6 2 6 N 7 : N 2 = 1 , N 1 = 3 , N 0 = 0 0 4 4 N 8 : N 2 = 1 , N 1 = 2 , N 0 = 1 0 4 8 N 9 : N 2 = 0 , N 1 = 4 , N 0 = 1 0 1 1 T a ble 1 : Numb er of score vectors for full gradient. the design pr inciples o f this schem e , we will b riefly o utline its advantages o n a simple mo tivating example. 2. MO TIV A TING EXAMPLE Consider M = 4 comp u tation tasks, represented by subma- trices W 1 , . . . , W 4 , which are to be executed across K = 4 workers, each with a maximum co mputatio n load of r = 2 ; that is, each worker can perform up to 2 computations, due to storage o r comp utation capacity limitations. Le t us first con- sider two known distributed com putation schem e s, namely UC-MMC [5, 13] and MDS-coded comp utation (MCC ) [1]. For each sch eme, the r × K comp utation scheduling ma- trix , A , shows the assigned comp utation tasks to each worker with the ir execution o rder . More specifically , A ( i , j ) d e notes the i th co mputation task to be executed by the j th worker . In MCC, linearly indepen dent coded comp utation tasks are dis- tributed to the w orkers as follows: A m = W 1 + W 3 W 1 + 2 W 3 W 1 + 4 W 3 W 1 + 8 W 3 W 2 + W 4 W 2 + 2 W 4 W 2 + 4 W 4 W 2 + 8 W 4 . Each worker sen ds the results of its computations o nly after all of them are completed, i. e . , first w orker send s the co ncate- nation [( W 1 + W 3 ) θ t ( W 2 + W 4 ) θ t ] after c o mpleting both computatio ns; ther efore, any permutatio ns of each column vector w ould result in the same p erform ance. A m correspo n ds to a ( 2 , 4 ) MDS c ode, and hence, the master can recover the full gradien t computation from the results of any two workers. In the UC-MMC scheme with a shifted com p utation schedule [5], computa tio n scheduling matrix is gi ven by A u = W 1 W 2 W 3 W 4 W 2 W 3 W 4 W 1 , and ea c h w orker s ends the results of its com putation s sequen- tially , as soon as eac h of them is c o mpleted. This helps to reduce the per-iteration co mpletion tim e with an increase in the commu nication load [5, 13]. W ith UC-MMC, full gradient can be recovered ev en if each w orker perf orms only one com- putation, which is faster if the workers ha ve similar speeds. The compu tation scheduling matrix of CPGC is giv en by A c = W 1 W 2 W 3 W 4 W 3 + W 4 W 1 + W 3 W 2 + W 4 W 1 + W 2 . cumulati ve co mputation type MCC UC-MMC CPGC N 1 : N 2 = 4 , N 1 = 0 , N 0 = 0 1 1 1 N 2 : N 2 = 3 , N 1 = 1 , N 0 = 0 4 4 4 N 3 : N 2 = 3 , N 1 = 0 , N 0 = 1 4 4 4 N 4 : N 2 = 2 , N 1 = 2 , N 0 = 0 6 6 6 N 5 : N 2 = 2 , N 1 = 1 , N 0 = 1 12 12 12 N 6 : N 2 = 2 , N 1 = 0 , N 0 = 2 6 6 6 N 7 : N 2 = 1 , N 1 = 3 , N 0 = 0 0 4 4 N 8 : N 2 = 1 , N 1 = 2 , N 0 = 1 0 12 12 N 9 : N 2 = 1 , N 1 = 1 , N 0 = 2 0 8 8 N 10 : N 2 = 0 , N 1 = 4 , N 0 = 0 0 1 1 N 11 : N 2 = 0 , N 1 = 3 , N 0 = 1 0 4 4 T a ble 2 : Numb er of score vectors for partial gradient. 2.1. Full Gradient Perf ormance Now , let us focus o n a particular iteration , an d let N s denote the numbe r of workers that have completed exactly s comp u - tations by time t , s = 0 , . . . , r . W e define N , ( N 0 , . . . , N r ) as the cumulative compu tation type . Additionally , we intro- duce the K -dimensional score vecto r C = [ c 1 , . . . , c K ] , where c i denotes the n umber of co mputatio ns co mpleted b y the i th worker . For each schem e, the n umber of distinct score vectors with th e sam e cu mulative computation type, which allow the recovery of full gradien t is listed i n T able 1. Particularly strik- ing are the last thr ee r ows that corresp ond to cases with very few co mputation s com pleted, i.e., w h en at most on e worker completes all its assigned t asks. I n these cases, CPGC is much more likely to allow full gr adient c omputatio n; and hence, the computatio n deadline can be reduced sign ificantly wh ile still recovering th e f u ll gradient. Next, we analyze the probability of each type u nder a spe- cific comp u tation time statisti cs. W e adop t the model in [15], where the pr obability of co mpleting exactly s comp utations by time t , P s ( t ) , is gi ven by P s ( t ) = 0 , if t < s α, 1 − e − µ ( t s − α ) , s α ≤ t < ( s + 1 ) α , e − µ ( t s + 1 − α ) − e − µ ( t s − α ) ( s + 1 ) α < t , (1) where α is the m inimum requ ir ed time to finish a computation task, and µ is the average number of co m putation s comple te d in unit time. The p robab ility o f cum ulative comp utation type N ( t ) at time t is given b y Pr ( N ( t )) = Î r s = 0 P s ( t ) N s . Let T denote the full gradien t recovery time. Accord ingly , Pr ( T < t ) for CPGC is given b y Pr ( N 1 ( t )) + 4Pr ( N 2 ( t )) + 4Pr ( N 3 ( t )) + 6Pr ( N 4 ( t )) + 12 Pr ( N 5 ( t )) + 6 Pr ( N 6 ( t )) + 4Pr ( N 7 ( t )) + 8Pr ( N 8 ( t )) + Pr ( N 9 ( t )) (2) where the types N 1 , . . . , N 9 are as listed in T ab le 1 . Pr ( T < t ) for MCC and UC-M M C ca n b e written similarly . Then, one can observe th a t, for any t , CPGC has the highest Pr ( T < t ) ; and hence, the m inimum average per-iteration comp letion time E [ T ] . In th e n ext subsection, we will highlig ht the partial recoverability p r operty o f CPGC. 2.2. Partial Gradient P erformance It is kn own that stochastic GD can still guaran te e convergence ev en if each iteration is com pleted with on ly a subset of the gradient comp utations [16, 17 ]. In our example, with three out of four grad ients, sufficient accur acy may be achieved at each iteration, particularly if the straggling server is v a r ying over iterations. Th e numb e r of sco re vectors for which a par tial gradient (with at least three g radient compu tations) ca n be re- covered are giv en in T able 2. W e observe that when three gradients are su fficient to complete an iter ation UC-MMC and CPGC have the same average com p letion time statistics. Hence, CPGC can provid e a lower average per-iteration com- pletion time for full gradien t computation comp a red to UC- MMC, while achieving the same perfo rmance when partial gradients are allowed. 3. DESIGN PRINCIPLES OF CPGC In [ 8], L T codes are propo sed for distributed computatio n in order to exploit MMC with coded co m putation s. However , L T codes com e with a trade- off between the overhead and the associated cod ing/deco ding com plexity . Moreover , the origi- nal design in [8] does not allow par tial g radient recovery . The key d esign issue in an L T code is the degree dis- tribution P ( d ) . Degree of a codeword, d , chosen random ly from P ( d ) , defines the number of symbols ( W i submatrices in o ur setting) that are used in ge n erating a codeword. Then , d sym bols are chosen rando mly to f o rm a codeword. The de- gree distribution p lays an important role in the performan ce of an L T code, and the main challenge is to find the op ti- mal d egree distribution. Codew ords with smaller degrees re- duce d ecoding complexity; howe ver , h aving many cod ewords with smaller degrees increases the prob ability of linear depen- dence among co dewords. W e also n ote that, L T co de design is based on the assump tion that th e e rasure pro bability of differ- ent cod ew ords are id entical an d inde p enden t from ea c h oth e r . Howe ver, in a coded compu ting scenario , the computational tasks, each of which corre spondin g to a distinct codeword, are executed seq uentially; thus, erasure pr o babilities o f co de- words are neither identical n or indep endent. Codewords must be designed taking into account their execution orders in ord er to prevent overlaps and to minimize the a verage completion time. This is the main in tuition be h ind the CPGC scheme, and g uides the design of the co mputatio n sched u ling m atrix. 3.1. Degree L imitation T o allow pa r tial gradien t comp utation at the m aster , we limit the degree o f all codew ords by tw o; that is, each codeword (i.e., coded submatrix) is the sum of at mo st two sub matrices. Moreover , the first compu ta tio n task assigned to each worker correspo n ds to a co dew ord with degre e o ne (i.e., a W i subma- trix is assigned to e a ch worker with o ut any cod ing), while all other tasks corre sp ond to co dewords with degree two ( coded submatrices). Recall th at, d u e to the stra ggling beh avior, the first task at each worker has the high est co mpletion prob abil- ity , thus assigning un coded sub m atrices as the fir st compu ta- tion task at each worker h elps to e n able partial recovery . 3.2. Coded Data Generation In an L T co de, symb o ls (submatrices) that are linear ly com- bined to gen e rate a c o deword are chosen ran domly; however , to enable p artial g r adient recovery , we carefully design the codewords for ea c h worker . For a g iven set of submatrices W , a partitio n P is a group ing o f its elements into n onemp ty disjoin t subsets. In o ur example, we have W = { W 1 , W 2 , W 3 , W 4 } , and P = { { W 1 , W 2 } , { W 3 , W 4 } } is a p artition. No w , consider the following sche m e: for eac h Q ∈ P , a co deword c ( Q ) is generated b y Í W ′ ∈ Q W ′ . Since for any Q i , Q j ∈ P , i , j , Q i ∩ Q j = ∅ , co dewords c ( Q i ) and c ( Q j ) shar e no common submatrix. Acco r dingly , one can easily observe that if n p arti- tions are used to gen erate co ded submatr ices, ea ch submatrix W i appears in exactly n different c o ded subm atrices. I n order to generate degree-two codewords, we use partition s with subsets of size two; an d hence, exactly K / 2 coded subma tri- ces are generate d from a single par tition. Therefo re, fo r each row of the com putation scheduling ma tr ix we need exactly two partitio n s of W , and in to tal we requ ire 2 ( r − 1 ) distinc t partitions ( see [18] for details). Note that the proba b ility of not receiving the results of computatio ns correspon d ing to coded submatr ic e s in th e same column of the compu tation sch e d uling matrix are correlated, as th ey are executed by the same worker . Hence, in order to minimize the d epende n ce on a single worker , w e would like to limit the appear ance of a submatrix in any single column of the comp u tation sch eduling matrix . In the n ext section, we provide a h euristic strategy for coded subm a trix assignm ent. 4. NUMERICAL RESUL TS AND CONCLUSIONS W e will analyze and compar e the perfo rmance of three schemes, UC-MMC, CPGC a n d MCC, in terms of three perfor mance m easures, the average per-iter ation comp letion time , communica tion load and the commu nication volume . The com m unication load, defined in [5, 13], ref e rs to th e av- erage num ber o f messages transmitted to the ma ster fr om the workers per iteration, wh ereas the com munication v olume refers to th e average total size of the comp utations sent to the master per iteration. This is normalized with respect to the result of W θ , which is set as th e unit data volume. This is to distinguish between the par tial and full computatio n results sent from the workers in CPGC and MCC schemes, respectively . In CPGC we transmit many m e ssag e s of smaller size, while MCC sends a single message consisting of mul- tiple results. Commu nication v olume allo ws us to compare the amoun t of redund ant computations sent from the work - 0 5 10 15 20 Tolerence(%) 0.08 0.1 0.12 0.14 0.16 0.18 0.2 0.22 Average per-iteration completion time UC-MMC CPGC MCC (a) A verage per-iteration t ime comparison. 0 5 10 15 20 Tolerence(%) 0.8 1 1.2 1.4 1.6 1.8 2 Communication volume UC-MMC CPGC MCC (b) Communication volume comparison. 0 5 10 15 20 Tolerence(%) 5 10 15 20 25 30 35 40 Communication load UC-MMC CPGC MCC (c) Communication load comparison. Fig. 1 : Perf orman ce compariso n of UC-MCC, CPGC an d MCC sch emes for M = K = 2 0 and r = 3 ers to the master . A comm unication volume of 1 implies zero co mmun ication overhead, wh ereas a comm u nication volume larger th a n 1 implies co mmunic a tio n overhead due to transmission o f multiple messages. 