Prosodic-Enhanced Siamese Convolutional Neural Networks for Cross-Device Text-Independent Speaker Verification
In this paper a novel cross-device text-independent speaker verification architecture is proposed. Majority of the state-of-the-art deep architectures that are used for speaker verification tasks consider Mel-frequency cepstral coefficients. In contr…
Authors: Sobhan Soleymani, Ali Dabouei, Seyed Mehdi Iranmanesh
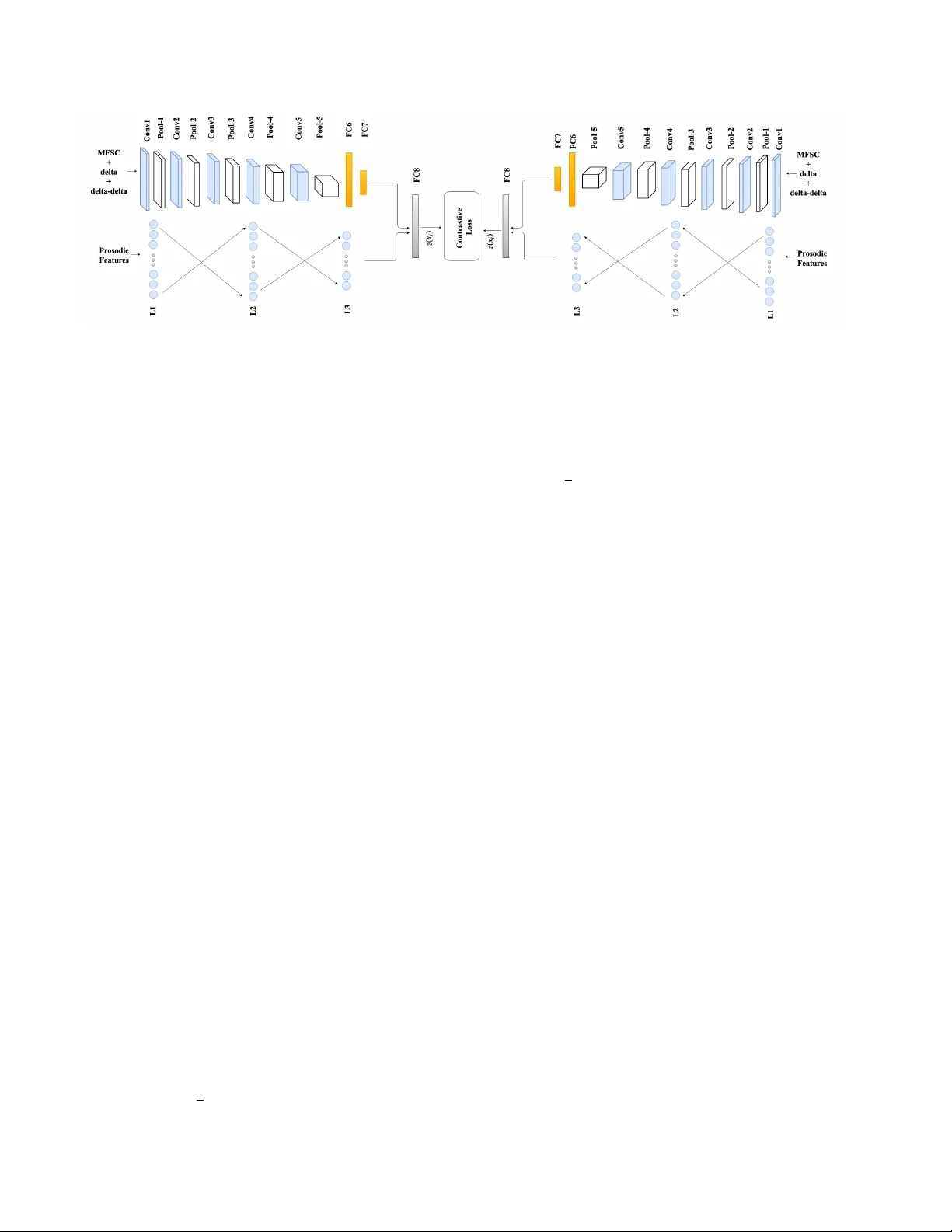
Pr osodic-Enhanced Siamese Con volutional Neural Netw orks f or Cross-De vice T ext-Independent Speaker V erification Sobhan Soleymani, Ali Dabouei, Se yed Mehdi Iranmanesh, Hadi Kazemi, Jeremy Dawson, and Nasser M. Nasrabadi, F ellow , IEEE W est V irginia Uni versity { ssoleyma, ad0046, seiranmanesh, hakazemi } @mix.wvu.edu, { jeremy.dawson, nasser.nasrabadi } @mail.wvu.edu Abstract In this paper a novel cr oss-device te xt-independent speaker verification ar chitectur e is pr oposed. Majority of the state-of-the-art deep ar chitectur es that ar e used for speaker verification tasks consider Mel-fr equency cepstral coefficients. In contrast, our pr oposed Siamese con vo- lutional neural network arc hitectur e uses Mel-fr equency spectr ogram coefficients to benefit fr om the dependency of the adjacent spectr o-temporal featur es. Mor eover , although spectr o-temporal featur es have pr oved to be highly r eliable in speaker verification models, the y only repr esent some aspects of short-term acoustic level traits of the speaker’ s voice. However , the human voice consists of sever al lin- guistic levels such as acoustic, lexicon, pr osody , and pho- netics, that can be utilized in speaker verification models. T o compensate for these inherited shortcomings in spectr o- temporal featur es, we pr opose to enhance the pr oposed Siamese con volutional neural network arc hitectur e by de- ploying a multilayer perceptr on network to incorporate the pr osodic, jitter , and shimmer featur es. The pr oposed end- to-end verification arc hitectur e performs featur e extraction and verification simultaneously . This pr oposed ar chitectur e displays significant impr ovement over classical signal pr o- cessing appr oaches and deep algorithms for for ensic cr oss- device speaker verification. 1. Introduction Speech is considered as a form of biometric v erification, since e verybody has his or her unique v oice. Speaker v erifi- cation aims to extract features from a speaker’ s speech sam- ples and use them to recognize or verify speaker identity through modelings of the speaker’ s speech samples [22]. The speaker-v erification literature focuses on designing a setup in which the claimed identity of a speaker is ei- ther accepted or rejected, which can be conducted as text- dependent [7, 32, 20] or text-independent [15, 33]. Dur- ing text-dependent speaker verification the speech content is a predefined, fixed text, such as a passphrase, while text- independent speaker verification aims to verify the speaker using freeform spoken words, independent of the text or language or other prior constraints. The possible uncon- strained v ariations in text-independent speaker verification make it much more challenging compared to text-dependent models [32]. V oice samples can be acquired through different record- ing devices and are subject to de vice and quality mis- match. In addition, the samples can be recorded at dif- ferent sampling rates and distances, which result in bit- rate mismatch and channel noise. The samples are also subject to background noise problem due to en vironmental noise and distortion. Channel-independent speaker v erifica- tion frameworks [25] try to address this problem. Channel- independent text-independent frameworks are considered to be the ultimate test in the speaker verification domain [26, 14]. Deep learning algorithms are the state-of-the-art frame- works for many biometric applications such as face [17], fingerprint [9], and iris [30] classification, as well as mul- timodal classification [30, 31], attribute-enhanced classifi- cation [18], and domain adaptation [24]. Deep learning ar- chitectures hav e recently proven to be able to provide su- perior performance compared to traditional speaker verifi- cation algorithms, showing significant gains ov er the state- of-the-art Gaussian Mixture Models and Hidden Markov Models [28, 21, 23]. The majority of the deep learning ar- chitectures proposed for speaker recognition task are multi- layer perceptron (MLP)-based models using Mel-frequenc y cepstral coef ficients (MFCCs) [29, 7, 32]. Howe ver , MLP- MFCC architectures fail to preserv e the correlation be- tween the adjacent features. T o address this issue con volu- tional neural networks (CNNs) are used in speaker recog- nition [33, 25]. Additionally , compared to architectures requiring hand-crafted features, con volutional neural net- works (CNNs) extract and classify features simultaneously , and, therefore, av oid losing valuable information [19]. State-of-the-art deep speaker recognition systems use spectro-temporal voice features [25, 29]. The most well- known these short-term features used in the literature are spectrogram, MFCCs, and Mel-frequency spectrogram co- efficients (MFSCs). Inheriting from the short-term nature of these features, most of the models proposed only e xplore the acoustic le vel of the signal, such as spectral magnitudes and formant frequencies [5, 13]. Ho we ver , sev eral impor- tant linguistic levels such as lexicon, prosody or phonetics cannot be recognized from short-term features. These lev els of information are learned habits by the speaker . These fea- tures do not perform as well as the short-term features in the identification and v erification scenarios when the utterances are significantly short. Howe ver , when the length of the utterance increases, it is shown that the identification and verification performance of the prosodic features increases drastically [27]. These features also significantly improve the model when fused with short-term features [13, 12]. In the speak er-verification literature a three-phase proce- dure is defined. Initially , in the development phase, back- ground models are de veloped from a large collection of data. New speakers are added to the model during the en- r ollment phase to construct speaker -dependent models. In the e valuation phase test utterances are compared to the en- rolled speaker models and the background model to ver - ify the identity of the speaker [32]. In this setup, the dif- ference between lo w-dimensional representations of enroll- ment and test utterances is considered to accept or reject the hypothesis [29]. Howe ver , in the proposed algorithm, the enrollment phase is excluded. The proposed Siamese model is trained using the utterances from the training set in the training phase. In the test phase, the trained model is deployed to compute the distance between two utterances. The computed inter sub-network distance is used to de- termine whether or not the utterances belong to the same speaker . In this paper , we make the following contributions: (i) prosodic, jitter , and shimmer features are deployed to en- hance the performance of the proposed CNN Siamese net- work; (ii) a text-independent embedding space is con- structed considering short-term and prosodic features; (iii) rather than extracting the features using hand-crafted meth- ods, a fully data-driven architecture using fused CNN and MLP networks has been optimized for joint domain-specific feature extraction and representation with the application of speaker v erification, finally (i v) the proposed algorithm can be used for real-time applications since it does not require the enrollment phase. 2. Prosodic featur es to enhance deep coupled CNN CNN architectures have recently prov en to outperform the traditional speaker verification algorithms. Follo wing the scenario deployed in image processing literature, the in- put fed into the CNN is a nonlinearly scaled spectrogram with its first and second temporal deri v ati ves [3]. CNN models prefer inputs that change smoothly along both di- mensions. Therefore, acoustic features need to smoothly change both in time and frequency [4]. Since the acous- tic signal is smooth in time, the frequency features need to preserve the locality of the speech signal. The majority of the works using deep neural networks for speech processing use MFCCs [29, 32, 6]. Howe ver , these features do not preserve the locality of the frequenc y domain signal since the discrete cosine trans- form (DCT) projects the spectral energies into a basis that does not maintain locality [3]. Recently , MFSCs hav e been introduced to compensate for this shortcoming [4]. MF- SCs are the log-energy computed directly from the mel- frequency spectral coefficients, which are the representation of the smoothed spectral en velope of the speech. These fea- tures, which are computed similarly to MFCC features with no DCT operation, along with their deltas and delta-deltas (first and second temporal deriv atives) are fed into CNN as three channels of the input, describing the acoustic energy distribution of the spok en utterances. These short-term coefficients represent the spectral en- velope of a speech frame. Although these parameters are speaker specific, they are unable to represent supra- segmental characteristics of the speech signal [13]. On the other hand, prosodic coef ficients represent features that are larger than phonetic units such as; sound, duration, tone and intensity variation. Although within-speaker variability in phonetic content and speaking style degrades the performance of speaker v er - ification systems for short utterances [27], due to the prac- tical complexity of the CNN architecture and the v ast num- ber of parameters that need to be trained, it is not feasible to feed the utterances to the network since it will drastically reduce the number of samples in the training set. T o com- pensate for this shortcoming, we propose to compute the prosodic features from the whole utterances. For each ut- terance, se veral short utterances are randomly chosen. Each of these short utterances, along with the prosodic features calculated for the utterance, are fed to the network. The decision is made upon the computed ov erall scores. Follo wing the setup in [13], 18 prosodic features are ex- tracted from the utterances: three features related to word and segmental durations (number of frames per word and length of word-internal voiced and un voiced segments), six features related to fundamental frequency (mean, maxi- mum, minimum, range, pseudo-slope and slope), and nine jitter and shimmer measurements. Jitter indices used in this setup are absolute jitter , relativ e jitter , rap, and ppq5, while the shimmer indices used are shimmer (dB), relati ve shim- mer , apq3, apq5, and apq11 [13]. Jitter and shimmer are defined as the indices for the cycle-to-c ycle v ariations of fundamental frequency and am- plitude, respectiv ely . These indices are used to describe the voice quality . The frequency of a speaker’ s voice varies from one cycle to the next cycle. Jitter is defined as the cycle-to-c ycle v ariation of fundamental frequency , and is the measurement of vocal stability . On the other hand, Shimmer is the index for vocal amplitude perturbation. Since these features characterize particular voices, they pro- vide speaker -specific information. 3. Proposed speak er-v erification ar chitecture The proposed Siamese architecture consists of two sub- networks that share weights. Each sub-network includes MLP and CNN networks, and the joint representation layer . Segmental features are extracted from each utterance, and are fed to the MLP network, while random short utterances are chosen from the utterances. MFSCs are extracted from short utterances and fed into CNN network. Each sub- network is represented by a fully-connected fusion layer that act as the joint representation. T wo joint representa- tions are used to train the network through the contrastive loss. 3.1. Frequency- and pr osody-domain networks Pooling algorithms are used in CNN architectures to reduce the possibility of over -fitting. Maxpooling is the sample-based con ventional process in CNN architectures to down-sample the feature map representation without smoothing the feature maps, while extracting the most im- portant features. It reduces the maps’ dimensionality and allows the architecture to make sub-region assumptions. Howe ver , maxpooling is a shift-in v ariant operator and risks undesirable phonetic confusion [11]. T o compensate, we propose to use multiple maxpooling sizes in the frequency domain instead of the con ventional maxpooling and con- catenate the output feature maps in depth as shown in T a- ble 1. On the other hand, since the proposed architec- ture is text-independent, the conv entional last-layer fully- connected layer is replaced by average pooling along the time axis and a fully connected layer along the frequency axis. Additionally , this modification allo ws the inputs to vary in size in the time domain. The frequency domain network is comprised of fi ve ma- jor con volutional components and two fully-connected lay- ers which are connected in series. Each conv olutional layer is follo wed by a rectified linear unit (ReLU) layer and a time domain maxpooling. C onv 2 and C onv 4 are also fol- T able 1: The MFSC-dedicated CNN architectures. Nota- tions (t) and (f) represent time and MFSC axis respecti vely . CNN-MFSC layer kernel input output con v1 3 × 3 × 64 40 × 300 × 3 40 × 300 × 64 maxpool1 (t) 2 × 1 × 1 40 × 300 × 64 40 × 150 × 64 con v2 3 × 3 × 128 40 × 150 × 64 40 × 150 × 128 maxpool2 (t) 2 × 1 40 × 150 × 128 40 × 75 × 128 maxpool2-a (f) 1 × 2 × 1 40 × 75 × 128 20 × 75 × 128 maxpool2-b (f) 1 × 3 × 1 40 × 75 × 128 20 × 75 × 128 maxpool2-c (f) 1 × 4 × 1 40 × 75 × 128 20 × 75 × 128 con v3 3 × 3 × 256 20 × 75 × 384 20 × 75 × 256 maxpool3 (t) 2 × 1 × 1 20 × 75 × 256 20 × 37 × 256 con v4 3 × 3 × 256 20 × 37 × 256 20 × 37 × 256 maxpool4 2 × 1 × 1 20 × 27 × 256 20 × 18 × 256 maxpool4-a (f) 1 × 2 × 1 20 × 18 × 256 10 × 18 × 256 maxpool4-b (f) 1 × 3 × 1 20 × 18 × 256 10 × 18 × 256 maxpool4-c (f) 1 × 4 × 1 20 × 18 × 256 10 × 18 × 256 con v5 3 × 3 × 512 10 × 18 × 768 10 × 18 × 512 avgpool (t) 1 × 18 × 1 10 × 18 × 512 10 × 1 × 512 FC6 (f) 10 × 1 × 1024 10 × 1 × 512 1 × 1 × 1024 FC7 1 × 1 × 128 1 × 1 × 1024 1 × 1 × 128 lowed by a heterogeneous frequency domain maxpooling. In the proposed heterogeneous maxpooling, different ker - nel sizes are applied on the feature maps and the outputs are concatenated in depth and fed into the next con volutional layer . The inputs to the frequency-domain network repre- sent short-term features of the acoustic signal. 18 Prosodic features are fed into a multilayer perceptron with two hid- den layers. Each hidden layer consists of 64 hidden units, while the output layer includes 32 nodes. 3.2. Speaker -verification coupled CNN The final objectiv e of the proposed model is to verify whether or not tw o utterances recorded on dif ferent de vices belong to the same speaker or not. The utterances can also be recorded at the same time or in dif ferent sessions. Therefore, the proposed method needs to satisfy the text- independent condition. On the other hand, it is not feasible to feed the whole utterances to the network, since it dras- tically reduces the number of samples. In addition, since the utterance can vary in length, feeding them to the net- work limits the batch normalization benefits. Therefore, we propose to randomly choose several fixed-length short ut- terances. Each short utterance is fed into the network along with the prosodic features calculated from the long utter- ance. The final decision is made upon the distances (scores) giv en to each pair of short utterances. Figure 1: Speaker verifier Siamese network. The MFSC-CNN consist of five con v olutional and two fully-connected layers. The MLP network consists of two 64-units hidden layers and the output layer of 32 units. This output layer along with FC7 layer are fed into FC8 of size 128 . Contrastiv e loss with weight-sharing is applied on sub-networks to compute the distance between two short utterances. As can be seen in Figure 1, the proposed architecture is a Siamese network, where tw o sub-netw orks share weights. Each sub-network consists of CNN and MLP networks. The MFSC-CNN consist of five con volutional and two fully- connected layers. The MLP network consists of two 64- units hidden layers and the output layer of 32 units. This output layer , along with the FC7 layer , are fed into a fully- connected layer of size 128 . Contrastiv e loss is applied to compute the distance between two short utterances. The ultimate goal of the proposed architecture is to find the latent deep features representing the speaker specific features. In order to find a common latent embedding sub- space, we couple sub-networks via a contrastiv e loss func- tion [8]. This function ( L c ) pulls the utterances that belong to the same speaker toward each other into a common la- tent embedding subspace and pushes the utterances belong to different speak ers apart. Although the utterances came from different devices, the recording device is assumed unknown in the test process. Therefore, the sub-networks cannot be trained for a spe- cific de vice. Considering no knowledge about the recording device, weight-sharing between sub-networks is assumed. The contrastive loss between the sub-networks is defined as [8]: L c ( x i , x j ; y i,j ) = (1 − y i,j ) l ge ( x i , x j ) + y i,j l im ( x i , x j ) , (1) where x i and x j are two utterances. The binary label y i,j is equal to 0 if x i and x j belong to the same speaker . Other- wise, it is equal to 1 . l g e and l im represent the partial loss functions for the genuine and impostor pairs, respectively , and D i,j indicates the Euclidean distance between the em- bedded data in the common feature subspace (FC8). l g e and l im are defined as follows: l ge ( x i , x j ) = 1 2 || z ( x i ) − z ( x j ) || 2 for y i,j = 0 , (2) l im ( x i , x j ) = 1 2 max (0 , m − || z ( x i ) − z ( x j ) || 2 ) for y i,j = 1 , (3) where m is the contrastive loss margin. z ( x ) is the sub- network based embedding functions, which transforms x into the common latent embedding space. It should be noted that the contrastiv e loss function considers the subjects’ la- bels inherently . Therefore, it has the ability to find a dis- criminativ e embedding space by employing the data labels in contrast to some other metrics, such as Euclidean dis- tance. This discriminative embedding space would be use- ful in identifying speaker specific features. During the train- ing phase, the pairs of the short-utterances are fed into the Siamese network along with the prosodic features computed from the pair of whole utterances. During the test phase, for a pair of utterances, first the prosodic features are computed. Then, se veral pairs of short utterances are randomly chosen and fed to the network. The distance for each pair is com- puted. The distance between two long utterances is defined as the mean of these distances. 4. Joint optimization of the netw ork In this section, the training of the Siamese architecture is discussed. Here, we explain the implementation of CNN and MLP networks, the joint fully-connected fusion layer and the concurrent optimization of the architecture. 4.1. T raining of the network Initially , the MFSC-dedicated CNNs are trained inde- pendently as a classifier using all the utterances in the train- ing set. As explained in Section 3, the network consists of fiv e conv olutional and two fully-connected layers. A soft- max layer is added to the network, where the number of units is equal to the number of speakers in the training set. T raining the network as classifier facilitates the extraction of the discriminativ e features from MFSC coefficients. The inputs are 3 seconds utterances which are repre- sented as 300 × 224 × 3 images. Three channels represent static, delta and delta-delta feature maps, while 40 repre- sent the number of MFSC coefficients. The training algo- rithm is deployed by minimizing the softmax cross-entrop y loss using mini-batch stochastic gradient descent with mo- mentum. The training w as regularized by weight decay and 50% dropout for the fully connected layers except for the last layer . The batch size, momentum and L 2 penalty multi- plier are set to 32, 0.9 and 0 . 0005 , respectiv ely . The initial learning rate is set to 0 . 1 . The learning rate is decreased e x- ponentially by a factor of 0 . 1 for e very 2 epochs of training. In this network, batch normalization [16] is applied. The moving a verage decay is set to 0 . 99 . Similarly , the MLP network is optimized independently . The parameters for this optimization are the same as the parameters for the CNN network. T o train the joint repre- sentation, the CNN and MLP networks are frozen and the joint representation layer is optimized greedily upon the e x- tracted features. The initial learning rate is reduced to the smallest final learning rate among two networks. Finally , the classification architecture is trained jointly . T o train the Siamese network, the network is initialized with the weights optimized for the classifier network. The pairs are fed into the network and the contrasti ve loss func- tion is minimized while the sub-networks share weight. 4.2. Hyperparameter optimization The hyperparameters in our experiments are : λ the reg- ularization parameter , α 0 initial learning rate, n number of epochs per decay for the learning rate, d moving average decay , and m as the momentum. For each optimization, the 5-fold cross-v alidation method on the training set is used to estimate the best hyperparameters. 5. Experiments and disscussions 5.1. Dataset FBI V oice Collection 2016: This database consists of two sessions (July 2016 and January 2017) of speech from 411 indi viduals using three recording devices: a high- qual- ity microphone, a typical interview room recording sys- tem/D VR, and a digital recorder capturing the speech o ver a cell phone connection. The last two recording are recorded simultaneously . The number of male and female speakers are 205 and 206 respecti vely . This database is one of the few databases that allows disjoint channel-independent training and testing of the proposed algorithm. The total number of utterances is equal to 2 , 418 . The training is conducted on 361 speak ers. The test is performed on the remaining 50 subjects. A summary of the database is presented in T able 2. T able 2: The number of utterances in train and test sets for FBI voice collection 2016 database. T rain set T est set Utterances 2148 300 Microphone 705 100 D VR 708 100 Phone 705 100 5.2. Data repr esentation Initially all utterances are re-sampled to 48 KHz. For each utterance prosodic features were extracted using Praat software for acoustic analysis [1]. These 18 features listed in Section 2 are the inputs fed to MLP network. Then, voiced segments of the utterances are detected using the voicebox toolbox [2]. Each voiced utterance is divided into 25 ms frames with 60% ov erlap. Each frame is multiplied with a hamming windo w to keep the continuity of the first and the last points in the frame. 40 MFSC coefficients are e xtracted from each frame. Delta and delta-delta channels are constructed for each frame as the first deriv ativ e and second temporal deriv ative of MFSC features. Cepstral mean and variance normaliza- tion are applied on each utterance, in which each frequenc y bin is normalized to zero mean and unit variance. Finally , short utterances of three seconds length with two seconds ov erlap are generated. The inputs fed to CNN network are 40 × 300 × 3 short utterances. 5.3. T raining and test phases T raining phase: Pairs of short utterances are randomly chosen, while we mak e sure that the ov erall number of gen- uine and imposter pairs are equal. The pairs of short utter- ances are fed into the architecture along with the prosodic features. The architecture is trained under contrastive loss with no normalization on the last fully-connected layer (FC8). Here the short utterances are assumed to be inde- pendent samples, and the contrasti ve loss is applied on each pair of short utterances. The contrastiv e loss margin is set to 10 . T est phase: For each pair of utterances, 500 pairs of short utterances are randomly chosen. The pairs of short ut- terances are fed into the architecture along with the prosodic features. For each pair of short utterances, the distance is computed as the Euclidean distance between the samples in the embedding space. The vector of the distances between the short utterances is used to determine the distance be- tween two utterances. The short samples can be noisy or may not include speaker specific information. Therefore, T able 3: V erification performance on FBI V oice Collection 2016 database. Algorithm A UC EER i-vector/PLD A (MFSC) 0.9153 0.1579 i-vector/PLD A (MFCC) 0.9185 0.1526 Chen et al. [7] 0.9207 0.1451 Nagrani et al. [25] 0.9215 0.1469 CNN network 0.9218 0.1421 Prosodic network 0.9011 0.1673 Score-lev el fusion 0.9148 0.1578 Coupled network 0.9358 0.1311 av eraging the distances between pairs of short utterances may include outliers. T o remo ve the ef fect of these short ut- terances, the vector’ s mean and standard de viation are com- puted. The av erage of the elements in the vicinity of two standard deviations from the mean value represent the dis- tance between the pair of utterances. 5.4. Evaluation metrics The performance of different experiments are reported and compared using two verification metrics. The utilized metrics are equal error rate (EER) and area under curve (A UC). When false acceptance and false rejection rate for the model are equal, the common value is referred to as EER. A UC represents the area under the receiver operating characteristic curve. 5.5. Results T able 3 presents the verification results for the proposed algorithm. In addition, the verification results for CNN and MLP trained independently are presented. The score-lev el fusion of two networks is considered as well. The perfor- mance of the proposed algorithm is compared with that of i-vector/PLD A algorithm [10]. The same MFSC feature used in the proposed deep algorithm are used in i-vector algorithm. The i-vector model is also trained with MFCC features. The algorithm is also compared with two state-of- the-art deep architectures [25, 7]. T able 4 presents the results for channel-dependent setup. In this special case, each sub-network is fed with utterances from a specific device. T o train this architecture, the sub- networks do not share weights. T o initialize the param- eters for this setup, both the sub-networks are initialized with the parameters from channel-independent setup. This setup leads to better performance compared to channel- independent setup, since the channel-dependent informa- tion in the test samples can be learned during the train- ing phase. The only exception is Phone-DVR cross-device verification setup, where, both devices are considered lo w- quality devices. T able 4: EER and A UC for the channel-dependent setup. Device Microphone DVR Phone Microphone 0.0712 0.1132 0.1247 D VR 0.0827 0.2069 Phone 0.1316 (a) EER Device Microphone DVR Phone Microphone 0.9785 0.9537 0.9512 D VR 0.9717 0.8467 Phone 0.9547 (b) A UC 6. Conclusion In this paper we proposed a novel cross-de vice text- independent speaker verification Siamese architecture, where Mel-frequency spectrogram coefficients are used to benefit from correlation of the adjacent features. In addi- tion, prosodic features were deployed to enhance the spec- tral features fed to CNN. A MLP network is trained to rep- resent the prosodic features describing words, fundamen- tal frequency , jitter and shimmer . The joint representa- tion fusing two networks, trains the network through con- trastiv e loss. The proposed end-to-end verification archi- tecture performs feature e xtraction and v erification simulta- neously . The proposed architecture displays significant im- prov ement over con ventional classical and deep algorithms for forensic cross-device speak er verification. A CKNOWLEDGEMENT This work is based upon a work supported by the Center for Identification T echnology Research and the National Sci- ence Foundation under Grant #1650474 . References [1] Praat software: http://www .fon.hum.uva.nl/praat/. [2] V oicebox: Speech processing toolbox for matlab: http://www .ee.ic.ac.uk/hp/staff/dmb/v oicebox/voicebox.html. [3] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, L. Deng, G. Penn, and D. Y u. Con volutional neural networks for speech recognition. IEEE/ACM T ransactions on audio, speech, and languag e pr ocessing , 22(10):1533–1545, 2014. [4] O. Abdel-Hamid, A.-r . Mohamed, H. Jiang, and G. Penn. Applying con volutional neural networks concepts to hybrid nn-hmm model for speech recognition. In IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocess- ing (ICASSP) , pages 4277–4280, 2012. [5] C. Bhat, B. V achhani, and S. K. Kopparapu. Recognition of dysarthric speech using voice parameters for speaker adap- tation and multi-taper spectral estimation. In Proc. Inter- speechs , pages 228–232, 2016. [6] K. Chen and A. Salman. Extracting speaker-specific infor- mation with a regularized siamese deep network. In Ad- vances in Neural Information Pr ocessing Systems , pages 298–306, 2011. [7] Y .-h. Chen, I. Lopez-Moreno, T . N. Sainath, M. V isontai, R. Alvarez, and C. Parada. Locally-connected and conv o- lutional neural networks for small footprint speaker recog- nition. In Annual Conference of the International Speech Communication Association , 2015. [8] S. Chopra, R. Hadsell, and Y . LeCun. Learning a similarity metric discriminati vely , with application to face verification. In IEEE Confer ence on Computer V ision and P attern Recog- nition (CVPR), 2005 , volume 1, pages 539–546, 2005. [9] A. Dabouei, H. Kazemi, S. M. Iranmanesh, J. Dawson, and N. M. Nasrabadi. Fingerprint distortion rectification using deep conv olutional neural networks. In International Con- fer ence on Biometrics , 2018. [10] N. Dehak, P . J. Kenny , R. Dehak, P . Dumouchel, and P . Ouel- let. Front-end factor analysis for speaker verification. IEEE T ransactions on Audio, Speec h, and Language Pr ocessing . [11] L. Deng, O. Abdel-Hamid, and D. Y u. A deep conv olu- tional neural network using heterogeneous pooling for trad- ing acoustic in variance with phonetic confusion. In IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , pages 6669–6673, 2013. [12] M. Farr ´ us, A. Garde, P . Ejarque, J. Luque, and J. Hernando. On the fusion of prosody , voice spectrum and face features for multimodal person verification. In Ninth International Confer ence on Spoken Language Pr ocessing , 2006. [13] M. Farr ´ us, J. Hernando, and P . Ejarque. Jitter and shim- mer measurements for speaker recognition. In Eighth Annual Confer ence of the International Speech Communication As- sociation , 2007. [14] L. P . Heck, Y . Konig, M. K. S ¨ onmez, and M. W eintraub . Ro- bustness to telephone handset distortion in speaker recogni- tion by discriminativ e feature design. Speech Communica- tion , 31(2-3):181–192, 2000. [15] G. Heigold, I. Moreno, S. Bengio, and N. Shazeer . End-to- end text-dependent speaker verification. In IEEE Interna- tional Confer ence on Acoustics, Speech and Signal Pr ocess- ing (ICASSP) , pages 5115–5119, 2016. [16] S. Ioffe and C. Szegedy . Batch normalization: Accelerating deep network training by reducing internal cov ariate shift. arXiv pr eprint , 2015. [17] S. M. Iranmanesh, A. Dabouei, H. Kazemi, and N. M. Nasrabadi. Deep cross polarimetric thermal-to-visible face recognition. arXiv preprint , 2018. [18] H. Kazemi, S. Soleymani, A. Dabouei, M. Iranmanesh, and N. M. Nasrabadi. Attribute-centered loss for soft-biometrics guided face sketch-photo recognition. In IEEE Confer - ence on Computer V ision and P attern Recognition W orkshop , 2018. [19] A. Krizhevsky , I. Sutskev er , and G. E. Hinton. Imagenet classification with deep conv olutional neural networks. In Advances in neural information processing systems , pages 1097–1105, 2012. [20] A. Larcher , K. A. Lee, B. Ma, and H. Li. T ext-dependent speaker verification: Classifiers, databases and rsr2015. Speech Communication , 60:56–77, 2014. [21] C. Li, X. Ma, B. Jiang, X. Li, X. Zhang, X. Liu, Y . Cao, A. Kannan, and Z. Zhu. Deep speaker: an end-to-end neural speaker embedding system. arXiv pr eprint , 2017. [22] Y . Liu, T . Fu, Y . F an, Y . Qian, and K. Y u. Speaker verification with deep features. In IJCNN , pages 747–753, 2014. [23] M. McLaren, Y . Lei, and L. Ferrer . Advances in deep neu- ral network approaches to speak er recognition. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE Inter- national Confer ence on , pages 4814–4818, 2015. [24] S. Motiian, Q. Jones, S. Iranmanesh, and G. Doretto. Fe w- shot adversarial domain adaptation. In Advances in Neural Information Pr ocessing Systems , pages 6670–6680, 2017. [25] A. Nagrani, J. S. Chung, and A. Zisserman. V oxceleb: a large-scale speaker identification dataset. arXiv preprint , 2017. [26] H. Nakasone and S. D. Beck. Forensic automatic speaker recognition. In A Speak er Odysse y-The Speaker Reco gnition W orkshop , 2001. [27] S. J. Park, G. Y eung, J. Kreiman, P . A. K eating, and A. Al- wan. Using voice quality features to improv e short-utterance, text-independent speaker verification systems. Proc. Inter- speech , pages 1522–1526, 2017. [28] T . N. Sainath, B. Kingsbury , G. Saon, H. Soltau, A.-r . Mo- hamed, G. Dahl, and B. Ramabhadran. Deep con volutional neural networks for large-scale speech tasks. Neural Net- works , 64:39–48, 2015. [29] D. Snyder , P . Ghahremani, D. Pove y , D. Garcia-Romero, Y . Carmiel, and S. Khudanpur . Deep neural network-based speaker embeddings for end-to-end speaker verification. In IEEE Spoken Language T echnology W orkshop (SLT) , pages 165–170, 2016. [30] S. Soleymani, A. Dabouei, H. Kazemi, J. Dawson, and N. M. Nasrabadi. Multi-le vel feature abstraction from con volu- tional neural networks for multimodal biometric identifica- tion. In 24th International Confer ence on P attern Recogni- tion (ICPR) , 2018. [31] S. Soleymani, A. T orfi, J. Dawson, and N. M. Nasrabadi. Generalized bilinear deep conv olutional neural networks for multimodal biometric identification. In IEEE International Confer ence on Image Pr ocessing (ICIP) , 2018. [32] E. V ariani, X. Lei, E. McDermott, I. L. Moreno, and J. Gonzalez-Dominguez. Deep neural networks for small footprint text-dependent speaker v erification. In IEEE Inter- national Confer ence on Acoustics, Speech and Signal Pro- cessing (ICASSP) , pages 4052–4056, 2014. [33] C. Zhang and K. K oishida. End-to-end text-independent speaker verification with triplet loss on short utterances. In Pr oc. of Interspeech , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment