OpenMP Loop Scheduling Revisited: Making a Case for More Schedules
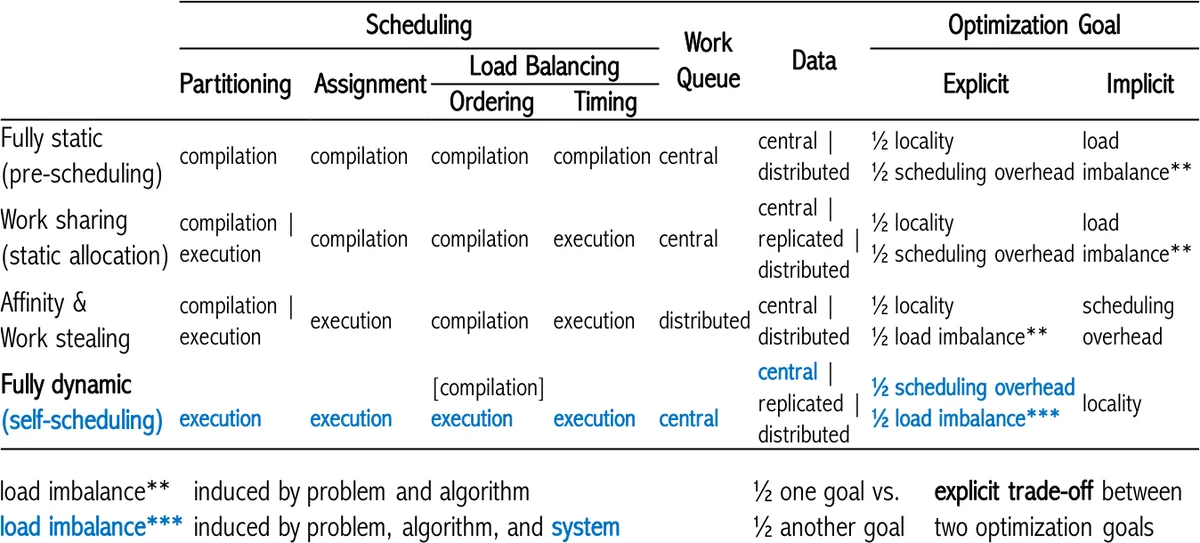
In light of continued advances in loop scheduling, this work revisits the OpenMP loop scheduling by outlining the current state of the art in loop scheduling and presenting evidence that the existing OpenMP schedules are insufficient for all combinations of applications, systems, and their characteristics. A review of the state of the art shows that due to the specifics of the parallel applications, the variety of computing platforms, and the numerous performance degradation factors, no single loop scheduling technique can be a ‘one-fits-all’ solution to effectively optimize the performance of all parallel applications in all situations. The impact of irregularity in computational workloads and hardware systems, including operating system noise, on the performance of parallel applications, results in performance loss and has often been neglected in loop scheduling research, in particular, the context of OpenMP schedules. Existing dynamic loop self-scheduling techniques, such as trapezoid self-scheduling, factoring, and weighted factoring, offer an unexplored potential to alleviate this degradation in OpenMP due to the fact that they explicitly target the minimization of load imbalance and scheduling overhead. Through theoretical and experimental evaluation, this work shows that these loop self-scheduling methods provide a benefit in the context of OpenMP. In conclusion, OpenMP must include more schedules to offer a broader performance coverage of applications executing on an increasing variety of heterogeneous shared memory computing platforms.
💡 Research Summary
The paper revisits loop scheduling in OpenMP, arguing that the three schedules currently defined in the OpenMP specification—static, dynamic, and guided—are insufficient to achieve optimal performance across the wide spectrum of modern applications and heterogeneous shared‑memory platforms. The authors first review the state of the art in loop scheduling, emphasizing that load imbalance, scheduling overhead, and system‑induced variability (e.g., OS noise, power capping, NUMA effects) are major sources of performance degradation that cannot be ignored. They demonstrate that no single scheduling technique can be a “one‑fits‑all” solution because the optimal choice depends on a complex interaction of loop‑level characteristics (iteration count, irregularity, data‑access patterns), algorithmic behavior, and hardware properties (core heterogeneity, memory hierarchy, runtime variability).
To address these shortcomings, the authors propose extending OpenMP with four dynamic loop self‑scheduling (DLS) techniques that have been studied extensively in the literature but are not part of the OpenMP runtime:
- Trapezoid Self‑Scheduling (TSS) – starts with large chunks and gradually reduces chunk size, aiming to keep scheduling overhead low while still adapting to load imbalance.
- Factoring (FAC2) – divides the iteration space into several phases; each phase halves the chunk size, which is effective for highly variable workloads.
- Weighted Factoring (WF2) – extends factoring by incorporating user‑provided weights that reflect heterogeneous core capabilities, allowing the runtime to allocate more work to faster cores.
- Random – selects chunk sizes uniformly at random within a bounded interval, which can mitigate the impact of unpredictable system noise.
The authors implemented these four DLS algorithms in the GNU OpenMP runtime library (libGOMP) and evaluated them on a 20‑thread Intel Broadwell system (10 × 2‑way cores). The benchmark suite includes classic OpenMP kernels as well as a real‑world molecular‑dynamics application, and the experiments explore different thread‑pinning strategies to expose the effect of hardware topology.
Key findings from the experimental study are:
- Static scheduling performs best only for uniformly distributed iterations; for irregular loops it can cause up to 30 % slowdown due to severe load imbalance.
- Dynamic and guided schedules improve performance over static in many cases but still leave considerable headroom.
- Adding any of the proposed DLS techniques yields additional speed‑ups ranging from 12 % to 25 % on average, depending on the benchmark and system conditions.
- WF2 shows the greatest benefit on heterogeneous cores, while Random is most robust when OS‑level noise dominates.
- No single schedule dominates across all experiments; the optimal schedule varies with workload irregularity, iteration count, and system variability.
Based on these results, the paper makes a strong case for standardizing the four DLS methods as optional OpenMP schedules (e.g., schedule(tss), schedule(fac2), schedule(wf2), schedule(random)). The authors also advocate for an adaptive runtime that can automatically profile a loop’s characteristics at start‑up and select the most appropriate schedule, possibly using machine‑learning models trained on prior runs.
Future research directions outlined include:
- Developing predictive models for schedule selection that consider both application‑level metrics and hardware counters.
- Extending DLS concepts to heterogeneous environments that combine CPUs with GPUs or other accelerators.
- Designing OS‑runtime interfaces that expose noise metrics to the scheduler, enabling more informed decisions.
In conclusion, the study demonstrates that the existing OpenMP loop schedules are not sufficient for the diverse and increasingly irregular workloads running on modern heterogeneous shared‑memory systems. By incorporating well‑studied dynamic self‑scheduling techniques, OpenMP can provide a broader performance envelope, reduce load imbalance, and better tolerate system‑induced variability, thereby remaining a relevant and high‑performance programming model for future architectures.
Comments & Academic Discussion
Loading comments...
Leave a Comment