4.1. Simulation Setup W e co nsider K = 20 workers and M = 20 computation tasks (submatrices) , and a co mputation loa d of r = 3 . W e set µ = 10 and α = 0 . 0 1 for the statistics of co m putation sp eed in (1). In CPGC, first com putation s assigned to the workers a re uncod e d submatrices. For the second and third rows of the computatio n sche duling matrix we use fou r different p arti- tions with the coded sub matrices as follows (assuming N is ev en): v 1 = [ W 1 + W 2 , . . . , W n + W n + 1 , . . . , W N − 1 + W N ] v 2 = [ W 1 + W 3 , . . . , W n + W n + 2 , . . . , W N − 2 + W N ] v 3 = [ W 1 + W N , . . . , W n + W N − n + 1 , . . . , W N / 2 + W N / 2 + 1 ] v 4 = [ W 1 + W N / 2 + 1 , . . . , W n + W N / 2 + n , . . . , W N / 2 + W N ] These coded submatrice s are used to fo rm a computa tio n scheduling matr ix in the following way: A ( 2 , 1 : K / 2 ) = circshift ( v 1 ; − 1 ) , A ( 2 , K / 2 + 1 : K ) = circshift ( v 2 ; − 1 ) , A ( 3 , 1 : K / 2 ) = cir cshift ( v 3 ; 1 ) , A ( 3 , K / 2 + 1 : K ) = circshift ( v 4 ; − 2 ) , where circshif t is the circula r shift oper- ator , i.e., circshift ( v ; d ) is the d times r ight shifted version of vector v . W e use th e shifted version of the vectors to prevent multiple ap pearan c e o f a subma trix in a sin g le column. 4.2. Results For M subm atrices, let M ′ be the r equired number of com- putations, each co rrespon ding to a different subma tr ix, to ter- minate an iteratio n. W e define M − M ′ M as the toler ance r ate , which r eflects th e g radient accu racy at each iteration ( lower tolerance rate means high er accu r acy). In Fig . 1 , we co mpare the three schem es un der the th ree perfor mance metrics with re spect to the tolerance ra te. Since partial recovery is not p ossible with MDS-coded com puta- tion, its perfo rmance remain s the same with the tolerance lev el. Th e p erform ance o f the UC-MMC a nd CPGC schemes improve with the increasing tolera n ce level. This c o mes at the expense of a slight reduction in th e accur acy of the r e su ltant gradient computatio n . W e rem ark that, b eyond a certain tol- erance level UC-MM C scheme achieves a lower average pe r iteration completion time co mpared to MCC d ue to th e uti- lization of non-persistent st raggler s tha nks to the MMC ap- proach [5, 13]. Also, CPGC ou tperfor ms b oth UC-M M C and MCC than ks to coded inpu ts. I t also allo ws p a r tial grad ient computatio n, and provid es approximately 25% reduction in the average per iteration completion time comp ared to M CC and UC-MM C at a 5% tolerance rate. Communica tio n volume of the UC-MMC scheme for 0% tolerance rate is around 1 . 8 , which mean s th at th ere is 80% commun ication overhead. Similarly , the commu nication vol- ume of CPGC is around 1 . 5 , which means a 5 0% overhead . MCC has the minim u m commun ication v olume since the MDS c ode has zero decodin g overhead 1 . W e also o bserve that the com municatio n volume o f CPGC decreases with the tolerance level, an d it is clo se to that of MCC at a tolerance lev el o f around 10% . W e recall that the desig n go al of the CPGC sche me is to provide flexibility in seek ing a balanc e betwe e n the per iter- ation co m pletion time an d accu racy . T o this end, different it- eration termin ation strategies can b e introdu ced to red uce the overall conv ergence tim e . W e show in [ 18] that a faster over- all conv ergence can be ac h ieved with CPGC by increasing the toler a nce a t eac h iteration, as this w ould red u ce th e per- iteration comp letion time . Finally , on e c a n observe from Fig. (1b) an d (1c) tha t the MMC appro ach a ffects the commun i- cation loa d more d rastically compared to the commun ication volume. T his may intro duce additio n al delays depend ing o n the compu ting infrastru cture and th e c ommun ication pro tocol employed, e. g., dedica te d links from the workers to the master compare d to a shared commu nication n e twork . 1 Communicat ion volume of the MCC is slightly greate r than 1 sinc e K is not di visible by r , and zero padding is used before encoding. 5. REFERENCES [1] K. L ee, M. L am, R. Pedarsani, D. Papailiopoulos, and K. R amchan dran, “Speeding u p distributed mach ine learning using codes, ” IEEE T ransactions on Info rma- tion Theory , vol. 6 4, no. 3 , pp. 1 514– 1529 , March 201 8. [2] N. Ferdinand an d S. C. Drap er , “Hiera rchical cod ed computatio n, ” in IEE E ISI T , Ju n e 2018 . [3] R. K. Ma ity , A. S. Ra wat, and A. Mazumd ar , “Ro- bust gradien t descent via m oment enco ding with LDPC codes, ” SysML Conference , February 2018. [4] Songze Li, Seyed Mo h ammadr eza Mousavi Kalan, Qian Y u, Mahdi So ltanolkotabi, and Amir Salman A ves- timehr, “Polynomially coded regression: Optimal straggler mitigation via data encodin g, ” CoRR , vol. abs/1805 .0993 4, 201 8 . [5] E. Ozfatura, D. Gü ndüz, a n d S. Ulukus, “ Sp eeding up distributed gradient descent by utilizing non -persistent stragglers, ” 201 8, av ailab le at arXiv:1808 :0224 0 . [6] Sanghamitr a Dutta, Mohamm ad Fahim, Farzin Hadda d - pour, Haew on Jeong, V iveck R. Cadamb e, and Pulkit Grover , “On the o p timal recovery threshold of c o ded matrix multiplication, ” CoRR , vol. ab s/1801. 1 0292 , 2018. [7] Can Karakus, Y ifan Sun, Su has Digga vi, an d W o ta o Y in, “Straggler mitigation in distributed optim iz a tion throug h data e ncodin g , ” in Advanc es in Neural Infor- mation Pr ocessing Systems 30 , I. Guyon , U. V . Luxburg, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, Ed s., pp. 5434– 5442 . Curran Associates, Inc., 201 7. [8] A. Mallick, M. Chau d hari, and G. Joshi, “Rateless codes for n ear-perfect load balancin g in distributed matrix-vector multiplication, ” 2018 , a vailable at arXiv:1804.103 31. [9] H. Park, K. Lee, J. Sohn, C. Suh, and J. Moo n, “Hier - archical co ding for distributed co mputing , ” 20 1 8, avail- able at arXiv:1801.0 4686 . [10] R. T and on, Q. Lei, A. G. Dimak is, and N. Karampatzi- akis, “Gradient coding: A voiding stragglers in dis- tributed learning , ” in Pr oceeding s of the 34th Inter- nationa l Conference o n Ma chine Lea rning , Doin a Pre- cup and Y ee Whye T eh , Eds., I nternation al Convention Centre, Syd ney , Australia, 06–11 Au g 20 17, vol. 70 of Pr ocee d ings of Machin e Learning Researc h , p p . 3368– 3376, PMLR. [11] Min Y e and Emm a nual Abb e, “Communic a tio n- computatio n effi cient grad ient coding, ” CoRR , vol. abs/1802 .0347 5, 201 8 . [12] W ael Halbawi, Navid Azizan Ruhi, Faribo rz Saleh i, and Babak Hassibi, “Impr ovin g distributed grad i- ent descent using reed-solomo n co des, ” CoRR , vol. abs/1706 .0543 6, 2 017. [13] M. M. Amir i an d D. Gün düz, “Computation schedu lin g for distributed machin e learning with straggling work- ers, ” 2 018, av ailable at arXiv:1810.09 9 92. [14] S. Li, S. M. M. Kalan, A. S. A vestimehr, and M. Soltanolkotabi, “Near-optimal stragg ler mitiga- tion fo r distributed grad ient me thods, ” CoRR , vol. abs/1710 .0999 0, 2 017. [15] K. Lee, M. Lam, R. Pedarsani, D. Papailiopoulos, and K. Ramchan dran, “Speeding up distributed machine learning usin g codes, ” in IEEE IS I T , July 20 16. [16] S. Dutta, G . Joshi, S. Ghosh, P . Dube, an d P . Nag- purkar, “Slow an d stale gradients can win the race: Error-runtime tr a de-offs in distributed SGD, ” in 2 1st Internation al Confer ence o n Artificial Intelligence and Statistics ( A IST A TS ) , April 201 8 . [17] Dan Alistarh, Jerry Li, Ryo ta T omio ka, an d Mi- lan V ojnovic, “QSGD: rand o mized quantization for commun ication-o ptimal stoc h astic gradien t d escent, ” CoRR , vol. abs/1610 .0213 2, 201 6. [18] E. Ozfatura, S. Uluku s, and D. Gün düz, “Distributed gradient descent with coded partial grad ient computations, ” https://1drv .ms/f/s!Ag0 zbhMUMbtqsQIhJhBQ6pL0Qt U A , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment