Frame-level speaker embeddings for text-independent speaker recognition and analysis of end-to-end model
In this paper, we propose a Convolutional Neural Network (CNN) based speaker recognition model for extracting robust speaker embeddings. The embedding can be extracted efficiently with linear activation in the embedding layer. To understand how the speaker recognition model operates with text-independent input, we modify the structure to extract frame-level speaker embeddings from each hidden layer. We feed utterances from the TIMIT dataset to the trained network and use several proxy tasks to study the networks ability to represent speech input and differentiate voice identity. We found that the networks are better at discriminating broad phonetic classes than individual phonemes. In particular, frame-level embeddings that belong to the same phonetic classes are similar (based on cosine distance) for the same speaker. The frame level representation also allows us to analyze the networks at the frame level, and has the potential for other analyses to improve speaker recognition.
💡 Research Summary
The paper presents a novel end‑to‑end speaker‑recognition system that extracts robust speaker embeddings using a one‑dimensional convolutional neural network (1‑D CNN) combined with a linear activation function. The authors first design a network architecture consisting of four 1‑D convolutional layers (with filter sizes that span the entire frequency axis) followed by two fully‑connected layers. After the statistics‑pooling layer traditionally used in x‑vector systems, they replace the non‑linear activation before the final fully‑connected layer with a linear mapping, thereby producing a 600‑dimensional embedding that is directly usable for downstream scoring.
Training is performed on the VoxCeleb1 development set (1,211 speakers, 147,935 utterances) with extensive data augmentation (reverberation, babble noise, music). The resulting embeddings are evaluated with both cosine similarity and PLDA back‑ends. When combined with PLDA, the proposed embeddings achieve an equal‑error‑rate (EER) of 5.3 % on the VoxCeleb1 test set, which is comparable to a strong i‑vector baseline (5.4 %) and superior to x‑vectors (6.0 % with augmentation) and a VGG‑based system (7.8 %). This demonstrates that the linear‑activation design does not sacrifice performance while simplifying the embedding space.
To investigate what the network actually learns, the authors modify the architecture to replace the statistics‑pooling layer with an average‑pooling layer placed just before the ReLU of the second fully‑connected layer. This change enables extraction of frame‑level representations from every hidden layer without affecting final verification performance. Using these frame‑level embeddings, two proxy tasks are conducted on the TIMIT corpus: (1) phoneme recognition and (2) broad‑class phonetic classification.
For phoneme recognition, a two‑layer LSTM‑based segmental model is trained on the frame‑level embeddings from each layer. Results show that lower layers (closer to the input) yield lower phoneme error rates (PER), whereas higher layers produce substantially higher PER (e.g., ~34 % at layer 6). This indicates that as depth increases, the network discards fine‑grained phonetic detail, suggesting that phoneme identity is not a primary factor for speaker discrimination in this model.
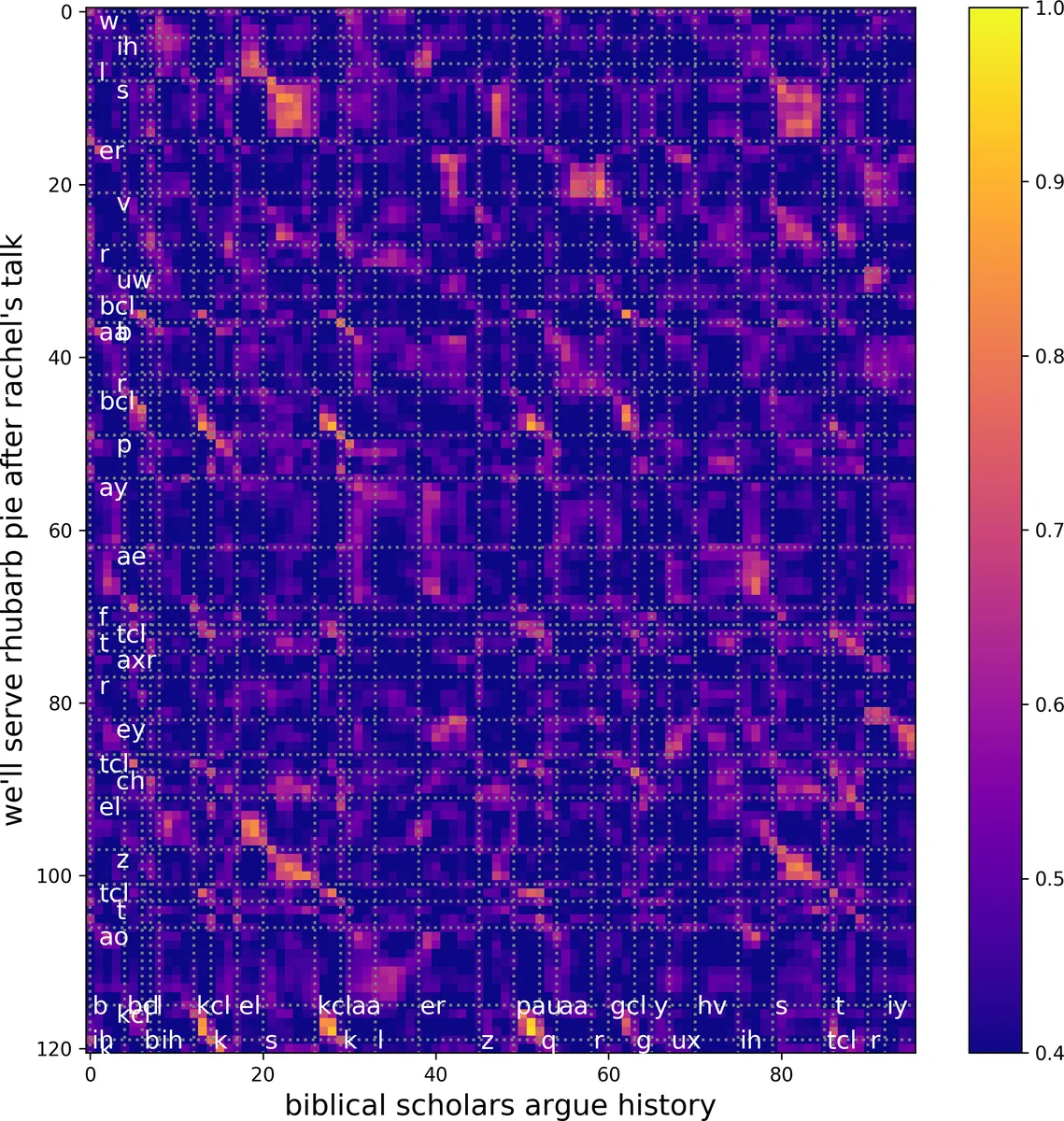
In the broad‑class classification experiment, the 39 TIMIT phonemes are grouped into seven coarse categories (vowels, stops, fricatives, affricates, nasals, semivowels/glides, and others). Segment embeddings are obtained by averaging the frame embeddings within each phoneme segment, and a simple cosine‑based nearest‑class classifier is applied. Over training epochs, the ability to separate these classes improves markedly, especially for higher layers. Confusion matrices reveal that while most classes become well separated, certain groups (e.g., affricates vs. fricatives, nasals vs. semivowels) remain partially confusable, implying that the network abstracts phonetic information into broader groups such as “obstruents” and “sonorants.” t‑SNE visualizations corroborate this trend, showing tighter clustering of the same broad class at deeper layers.
Further analysis of frame‑level cosine similarity between a speaker’s enrollment embedding and individual frames shows that frames belonging to the same phonetic class have higher similarity. Notably, high‑frequency vowels such as /iy/ and /ih/ exhibit the strongest similarity, whereas low‑frequency glide /w/ shows the weakest. Histogram comparisons between overall phoneme frequencies and the distribution of highest‑similarity phonemes confirm that vowels and nasals contribute most to speaker discrimination, aligning with prior linguistic findings.
The study yields several key insights: (1) removing non‑linearities before the final embedding layer simplifies the representation without degrading verification performance; (2) frame‑level embeddings provide a practical window into the internal representations of end‑to‑end speaker models; (3) in text‑independent speaker verification, the network relies more on broad phonetic class information than on exact phoneme identity, which explains robustness when enrollment and test utterances contain different lexical content; and (4) specific phonetic categories—especially vowels and nasals—are disproportionately important for distinguishing speakers.
Overall, the paper contributes both a competitive speaker‑embedding architecture and a methodological framework for probing the linguistic content encoded in deep speaker‑recognition networks. The findings can guide future work on data augmentation, loss‑function design, and multi‑task training aimed at further improving the robustness and interpretability of speaker verification systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment