Automatic Clone Recommendation for Refactoring Based on the Present and the Past
When many clones are detected in software programs, not all clones are equally important to developers. To help developers refactor code and improve software quality, various tools were built to recommend clone-removal refactorings based on the past and the present information, such as the cohesion degree of individual clones or the co-evolution relations of clone peers. The existence of these tools inspired us to build an approach that considers as many factors as possible to more accurately recommend clones. This paper introduces CREC, a learning-based approach that recommends clones by extracting features from the current status and past history of software projects. Given a set of software repositories, CREC first automatically extracts the clone groups historically refactored (R-clones) and those not refactored (NR-clones) to construct the training set. CREC extracts 34 features to characterize the content and evolution behaviors of individual clones, as well as the spatial, syntactical, and co-change relations of clone peers. With these features, CREC trains a classifier that recommends clones for refactoring. We designed the largest feature set thus far for clone recommendation, and performed an evaluation on six large projects. The results show that our approach suggested refactorings with 83% and 76% F-scores in the within-project and cross-project settings. CREC significantly outperforms a state-of-the-art similar approach on our data set, with the latter one achieving 70% and 50% F-scores. We also compared the effectiveness of different factors and different learning algorithms.
💡 Research Summary
The paper addresses the practical problem of identifying which code clones (duplicated code fragments) should be refactored, recognizing that developers cannot manually inspect the often‑thousands of clones reported by detection tools. The authors propose CREC (Clone REcommendation for Refactoring based on the present and the past), a learning‑based framework that automatically extracts labeled examples from version histories, derives a rich set of features describing both the current state and historical evolution of clones, and trains a classifier to predict refactoring‑worthiness.
CREC’s workflow consists of four phases. In Phase I (Clone Data Preparation) the system builds clone genealogies across multiple versions. The authors re‑implemented the genealogy model of Kim et al. and employed SourcererCC for multi‑version near‑miss clone detection. To keep the analysis tractable, they sample versions only when at least 200 lines of code have changed, thereby preserving meaningful evolution while drastically reducing the number of versions to process. Phase II (Clone Labeling) automatically classifies clone groups as “R‑clones” (historically refactored) or “NR‑clones” (never refactored) using three heuristics: (1) at least two clone instances shrink in size in the next version, (2) those instances add an invocation to a newly created method, and (3) the body of that method shares at least 0.4 similarity with the removed code. This heuristic is designed to capture typical Extract‑Method refactorings; manual validation shows a precision of about 92 %.
Phase III (Feature Extraction) is the core contribution. The authors define 34 features grouped into five categories: (a) Clone Code Features (11 metrics such as LOC, token count, cyclomatic complexity, field accesses, control‑flow presence, etc.), (b) Clone History Features (6 metrics measuring file‑level and directory‑level change frequencies, recent activity, and number of maintainers), (c) Relative Location Features (6 binary indicators of whether clone peers share the same directory, file, class hierarchy, etc.), (d) Syntactic Difference Features (6 measures of textual or structural divergence among peers), and (e) Co‑change Features (5 metrics counting how often clone peers are modified together in commits). These features jointly capture the perceived effort required to refactor (size, complexity, syntactic distance) and the potential benefit (recent churn, co‑evolution).
In Phase IV (Training and Testing) the extracted feature vectors are fed to machine‑learning classifiers. The authors compare several algorithms—Random Forest, Gradient Boosting, SMO (SVM), and Naïve Bayes—and find that tree‑based models consistently outperform the others, achieving the highest F‑scores. They also perform feature‑importance analysis, revealing that history‑related and co‑change features contribute the most, while traditional code‑complexity metrics are less decisive.
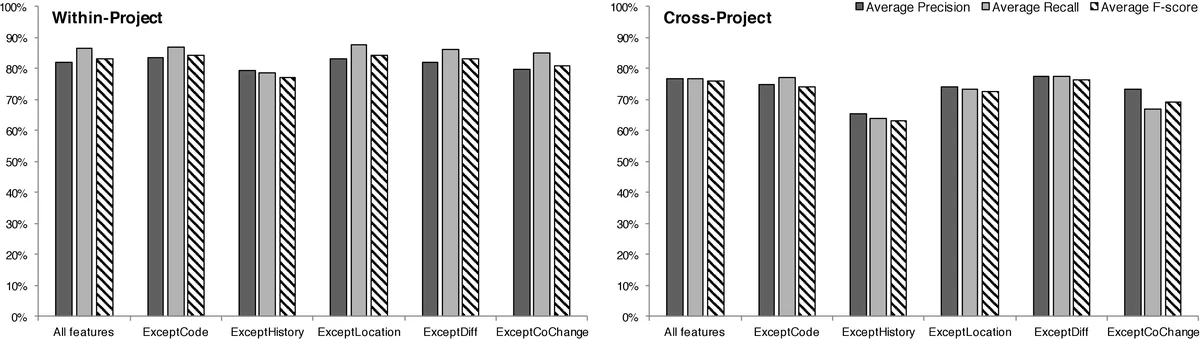
The empirical evaluation uses six large open‑source projects from different domains. Two experimental settings are considered: (1) within‑project, where the model is trained and tested on the same project, yielding an 83 % F‑score; and (2) cross‑project, where a model trained on five projects is applied to the sixth, achieving a 76 % F‑score. Both results surpass the state‑of‑the‑art approach of Kim et al. (70 % and 50 % respectively). The authors also examine the impact of varying the similarity threshold in the labeling heuristic, confirming that the chosen 0.4 value balances precision and recall well.
Overall, CREC demonstrates that (i) automatic extraction of refactored clones from version control is feasible and accurate, (ii) a comprehensive, multi‑dimensional feature set significantly improves prediction quality, and (iii) tree‑based learners are well‑suited for this task. Limitations include the focus on Extract‑Method style refactorings; extending the labeling heuristics to other refactoring types (e.g., Inline Method, Move Method) would broaden applicability. Additionally, the approach depends on the underlying clone detector and sampling parameters, suggesting that project‑specific tuning may be required in practice. Future work could explore multi‑refactoring labeling, dynamic feature selection, and integration with IDEs to provide real‑time clone‑refactoring recommendations.
Comments & Academic Discussion
Loading comments...
Leave a Comment