Automated Vulnerability Detection in Source Code Using Deep Representation Learning
Increasing numbers of software vulnerabilities are discovered every year whether they are reported publicly or discovered internally in proprietary code. These vulnerabilities can pose serious risk of exploit and result in system compromise, information leaks, or denial of service. We leveraged the wealth of C and C++ open-source code available to develop a large-scale function-level vulnerability detection system using machine learning. To supplement existing labeled vulnerability datasets, we compiled a vast dataset of millions of open-source functions and labeled it with carefully-selected findings from three different static analyzers that indicate potential exploits. The labeled dataset is available at: https://osf.io/d45bw/. Using these datasets, we developed a fast and scalable vulnerability detection tool based on deep feature representation learning that directly interprets lexed source code. We evaluated our tool on code from both real software packages and the NIST SATE IV benchmark dataset. Our results demonstrate that deep feature representation learning on source code is a promising approach for automated software vulnerability detection.
💡 Research Summary
The paper presents a large‑scale, function‑level vulnerability detection system for C and C++ source code that leverages deep representation learning directly on lexed code. Recognizing the limitations of traditional static and dynamic analysis tools—namely their rule‑based nature and poor scalability—the authors construct a massive dataset of over 12 million functions drawn from three sources: the synthetic SATE IV Juliet test suite, Debian package repositories, and public GitHub projects. After aggressive duplicate removal using both lexical and compile‑level feature vectors (control‑flow graphs, opcode vectors, use‑def matrices), roughly 1.08 million unique functions remain for training and evaluation.
Because most open‑source functions lack ground‑truth vulnerability labels, the authors generate binary “vulnerable”/“not vulnerable” annotations by running three open‑source static analyzers (Clang, Cppcheck, Flawfinder). Security experts map each analyzer finding to CWE identifiers and filter out non‑security‑relevant warnings, resulting in 149 out of 390 finding types being treated as true vulnerabilities. Approximately 6.8 % of the curated functions receive a vulnerable label.
The machine‑learning pipeline consists of two stages. First, a custom lexer reduces C/C++ source to a sequence of only 156 tokens, normalizing identifiers, literals, and common type aliases while preserving all keywords, operators, and separators. Each token is embedded into a 13‑dimensional vector that is learned end‑to‑end during model training (random initialization proved superior to pre‑trained word2vec).
Second, the embedded token sequence is processed by either a convolutional neural network (CNN) or a recurrent neural network (RNN). The CNN uses 512 filters of size 9 × 13 (covering the full embedding dimension) followed by batch normalization, ReLU, and max‑pooling across the sequence length, yielding a fixed‑size feature vector. The RNN employs a two‑layer GRU with hidden size 256 (LSTM performed similarly), also followed by max‑pooling. The pooled representation is passed through two fully‑connected layers (64 and 16 units) with 50 % dropout before a softmax output.
Crucially, the learned feature vector is not used directly for classification; instead it serves as input to a random forest (RF) ensemble. This hybrid CNN‑RF (or RNN‑RF) architecture consistently outperforms the neural network alone, providing better resistance to over‑fitting and higher discriminative power. Training is performed on functions with token lengths between 10 and 500 (padded to 500), using batch size 128, Adam optimizer (learning rates 5 × 10⁻⁴ for CNN, 1 × 10⁻⁴ for RNN), and a weighted cross‑entropy loss to compensate for class imbalance.
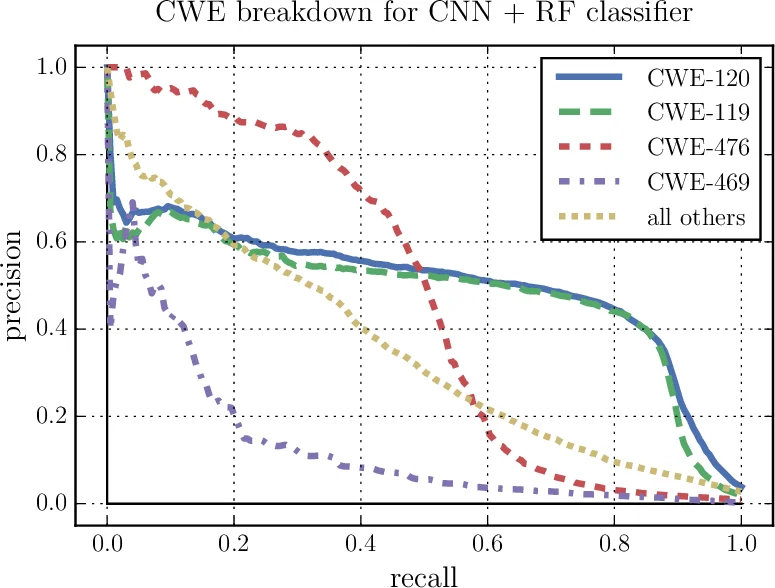
Evaluation is carried out on two fronts: (1) real‑world software packages (e.g., LibTIFF, OpenSSL) and (2) the NIST SATE IV benchmark. Metrics such as accuracy, recall, precision, and F1‑score demonstrate that the proposed system surpasses prior approaches based on support vector machines and bag‑of‑words representations. The CNN‑RF combination achieves the highest detection rates, while the RNN‑RF variant yields comparable performance, confirming that both local token patterns and longer‑range dependencies are valuable cues for vulnerability prediction.
The authors highlight several contributions: (i) a compact, language‑agnostic lexer that enables transfer learning across heterogeneous code bases; (ii) the release of a curated, labeled dataset of over one million C/C++ functions for the research community; (iii) empirical evidence that deep feature extraction combined with traditional ensemble classifiers can effectively detect a wide variety of CWE‑based vulnerabilities at scale.
Limitations are acknowledged. The reliance on static‑analysis‑derived labels means that any systematic bias or false positive/negative in the underlying tools propagates into the training data. Function‑level labeling also ignores inter‑procedural context, which may be critical for certain classes of bugs. Moreover, the study focuses exclusively on C/C++; extending the methodology to other languages would require adapting the lexer and possibly the token vocabulary.
Future work is proposed in three directions: (a) integrating dynamic analysis results and bug‑track data to create richer, multi‑modal labels; (b) employing graph neural networks to capture call‑graph and data‑flow relationships between functions; and (c) expanding the approach to additional programming languages and larger, continuously updated code repositories.
In summary, the paper demonstrates that deep representation learning on lexed source code, when coupled with a robust ensemble classifier, can achieve high‑accuracy, scalable vulnerability detection across diverse, real‑world code bases, offering a promising path toward more automated and proactive software security.
Comments & Academic Discussion
Loading comments...
Leave a Comment