Collapsed speech segment detection and suppression for WaveNet vocoder
In this paper, we propose a technique to alleviate the quality degradation caused by collapsed speech segments sometimes generated by the WaveNet vocoder. The effectiveness of the WaveNet vocoder for generating natural speech from acoustic features h…
Authors: Yi-Chiao Wu, Kazuhiro Kobayashi, Tomoki Hayashi
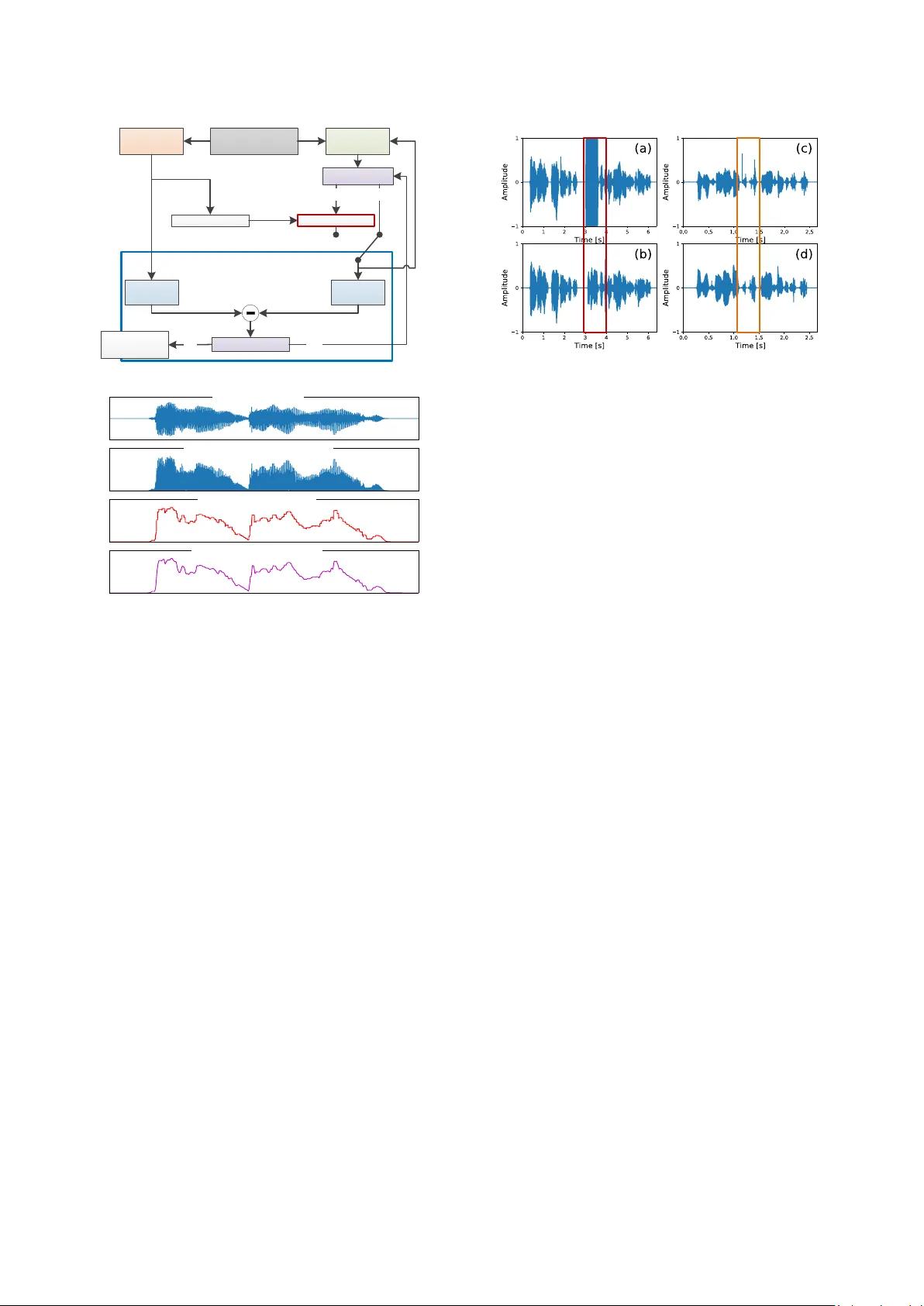
Collapsed speech se gment detection and suppr ession for W aveNet vocode r Yi -Chiao Wu 1 , Kazuhiro Kobayashi 2 , Tomoki Hayashi 3 , Patrick Lumban Tobing 1 , Tomoki Toda 2 1 Graduate School of Informatics, Nag oya University, Japan 2 I nformation Technology Center, Nagoya University, Japan 3 Graduate School of Information Scienc e, Nagoya University, Japan yichiao.wu@g.sp.m.is.nagoya - u.c.jp, tomoki@icts.nagoya -u.c.jp Abstract In this paper, we propose a technique to alleviate the quality degradation caused by collapsed speech segme nts so metimes generated by th e WaveNet vocoder. The effectiveness of the WaveNet vocoder f or ge nerating natural speech f rom acoustic features has been pro ved in recent works. However, it sometimes generates very n oisy speec h with collapsed speec h segments when only a lim ited amount o f training d ata is available or significant acoustic mismatches exist bet ween the training and testing data. Such a limitation on the corpus and limited ability of the model can easily occur in some speech generation applications, such as voice conversion and speech enhancement. T o address this pr oblem, we propose a technique to automatically detect collapsed speech segme nts. Moreover, to refine th e detected segments, we also p ropose a waveform generation technique for Wav eNet using a linear predictive coding constraint. Verifica tion and subjective tests are conducted to investiga te the effective ness of the proposed techniques. The verification results indicate that the detection technique can d etect most collapsed segments. The sub jective evaluations of v oice conversion demonstrate th at th e generation technique significantly improves the speech qu ality while maintaining the same speaker similarity . Index Terms : speech generation, WaveNet, vocoder, lin ear predictive co ding, collapsed spee ch detection, voice co nversion 1. Introduction In recent years, several w o rks have focus ed o n speech synthesis using deep n eural networks (DNN s) [1 - 8] . One o f the state- of - the-art techniques is Wave Net [8], which is an autoregressive model for predicting th e probab ility distribution of a current waveform sample based on a s p ecific number of previous samples. Because of the d ata-driven characteristic of WaveNet, it directly generates raw audio sam ples without various assumptions based on prior kn owledge specific to audio (e.g., source-filter modeling for norm al sp eech). Moreover, Wav eNet has been applied to ma ny applications, such as speech enhancement [9, 10 ], text- to -speech (TT S) sy nthesis [3, 5], singing voice synthesis [11], and speech coding [ 12]. In this paper, we focus on the use of W aveNet as a vocoder [13-16] to replace con ventional vocoders (e.g., WORLD [17, 18]), which are usually developed on the b asis of the source-filter model and cause significant degradation in the naturalness of speech. In [ 13 - 16 ] , th e effectiveness o f t he WaveNet vocoder for generating natural speech with acou stic spectral and prosodic features as auxiliary features was demonstrated. However, in [14, 19, 20], we found that the samples g enerated from the WaveNet vocoder som eti mes become unstable. This instability causes the amplitudes of some generated speech segments to suddenly b ecome extremely lar ge and contain alm ost equal intensity at all frequencies, similarly to white no ise. Consequently, the resulting speec h sam p le has significantly degraded naturalness. One possible rea son for this problem is the difference in th e acoustic features used for training and decoding. Specifically , this problem has been observed in our proposed voice conversion (VC) system [14, 19, 20] with the WaveNet vocoder, which is a technique to con vert the speaker identity of sp eech whil e maintaining the same linguis tic contents . In the proposed VC system , the acoustic features of the source sp eaker are con verted into those of the target speaker using a statistical ma pping functio n separate from the WaveNet vocoder. There fore, instead of directly generating a waveform based on the acoustic features o f n atural speech, the WaveNet vocoder generate samples with the converted acoustic features, and these less accurately predicted acoustic f eatures easily cause th e collap sed speech pro blem . Moreover, because o f the limited source-target p arallel corpus, it is still difficult to directly train the WaveNet vocoder using converted acoustic features . A straightforward wa y to tackle th e collapsed speech problem is to constrain the predicted probability distribution by using an other probability distribu tion derived from linear predictive coding (L PC) coefficients [19, 20] to prevent WaveNet from generating extremely discontin u ous or non- speech-like samples. However, this LP C constraint also introduces an over-smoothin g effect in to the generated speech because the LPC coefficients are estimated from over-s moothed converted acoustic features. Therefore, in [19, 2 0], we proposed a system selection framework with collapsed speech detectio n based on an utterance-based power difference. The framework only selected th e u tterances generated w ith the LPC constraint when the utterances generated from the original WaveNet vocoder suffered from collapsed speech . In th is paper, we propose an improved segment-based collapsed speech detector that is based on envelope detection [21] and can detect more collapsed types th an the p revious method. In th is method, c ollapsed seg ments are first detected, and an LPC-based co nstraint f o r W aveNet vocoder is only applied to th e collapsed segments. Therefore, we can restrict the over-smoothing effect only in a short time slot, which avoids the quality degradation caused by o ver-smoothing . Verification and subjective tests are conducted to evaluate the detection performance of th e propo sed detectors, and the speech q uality and similarity of the proposed system, respective ly. 2. WaveNet vocoder WaveNet [8 ] is a deep autoregressive network capable of directly modeling a speech waveform sample- by -sample using the following conditional probability: 1 1 | | , ..., , N n n r n n P P y y y Y h h , (1) where n is the sample in dex, r is the size of the receptive field (a specific number of previous samples), y n is the current audio sample, and h is the vector of the auxiliary features. In our system, h consists of the coded aperiodicity ( ap ) , the transformed F 0 , and the converted spectral features ( mcep ). Figure 1 shows the structure of the WaveNet vocoder, which co nsists of man y residual blocks, each containing a 2 1 dilated causal convolution, a gated activation function, and two 1 1 convolutions. The dilated causal convolu tion is a skipping value filter, which enables the network to efficiently operate on a larg e rece ptive field. The g ated ac tivation function is formulated as 1 2 1 2 , , , , ta nh f k f k g k g k aa V Y V h V Y V h , (2) where 1 V and 2 V are trainable convolution filters, is the convolution operator, is an elementwise multiplication operator, is a sigmoid function, k is the layer index, f and g represent the “f ilter” and “g ate”, respectiv ely, and a is the resolution adjustment function used to duplicate auxiliary features to match the resolution of input speech samples. T he input wavefo rm is quantized to 8 bits on the basis of µ -law encoding and the generated wa veform is restored by µ -law decoding. 3. Segment-based collapsed speech detection and suppression For collapsed speech d etection, th e main con cept of the proposed method is t hat even withou t listening to a u dio samples, people still can easily detect coll apsed speech segments from the waveform shape. Fu rthermore, in accordance with the obs ervation in our previous work [19], the quality of WaveNe t- vocoder-generated speech is usually higher than that of speech generated from the WORLD vocoder, but the WaveNet vocoder is more sensitive to less ac curately converted acoustic features. Moreover, although the perceptual qu alities are different, the waveform env elopes and powers of the utt erances generated by these vocoders are similar except for the coll apsed speech segments. As a result, f or the same a coustic features, it is reasonable to take the utterance generated from the WORLD vocoder as the reference to evaluate whether or n ot the utterance generated from the WaveNet vocoder contain s collapsed speech segments . Mo reover, owing to the similar waveform characteristics, the LPC coefficients extracted from the WORLD-generated u tterances are also used to design a constraint f or t he WaveNet v ocoder t o avoid generating collapsed speech segments. Figure 2 shows the procedure of the proposed system . After obtaining the acoustic features converted from the V C m odel, the propo sed system uses the WORLD vocoder to synthesize the reference speech. Then, the reference en velope and LPC coefficients are extracted from the reference speech. As shown in Figure 2 , eve ry ti me th e W aveNet vocoder genera tes audio samples with a predefined length, the system extracts the envelope of the n on-overlapping spee ch segment a nd compares it with the correspon ding reference envelope segment to check whether the segment co ntains coll apsed speech. If collapsed speech is detected, the sy stem re g enerates th e collapsed segment with the LPC-constrained WaveNet vocoder. 3.1. Speech waveform extraction Because we must extract the envelope during the wav eform generation procedure, a method with a low co mputation al co st is requ ired. In [21], Ja rne proposed a heuristic app roach to obtain a signal envelope that contains th ree simple steps. As shown in Figure 3 , the first step is to take the absolute value of the signal. In the second ste p, the abso lute signal is divided i nto several non -overlapping slo ts with a predefined window length, and then peak detection is performed by r eplacing all the values in each signal slot with the maximum value of th at signal slot. Finally, the peak detection result s are processed with a low-pass filter. In our system, we m odify the f ramework by replacing the taking of the absolute value with Hilbert transf orm, because the experimental results, which will be presented in Section 4, show better collapsed speech d etection p erformance with this modification. Furthermore, after obtaining the e nvelopes of the WaveNet- and WR OL D-generated speech segme nts, if the differen ce between these envelopes exceeds an empirical threshold, collapsed speech is detected. 3.2. LPC-constrained WaveNet vocoder The main concept of LPC is that the current signal sample can be a linear combination of previous sig nal samples. That is, the LPC coefficients describe the relationship between the current sample and past sam ples , and we can app ly the relationship to the p robability distribution p redicted from th e WaveNet vocoder to avoid generating extremely non-speech-like samples. Specifically, in the L P C-constrained WaveNe t vocoder, the equation used to constrain the predicted probability distribution of the current speech sam p le is Skip connection Time resolution adjustment Residual block Auxiliary feature 1 mcep 1× 1 1× 1 Residual block Residual block 1× 1 1× 1 Residual block Residual block ... ap F 0 mcep ap F 0 mcep ap F 0 ... mcep ap F 0 mcep ap F 0 mcep ap F 0 ... ... Auxiliary feature T ... ... ... ... 1× 1 1× 1 2× 1 dilated Gated Next residual block Relu 1× 1 Softmax Relu 1× 1 Previous residual block Causl Output Auxiliary feature t Skip connection Input Figure 1: Conditional WaveNet vocoder architecture 1 | ,..., , , n n r n P y y y h 11 | ,... , , | ,..., , n n r n n n I n P y y y P y y y h , (3) where 1 | ,..., , n n r n P y y y h is the conditional p robability fr o m WaveNet given the vector of auxiliary features h , is a control factor, and 1 | , .. ., , n n I n P y y y is the p robability mask from the LP C constraint , which is a probability mass function approximating a Gaussian d istribution with mean lpc and variance lp c . The mean lpc is the product of the past I samples generated from the WaveNet vocod er with the corresponding LPC coefficients extracted from the reference samples generated from the WORLD vocoder. The variance lp c is th e variance o f the LPC prediction errors, which are extracted from the co rresponding frame of the WORLD- generated sample. Fu rtherm ore, to simulate the disto rtion from µ -law coding, the WORLD-generated samples are pro cessed by µ -law encoding and d ecoding before extracting the LP C coefficient. Note that we may also d irectly calculate the Gaussian distribution f ro m the mel -cepstrum (auxiliary features for the WaveNet vocoder) by using th e MLSA filter without generating the refere nce speech using the WORLD vocoder. 4. Experiments 4.1. Experimental settings We conducted o bjective and subjective tests on the SP OKE task corpus of Voice Conversion C hallenge 2 018 (VCC2018) [22] , which was an English speech corpus . The SPOKE corpus included four source speakers and another four targ et speakers . Each speak er had 81 training utterances and 35 testing utterances, and the contents of the source and target utterances we re non-p arallel. Therefore, the to tal number of sou rce-target pairs in the SPOKE task w as 16, which included four fema le to female (F-F) pairs, four fe male to male (F-M) pairs, four ma le to female (M-F) pairs, and four male to m ale (M-M) pairs. The sampling ra te of the spe ech signals was set to 2 2050 Hz and the quantization bit number was 16 bits. We e valuated the perfo rmance of the proposed fram e work combined with our previous non -parallel VC system [ 19 ] , which was a DNN-based two- stage VC system, and we generated th e waveform u sing th e WaveNet vocoder. Moreover, the hyperparameters and training procedures of the DNN and WaveNet models and the signal an alysis settings also followed those in the previous work. Specifically, a noise-shaping technique [16] was also applied to the WaveNet vocoder. During the waveform generation stag e, the LPC control factor was initially set as 0.01, and if the regenerated speech segment still contained collapsed speech , the system in creased to 0.1 and 1. The length of the collapsed speech detection segment was set as 4 000 samples, th e length o f the peak detection window was set a s 2 00 samples, an d the cutoff frequency of the low-pass f ilter in the envelope detection was set as 300 Hz, all these setting were decided empirically. 4.2. Evaluation of collapsed speech detection We considered collapsed speec h detection as a ve rification problem, so the performance of the d etector was m easured by false accept (collapsed utterances not being d etected) rates and false reject (normal utterances being detected) rates. In addition, as shown in Figure 4, there we re two types of collapsed speech, one ha d an e xtremely lar ge power at all frequencies similarly to white noise ( type-I ), and the other one ha d irregular impulses o ver a very sh ort time ( type- II ). Therefore, we evaluated the performances of d etectors for both types on the basis of the following criterions: • ENV_/wNS_/HT : The diffe rence in the envelopes of the WaveNet- and WORLD-generated segments before/after noise shaping (NS) with/without Hilbert transform (HT). • ma xM CD : The maximum difference in the mel-cepstral distortions of the WaveNet- and WORLD-generated utterances to the converted mel-cepstral features. Converted acoustic features Envelope detection Envelope detection Generating next segment LPC extraction LPC constraint WaveNet vocoder WORLD vocoder Collapsed speech detection Regeneration > Threshold No Yes No Yes Figure 2: Flowchart of the proposed system Step1: taking absolute value Step2: peak detection Step3: low-pass filtering Waveform signal Figure 3: Th ree steps of envelope detection Figure 4: (a) WaveNet-generated samples with type-I collapsed speech and (b) reference WORLD samples. (c ) WaveNet-generated samples with type- II collapsed speech and (d ) reference WORLD samples. Type 1 Type2 • ma xPOW : The difference in the maxim um po wers of the WaveNet- and WORLD-generated utterances. For the evaluation dataset, a hum an subject labeled a ll the converted utterances generated by the WaveNet vocoder. The total number of converted utterances wa s 560, and 46 and 276 converted utterances we re labeled as type-I and type- II collapsed utteran ces , respectively. Figures 5 and 6 show the detection error tradeoff (DET) curves of these detectors. We found that the proposed methods ( ENV* ) ou tperform maxPOW and ma xMCD f or b oth types of collapsed speech, particularly for th e type- II speech. The se results in dicate that maxPOW can only d etect the type-I collapsed spee ch, b ut t he proposed method can d etect both ty pes. Moreover, replacing the absolu te value with Hilbert transform improves th e v erification perform ance for type-I and achieves the similar perfor mance for type- II . Additionally, the verification perform ances are similar for envelop e detection before and af ter noise s haping. The refore, we used the criteri on based on envelope detection with Hilbert transform to detect the envelope of speech sam ples processed by noise shaping. 4.3. Subjective evaluation The goal of the proposed framew ork is to generate samples without collapsed speech se gme nts while maintaining the sam e speaker similarity as the original WaveNet vocoder. Theref ore, we con ducted a preference t est to compare the quality of the waveforms genera ted from the WaveNet vocoder with and without the proposed f ramework. We also conducted similarity tests to evaluate the sp eaker identity conversion accuracy , in which listeners were given converted and target utt erances and asked to select an answer from “definitely the sa me speak er ”, “probably the same speaker ”, “probably a different speaker ” and “definitely a di fferent speaker ”. The final si milarity scores were the sum of the percentages of “definitely th e sa me sp eaker ” and “probably the same speaker ”. For the evaluation data, we simultaneously g enerated waveforms with and withou t the use of the pro posed collapsed speech d etection and reduction fra mework, so when a c ollapsed speech se gment w as detected, the s ystem outputted reg enerated and n on-regenerated speech sa mples. The total number of converted utterances was 560 , 377 of which w ere detected containing collapsed segments based o n the threshold chosen from th e eq ual-error-rate point in Figure 6 . Ho weve r, because of the equal error rate of about 20% and the unoptimized threshold, the d etection rate wa s much higher than that obtaining by human labeling. In the f uture, we can improve the detection p erformance by tuning th e th reshold. We rando mly selected five utterance pairs f or each speaker pair from the utterances in which collapsed segments was detected as th e evaluation data in the quality test, and we randomly select ed two utterance pairs for each speaker pair from the five selected pairs o f utterances as the testing data in the similarity test. Therefore, the q uality test con tained 80 regenerated and 80 non- regenerated utterances, and th e similarity test in cluded 32 regenerated, 32 non-regenerated, and 32 natural target speech utterances. The number of subjective listeners was nine. As show n in Table 1, the s u bjective results indicate that the proposed regeneration framework achieves a significant improvement in speech quality while main taining similar speaker conversion accuracy. Specifically, the results prove that humans can be aware o f collapsed speech segments and prefer regenerated samples without o r with fewer collap sed speech segments . Furth ermore, because we conducted the similarity test o n converted and target utt erance s with the same con tents, it made hu mans easil y detect the similarity degradation caused by lo wer spee ch quality. Therefore, the similarity scores are much lower than the results of VCC2018, which were conducted on the utterances with different contents. 5. Conclusions In this paper, we pro posed a framework to d etect collap sed speech segments and then regenerate the waveform with the LPC-constrained WaveNet vocoder to avoid the problem of collapsed sp eech. The propo sed method achieved a h igh collapsed speech detection error rate and a 77 % pref erence in a subjective qu ality test while maintaining th e same speaker similarity as that of the original WaveNe t vocoder. 6. Acknowledgements This work was partly sup ported by JST, PRESTO Grant Number JPMJPR1657, and JSPS KAKENHI Grant Number JP17H06101. Figure 5: DET curve for type-I detection Figure 6: DET curve for type- II detection Table 1: Subjective results and p-values of the WaveNet vocoder with the proposed method (w/ CL) and without the proposed method (w/o CL) w/ CL w/o CL p -value speech quality 77% 23% 1.091e-7 speaker similarity 46% 48% 0.813 definitely the same 11% 10% 0.810 probably the same 35% 38% 0.667 probably different 34% 33% 0.752 definitely different 20% 19% 0.963 7. References [1] S. O. Arik, M. Chrzanow ski, A. C oates, G. Diamos, A. Gibiansky, Y. Kang, X. Li, J. Mill er, J. Raiman, S. Sengupta, and M. Shoey bi , “ Deep Voice: Re al-time neural tex t- to - speech,” Proc. ICML , 2017. [2] S. O. Arik, G . Diamos, A. G i biansky , J. Miller, K . Pe ng, W . Ping, J. Raiman, and Y. Zho u, “Deep V oice 2 : Multi-speaker neural text- to -s peech,” Proc. NIPS , 2 017. [3] W. Ping, K . Peng, A. Gibiansky, S. O. Arik, A . Kannan and S. Narang , “De ep V oice 3: 2000-speaker neural tex t- to - spee ch,” Proc. IC LR , 2018. [4] Y. Wang, R . Skerry-Ryan, D. Stanton, Y. Wu, R. J. We iss, N. Jaitly, Z. Yang, Y. Xiao, Z. Chen, S. Bengio, Q. Le, Y. Agiomyrg iannakis, R. Clark, and R. A. Sau rous, “Tacotron: Towards e nd- to - end speech synthesis,” Proc. Inters peech , 2017. [5] J. Shen, R. Pang, R. J. Weiss, M. Schuster, N. Jaitly, Z. Yang, Z. Chen, Y. Zhang, Y. Wang, R. S. Ryan, R. A. Saurous, Y. Agiomyrg iannakis, and Y. Wu, “Natural TTS s ynthe sis by conditioning WaveNe t on M el spectrogr am p redictio ns,” Proc. ICASSP , 2018. [6] J. Sotelo, S. Mehri, K . K umar, J. F. Santosy , K. Kastner, A. Courville z, and Y. Bengio, “ Char2wav: E nd - to -end speech synthesis, ” Proc. ICLR , 2017. [7] S. Mehri, K . Kumar, I . Gulrajani, R. K umar, S. Jain, J. Sotelo , A. Courville and Y. Bengio , “ SampleRNN : An unconditional end- to -end neural audio gener ation model ,” Proc. ICLR , 201 7. [8] A. v an den Oor d, S. D i ele man, H. Ze n, K. Simonyan, O . Viny als, A. Graves, N. Kalchbrenner, A. Sen ior, and K. Kavukcuogl u, “WaveNe t: A generative model for raw audio,” CoRR abs/1609.034 99 , 2016. [9] K. Qia n, Y. Zhang, S. Chang, X. Yang, D. Florencio, and M. H. Johnson, “Spe e ch enhanceme nt using Bayesian WaveN et , ” Proc. Interspeech , 2017 . [10] D. Re thage, J. Pons, and X. Se rra, “ A WaveNet for speech denoising ,” arXi v preprint arXi v: 1706.07162 , 2017. [11] M. B laauw , J. Bonada, “A neural pa rame tric sining synthesizer,” https://arxiv.org /abs/1704.0380 9, 2017. [12] W. Bastiaan Kleijn, F elicia S. C. Lim, Alejandro Luebs, Jan Skoglund, Florian Stimberg, Q uan Wang, and T. C . W a lters, “WaveNe t based low rate speech coding,” Proc. IC ASSP , 2018. [13] A. Tamamori, T . Hayashi, K. Kobayashi, K. Takeda, and T. T oda, “Speaker -de pend ent WaveNet vocoder,” Proc. Interspeech , pp. 1118 – 1122, 20 17. [14] K. K obayashi, T . Hay a shi, A. Tamamo ri, and T. Toda, “Statistical voice conve rsion w it h W aveNe t- based wave form ge neration,” Proc. Interspeec h , pp. 1138 – 1142, 2 017. [15] T. Hayashi, A. Tamamori, K. Kobayashi, K. T a keda, and T. Toda, “An investigation of multi - speake r t raini ng for WaveNe t vocoder,” Proc. ASRU , 2017. [16] K. Tachibana, T. Toda, Y. Shiga, and H. Kawai, “An investigation of noise shaping with perceptual weighting for WaveNet-based speech gener at ion,” Proc. ICAS SP , 2018. [17] M. Morise, F. Yoko mori, and K. Ozawa, “WORLD: a vocoder - based high-quality speech synthesis system for real-time applications,” IEICE Trans. I n f. Sys t. , v ol. E99-D, no. 7, pp. 1877 – 1884, 20 16. [18] M. Morise, “D4C, a band -aperiodicity estimator for high-quality speech synthesis,” Speech Commun. , vol. 8 4, pp. 57 – 65, Nov. 2016. [19] Y. C. Wu, P. Lumban Tobing, T. Hayashi, K. Kobay ashi, and T. Toda , “ The NU non-parallel voice conve rsion sy stem for the Voice Conver sion Challeng e 2018 ,” Proc. Odyssey , 2 018. [20] P. Lumban Tobing, Y. C. Wu, T. Hayashi, K. Kobay ashi, and T. Toda , “ The NU voice conversion system for th e Voice Conversion Chal lenge 2018 ,” Proc. Odyssey , 2018 . [21] C. Jarne, “An heuristic appro ach to obtain signal e nvelope w ith a simple softw a re implementation, ” arXiv preprint arXiv: 1703.06812 , 201 7. [22] J. Lorenzo-T rueba, J. Yamagishi, T. Toda, D. Saito, F. Villavicencio, T . Kinnunen, an d Z. L i ng, “The Voice Conversion Challenge 2018: Promoting Developme nt of Parallel and Nonparallel Methods,” Proc. Odyssey , 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment