A Convergence indicator for Multi-Objective Optimisation Algorithms
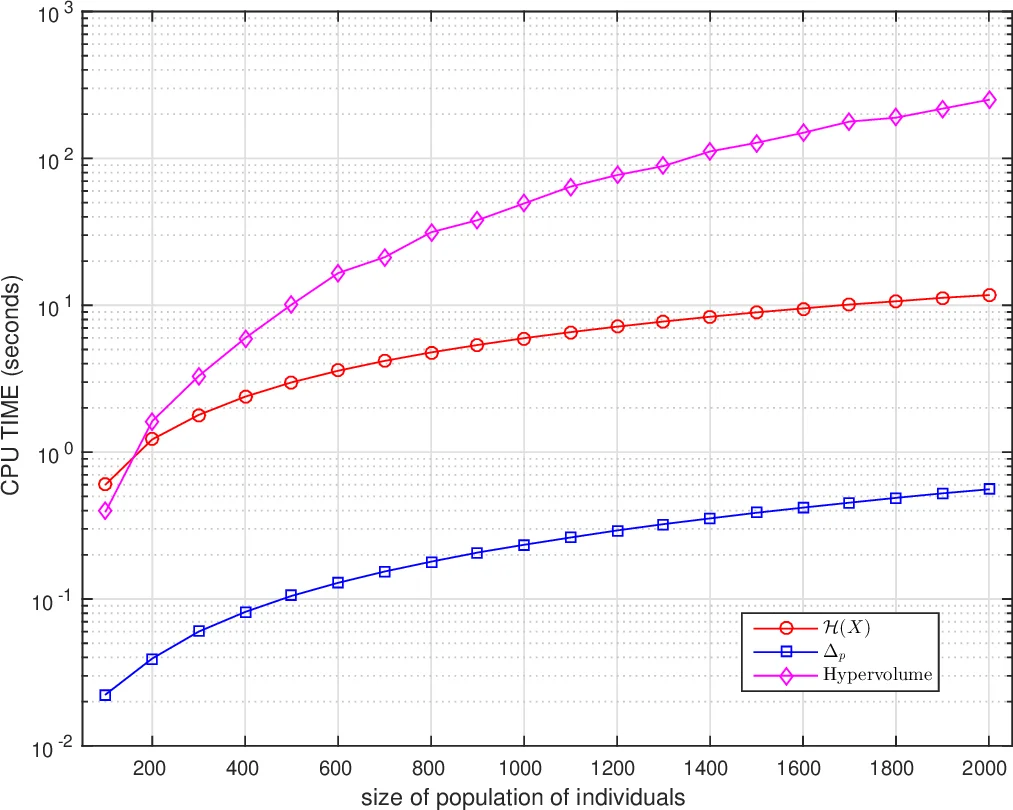
The algorithms of multi-objective optimisation had a relative growth in the last years. Thereby, it’s requires some way of comparing the results of these. In this sense, performance measures play a key role. In general, it’s considered some properties of these algorithms such as capacity, convergence, diversity or convergence-diversity. There are some known measures such as generational distance (GD), inverted generational distance (IGD), hypervolume (HV), Spread($\Delta$), Averaged Hausdorff distance ($\Delta_p$), R2-indicator, among others. In this paper, we focuses on proposing a new indicator to measure convergence based on the traditional formula for Shannon entropy. The main features about this measure are: 1) It does not require tho know the true Pareto set and 2) Medium computational cost when compared with Hypervolume.
💡 Research Summary
The paper introduces a new convergence indicator, denoted H, for evaluating the performance of multi‑objective evolutionary algorithms (MOEAs) without requiring prior knowledge of the true Pareto front. Traditional performance measures such as Generational Distance (GD), Inverted Generational Distance (IGD), the Δp metric, and Hypervolume (HV) either need a reference Pareto set or become computationally prohibitive as the number of objectives grows. To overcome these limitations, the authors build on the Karush‑Kuhn‑Tucker (KKT) optimality conditions.
For a multi‑objective problem min f(x) with m objectives, the KKT theorem guarantees the existence of non‑negative scalars α_i (∑α_i = 1) such that ∑α_i ∇f_i(x*) = 0 at any Pareto‑optimal point x*. The authors formulate a quadratic program (Equation 9) to compute the α‑vector for any candidate solution x. They then define a vector‑valued function q(x) = ∑α_i ∇f_i(x). At a true Pareto point, ‖q(x)‖ = 0; thus the norm of q serves as a proxy for distance to the Pareto set.
Given a set X = {x₁,…,x_k} produced by an MOEA, each solution is assigned a normalized scalar
q_i = min{1/e, ‖q(x_i)‖₂}.
These values lie in the interval
Comments & Academic Discussion
Loading comments...
Leave a Comment