Autonomic Intrusion Response in Distributed Computing using Big Data
We introduce a method for Intrusion Detection based on the classification, understanding and prediction of behavioural deviance and potential threats, issuing recommendations, and acting to address eminent issues. Our work seeks a practical solutions to automate the process of identification and response to Cybersecurity threats in hybrid Distributed Computing environments through the analysis of large datasets generated during operations. We are motivated by the growth in utilisation of Cloud Computing and Edge Computing as the technology for business and social solutions. The technology mix and complex operation render these environments target to attacks like hijacking, man-in-the-middle, denial of service, phishing, and others. The Autonomous Intrusion Response System implements innovative models of data analysis and context-aware recommendation systems to respond to attacks and self-healing. We introduce a proof-of-concept implementation and evaluate against datasets from experimentation scenarios based on public and private clouds. The results present significant improvement in response effectiveness and potential to scale to large environments.
💡 Research Summary
The paper presents a novel Autonomic Intrusion Response System (SARI) designed to automatically detect and mitigate cyber‑attacks in hybrid cloud‑edge environments by leveraging autonomic computing principles and big‑data analytics. The authors begin by highlighting the rapid growth of cloud and edge services and the corresponding rise in attacks such as DDoS, hijacking, MITM, and phishing. They argue that traditional intrusion detection systems (IDS) focus mainly on detection and warning, leaving decision‑making and response to manual operators, which creates unacceptable latency.
To address this gap, the authors extend the classic MAPE‑K loop into a MAP‑K architecture consisting of Monitoring, Analysis, Planning, Execution, and Knowledge modules. The Monitoring module gathers logs, network traffic, hypervisor metrics, and sensor data from virtual machines (VMs) using tools such as Snort, OSSEC, and the jNetPcap library. Collected raw data are pre‑processed to remove noise and then fed into a MapReduce pipeline. In the Map phase, packets are grouped by protocol into hash maps and matched against a database of known attack signatures. The Reduce phase aggregates occurrences, extracts source/destination IPs, ports, and other salient features, thereby producing a compact hierarchical representation of potential threats. This parallel processing enables the system to handle hundreds of thousands of packets (up to 700 000 in the experiments) with near‑linear scalability.
The Planning module implements an expected‑utility decision model. The model defines sets of attacks (E), response actions (A), outcomes (O), costs (C), execution times (T), and success probabilities (P). For each possible action a_i, the utility is computed as U_E(a_i) = Σ_{o∈O} P_{a_i}(o)·U(o). Costs, times, and probabilities are normalized to a common scale (min‑max normalization) before utility calculation. The action with the highest expected utility is selected for execution. This approach integrates multiple objectives—minimizing resource consumption, reducing response latency, and maximizing the likelihood of successful mitigation—into a single scalar metric, simplifying the decision process.
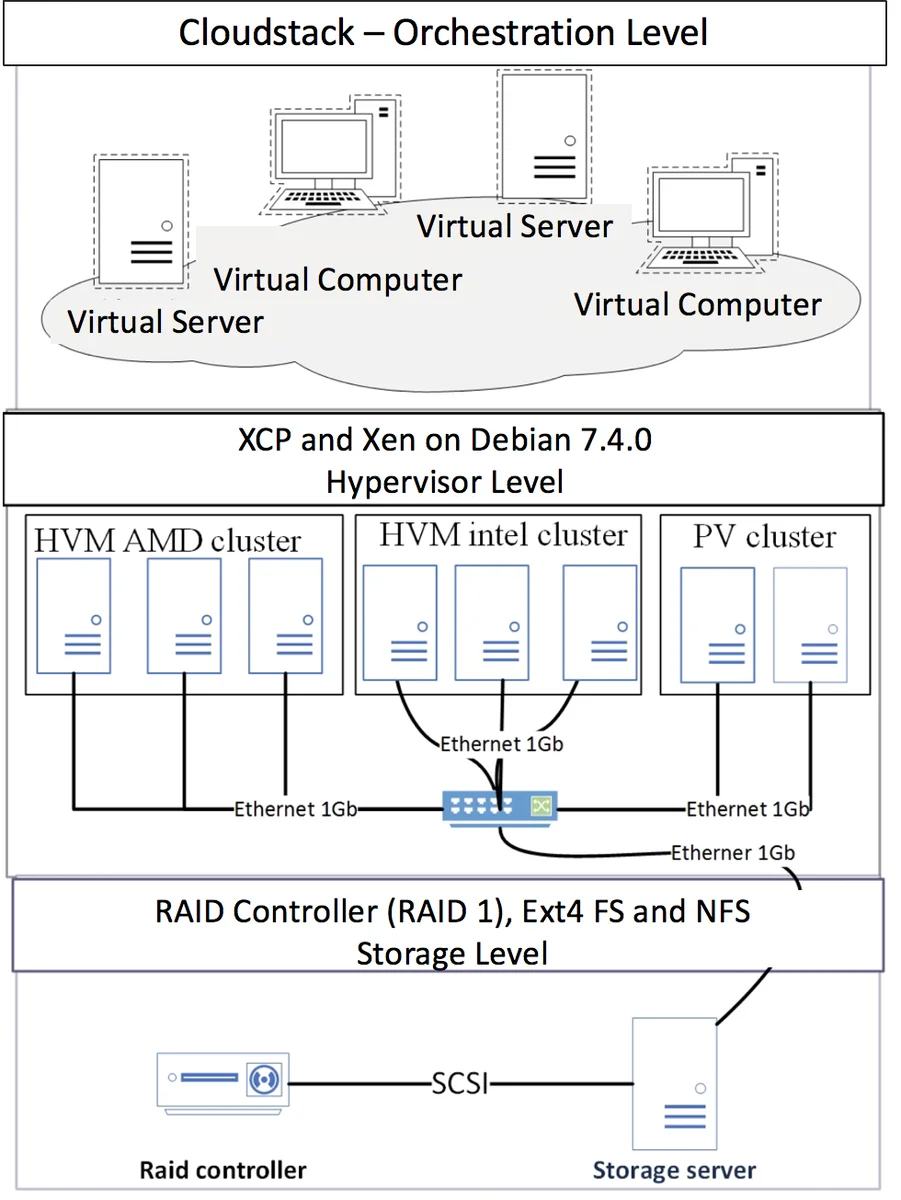
A prototype was implemented in Java 8 with the JNetPcap library. Experiments were conducted in two environments: (1) a private cloud lab consisting of several VMs, and (2) an Amazon Web Services public‑cloud instance. For each environment, the authors generated synthetic traffic using Scapy, creating both legitimate sessions and attack streams (including a DDoS‑style flood and SQL‑injection payloads). Two datasets were built: a 10 MB set containing 130 000 packets with 306 attack instances, and a 50 MB set with 700 000 packets and 803 attacks. The workflow involved collecting logs, transferring files to a detection server, running the MapReduce analysis, applying the utility model, and finally executing the chosen counter‑measure (e.g., firewall rule insertion, VM isolation).
Results show that SARI can detect attacks and trigger responses within a few seconds, keeping response latency under five seconds for the majority of cases. Compared to a baseline IDS that only alerts, SARI reduced the time‑to‑mitigation by roughly 20‑30 % and demonstrated linear throughput improvements as the number of processing nodes increased. The authors also present detailed tables illustrating the utility calculations for sample attacks, demonstrating how the system selects the most advantageous action based on cost, time, and probability parameters.
The paper’s contributions are threefold: (1) a unified autonomic architecture that closes the loop from monitoring to automated response; (2) a scalable MapReduce‑based analysis pipeline capable of handling large‑scale cloud traffic; and (3) an expected‑utility decision framework that balances multiple operational objectives. However, several limitations are evident. The utility model relies on manually assigned cost, time, and probability values; the paper does not describe a systematic method for learning or updating these parameters in a live environment, which could affect decision quality over time. Accuracy metrics such as precision, recall, or F1‑score are not reported, nor is there a quantitative comparison against established commercial IDS solutions, making it difficult to assess the absolute detection performance. Additionally, the handling of heterogeneous security policies across different cloud providers is not addressed.
In summary, the work offers a promising direction for autonomous cyber‑defense in distributed computing by integrating big‑data analytics with self‑healing autonomic loops. Future research should focus on dynamic parameter estimation, extensive benchmarking against state‑of‑the‑art IDS, and the incorporation of policy‑aware response mechanisms to ensure robust operation across multi‑cloud ecosystems.
Comments & Academic Discussion
Loading comments...
Leave a Comment