Attention as a Perspective for Learning Tempo-invariant Audio Queries
Current models for audio--sheet music retrieval via multimodal embedding space learning use convolutional neural networks with a fixed-size window for the input audio. Depending on the tempo of a query performance, this window captures more or less m…
Authors: Matthias Dorfer, Jan Hajiv{c} Jr., Gerhard Widmer
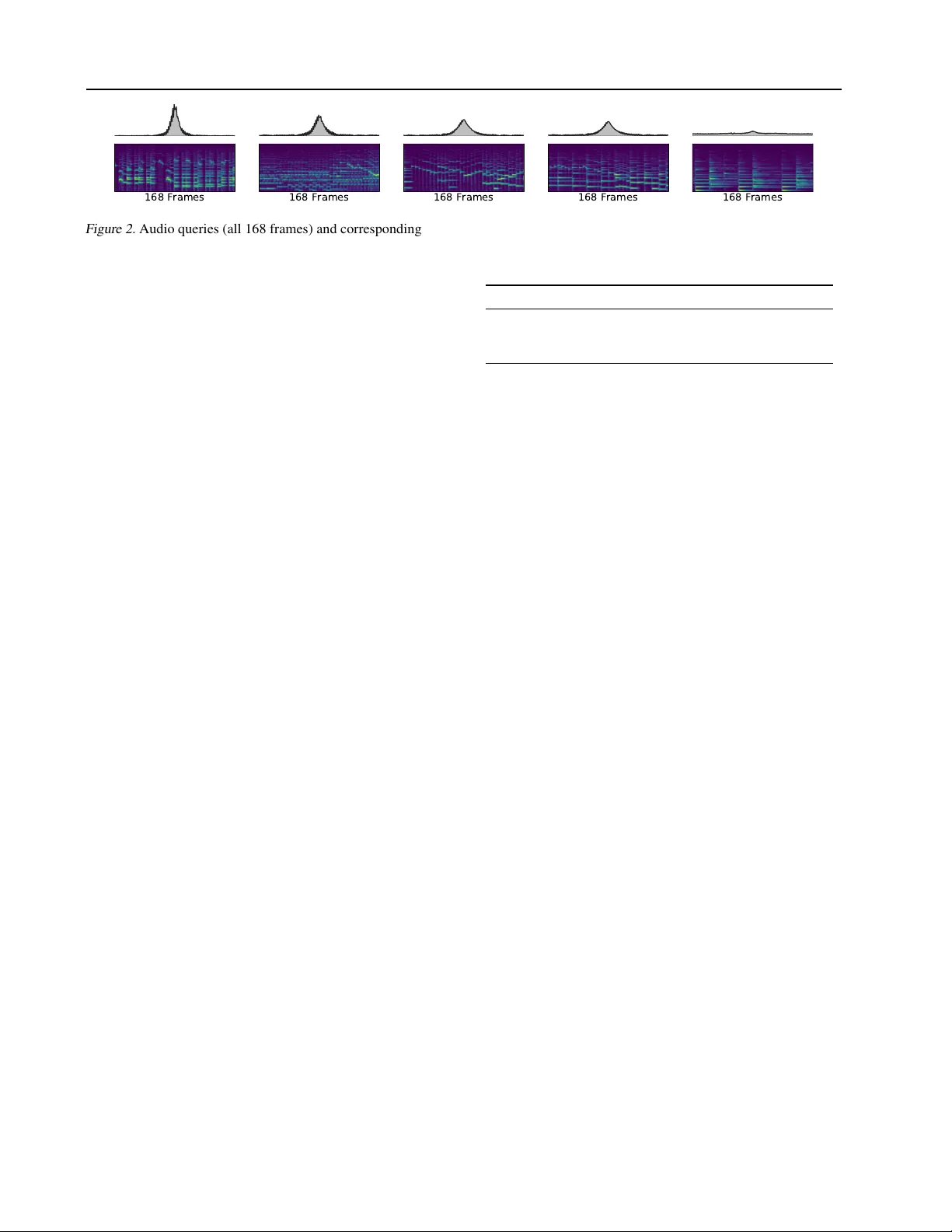
Attention as a P erspectiv e f or Lear ning T empo-in variant A udio Queries Matthias Dorfer 1 Jan Haji ˇ c jr . 2 Gerhard Widmer 1 Abstract Current models for audio–sheet music retriev al via multimodal embedding space learning use con- volutional neural netw orks with a fixed-size win- dow for the input audio. Depending on the tempo of a query performance, this window captures more or less musical content, while notehead den- sity in the score is largely tempo-independent. In this work we address this disparity with a soft attention mechanism, which allo ws the model to encode only those parts of an audio excerpt that are most rele vant with respect to efficient query codes. Empirical results on classical piano music indicate that attention is beneficial for retriev al performance, and exhibits intuiti vely appealing behavior . 1. Introduction Cross-modal embedding models hav e demonstrated the abil- ity to retriev e sheet music using an audio query , and vice versa, based on just the raw audio and visual signal ( Dorfer et al. , 2017 ). A limitation of the system was that the field of vie w into both modalities had a fixed size. This is most pronounced for audio: a human listener can easily recog- nize the same piece of music played in very dif ferent tempi, but when the audio is segmented into spectrogram e xcerpts with a fixed number of time steps, these contain disparate amounts of musical content, relati ve to what the model has seen during training. The tempo can also change within a single query , especially in live retrie val settings. W e propose applying an attention mechanism ( Olah & Carter , 2016 ; Chan et al. , 2016 ; Bahdanau et al. , 2014 ; Mnih et al. , 2014 ; Xu et al. , 2015 ; V aswani et al. , 2017 ; Southall et al. , 2017 ) over the audio input, to distinguish parts of the audio that are in fact useful for finding the corresponding sheet music snippets. The system can then adapt to tempo 1 Johannes K epler Univ ersity Linz, Austria 2 Charles Uni- versity , Czech Republic. Correspondence to: Matthias Dorfer < matthias.dorfer@jku.at > . F AIM W orkshop of the 35 th International Confer ence on Mac hine Learning , Stockholm, Sweden, PMLR 80, 2018. Copyright 2018 by the author(s). Figure 1. Audio–sheet music embedding space learning with soft- input-attention on the input audio. changes: both to lower and to higher densities of musical ev ents. Our experiments show that attention is indeed a promising way to obtain tempo-in variant embeddings for cross-modal retriev al. 2. A udio–Sheet Music Embedding Space Learning with Attention W e approach the cross-modal audio-sheet music retriev al problem by learning a low-dimensional multimodal embed- ding space (32 dimensions) for both snippets of sheet music and excerpts of music audio. W e desire for each modality a projection into a shared space where semantically similar items of the two modalities are projected close together , and dissimilar items far apart. Once the input modalities are em- bedded in such a space, cross-modal retriev al is performed using simple distance measures and nearest-neighbor search. W e train the embedding space using con volutional neural networks; Figure 1 sk etches the network architecture. The baseline model (without attention) consists of two con volu- tional pathways: one is responsible for embedding the sheet music, and the other for embedding the audio excerpt. The key part of the network is the canonically correlated em- bedding layer ( Dorfer et al. , 2018b ), which forces the two pathways to learn representations that can then be projected into a shared space (and finds these projections); the desired properties of this multimodal embedding space are enforced by training with pairwise ranking loss ( Kiros et al. , 2014 ). Attention as a Perspecti ve f or Learning T empo-in variant A udio Queries 168 Frames 168 Frames 168 Frames 168 Frames 168 Frames Figure 2. Audio queries (all 168 frames) and corresponding attention vectors of model BL + A T + LC . Note, that when the music gets slower (see right most e xample) and covers less onsets, the attention mechanisms starts to consider a larger temporal conte xt. This is the basic structure of the model recently described and ev aluated in ( Dorfer et al. , 2017 ). This attention-less model serves as a baseline in our e xperiments. As already mentioned, this model trains and operates on fixed-size input windo ws from both modalities. At runtime, the input audio (or sheet music) query therefore has to be broken do wn into excerpts of the gi ven size. When process- ing audio played in dif ferent tempi, the fixed-size excerpts contain significantly less (or more) musical content – esp. onsets – than excerpts that the model has been trained on. One may of course combat this with data augmentation, but a more general solution is to simply let the model read as much information from the input excerpt as it needs. W e explore using a soft attention mechanism for this pur- pose. First, we substantially increase the audio field of vie w (number of spectrogram frames), up to a factor of four . Next, we add to the model the attention pathway h , which is implemented as a softmax layer that outputs a weight a t for each input spectrogram frame in A . Before feeding the spectrogram to the audio embedding network g , we multiply each frame with its attention weight. This enables the model to cancel out irrelev ant parts of the query . 3. Experimental Evaluation and Discussion In our retriev al experiments, we use a dataset of classical piano music, MSMD ( Dorfer et al. , 2018a ). It contains 479 pieces of 53 composers, including Bach, Mozart, Beethov en and Chopin, totalling 1,129 pages of sheet music and 15+ hours of audio, with fine-grained cross-modal alignment be- tween note onsets and noteheads. The scores and audio are both synthesized based on LilyPond, b ut results in ( Dorfer et al. , 2018a ) suggest that the embedding models trained on this data do generalize to real scores and performances. Our e xperiments are carried out on aligned snippets of sheet music and spectrogram excerpts, as indicated in Figure 1 . Giv en an audio excerpt as a search query , we aim to re- trie ve (only) the corresponding snippet of sheet music of the respectiv e piece. As an experimental baseline, we use a model similar to the one presented in ( Dorfer et al. , 2017 ), which does not use attention (denoted as BL ). The second model we consider follows exactly the same architecture, b ut is additionally Model R@1 R@5 R@25 MRR MR BL 41.4 63.8 77.2 51.8 2 BL + A T 47.6 68.2 79.4 57.1 2 BL + A T + LC 55.5 77.1 85.8 65.1 1 T able 1. Comparison of retrieval results (10,000 candidates). equipped with the soft attention mechanism described above ( BL + AT ). The temporal context for both models is 84 frames ( ≈ 4 seconds), twice as much compared to ( Dorfer et al. , 2018a ). The third model is the same as BL + A T but is gi ven a lar ger temporal context (168 frames) for the audio spectrogram ( BL + A T + LC ). This should re veal if and how the model will learn to focus on the relev ant parts in the audio, depending on the musical content it is presented with. The sheet music snippet has the same dimensions ( 80 × 100 pixels) for all models, implying that the audio network has to adapt to this fixed condition. As ev aluation measures we compute the Recall@k (R@k) , the Mean Recipr ocal Rank (MRR) , as well as the Median Rank (MR, low is better) . T able 1 summarizes our results. The attention mechanism ( BL + A T ) impro ves the retriev al performance o ver the base- line consistently across all retriev al metrics. W ith increased temporal context of the attention model ( BL + AT + LC ) we achiev e another substantial jump in performance. T o in vestigate whether the attention mechanism behaves according to our intuition, we plot audio queries along with their attention weights in Figure 2 . Depending on the spec- trogram content, the model indeed attends to whatever it believ es is a representativ e counterpart of the target sheet music snippet. Since the fixed-size sheet snippets contain roughly similar amounts of notes, as the density of note- heads is independent on the tempo of the piece, attention is sharply peaked when the density of notes in the audio is high, and con versely it is distributed more e venly when there are fewer notes in the audio e xcerpt. Giv en the improved retrie val performance and the intuiti ve behavior of the model, we think this is a promising line of research for reducing the sensiti vity of cross-modal music retriev al models to the audio input windo w size. By exten- sion, this is a step to wards tempo-in variant representations, at least in the context of retrie val. Attention as a Perspecti ve f or Learning T empo-in variant A udio Queries Acknowledgements This research was supported in part by the European Re- search Council (ERC) under grant ERC-2014-AdG 670035 (ERC Advanced Grant, project ”Con Espressione”). Jan Haji ˇ c jr . wishes to ackno wledge support by the Czech Sci- ence Foundation grant no. P103/12/G084 and Charles Uni- versity Grant Agenc y grant no. 1444217. References Bahdanau, Dzmitry , Cho, Kyunghyun, and Bengio, Y oshua. Neural machine translation by jointly learning to align and translate. CoRR , abs/1409.0473, 2014. URL http: //arxiv.org/abs/1409.0473 . Chan, W illiam, Jaitly , Navdeep, Le, Quoc V ., and V inyals, Oriol. Listen, attend and spell: A neural network for lar ge vocab ulary conv ersational speech recognition. In 2016 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing, ICASSP 2016, Shanghai, China, Mar ch 20-25, 2016 , pp. 4960–4964. IEEE, 2016. doi: 10.1109/ICASSP .2016.7472621. URL https://doi. org/10.1109/ICASSP.2016.7472621 . Dorfer , Matthias, Arzt, Andreas, and W idmer , Gerhard. Learning audio-sheet music correspondences for score identification and offline alignment. In Proceedings of the 18th International Society for Music Information Re- trieval Confer ence (ISMIR) , pp. 115–122, Suzhou, China, 2017. Dorfer , Matthias, Haji ˇ c, Jan jr ., Arzt, Andreas, Frostel, Har- ald, and W idmer , Gerhard. Learning audio—sheet music correspondences for cross-modal retriev al and piece iden- tification. T ransactions of the International Society for Music Information Retrieval (In Press) , – 2018a. ISSN –. doi: - - . URL - - . Dorfer , Matthias, Schl ¨ uter , Jan, V all, Andreu, K orzeniowski, Filip, and W idmer , Gerhard. End-to-end cross-modality retriev al with cca projections and pairwise ranking loss. International Journal of Multimedia Information Re- trieval , 7(2):117–128, Jun 2018b. ISSN 2192-662X. doi: 10.1007/s13735- 018- 0151- 5. URL https:// doi.org/10.1007/s13735- 018- 0151- 5 . Kiros, Ryan, Salakhutdinov , Ruslan, and Zemel, Richard S. Unifying visual-semantic embeddings with multi- modal neural language models. arXiv preprint (arXiv:1411.2539) , 2014. Mnih, V olodymyr , Heess, Nicolas, Graves, Ale x, and Kavukcuoglu, Koray . Recurrent models of visual attention. In Ghahramani, Zoubin, W elling, Max, Cortes, Corinna, Lawrence, Neil D., and W einberger , Kilian Q. (eds.), Advances in Neural Information Pr ocessing Systems 27: Annual Confer ence on Neural Information Pr ocessing Systems 2014, December 8-13 2014, Montreal, Quebec, Canada , pp. 2204–2212, 2014. URL http://papers.nips.cc/paper/ 5542- recurrent- models- of- visual- attention . Olah, Chris and Carter , Shan. Attention and augmented recurrent neural networks. Distill , 2016. doi: 10.23915/ distill.00001. URL http://distill.pub/2016/ augmented- rnns . Southall, Carl, Stables, Ryan, and Hockman, Jason. Automatic drum transcription for polyphonic recordings using soft attention mechanisms and con volutional neural networks. In Cunningham, Sally Jo, Duan, Zhiyao, Hu, Xiao, and T urnbull, Douglas (eds.), Pr oceedings of the 18th International Society for Music Information Retrieval Confer ence, ISMIR 2017, Suzhou, China, October 23-27, 2017 , pp. 606–612, 2017. URL https: //ismir2017.smcnus.org/wp- content/ uploads/2017/10/146_Paper.pdf . V aswani, Ashish, Shazeer , Noam, Parmar , Niki, Uszk o- reit, Jakob, Jones, Llion, Gomez, Aidan N, Kaiser , Ł ukasz, and Polosukhin, Illia. Attention is all you need. In Guyon, I., Luxburg, U. V ., Bengio, S., W al- lach, H., Fergus, R., V ishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Pr ocessing Systems 30 , pp. 5998–6008. Curran Associates, Inc., 2017. URL http://papers.nips.cc/paper/ 7181- attention- is- all- you- need.pdf . Xu, Kelvin, Ba, Jimmy , Kiros, Ryan, Cho, K yunghyun, Courville, Aaron C., Salakhutdinov , Ruslan, Zemel, Richard S., and Bengio, Y oshua. Show , attend and tell: Neural image caption generation with visual attention. In Bach, Francis R. and Blei, David M. (eds.), Pr oceed- ings of the 32nd International Conference on Machine Learning, ICML 2015, Lille, F rance, 6-11 J uly 2015 , vol- ume 37 of JMLR W orkshop and Conference Pr oceedings , pp. 2048–2057. JMLR.org, 2015. URL http://jmlr. org/proceedings/papers/v37/xuc15.html .
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment