Differentiable lower bound for expected BLEU score
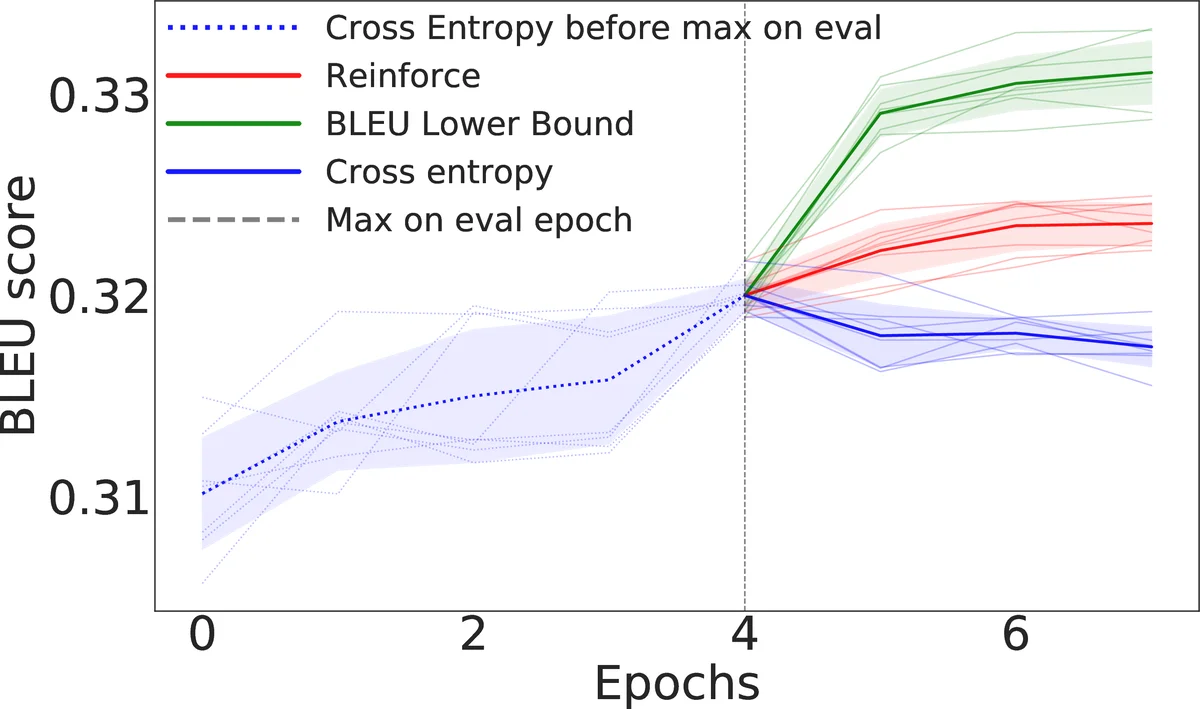
In natural language processing tasks performance of the models is often measured with some non-differentiable metric, such as BLEU score. To use efficient gradient-based methods for optimization, it is a common workaround to optimize some surrogate loss function. This approach is effective if optimization of such loss also results in improving target metric. The corresponding problem is referred to as loss-evaluation mismatch. In the present work we propose a method for calculation of differentiable lower bound of expected BLEU score that does not involve computationally expensive sampling procedure such as the one required when using REINFORCE rule from reinforcement learning (RL) framework.
💡 Research Summary
The paper addresses a fundamental problem in natural‑language‑processing (NLP) model training: the evaluation metric most commonly used for machine translation, BLEU, is non‑differentiable, which prevents direct gradient‑based optimization. The standard work‑arounds are (i) to train with a surrogate differentiable loss such as cross‑entropy, hoping that improvements in the surrogate correlate with BLEU, and (ii) to apply reinforcement‑learning (RL) techniques, most notably the REINFORCE estimator, to directly maximize the expected BLEU. While the RL approach is theoretically sound, it suffers from high variance gradient estimates, requires costly Monte‑Carlo sampling, and often needs elaborate variance‑reduction tricks to be practical.
The authors propose a third, more efficient alternative: a differentiable lower bound (LB) on the expected BLEU score that can be computed analytically from the model’s output probability distributions, thereby eliminating the need for sampling. Their derivation proceeds in two stages. First, they rewrite the BLEU computation in a fully matrix‑based form. Candidate and reference sentences are represented as one‑hot matrices x (size lenₓ × |V|) and y (size lenᵧ × |V|). For each n‑gram length n they construct binary matching matrices Sₙ and Pₙ that encode whether two n‑grams are identical. Using column‑wise sums of these matrices they obtain vectors vₓ,ₙ and vᵧ,ₙ that count how many times each n‑gram occurring at a particular position appears elsewhere in the candidate or reference. The standard BLEU precision pₙ = Oₙ / (lenₓ − n + 1) is then expressed as a ratio of differentiable sums, removing the discrete Count operation.
Second, they bound the expectation of BLEU over the stochastic output distribution pₓ. By applying Jensen’s inequality to the product of precisions and by linearising the min(·,·) operation that appears in the overlap computation, they derive a closed‑form lower bound for each overlap term Oₙ. For unigrams the bound takes the form
Eₓ
Comments & Academic Discussion
Loading comments...
Leave a Comment