Deep Residual Learning for Small-Footprint Keyword Spotting
We explore the application of deep residual learning and dilated convolutions to the keyword spotting task, using the recently-released Google Speech Commands Dataset as our benchmark. Our best residual network (ResNet) implementation significantly outperforms Google’s previous convolutional neural networks in terms of accuracy. By varying model depth and width, we can achieve compact models that also outperform previous small-footprint variants. To our knowledge, we are the first to examine these approaches for keyword spotting, and our results establish an open-source state-of-the-art reference to support the development of future speech-based interfaces.
💡 Research Summary
**
The paper investigates the use of deep residual learning and dilated convolutions for the small‑footprint keyword spotting task, using the publicly available Google Speech Commands dataset as a benchmark. The authors build a family of convolutional neural networks (CNNs) based on the ResNet architecture, adapting it to the audio domain by processing 1‑second MFCC feature maps (40‑dimensional, 30 ms window, 10 ms stride).
The core contribution is a “res15” model consisting of six residual blocks, each containing a bias‑free 3×3 convolution, batch normalization, and ReLU activation. Between blocks, the dilation factor is increased exponentially (1, 2, 4, …) so that the receptive field grows to 125 × 125, allowing the network to capture the full temporal context of a one‑second utterance with relatively few layers. This design mimics the long‑range dependency modeling that recurrent networks provide, but retains the simplicity, parallelism, and hardware friendliness of pure CNNs.
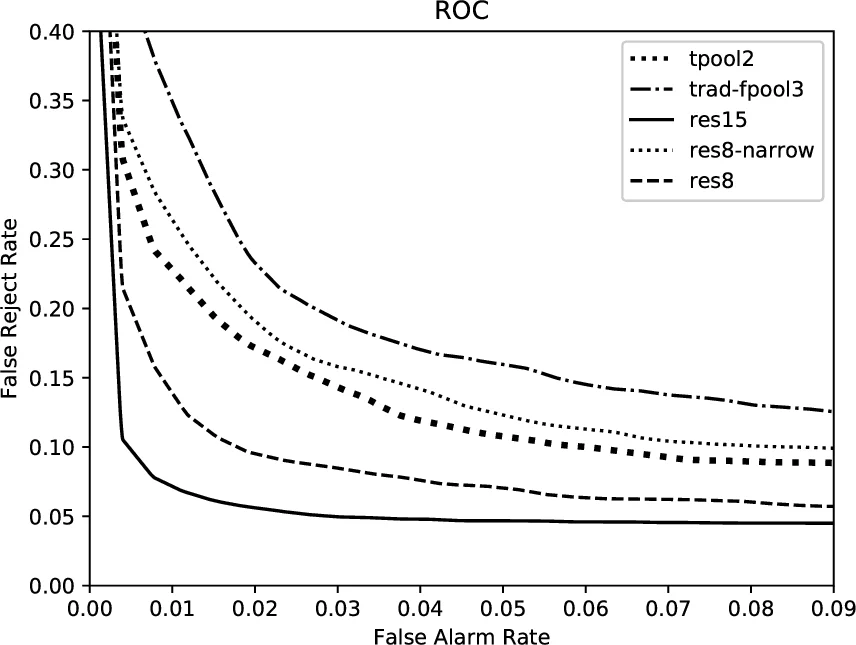
In terms of performance, res15 achieves 95.8 % classification accuracy on the 12‑class subset of the Speech Commands dataset, surpassing the best previously reported Google CNN (tpool2, 91.7 %). Although res15 uses fewer parameters (≈238 K) than tpool2 (≈1.09 M), it requires more multiply‑accumulate operations (≈894 M vs. 103 M), reflecting a trade‑off between memory footprint and computational load.
To address scenarios where computational resources are severely limited, the authors explore two orthogonal compression strategies: reducing depth (res8) and reducing width (narrow variants). The “res8‑narrow” model contains only 19 K parameters and 5.65 M multiplies, yet still reaches 90.1 % accuracy—substantially better than Google’s compact one‑stride1 model (≈12 K parameters, 5.76 M multiplies, 77.9 % accuracy). The wider “res8” model (110 K parameters, 30 M multiplies) attains 94.1 % accuracy, delivering a 50‑fold reduction in parameters and an 18‑fold reduction in multiplies compared with tpool2 while improving accuracy.
A deeper variant, “res26,” with twelve residual blocks (26 layers total) was also evaluated. Its accuracy (95.2 %) fell slightly below that of res15, suggesting that beyond a certain depth the optimization becomes more difficult and that increasing width has a larger impact on performance than increasing depth for this task.
Training follows the exact protocol of the original Google baseline: stochastic gradient descent with momentum 0.9, an initial learning rate of 0.1 (decayed by a factor of 0.1 on plateaus), L2 weight decay of 1e‑5, batch size 64, and 26 epochs (≈9 000 steps). Data augmentation includes random background noise insertion (80 % probability per epoch) and uniform time‑shift in the range ±100 ms. All pre‑processed MFCC tensors are cached and partially evicted each epoch to accelerate training.
Evaluation uses classification accuracy as the primary metric and ROC curves (area under curve) for a more nuanced view of false‑alarm and false‑reject trade‑offs. Five independent runs with different random seeds provide 95 % confidence intervals. Across all experiments, every ResNet‑based model statistically outperforms the three Google CNN baselines (trad‑fpool3, tpool2, one‑stride1). Notably, the compact res8‑narrow model dominates the one‑stride1 baseline while using 50× fewer parameters and 18× fewer multiplies.
The authors conclude that deep residual learning combined with dilated convolutions offers a powerful, yet hardware‑friendly, solution for on‑device keyword spotting. Their open‑source implementation (GitHub repository) establishes a new state‑of‑the‑art reference for the Speech Commands benchmark. Future work is planned to compare these CNN‑based approaches with emerging recurrent architectures (e.g., CRNNs, LSTMs) once publicly available implementations and common benchmarks become accessible, and to explore additional model compression techniques such as quantization and pruning for further footprint reduction.
Comments & Academic Discussion
Loading comments...
Leave a Comment