Error Reduction Network for DBLSTM-based Voice Conversion
So far, many of the deep learning approaches for voice conversion produce good quality speech by using a large amount of training data. This paper presents a Deep Bidirectional Long Short-Term Memory (DBLSTM) based voice conversion framework that can…
Authors: Mingyang Zhang, Berrak Sisman, Sai Sirisha Rallab
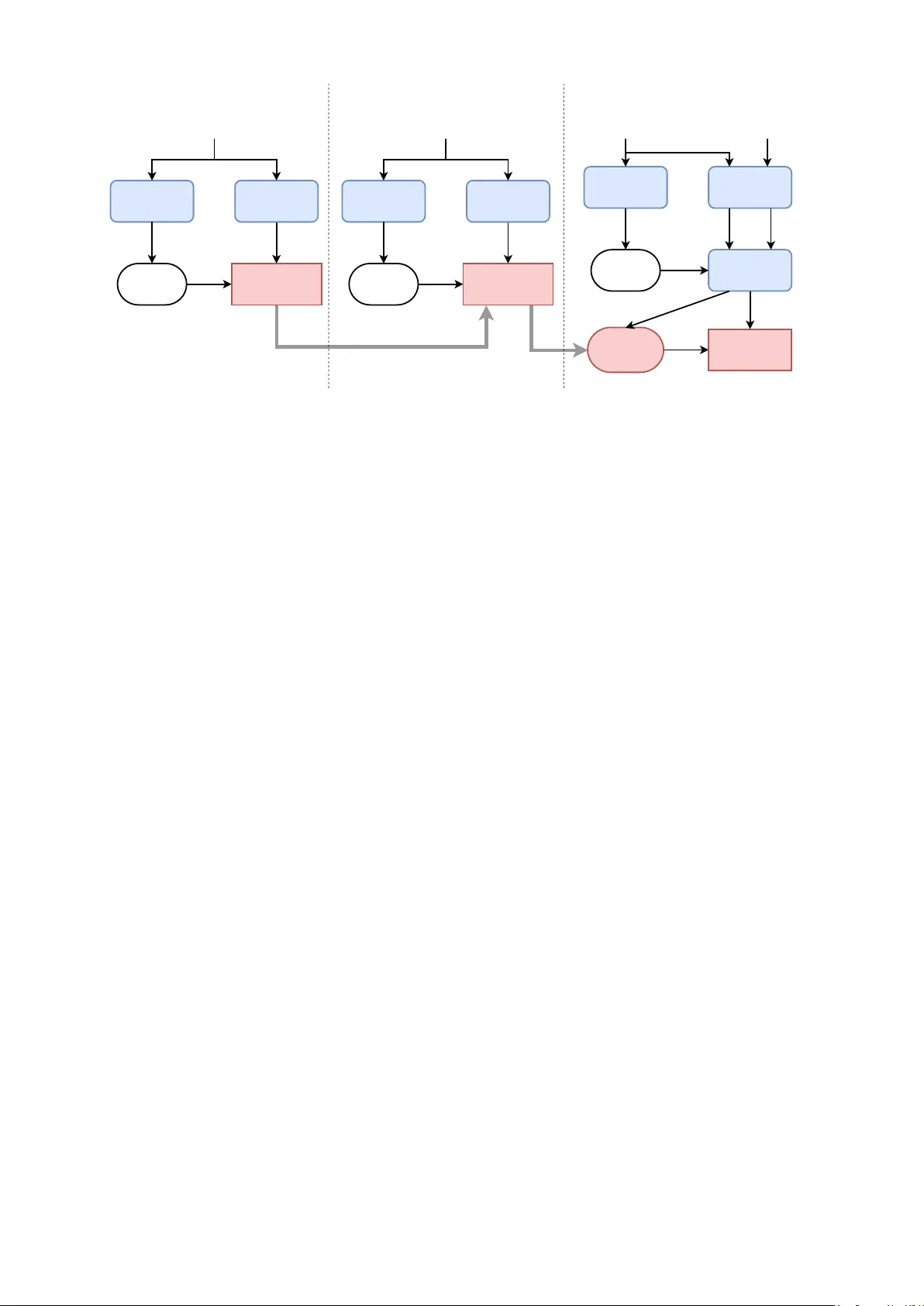
Error Reduction Network for DBLSTM-based V oice Con v ersion Mingyang Zhang ∗ † , Berrak Sisman † , Sai Sirisha Rallabandi † , Haizhou Li † , Li Zhao ∗ ∗ Ke y Laboratory of Underwater Acoustic Signal Processing of Ministry of Education, Southeast Uni versity , Nanjing, China E-mail: zhangmy@seu.edu.cn, zhaoli@seu.edu.cn † National Univ ersity of Singapore, Singapore E-mail: berraksisman@u.nus.edu, siri.gene@gmail.com, haizhou.li@nus.edu.sg Abstract —So far , many of the deep learning approaches for voice con version produce good quality speech by using a large amount of training data. This paper pr esents a Deep Bidir ectional Long Short-T erm Memory (DBLSTM) based voice con version framework that can w ork with a limited amount of training data. W e propose to implement a DBLSTM based av erage model that is trained with data from many speakers. Then, we propose to perf orm adaptation with a limited amount of target data. Last but not least, we pr opose an error r eduction network that can improv e the voice conv ersion quality even further . The pr oposed framework is motivated by three observ ations. Firstly , DBLSTM can achieve a remarkable voice conversion by considering the long-term dependencies of the speech utterance. Secondly , DBLSTM based a verage model can be easily adapted with a small amount of data, to achieve a speech that sounds closer to the target. Thirdly , an error reduction network can be trained with a small amount of training data, and can improve the conv ersion quality effectively . The experiments show that the proposed voice conv ersion framework is flexible to work with limited training data and outperf orms the traditional frameworks in both objecti ve and subjectiv e ev aluations. I . I N T RO D U C T I O N V oice Con version (VC) is a technology that modifies the speech of the source speaker to make it sounds like the target speaker . The v oice con version technology has been applied to many tasks, such as T ext-to-Speech (TTS) system [1], speech enhancement [2] and speaking assistance [3]. V oice conv ersion can be formulated as a regression problem of estimating a mapping function between the source and target features. Many state-of-the-art approaches for voice con version are including Gaussian Mixed Model (GMM) [4– 6] which is based on the maximum-likelihood estimation of spectral parameter trajectory . Dynamic K ernel Partial Least Squares (DKPLS) [7] integrates a kernel transformation into partial least squares to model nonlinearities as well as to capture the dynamics in the data. Sparse representation [8– 11] can be seen as a data-dri ven, non-parametric approach as an alternative to the traditional parametric approaches to voice con version. Frequency warping based approaches [12 – 14] aim to modify the frequency axis of source spectra to wards that of the target. There are also some post-filter approaches for voice con version to improv e the speech quality [15, 16]. Recently , deep learning approaches became popular in the field of voice con version. For example, Deep Neural Net- work (DNN) based approaches [17 – 19] focus on spectrum con version under the constraint of parallel training data and achiev e high-quality speech by using a lar ge amount of parallel training data. In addition, there ha ve been some researches on variational autoencoder [20, 21] that effecti vely improve the con version performance. The above-mentioned voice conv ersion frameworks con- sider the frame features as individual components, and do not concern about the long-term dependencies of the speech sequences. Standard Recurrent Neural Networks (RNNs) can be used to solve this problem [22, 23], but it has limited ability in modeling context because of the vanishing gradient problem [24]. Moreover , the standard RNNs can only capture the information from the former sequences and not the latter sequences. T o alleviate these problems, Deep Bidirectional Long Short- T erm Memory (DBLSTM) has been proposed to perform v oice con version [25–27], and achiev es remarkable performance ov er the traditional DNN-based v oice con version framework [27]. Moreov er , DBLSTM has been successfully used in various tasks in the field of speech and language processing, such as Automatic Speech Recognition (ASR) [28 – 30], speech synthesis [31] and emotion recognition [32, 33]. Although the DBLSTM and DNN based voice con version framew orks can achie ve good voice con version performance, they still suffer from the dependency of a lar ge amount of training data which is not practical in real life. The remaining issue is to find a way to make a good use of limited data. Different from the pre vious studies, in this paper, we take advantage of the powerful deep learning frame work DBLSTM, and propose a voice con version framew ork that can produce high-quality speech under the constraint of limited parallel data. Specifically , we make the following contrib utions: 1) due to DBLSTM can achiev e a remarkable voice con version by considering the long-term dependencies of the speech utter- ance, we build a DBLSTM-based average model by using data from many speakers; 2) since the DBLSTM-based average model can be easily adapted with a small amount of data, we perform adaptation to the DBLSTM-based a verage model by using limited target data, to achiev e a con verted sound that is more similar to that of target; 3) an error reduction network can be trained with a small amount of training data from source and target, so we propose an error reduction network for the adapted DBLSTM framework, that can improve the voice con version quality even further . Overall, we propose a DBLSTM-based voice con version framew ork that can produce high-quality speech with a small amount of training data. The rest of this paper is organized as follows: Section II explains the traditional DBLSTM-based approach of voice con version. Section III describes our proposed voice con ver- sion framework that is based on an error reduction network for the adapted DBLSTM-based approach. W e report the objectiv e and subjectiv e results in Section IV . Section V concludes this paper . I I . D B L S T M - B A S E D V O I C E C O N V E R S I O N The network architecture of BLSTM-based V oice Con- version is a combination of bidirectional RNNs and LSTM memory block, which can learn long-range contextual in both forward and backward directions. By stacking multiple hidden layers, a deep network architecture is built to capture the high-lev el representation of voice features. For bidirectional RNNs, the iteration functions for the forward sequence ~ h and backward sequence ~ h are as follows: ~ h t = H ( W x ~ h x t + W ~ h ~ h ~ h t − 1 + b ~ h ) (1) ~ h t = H ( W x ~ h x t + W ~ h ~ h ~ h t +1 + b ~ h ) (2) y t = W ~ hy ~ h t + W ~ hy ~ h t + b y (3) where x, y , h, t are the input, output, hidden state and time se- quence respectively . A LSTM network consists of recurrently connected blocks, known as memory block. Every memory block contains self-connected memory cells and three adap- tiv e and multiplicativ e gate units. The recurrent hidden layer function H of the LSTM network is implemented according to the following equations: i t = σ ( W xi x t + W hi h t − 1 + W ci c t − 1 + b i ) (4) f t = σ ( W xf x t + W hf h t − 1 + W ci c t − 1 + b f ) (5) c t = f t c t − 1 + i t tanh( W xc x t + W hc h t − 1 + b c ) (6) o t = σ ( W xo x t + W ho h t − 1 + W co c t + b o ) (7) h t = o t tanh( c t ) (8) where i, f , o, c refer to the input gate, forget gate, output gate and the element of cells C respectively . σ is the logistic sigmoid function. The overall framew ork of a DBSL TM-based voice con- version is shown in Fig. 1. In this frame work, the three feature streams including the spectrum feature, log( F 0 ) and the aperiodic component are con verted separately . The spectrum feature is conv erted by the DBLSTM model. log ( F 0 ) is con verted by equalizing the mean and the standard de viation of the source and target speech. And the aperiodic component is directly copied to synthesize the con verted speech. The whole utterance is treated as input so that the system can access the long-range context in both forward and backward directions. In this paper , we propose to use DBLSTM to perform voice con version under limited training data. Log F 0 Aperiodicity Spectrum Log F 0 Aperiodicity Spectrum STRAIGHT Analysis STRAIGHT Synthesis Source Speech Linear Conversion DBLSTM Model Converted Speech Fig. 1. DBLSTM-based voice conv ersion framework. I I I . E R R O R R E D U C T I O N N E T W O R K F O R A DA P T E D D B L S T M - B A SE D V O I C E C O N V E R S I O N The DBLSTM-based voice conv ersion has a good perfor- mance while it needs a large amount of parallel data from source speaker and target speaker , which is expensiv e to collect in practice. T o solve this problem, we propose an error reduction network for adapted DBLSTM-based approach. A. T raining Phase As illustrated in Fig. 2, the proposed approach can be divided into three training phases. In training phase 1, an av erage DBLSTM model is trained for the one-hot phoneme label to Mel-cepstral coefficients (MCEPs) mapping, using the data from many speakers except the source speaker and the target speaker . MCEPs are the Mel Log Spectral Approximation (MLSA) parameters which approximate Mel- Frequency Cepstral Coef ficients (MFCCs). A trained ASR system is used to extract the phoneme information of the input speech. The input of the ASR model is MFCC feature of the speech frame. The output is a one-hot phoneme label vector that indicates the phoneme information of the speech frame. Then a DBLSTM-based model is trained to get the mapping relationship between the one-hot phoneme label and the corresponding MCEPs which are extracted by STRAIGHT [34]. W e call this framework as A verage Model, it can only generate MCEPs of an average voice of the speakers whose data are used. In training phase 2, the average model is adapted using a small amount of data from the target speaker . The adaptation is similar to the training of the av erage model, except the ini- tialized network is the trained average model and the training data is the target speech. After the adaptation, the output of the adapted model will be closer to the target speaker . W e call this framew ork as adapted av erage model. Ho wev er , there always exists an error between the conv erted features and the target features. This error degrades both quality and similarity of the con verted speech [35]. T o reduce such error , we propose an error reduction network after the adapted average model. T raining phase 3 inv olves the error reduction network which is essentially an additional DBLSTM network, used to map the con verted MCEPs to the target MCEPs. The error reduction network brings the final output MCEPs features closer to the Trained ASR model Feature Extraction MFCC One-hot Phoneme Label DBLSTM Error Reduction Network Training Converted Mceps Source MCEPs STRAIGHT Analysis Adapted DBLSTM Average Model Trained ASR Model Feature Extraction MFCC Adapt the DBLSTM Average Model One-hot Phoneme Label MCEPs STRAIGHT Analysis Trained ASR Model Feature Extraction MFCC DBLSTM Average Model Training One-hot Phoneme Label MCEPs STRAIGHT Analysis T raining Phase 1 T raining Phase 2 T raining Phase 3 DTW T arget MCEPs Paired T arget MCEPs Paired One- hot Phoneme Label Data from the source speaker Data from the target speaker Data from the target speaker Data from many speakers Fig. 2. The proposed DBLSTM based VC framew ork. In training phase 1, we exclude the data from the source and the target speakers. In training phase 2, we only use the data from the target speaker . In training phase 3, we use the same sentences from both source and target speakers. target speaker . The same utterances ha ve been used in the adapted av erage model of the target speaker and the parallel data of the source speaker are used in the error reduction network. The same ASR system is used to generate the one-hot phoneme label of the target speech. MCEPs features from the same sentences of the source speech and the target speech are aligned by dynamic time warping (DTW), and the alignment information is also used to get the paired one-hot phoneme label. Then feed the label to the adapted average model to generate the paired conv erted MCEPs. For the training of the error reduction network, the input is the paired conv erted MCEPs, and the output is the original feature of the target speech. The error reduction network can reduce the error that created by the previous training part. B. Run-time Conver sion Phase In the conv ersion stage, the input is a whole sentence of the source speaker . The con version of log ( F 0 ) and aperiodicity is the same as that of the DBLSTM-based system mentioned in Section II. MFCC features of the source speech are used by the trained ASR model to obtain the one-hot phoneme labels. Next, the one-hot phoneme labels are con verted to MCEPs by the trained adapted av erage model. Then, the con verted MCEPs are fed into the error reduction network to get the final result. Finally , the con verted MCEPs together with the con verted log( F 0 ) and aperiodicity are used by the STRAIGHT vocoder to synthesize the output speech. I V . E X P E R I M E N T S A. Experimental Setup W e conduct listening experiments to assess the performance of our proposed framework that is error reduction network for adapted DBLSTM-based v oice con version. W e compare this framew ork with the baseline DBLSTM [27] that is explained in Section II, and DBLSTM-based adapted average model that is explained in Section III and given in Fig. 3. W e note that the adapted average model is an intermediate step of our proposed algorithm. Fig. 4 also shows the differences between of our proposed framew ork and the adapted average model. The database used in the experiments is CMU ARCTIC corpus [36]. As it is the most challenging work in voice con version, we conduct the cross-gender voice conv ersion experiments. The speech signals are sampled at 16kHz with mono channel, windo wed by 25ms, and the frameshift is 5ms. For the DBLSTM-based average model training, data from four male speakers (awb, jmk, ksp, rms) are used. 4433 and 489 sentences are used as training data and validation data. In training phase 2, 45 and 5 sentences from the target speaker (slt) are used as training data and v alidation data to adapt the average model. For the error reduction training, the same sentences of the target speaker that ha ve been used to adapt the av erage model and the parallel data of the source speaker (bdl) are used. A DNN-HMM based ASR system [37] is used to get the 171-dimension one-hot phoneme label. 40-dimension MCEPs are extracted by STRAIGHT to train the model. In our proposed approach, to train a DBLSTM-based model, we prefer to use four hidden layers, the number of units in each layer is [171 128 256 256 128 40] respecti vely . Each bidirectional LSTM hidden layer contains one forward LSTM layer and one backward LSTM layer . The training samples are normalized to zero mean and unit v ariance for each dimension before training. For the error reduction network, in order to take advantage of context information, three frames of con verted MCEPs i.e. current frame, one left frame and 1 right frame are used as input features. In addition, there are three hidden layers in the error reduction network, the number of units in each layer is [120 128 256 128 40] respecti vely . In order to ev aluate our proposed approach, 100 parallel Source Speech Converted Mceps Converted Speech Adapted DBLSTM Average Model Linear Conversion Log F 0 STRAIGHT Synthesis Aperiodicity Trained ASR model STRAIGHT Analysis Fig. 3. The run-time phase of the adapted average model. utterances from the source speaker and the target speaker are used to train a DBLSTM-based parallel voice con version system. This system is de veloped as the baseline approach. There are four hidden layers in the baseline model where the number of units in each layer is same as the training of the adapted av erage model that is [40 128 256 256 128 40] respectiv ely . W e use an open-source CUD A recurrent neural network toolkit CURRENNT [38] to train the DBLSTM model with a learning rate of 10 − 5 and a momentum of 0 . 9 . B. Objective Evaluation Mel-cepstral distortion (MCD) [39] is used as objective measure of the spectral distance from con verted to target speech, which is denoted as: M C D [ dB ] = 10 ln 10 v u u t 2 D X d =1 ( C targ et d − C conv er ted d ) 2 (9) where C targ et d and C conv er ted d are the d th dimension of the original target MCEPs and the conv erted MCEPs, respectively . W e expect a good system to report a low MCD value. The MCD scores of the dif ferent systems for the cross- gender voice conv ersion are summarized in T able I. W e can see that our proposed approach outperforms the baseline model and the adapted a verage model. W e can also note that the MCD scores of the adapted average model is not as good as the baseline model, because there is no parallel data in the training of the adapted average model. But after the error reduction network with only 50 utterances of parallel data, the performance can be improved obviously , and outperform both adapted av erage model and baseline model with 100 utterances of parallel training data. T ABLE I T H E M C D O F DI FF E R EN T S YS T E MS . Source-T arget Baseline Adapted A verage Model Proposed Approach 9.3197 6.3042 6.7378 6.1989 C. Subjective Evaluation T o e valuate the quality and similarity of the conv erted speech from the different systems, we conduct a subjectiv e listening test and 10 listeners are invited to ev aluate 10 sentences in each system. W e carry out Mean Opinion Score (MOS) test for e valuating speech quality and naturalness. In the MOS test, comparing Source Speech Converted Mceps Converted Speech Adapted DBLSTM Average Model Linear Conversion Log F 0 STRAIGHT Synthesis Aperiodicity Trained ASR model STRAIGHT Analysis DBLSTM Error Reduction Network Fig. 4. The run-time phase of the proposed framework. with target speech, the grades of the con verted speech are: 5 = excellent, 4 = good, 3 = fair , 2 = poor , and 1 = bad. The listeners are asked to rate the speech according to this regulation. In this experiment, we conduct the MOS test among three systems: 1) baseline approach, the parallel DBLSTM-based voice conv ersion training with 100 utterances of parallel data; 2) adapted average model that explained in Section III; 3) our proposed approach. The results of the MOS test and the 95% confidence intervals are shown in Fig. 5. The scores of the baseline, adapted av erage Model and the proposed approach are 2.62, 2.71 and 3.41 respecti vely . ABX preference test is adopted to e v aluate speaker sim- ilarity of the con verted speech generated by two different systems. The listeners are asked to choose either A or B that sounds closer to the target speaker’ s speech X. W e conduct the ABX preference test between the baseline approach and our proposed approach. The preference bars for speaker similarity are shown in Fig. 6. 2 .62 2 .71 3 .41 1 .5 2 2 .5 3 3 .5 4 Bas e li ne Ada p t e d Av er ag e M o de l P r o po s ed App r o ac h Fig. 5. The result of the MOS test with the 95% confidence interv als for speech quality and naturalness among the three systems. Overall, the results of both MOS test and ABX prefer- ence test show that our proposed error reduction network for adapted DBLSTM-based voice con version with a limited amount of parallel data outperforms the baseline approach with a large amount of parallel data in both speech quality and similarity . Probably because the average model is trained with a large amount of data to achiev e a better speech quality than the baseline approach, improv e the performance of the following portions of the system. 87% 13% 0% 1 0 % 2 0 % 3 0 % 4 0 % 5 0 % 6 0 % 7 0 % 8 0 % 9 0 % 1 0 0 % P ro po se d Appro ac h Base li n e Fig. 6. The result of the ABX preference test for speaker similarity between the baseline and our proposed approach. V . C O N C L U S I O N S This paper presents an error reduction network for adapted DBLSTM-based voice con version approach, which can achiev e a good performance with limited parallel data of the source speaker and the target speaker . Firstly , we propose to train an av erage model for the one-hot phoneme label to MCEPs mapping with data from many speakers exclude the source speaker and the target speaker . Then, we propose to adapt the average model with a limited amount of target data. Furthermore, we implement an error reduction network that can improve the v oice con version quality . Experiment results from both objective and subjectiv e ev olution show that our proposed approach can make a good use of limited data, and outperforms the baseline approach. In the future, we will in vestigate to use the W aveNet V ocoder , which is a con volu- tional neural network that can generate raw audio waveform sample by sample, to improv e the quality and naturalness of the conv erted speech. Some samples for the listening test are av ailable through this link: https://arkhamimp.github .io/ ErrorReductionNetwork/ A C K N O W L E D G M E N T This research is supported by Ministry of Education, Sin- gapore AcRF Tier 1 NUS Start-up Grant FY2016. Mingyang Zhang is also supported by the China Scholarship Council (Grant No.201706090063). Berrak Sisman is also funded by SINGA Scholarship under A*ST AR Graduate Academy . R E F E R E N C E S [1] A. Kain and M. W . Macon, “Spectral voice con version for text-to-speech synthesis, ” in Acoustics, Speech and Signal Pr ocessing, 1998. Pr oceedings of the 1998 IEEE International Confer ence on , vol. 1, pp. 285–288 vol.1, May 1998. [2] T . T oda, M. Nakagiri, and K. Shikano, “Statistical voice conv ersion techniques for body-conducted un- voiced speech enhancement, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 20, pp. 2505–2517, Nov 2012. [3] K. Nakamura, T . T oda, H. Saruwatari, and K. Shikano, “Speaking-aid systems using gmm-based v oice con ver- sion for electrolaryngeal speech, ” Speech Communica- tion , vol. 54, no. 1, pp. 134 – 146, 2012. [4] T . T oda, A. W . Black, and K. T okuda, “V oice con version based on maximum-likelihood estimation of spectral pa- rameter trajectory , ” IEEE T ransactions on Audio, Speech and Language Pr ocessing , vol. 15, no. 8, pp. 2222–2235, 2007. [5] S. T akamichi, T . T oda, A. W . Black, and S. Nakamura, “Modulation spectrum-constrained trajectory training al- gorithm for gmm-based voice con version, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE In- ternational Confer ence on , pp. 4859–4863, IEEE, 2015. [6] K. T anaka, S. Hara, M. Abe, M. Sato, and S. Minagi, “Speaker dependent approach for enhancing a glossec- tomy patient’ s speech via gmm-based voice conv ersion, ” Pr oc. Interspeech 2017 , pp. 3384–3388, 2017. [7] E. Helander , H. Silen, T . V irtanen, and M. Gab- bouj, “V oice con version using dynamic kernel partial least squares regression, ” IEEE T ransactions on Au- dio, Speech, and Language Pr ocessing , vol. 20, no. 3, pp. 806–817, 2012. [8] Z. W u, T . V irtanen, E. S. Chng, and H. Li, “Exemplar - based sparse representation with residual compensation for voice conv ersion, ” IEEE/ACM T ransactions on Au- dio, Speech and Languag e Pr ocessing , vol. 22, no. 10, pp. 1506–1521, 2014. [9] R. T akashima, T . T akiguchi, and Y . Ariki, “Exemplar - based voice conv ersion using sparse representation in noisy en vironments, ” IEICE T ransactions on Funda- mentals of Electr onics, Communications and Computer Sciences , vol. 96, no. 10, pp. 1946–1953, 2013. [10] B. C ¸ is ¸ man, H. Li, and K. C. T an, “Sparse representation of phonetic features for voice con version with and with- out parallel data, ” in Automatic Speech Recognition and Understanding W orkshop (ASR U), 2017 IEEE , pp. 677– 684, IEEE, 2017. [11] B. Sisman, H. Li, and K. C. T an, “Transformation of prosody in voice con version, ” in 2017 Asia-P acific Signal and Information Pr ocessing Association Annual Summit and Conference (APSIP A ASC) , pp. 1537–1546, Dec 2017. [12] X. Tian, Z. W u, S. W . Lee, and E. S. Chng, “Correlation- based frequency warping for voice conv ersion, ” in Chi- nese Spoken Languag e Pr ocessing (ISCSLP), 2014 9th International Symposium on , pp. 211–215, IEEE, 2014. [13] X. T ian, Z. W u, S. W . Lee, N. Q. Hy , M. Dong, and E. S. Chng, “System fusion for high-performance voice con version, ” In Pr oceedings of the Annual Conference of the International Speech Communication Associa- tion, INTERSPEECH , vol. 2015-January , pp. 2759–2763, 2015. [14] X. T ian, S. W . Lee, Z. W u, E. S. Chng, S. Member , and H. Li, “An Exemplar -based Approach to Frequency W arping for V oice Con version, ” pp. 1–10, 2016. [15] S. T akamichi, T . T oda, A. W . Black, G. Neubig, S. Sakti, and S. Nakamura, “Postfilters to modify the modulation spectrum for statistical parametric speech synthesis, ” IEEE/A CM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 24, pp. 755–767, April 2016. [16] N. Xu, X. Y ao, A. Jiang, X. Liu, and J. Bao, “High quality voice con version by post-filtering the outputs of gaussian processes, ” in 2016 24th Eur opean Signal Pr ocessing Conference (EUSIPCO) , pp. 863–867, Aug 2016. [17] L.-h. Chen, Z.-h. Ling, L.-j. Liu, and L.-r . Dai, “V oice Con version Using Deep Neural Networks With Layer- W ise Generativ e Training, ” IEEE T ransactions on A u- dio, Speech and Languag e Pr ocessing , vol. 22, no. 12, pp. 1859–1872, 2014. [18] T . Nakashika, R. T akashima, T . T akiguchi, and Y . Ariki, “V oice conv ersion in high-order eigen space using deep belief nets, ” In INTERSPEECH , no. August, pp. 369– 372, 2013. [19] S. H. Mohammadi and A. Kain, “V oice con version using deep neural networks with speaker-independent pre-training, ” in Spoken Language T echnolo gy W orkshop (SLT), 2014 IEEE , pp. 19–23, IEEE, 2014. [20] C.-C. Hsu, H.-T . Hwang, Y .-C. W u, Y . Tsao, and H.-M. W ang, “V oice con version from non-parallel corpora us- ing variational auto-encoder , ” in Signal and Information Pr ocessing Association Annual Summit and Confer ence (APSIP A), 2016 Asia-P acific , pp. 1–6, IEEE, 2016. [21] C.-C. Hsu, H.-T . Hwang, Y .-C. W u, Y . Tsao, and H.- M. W ang, “V oice con version from unaligned corpora using v ariational autoencoding wasserstein generativ e adversarial networks, ” arXiv preprint , 2017. [22] T . Nakashika, T . T akiguchi, and Y . Ariki, “High-order sequence modeling using speaker -dependent recurrent temporal restricted Boltzmann machines for voice con- version, ” In Pr oceedings of the Annual Confer ence of the International Speech Communication Association, INTERSPEECH , no. September , pp. 2278–2282, 2014. [23] T . Nakashika, T . T akiguchi, and Y . Ariki, “V oice con- version using rnn pre-trained by recurrent temporal re- stricted boltzmann machines, ” IEEE/A CM T ransactions on Audio, Speech and Language Pr ocessing (T ASLP) , vol. 23, no. 3, pp. 580–587, 2015. [24] Y . Bengio, P . Simard, and P . Frasconi, “Learning long- term dependencies with gradient descent is difficult, ” IEEE transactions on neural networks , vol. 5, no. 2, pp. 157–166, 1994. [25] S. Hochreiter and J. Schmidhuber , “Long short-term memory , ” Neural computation , v ol. 9, no. 8, pp. 1735– 1780, 1997. [26] A. Graves and J. Schmidhuber, “Framewise phoneme classification with bidirectional lstm and other neural network architectures, ” Neural Networks , vol. 18, no. 5- 6, pp. 602–610, 2005. [27] L. Sun, S. Kang, K. Li, and H. Meng, “V oice conv er- sion using deep bidirectional Long Short-T erm Memory based Recurrent Neural Networks, ” In ICASSP , no. 1, pp. 4869–4873, 2015. [28] A. Grav es, N. Jaitly , and A.-r . Mohamed, “Hybrid speech recognition with deep bidirectional lstm, ” in Automatic Speech Recognition and Understanding (ASR U), 2013 IEEE W orkshop on , pp. 273–278, IEEE, 2013. [29] M. W ¨ ollmer , Z. Zhang, F . W eninger , B. Schuller, and G. Rigoll, “Feature enhancement by bidirectional lstm networks for con versational speech recognition in highly non-stationary noise, ” in Acoustics, Speec h and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer- ence on , pp. 6822–6826, IEEE, 2013. [30] A. Zeyer , P . Doetsch, P . V oigtlaender , R. Schl ¨ uter , and H. Ney , “ A comprehensi ve study of deep bidirectional lstm rnns for acoustic modeling in speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on , pp. 2462–2466, IEEE, 2017. [31] Y . Fan, Y . Qian, F .-L. Xie, and F . K. Soong, “Tts synthesis with bidirectional lstm based recurrent neural networks, ” in F ifteenth Annual Confer ence of the Inter- national Speech Communication Association , 2014. [32] M. W ¨ ollmer , A. Metallinou, F . Eyben, B. Schuller , and S. Narayanan, “Context-sensitiv e multimodal emotion recognition from speech and facial expression using bidirectional lstm modeling, ” in Pr oc. INTERSPEECH 2010, Makuhari, J apan , pp. 2362–2365, 2010. [33] L. He, D. Jiang, L. Y ang, E. Pei, P . W u, and H. Sahli, “Multimodal affecti ve dimension prediction using deep bidirectional long short-term memory recurrent neural networks, ” in Pr oceedings of the 5th International W ork- shop on Audio/V isual Emotion Challenge , pp. 73–80, A CM, 2015. [34] H. Kawahara, I. Masuda-Katsuse, and A. de Chev eigne, “Restructuring speech representations using a pitch- adaptiv e timefrequency smoothing and an instantaneous- frequency-based f0 extraction: Possible role of a repetitiv e structure in sounds, ” Speec h communication , pp. 187–207, 1999. [35] J. W u, D. Huang, L. Xie, and H. Li, “Denoising recurrent neural network for deep bidirectional lstm based voice con version, ” Pr oc. Interspeech 2017 , pp. 3379–3383, 2017. [36] J. Kominek and A. W . Black, “The cmu arctic speech databases, ” in F ifth ISCA W orkshop on Speech Synthesis , pp. 223–224, 2004. [37] D. Pove y , A. Ghoshal, N. Goel, M. Hannemann, Y . Qian, P . Schwarz, J. Silovsk, and P . Motl, “The Kaldi Speech Recognition T oolkit, ” In IEEE ASR U , 2011. [38] F . W eninger, J. Bergmann, and B. Schuller, “Introducing currennt: The munich open-source cuda recurrent neu- ral network toolkit, ” The Journal of Machine Learning Resear ch , vol. 16, no. 1, pp. 547–551, 2015. [39] R. Kubichek, “Mel-cepstral distance measure for objec- tiv e speech quality assessment, ” Communications, Com- puters and Signal Pr ocessing , pp. 125–128, 1993.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment