Automatic acoustic identification of individual animals: Improving generalisation across species and recording conditions
Many animals emit vocal sounds which, independently from the sounds' function, embed some individually-distinctive signature. Thus the automatic recognition of individuals by sound is a potentially powerful tool for zoology and ecology research and p…
Authors: Dan Stowell, Tereza Petruskova, Martin v{S}alek
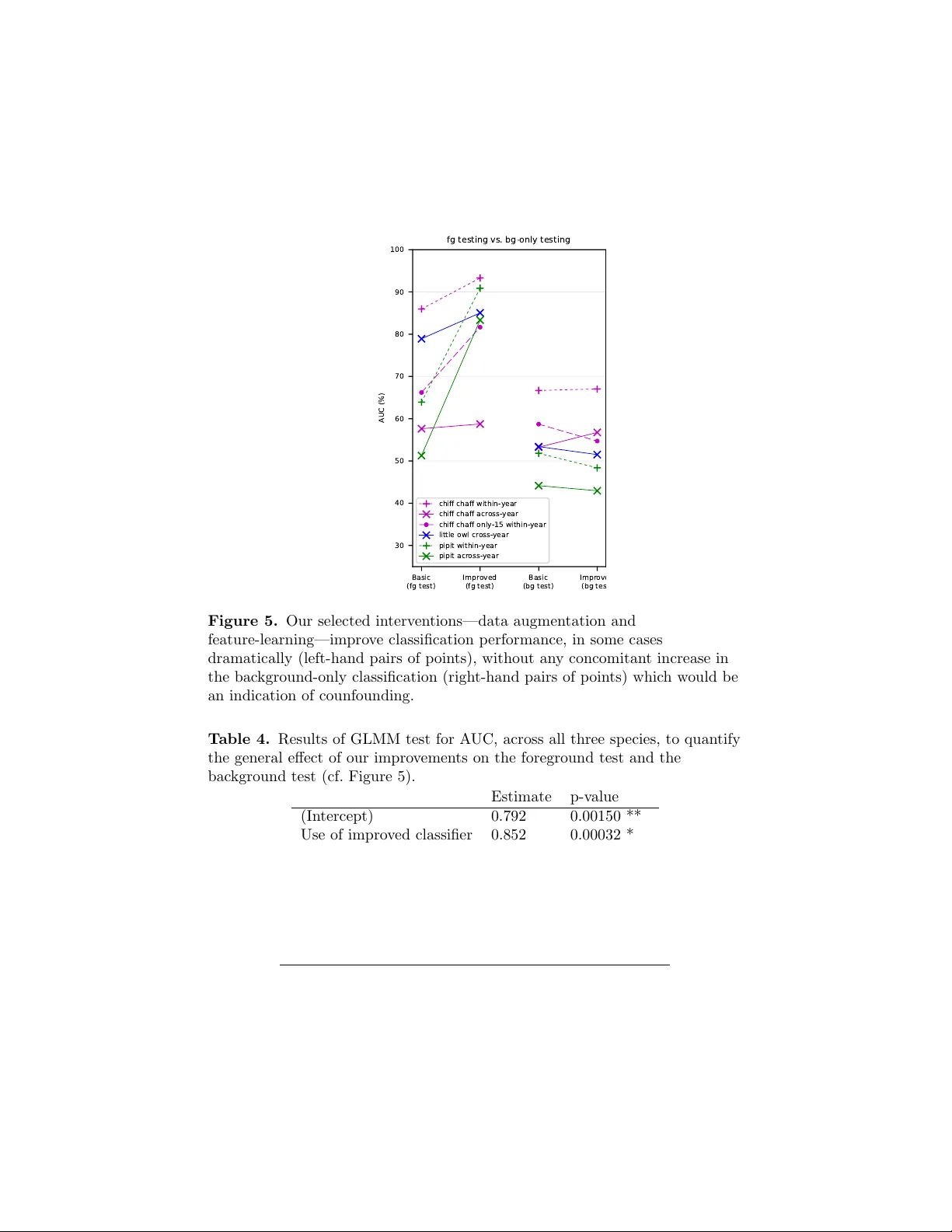
Automatic acoustic iden tification of individual animals: Impro ving generalisation across sp ecies and recording conditions Dan Sto well 1* , T ereza P etrusko v´ a 2 , Martin ˇ S´ alek 3,4 , P av el Linhart 5 1 Mac hine Listening Lab, Centre for Digital Music, Queen Mary Univ ersit y of London, UK 2 Departmen t of Ecology , F acult y of Science, Charles Univ ersit y , Prague, Czec h Republic 3 Institute of V ertebrate Biology , The Czec h Academ y of Sciences, Brno, Czec h Republic 4 F acult y of En vironmen tal Sciences, Czech Univ ersit y of Life Sciences Prague, Prague, Czec h Republic 5 Departmen t of Behavioural Ecology , F aculty of Biology , Adam Mic kiewicz Universit y , P ozna ´ n, P oland * dan.sto we ll@qmul.ac.uk Abstract Man y animals emit v ocal sounds which, independently from the sounds’ func- tion, em bed some individually-distinctiv e signature. Th us the automatic recog- nition of individuals by sound is a potentially p o werful to ol for zoology and ecology research and practical monitoring. Here we presen t a general automatic iden tification metho d, that can work across multiple animal sp ecies with v ari- ous levels of complexity in their communication systems. W e further introduce new analysis techniques based on dataset manipulations that can ev aluate the robustness and generalit y of a classifier. By using these techniques w e confirmed the presence of experimental confounds in situations resem bling those from past studies. W e introduce data manipulations that can reduce the impact of these confounds, compatible with any classifier. W e suggest that assessmen t of con- founds should b ecome a standard part of future studies to ensure they do not rep ort ov er-optimistic results. W e pro vide annotated recordings used for anal- yses along with this study and w e call for dataset sharing to be a common practice to enhance dev elopment of metho ds and comparisons of results. Keyw ords: animal communication; individual differences; individualit y; acoustic monitoring; song rep ertoire; vocalisation. 1 1 In tro duction Animal vocalisations exhibit consistent individually-distinctiv e patterns, often referred to as acoustic signatures. Individual differences in acoustic signals ha ve b een rep orted universally across vertebrate sp ecies (e.g., fish [1], amphib- ians [2], birds [3], mammals [4]). Individual differences may arise from v arious sources, for example: distinctiv e fundamental frequency and harmonic struc- ture of acoustic signal can result from individual vocal tract anatomy [4, 5]; distinct temporal or frequency mo dulation patterns of v o cal elemen ts ma y re- sult from inaccurate matching of innate or learned template or can occur de novo through improvisation [6]. Such individual signatures pro vide individual recognition cues for other consp ecific animals, and individual recognition based on acoustic signals is widespread among animals [7]. Long-lasting individual recognition spanning ov er one or more year has also b een often demonstrated [8, 9, 10]. External and internal factors suc h as, for example, sound degradation during transmission [11, 12], v ariable ambien t temp erature [13], inner motiv a- tion state [14, 15], acquisition of new sounds during life [16], may p oten tially increase v ariation of acoustic signals. Despite these potential complications, robust individual signatures w ere found in many taxa. Besides b eing studied for their crucial imp ortance in so cial interactions [17, 18, 19], individual signatures can become a v aluable tool for monitoring animals. Acoustic monitoring of individuals of v arious sp ecies based on v ocal cues could b ecome a p ow erful tool in conserv ation (review ed in [3, 20, 21]). Classical capture-mark metho ds of individual monitoring inv olv e physically dis- turbing the animals of in terest and might hav e a negative impact on health of studied animals or their b eha viour (e.g. [22, 23, 24, 25]). Also, concerns ha ve b een raised ab out p ossible biases in demographic and b eha vioural studies resulting from trap boldness or shyness of specific individuals [26]. Individual acoustic monitoring offers a great adv antage of b eing non-in v asiv e, and th us can b e deploy ed across sp ecies with few er concerns ab out effect on b eha viour [3]. It also may rev eal complementary or more detailed information about sp ecies b eha viour than classical metho ds [27, 28, 29, 30]. Despite many pilot studies [31, 28, 32, 33], automatic acoustic individual iden tification is still not routinely applied. It is usually restricted to a p articular researc h team or even to a single research pro ject, and even tually , might be abandoned altogether for a particular sp ecies. P art of the problem probably lies in the fact that methods of acoustic individual iden tification were closely tailored to a single sp ecies (softw are platform, acoustic features used, etc.). This is go od in order to obtain the b est p ossible results for a particular sp ecies but it also hinders general, widespread application b ecause metho ds need to b e dev elop ed from scratc h for eac h new sp ecies or ev en pro ject. Little attention has been paid to dev eloping general methods of automatic acoustic individual iden tification (henceforth “AAI I”) whic h could b e used across different sp ecies. A few studies in the past ha ve prop osed to develop a general, call-t yp e- indep enden t acoustic iden tification, w orking tow ards approaches that could b e used across different s pecies, ha ving simple as well as complex v o calisations 2 [34]. Despite promising results, most of the published pap ers included vocal- isations recorded within very limited p erio ds of time (a few hours in a da y) [34, 35, 36, 37]. Hence, these studies migh t ha v e failed to separate effects of target signal and potentially confounding effects of particular recording condi- tions and background sound, whic h hav e b een rep orted as notable problems in case of other machine learning tasks [38, 39]. Reducing such confounds directly , b y recording an animal in different backgrounds, may not b e ac hiev able in field conditions since animals t ypically liv e within limited home ranges and territo- ries. How ev er, acoustic bac kground can change during the breeding season due to v egetation c hanges or cycles in activity of different bird species. Also, song birds ma y change territories in subsequent years or even within a single season [27]. Some other studies of individual acoustic identification, on the other hand, pro vided evidence that machine learning acoustic iden tification can be robust in resp ect to p ossible long-term changes in the acoustic background but did not pro vide evidence of being generally usable for m ultiple sp ecies [30, 32]. There- fore, the c hallenge of reliable generalisation of mac hine learning approac h in acoustic individual iden tification across differen t conditions and differen t species has not y et b een satisfactorily demonstrated. 1.1 Previous metho ds for automatic classification of indi- viduals from their vocalisations W e briefly review studies represen ting metho ds for automatic classification of individuals. Note that in the presen t w ork, as in man y of the cited w orks, we set aside questions of automating the prior steps of recording fo cal birds and isolat- ing the recording segments in whic h they are active. It is common, in prepar- ing data sets, for recordists to collate recordings and manu ally trim them to the regions containing the “foreground” individual of interest (often with some bac kground noise), discarding the regions con taining only bac kground sound. In the present w ork w e will make use of b oth the foreground and bac kground clips, and our metho d will b e applicable whether such segmen tation is done manually or automatically . Matc hing a signal against a library of templates is a well-kno wn bioacoustic tec hnique, most commonly using sp ectrogram (sonogram) representations of the sound, via spectrogram cross-correlation [40]. F or iden tifying individuals, template matc hing will work in principle when the individuals’ v ocalisations are strongly stereot yp ed with stable individual differences—and in practice this can giv e go o d recognition results for some sp ecies [41]. Ho w ever, template matc hing is only applicable to a minorit y of sp ecies. It is strongly call-t yp e dependent and requires a library cov ering all of the vocalisation units that are to b e iden tified. It is unlikely to b e useful for sp ecies whic h ha v e a v ery large vocabulary , high v ariabilit y , or whose vocabulary changes substantially across seasons. An approach whic h can b e more independent of call type is that of Gaussian mixture mo dels (GMMs), previously used extensiv ely in human sp eec h tec hnol- ogy [42, 30]. These do not rely on a strongly fixed template but rather build a statistical mo del summarising the observ ations (e.g. the sp ectral shap es) that 3 are likely to be produced from eac h individual. A particularly useful aspect of the GMM paradigm is that it can straightforw ardly incorp orate the concept of a “universal background mo del” (UBM), whic h represen ts not “background” as ordinarily understo od but a universal po ol of the sounds that migh t b e pro- duced by individuals known and unknown. It therefore allows for the practical p ossibilit y that a given sound migh t come from unknown individuals that are not part of the target set [42]. This approac h has b een used in songbirds, al- though without testing across m ultiple seasons [42], and for orangutan including across-season ev aluation [30]. The GMM is a v ery basic statistical mo del, which do es not incorp orate an y notion of temp oral structure. It th us misses out on making use of a large amoun t of information in the signal. One wa y to improv e on this, again w ell-developed in human sp eec h technology , is to apply hidden Mark o v mo dels (HMMs). HMMs are statistical models of temporal structure and hav e more flexibilit y than template-matc hing. How ev er, in general they are lik ely to be call-t yp e-dep enden t since they do enco de the temp oral structure observ ed in eac h vocalisation. Adi et al. used HMMs for recognising individual songbirds, in this case ortolan bun tings, with a pragmatic approac h to call-type dependence [32]. They first applied HMMs to infer the call type active in a given recording (indep enden t of individual), and then giv en the call type, applied GMMs to infer whic h individual was active. Other computational approaches hav e been studied. Cheng et al. com - pared four classifier metho ds, aiming to dev elop call-type-indep endent recog- nition across three passerine sp ecies [37]. They found HMM and supp ort vector mac hines to b e fa v ourable among the metho ds they tested. How ever, the data used in this study w as relatively limited: it w as based on single recording ses- sions per individual, and th us could not test across-year p erformance; and the authors delib erately curated the data to select clean recordings with minimal noise, ackno wledging that this would not be representativ e of realistic record- ings. F ox et al. also fo cused on the challenge of call-indep endent identification, across three other passerine sp ecies [35, 34]. They used a neural net work classi- fier, and achiev ed go od performance for their sp ecies. How ev er, again the data for this study was based on a single session p er individual, whic h makes it un- clear how far the findings generalise across da ys and y ears, and also do es not fully test whether the results may b e affected by confounding factors suc h as recording conditions. Computational metho ds for v arious automatic recognition tasks ha ve re- cen tly b een dominated and dramatically impro ved by new trends in machine learning, including dee p learning. Within that broad field, the c hallenge of re- liable generalisation is far from solv ed, and is an activ e research topic. Within bioacoustics this has recen tly b een studied for detection of bird sounds [43]. In deep learning, it was disco vered that ev en the best-p erforming deep neural net works might b e surprisingly non-robust, and could b e forced to change their decisions by the addition of tiny imperceptible amounts of background noise to an image [38]. Note that deep learning systems also typically require very large amounts of 4 data to train, meaning they may currently b e infeasible for tasks suc h as acous- tic individual ID in whic h the n um b er of r ecordings per individual is necessar- ily limited. F or deep learning, “data augmen tation” has b een used to expand dataset sizes. Data augmentation refers to the practice of syn thetically creating additional data items by mo difying or recom bining existing items. In the audio domain, this could b e done for example b y adding noise, filtering, or mixing audio clips together [44]. Ho wev er, simple unprincipled data augmentation does not reduce issues such as undersampling (e.g. some v o calisations unrepresented in data set) or confounding factors. There thus remains a gap in applying mac hine learning for automatic indi- vidual iden tification as a general-purp ose to ol that can b e shown to b e reliable for m ultiple sp ecies and can generalise correctly across recording conditions. In the work rep orted in this paper, w e tested generalisation of machine learning across sp ecies and across recording conditions in con text of individual acoustic identification. W e used extensiv e data for three differen t bird species, including repeated recordings of the same individuals within and across tw o breeding seasons. As w ell as directly ev aluating across seasons, we also in tro- duced w ays to mo dify the ev aluation data to probe the generalisation prop erties of the classifier. W e then impro v ed on the baseline approac h b y dev eloping no v el metho ds which help to impro ve generalisation p erformance, again by mo dify- ing the data used. Although tested with selected sp ecies and classifiers, our approac h of mo difying the data rather than the classification algorithm was designed to b e compatible with a wide v ariet y of automatic identification work- flo ws. 2 Materials and metho ds 2.1 Data collection F or this study w e chose three bird sp ecies of v arying vocal complexit y (Figure 1), in order to explore ho w a single metho d might apply to the same task at differing levels of difficulty and v ariation. Little owl ( Athene no ctua ) represents a sp ecies with simple vocalisation (Figure 1a): territorial call is a single syllable whic h is individually unique and it is held to b e stable o v er time (Linhart and ˇ S´ alek unpubl. data) as w as sho wn in several other o wl species (e.g. [31, 45]). Then, w e selected t wo passerine sp ecies, which exhibit vocal learning: chiffc haff ( Phyl losc opus c ol lybita ) and tree pipit ( Anthus trivialis ). T ree pipit songs are also individually unique and stable ov er time [27]; but male on av erage uses 11 syllable types (6-18) which are rep eated in phrases that can b e v ariably com bined to create a song ([46], Figure 1b). Chiffchaff song, when visualised, ma y seem simpler than that of the pipit. Ho wev er, the syllable rep ertoire size migh t actually b e higher—9 to 24 types—and, con trary to the other sp ecies considered, c hiffchaff males may change syllable composition of their songs ov er time ([47], (Figure 1c). Selected sp ecies also differ in their ecology . While little o wls are seden tary and extremely faithful to their territories [48], tree pipits 5 f r eq ue nc y ( k Hz ) 1 2 3 4 5 6 5 10 5 10 5 10 ti m e ( s ) A B C Figure 1. Example sp ectrograms representing our three study sp ecies: (a) little o wl (b) tree pipit (c) chiffc haff. and chiffc haffs b elong to migratory sp ecies with high fidelity to their lo calities. Ann ual returning rates for b oth are 25% to 30% ([27], Linhart unpubl. data). F or eac h of these species, w e used targeted recordings of single v o cally activ e individuals. Distance to the recorded individual v aried across individuals and sp ecies according to their tolerance to wards p eople. W e tried to get the b est recording and minimise distance to each singing individual without disturbing its activities. Recordings w ere alwa ys done under fav orable weather conditions (no rain, no strong wind). In general, signal-to-noise ratio is v ery go o d in all of our recordings (not rigorously assessed), but there are also en vironmental sounds, sounds from other animals or consp ecifics in the recording background. All three sp ecies were recorded with follo wing equipmen t: Sennheiser ME67 microphone, Marantz PMD660 or 661 solid-state recorder (sampling frequency 44.1 kHz, 16 bit, PCM). Little owl (Linhart and ˇ S´ alek 2017) [49]: Little owls w ere recorded in t w o Cen tral Europ ean farmland areas: northern Bohemia, Czech Republic (50 ° 23N, 13 ° 40E), and eastern Hungary (47 ° 33N, 20 ° 54E). Recordings were made from sunset un til midnight b et ween Marc h and April of 2013—2014. T erritorial calls of each male were recorded for up to three minutes after a short playbac k pro vocation (1 min) inside their territories from up to 50 m distance from the individuals. Iden tity of the males could not b e explicitly chec k ed because only a small prop ortion of males were ringed. Therefore, we inferred identit y by the territory lo cation com bined with the call frequency modulation pattern which is distinctiv e p er individual. Chiffc haff (Pr ˚ uc ho v´ a et al 2017 [47], Pt´ aˇ cek et al 2016 [42]): Chif- fc haff males were recorded in a former military training area on the outer b ound- ary of ˇ Cesk ´ e Budˇ ejovice town, the Czech Republic (48 ° 59.5N, 14 ° 26.5E). Males w ere recorded for the purp oses of v arious studies from 2008 up to and including 2011. Recordings were done from 05:30 to 11:00 hours in the morning. Only sp on taneously singing males were recorded from within ab out 5–15 m distance. Iden tity of males was confirmed by colour rings. T ree Pipit (Petrusk o v´ a et al. 2015 [27]): T ree Pipit males w ere 6 T able 1. Details of the audio recording datasets used. Ev aluation scenario Num. of inds F oreground # audio files (train : ev al) F oreground total min utes (train : ev al) Background # audio files (train : ev al) Background total min utes (train : ev al) Chiffc haff within-year 13 5107 : 1131 451 : 99 5011 : 1100 453 : 92 Chiffc haff only-15 13 195 : 1131 18 : 99 195 : 1100 21 : 92 Chiffc haff across-year 10 324 : 201 32 : 20 304 : 197 31 : 24 Little o wl across-year 16 545 : 407 11 : 8 546 : 409 34 : 27 Pipit within-y ear 10 409 : 303 27 : 21 398 : 293 49 : 47 Pipit across-y ear 10 409 : 313 27 : 19 398 : 306 49 : 37 recorded at the locality Brdsk´ a vrc ho vina, the Czech Republic (49 ° 84N, 14 ° 10E) where the p opulation has b een contin uously studied since 2011. Sp ontaneously singing males were recorded throughout whole da y according to the natural singing activit y of T ree pipits from mid-April to mid-July . Males w ere identi- fied either based on colour ring observ ations or their song structure [27]. Audio files were divided in to regions during whic h the fo cal individual was v o cally activ e (“foreground”) and inactiv e (“background”). The total num b ers of individuals and sound files in eac h dataset are summarised in T able 1. 2.2 Structured data augmen tation “Data augmen tation” in mac hine learning refers to creating artificially large or diverse data sets by synthetically manipulating items in data sets to cre- ate new items—for example, b y adding noise or p erforming mild distortions. These artificially enriched data sets, used for training, often lead to impro v ed automatic classification results, helping to mitigate the effects of limited data a v ailabilit y [50, 51]. Data augmen tation is increasingly used in mac hine learning applied to audio. Audio-sp ecific manipulations used migh t include filtering or pitc h-shifting, or the mixing together of audio files (i.e. summing their signals together) [52, 53]. Some of the highest-p erforming automatic sp ecies recogni- tion systems rely in part on suc h data augmen tations to attain their strongest results [44]. In this work, we describ e tw o augmen tation methods used sp ecifically to ev aluate and to reduce the confounding effect of background sound. These structur e d data augmen tations are based on audio mixing but with the com- binations of files to mix selected based on foreground and bac kground identit y metadata. W e make use of the fact that when recording audio from fo cal indi- viduals in the wild, it is common to obtain recording clips in which the fo cal individual is vocalising (Figure 2a), as well as ‘bac kground’ recordings in which the v o cal individual is silen t (Figure 2b). The latter are commonly discarded. W e used them as follo ws: Adv ersarial data augmentation: T o ev aluate the exten t to whic h confound- ing from background information is an issue, w e created datasets in which 7 eac h foreground recording has b een mixed with one bac kground record- ing from some other individual (Figure 2c). In the b est case, this should mak e no difference, since the resulting sound clip is acoustically equiv a- len t to a recording of the foreground individual, but with a little extra irrelev an t background noise. In fact it could be considered a synthetic test of the case in whic h an individual is recorded ha ving trav elled out of their home range. In the w orst case, a classifier that has learnt un- desirable correlations betw een foreground and background will be misled b y the mo dification, either increasing the probability of classifying as the individual whose territory provided the extra background, or simply con- fusing the classifier and reducing its general ability to classify well. In our implemen tation, eac h foreground item w as used once, each mixed with a differen t background item. Thus the ev aluation set remains the same size as the unmo dified set. W e ev aluated the robustness of a classifier b y look- ing at an y c hanges in the ov erall correctness of classification, or in more detail via the exten t to whic h the classifier outputs are modified b y the adv ersarial augmentation. Stratified data augmen tation: W e can use a similar principle during the training pro cess, to create an enlarged and impro ved training data set. W e created training datasets in which eac h training item had b een mixed with an example of background sound from eac h other individual (Figure 2d). If there are K individuals this means that eac h item is con verted in to K syn thetic items, and the data set size increases by a factor of K . Stratifying the mixing in this w a y , rather than selecting bac kground samples purely at random, is intended to exp ose a classifier to training data with reduced correlation betw een foreground and bac kground, and th us reduce the chance that it uses confounding information in making decisions. T o implement the foreground and bac kground audio file mixing, we used the sox pro cessing to ol v14.4.1. 2.3 Using background items directly Alongside our data augmentation, we can also consider sim ple interv entions in whic h the background sound recordings are used alone without mo dification. One w a y of diagnosing confounding-factor issues in AAI I is to apply the classifier to b ackgr ound-only sound recordings. If there are no confounds in the trained classifier, trained on foreground sounds, then it should b e unable to identify the corresponding individual for any given bac kground-only sound (iden tifying ‘a’ or ‘b’ in Figure 2b). Automatic identification (“AAI I”) for bac kground-only sounds should yield results at around chance level. A second use of using the background-only recordings is to create an explicit ‘w astebasket’ class during training. As well as training the classifier to recognise individual lab els A, B, C, ..., we created an additional ‘w astebasket’ class whic h 8 (a) ‘F oreground’ recordings, which also con tain some signal conten t coming from the background habitat. The foreground and background might not v ary independently , esp ecially in the case of territorial animals. (b) ‘Background’ recordings, recorded when the fo cal animal is not vocalising → classify vs. → classify (c) In adversarial data augmen tation, w e mix eac h foreground recording with a bac kground recording from another individual, and measure the extent to whic h this alters the classifier’s decision. ... → train (d) In str atifie d data augmentation, each foreground recording is mixed with a background recording fr om e ach other class . This creates a to reduce the confounding correlation in the training data. Figure 2. Explanatory illustration of our data augmentation interv en tions. 9 should b e recognised as ‘none of the ab ov e’, or in this case, explicitly as ‘back- ground’. The explicit-background class may or ma y not b e used in the ev entual deplo yment of the system. Either w a y , its inclusion in the training pro cess could help to ensure that the classifier learns not to make mistaken asso ciations with the other classes. This approac h is related to the univ ersal bac kground model (UBM) used in op en-set recognition metho ds [42]. Note that the ‘bac kground’ class is likely to b e different in kind from the other classes, having very diverse sounds. In methods with an explicit UBM, the bac kground class can b e handled differen tly than the others [42]. Here, w e c hose to use metho ds that can work with any classifier, and so the background class w as simply treated analogously to the classes of in terest. 2.4 Automatic classification In this w ork, we started with a standard automatic classification pro cessing w orkflow (Figure 3a), and then exp erimented with inserting our prop osed im- pro vemen ts. W e modified the feature processing stage, but our main inno v ations in fact came during the data set preparation stage, using the foreground and/or bac kground data sets in v arious com binations to create differen t v arieties of training and testing data (Figure 3b). As in man y other w orks, the audio files—which in this case may b e the originals or their augmen ted versions—w ere not analysed in their raw w av eform format, but w ere conv erted to a mel sp ectrogram representation: ‘mel’ referring to a p erceptually-motiv ated compression of the frequency axis of a standard sp ectrogram. W e used audio files (44.1 kHz mono) conv erted into sp ectrograms using frames of length 1024 (23 ms), with Hamming windows, 50% frame ov er- lap, and 40 mel bands. W e applied median-filtering noise reduction to the sp ectrogram data. F ollo wing the findings of [54], w e also applied unsup ervise d fe atur e le arning to the mel sp ectrogram data as a prepro cessing step. This pro cedure scans through the training data in unsupervised fashion (i.e. neglecting the data lab els), finding a linear pro jection that provides an informative transformation of the data. W e ev aluated the audio feature data with and without this feature learning step, to ev aluate whether the data representation had an impact on the robustness and generalisability of automatic classification. In other words, as input to the classifier w e used either the mel sp ectrograms, or the learned representation obtained b y transforming the mel sp ectrogram data. The automatic classifier we used was one based on a random forest classifer that w as previously tested successfully for bird sp ecies classification, but had not b een tested for AAI I [54]. 2.5 Ev aluation As is standard in automatic classification ev aluation, we divided our datasets in to p ortions used for training the system, and p ortions used for ev aluating system p erformance. Items used in training were not used in ev aluation, and 10 T raining data (for egr ound) T esting data (for egr ound) Mel spectrogram T rain classi fi er Mel spectrogram Apply classi fi er Decision D ata set preparation F eature processing Classi fi cation (a) A standard workflo w for automatic audio classification. The upp er portion shows the training pro cedure, and the lo wer shows the application or ev aluation pro cedure. T raining data (for egr ound) T raining data (back gr ound) A ugment (mix audi o ) - str ati fi ed C oncat enat e data sets T esting data (for egr ound) T esting data (back gr ound) A ugment (mix audi o ) - adversarial Choose bg or fg Mel spectrogram F eature-learning (learn & transform ) T rain classi fi er Mel spectrogram F eature-learning (transform ) Apply classi fi er Decision D ata set preparation F eature processing Classi fi cation (b) W orkflo w for our automatic classification exp eriments. Dashed b oxes represent steps which we enable/disable as part of our experiment. The upp er p ortion shows the training procedure, and the low er shows the evaluation pro cedure. The tw o p ortions are very similar. How ev er, note that the purp ose and metho d of augmentation is different in each, as is the use of background-only audio: in the training phase the ‘concatenation’ blo c k creates an enlarged training set as the union of the background items and the foreground items, while in the ev aluation phase the ‘choose’ block select only one of the t wo, for the system to make predictions ab out. Figure 3. Classification workflo ws. 11 the allo cation of items to the training or ev aluation sets was done to create a partitioning through time: ev aluation data came from different days within the breeding season, or subsequent years, than the training data. This corresp onds to a plausible use-case in which a system is trained with existing recordings and then deploy ed; the partitioning also helps to reduce the probability of o ver- estimating p erformance. T o quan tify p erformance w e used receiver op erating curve (ROC) analysis, and as a summary statistic the area under the R OC curve (AUC). The AUC summarises classifier p erformance and has v arious desirable prop erties for ev al- uating classification [55]. W e ev aluated the classifiers follo wing the standard paradigm used in ma- c hine learning. Note that during ev aluation, w e optionally modified the ev al- uation data sets in tw o possible w ays, as already describ ed: adversarial data augmen tation, and bac kground-only classification. In all cases we used A UC as the primary ev aluation measure. How ev er, we also wished to prob e the effect of adv ersarial data augmentation in finer detail: even when the o verall decisions made by a classifier are not c hanged by modifying the input data, there may b e small c hanges in the full set of probabilities it outputs. A classifier that is robust to adv ersarial augmentation should b e one whose probabilities c hange little if at all. Hence for the adv ersarial augmentation test, we also to ok the probabilities output from the classifier and compared them against their equiv alent proba- bilities from the same classifier in the non-adv ersarial case. W e measured the difference b etw een these sets of probabilities simply by their ro ot-mean-square error (RMS error). 2.6 Phase one: testing with c hiffchaff F or our first phase of testing, we wished to compare the effectiv eness of the differen t proposed in terv entions, and their relative effectiveness on data tested within-y ear or across-y ear. W e chose to use the chiffc haff datasets for these tests, since the chiffc haff song has an appropriate level of complexit y to elucidate the differences betw een classifier performance, in particular the possible c hange of syllable comp osition across years. The chiffc haff dataset is also by far the largest. W e w an ted to explore the difference in estimated p erformance when ev alu- ating a system with recordings from the same y ear, separated by days from the training data, v ersus recordings from a subsequent year. In the latter case, the bac kground sounds may ha ve changed intrinsically , or the individual may hav e mo ved to a differen t territory; and of course the individual’s o wn v o calisation patterns ma y change across y ears. This latter effect ma y be an issue for AAI I with a sp ecies suc h as the chiffc haff, and also impose limits to the application of previous approac hes suc h as template-based matching. Hence we wan ted to test whether this more flexible machine learning approach could detect individ- ual signature in the chiffc haff ev en when applied to data from a different field season. W e thus ev aluated p erformance on ‘within-y ear’ data—recordings from the same season—and ‘across-y ear’ data—recordings from the subsequent year, or a later y ear. 12 Since the size of data av ailable is often a practical constrain t in AAI I, and since dataset size can hav e a strong influence on classifier p erformance, we fur- ther p erformed a v ersion of the ‘within-year’ test in whic h the training data had b een restricted to only 15 items per individual. The ev aluation data w as not restricted. T o ev aluate formally the effect of the different in terven tions, w e applied generalised linear mixed mo dels (GLMM) to our ev aluation statistics, using the glmmadmb pack age within R version 3.4.4 [56, 57]. Since AUC is a con tinuous v alue constrained to the range [0 , 1], w e used a b eta link function. Since RMSE is a non-negative error measure, w e used a gamma family with a logarithmic link function. F or each of these tw o ev aluation measures, we applied a GLMM, using the data from all three ev aluation scenarios (within-y ear, cross-year, only- 15). The ev aluation scenario w as included as a random effect. Since the same ev aluation-set items were reused in differing conditions, this w as a rep eated- measures mo del with resp ect to the individual song recordings. 2.7 Phase tw o: testing multiple sp ecies In the second phase of our inv estigations, w e ev aluated the selected approac h across the three sp ecies separately: chiffc haff, pipit and little owl. F or eac h of these w e compared the most basic v ersion of the classifier (using mel features, no augmentation, and no explicit-background) against the improv ed version that was selected from phase one of the inv estigation. F or each sp ecies sep- arately , and using within-y ear and across-year data according to av ailability , w e ev aluated the basic and the impro v ed classifier for the ov erall performance (A UC measured on foreground sounds). W e also ev aluated their p erformance on bac kground-only sounds, and on the adv ersarial data augmentation test, both of which chec ked the relationship b et w een impro v ed classification p erformance and impro vemen ts or degradations in the handling of confounding factors. F or b oth of these tests (background-only testing and adversarial augmenta- tion), we applied GLMM tests similar to those already stated. In these cases w e en tered separate factors for the testing condition and for whether the improv ed classifier w as in use, as w ell as an in teraction term b etw een the t w o factors. This therefore tested for an effect of whether our impro v ed classifier indeed mitigated the problems that the tests w ere designed to exp ose. 3 Results 3.1 Phase one: c hiffc haff AAI I p erformance ov er the 13 c hiffchaff individuals w as strong, abov e 85% A UC in all v arian ts of the within-year scenario (Figure 4). F or interpretation, note that this corresp onds to ov er 85% probabilit y that a random true-p ositive item is rank ed higher than a random true-negativ e item by the system [55]. This reduced to around 70–80% when the training set w as limited to 15 items per 13 Basic +exbg +aug +aug +exbg 30 40 50 60 70 80 90 100 AUC (%) mel spec features chiff chaff within-year chiff chaff across-year chiff chaff only-15 within-year Basic +exbg +aug +aug +exbg 30 40 50 60 70 80 90 100 AUC (%) learnt features chiff chaff within-year chiff chaff across-year chiff chaff only-15 within-year Figure 4. Performance of classifier (AUC) across the three chiffc haff ev aluation scenarios, and with v arious combinations of configuration: with/without augmen tation (‘aug’), learnt features, and explicit-background (‘exbg’) training. individual, and reduced even further to around 60% in the across-y ear ev aluation scenario. Recognising chiffc haff individuals across y ears remains a c hallenging task ev en under the studied interv en tions. The fo cus of our study is on discriminating b etw een individuals, but our “explicit-bac kground” configuration additionally made it possible for the same classifier to discriminate b etw een cases where a fo cal individual was singing, and cases where it was not. Across all three of the conditions mentioned ab o ve, foreground-vs-bac kground discrimination (ak a “detection” of any fo cal individ- ual) for chiffc haff was strong at ov er 95% AUC. Mel spectral features p erformed sligh tly b etter for this (range 96.6–98.6%) than learnt features (range 95.3– 96.7%). Given this, in the remainder of the results we fo cus on our main ques- tion of discriminating b et w een individuals. W e tested the GLMM residuals for the tw o ev aluation measures (A UC, RMSE) and found no evidence for ov erdisp ersion. W e also tested all possi- ble reduced mo dels with factors remov ed, comparing among mo dels using AIC. In both cases, the full mo del as w ell as a mo del with ‘exbg’ (explicit-bac kground training) remov ed ga ve the b est fit, with the full mo del less than 2 units ab ov e the exbg-reduced model and leading to no difference in significance estimates. W e therefore rep ort results from the full mo dels. F eature-learning and structured data augmentation w ere b oth found to sig- nifican tly impro v e classifier performance (T able 2) as well as robustness to ad- v ersarial data augmentation (T able 3). Explicit-bac kground training w as found to lead to mild impro vemen t but this was a long wa y b elo w significance. 14 T able 2. Results of GLMM test for AUC, across the three chiffc haff ev aluation scenarios. Estimate p-v alue (In tercept) 0.8199 0.041 * F eature-learning 0.3093 0.014 * Augmen tation 0.2509 0.048 * Explicit-bg class 0.0626 0.621 T able 3. Results of GLMM fit for RMSE in the adversarial data augmen tation test, across the three chiffc haff ev aluation scenarios. Estimate p-v alue (In tercept) 1.8543 1.9e-05 *** F eature-learning -0.5044 1.9e-08 *** Augmen tation -0.8734 < 2e-16 *** Explicit-bg class -0.0141 0.87 3.2 Phase tw o: m ultiple sp ecies Based on the results of our first study , we to ok forward an improv ed version of the classifier (using stratified data augmentation, and learn t features, but not explicit-bac kground training) to test across multiple sp ecies. Applying this classifier to the different sp ecies and conditions, we found that it led in most cases to a dramatic improv emen t in recognition p erformance of foreground recordings, and little change in the recognition of background recordings (Figure 5, T able 4). This suggests that the improv emen t is based on the individuals’ signal c haracteristics and not confounding factors. Our adversarial augmentation, intended as a diagnostic test to adversarially reduce classification p erformance, did not hav e strong ov erall effects on the headline performance indicated b y the AUC scores (Figure 6, T able 4). Half of the cases examined—the across-y ear cases—were not adversely impacted, in fact sho wing a v ery small increase in A UC score. The c hiffchaff within-year tests w ere the only to show a strong negativ e impact of adv ersarial augmen tation, and this negativ e impact was remov ed by our improv ed classification metho d. W e also conducted a more fine-grained analysis of the effect of augmen ta- tion, by measuring the amount of deviation induced in the probabilities output from the classifier. On this measure we observ ed a consistent effect, with our impro vemen ts reducing the RMS error by ratios of appro x 2–6, while the ov erall magnitude of the error differed across sp ecies (Figure 7). 15 Basic (fg test) Improved (bg test) Basic (bg test) Improved (fg test) 30 40 50 60 70 80 90 100 AUC (%) fg testing vs. bg-only testing chiff chaff within-year chiff chaff across-year chiff chaff only-15 within-year little owl cross-year pipit within-year pipit across-year Basic (fg test) Improved (bg test) Basic (bg test) Improved (fg test) 50 60 70 80 90 100 Accuracy (%) fg testing vs. bg-only testing chiff chaff within-year chiff chaff across-year chiff chaff only-15 within-year little owl cross-year pipit within-year pipit across-year Figure 5. Our selected interv en tions—data augmentation and feature-learning—impro ve classification p erformance, in some cases dramatically (left-hand pairs of p oin ts), without an y concomitant increase in the bac kground-only classification (right-hand pairs of p oin ts) which would b e an indication of counfounding. T able 4. Results of GLMM test for AUC, across all three sp ecies, to quantify the general effect of our impro vemen ts on the foreground test and the bac kground test (cf. Figure 5). Estimate p-v alue (In tercept) 0.792 0.00150 ** Use of impro ved classifier 0.852 0.00032 *** Bac kground-only testing -0.562 0.00624 ** In teraction term -0.896 0.00391 ** T able 5. Results of GLMM test for AUC, across all three sp ecies, to quantify the general effect of our impro vemen ts on the adversarial test (cf. Figure 6). Estimate p-v alue (In tercept) 0.873 0.0121 * Use of impro ved classifier 0.820 0.0027 ** Adv ersarial data augmentation -0.333 0.1713 In teraction term 0.225 0.5520 16 Basic (fg test) Improved (adversarial) Basic (adversarial) Improved (fg test) 30 40 50 60 70 80 90 100 AUC (%) adversarials chiff chaff within-year chiff chaff across-year chiff chaff only-15 within-year little owl cross-year pipit within-year pipit across-year Basic (fg test) Improved (adversarial) Basic (adversarial) Improved (fg test) 50 60 70 80 90 100 Accuracy (%) adversarials chiff chaff within-year chiff chaff across-year chiff chaff only-15 within-year little owl cross-year pipit within-year pipit across-year Figure 6. Adversarial augmentation has a v aried impact on classifier p erformance (left-hand pairs of p oin ts), in some cases giving a large decline. Our selected in terven tions v astly reduce the impact of this adversarial test, while also generally impro ving classification p erformance (righ t-hand pairs of p oin ts). 17 chiff chaff within- -year chiff chaff across- -year pipit within- -year pipit across- -year little owl across- -year 0 2 4 6 8 10 12 RMS error Basic Improved Figure 7. Measuring in detail how muc h effect the adversarial augmentation has on classifier decisions: RMS error of classifier output, in each case applying adv ersarial augmentation and then measuring the differences compared against the non-adv ersarial equiv alen t applied to the exact same data. In all five scenarios, our selected in terven tions lead to a large decrease in the RMS error. 18 4 Discussion W e demonstrate that a single approach to automatic acoustic iden tification of individuals (AAII) can be successfully used across different sp ecies with dif- feren t complexit y of v ocalisations. One exception to this is the hardest case, c hiffchaff tested across years, in whic h automatic classification performance re- mains modest. The c hiffc haff case (complex song, v ariable song conten t), in par- ticular, highlights the need for prop er assessment of identification p erformance. Without proper assessmen t w e cannot b e sure if promising results reflect the real p otential of prop osed identification metho d. W e do cument that our pro- p osed improv emen ts to the classifier training pro cess are able, in some cases, to impro ve the generalisation p erformance dramatically and, on the other hand, rev eal confounds causing ov er–optimistic results. W e ev aluated spheric al k-me ans feature-learning as previously used for sp ecies classification [54]. W e found that for individual identification it provides an im- pro vemen t o ver plain Mel spectral features, not just in accuracy (as previously rep orted) but also in resistance to confounding factors (ibid.). W e b elieve this is due to the feature-learning having b een tailored to reflect fine temp oral details of bird sound; if so, this lesson w ould carry across to related systems such as con- v olutional neural net works. Our machine-learning approach ma y be particularly useful for automatic iden tification of individuals in sp ecies with more complex songs, such as pipits (note huge increase in performance ov er mel features in Figure 5), or c hiffchaffs (on short-time scale though). Using silence-regions from fo cal individuals to create an “explicit-background” training category pro vided only a mild improv emen t in the b eha viour of the classifier, under v arious ev aluations. Also, w e found that the b est-p erforming configuration used for detecting the presence/absence of a fo cal individual was not the same as the best-p erforming configuration for discriminating betw een individuals. Hence, it seems generally preferable not to com bine the detection and AAI I tasks into one classifier. By con trast, using silence-regions to p erform dataset augmentation of the foreground sounds was found to giv e a strong b o ost to p erformance as well as resistance against confounding factors. Bac kground sounds are useful in training a system for AAII, through data augmen tation (rather than explicit-bac kground training). W e found that adversarial augmentation provided a useful tool to diagnose concerns ab out the robustness of an AAI I system. In the presen t w ork w e found that the classifier was robust against this augmentation (and thus w e can infer that it was largely not using bac kground confounds to mak e its decision), except for the case of chiffc haff with the simple mel features (Figure 6). This latter case exhorts us to b e cautious, and suggests that results from previous call-type indep enden t metho ds ma y ha ve been ov er-optimistic in assessing performance [34, 35, 36, 37, 42]. Our adv ersarial augmentation metho d can help to test for this ev en in the absense of across-year data. Bac kground-only testing was useful to confirm that when the performance of a classifier w as impro v ed, the confounding factors were not aggra v ated in 19 parallel, i.e. that the improv emen t was due to signal and not confound (Figure 5). Ho wev er, the p erformance on bac kground sound rec ordings w as not reduced to chance, but remained at some level reflecting the foreground-background correlations in eac h case, so results need to interpreted comparativ ely against the foreground improv emen t, rather than in isolation. This individual sp ecificit y of the bac kground may b e related to the time interv al b et ween recordings. This is clear from the across-year outcomes; within-year, we note that there w as one da y of temp oral separation for chiffc haffs (close to 70 p ercen t A UC on background- only sound), while an interv al of weeks for pipits (chance-lev el classification of bac kground). These effects surely dep end on c haracteristics of the habitat. Our improv ed classifier p erforms muc h more reliably than the standard one; ho wev er, the most crucial factor still seems to b e a targeted sp ecies. F or the little o wl w e found go o d p erformance, and least affected by mo difications in metho ds - consistent with the fact that it is the species with the simplest vocalisations. Little o wl represen ts a species w ell suited for template matc hing individual iden- tification metho ds whic h hav e been used in past for man y sp ecies with similar simple, fixed v o calisations (discriminant analysis, cross-correlation). F or these cases, it seems that our automatic identification metho d do es not bring adv an- tage regarding improv ed classification performance. How ev er, a general classifier suc h as ours, automatically adjusting a set of features for eac h sp ecies, would allo w common users to start individual identification righ t aw a y without the need to c ho ose an appropriate template-matc hing metho d (e.g. [49]). W e found that feature learning gav e the best improv emen t in case of pipits (Figure 5). Pipits ha ve more complex song, where simple tem plate matching cannot b e used to iden tify individuals. In pipits, each song ma y hav e differen t duration and may be comp osed of different subsets of syllable rep ertoire, and so an y a single song cannot b e used as template for template matc hing approach. This singing v ariation lik ely also preven ts go od iden tification performance based on Mel features in pipits. Nev ertheless, a singing pipit male will cycle through the whole syllable rep ertoire within a relatively low num b er of songs and indi- vidual males can be iden tified based on their unique syllable rep ertoires ([27]). W e think that our improv emen ts to the automatic identification migh t allow the system to pick up correct features asso ciated with stable rep ertoire of each male. This extends the use of the same automatic iden tification metho d to the large part of songbird sp ecies that organise songs into sev eral song t ypes and, at the same time, are so-called closed-ended learners ([58]). Our automatic identification, how ev er, cannot b e considered fully indepen- den t of song conten t in a sense defined earlier (e.g.[34, 36]). Suc h conten t- indep enden t identification metho d should be able to classify across-year record- ings of chiffc haffs in which syllable rep ertoires of males differ almost completely b et w een the tw o y ears [47]. Due to vulnerabilit y of Mel feature classification to confounds rep orted here and b ecause p erformance of conten t indep enden t iden tification has b een only tested on short-term recordings, we believe that the concept of fully conten t-independent individual identification needs to b e reliably demonstrated y et. Our approac h seems to b e definitely suitable for sp ecies with individual 20 v o calisation stable ov er time, even if that vocalisation is complex—a very wide range of species—in general outdo or conditions. F or such sp ecies it migh t b e successfully used for individual automatic acoustic monitoring, although this needs to be tested at larger scale: in v arious species and in large p opulations. In future work these approaches should also b e tested with ‘op en-set’ classifiers allo wing for the p ossibility that new unkno wn individuals might appear in data. This is well-dev eloped in the “universal background mo del” (UBM) developed in GMM-based sp eak er recognition [42], and future w ork in machine learning is needed to dev elop this for the case of more p o werful classifiers. Imp ortan t for further w ork in this topic is open sharing of data in stan- dard formats. Only this w ay can div erse datasets from individuals b e used to dev elop/ev aluate automatic recognition that w orks across many taxa and recording conditions. W e conclude by listing the recommendations that emerge from this w ork for users of automatic classifiers, in particular for acoustic recognition of individuals: 1. Record ‘bac kground’ segments, for eac h individual (class), and publish bac kground audio samples alongside the trimmed individual audio sam- ples. Standard data rep ositories can b e used for these purp oses (e.g. Dry ad, Zeno do). 2. Improv e robustness by: (a) suitable c hoice of input features; (b) structured data augmen tation, using background sound recordings. 3. Prob e your classifier for robustness by: (a) background-only recognition: higher-than-chance recognition strongly implies confound; (b) adv ersarial distraction with bac kground: a large change in classifier outputs implies confound; (c) across-y ear testing (if suc h data are a v ailable): a stronger test than within-y ear. 4. Be aw are of how sp ecies characteristics will affect recognition. The v o cal- isation characteristics of the sp ecies will influence the ease with whic h au- tomatic classifiers can identify individuals. Songbirds whose song changes within and b et ween seasons will alwa ys b e harder to identify reliably - as is also the case in man ual identification. 5. Best practice is to test manual features and learned features since the generalisation and p erformance characteristics are rather differen t. In the presen t work w e compare basic features against learned features; for a dif- feren t example see [12]. Man ual features are usually of lo wer accuracy , but with learned features more care must b e taken with resp ect to confounds and generalisation. 21 Ethics Our study primarily inv olv ed only non-inv asive recording of v o calising indi- viduals. In the case of ringed individuals (all c hiffchaffs and some tree pipits and little o wls), ringing w as done by experienced ringers (PL, M ˇ S, TP) who all held ringing licences at the time of study . T ree pipits and c hiffchaff males w ere recorded during spontaneous singing. Only for little o wls short pla yback recording (1 min) w as used to prov ok e calling. Pla yback pro v o cations as well as handling during ringing were k ept as short as p ossible and we are not aw are of an y consequences for sub jects’ breeding or welfare. Data Accessibilit y Our audio data and the associated metadata files are a v ailable online under the Creativ e Commons Attribution licence (CC BY 4.0) at http://doi.org/10. 5281/zenodo.1413495 Comp eting In terests W e ha ve no comp eting interests. Authors’ Con tributions DS and PL conceived and designed the study . PL, TP and M ˇ S recorded audio. PL pro cessed the audio recordings in to data sets. DS carried out the classi- fication exp erimen ts and performed data analysis. DS, PL and TP wrote the man uscript. All authors gav e final approv al for publication. F unding DS was supp orted by EPSRC Early Career researc h fellowship EP/L020505/1. PL w as supported by the National Science Cen tre, P oland, under P olonez fel- lo wship reg. no UMO-2015/19/P/NZ8/02507 funded b y the Europ ean Unions Horizon 2020 research and innov ation programme under the Marie Sko dowsk a- Curie grant agreement No 665778. TP was supp orted by the Czech Science F oundation (pro ject P505/11/P572).M ˇ S was supp orted b y the researc h aim of the Czec h Academy of Sciences (R VO 68081766). 22 References 1. Amorim MCP , V asconcelos RO. V ariability in the mating calls of the Lusitanian toadfish Halobatrach us didact ylus: cues for p otential individ- ual recognition. Journal of Fish Biology . 2008;73:1267–1283. 2. Bee MA, Gerhardt HC. Neigh b our-stranger discrimination b y territorial male bullfrogs (Rana catesb eiana): I. Acoustic basis. Animal Behaviour. 2001;62:1129–1140. 3. T erry AM, Peak e TM, McGregor PK. The role of vocal individualit y in conserv ation. F ron tiers in Zo ology . 2005;2(1):10. 4. T aylor AM, Reby D. The con tribution of source-filter theory to mam- mal vocal communication research. Journal of Zo ology . 2010;280(3):221– 236. Av ailable from: http://onlinelibrary.wiley.com/doi/10.1111/ j.1469- 7998.2009.00661.x/abstract . 5. Gamba M, F av aro L, Araldi A, Matteucci V, Giacoma C, F riard O. Mo d- eling individual vocal differences in group-living lemurs using v o cal tract morphology . CURRENT ZOOLOGY. 2017;63(4):467–475. 6. Janik V, Slater PB. V o cal Learning in Mammals. vol. V olume 26. Academic Press; 1997. p. 59–99. Av ailable from: http://www. sciencedirect.com/science/article/pii/S0065345408603770 . 7. Wiley RH. Sp ecificit y and multiplicit y in the recognition of individuals: implications for the evolution of so cial b eha viour. Biological Reviews. 2013;88(1):179–195. WOS:000317066700011. 8. Bo ec kle M, Bugny ar T. Long-T erm Memory for Affiliates in Rav ens. Curren t Biology . 2012;22(9):801–806. Av ailable from: http://www. sciencedirect.com/science/article/pii/S0960982212003107 . 9. Insley SJ. Long-term vocal recognition in the northern fur seal : Article : Nature. Nature. 2000;406(6794):404–405. Av ailable from: http://www. nature.com/nature/journal/v406/n6794/full/406404a0.html . 10. Briefer EF, de la T orre MP , McElligott AG. Mother goats do not forget their kids ' calls. Pro ceedings of the Roy al So ciet y B: Biological Sciences. 2012 jun;279(1743):3749–3755. 11. Slabb ek o orn H. Singing in the wild: the ecology of birdsong. In: Marler P , Slabb ek o orn H, editors. Nature’s music: the science of birdsong. Elsevier Academic Press; 2004. p. 178–205. 12. Mouterde SC, Elie JE, Theunissen FE, Mathev on N. Learning to cope with degraded sounds: F emale zebra finches can impro v e their exp ertise at discriminating b et ween male v oices at long distance. The Journal of Exp erimen tal Biology . 2014;p. jeb–104463. 23 13. Gambale PG, Signorelli L, Bastos RP . Individual v ariation in the adv ertisement calls of a Neotropical treefrog (Scinax constric- tus). Amphibia-Reptilia. 2014;35(3):271–281. Av ailable from: http://booksandjournals.brillonline.com/content/journals/ 10.1163/15685381- 00002949 . 14. Collins SA. V o cal fighting and flirting: the functions of birdsong. In: Mar- ler PR, Slabbekoorn H, editors. Nature’s m usic: the science of birdsong. Elsevier Academic Press; 2004. p. 39–79. 15. Linhart P , Ja ˇ sk a P , Petrusk o v´ a T, P etrusek A, F uchs R. Being an- gry , singing fast? Signalling of aggressive motiv ation by syllable rate in a songbird with slow song. Behavioural Pro cesses. 2013;100:139–145. Av ailable from: http://www.sciencedirect.com/science/article/ pii/S0376635713001927 . 16. Kro odsma DE. The div ersity and plasticit y of bird song. In: Marler PR, Slabb ek o orn H, editors. Nature’s music: the science of birdsong. Elsevier Academic Press; 2004. p. 108–131. 17. Thom MDF, Dytham C. F emale Cho osiness Leads to the Evolution of Individually Distinctive Males. Evolution. 2012;66(12):3736–3742. W OS:000312218200008. 18. Bradbury JW, V ehrencamp SL. Principles of animal communication. 1st ed. Sinauer Asso ciates; 1998. 19. Crowley PH, Prov enc her L, Sloane S, Dugatkin LA, Spohn B, Rogers L, et al. Ev olving co op eration: the role of individual recognition. Biosys- tems. 1996;37(1):49–66. Av ailable from: http://www.sciencedirect. com/science/article/pii/0303264795015469 . 20. Mennill DJ. Individual distinctiv eness in avian v o calizations and the spatial monitoring of b eha viour. Ibis. 2011;153(2):235–238. Av ailable from: http://onlinelibrary.wiley.com/doi/10.1111/j.1474- 919X. 2011.01119.x/abstract . 21. Blumstein DT, Mennill DJ, Clemins P , Giro d L, Y ao K, P atricelli G, et al. Acoustic monitoring in terrestrial environmen ts using micro- phone arrays: applications, tec hnological considerations and prosp ec- tus. Journal of Applied Ecology . 2011;48(3):758–767. Av ailable from: http://onlinelibrary.wiley.com/doi/10.1111/j.1365- 2664. 2011.01993.x/abstract . 22. Johnsen A, Lifjeld J, Rohde P A. Coloured leg bands affect male mate- guarding b eha viour in the bluethroat. Animal Beha viour. 1997;54(1):121– 130. 24 23. Gerv ais JA, Catlin DH, Chelgren ND, Rosen b erg DK. Radiotransmit- ter moun t t yp e affects burrowing o wl surviv al. The Journal of wildlife managemen t. 2006;70(3):872–876. 24. Linhart P , F uc hs R, P ol´ ako v´ a S, Slabb ekoorn H. Once bitten twice shy: long-term b ehavioural c hanges caused by trapping exp erience in willo w w arblers Ph ylloscopus tro chilus. Journal of a vian biology . 2012;43(2):186– 192. 25. Rivera-Gutierrez HF, Pinxten R, Eens M. Songbirds nev er for- get: long-lasting b eha vioural change triggered by a single play- bac k ev ent. Beha viour. 2015;152(9):1277–1290. Av ailable from: http://booksandjournals.brillonline.com/content/journals/10. 1163/1568539x- 00003278 . 26. Camacho C, Canal D, Potti J. Lifelong effects of trapping exp eri- ence lead to age-biased sampling: lessons from a wild bird p opula- tion. Animal Behaviour. 2017;130:133–139. Av ailable from: http:// www.sciencedirect.com/science/article/pii/S0003347217301938 . 27. Petrusk o v´ a T, Pi ˇ svejco v´ a I, Kin ˇ stov´ a A, Brinke T, P etrusek A. Rep ertoire-based individual acoustic monitoring of a migratory passer- ine bird with complex song as an efficient tool for trac king territorial dynamics and ann ual return rates. Metho ds in Ecology and Evolution. 2015 nov;7(3):274–284. Av ailable from: https://doi.org/10.1111% 2F2041- 210x.12496 . 28. Laiolo P , V¨ ogeli M, Serrano D, T ella JL. T esting acoustic versus physical marking: t w o complemen tary methods for individual-based monitoring of elusiv e sp ecies. Journal of Avian Biology . 2007;38(6):672–681. 29. Kirschel ANG, Cody ML, Harlo w ZT, Promponas VJ, V allejo EE, T aylor CE. T erritorial dynamics of Mexican Ant-thrushes F ormicarius moniliger rev ealed by individual recognition of their songs. Ibis. 2011;153:255–268. 30. Spillmann B, v an Sc haik CP , Setia TM, Sadjadi SO. Who shall I sa y is calling? V alidation of a caller recognition procedure in Bornean flanged male orangutan (P ongo p ygmaeus wurmbii) long calls. Bioacoustics. 2017;26(2):109–120. 31. Delp ort W, Kemp A C, F erguson JWH. V o cal iden tification of individual African W oo d Owls Strix woo dfordii: a tec hnique to monitor long-term adult turno ver and residency . Ibis. 2002;144:30–39. 32. Adi K, Johnson MT, Osiejuk TS. Acoustic censusing using automatic v o calization classification and iden tity recognition. Journal of the Acous- tical So ciet y of America. 2010 FEB;127(2):874–883. 25 33. T erry AMR, McGregor PK. Census and monitoring based on individually iden tifiable vocalizations: the role of neural netw orks. Animal Conserv a- tion. 2002;5:103–111. 34. F ox EJS. A new p ersp ectiv e on acoustic individual recognition in animals with limited call sharing or c hanging rep ertoires. Animal Beha viour. 2008 MAR;75(3):1187–1194. 35. F ox EJS, Rob erts JD, Bennamoun M. Call-indep enden t individual iden- tification in birds. Bioacoustics. 2008;18(1):51–67. 36. Cheng J, Sun Y, Ji L. A call-indep enden t and automatic acoustic sys- tem for the individual recognition of animals: A no vel mo del using four passerines. Pattern Recognition. 2010 NOV;43(11):3846–3852. 37. Cheng J, Xie B, Lin C, Ji L. A comparative study in birds: call- t yp e-indep enden t sp ecies and individual recognition using four machine- learning metho ds and tw o acoustic features. Bioacoustics. 2012 JUN;21(2):157–171. 38. Szegedy C, Zaremba W, Sutsk ever I, Bruna J, Erhan D, Go o dfello w I, et al. Intriguing prop erties of neural netw orks. arXiv preprint arXiv:13126199. 2013;. 39. Mesaros A, Heittola T, Virtanen T. Acoustic Scene Classification: an Ov erview of DCASE 2017 Challenge En tries. In: 16th In ternational W orkshop on Acoustic Signal Enhancemen t (IW AENC). T okyo, Japan; 2018. . 40. Khanna H, Gaunt S, McCallum D. Digital sp ectrographic cross- correlation: tests of sensitivity . Bioacoustics. 1997;7(3):209–234. 41. F o ote JR, Palazzi E, Mennill DJ. Songs of the Eastern Pho ebe, a sub- oscine songbird, are individually distinctiv e but do not v ary geographi- cally . Bioacoustics. 2013;22(2):137–151. 42. Pt´ aˇ cek L, Machlica L, Linhart P , Ja ˇ sk a P , Muller L. Automatic recogni- tion of bird individuals on an op en set using as-is recordings. Bioacoustics. 2016;25(1):55–73. 43. Stow ell D, St ylianou Y, W o o d M, P amu la H, Glotin H. Automatic acous- tic detection of birds through deep learning: the first Bird Audio Detec- tion c hallenge. ArXiv e-prints. 2018 Jul;. 44. Lasseck M. Audio-based Bird Sp ecies Identification with Deep Conv olu- tional Neural Net works. W orking Notes of CLEF. 2018;2018. 45. Grav a T, Mathev on N, Place E, Balluet P . Individual acoustic monitoring of the Europ ean Eagle Owl Bub o bub o. Ibis. 2008;150:279–287. 26 46. Petrusk o v´ a T, Osiejuk TS, Linhart P , Petrusek A. Structure and Com- plexit y of Perc hed and Flight Songs of the T ree Pipit (Anth us trivi- alis). Annales Zo ologici F ennici. 2008 apr;45(2):135–148. Av ailable from: https://doi.org/10.5735%2F086.045.0205 . 47. Pr ˚ uc hov´ a A, Ja ˇ sk a P , Linhart P . Cues to individual identit y in songs of songbirds: testing general song characteristics in Chiffchaffs Phyl losc opus c ol lybita . Journal of Ornithology . 2017 apr;Av ailable from: https://doi. org/10.1007%2Fs10336- 017- 1455- 6 . 48. Nieuw enh uyse D V, Gnot JC, Johnson DH. The Little Owl: Conserv ation, Ecology and Behavior of A thene no ctua . Cam bridge Univ ersity Press; 2008. 49. Linhart P , ˇ S´ alek M. The assessment of biases in the acoustic discrimina- tion of individuals. PloS one. 2017;12(5):e0177206. 50. Krizhevsky A, Sutskev er I, Hinton GE. ImageNet classifica- tion with deep con volutional neural net w orks. In: Adv ances in neural information pro cessing systems (NIPS); 2012. p. 1097–1105. Av ailable from: http://papers.nips.cc/paper/ 4824- imagenet- classification- with- deep- convolutional- neural- networks . 51. Cire¸ san D, Meier U, Schmidh uber J. Multi-column deep neural netw orks for image classification. arXiv preprint arXiv:12022745. 2012;. 52. Schl¨ uter J, Grill T. Exploring Data Augmentation for Improv ed Singing V oice Detection with Neural Netw orks. In: Pro ceedings of the Inter- national Conference on Music Information Retriev al (ISMIR); 2015. p. 121–126. 53. Salamon J, Bello JP . Deep con v olutional neural netw orks and data aug- men tation for environmen tal sound classification. IEEE Signal Processing Letters. 2017;24(3):279–283. 54. Stow ell D, Plumbley MD. Automatic large-scale classification of bird sounds is strongly improv ed by unsupervised feature learning. PeerJ. 2014;2:e488. 55. F aw cett T. An introduction to ROC analysis. P attern Recognition Let- ters. 2006;27(8):861–874. 56. F ournier DA, Sk aug HJ, Anc heta J, Ianelli J, Magn usson A, Maunder MN, et al. AD Mo del Builder: using automatic differentiation for statis- tical inference of highly parameterized complex nonlinear mo dels. Optim Metho ds Softw. 2012;27:233–249. 57. Sk aug H, F ournier D, Bolk er B, Magn usson A, Nielsen A. Generalized Linear Mixed Mo dels using ’AD Model Builder’; 2016-01-19. R pack age v ersion 0.8.3.3. 27 58. Beecher MD, Breno witz EA. F unctional asp ects of song learning in songbirds. T rends in Ecology & Ev olution. 2005;20(3):143–149. Av ail- able from: http://www.sciencedirect.com/science/article/pii/ S0169534705000054 . 28
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment