Sequence-to-sequence Models for Small-Footprint Keyword Spotting
In this paper, we propose a sequence-to-sequence model for keyword spotting (KWS). Compared with other end-to-end architectures for KWS, our model simplifies the pipelines of production-quality KWS system and satisfies the requirement of high accurac…
Authors: Haitong Zhang, Junbo Zhang, Yujun Wang
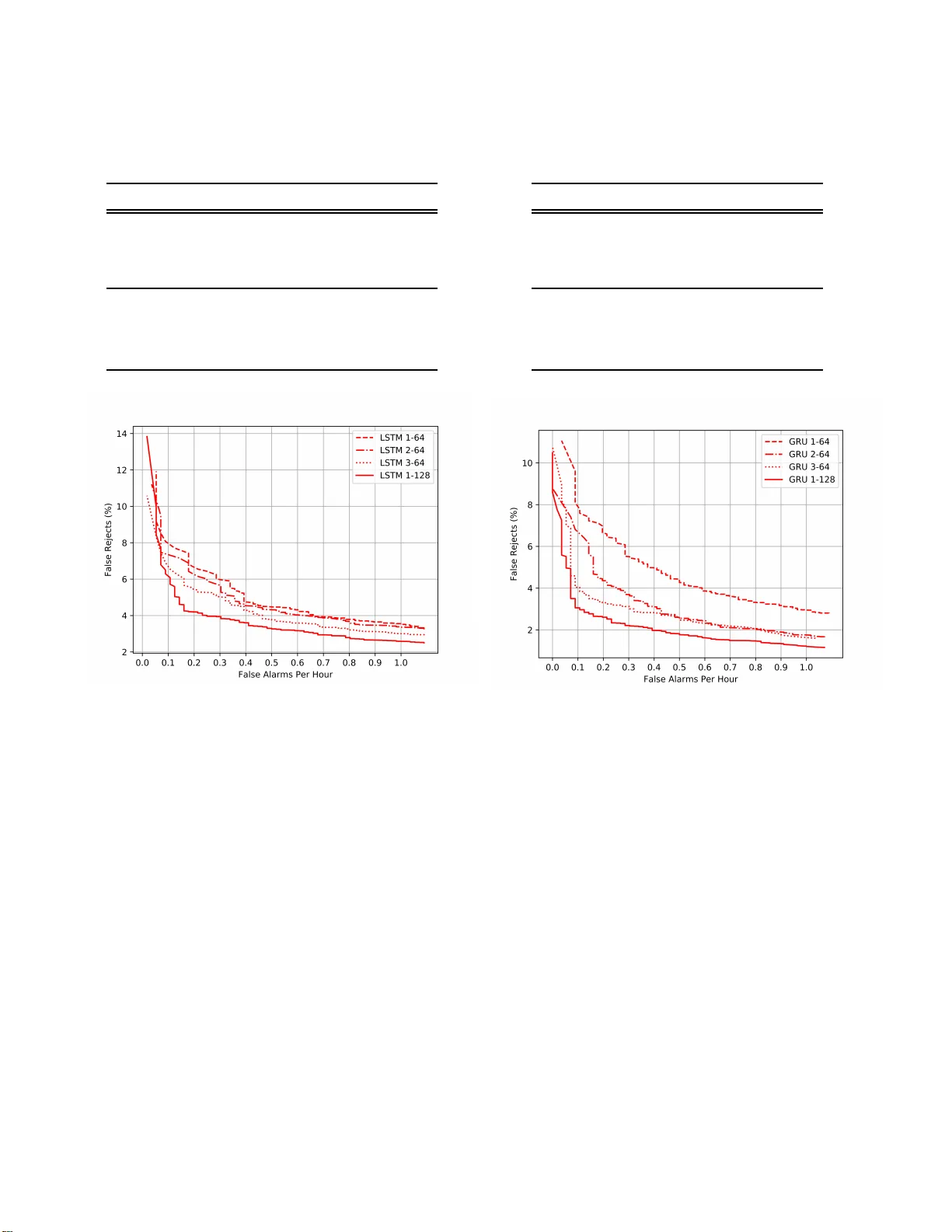
SEQUENCE-TO-SEQUENCE MODELS FOR SMALL-FOOTPRINT KEYWORD SPOTTING Haitong Zhang Junbo Zhang Y ujun Wa ng Xiaomi Inc., Beijing, Chin a { zhanghaitong, zhangjunbo, wangyuju n } @xiaomi.com ABSTRACT In this paper , we propose a sequence-to-sequence model for keyword spotting (KWS). Compared with other end-to-end architectures for KWS, o ur model simplifies the pipelines of production-quality KWS sys- tem and satisfies the requirement of high accura cy , low-latency , and small-footprint. W e also evaluate the performances of different encoder architectures, which include LSTM and GRU. Ex p e riments on the real-world wake-up data show that our approach out- performs the recently proposed attention-based end-to- end model. Specifically speaking, with ∼ 73K parame- ters, our sequence-to-sequence model achieves ∼ 3.05 % false rejection rate (FRR) at 0.1 false alarm (F A) per hour . Index T erms — sequence-to-sequence, keyword spot- ting, recurrent neura l networks 1. INTRODUCTION Keywords Sp otting (KWS), recently used as a wake-up trigger in the mobile dev ice s, has become p opula r . As a wake-up trigger , KWS should satisfy the requir ement of small memory and low CPU footprint, with high a c - curacy . There are e xtensive resear ches on KWS, a lthough most of them do not satisfy the requiremen ts men- tioned. For example, some systems [ 1 , 2 ] are us ed to process the audio data base offl ine. They gener- ate the rich lattices using large vocabulary continu- ous speech recognition system (L VCS R) and search for the keyword. Another commonly used technique for KWS is the keyword/filler Hidden M arkov Model (HMM) [ 3 – 5 ]. In these models, HMMs a re tra ined sep- arately for the keyword and non-keywor d segments. The V iterbi decoding is used to search for the keyword at runtime. Recently , [ 6 ] proposes a Deep KWS model, whose output is the probability of the sub-word of the key- word. Posterior probability handling is proposed to come up with a con fidence score for t he detection de- cision. Other neural networks, such as convolu tional neural network (CNN) [ 7 ], are used in the similar model architecture to improve the KWS per formance. T o f ur- ther simplify the pipelines of the KWS model, some end-to-end models pr oposed can predict the probabil- ity of the whole keyword directly [ 8 – 10 ]. In [ 9 ], the model uses the combination of the con- volution layer a nd recurrent layer to exploit both loca l temporal/spatial relation and long-term temporal de- pendencies. But the la te ncy introduced by the window shifting makes it unpractical. [ 10 ] solves the probl em by ad opting a n attention mechanism. However , there are two potential problems: (1) the sequence-to-one training is different from sequence-to-sequence decod- ing; (2) the pre-setting of the sliding window of 100 frame is arbitrary . T o handle the problems, we pro- pose a sequence-to-sequence KWS model. W ith the frame-wise alignments, we ca n tra in the model in the sequence-to-sequence fra mework, and simultaneously get rids of the sliding window . The a ttention-based model in [ 10 ] is used as the baseline model and described in Section 2. Our pro- posed sequence-to-sequence models a re detailed in Sec- tion 3 . The expe r iment data , setup, a nd results follow in section 4. Se c tion 5 closes with the conclusion. 2. THE BAS ELINE MODEL The baseline model, a s shown in Fig. 1 , mainly consists of two pa r ts: the encoder and the attention mechanism. The encoder lea r ns the higher repr esentation h = { h 1 , h 2 , ..., h T } from the input features x = { x 1 , x 2 , ..., x T } . T = 18 9 is a pplied when training. Only LSTM [ 11 ]and GRU [ 12 ] are used in our experiments for pair compari- son. A n attention mechanism [ 13 ] is applied to come up with a n attention weight vector a = { a 1 , a 2 , a 3 , ..., a T } . Then C is the fea ture representation for the whole se- quential input, which is computed as the weighted sum of h = { h 1 , h 2 , ..., h T } . Finally the probability of the key- word P ( y ) is predicted by a linear tra nsformation a nd softmax function. At runtime, the attention mechanism is applied to only 100 frames of input, b ut only one frame is fed into the network at each time-step since the others are com- puted already . x 1 x 2 x 3 ... x T Encoder h 3 h 2 h 1 ... h T Attention Me c ha nism a 2 a 2 a 1 ... a T C = ∑ T t = 1 a t h t p ( y ) Fig. 1 : The baseline model, which is proposed in [ 10 ]. x 1 x 2 x 3 ... x T Encoder h 3 h 2 h 1 ... h T y 3 y 2 y 1 ... y T Fig. 2 : The proposed sequence-to-sequence model. 3. THE P ROPOSED MODEL The proposed model is illustrated as Fig. 2 , which mainly includes the sequence-to-sequence tr a ining and the decode smoothing. 3.1. Se quence -to-seque nce T rai ning The proposed model ad opts the sequence-to-sequence training [ 14 , 1 5 ], where the inputs are the features, and the outputs are the one-hot labels which indica te whether the current frame (together with the previous frames) includes the keyword or not. An example of labeling the keyword is provided a s Fig. 3 . T ier one in Fig. 3 shows the phone-state align- ments generated by the TDNN- LSTM model, which is trained using ∼ 300 0 hours of speech. Then the align- ments are converted into the one-hot labe ls. As a result, the fra mes, which do not include the entire keyword, are labeled as 0. Otherwise, they are 1. The frames a re labeled as -1 if they contain three and a half character s. Since these frames are ambiguous, labeling them as - 1 and attaching z e ro weight to them ca n avoid the poten- tial impact of labe ling mistakes. Fig. 3 : The example la beling of the keyword, where the first tire are the alignments and the second the labe ls. 3.2. Dec oding When testing, the model takes the features for a single frame a s input, and directly outputs the probability of detecting the keyword y t . While it is fine to rely on the probability for a single frame, we a d opt a smooth- ing method to come up with a more reliable probability ˆ y , namely the average probability of probabilities of n consecutive frames: ˆ y t = ∑ t i = t − n + 1 y i n (1) 4. EXPERIMENT 4.1. Dat aset The keyword in our experiments is a four-Chinese- character term (” xiao-ai-tong-xue”) . The training data consists of ∼ 188. 9k examples of the keyword ( ∼ 99.8h) and ∼ 1007 .4k negative examples ( ∼ 1581 .8h). The de- velopment data includes ∼ 9.9K positive examples and ∼ 53.0 K negative examples. The testing data includes ∼ 28.8 k keyword exa mples ( ∼ 15 .2h) a nd ∼ 32.8k non- keyword ( ∼ 37 h). The da ta is all c ollected from MI AI Speaker 1 . 4.2. Ex periment setup 40-dimensional filterbank features are computed from each audio frame, with 25ms window size and 10ms frameshift. Then the filterbank fe a tures are converted into the per-channel energy normaliza tion (PCE N) [ 16 ] Mel-spectrograms. 1 https://www . m i.com/aispeaker/ T abl e 1 : Performance compar ison b e tween the baseline models and the proposed seq-to-seq models, False Re- ject Rate (FRR) is at 0. 1 fa lse alarm (F A) per hour . Model FRR(%) Pa rams(K) Baseline GRU 4.47 77.5 Baseline LS T M 11.86 103 Seq-to-seq GRU 3.05 73.3 Seq-to-seq LSTM 6.08 86.8 Fig. 4 : T he ROC of the baseline models and the pro - posed sequence-to-sequence model with the smoothing frame n =12 . The cross entropy is used as the loss function in the experiments. While training, all the weight matrice s are initialized with the normalized initialization, and the bias vectors are initialized to 0 [ 17 ]. Adam opti- mizer [ 18 ] is used to update the training para meters, with the initialize learning ra te of 1e-3 . The batch size is 64. Gradient norm clipping to 1 is applied, and L2 weight decay is 1e-5. 4.3. Base line vs Sequence- to-seque nce The experimental results are reported in the form of Re- ceiver Operating Cha racteristic (ROC) curve, which is created by plotting the f a lse reject rate (FRR) against false a larm ( F A) number per hour at various thresh olds. Lower curve represents the better result. Fig. 4 illustrates the performance of the baseline models and the proposed models. In this experiment, the encoder is the 1-128 RNN layer , which is found to be the best a rchitecture in [ 10 ]. It is clearly shown that our proposed model outperforms the baseline models Fig. 5 : The representative exa mple for the keyword with four tiers of annotation. The first one is the align- ment for the keyword;the second is the heatmap for the attention weights le a rned in Baseline GRU; the third and forth a re the heatmaps f or the output probabili- ties given by Baseline GRU a nd Se q-to-seq GRU, respec- tively . Larger values a re illustrated lighter . in both L S TM and GRU architectures. The Seq-to-seq GRU achieves ∼ 3% FFR at 0.1 F A per hour , with an ∼ 20% improvement over Ba seline GRU. The similar situation is observe d in the L STM architecture. The second tire in Fig. 5 shows that the attention weights concentrate a round the last chara c ter of the keyword. This d istribution indicates that the a ttention mechanism is strengthening the role of RNN in learning the long-term dependency , rather than focusing on the keyword ”with high resolution” [ 10 ]. The last heat-mat in Fig. 5 illustrates that sequence- to-sequence model is modeling the human auditory at- tention. As people wake up when the entire keyword is perceived, the probability gets large at present of the whole keyword. Although the second heat-mat in Fig. 5 shows a similar picture, the probabilities at the begin- ning a re unreasonably larger than those for the third character , and the wake-up is triggered before the last character is perceived. These impacts can be attributed to two p otential problems (Se ction 1 ). Instead of using human interve ntion to set the sliding window for the at- tention mechanism, our proposed models lear n the in- formation implicitly in the sequence-to-sequence archi- tecture. T abl e 2 : Performance comparison betwee n different en- coder a rchitectures, False Reject Rate (FRR) is at 0 .1 false alarm (F A) per hour . T ype Layer U nit FRR(%) Params(K) LSTM 1 64 7.71 27.0 LSTM 2 64 7.16 60.0 LSTM 3 64 6.55 93.1 LSTM 1 128 6.08 86.8 GRU 1 64 7 .79 24.5 GRU 2 64 6 .40 49.2 GRU 3 64 4 .04 74.0 GRU 2 128 3 .05 73.3 Fig. 6 : The ROC of the seq-to-seq model with L STM layer , with the smoothing f r ame n = 12. 4.4. Impa ct of encoder W e also explore the impact of the encoder on the model performance. As shown in Fig. 6 a nd Fig. 7 , and T able 2 , the models with more p a rameters tend to perform bet- ter than those with fewer para mete r s. The best models are LSTM 1- 128 a nd GRU 1-128 , respectively . As shown in Fig. 6 and Fig. 7 , the 1-128 models outperform all the models with only 6 4 units by a large margin, which in- dicates that getting the network wider results in a better performance than getting it deeper in our experiment. 4.5. Impa ct of smoothing frame The results of different settings of the smoothing fr a me n are illustrated in T able 3 . Compared with no smooth- ing, the application of smoothing frame n = 12 can gain an absolute ∼ 0.15% and ∼ 0. 06%, respectively in LS T M 1-128 a nd GRU 1-128 . Although the performance dif- T abl e 3 : Performance differences due to the smoothi ng frame, False Reject Rate (FRR) is at 0.1 fa lse alarm (F A) per hour . Model Smooth Frame FRR(%) LSTM 1-12 8 1 6.23 LSTM 1-12 8 2 6.23 LSTM 1-12 8 5 6.25 LSTM 1-12 8 12 6.08 GRU 1-12 8 1 3.11 GRU 1-12 8 2 3.11 GRU 1-12 8 5 3.12 GRU 1-12 8 12 3.05 Fig. 7 : The ROC of the seq-to-seq models with GRU layer , with the smoothing fra me n = 1 2. ference is minor , we insist that the smoothing strategy is reasonable a nd pra gmatic. It is reasonable b e cause in our sequence-to-sequence model, the detection of the keyword must be kept triggered for several fra mes once triggered. It is pragmatic since it is computation ally cheap to take a n avera ge operation. 5. CONCL USION T o conclude, the sequence-to-sequence model is more flexible than the attention-based one, beca use no sliding window is used and the training a nd decoding strate - gies are the same. As a result, the proposed sequence- to-sequence model outperforms the other in our real- world data, eve n with less model para meters. In ad- dition, a computationally-cheap probability smoothing method can improve the pe r formance’s robustness. 6. RE FERENCES [1] Da vid RH Miller , Michael Kleber , Chia- Lin Kao, Owen Kimball, Thomas Colthurst, Ste phen A Lowe, Richard M Schwartz, and Herbe r t Gish. Rapid and a ccurate spoken term detection. In Eighth Annual Conference o f the International Speech Communication Association , 2007. [2] J onathan Mamou, Bhuvana Ramabhadran, and Olivier Siohan. V ocabulary independent spoken term detection. In Proceedings of the 3 0th annual international ACM SIGIR conference on Research a nd development in information retrieval , pages 6 1 5–62 2. ACM, 20 07. [3] Richard C Ros e and Douglas B Paul. A hidden markov model b a sed keyword recognition system. In Acoustics, Sp eech, and Signal Processing, 1990. ICASSP-90., 1990 International Conference on , pages 129–1 32. IEE E, 199 0 . [4] J Robin Rohlicek, W illiam Russell, Salim Roukos, and Herber t Gish. Continuo us hidden markov modeling for speaker-independent word spotting. In Acoustics, Sp eech, and Signal Processing, 1989. ICASSP-89., 1989 International Conference on , pages 627–6 30. IEE E, 198 9 . [5] J G W ilpon, LG M iller , and P Modi. Improvements and applications for key wor d recogniti on using hidden markov modeling techniques. In Acous- tics, Sp eech, and Signal Process ing , 199 1. ICASSP- 91., 1991 Int ernational Conference on , pages 30 9 –312 . IEEE, 19 9 1. [6] Guoguo Chen, Ca rolina Para da, and Georg Heigold. Small-f ootprint keyword spotting using deep neural networks. In Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE Int ernational Confere nce on , pages 4087– 4091 . IEE E, 201 4. [7] T ara N Sainath and Carolina Par ada. Convo- lutional neura l networks f or small-footprint key- word spotting. In Sixteenth Annual Conference of the International Speech Communication Association , 2015. [8] Y e B ai, Jiangyan Y i, Hao Ni, Zhengq i W en, Bin Liu, Y a Li, and Jianhua T ao. End-to-end keywords spot- ting based on connectionist temporal classification for ma nda rin. In Chinese Spoken Languag e Process- ing (ISCSLP), 20 16 10 t h International Symposium on , pages 1– 5. IEEE, 2016 . [9] S ercan O A rik, M a rkus Kliegl, Rewon Child, J oel Hestness, Andrew Gibiansky , Chris Fougner , R yan Prenger , and Adam Coate s. Convo lutional recur- rent neural networks for small-footprint keyword spotting. arXiv preprint arXiv:1703. 05390 , 201 7. [10] Changhao Shan, Junbo Zhang, Y ujun W ang, a nd Lei Xie. Attention-based e nd- to-end models for small-footprint keywor d spotting. arXiv preprint arXiv:1803 .1091 6 , 20 18. [11] Sepp Hochreiter and J ¨ urgen Schmidhuber . Long short-term memory . Neural computa tion , 9(8) :1735 – 1780, 1997 . [12] Junyoung Chung, Ca glar Gulcehre, KyungHyun Cho, and Y oshua Bengio. Empirical evalua tion of gated recurrent neural networks on sequence mod- eling. arXiv preprint arXiv:1412 .3555 , 2 014. [13] F A Chowdhury , Quan W a ng, Ignacio Lopez Moreno, and Li W an. A ttention-based models for text-dependent speaker verifica tion. arXiv preprint arXiv:1710 .1047 0 , 20 17. [14] Rohit Prabhav a lkar , Kanishka Rao, T a ra N Sainath, Bo Li, L e if Johnson, and Navdeep Jaitly . A compar- ison of sequence-to-sequence models for speech recognition . In P roc. Interspeech , pa ges 93 9–943 , 2017. [15] Chung-Cheng Chiu, T ara N Sainath, Y onghui W u, Rohit Prabhava lkar , Patrick Nguyen, Zhifeng Chen, Anjuli Kannan, Ron J W eiss, Kanishka Rao, Ekaterina Gonina, et al. State-of-the-a rt speec h recognition with sequence-to-sequence models. In 2018 IEEE International Confe rence on Acoustics, Speech and Signal P rocessin g (ICASSP) , p a ges 4774 – 4778. IEEE, 20 18. [16] Y uxuan W ang, Pasca l Getreuer , Thad Hughes, Richard F L yon, and Rif A Saurous. T ra inab le frontend for robust a nd far-field keyword spotting. In 20 1 7 IEE E International Confer ence on Acoustics, Speech and Signal P rocessin g (ICASSP) , p a ges 5670 – 5674. IEEE, 20 17. [17] Xavier Glorot and Y oshua Bengio. Understanding the difficulty of training deep feedforward neural networks. In Proceedings of the th irteenth interna- tional confer ence on artificial intelligence and statistics , pages 249– 256, 2010. [18] Diederik P Kingma and Jimmy Ba . Ada m: A method f or stochastic optimization. arXiv p reprint arXiv:1412 .6980 , 201 4.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment