Approximating the Void: Learning Stochastic Channel Models from Observation with Variational Generative Adversarial Networks
Channel modeling is a critical topic when considering designing, learning, or evaluating the performance of any communications system. Most prior work in designing or learning new modulation schemes has focused on using highly simplified analytic cha…
Authors: Timothy J. OShea, Tamoghna Roy, Nathan West
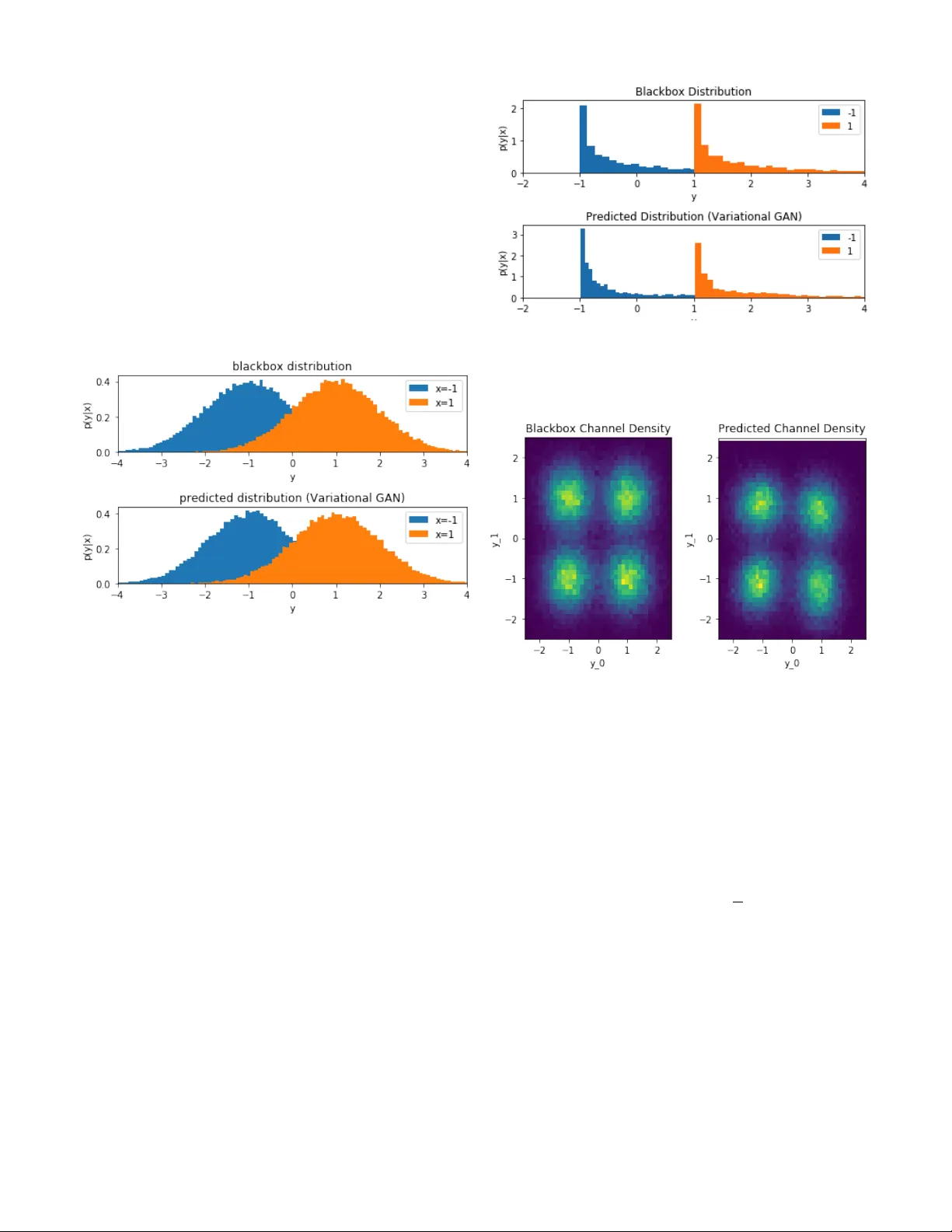
Approximating the V oid: Learning Stochastic Channel Models from Observ ation with V ariational Generati v e Adversarial Netw orks T imothy J. O’Shea DeepSig Inc & V irginia T ech Arlington, V A toshea@deepsig.io T amoghna Ro y DeepSig Inc., Arlington, V A troy@deepsig.io Nathan W est DeepSig Inc., Arlington, V A nwest@deepsig.io Abstract —Channel modeling is a critical topic when consid- ering designing, learning, or ev aluating the performance of any communications system. Most prior work in designing or learning new modulation schemes has f ocused on using highly simplified analytic channel models such as additive white Gaussian noise (A WGN), Rayleigh fading channels or similar . Recently , we proposed the usage of a generative adversarial networks (GANs) to jointly appr oximate a wireless channel r esponse model (e.g . from real black box measurements) and optimize f or an efficient modulation scheme o ver it using machine lear ning. This approach worked to some degree, b ut was unable to produce accurate pr ob- ability distribution functions (PDFs) repr esenting the stochastic channel response. In this paper , we f ocus specifically on the problem of accurately learning a channel PDF using a variational GAN, introducing an architecture and loss function which can accurately capture stochastic behavior . W e illustrate where our prior method failed and share results capturing the performance of such as system over a range of realistic channel distributions. Index T erms —machine learning; deep learning; neural net- works; autoencoders; generative adversarial networks; modula- tion; neural networks; software radio I . I N T RO D U C T I O N Recent work in machine learning based communications systems has sho wn that the autoencoder can be used very effecti vely to jointly design modulation schemes through parametric encoding and decoding networks under complex impairments while obtaining excellent performance [1] (basic architecture shown in Figure 1). This approach generally employs a parametric encoder network f ( s , θ f ) which encodes symbols s into a transmitted symbol x , a stochastic channel model y = h ( x ) , and a decoder g ( y , θ g ) which recov ers estimates for the transmitted symbols ˆ s from the receiv ed samples y . Both networks employ dense neural network style functions with weight and bias parameters θ f and θ g whose weight vectors may be optimized to learn many dif ferent non-linear mappings and function approximations. The major drawback of this work howe ver , is that it relies on ha ving a dif ferentiable channel model function ( ˆ y = h ( x ) ), so that the gradients can be computed during back-propagation while training the netw ork to minimize the reconstruction error rate (e.g. by directly computing the channel gradient ∂ h ( x ) ∂ x for use in the chain rule when computing the gradient of the loss with respect to the encoder network weights). W ithout a differentiable channel model, the best we can do is optimize only-the decoder portion of the network, giv en ground truth label information, as discussed in [2]. The simplest forms of such an analytic channel model include the additiv e white Gaussian noise (A WGN) channel, but can also include a wide range of ef fects such as device non-linearities, propagation effects, f ading, interference, or other distortions. Figure 1 contains a high level illustration of this training architecture. Since the channel model, h ( x ) is a stochastic function, it may also be represented as a conditional probability distribution p ( y | x ) , which more realistically approximates the random behavior of man y channel phenomena. Fig. 1: A channel autoencoder system for learning physical layer encoding schemes optimized for a stochastic channel model expression In many applications it may be desirable to optimize per- formance for specific ov er the air channel effects or scenarios which exhibit several combined channel effects (e.g. devices response, interference effects, distortion ef fects, noise ef fects). While simplified analytic models can be used in some cases to capture some of these effects, often real world non-linear effects and especially combinations of such effects are not well captured by these models simply due to their complexity and de grees of freedom which can be hard to capture in compact expressions. In this work we focus on a more model- free approach for approximating stochastic channel responses, allowing for high degrees of freedom, by using variational neural networks [3] in order to approximate the end-to- end responses based on real world measurement data. This approach is appealing in its degree of flexibility , accuracy , and the degree with which such a channel approximation network can be used to directly optimize the modulation and encoding methods for a corresponding communications system to attain excellent real world performance under a wide range of conditions, effects and constraints. T o accomplish this, we consider the task of jointly approx- imating the wireless channel response and a good encoding therefore using a generativ e adversarial network (GAN) [4] in our prior work [5]. Here, we leverage three neural networks, an encoder f ( s , θ f ) , a channel approximation h ( x , θ h ) , and a decoder g ( y , θ g ) . Each of these is comprised principally of fully connected (FC) rectified linear unit (ReLU) layers [6], where the transfer function for a single FC-RELU layer is shown below in equation 1. Here, the layer output values ® ` + 1 , are computed from the input values ® ` , weight vector ® w , bias vector ® b , while using a rectifier as a non-linearity . Where i denotes the layer index, k denotes the input index, and j denotes the output index. An equi valent FC layer without the RELU acti vation is used at the output of the encoder, and channel approximation layers as shown in equations 2. Each network’ s parameters θ then constitute the weight ® w and bias ® b v alues for each of the network’ s layers. ® ` i + 1 , j = m a x ( 0 , Õ k ® ` i , k ® w i , k + ® b i , j ) (1) ® ` i + 1 , j = Õ k ® ` i , k ® w i , k + ® b i , j (2) A variety of loss functions can be used to optimize these networks, in the prior work, mean squared error (MSE) was used to to perform regression of transmit and receiv ed sample values ( x and y ) to approximate the channel response, wherein network parameters are updated using stochastic gradient of the MSE loss function as shown in equation 3. ∇ θ h ( y − h ( x , θ h ) ) 2 (3) In this work, we in vestigate instead treating the channel network y = h ( x ) as a stochastic function approximation and replicate the resulting conditional probability distribution p ( y | x ) instead, which yields a significantly more appropriate tool for optimization, test, and measurement of communica- tions systems. I I . T E C H N I C A L A P P RO AC H Generativ e adversarial networks (GANs), introduced in [4] are a powerful class of generativ e models that consist of two or more competing objecti ve functions which help reinforce each other . T ypically this consists of a generator, which translates a latent space into a high dimensional sample which mimics some real data distributions, and a discriminator which attempts to classify samples as real or fake (i.e. produced by the generator network). By jointly/iterativ ely training these two networks, and by leveraging the backwards pass gradient of the discriminator to train the generator tow ards the "true" label, this approach has prov en to be extremely ef fective in producing synthetic generators which produce data samples indistinguishable from real dataset samples for a range of com- mon visual tasks. Numerous improv ements have been made to the approach since its introduction, including v ariational network features, training stability improvements, architecture enhancements and others further explored in [7]–[11]. Most of these works focus on computer vision applications of GANs, for instance for image generation. W e focus in contrast on the ability of variational-GANs to approximate robust probability distributions for the task of approximating accurate conditional channel distribution p ( y | x ) primarily for the purpose of training autoencoder based communications systems as described in section I. W e consider the channel approximation network ˆ y = h ( x , θ h ) to be a conditional probability distribution, p ( ˆ y | x ) and instead of minimizing L M S E ( y , ˆ y ) as before, we seek to minimize the distance between the conditional probability distributions p ( y | x ) and p ( ˆ y | x ) resulting from measurement and from the variational channel approximation network re- spectiv ely . This can be accomplished as in [4] by minimizing parameters of each network using the two stochastic gradients giv en below in equations 4 and 5 where we introduce a new discriminativ e network D ( x i , y , θ D ) to classify between real ( y ) and synthetic samples ( ˆ y ) from the channel given its input ( x ). In this case, h ( x , θ h ) takes the place of the generative network (often written as G ( z ) ), where x reflects conditional transmitted symbols/samples, and additional stochasticity in the function is introduced by variational layers. ∇ θ D 1 N N Õ i = 0 [ log ( D ( x i , y i , θ D ) ) + log ( 1 − D ( x i , h ( x i , θ h ) , θ D ) )] (4) ∇ θ h 1 N N Õ i = 0 log ( 1 − D ( x i , h ( x i , θ h ) , θ D ) ) (5) This optimization can also be performed using a W asserstein GAN [10] to improve training stability wherein updates can be made according to the stochastic gradient giv en in equations 6 and 7. ∇ θ D 1 N N Õ i = 0 [( D ( x i , y i , θ D ) ) − D ( x i , h ( x i , θ h ) , θ D ) ] (6) ∇ θ h 1 N N Õ i = 0 D ( x i , h ( x i , θ h ) , θ D ) (7) W ithin the channel approximation network, the variational sampler layer samples from a random distribution (the Gaus- sian distrib ution in this case) parameterized by the outputs of Layer Outputs Params in θ h FC-RELU 20 w 0 , b 0 FC-RELU 20 w 1 , b 1 FC-RELU 20 w 2 , b 2 FC-LIN 32 w 3 , b 3 Sampler 16 None FC-RELU 80 w 4 , b 4 FC-LIN 2 w 5 , b 5 T ABLE I: Channel Approximation Network, h ( x , θ h ) Layer Outputs Params in θ D FC-RELU 80 w 0 , b 0 FC-RELU 80 w 1 , b 1 FC-RELU 80 w 2 , b 2 FC-Sigmoid 1 w 3 , b 3 T ABLE II: Channel Discriminati ve Netw ork, D ( x , y , θ D ) the previous layer . The number of FC ReLU and Linear(LIN) layers is not-tuned in this case, but should be wide and deep enough to express the complexity of the topology required for the mapping. This may v ary for different applications and should be tuned as with any architecture or set of hyper- parameters for your application. Linear layers are used for regression of all real v alues for sampler parameters and for network output, the full architecture is shown in table I for the channel approximation network and in table II for the discriminativ e network. ® ` i + 1 , j = ® N ( µ = ® ` i , 2 j , σ = ® ` i , 2 j + 1 ) (8) Optimization of these networks is performed iterativ ely (e.g. one mini-batch of each, alternating between objectiv e functions and update parameter sets) and using the Adam [12] optimizer with a learning rate between 1e-4 and 5e-4. Fig. 2: High level training architecture for conditional- variational-GAN based learning of stochastic channel approx- imation function I I I . M E A S U R E M E N T S A N D R E S U LT S Considering one of the simplest canonical communications system formulations, we focus first on the case of a binary phase-shift keying (BPSK)-A WGN system where, p ( x ) is a discrete uniform (IID) random v ariable over all (2) possible symbol values (e.g. whitened information bits), in this case x ∈ { − 1 , + 1 } and p ( x ) = [ 0 . 5 , 0 . 5 ] . This encoding scheme, while fixed in this work, can easily be updated as an additional optimization network process using a channel autoencoder as described in [1], [5] over the learned stochastic channel approximation function. W e first consider the A WGN channel h ( x ) given by h ( x ) = x + N ( 0 , 1 . 0 ) . If we consider the direct approach to training a [non- stochastic] channel function approximation (e.g. no variational layer), using MSE less directly as expressed in equation 3, we obtain the two resulting distributions sho wn in figure 3. Here, the blackbox distribution results from measurement of the channel based on the ground truth stochastic process, while the predicted distribution reflects the expected behavior of the channel approximation network. Fig. 3: Learned distribution using direct MSE minimization W e can see here that the channel network approximation when trained with MSE loss rapidly con ver ges to the same mean values for each conditional input value. Unfortunately , we do not accurately learn an appropriate v ariance or full distribution to reflect the channel ef fects at all using this approach. Our conditional generator h ( x , θ h ) in this case is a deterministic function (not including the variational layer , but also when training the variational layer using only MSE loss). It can not accurately reflect this mapping from the discrete valued x distribution to real continuous distributions ov er y without the variational layer . T o this end, we instead consider the channel approximation function h ( x , θ h ) with the v ariational sampling layer, with the architecture shown in Figure 4, where a latent space z is sampled from latent distribution parameters θ z produced by the first FC/LIN layer within the hidden layers of the network. Fig. 4: V ariational architecture for the stochastic channel approximation network (conditional generator) In contrast, if we do include the variational layer, and con- sider the GAN based training approach (using cross-entropy loss and a discriminator network), we can obtain significantly better performance. Figure 5 illustrates the measured and approximated conditional distributions for the same channel when using this approach. W e see that the distrib utions match well in both mean and variance this time, closely resembling the appropriate BPSK-A WGN channel response which has been measured. In this way , we’ ve learned a model which can accurately reflect the stochastic channel behavior , and produce be used for training or tuning a communications system which closely matches the performance of the real world as far as the distribution p ( y | x ) is concerned, for instance reflecting a nearly identical signal-to-noise ratio in this case. Fig. 5: Learned distribution using v ariational GAN training The appeal of this approach howe ver , is its applicability beyond a simple A WGN channel to much more complex channel ef fects which are unconv entional, non-linear and hard-to-express in compact parametric analytic forms. W e can consider the case for instance of a similar BPSK style communications system, with an additi ve Chi-Squared channel distribution. Using the same variational GAN based approach for conditional PDF channel approximation, we can still rapidly con ver ge on a representati ve non-Gaussian distribution formed from the same channel approximation network. In this case, the 16 latent variables sampled from the learned latent parameter space are all Gaussian, but they combine to form an additive approximation for the non-Gaussian distribution. Measured and approximated conditional distributions from the black box channel model are sho wn in Figure 6. There is definitely some error present in the resulting distribution from this approximation, resulting in part from its representation as a mixture of Gaussian latent v ariables, but this can be alleviated by choosing dif ferent sampling distrib utions and by increasing the dimension size of the latent space (at the cost of increased model complexity). A. Scaling Dimensionality This approach can be readily scaled to higher dimensional channel responses, as well as complex cascades of stochastic Fig. 6: Learned 1D distributions of conditional density on non- Gaussian (Chi-Squared) channel ef fects using variational GAN training Fig. 7: Learned 2D distribution for 4-QAM using variational GAN training on A WGN data effects, jointly approximating the aggregate distribution with the network. W e expand the real-valued BPSK case to a canonical complex quadrature representation of symbols using in-phase and quadrature basis functions. Figure 8 illustrates a heat-map for the measured and approximated probability density functions ( p ( y | x ) ) for a QPSK system with a simple A WGN channel. In this plot, we marginalize ov er the condi- tional x and show simply p ( y ) = Í N i = 0 1 N p ( y | x i ) . While the channel in this case is still quite simple, we can see that the variational GAN has readily learned appropriate statistics for the distribution, which matches the measured distribution accurately . While there were simple examples, the real appeal of this approach is its ability to scale to new modulation types, new channel ef fects, accurate non-linear models, and new complex combinations of channel impairments which may be present in any giv en black box system or measurement campaign. T o illustrate this we include a final experiment with a higher degree of realism, modeling a 16-QAM system which includes Fig. 8: Learned 2D distrib utions of receiv ed 16-QAM con- stellation non-linear channel effects using variational GAN training A WGN ef fects as well as phase noise, phase offset, and non- linear AM/AM and AM/PM effects introduced by a hardware amplifier model. There are all impairments which are typically encountered in a wide range of devices and communications systems. Figure 8 illustrates as with the previous examples, the marginalized p ( x ) distribution for both the measured version of the receiv ed signal, and the approximated version of the distribution when learning a stochastic channel approximation model with our approach. In this case, we can see a number of interesting effects are learned, including each constellation point’ s distrib ution, circumferential elongation of these distri- butions due to phase noise at higher amplitudes, and generally a decent looking first order approximation of the distrib ution. The distribution is notably not perfect in this example, we can see some differences and errors in the estimation of the radial variance of these distributions, especially at higher am- plitudes. W e believ e this can be addressed through improved model training, for instance using the WGAN approach to improv e stability , along with the use of larger models with more degrees of freedom to facilitate accurate representation. Numerous additional architecture enhancements are possible, for instance ones that could take advantage of the polar nature of the representation, which may simplify the representation of some of the effects what are often modeled in polar terms more simply . Time v arying behaviors such as SNR variation, fading, etc can be easily extended from this model by adding temporal dependencies into the network for instance with series of channel samples, and RNN-style sequence modeling of density approximations in the model. I V . D I S C U S S I O N Channel modeling has always been a difficult b ut critical task within wireless communications systems. W ith accurate stochastic models of a wireless channel, we can design and optimize communications systems for them using both closed form analytic modeling approaches and higher more scalable machine learning based approaches such as the channel au- toencoder . By adopting a mostly model-free learning approach to channel modeling using deep learning and variational- GANs, we illustrate in this work that a range of different types of stochastic channel models can be learned accurately from measurement, without the introduction of many assumptions about the effects occurring, or the simplification to a paramet- ric model. This approach holds to potential then to accurately reflect a wide range of stochastic channel beha viors, provides a con venient, compact, and uniform way to represent them, allows for high rate sampling and simulation from these models, and lends itself to scaling such models to very high degrees of freedom. In doing so, we hope that this approach will scale well to systems with numerous hardware ef fects, hardware impairments, multiple-antennas, and any other sort of stochastic impairment which may be measured within a communications system. Such a model can then be readily paired with an autoencoder based approach and used either pre-trained, or during joint training to optimize communica- tions systems and ne w modulation types directly for many real world deployment scenarios in a highly generalizable way , with little specific manual optimization or specification needed. While analytic closed form parametric channel models and understanding of stochastic wireless impairments will always be important in modeling and thinking about wireless sys- tems, this basic approach to channel approximation offers an important tool in dealing with complexity and degrees of freedom. By making less assumptions and by more accurately modeling end-to-end system behavior in a comprehensi ve way , we belie ve this will lead to better models and better performance for an entire class of future wireless systems. Further more, by providing accurate stochastic dif ferentiable approximations of these complex aggregation of propaga- tion effects, we can readily optimize encoding and decoding schemes on both ends of a link (using backpropagation) to achiev e near optimal performance metrics. This is one the collection of methods DeepSig is lev eraging in order to train, validate, and adapt their prototype next generation learned physical layer communications systems for specific channels in ov er the air and unique deployment configurations. Such over the air , data-centric learning methods in com- munications systems stand to become increasingly important in the future as as multi-antenna and multi-user and many device systems continue to increase in complexity and plurality of possible configurations and deployment scenarios, each benefiting from a slightly different tailored set of physical layer adaptations. While many enhancements may exist for this approach in terms of improving GAN stability and per- formance, this work illustrates that such an approach can, even with relativ ely simple variational GANs, obtain reasonably accurate channel approximation performance for common wireless channel models and effects. Significantly more work remains to be done in this field R E F E R E N C E S [1] T . J. O’Shea and J. Hoydis, “An introduction to deep learning for the physical layer, ” IEEE T ransactions on Cognitive Communications and Networking , vol. PP, no. 99, pp. 1–1, 2017. D O I : 10 . 1109 / TCCN . 2017 . 2758370. [2] S. Dörner, S. Cammerer , J. Hoydis, and S. ten Brink, “Deep learning-based communication o ver the air, ” IEEE Journal of Selected T opics in Signal Pr ocessing , 2017. [3] D. P . Kingma and M. W elling, “Auto-encoding varia- tional bayes, ” ArXiv preprint , 2013. [4] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde-Farle y, S. Ozair, A. Courville, and Y . Bengio, “Generativ e adversarial nets, ” in Advances in neural information pr ocessing systems , 2014, pp. 2672–2680. [5] T . J. O’Shea, T . Roy, N. W est, and B. C. Hilburn, “Physical layer communications system design over - the-air using adversarial networks, ” ArXiv pr eprint arXiv:1803.03145 , 2018. [6] V . Nair and G. E. Hinton, “Rectified linear units im- prov e restricted boltzmann machines, ” in Pr oceedings of the 27th international conference on machine learning (ICML-10) , 2010, pp. 807–814. [7] A. Sriv astava, L. V alk oz, C. Russell, M. U. Gut- mann, and C. Sutton, “V eegan: Reducing mode col- lapse in gans using implicit variational learning, ” in Advances in Neural Information Processing Systems , 2017, pp. 3310–3320. [8] M. Mirza and S. Osindero, “Conditional generati ve ad- versarial nets, ” CoRR , vol. abs/1411.1784, 2014. arXiv: 1411 . 1784. [Online]. A vailable: http : / / arxi v . org / abs / 1411.1784. [9] A. Radford, L. Metz, and S. Chintala, “Unsupervised representation learning with deep con v olutional genera- tiv e adversarial networks, ” CoRR , v ol. abs/1511.06434, 2015. arXi v: 1511 . 06434. [Online]. A vailable: http : / / arxiv .org/abs/1511.06434. [10] M. Arjovsk y, S. Chintala, and L. Bottou, “Wasserstein gan, ” ArXiv preprint , 2017. [11] X. Chen, Y . Duan, R. Houthooft, J. Schulman, I. Sutske ver, and P . Abbeel, “Infogan: Interpretable rep- resentation learning by information maximizing genera- tiv e adversarial nets, ” CoRR , vol. abs/1606.03657, 2016. arXiv: 1606.03657. [Online]. A vailable: http://arxiv .org/ abs/1606.03657. [12] D. P . Kingma and J. Ba, “Adam: A method for stochas- tic optimization, ” ArXiv pr eprint arXiv:1412.6980 , 2014.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment