An improved hybrid CTC-Attention model for speech recognition
Recently, end-to-end speech recognition with a hybrid model consisting of the connectionist temporal classification(CTC) and the attention encoder-decoder achieved state-of-the-art results. In this paper, we propose a novel CTC decoder structure base…
Authors: Zhe Yuan, Zhuoran Lyu, Jiwei Li
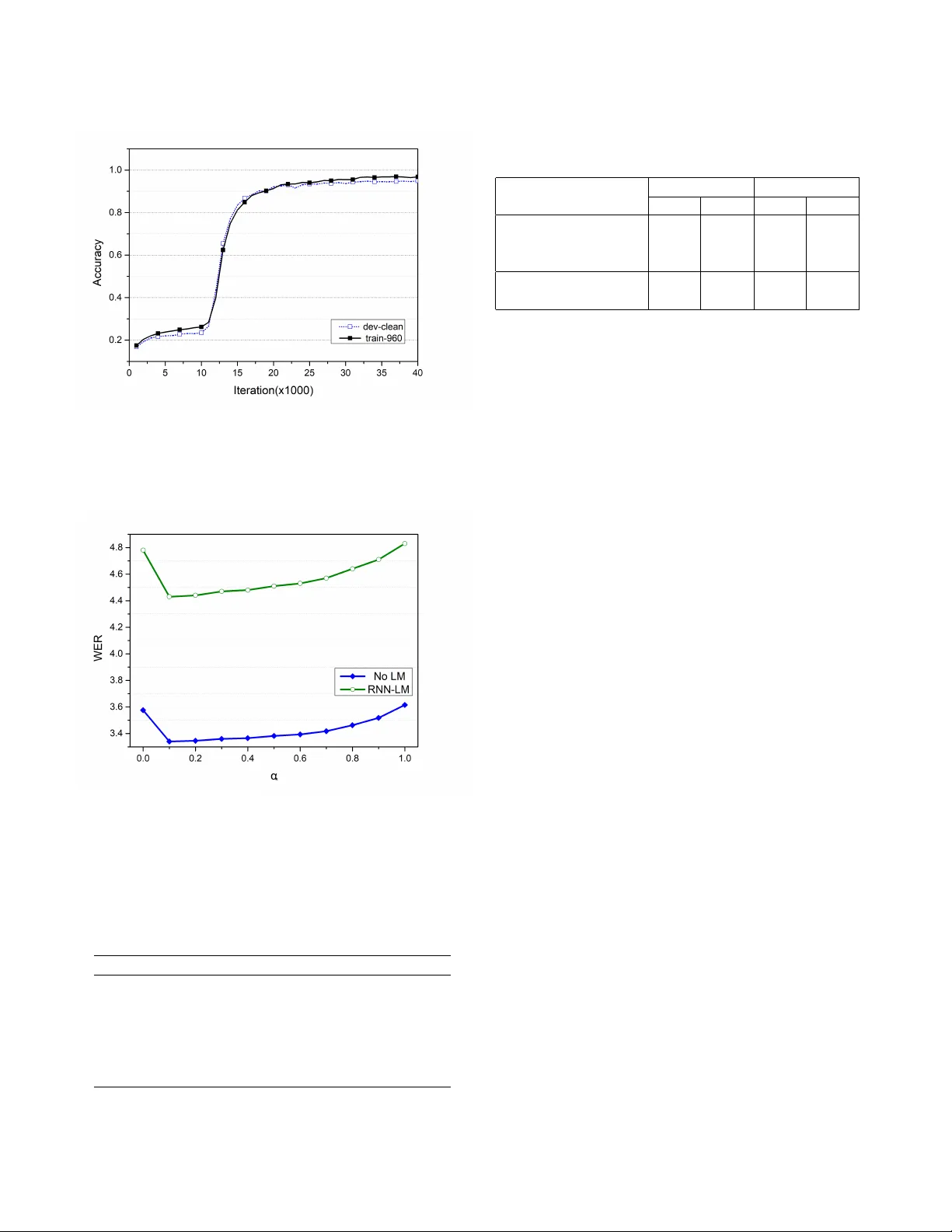
AN IMPR O VED HYBRID CTC-A TTENTION MODEL FOR SPEECH RECOGNITION Zhe Y uan, Zhuoran L yu, Jiwei Li and Xi Zhou ∗ Cloudwalk T echnology Inc, Shanghai, China ABSTRA CT Recently , end-to-end speech recognition with a hybrid model consisting of the connectionist temporal classification(CTC) and the attention encoder-decoder achie ved state-of-the-art results. In this paper , we propose a nov el CTC decoder struc- ture based on the experiments we conducted and explore the relation between decoding performance and the depth of encoder . W e also apply attention smoothing mechanism to acquire more context information for subword-based decod- ing. T aken together , these strategies allow us to achiev e a word error rate(WER) of 4.43% without LM and 3.34% with RNN-LM on the test-clean subset of the LibriSpeech corpora, which by far are the best reported WERs for end-to-end ASR systems on this dataset. Index T erms — Automatic speech recognition, attention, CTC, RNN-LM, seq2seq 1. INTR ODUCTION AND B A CKGROUND Automatic speech recognition (ASR), the technology that enables the recognition and translation of spoken language into text by computers, has been widely used in different applications. In the past few decades, ASR relied on com- plicated traditional techniques including Hidden Markov Models (HMMs) and Gaussian Mixture Models (GMMs) [1]. Besides, these traditional models also require hand-made pro- nunciation dictionaries and predefined alignments between audio and phoneme[2, 3]. Although these traditional models achiev e state-of-the-art accuracies on most audio corpora, it is quite a challenge to develop ASR models without enough acoustics kno wledge. Therefore, benefiting from rapid dev el- opment of deep learning, a few end-to-end ASR models were raised in recent years. Connectionist temporal classification(CTC) based mod- els and sequence-to-sequence(seq2seq) with attention models are two major approaches in end-to-end ASR systems. Both methods address the problem of variable-length input audios and output te xts. Deep Speech 2, which w as came up with by Baidu Silicon V alley AI Lab in 2016 [4], making full use of CTC and RNN, achiev ed a state-of-the-art recognition accu- racy . As for seq2seq model, Chorowski et al utilized seq2seq ∗ { yuanzhe, lvzhuoran, lijiwei, zhouxi } @cloudwalk.cn model with attention mechanism to perform speech recogni- tion [5]. Howe ver , the accuracy of the model is unsatisfactory since alignment estimation in the attention mechanism is eas- ily corrupted by noise, especially in real en vironment tasks. T o o vercome the abov e misalignment problem, a combi- nation of CTC and attention-based seq2seq model were pro- posed by W atanabe in 2017 [6]. The ke y to this joint CTC- attention model is training a shared encoder , with both CTC and attention decoder as objectiv e functions simultaneously . This novel approach improves the performance in both train- ing speed and recognition accuracy . This paper is partly inspired by the above method. Our main contributions in this paper include exploring different encoder and decoder network architecture and adopting sev- eral optimization methods such as attention smoothing and L2 regularization. W e demonstrate that our system outper- forms other published end-to-end ASR models in WER on LibriSpeech dataset. The paper is organized as follows. Section 2 briefly in- troduces the related works, mainly focusing on the hybrid CTC/Attention method. Section 3 details our model archi- tecture and section 4 presents our training methods and ex- perimental results. Finally , section 5 concludes this work. 2. RELA TED WORK In this section, we re vie w the hybrid CTC-attention architec- ture in Section 2.1 and unit selection methods in Section 2.2. 2.1. Hybrid CTC-attention ar chitecture The idea of this architecture is to use CTC as an auxiliary ob- jectiv e function to train the attention-based seq2seq network. Fig. 1 illustrates the architecture of the network, where the encoder has se veral conv olutional neural network(CNN) lay- ers followed by bidirectional long short-term memory (BiL- STM) layers, while the decoder includes a CTC module and an attention-based network. According to [7], using CTC along with attention decoder brings more robustness to the network since CTC helps acquiring appropriate alignments in noisy conditions. Moreov er , CTC also assists the network in training speed. CTC, which is introduced by [8], provides a method to train RNNs without an y prior alignments between inputs and outputs. Suppose the length of the input sequence is t , then the probability of a CTC path can be computed as follow: p ctc ( c | x ) = T Y t =1 q c t t (1) where q c t t denotes the the softmax probability of outputting label c t at frame t and c = ( c 1 , c 2 , ..., c t ) denotes the CTC path. Hence the likelihood of the label sequence can be com- puted as follow: p ctc ( y | x ) = X c ∈ θ ( y ) p ctc ( c | x ) (2) where θ ( y ) is the set of all possible CTC paths that can be mapped to y . Therefore, we have CTC loss to be: L ctc = − ln ( p ctc ( y | x )) . (3) As for decoder part, the possibility of label y s at each step depends on input feature h and pre vious labels y 1: s − 1 . The ov erall possibility of the entire sequence can be obtained as follow: p att ( y | x ) = Y s p att ( y s | h, y 1: s − 1 ) (4) where y s = F ull y C onnected ( d s , a s ) , (5) d s = LS T M ( d s − 1 , y s − 1 , a s ) , (6) a s = X t s,t h t . (7) d s denotes LS T M hidden states while a s is the conte xt vec- tor based on input features h and attention weight s,t in the abov e equation. The loss function of this part is defined as: L att = α L ctc + (1 − α ) L att (8) where α denotes the weight of dif ferent loss, α ∈ [0 , 1] . 2.2. Unit selection Methods based on large le xicon, such as phoneme-based ASR systems or w ord-based ASR systems, are not able to resolve out-of-vocab ulary (OO V) problems. Thus, starting from LAS [9], such seq2seq model raises ne w character-based method. By combining frame information in audio clips and the cor- responding characters together , the OO V problem is resolved to some extent. Since many characters in English words are silent and same characters in different sentences may pro- nounce differently (e.g. ”a” in ”apple” and ”approve”), de- coding procedure on character le vel relies hea vily on the sen- tence sequence relationship giv en by RNN rather than the acoustic information giv en by the audio clip frames, which results in the uncertainty of decoding procedure on character Fig. 1 . Architecture of the hybrid CTC-Attention model lev el. Considering all the issues mentioned abov e, subword- based structure can resolve OO V problems on one hand, and can learn the relationship between acoustic information and character information on the other hand. An effecti ve and f ast method for generating subwords is byte-pair encoding (BPE) [10]. Which is a compression algorithm that iterati vely re- places the most frequent pair of units (or bytes) with an un- used unit, and e ventually generates new units that are consis- tent with the number of iterations. 3. METHODOLOGY In this section, we detail our optimization and impro vements based on the previous hybrid CTC-attention architecture. W e show our improvements to encoder-decoder architecture and attention mechanism in section 3.1 and section 3.2. 3.1. Encoder -Decoder architectur e The authors in Espnet [11], stacked several BiLSTM layers abov e a fe w con volutional layers. The outputs of the last BiL- STM layer sev er as inputs to both CTC and attention-decoder as sho wn in Fig. 1. Our major improv ements conclude insert- ing a BiLSTM layer, which is solely occupied by the CTC branch, between the top shared encoder layer and FC layer connected to CTC. The entire hybrid architecture is sho wn in Fig. 2. According to our experiments in Section 4, setting α in (8) to a smaller value makes the network perform better . Ho w- ev er, when the weight α is low , a ne w problem is raised. Since lower α brings smaller gradient descent in back propagation in CTC loss part, the shared decoder focuses more on the at- Fig. 2 . Encoder and decoder architecture of our model tention module than the CTC module, which limits the perfor- mance of the CTC decoder . Considering this limitation, we introduce a solely BiLSTM layer linking to the CTC decoder , which can compensate the problem we mentioned abov e. 3.2. Attention smoothing Inspired by [5], we use a location-based attention mechanism in our implementation. Specifically , the location based atten- tion ener gies e s,t can be computed by the follo wing equation: e s,t = W T tanh ( W d d s − 1 + W h h t + W f f s,t + b ) (9) where s,t = exp ( e s,t ) / T X i =1 exp ( e s,i ) (10) and f s = F ∗ s − 1 . In our speech recognition system, subwords are chosen as the model units, which require more sequence conte xt in- formation than character-based units. Howe ver , the attention score distribution is usually v ery sharp when computed using abov e equations. Hence, we apply attention smoothing mech- anism instead, which can be computed by s,t = sig moid ( e s,t ) / T X i =1 sig moid ( e s,i ) . (11) The above method successfully smooths attention score distri- butions and then keep more conte xt information for subword- based decoding. 4. EXPERIMENTS 4.1. Experimental Setup W e train and test our implementation o ver LibriSpeech dataset [12]. Specificlly , we use train-clean-100, train-clean- 360, train-other-500 as our training set and de v-clean as our validation set. F or ev aluation, we report the word er- ror rates (WERs) on the subsets test-clean, test-other , dev- clean and dev-other . W e also adopt 3-fold speed perturba- tion(0.9x/1.0x/1.1x) for data augmentation. 80 dimensional Mel-filterbank features are generated using a sliding windo w of length 25 ms with 10ms stride, and the feature extrac- tion is performed by KALDI toolkit [13]. Subword units are extracted using all the transcripts of training data by BPE algorithm. The number of subword units is set to 5000. W e use a 4-layer CNN architecture follo wed by a 7-layer BiLSTM where each layer is a BiLSTM with 1024 cell units per direction as encoder . In the CNN part, input features are do wnsampled to 1/4 through two max-pooling layers. The decoder consists of two branches where one branch is a one-layer BiLSTM followed by a CTC decoder and the other branch is a 2-layer LSTM with 1024 cell units per layer . The AdaDelta algorithm [14] with initial hyper-parameter epsilon=1e-8 is used for optimization, and L2 regularization and gradient clipping are applied. W e measure the accuracy of the validation set e very 1000 iterations and apply a strategy that eps is decayed by 0.1 when the average validation accu- racy drops. All experiments are performed on 4 T esla P40 GPUs with batchsize = 40 on each GPU. Our language model is a two-layer LSTM with units=1536 trained on lar ge text data of 14500 public domain books, which is commonly used as training material for the Lib- riSpeech’ s LM. The SGD algorithm is used for optimization, with initial learning-rate 1.0 and lr-decay 0.9 per 2 epochs. For decoding, we use the beam search algorithm with the beam size 20. 4.2. Results Fig. 3 sho ws the accuracy curve during training process, from which we can see that the model conv erges after 35000 itera- tions. The perplexity of our trained RNN-LM is 50.4 on the training set, and 46.9 on the test-clean subset. W e conduct e x- periments with dif ferent number of layers in encoder and the addition of BiLSTM layer on the CTC branch. Results are shown in T able. 1, from which we have the follo wing com- ments. Both increasing the number of BiLSTM layers in en- coder and the addition of BiLSTM layer on the CTC branch lead to better WER. Moreo ver , WER can be reduced by about 25% using our trained RNN-LM. After that, we compare the different weight α between CTC loss and attention loss by step 0.1. The result is sho wn in Fig.4. When we use pure attention-based system or pure ctc- based system, it produces inferior performance. The curve also shows that decreasing α leads to better WER in hybrid system, which is consistent with the purpose of using CTC- decoder at the beginning: the CTC module is mainly used to assist the monotonic alignment and increase the con ver- gence speed of training, and the hybrid system decoding ef- Fig. 3 . Accuracy curv es with the number of iterations on both the train set and the validation set during training Fig. 4 . WER performance as a function of alpha on test-clean subset T able 1 . Comparison of test-clean-subset WERs under dif fer- ent structures Encoder Layers WER(no LM) WER(RNN-LM) 5 5.01 3.73 5+CTC-BiLSTM 4.73 3.59 6 4.82 3.64 6+CTC-BiLSTM 4.57 3.43 7 4.64 3.51 7+CTC-BiLSTM 4.43 3.34 T able 2 . Performance of different networks on the Lib- riSpeech dataset Model T est Dev clean other clean other Baidu DS2[4] + LM 5.15 12.73 - - Espnet[15] + LM 4.6 13.7 4.5 13.0 I-Attention[16] + LM 3.82 12.76 3.54 11.52 Ours + no LM 4.43 13.5 4.37 13.1 Ours + LM 3.34 10.54 3.15 9.98 fect mainly relies on the attention-decoder . As fig. 4 shows, we find that the best tuned α is 0.1. Finally , we compare our results with other reported state- of-the-art end-to-end systems on the LibriSpeech dataset in T able. 2. The results sho w that our system achiev es better WERs than other known end-to-end ASR models. 5. CONCLUSIONS In summary , we e xplore a variety of structural improvements and optimization methods on the hybrid CTC-attention-based ASR system. By applying the CTC-decoder BiLSTM, atten- tion smoothing and some other tricks, our system achiev es a word error rate(WER) of 4.43% without LM and 3.34% with RNN-LM on the test-clean subset of LibriSpeech corpus. Future w ork will concentrate on the optimization of both the decoder structure and the training method, such as fine- tuning the CTC-decoder-branch after training the shared en- coder . Another future work is to apply this technique to other languages like Mandarin, in which there are many polyphonic words that need to be solved in the decoding process. 6. REFERENCES [1] Lawrence R Rabiner and Biing-Hwang Juang, Funda- mentals of speech recognition , vol. 14, PTR Prentice Hall Englew ood Cliffs, 1993. [2] Lawrence R Rabiner, “ A tutorial on hidden markov models and selected applications in speech recognition, ” in Readings in speech r ecognition , pp. 267–296. Else- vier , 1990. [3] Geoffrey Hinton, Li Deng, Dong Y u, George E Dahl, Abdel-rahman Mohamed, Navdeep Jaitly , Andrew Se- nior , V incent V anhoucke, P atrick Nguyen, T ara N Sainath, et al., “Deep neural networks for acoustic mod- eling in speech recognition: The shared views of four re- search groups, ” IEEE Signal pr ocessing magazine , v ol. 29, no. 6, pp. 82–97, 2012. [4] Dario Amodei, Sundaram Ananthanarayanan, Rishita Anubhai, Jingliang Bai, Eric Battenberg, Carl Case, Jared Casper , Bryan Catanzaro, Qiang Cheng, Guoliang Chen, et al., “Deep speech 2: End-to-end speech recog- nition in english and mandarin, ” in International Con- fer ence on Mac hine Learning , 2016, pp. 173–182. [5] Jan K Choro wski, Dzmitry Bahdanau, Dmitriy Serdyuk, Kyungh yun Cho, and Y oshua Bengio, “ Attention-based models for speech recognition, ” in Advances in neural information pr ocessing systems , 2015, pp. 577–585. [6] Shinji W atanabe, T akaaki Hori, Suyoun Kim, John R Hershey , and T omoki Hayashi, “Hybrid ctc/attention architecture for end-to-end speech recognition, ” IEEE Journal of Selected T opics in Signal Pr ocessing , vol. 11, no. 8, pp. 1240–1253, 2017. [7] Suyoun Kim, T akaaki Hori, and Shinji W atanabe, “Joint ctc-attention based end-to-end speech recognition using multi-task learning, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer- ence on . IEEE, 2017, pp. 4835–4839. [8] Alex Gra ves and Faustino Gomez, “Connectionist temporal classification:labelling unsegmented sequence data with recurrent neural networks, ” in International Confer ence on Mac hine Learning , 2006, pp. 369–376. [9] William Chan, Na vdeep Jaitly , Quoc Le, and Oriol V inyals, “Listen, attend and spell: A neural network for large v ocabulary conv ersational speech recognition, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , 2016, pp. 4960–4964. [10] Rico Sennrich, Barry Haddow , and Alexandra Birch, “Neural machine translation of rare words with subword units, ” arXiv pr eprint arXiv:1508.07909 , 2015. [11] Shinji W atanabe, T akaaki Hori, Shigeki Karita, T omoki Hayashi, Jiro Nishitoba, Y uya Unno, Nelson En- rique Y alta Soplin, Jahn Heymann, Matthew W iesner , Nanxin Chen, et al., “Espnet: End-to-end speech processing toolkit, ” arXiv preprint , 2018. [12] V assil Panayoto v , Guoguo Chen, Daniel Povey , and San- jeev Khudanpur, “Librispeech: an asr corpus based on public domain audio books, ” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 5206–5210. [13] Daniel Pov ey , Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Han- nemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, et al., “The kaldi speech recognition toolkit, ” in IEEE 2011 workshop on automatic speech r ecognition and understanding . IEEE Signal Processing Society , 2011, number EPFL-CONF-192584. [14] Matthew D Zeiler , “ Adadelta: an adaptive learning rate method, ” arXiv pr eprint arXiv:1212.5701 , 2012. [15] T omoki Hayashi, Shinji W atanabe, Suyoun Kim, T akaaki Hori, and John R. Hershey , “Espnet: end-to-end speech processing toolkit, ” https://github.com/ espnet/espnet/pull/407/commits/ , 2018. [16] Albert Ze yer , Kazuki Irie, Ralf Schl ¨ uter , and Her - mann Ney , “Improv ed training of end-to-end atten- tion models for speech recognition, ” arXiv preprint arXiv:1805.03294 , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment