Triplet Network with Attention for Speaker Diarization
In automatic speech processing systems, speaker diarization is a crucial front-end component to separate segments from different speakers. Inspired by the recent success of deep neural networks (DNNs) in semantic inferencing, triplet loss-based archi…
Authors: Huan Song, Megan Willi, Jayaraman J. Thiagarajan
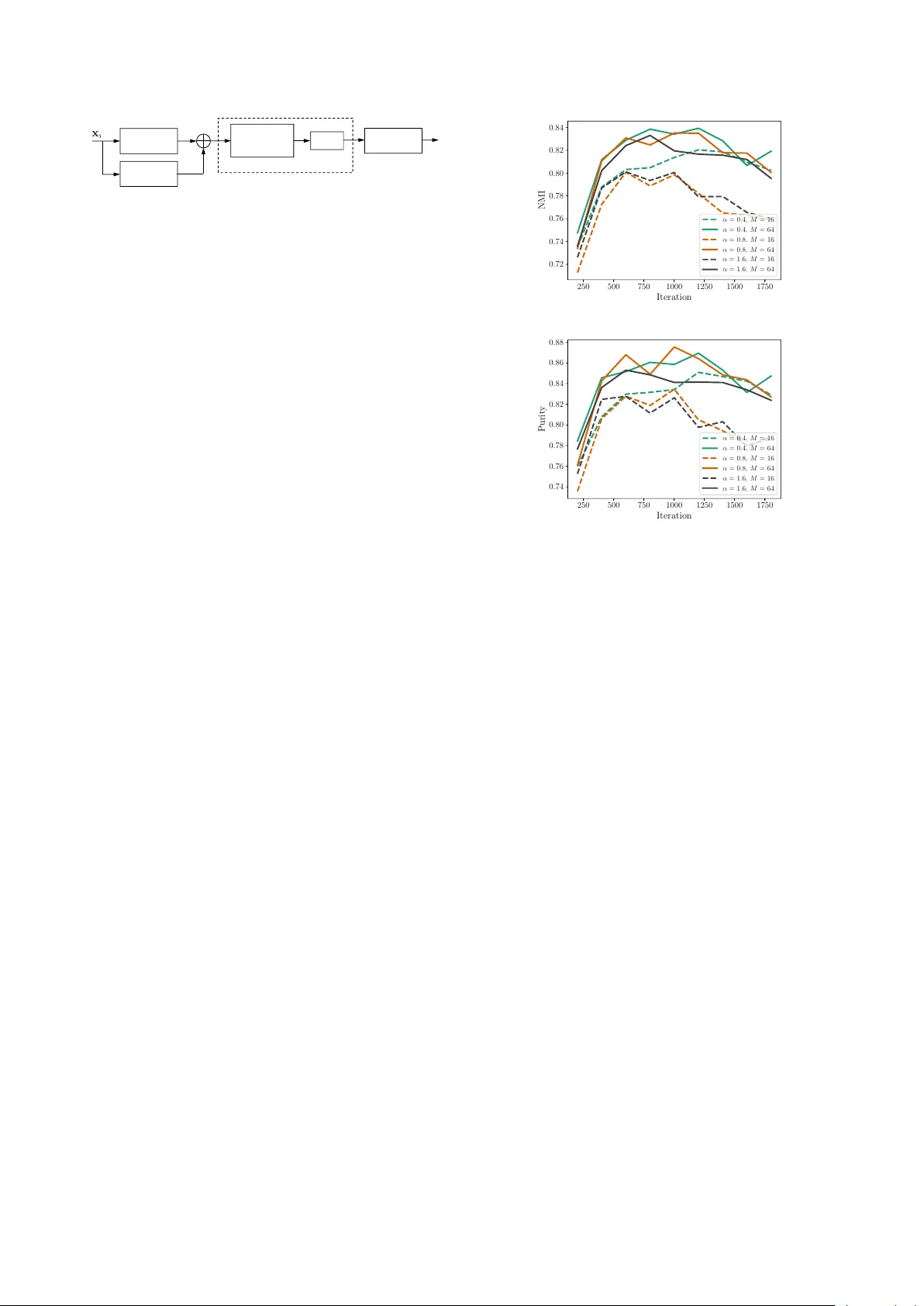
T riplet Network with Attention f or Speaker Diarization Huan Song 1 , Me gan W illi 2 , J ayaraman J . Thiagarajan 3 , V isar Berisha 1 , 2 , Andr eas Spanias 1 1 SenSIP Center , School of ECEE, Arizona State Uni versity , T empe, AZ 2 Department of Speech and Hearing Science, Arizona State Uni versity , T empe, AZ 3 Lawrence Li vermore National Labs, 7000 East A venue, Li vermore, CA { huan.song, megan.willi, visar, spanias } @asu.edu, jjayaram@llnl.gov Abstract In automatic speech processing systems, speaker diarization is a crucial front-end component to separate segments from dif fer- ent speakers. Inspired by the recent success of deep neural net- works (DNNs) in semantic inferencing, triplet loss-based archi- tectures ha ve been successfully used for this problem. Ho wever , existing work utilizes conv entional i-v ectors as the input repre- sentation and builds simple fully connected networks for metric learning, thus not fully lev eraging the modeling power of DNN architectures. This paper in vestigates the importance of learn- ing effectiv e representations from the sequences directly in met- ric learning pipelines for speaker diarization. More specifically , we propose to employ attention models to learn embeddings and the metric jointly in an end-to-end fashion. Experiments are conducted on the CALLHOME con versational speech cor- pus. The diarization results demonstrate that, besides pro viding a unified model, the proposed approach achie ves improv ed per- formance when compared against existing approaches. Index T erms : speaker diarization, triplet network, metric learn- ing, attention models 1. Introduction W ith the e ver -increasing v olume of multimedia content on the Internet, there is a crucial need for tools that can automatically index and organize the content. In particular, speaker diariza- tion deals with the problem of indexing speakers in a collection of recordings, without a priori knowledge about the speaker identities. In scenarios where the single-speaker assumption of recognition systems is violated, it is critical to first separate speech segments from different speakers prior to downstream processing. T ypical challenges in speaker diarization include the need to deal with similarities between a lar ge set of speak- ers, dif ferences in acoustic conditions, and the adaptation of a trained system to new speak er sets. An important class of diarization approaches rely on ex- tracting i-vectors to represent speech segments, and then scor- ing similarities between i-vectors using pre-defined similarity metrics (e.g. cosine distance) to achie ve speaker discrimination. Despite its widespread use, it is well known that the i-vector ex- traction process requires extensi ve training of a Gaussian Mix- ture Model based Univ ersal Background Model (GMM-UBM) and estimation of the total variability matrix (i-vector extractor) beforehand using large corpora of speech recordings. While sev eral choices for the similarity metric currently exist, likeli- hood ratios obtained through a separately trained Probabilistic This w ork was supported in part by the SenSIP center at Arizona State Univ ersity . This work was performed under the auspices of the U.S. Dept. of Energy by Lawrence Liv ermore National Laboratory un- der Contract DE-A C52- 07NA27344. Linear Discriminant Analysis (PLD A) model are commonly uti- lized [1]. More recently , with the advent of modern representation learning paradigms, designing effecti ve metrics for comparing i-vectors has become an activ e research direction. In particu- lar , inspired by its success in computer vision tasks [2, 3, 4], many recent efforts formulate the diarization problem as deep metric learning [5, 6, 7]. For instance, a triplet network that builds latent spaces, wherein a simple Euclidean distance met- ric is highly ef fective at separating dif ferent classes, is a widely adopted architecture. Howe ver , in contrast to its application in vision tasks, metric learning is carried out on the i-vector rep- resentations instead of the raw data [5]. Consequently , the first stage of the diarization pipeline stays intact, while the second stage is restricted to using fully connected networks. Though this modification produced state-of-the-art results in diarization and outperformed conv entional scoring strategies, it does not support joint representation and task-based learning, which has become the modus operandi in deep learning. On the other hand, Garcia-Romero et al. [6] propose to perform joint em- bedding and metric learning, b ut use siamese netw orks for met- ric learning, which have generally shown poorer performance when compared to triplet networks [4]. In this paper, we propose to explore the use of joint repre- sentation learning and similarity metric learning with triplet loss in speaker diarization, while entirely dispensing the need for i-vector extraction. Encouraged by the recent success of self- attention mechanism in sequence modeling tasks [8, 9], for the first time, we lev erage attention networks to model the tempo- ral characteristics of speech se gments. Experimental results on the CALLHOME corpus demonstrate that, with an appropriate embedding architecture, triplet network applied on raw audio features from a comparatively smaller dataset outperforms the same applied on i-v ectors, wherein the GMM-UBM was trained using a much larger corpus. 2. Related W ork In this section, we briefly revie w the recent literature on tech- niques for speaker diarization. Over the last fe w years, speaker diarization approaches ha ve quickly e volved from the tradi- tional MFCC based GMM segmentation and BIC clustering [10, 11, 12] to systems centered around i-v ector representations [13, 14]. Initially proposed for speaker verification tasks [15], i-vectors are lo w-dimensional features extracted ov er variable- length speech segments to compensate for within and between- speaker variabilities. Different speakers can then be effec- tiv ely discriminated by utilizing either standard similarity met- rics (e.g. cosine distance) [16] or likelihood ratios from PLD A [17]) to cluster i-vectors from the se gments. More recently , sev eral deep learning-based solutions hav e been developed to automatically infer similarity metrics to com- pare speech segments. More specifically , supervised metric learning architectures namely siamese [18, 19] and triplet [4, 2] networks are pre valent. Broadly speaking, these architectures infer a non-linear mapping A ( · ) , such that, in the resulting latent space the within-class sample distances are minimized while the between-class distances are maximized based on a certain margin. For instance, in [5], Lan et al. proposed to em- ploy triplet networks on i-vectors to infer a similarity metric, and achie ved state-of-the-art results over conv entional metrics in the diarization literature. Despite its effecti veness, it is im- portant to note that the feature extraction process is disentangled from the metric learning network and hence cannot support end- to-end inferencing. Howev er, recent success of such end-to-end learning systems in computer vision applications [20, 21, 22] motiv ates the design of a deep metric learning architecture that works directly on the temporal sequences. Long Short-T erm Memory (LSTM) based recurrent net- works have become the de facto solution to sequence model- ing tasks including acoustic modeling [23], speech recognition [24] and Natural Language Processing (NLP) [25]. Recently , architectures entirely based on attention mechanism have sho wn promising value in sequence-to-sequence learning [8] and clin- ical data analysis [9]. Besides providing significantly faster training, attention networks demonstrate efficient modeling of long-term dependencies. In this paper , we utilize attention networks with the triplet ranking loss to jointly learn embeddings and a similarity met- rics for speech segments. T o the best of our knowledge, the approaches in [7] and [6] are the most related to our work. While Bredin et al. [7] used triplet networks based on LSTMs, they applied it to a simpler binary classification task of speaker turn identification. Whereas, in [6], Romero et al. performed a similar joint learning for diarization, but based on a siamese network. Compared to the triplet ranking loss, which requires a margin to be satisfied for each giv en reference sample, the cross-entropy loss used in [6] requests correct prediction of all different-speak er or same-speaker pairs and hence exhibits much less flexibility . 3. Proposed Appr oach As shown in Figure 1(b), the proposed approach w orks directly with raw temporal speech features to learn a similarity metric for diarization. Compared to the baseline in Figure 1(a), the two-stage training process is simplified into a single end-to-end learning strategy , wherein deep attention models are used for embedding computation and the triplet loss is used to infer the metric. Similar to existing diarization paradigms, we first train our network using out-of-domain labeled corpus, and then per- form diarization on a tar get dataset using unsupervised cluster- ing. In the rest of this section, we describe the proposed ap- proach in detail. 3.1. T emporal Segmentation and Featur e Extraction For the speech recordings, we first perform non-overlapping temporal segmentation into 2 -second segments. Following the V oice Biometry Standardization (VBS) 1 , we extract MFCC fea- tures using 25 ms Hamming windo ws with 15 ms overlap. Af- ter adding delta and double-delta coefficients, we obtain 60 - dimensional feature vectors at every frame. Consequently , each data sample corresponds to a temporal sequence feature 1 http://voicebiometry .org/ T est Embeddings Tr a i n i n g D a t a TEDLIUM ( ≈ 200 hours ) Te s t D a t a CALLHOME Fully Connected Network Tri p l e t L o s s Clustering Diarization Output UBM, ! Tr a i n a n d T est i-vectors UBM Tr a i n i n g D a t a NIST SRE 04’ - 08’ ( ≈ 1000 hours ) Tr a i n i n g D a t a NIST SRE 04’ - 08’, Fisher English, Switchboard ( ≈ 9000 hours ) i- vector Extracto r (a) Baseline appr oach: (top) i-vectors ar e extr acted using a lar ge corpus of recor dings with GMM-UBM and i-vector ex- tractor modules; (bottom) Similarity metric is trained using a triple network trained on the i-vectors. T est Embeddings T est Data CALLHOME Attention Network T r iplet Loss Clustering Diarization Output T rainin g Data TEDLIUM ( ≈ 200 hours ) (b) Pr oposed appr oach: Joint learning of embedding and sim- ilarity metric for diarization. As observed, it completely elimi- nates the i-vector e xtraction pr ocess and enables ef fective tr ain- ing with limited data. Figure 1: Comparison of diarization strate gies and training data r equir ements for the baseline appr oach in [5] and the pr o- posed appr oach. x i ∈ R T × d , where T is the number of frames in each segment and d = 60 is the feature dimension. 3.2. Embeddings using Attention Models As described earlier , we use attention models to learn embed- dings directly from MFCC features for the subsequent metric learning task. The attention model used in our architecture is illustrated in Figure 2. The module comprised of a multi-head, self-attention mechanism is the core component of the attention model [8]. More specifically , denoting the input representation at layer ` as { h ` − 1 t } T t =1 , we can obtain the hidden representa- tion at time step i based on attention as follo ws: h ` i = T X t =1 w ( i ) t h ` − 1 t , 1 ≤ i ≤ T , (1) w ( i ) t = softmax h ` − 1 i · h ` − 1 t √ D , (2) h ` i ← F ( h ` i ) , (3) Here, D = 256 refers to the size of the hidden layer and F denotes a feed-forward neural network. The attention weight in equation (2) denotes the interaction between temporal positions Input Embedding Multi-head, Self-attention Positional Encoding NN Attention Module, Stack L times T emporal Pooling Figure 2: Illustration of the attention model used for computing embeddings fr om MFCC features of speec h segments. i and t by performing scaled inner product between the two rep- resentations. During the computation of hidden representation at time step i , w ( i ) t weights the contribution from other tempo- ral positions. Note that, these representations are processed by F before connecting to the next attention module, as sho wn in Figure 2. W e employ a 1 D con volutional layer (kernel size is 1 ) with ReLU acti vation [26] for F . Finally , the attention module is stacked L times to learn increasingly deeper representations. Attention-based representations in equation (1) are com- puted within each speech se gment independently and hence this process is referred to as self-attention . Furthermore, the hidden representations h ` t are computed using H different netw ork pa- rameterizations, denoted as heads [8], and the resulting H at- tention representations are concatenated together . This can be loosely interpreted as an ensemble of representations. Such a multi-head operation facilitates dramatically dif ferent tempo- ral parameterizations and significantly expands the modeling power . Our current implementation sets L = 2 and H = 8 . Although attention computation explicitly models the tem- poral interactions, it does not encode the crucial ordering infor - mation contained in speech. The front-end positional encoding block handles this problem by mapping every relative frame po- sition t in the segment to fixed locations in a random lookup table. As shown in Figure 2, the encoded representation is sub- sequently added up with the input embedding (obtained also from a 1 D CNN layer). Finally , we include a temporal pool- ing layer to reduce the final representation h L ∈ R T × D into a D -dimensional vector by a veraging along the time-axis. 3.3. Metric Learning with T riplet Loss The representations from the deep attention model are then used to learn a similarity metric with the triplet ranking loss. Note that the attention model parameters and the metric learner are optimized jointly using back-propagation. In a triplet net- work, each input is constructed as a set of 3 samples x = { x p , x r , x n } , where x r denotes an anchor, x p denotes a posi- tiv e sample belonging to the same class as x r , and x n a negativ e sample from a dif ferent class. Each of the samples in x are pro- cessed using the attention model (Section 3.2) A ( · ) : R T × d 7→ R D and distances are computed in the resulting latent spaces: D rp = kA ( x r ) − A ( x p ) k 2 D rn = kA ( x r ) − A ( x n ) k 2 The triplet loss is defined as l ( x p , x r , x n ) = max(0 , D 2 rp − D 2 rn + α ) (4) where α is the margin and the objecti ve is to achiev e D 2 rn ≥ D 2 rp + α . In comparison, the contrastiv e loss often used in siamese network includes the hinge term max(0 , α − D ij ) for different-class samples x i and x j , and hence requires α to be a global margin. Such a formulation significantly restricts the model flexibility and e xpressive po wer . Giv en a large number of samples N , the computation of equation (4) is infeasible among the O ( N 3 ) triplet space. It 250 500 750 1000 1250 1500 1750 Iteration 0 . 72 0 . 74 0 . 76 0 . 78 0 . 80 0 . 82 0 . 84 NMI α = 0.4, M = 16 α = 0.4, M = 64 α = 0.8, M = 16 α = 0.8, M = 64 α = 1.6, M = 16 α = 1.6, M = 64 (a) NMI scor e from the speak er clustering results. 250 500 750 1000 1250 1500 1750 Iteration 0 . 74 0 . 76 0 . 78 0 . 80 0 . 82 0 . 84 0 . 86 0 . 88 Purit y α = 0.4, M = 16 α = 0.4, M = 64 α = 0.8, M = 16 α = 0.8, M = 64 α = 1.6, M = 16 α = 1.6, M = 64 (b) Purity scor e fr om the speaker clustering r esults. Figure 3: P arameter tuning on TEDLIUM development set for triplet margin α and number of speakers per batch M . Curves for M = 8 and 32 ar e omitted for clarity . is tempting to greedily select the most effecti ve triplets, which maximizes D rp and minimizes D rn . Instead of performing such hard sampling, we follow [2] to sample all possible x p and only selecting semi-hard x n : the negati ve samples satisfy- ing D 2 rp ≤ D 2 rn ≤ D 2 rp + α . Additionally , we adopt an online sampling strategy that restricts the sampling space to the current mini-batch during training. All sampled triplets are gathered to compute the loss in equation (4). For the online sampling scheme, the mini-batch construc- tion step is crucial. Ideally , each batch should cover both a large number of speakers and sufficient samples per speaker . Howe ver , we are constrained by the GPU memory ( 8 GB) and only able to set maximum batch size B = 256 . W e preset M as the number of speakers per batch and when sampling each mini- batch, M speakers are first sampled and B / M speech se gments are then sampled for ev ery speaker . As a result, the parame- ter M represents the trade-off between modeling more speakers each time, and cov ering sufficient samples for those speakers. In our experiments, M was tuned based on the performance on the dev elopment set, as will be discussed in Section 4.1. 4. Experiments In this section, we discuss the training process for our approach and ev aluate its performance on the CALLHOME corpus. 4.1. T riplet Network T raining The proposed model was trained on the TEDLIUM corpus which consists of 1495 audio recordings. After ignoring speak- ers with less than 45 transcribed segments, we have a set of 1211 speakers with an av erage recording length of 10 . 2 min- utes. All recordings were do wn-sampled to 8 kHz to match the − 60 − 40 − 20 0 20 40 60 − 80 − 60 − 40 − 20 0 20 40 60 Figure 4: 2 D t-SNE visualization of the first 20 speakers fr om TEDLIUM development set. Each point corresponds to one speech se gment and the y are color coded by the speaker . target CALLHOME corpus. The temporal segmentation and MFCC extraction were carried out as discussed in Section 3.1. For the proposed approach, there are two important train- ing parameters that need to be selected, i.e. triplet margin α and the number of speakers per mini-batch M . In order to quickly configure the parameters, we build a training subset by randomly selecting 20% of the total recordings and a dev elop- ment set by taking 50 recordings from the original TEDLIUM train, dev and test sets. At every 200 iterations of training on the subset, we extract the embeddings for the dev elopment set and perform speaker clustering using k -Means, with a known number of speakers. The clustering performance is evaluated by the standard Normalized Mutual Information (NMI) and Pu- rity scores. Based on this procedure, we jointly tuned both pa- rameters by performing a grid search on α = [0 . 4 , 0 . 8 , 1 . 6] and M = [8 , 16 , 32 , 64] . As shown in Figure 3, having a higher M value consistently provides better clustering results and al- leviates model overfitting. Additionally , a lower triplet margin generally helps the training process. Based on these observa- tions, we configured α = 0 . 8 , M = 64 to train our model on the entire TEDLIUM corpus. T o study the embeddings from the attention model and the impact of triplet loss, we show the 2 D t-SNE visualization [27] of samples in the dev elopment set in Figure 4. It is observed that the model is highly effectiv e at separating unseen speakers and provides little distinction on segments from the same speakers. These embeddings achieve 0 . 94 score on both NMI and Purity , with k -Means clustering for the dev elopment set. 4.2. Diarization Results The trained model is evaluated on the CALLHOME corpus 2 for diarization performance. CALLHOME consists of tele- phone conversations in 6 languages: Arabic, Chinese, English, German, Japanese and Spanish. In total, there are 780 tran- scribed conv ersations containing 2 to 7 speakers. After obtain- ing the embeddings through the proposed approach, we perform x-means [28] to estimate the number of speakers and then use k - means clustering with the estimation. W e force x-means to split at least 2 clusters by initializing it with 2 centroids. Note that there are usually multiple moving parts on complete diarization 2 https://ca.talkbank.org/access/CallHome/ T able 1: Diarization Results on CALLHOME Corpus. System DER (%) i-vector cosine 18 . 7 PLD A [1] 17 . 6 T riplet with FCN [5] 13 . 4 Proposed Appr oach 12 . 7 systems in the literature. In particular , more sophisticated clus- tering algorithms [29], overlapping test segments and calibra- tion [14] can be incorporated to improve the overall diarization performance. Ho wever , in this work we focus on in vestigating the ef ficacy of the DNN modeling and fix the other components in their basic configurations. W e utilize pyannote.metric [30] to calculate Diariza- tion Error Rate (DER) as the evaluation metric. Although DER collectiv ely considers false alarms, missed detections and con- fusion errors, most e xisting systems e valuated on CALLHOME [14, 6] accounts for only the confusion rate and ignores over- lapping segments. F ollowing this con vention, we use the oracle speech activity regions and use only the non-ov erlapping sec- tions. Additionally , there is a collar tolerance of 250 ms at both beginning and end of each segment. W e compare the proposed approach with the following baseline systems: Baseline 1: i-vector + cosine/PLD A scoring . W e uti- lize VBS pre-trained models for i-vector extraction on CALL- HOME corpus. The specific GMM-UBM and i-vector extrac- tor training data are shown in Figure 1(a). Though different from ours, the training corpus is significantly more compre- hensiv e than the TEDLIUM set we used. The GMM-UBM consists of 2048 Gaussian components and the i-vectors are 600 − dimensional. W e also used the backend LD A model con- tained in VBS for i-vector pre-processing. In the actual cluster - ing, cosine or PLD A scores are used to calculate the sample-to- centroid similarities at each iteration. Baseline 2: i-vector + triplet with FCN training . This baseline is v ery similar to [5] except for 2 modifications: 1) W e do not consider the speaker linking procedure as there are very few repeated speakers in CALLHOME. 2) W e use a larger FCN network than [5] to allo w a fair comparison to the proposed ap- proach. The hidden layers hav e size 512 − 1024 − 512 − 256 and batch normalization [31] is applied at each layer after the ReLU acti vation. Further , i-vectors are extracted on TEDLIUM based on the transcribed speech sections with a verage length of 8 . 6 seconds. The triplet network is tuned in a similar proce- dure as in Section 4.1 and the best parameters were found to be α = 0 . 4 , M = 16 . The comparison between the proposed approach and the baselines is sho wn in T able 1. It is observed that baseline 2 in- deed exceeds both conv entional i-vector scoring methods. Ho w- ev er, our unified learning approach trained on a much smaller TEDLIUM corpus achie ves better performance, this evidencing the effecti veness of end-to-end learning. 5. Conclusions This paper studies the role of learning embeddings under a triplet ranking loss for speaker diarization. Results on the CALLHOME corpus show that when compared to training a UBM model and then a separate triplet DNN, the tw o steps can be combined together to achiev e improved performance with less training ef fort. Future work will inv estigate more sophisti- cated sampling strategies for metric learning [32] and compara- tiv e studies with existing DNN architectures [29, 6]. 6. References [1] E. Khoury , L. El Shafey , M. Ferras, and S. Marcel, “Hierarchi- cal speaker clustering methods for the nist i-vector challenge, ” in Odyssey: The Speaker and Language Recognition W orkshop , 2014. [2] F . Schroff, D. Kalenichenko, and J. Philbin, “Facenet: A unified embedding for face recognition and clustering, ” in Pr oceedings of the IEEE conference on computer vision and pattern recognition , 2015, pp. 815–823. [3] T .-Y . Lin, Y . Cui, S. Belongie, and J. Hays, “Learning deep repre- sentations for ground-to-aerial geolocalization, ” in Proceedings of the IEEE conference on computer vision and pattern recognition , 2015, pp. 5007–5015. [4] E. Hoffer and N. Ailon, “Deep metric learning using triplet net- work, ” in International W orkshop on Similarity-Based P attern Recognition . Springer , 2015, pp. 84–92. [5] G. Le Lan, D. Charlet, A. Larcher , and S. Meignier, “ A triplet ranking-based neural network for speaker diarization and linking, ” Pr oc. Interspeech 2017 , pp. 3572–3576, 2017. [6] D. Garcia-Romero, D. Snyder , G. Sell, D. Pov ey , and A. McCree, “Speaker diarization using deep neural network embeddings, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 4930–4934. [7] H. Bredin, “T ristounet: triplet loss for speaker turn embedding, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 5430–5434. [8] A. V aswani, N. Shazeer, N. Parmar , J. Uszkoreit, L. Jones, A. N. Gomez, Ł. Kaiser, and I. Polosukhin, “ Attention is all you need, ” in Advances in Neural Information Pr ocessing Systems , 2017, pp. 6000–6010. [9] H. Song, D. Rajan, J. J. Thiagarajan, and A. Spanias, “ Attend and diagnose: Clinical time series analysis using attention models, ” in Pr oceedings of the Thirty-Second AAAI Confer ence on Artificial Intelligence (AAAI-2018) , 2018. [10] S. E. Tranter and D. A. Reynolds, “ An overvie w of auto- matic speaker diarization systems, ” IEEE T ransactions on audio, speech, and language pr ocessing , vol. 14, no. 5, pp. 1557–1565, 2006. [11] X. Anguera, S. Bozonnet, N. Evans, C. Fredouille, G. Fried- land, and O. V inyals, “Speaker diarization: A revie w of recent research, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 20, no. 2, pp. 356–370, 2012. [12] C. Barras, X. Zhu, S. Meignier, and J.-L. Gauvain, “Multistage speaker diarization of broadcast ne ws, ” IEEE T ransactions on A u- dio, Speech, and Language Processing , vol. 14, no. 5, pp. 1505– 1512, 2006. [13] J. Prazak and J. Silo vsky , “Speaker diarization using plda-based speaker clustering, ” in Intelligent Data Acquisition and Advanced Computing Systems (IDAA CS), 2011 IEEE 6th International Con- fer ence on , vol. 1. IEEE, 2011, pp. 347–350. [14] G. Sell and D. Garcia-Romero, “Speaker diarization with plda i- vector scoring and unsupervised calibration, ” in Spoken Language T echnology W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 413– 417. [15] N. Dehak, P . J. Kenn y , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T rans- actions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 4, pp. 788–798, 2011. [16] I. Shapiro, N. Rabin, I. Opher , and I. Lapidot, “Clustering short push-to-talk segments, ” in Sixteenth Annual Conference of the In- ternational Speech Communication Association , 2015. [17] P . Kenny , “Bayesian speaker verification with heavy-tailed pri- ors. ” in Odyssey , 2010, p. 14. [18] S. Chopra, R. Hadsell, and Y . LeCun, “Learning a similarity met- ric discriminativ ely , with application to face verification, ” in Com- puter V ision and P attern Recognition, 2005. CVPR 2005. IEEE Computer Society Conference on , vol. 1. IEEE, 2005, pp. 539– 546. [19] G. Koch, R. Zemel, and R. Salakhutdino v , “Siamese neural net- works for one-shot image recognition, ” in ICML Deep Learning W orkshop , vol. 2, 2015. [20] A. Krizhe vsky , I. Sutske ver , and G. E. Hinton, “Imagenet classi- fication with deep con volutional neural networks, ” in Advances in neural information pr ocessing systems , 2012, pp. 1097–1105. [21] A. Gordo, J. Almazan, J. Rev aud, and D. Larlus, “End-to-end learning of deep visual representations for image retriev al, ” Inter- national Journal of Computer V ision , v ol. 124, no. 2, pp. 237–254, 2017. [22] H. Song, J. J. Thiagarajan, P . Sattigeri, and A. Spanias, “Optimiz- ing kernel machines using deep learning, ” IEEE Tr ansactions on Neural Networks and Learning Systems , 2018. [23] H. Sak, A. Senior , and F . Beaufays, “Long short-term memory re- current neural network architectures for large scale acoustic mod- eling, ” in Fifteenth annual conference of the international speech communication association , 2014. [24] A. Graves, A.-r . Mohamed, and G. Hinton, “Speech recognition with deep recurrent neural networks, ” in Acoustics, speech and signal pr ocessing (icassp), 2013 ieee international confer ence on . IEEE, 2013, pp. 6645–6649. [25] M. Sundermeyer , R. Schl ¨ uter , and H. Ne y , “Lstm neural networks for language modeling, ” in Thirteenth Annual Conference of the International Speech Communication Association , 2012. [26] V . Nair and G. E. Hinton, “Rectified linear units improve restricted boltzmann machines, ” in Pr oceedings of the 27th international confer ence on machine learning (ICML-10) , 2010, pp. 807–814. [27] L. V an Der Maaten, “ Accelerating t-sne using tree-based algo- rithms. ” Journal of machine learning r esearch , vol. 15, no. 1, pp. 3221–3245, 2014. [28] D. Pelleg, A. W . Moore et al. , “X-means: Extending k-means with efficient estimation of the number of clusters. ” in Icml , v ol. 1, 2000, pp. 727–734. [29] Q. W ang, C. Downe y , L. W an, P . A. Mansfield, and I. L. Moreno, “Speaker diarization with lstm, ” arXiv preprint arXiv:1710.10468 , 2017. [30] H. Bredin, “pyannote. metrics: a toolkit for reproducible ev alu- ation, diagnostic, and error analysis of speaker diarization sys- tems, ” in Interspeech 2017, 18th Annual Conference of the Inter- national Speech Communication Association , 2017. [31] S. Ioffe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal covariate shift, ” arXiv pr eprint arXiv:1502.03167 , 2015. [32] R. Manmatha, C.-Y . Wu, A. J. Smola, and P . Kr ¨ ahenb ¨ uhl, “Sam- pling matters in deep embedding learning, ” in Computer V ision (ICCV), 2017 IEEE International Confer ence on . IEEE, 2017, pp. 2859–2867.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment