Metric Learning for Phoneme Perception
Metric functions for phoneme perception capture the similarity structure among phonemes in a given language and therefore play a central role in phonology and psycho-linguistics. Various phenomena depend on phoneme similarity, such as spoken word recognition or serial recall from verbal working memory. This study presents a new framework for learning a metric function for perceptual distances among pairs of phonemes. Previous studies have proposed various metric functions, from simple measures counting the number of phonetic dimensions that two phonemes share (place-, manner-of-articulation and voicing), to more sophisticated ones such as deriving perceptual distances based on the number of natural classes that both phonemes belong to. However, previous studies have manually constructed the metric function, which may lead to unsatisfactory account of the empirical data. This study presents a framework to derive the metric function from behavioral data on phoneme perception using learning algorithms. We first show that this approach outperforms previous metrics suggested in the literature in predicting perceptual distances among phoneme pairs. We then study several metric functions derived by the learning algorithms and show how perceptual saliencies of phonological features can be derived from them. For English, we show that the derived perceptual saliencies are in accordance with a previously described order among phonological features and show how the framework extends the results to more features. Finally, we explore how the metric function and perceptual saliencies of phonological features may vary across languages. To this end, we compare results based on two English datasets and a new dataset that we have collected for Hebrew.
💡 Research Summary
The paper introduces a data‑driven framework for learning phoneme‑perception distance metrics, addressing the longstanding reliance on manually crafted similarity functions in phonology and psycholinguistics. Traditional approaches—such as counting shared phonetic dimensions (place, manner, voicing), computing overlap of natural classes, or assigning heuristic weights to features—have struggled to fully account for empirical confusion data. To overcome this, the authors propose a metric‑learning method that assumes a general form of the distance function but lets its parameters be estimated directly from behavioral confusion matrices.
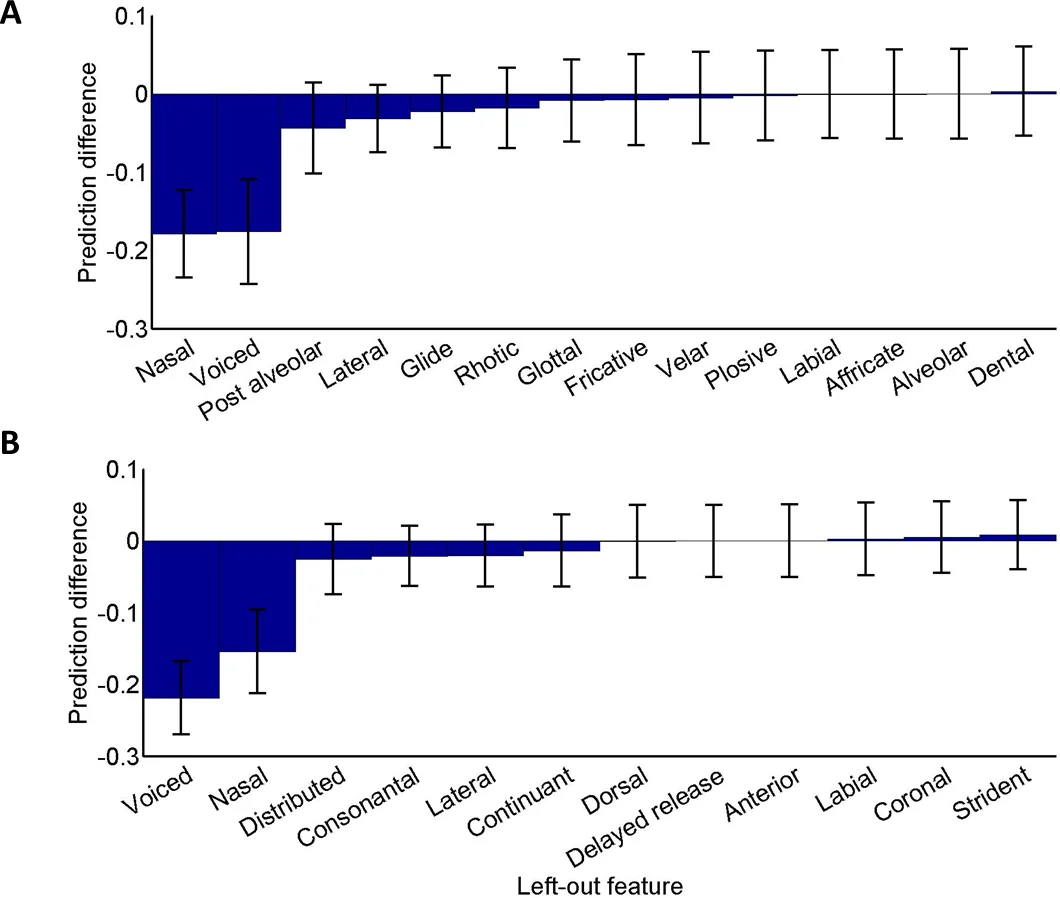
The method proceeds as follows. First, each phoneme is encoded as a binary vector over a set of phonological features derived from a chosen feature theory (e.g., distinctive features). Second, human confusion data (probability that phoneme i is heard as phoneme j) are transformed into a distance-like quantity, typically via a log‑inverse or similar monotonic mapping. Third, a parametric metric—implemented as a positive diagonal matrix—maps the Euclidean distances in feature space to the empirically derived distances. The diagonal entries act as scaling factors for each feature, thereby revealing the perceptual saliency of that feature: larger weights indicate that small differences along that dimension produce larger perceived dissimilarities.
The authors evaluate the approach on three datasets: (1) Miller & Nicely (1955) English consonant confusions in white noise, (2) Luce (1987) English confusions in speech‑shaped noise, and (3) a newly collected Hebrew dataset focusing on initial consonant confusions. Using five‑fold cross‑validation, they compare the learned metric against several benchmark metrics: (a) simple count of shared features, (b) natural‑class overlap, and (c) previously published weighted‑feature schemes. Performance is assessed with Pearson’s R², root‑mean‑square error (RMSE), and information‑theoretic criteria (AIC/BIC). In every case, the learned metric yields higher correlation with held‑out data and lower prediction error, demonstrating superior generalization.
Beyond predictive accuracy, the learned diagonal weights provide interpretable insights. For English, the most salient features are place of articulation and voicing, while manner of articulation receives comparatively lower weight. In Hebrew, voicing emerges as especially salient, reflecting language‑specific phonotactic sensitivities. These findings corroborate earlier qualitative claims about feature importance but now quantify them directly from perception data, and they reveal cross‑linguistic differences that challenge the notion of universal feature saliency.
The paper also discusses theoretical implications. By integrating feature‑based representations with empirical distance learning, the framework bridges the gap between symbolic phonological theory and data‑driven psycholinguistics. It offers a principled way to test competing feature inventories, to examine asymmetries in confusion (e.g., /t/→/f/ vs. /f/→/t/), and to explore context effects by incorporating additional covariates into the learning model.
Limitations are acknowledged. The diagonal‑only assumption precludes modeling interactions between features (e.g., co‑articulation effects). The datasets are restricted to initial consonants, leaving vowel and final‑consonant perception unexamined. The conversion from confusion probabilities to distances is somewhat arbitrary, and alternative transformations could affect the learned weights. Moreover, the relatively small size of the Hebrew dataset raises concerns about overfitting.
Future work is outlined: extending the metric to full (non‑diagonal) positive‑semidefinite matrices to capture feature interdependencies; incorporating non‑linear transformations via kernel methods or neural networks; expanding the experimental corpus to include multiple languages, dialects, noise types, and lexical contexts; and applying the learned metrics to downstream technologies such as speech recognition, language acquisition modeling, and clinical assessment of phonological disorders.
In sum, the study demonstrates that a modestly constrained metric‑learning approach can both outperform traditional hand‑crafted phoneme similarity measures and yield quantitative estimates of feature saliency, opening new avenues for empirically grounded phonological theory and practical speech technology.
Comments & Academic Discussion
Loading comments...
Leave a Comment