Blind Multiclass Ensemble Classification
The rising interest in pattern recognition and data analytics has spurred the development of innovative machine learning algorithms and tools. However, as each algorithm has its strengths and limitations, one is motivated to judiciously fuse multiple…
Authors: Panagiotis A. Traganitis, Alba Pag`es-Zamora, Georgios B. Giannakis
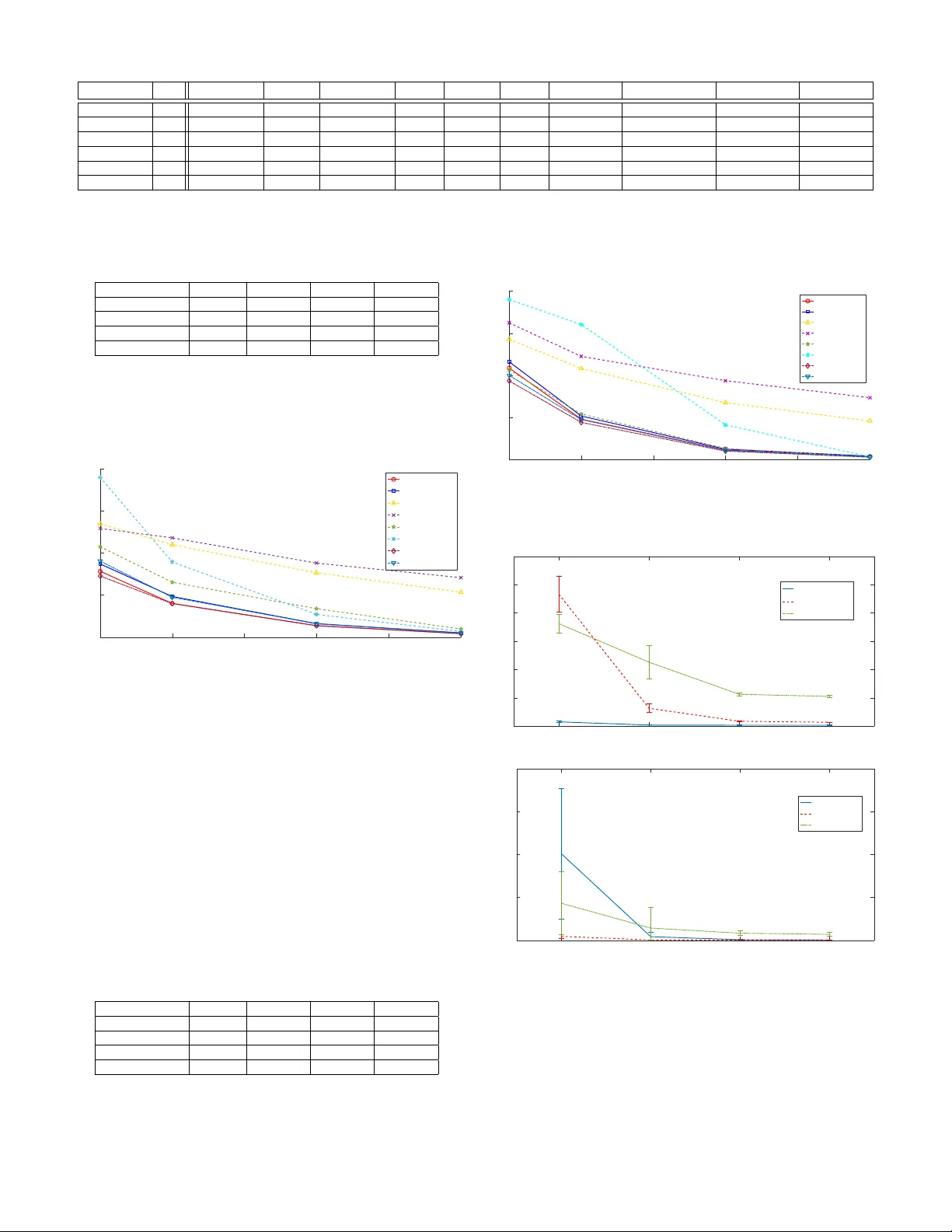
1 Blind Multiclass Ensemble Classification Panagiotis A. Trag anitis, Student Member , IEEE, Alba Pag ` es-Zamora, Senior Member , IEEE, and Georgios B. Giannakis, F ellow , IEEE Abstract —The rising interest in pattern recognition and data analytics has spurred the de velopment of innov ative machine learning algorithms and tools. Howev er , as each algorithm has its strengths and limitations, one is motiv ated to judiciously fuse multiple algorithms in order to find the “best” performing one, for a given dataset. Ensemble learning aims at such high- performance meta-algorithm, by combining the outputs from multiple algorithms. The present work introduces a blind scheme for lear ning from ensembles of classifiers, using a moment match- ing method that le verages joint tensor and matrix factorization. Blind r efers to the combiner who has no knowledge of the gr ound- truth labels that each classifier has been trained on. A rigorous performance analysis is deri ved and the proposed scheme is evaluated on synthetic and real datasets. Index T erms —Ensemble lear ning, unsupervised, multiclass classification, crowdsourcing . I . I N T R O D U C T I O N T HE massi ve amounts of generated and communicated data has introduced society and computing to a data “deluge. ” Along with the increase in the amount of data, multiple machine learning, signal processing and data mining algorithms ha ve been dev eloped. These algorithms are usually tailored for different datasets, and the y often operate under dif- ferent assumptions. As such, finding an algorithm that works “well” for a specific dataset can be prohibitively complex or impossible. Ensemble learning refers to the task of designing a meta- learner , by combining the results provided by multiple dif- ferent learners or annotators 1 ; see Fig. 1. This meta-learner should generally be able to outperform the individual learners. In particular , ensemble classification refers to fusing the results provided by different classifiers. Each classifier observes data, decides one class, out of K possible, each of these data belong to, and provides the meta-learner with those decisions. Such a setup emerges in diverse disciplines including medicine [1], biology [2], team decision making and economics [3], and has recently gained attention with the advent of cro wdsourcing [4], as well as services such as Amazon’ s Mechanical Turk [5], CrowdFlo wer and Clickworker , to name a few . A related setup appears in distributed detection [6], [7], where sensors collect data, decide which one out of K possible hypotheses is in effect, and transmit those decisions to a fusion center , that makes a final decision. A similar task is also known as the CEO pr oblem or multiterminal source coding [8]. Panagiotis A. T raganitis and Georgios B. Giannakis are with the Dept. of Electrical and Computer Engineering and the Digital T echnology Center, Univ ersity of Minnesota, Minneapolis, MN 55455, USA. Alba Pag ` es-Zamora is with the SPCOM Group, Univ ersitat Polit ` ecnica de Catalunya BarcelonaT ech, Spain. Emails: { traga003@umn.edu, alba.pages@upc.edu, georgios@umn.edu } 1 The terms learner, annotator, and classifier will be used interchangeably throughout this manuscript. When training data are av ailable, a meta-learner can learn how to combine the results from individual classifiers, based on these ground-truth labels [9]. One such approach is boost- ing [10], where multiple classifiers are combined according to their probability of error on the training set. In the boosting regime, each classifier is also using information from the rest. In many cases howe ver , labeled data are not av ailable to train the combining meta-classifier , and/or, the individual classifiers cannot be retrained, justifying the need for unsupervised (or blind ) ensemble learning methods. One such paradigm is provided by crowdsourcing, where people are tasked with providing classification labels. Accordingly , in a distributed detection setup, the fusion center might not hav e access to the sensors, once they have been deployed. The present work puts forth a nov el scheme for multiclass blind ensemble classification , built upon simple concepts from probability and detection theory , as well as recent adv ances in tensor decompositions [11] and optimization theory , that enable assessing the reliability of multiple annotators and combining their answers. Under our proposed model, each annotator has a fixed probability of deciding that a datum belongs to class k , gi ven that the true class of the datum is k 0 . Assuming that annotators make decisions independent of each other , the proposed method extracts these probabilities from the first-, second-, and third-order statistics of annotator responses. This becomes possible thanks to a joint P ARAF A C decomposition, which has been employed in a related problem of identifying conditional probabilities to complete a joint probability functions from its projections [12]. The crux of our algorithm is a moment matching method, that le v erages the aforementioned P ARAF AC decomposition approach to obtain accurate estimates of annotator decision probabilities along with class priors. These estimates are then provided to the meta-detector to form the final estimate of data labels. T o assess the proposed scheme, extensi ve numerical tests, on synthetic as well as real data are presented, comparing the proposed approach to state-of-the-art binary and multiclass blind ensemble classification methods. In addition, a rigorous performance analysis is provided, which sho wcases the con- ditions under which our novel method works. The rest of the paper is organized as follows. Section II states the problem, provides preliminaries for the proposed approach along with a brief description of the prior art in unsupervised ensemble classification. Section III introduces the proposed scheme for multiclass unsupervised ensemble classification, while Section IV analyses the performance of the proposed method. Section V presents numerical tests to compare our method with state-of-the-art ensemble classi- fication algorithms. Finally , concluding remarks and future research directions are given in Section VI. Detailed deriv a- 2 Data x Learner 1 Learner 2 . . . Learner M Meta-learner/Fusion center ˆ y f 1 ( x ) f 2 ( x ) f M ( x ) Fig. 1. Unsupervised ensemble classification setup, where the outputs of learners are combined in parallel. tions are delegated to Appendix A, while proofs of theorems, propositions and lemmata are deferred to Appendix B. Notation: Unless otherwise noted, lowercase bold letters, x , denote vectors, uppercase bold letters, X , represent matrices, and calligraphic uppercase letters, X , stand for sets. The ( i, j ) th entry of matrix X is denoted by [ X ] ij ; and its rank by rank ( X ) ; X > denotes the tranpose of matrix X ; R D stands for the D -dimensional real Euclidean space, R + for the set of positive real numbers, Z + for the set of positiv e integers, E [ · ] for expectation, and k · k for the ` 2 -norm. Underlined capital letters X denote tensors, vec ( · ) denotes the vectorization operator , that stacks columns of a matrix into a longer column vector; the vector outer product is denoted by ◦ , and, denotes the Khatri-Rao matrix product. For a 3- mode tensor X , X (: , : , i ) , X (: , i, :) , and X ( i, : , :) denote the i -th frontal, longitudinal and lateral slabs of X , respectiv ely , while X ( i, j , l ) denotes the ij l -th element of X . I I . P R O B L E M S TA T E M E N T A N D P R E L I M I N A R I E S Consider a dataset consisting of N data (possibly vectors) { x n } N n =1 each belonging to one of K possible classes with corresponding labels { y n } N n =1 , e.g. y n = k if x n belongs to class k . The pairs { ( x n , y n ) } are drawn independently from an unknown joint distribution D , and X and Y denote random variables such that ( X , Y ) ∼ D . Consider no w M annotators that observe { x n } N n =1 , and provide estimates of labels. Let f m ( x n ) ∈ { 1 , . . . , K } denote the label assigned to datum x n by the m -th annotator . All annotator responses are then collected at a centralized meta-learner or fusion center . The task of unsupervised ensemble classification is: Giv en only the annotator responses { f m ( x n ) , m = 1 , . . . , M } N n =1 , we wish to estimate the ground-truth labels of the data { y n } ; see Fig. 1. Similar to unsupervised ensemble classification, crowd- sourced classification seeks to estimate ground-truth labels of the data { y n } from annotator responses { f m ( x n ) } , with the additional caveat that each annotator m may choose to provide labels for only a subset N m < N of data. A. Prior work Probably the simplest scheme for blind or unsupervised ensemble classification is majority voting, where the estimated label of a datum is the one that most annotators agree upon. Majority voting has been used in popular ensemble schemes such as bagging, and random forests [13]. While relativ ely easy to implement, majority voting presumes that all annotators are equally “reliable, ” which is rather unrealis- tic, both in crowdsourcing as well as in ensemble learning setups. Other blind ensemble methods aim to estimate the parameters that characterize the annotators’ performance. A joint maximum likelihood (ML) estimator of the unknown labels and these parameters has been reported using the expectation-maximization (EM) algorithm [14]. As the EM algorithm does not guarantee con v ergence to the ML solution, recent works pursue alternati v e estimation methods. For binary classification, [15] assumes that annotators adhere to the “one- coin” model, meaning each annotator m provides the correct (incorrect) label with probability δ m ( 1 − δ m ); see also [16] when annotators do not label all the data, and [17] for an iterativ e method. Recently , [18], [19] adv ocated a spectral decomposition technique of the second-order statistics of annotator responses for binary classification, that yields the reliability param- eters of annotators, when class probabilities are unknown, while [20] introduced a minimax optimal algorithm that can infer annotator reliabilities. In the multiclass setting, [17] solves multiple binary classification problems. In addition, [21] and [22] utilize third-order moments and orthogonal tensor decomposition to estimate the unkno wn reliability pa- rameters and then initialize the EM algorithm of [14]. This procedure howe ver , can be numerically unstable, espe- cially when the number of classes K is large, and classes are unequally populated. Finally , all the methods mentioned in this section employ ML estimation, which implicitly assumes that the dataset is balanced, meaning classes are roughly equiproba- ble. Another interesting approach is presented in [23], where a joint moment matching and maximum likelihood optimization problem is solved. The present work puts forth a nov el scheme for multiclass blind ensemble classification , built upon simple concepts from probability and detection theory . It relies on a joint P ARAF A C decomposition approach, which lends itself to a numerically stable algorithm. At the same time, our novel approach takes into account class prior probabilities to yield accurate esti- mates of class labels. Compared to our conference precursor in [24], here we do not require the prior probabilities to be known, and we present comprehensiv e numerical tests, along with a rigorous performance analysis. B. Canonical P olyadic Decomposition/P ARAF AC This subsection will outline tensor decompositions, which will be used in the following sections to deriv e the proposed scheme. Consider a 3-mode I × J × L tensor X , which can be described by a matrix in 3 different ways X (1) := [ vec ( X (1 , : , :)) , . . . , vec ( X ( I , : , :))] (1a) X (2) := [ vec ( X (: , 1 , :)) , . . . , vec ( X (: , J, :))] (1b) X (3) := [ vec ( X (: , : , 1)) , . . . , vec ( X (: , : , L ))] (1c) where X (1) is of dimension J L × I , X (2) is I L × J and X (3) is I J × L . Under the Canonical Polyadic Decomposi- tion(CPD)/Parallel Factor Analysis (P ARAF AC) model [25], 3 X can be written as a sum of R rank one tensors (a.k.a. factors ) X = R X r =1 a r ◦ b r ◦ c r (2) where a r , b r , c r are I × 1 , J × 1 and L × 1 vectors, respec- tiv ely . Letting A := [ a 1 , . . . , a R ] , B := [ b 1 , . . . , b R ] , and C := [ c 1 , . . . , c R ] be the so-called factor matrices of the CPD model, we write (2) compactly as X = [[ A , B , C ]] R (3) and (1) can be equiv alently written as X (1) = ( C B ) A > (4a) X (2) = ( C A ) B > (4b) X (3) = ( B A ) C > (4c) where we hav e used the fact that for matrices A , B and a vector c of appropriate dimensions, it holds that vec ( A diag ( c ) B > ) = ( B A ) c . By vectorizing X (3) , it is easy to show that the vectorization of the entire tensor will be of the form x := vec ( X ) = vec ( X (3) ) = ( C B A ) 1 . Accordingly , vectorizing X (1) or X (2) produces different vectorizations of the entire tensor, where the order of factor matrices in the Khatri-Rao product is permuted. Recovery of the factor matrices A , B and C , can be done by solving the following non-con ve x optimization problem [ ˆ A , ˆ B , ˆ C ] = arg min A , B , C k X − [[ A , B , C ]] R k 2 F . (5) Similar to the matrix case, the Frobenius norm here can be defined as k X k F := q P i,j,l X ( i, j, l ) 2 , and as (4) is just a rearrangement of the terms in X , it holds that k X k F = k X (1) k F = k X (2) k F = k X (3) k F . (6) T ypically , (5) is solved using alternating optimization (A O) or gradient descent [11]. Multiple off-the-shelf solvers are av ail- able for P ARAF AC tensor decomposition; see e.g. [26], [27]. Furthermore, depending on extra properties of X , constraints can be enforced on the factor matrices, such as nonnegati vity and sparsity to name a fe w , which can be effecti vely handled by popular solvers such as A O-ADMM [28]. Under certain conditions, the factorization of X into A , B , and C , is essentially unique , or essentially identifiable , that is ˆ A , ˆ B , and ˆ C can be expressed as ˆ A = APΛ a , ˆ B = BPΛ b , ˆ C = CPΛ c (7) where P is a common permutation matrix, and Λ a , Λ b , Λ c are diagonal scaling matrices such that Λ a Λ b Λ c = I [11]. For more details regarding the P ARAF A C decomposition and tensors with more than 3 modes, interested readers are referred to the comprehensive tutorial in [11] and references therein. I I I . U N S U P E RV I S E D E N S E M B L E C L A S S I FI C A T I O N Each annotator in our model has a fixed probability of deciding that a datum belongs to class k 0 , when presented with a datum of class k . Thus, each annotator m can be characterized by a so called confusion matrix Γ m , whose ( k 0 , k ) -th entry is [ Γ m ] k 0 k := Γ m ( k 0 , k ) = Pr ( f m ( X ) = k 0 | Y = k ) . (8) The K × K matrix Γ m has non-negati v e entries that obey the simplex constraint, since P K k 0 =1 Pr ( f m ( X ) = k 0 | Y = k ) = 1 , for k = 1 , . . . , K ; hence, entries of each Γ m column sum up to 1 , that is, Γ > m 1 = 1 and Γ m ≥ 0 . The confusion matrix showcases the statistical behavior of an annotator , as each column provides the annotator’ s probability of deciding the correct class, when presented with a datum from each class. Before proceeding, we adopt the following assumptions. As1. Responses of dif ferent annotators per datum, are condi- tionally independent, given the ground-truth label Y of the same datum X ; that is, Pr ( f 1 ( X ) = k 1 , . . . , f M ( X ) = k M | Y = k ) = M Y m =1 Pr ( f m ( X ) = k m | Y = k ) As2. Most annotators are better than random; e.g., most have probability of correct detection exceeding 0 . 5 for K = 2 . Clearly , for annotators that are better than random, the largest elements of each column of their confusion matrix will be those on the diagonal of Γ m ; that is [ Γ m ] kk ≥ [ Γ m ] k 0 k , for k 0 , k = 1 , . . . , K . As1 suggests that annotators make decisions independently of each other , which is rather a standard assumption [14], [19], [22]. Likewise, As2 is another standard assumption, used to alleviate the inherent permutation ambiguity of the confusion matrix estimates provided by our algorithm. Note that As2 is slightly more relaxed than the corresponding assumption in [22], which splits annotators into 3 groups and requires most annotators in each group to be better than random. A. Maximum a posteriori label estimation Giv en only annotator responses for all data, a straight- forward approach to estimating their ground-truth labels is through a maximum a posteriori (MAP) classifier [29]. In particular , for datum X the MAP classifier is ˆ y MAP ( X ) = arg max k ∈{ 1 ,...,K } L ( X | k ) Pr( Y = k ) (9) where L ( X | k ) := Pr ( f 1 ( X ) = k 1 , . . . , f M ( X ) = k M | Y = k ) is the conditional likelihood of X . As annotators make independent decisions, it holds that L ( X | k ) = Q M m =1 Pr ( f m ( X ) = k m | Y = k ) , and thus the MAP classifier can be rewritten as ˆ y MAP ( X ) = arg max k ∈{ 1 ,...,K } log π k + M X m =1 log(Γ m ( k m , k )) (10) 4 where π k := Pr( Y = k ) . It is well known from detection theory [29] that the MAP classifier (10) minimizes the av erage probability of error P e , giv en by P e = K X k =1 π k Pr( ˆ y MAP = k 0 6 = k | Y = k ) . (11) If all classes are equiprobable, that is π k = 1 /K for all k = 1 , . . . , K , then (10) reduces to the ML classifier . In order to obtain the MAP or ML classifier , { Γ m } M m =1 must be a vail- able, while in the MAP classifier case π := [ π 1 , . . . , π K ] > is also required. Interestingly , the next section will illustrate that { Γ m } M m =1 and π show up in (and can thus be estimated from) the moments of annotator responses. B. Statistics of annotator responses Consider each label represented by the annotators using the canonical K × 1 vector e k , denoting the k -th column of the K × K identity matrix I . Let f m ( X ) denote the m -th annotator’ s response in vector format. Since f m ( X ) is just a vector representation of f m ( X ) , it holds that Pr ( f m ( X ) = k 0 | Y = k ) ≡ Pr ( f m ( X ) = e k 0 | Y = k ) . With γ m,k denoting the k -th column of Γ m , it thus holds that E [ f m ( X ) | Y = k ] = K X k 0 =1 e k 0 Pr ( f m ( X ) = k 0 | Y = k ) (12) = γ m,k where the first equality comes from the definition of con- ditional expectation, and the second one because e k ’ s are columns of I . Using (12) and the law of total probability , the mean vector of responses from annotator m , is hence E [ f m ( X )] = K X k =1 E [ f m ( X ) | Y = k ] Pr ( Y = k ) = Γ m π . (13) Upon defining the diagonal matrix Π := diag ( π ) , the K × K cross-correlation matrix between the responses of annotators m and m 0 6 = m , can be expressed as R mm 0 := E [ f m ( X ) f > m 0 ( X )] = K X k =1 E [ f m ( X ) | Y = k ] E [ f > m 0 ( X ) | Y = k ] Pr ( Y = k ) = Γ m diag ( π ) Γ > m 0 = Γ m ΠΓ > m 0 (14) where we successiv ely relied on the law of total probability , As1, and (12). Consider now the K × K × K cross-correlation tensor between the responses of annotators m , m 0 6 = m and m 00 6 = m 0 , m , namely Ψ mm 0 m 00 = E [ f m ( X ) ◦ f m 0 ( X ) ◦ f m 00 ( X )] . (15) It can be shown that Ψ mm 0 m 00 obeys a CPD/P ARAF AC model [cf. Sec. II-B] with factor matrices Γ m , Γ m 0 and Γ m 00 ; that is, Ψ mm 0 m 00 = K X k =1 π k γ m,k ◦ γ m 0 ,k ◦ γ m 00 ,k (16) = [[ Γ m Π , Γ m 0 , Γ m 00 ]] K . Note here that the diagonal matrix Π can multiply any of the factor matrices Γ m , Γ m 0 , or , Γ m 00 . W ith F m := [ f m ( x 1 ) , f m ( x 2 ) , . . . , f m ( x N )] the sample mean of the m -th annotator responses can be readily obtained as µ m = 1 N N X n =1 f m ( x n ) = 1 N F m 1 . (17) Accordingly , the K × K sample cross-correlation S mm 0 ma- trices between the responses of annotators m and m 0 6 = m , are giv en by S mm 0 = 1 N N X n =1 f m ( x n ) f > m 0 ( x n ) = 1 N F m F > m 0 . (18) Lastly , the sample K × K × K cross-correlation tensors T mm 0 m 00 between the responses of annotators m, m 0 6 = m and m 00 6 = m, m 0 are T mm 0 m 00 = 1 N N X n =1 f m ( x n ) ◦ f m 0 ( x n ) ◦ f m 00 ( x n ) (19) = 1 N F m ◦ F m 0 ◦ F m 00 . Clearly , S mm 0 = S > m 0 m , T (2) m 0 mm 00 = T (3) m 0 m 00 m = T (1) mm 0 m 00 . In addition, as N increases, the law of large numbers (LLN) implies that, { µ m } , { S mm 0 } , and { T mm 0 m 00 } approach their ensemble counterparts in (13), (14), and (15). Having av ailable first-, second-, and third-order statistics of annotator responses, namely { µ m } M m =1 , { S mm 0 } M m,m 0 =1 , and { T mm 0 m 00 } M m,m 0 ,m 00 =1 , estimates of { Γ m } M m =1 and π can be readily extracted from them [cf. (13), (14), (15)]. This procedure corresponds to the method-of-moments estima- tion [30]. Upon obtaining { ˆ Γ m } M m =1 and ˆ π , the MAP classifier of Sec. III-A can be subsequently employed to estimate the label for each datum. That is, for n = 1 , . . . , N , ˆ y MAP ( x n ) = arg max k ∈{ 1 ,...,K } log ˆ π k + M X m =1 log ˆ Γ m ( f m ( x n ) , k ) (20) where ˆ Γ m ( k 0 , k ) = [ ˆ Γ m ] k 0 k , and ˆ π k = [ ˆ π ] k . The following section provides an algorithm to estimate these unkno wn quantities. C. Confusion matrix and prior probability estimation T o estimate the unknown confusion matrices and prior probabilities consider the following non-conv ex constrained optimization problem, min π { Γ m } M m =1 h N ( { Γ m } M m =1 , π ) (21) s.to Γ m ≥ 0 , Γ > m 1 = 1 , m = 1 , . . . , M π ≥ 0 , π > 1 = 1 where 5 Algorithm 1 Confusion matrix and prior probability estima- tion algorithm Input: Annotator responses { F m } M m =1 , λ > 0 , ν > 0; maximum number of iterations I ∈ Z + Output: Estimates of { ˆ Γ m } M m =1 and ˆ π 1: Compute { µ m } , { S mm 0 } , { T mm 0 m 00 } using (17), (18), and (19). 2: Initialize { Γ m } and π randomly . 3: do 4: for m = 1 , . . . , M do 5: Update Γ m using (23) 6: Γ (prev) m ← Γ m 7: end for 8: Update π using (22) 9: π (prev) ← π 10: i ← i + 1 11: while not con ver ged and i < I T 12: Find permutation matrix ˆ P , such that the majority of { ˆ Γ m ˆ P } M m =1 satisfy As2. Algorithm 2 Unsupervised multiclass ensemble classification Input: Annotator responses { F m } M m =1 Output: Estimates of data labels { ˆ y n } N n =1 1: Find estimates { ˆ Γ m } M m =1 and ˆ π using Alg. 1 2: for n = 1 , . . . , N do 3: Estimate label y n using (20). 4: end for h N ( { Γ m } , π ) := 1 2 M X m =1 k µ m − Γ m π k 2 2 + 1 2 M X m =1 m 0 >m k S mm 0 − Γ m ΠΓ > m 0 k 2 F + 1 2 M X m =1 m 0 >m m 00 >m 0 k T mm 0 m 00 − [[ Γ m Π , Γ m 0 , Γ m 00 ]] K k 2 F and the subscript N in h N denotes the number of data used to obtain annotator statistics. Collect the set of constraints per matrix to the con vex set C := { Γ ∈ R K × K : Γ ≥ 0 , Γ > 1 = 1 } , where essentially each column lies on a probability sim- plex, and let C p := { u ∈ R K : u ≥ 0 , u > 1 = 1 } denote the constraint set for π . As (21) is a non-con v ex problem, alternating optimization will be employed to solve it. Specifically the alternating optimization-alternating direction method of multipliers (A O- ADMM) will be employed; see [28], and also [12] where a similar formulation appears. Under the A O-ADMM paradigm, h N is minimized per block of unknown variables { Γ m } or π while the other blocks remain fixed, as in block coordinate descent schemes. Solving for one block of v ariables with the remaining fixed is a con ve x constrained optimization problem under con ve x C and C p constraint sets. These optimization problems are pretty standard and se veral solvers are av ailable, including proximal splitting methods, projected gradient de- scent or ADMM [31]–[34]. Here, the solver of choice for each block of variables will be ADMM. The update for π in v olves minimizing h N with { Γ m } M m =1 fixed. Specifically , the following problem is solved min π ∈C p g N , π ( π ) (22) where g N , π ( π ) := 1 2 M X m =1 k µ m − Γ m π k 2 2 + ν 2 k π − π (prev) k 2 2 + 1 2 M X m =1 m 0 >m k s mm 0 − ( Γ m 0 Γ m ) π k 2 2 + 1 2 M X m =1 m 0 >m m 00 >m 0 k t mm 0 m 00 − ( Γ m 00 Γ m 0 Γ m ) π k 2 2 s mm 0 = vec ( S mm 0 ) , t mm 0 m 00 = vec ( T (3) mm 0 m 00 ) [cf. (4)], ν is a positi ve scalar , and we have used v ec ( Γ m diag ( π ) Γ > m 0 ) = ( Γ m 0 Γ m ) π and vec ([[ Γ m diag ( π ) , Γ m 0 , Γ m 00 ]] K ) = ( Γ m 00 Γ m 0 Γ m ) π . Note that g N , π contains all of the terms in h N along with ( ν / 2) k π − π (prev) k 2 2 , which is included to ensure con ver gence of the A O-ADMM iterations to a stationary point of (21) [28], [35]. Here, π (prev) denotes the estimate of π obtained by the previous solutions of (22). Accordingly per Γ m , the following subproblem is solved with { Γ m 0 } M m 0 6 = m and π fixed min Γ m ∈C g N ,m ( Γ m ) (23) where g N ,m ( Γ m ) := 1 2 k µ m − Γ m π k 2 2 + ν 2 k Γ m − Γ (prev) m k 2 F + 1 2 M X m 0 6 = m k S m 0 m − Γ m 0 ΠΓ > m k 2 F + 1 2 M X m 0 >m m 00 >m 0 k T (1) mm 0 m 00 − ( Γ m 00 Γ m 0 ) ΠΓ > m k 2 F T (1) mm 0 m 00 = [ vec ( T (1 , : , :)) , . . . , vec ( T ( K, : , :))] , Γ (prev) m de- notes the estimate of Γ m obtained by the pre vious solution of (23), ν is a positi ve scalar, and we have used (6). Here, g N ,m contains all the terms of h N that in volv e Γ m with the additional term ( ν / 2) k Γ m − Γ (prev) m k 2 F , which ensures con v ergence of the A O-ADMM iterations. Detailed deriv ations of the ADMM iterations for solving (23) and (22) are provided in Appendix A, while the A O- ADMM is summarized in Alg. 1. The computational com- plexity of the entire A O-ADMM scheme is approximately O ( I T M 3 K 4 ) , where I T is the number of required iterations until con v ergence (see Appendix A-C). The entire unsuper- vised ensemble classification procedure is listed in Alg. 2. 6 D. Con ver gence and identifiability Con v ergence of the entire A O-ADMM scheme for (21), follows readily from results in [28, Prop. 1], stated next for our setup. Proposition 1. [28, Prop. 1] Alg. 1 for M ≥ 3 , and ν > 0 con ver ges to a stationary point of (21) . Having established the conv ergence of Alg. 1 to a stationary point of (21) using Prop. 1, the suitability of the estimates provided by Alg. 1 for the ensemble classification task needs to be assessed. As (21) in v olves joint tensor decompositions, under certain conditions the solutions { ˆ Γ m } , ˆ π of (21) will be, similar to the P ARAF A C decomposition of Sec. II-B, essentially unique . Thus, in order to assess the suitability of the estimates provided by Alg. 1 the conditions under which the model employed in (21) is identifiable hav e to be established. Luckily , identifiability claims for the present problem can be easily de- riv ed from recent results in joint P ARAF AC factorization [12], [36]. Lemma 1. Let { Γ ∗ m } , π ∗ be the optimal solutions of (21) , and { ˆ Γ m } , ˆ π the estimates pr ovided by Alg. 1. If at least thr ee { Γ m } M m =1 have full column rank, there exists a permutation matrix ˆ P such that ˆ Γ m ˆ P = Γ ∗ m , m = 1 , . . . , M , ˆ P > ˆ π = π ∗ . Lemma 1 essentially requires that at least three annotators respond differently to different classes, that is no two columns of at least three confusion matrices are colinear . Possibly more relaxed identifiability conditions could be deriv ed using techniques mentioned in [36]. Unlike the tensor decomposition mentioned in Sec. II-B, here we have no scaling ambiguity on the confusion matrices or prior probabilities. This is important because there are infinite scalings, but finite permutation matrices since K is finite. Under As2, ˆ P can be easily obtained since the largest elements of each column of a confusion matrix must lie on the diagonal for the majority of annotators. Each ˆ Γ m can be multiplied by a permutation matrix ˆ P m , such that the largest elements are located on the diagonal. The final ˆ P can be deriv ed as the most commonly occurring permutation matrix out of { ˆ P m } M m =1 . Remark 1. While we relied on statistics of annotator re- sponses up to order three, higher-order statistics can also be employed. Higher-order moments howe ver , will increase the complexity of the algorithm, as well as the number of data required to obtain reliable (low-v ariance) estimates. Remark 2. Estimates of annotator confusion matrices { ˆ Γ m } and data labels { ˆ y n } , provided by Alg. 2, can be used to initialize the EM algorithm of [14]. Remark 3. The orthogonal tensor decomposition used by [21], [22] is a special case of the P ARAF A C decomposition employed in this work. Remark 4. When π is known, (22) can be skipped, and correspondingly steps 8 and 9 of Alg. 1. E. Reducing complexity When K and M are large Alg. 1 may require long computational time to conv erge. Our idea in this case is to split the annotators into L groups, and solve (21) for each group. For simplicity of exposition, consider non-ov erlapping groups, each with M ` ≥ 3 annotators ( P L ` =1 M ` = M ). Let µ ( ` ) m , S ( ` ) mm 0 and T ( ` ) mm 0 m 00 denote the sample statistics for annotators in group ` , and { Γ ( ` ) m } M ` m =1 the confusion matrices in group ` . For each group ` ∈ { 1 , . . . , L } confusion matrices { ˆ Γ ( ` ) m } M ` m =1 and prior probabilities π ( ` ) are estimated by solv- ing a smaller version of (21), namely min π ( ` ) { Γ ( ` ) m } M m =1 h ( ` ) N ( { Γ ( ` ) m } M m =1 , π ( ` ) ) (24) s.to Γ ( ` ) m ≥ 0 , 1 > Γ ( ` ) m = 1 > , m = 1 , . . . , M ` π ( ` ) ≥ 0 , 1 > π ( ` ) = 1 where h ( ` ) N ( { Γ m } , π ) := 1 2 M ` X m =1 k µ ( ` ) m − Γ m π k 2 2 + 1 2 M ` X m =1 m 0 >m k S ( ` ) mm 0 − Γ m ΠΓ > m 0 k 2 F + 1 2 M X m =1 m 0 >m m 00 >m 0 k T ( ` ) mm 0 m 00 − [[ Γ m Π , Γ m 0 , Γ m 00 ]] K k 2 F . Upon solving (24) for all L groups, estimates of { Γ m } M m =1 are readily obtained, since we have assumed non-ov erlapping groups. A final estimate of the prior probabilities π can be obtained by averaging the L estimates { π ` } L ` =1 . As (24) incurs a complexity of O ( I M 3 ` K 3 ) , the worst-case complexity of this approach is O ( I M K 3 P L ` =1 M 3 ` ) , where I M is the largest number of iterations required to con v erge among all L groups. Since M 3 = ( P L ` =1 M ` ) 3 > P L ` =1 M 3 ` this approach reduces the computational and memory ov erhead significantly compared to Alg. 1. Note howe ver , that this method is expected to perform well when As1 and As2, as well as the conditions outlined in Lemma 1 are satisfied for all L groups of annotators, and N is sufficiently large. The effecti veness of this complexity reduction scheme is tested in Sec. V. F . Application to cr owdsour cing While cro wdsourced classification is a task related to ensem- ble classification, it presents additional challenges. So far it has been implicitly assumed that all annotators provide labels for all { x n } N n =1 . In the cro wdsourcing setup ho we ver , an annotator m could provide labels just for a subset of N m < N data. Next, we outline a computationally attractiv e approach, that takes into account only the av ailable annotator responses. If an annotator m does not provide a label for a datum, his/her response is f m ( x ) = 0 or f m ( x ) = 0 in vector format. Let J m ( x n ) be an indicator function that takes the value 1 when 7 annotator m provides a label for x n , and 0 when f m ( x n ) = 0 . T o account for such cases, the annotator sample statistics become µ m = 1 P N n =1 J m ( x n ) N X n =1 J m ( x n ) f m ( x n ) (25a) S mm 0 = P N n =1 J m ( x n ) J m 0 ( x n ) f m ( x n ) f > m 0 ( x n ) P N n =1 J m ( x n ) J m 0 ( x n ) (25b) T mm 0 m 00 (25c) = P n J m ( x n ) J m 0 ( x n ) J m 00 ( x n ) f m ( x n ) ◦ f m 0 ( x n ) ◦ f m 00 ( x n ) P N n =1 J m ( x n ) J m 0 ( x n ) J m 00 ( x n ) . Upon computing the modified sample statistics of (25), we can obtain estimates of the confusion matrices and prior probabilities in the crowdsourcing setup, via Alg. 1. Finally , the MAP classifier in (20) has to be modified as follows ˆ y MAP ( x ) = arg max k ∈{ 1 ,...,K } log ˆ π k + M X m =1 J m ( x ) log ˆ Γ m ( f m ( x ) , k ) (26) to take into account only the av ailable annotator responses for each x . Having completed the algorithmic aspects of our approach, we proceed with performance analysis. I V . P E R F O R M A N C E A N A L Y S I S In this section, performance of the proposed method will be quantified analytically . First, the consistency of the estimates provided by Alg. 1 as N → ∞ will be established, followed by a performance analysis for the MAP classifier of Sec. III-A. A. Consistency of Alg. 1 estimates As N → ∞ , the sample statistics in (17), (18), and (19) approach their ensemble counterparts, and we end up with the following optimization problem for extracting annotator confusion matrices and prior probabilities min π { Γ m } M m =1 h ∞ ( { Γ m } M m =1 , π ) (27) s.to Γ m ∈ C , m = 1 , . . . , M , π ∈ C p . Clearly , the optimal solutions to (27) are the true confusion matrices and prior probabilities. As N increases, it is desirable to sho w that the solutions obtained from Alg. 1 conv er ge to the true confusion matrices and prior probabilities. T o this end, techniques from statistical learning theory and stochastic optimization will be employed [37], [38]. Specifically , we will establish the uniform conv er gence of h N to h ∞ , which implies the consistency of the solutions. Define the distance between two sets A , B ⊆ R q , for some q > 0 , as D ( A , B ) = sup x ∈A { inf y ∈B k x − y k 2 } . The following theorem sho ws that as N increases, the solutions of (21) approach those of (27). Theorem 1. If S ∗ and S N denote the sets of solutions of pr oblems (27) and (21) , respectively , then D ( S N , S ∗ ) → 0 , as N → ∞ almost sur ely . Under As2 and the conditions outlined in Lemma 1, Alg. 1 can recover the true solutions of (21) or (27). Then, by Thm. 1 we know that as N → ∞ the solutions of (21) conv er ge to the solutions of (27), which together with the result of Lemma 1 implies the statistical consistency of the solutions of Alg. 1. As a result, the estimates { ˆ Γ m } M m =1 , and ˆ π from Alg. 1 will con v erge to their true values w .p. 1 as N → ∞ . B. MAP classifier performance W ith consistency of the confusion matrix and prior prob- ability estimates established, the performance of the final component of the proposed algorithm has to be studied. The behavior of the MAP classifier of Sec. III-A can be quantified in terms of its average probability of error P e = K X k =1 Pr( ˆ y MAP = k 0 6 = k | Y = k ) Pr( Y = k ) Here, a well-kno wn asymptotic result for distributed binary detection under the MAP detector [6] is extended to the multiclass case. Theorem 2. Under As1, and given { Γ m } M m =1 and π , there exist constants α > 0 , β > 0 such that the MAP classifier of Sec. III-A satisfies P e ≤ αe − β M . In words, Theorem 2 suggests that when accurate estimates of { Γ m } M m =1 and π are av ailable, the error rate decreases at an exponential rate with the number of annotators M . In order to v alidate our theoretical results and ev aluate the performance of the proposed scheme, the following section presents numerical tests with synthetic and real data. V . N U M E R I C A L T E S T S For K ≥ 2 , Alg. 2, using both MAP and ML criteria in step 3, (denoted as Alg. 2 MAP and Alg. 2 ML respectiv ely) is compared to majority v oting, the algorithm of [17] (denoted as K OS ), and the EM algorithm initialized both with majority voting and with the spectral method of [22] (denoted as EM + MV and EM + Spectral , respectively). For K = 2 , Alg. 2 is also compared to the binary ensemble learning methods of [19], [20] and [16], denoted as SML , TE and EigenRatio , respectiv ely . For synthetic data, the performance of “oracle” estimators, that is MAP/ML classifiers with true confusion matrices of the annotators, and the true class priors, is also ev aluated for benchmarking purposes. The metric utilized in all experiments is the classification error rate (ER), defined as the percentage of misclassified data, E R = # of misclassified data N × 100% , where E R = 100% indicates that all N data have been misclassified, and E R = 0% indicates perfect classification 8 accuracy . For synthetic data, the average confusion matrix and prior probability estimation error is also ev aluated ¯ ε C M := 1 M M X m =1 k Γ m − ˆ Γ m k 1 k Γ m k 1 = 1 M M X m =1 k Γ m − ˆ Γ m k 1 ¯ ε π := k π − ˆ π k 1 . All results represent averages over 10 independent Monte Carlo runs, using MA TLAB [39]. In all experiments, the parameters λ and ν of Alg. 1 are set as suggested in [28], [35]. V ertical lines in some figures indicate standard deviation. For some experiments, classification times (in seconds) required by the ensemble algorithms are also reported. Note that classification times for majority voting and oracle estimators are not reported as the time required by these methods is negligible compared to the rest of the algorithms. A. Synthetic data For the synthetic data tests, N ground-truth labels { y n } N n =1 , each corresponding to one out of K possible classes, were generated i.i.d. at random according to π , that is y n ∼ π , for n = 1 , . . . , N . Afterwards, { Γ m } M m =1 were generated at random, such that Γ m ∈ C , for all m = 1 , . . . , M , and annotators are better than random, as per As2. Then annotators’ responses were generated as follo ws: if y n = k , then the response of annotator m will be generated randomly according to the k -th column of its confusion matrix, γ m,k [cf. Sec. II], that is f m ( x n ) ∼ γ m,k . T ab. I lists the classification ER of dif ferent algorithms, for a synthetic dataset with K = 2 classes with prior probabilities π = [0 . 9003 , 0 . 0997] > , and M = 10 annotators. T ab . II lists the results for a similar experiment, with K = 2 classes, priors π = [0 . 5856 , 0 . 4144] > , and M = 10 annotators, while T ab . III shows the clustering time required by all algorithms. Note that when the class probabilities are similar , the ML and MAP classifiers perform comparably as expected. Furthermore, majority voting giv es good results for a reduced number of instances N . Fig. 2 depicts the av erage estimation errors for the confusion matrices and prior probabilities in the two aforementioned experiments. Clearly , as N increases, the proposed classifiers approach the performance of the oracle ones, and as suggested by Thm. 1, the estimation error for the confusion matrices and prior probabilities approaches 0 . The next synthetic data experiment in vestig ates how the proposed method performs when presented with multiclass data. Furthermore, to showcase that accurate estimation of π is beneficial, we also compare against Alg. 2 with π fixed to the uniform distribution, i.e. π = 1 /K (denoted as Alg. 2 - fixed π .) Fig. 3 sho ws the simulation results for a synthetic dataset with K = 5 classes, prior proba- bilities π = [0 . 2404 , 0 . 2679 , 0 . 0731 , 0 . 1950 , 0 . 2236] > , and M = 10 annotators, while Fig. 4 shows the simulation results for a synthetic dataset with K = 7 classes, priors π = [0 . 2347 , 0 . 0230 , 0 . 0705 , 0 . 1477 , 0 . 2659 , 0 . 0043 , 0 . 2539] > and M = 10 annotators. T abs. IV and V show classification times for the K = 5 and K = 7 experiments, respectiv ely . Fig. 5 shows the av erage estimation errors for the confusion matrices and prior probabilities in the two aforementioned multiclass experiments. Note that for K = 5 for small values of N and K = 7 the EM+Spectral approach of [22] suffers from numerical issues during the tensor whitening procedure, which explains its worst classification ER and slow runtimes. Here, the proposed approaches exhibit similar behavior to the binary case, as expected from Thm. 1; as the number of data increases, their performance appr oaches the clairvoyant “oracle” estimators, and the estimation accuracy of the confusion matrices and prior pr obabilities increases. In addition, our methods outperform the competing alternativ es for almost all values of N . Here we also see that running Alg. 2 with fixed π = 1 /K produces lower quality estimates than Alg. 2 that solves for π . Specifically , Alg. 2 with fixed π performs similarly to the EM algorithm when initialized with majority voting. Next, we ev aluate how the number of annotators M af- fects the classification ER, for fixed N = 10 6 . Fig. 6 depicts an experiment for K = 3 classes with pri- ors π = [0 . 2318 , 0 . 4713 , 0 . 2969] > , while Fig. 7 shows an experiment for K = 5 classes with priors π = [0 . 3596 , 0 . 1553 , 0 . 1229 , 0 . 3258 , 0 . 0364] > . T abs. VI and VII list classification times for the K = 3 and K = 5 experiments, respectiv ely . Fig. 8 plots the results of an experiment with K = 5 classes with the same priors as those in Fig. 7 and N = 5 , 000 data, for varying number of annotators. The av erage estimation error for the confusion matrices and prior probabilities, for the aforementioned tests, is shown in Fig. 9. As expected from Thm. 2, the classification ER decr eases as the number of annotators incr ease , for all methods considered. In addition, our proposed algorithm outperforms the competing alternativ es for all v alues of M . Furthermore, the results of Fig. 8 indicate that when the number of data is small, incr easing the number of annotators pr ovides a boost to the classification performance. Fig. 9 shows another interesting feature: as the number of annotators increases the estimation accuracy of { Γ m } and π also increases. The following experiment ev aluates the effecti veness of the complexity reduction scheme of Sec. III-E, for a dataset with M = 30 annotators with K = 3 classes with priors π = [0 . 3096 , 0 . 3416 , 0 . 3488] > , and a v arying number of data N . Annotators are split into L = { 1 , 2 , 4 , 5 } non- ov erlapping groups. Fig. 10 shows the classifcation ER and time (in seconds) required for the ensemble classification task, for different group sizes. When N is large we observe similar ER for all L , ho we ver larger number of groups require significantly less time than L = 1 . In all aforementioned experiments, all annotators were gen- erated to be better than random. The next experiment, in vesti- gates the ef fect of adversarial annotator s , that is annotators for who the largest values of the confusion matrix are not located on its diagonal. Let α denote the percentage of adversarial annotators. Fig. 11 shows the classification ER on a synthetic dataset with K = 3 , N = 10 6 , π = [0 . 31 , 0 . 34 , 0 . 35] > and M = 10 annotators, for varying α . While all approaches, with the exception of majority voting, seem to be robust to a small number of adversarial annotators, Alg. 2 can handle values of α of up to 50% , which speaks for the potential of the nov el 9 Algorithm N = 100 N = 1000 N = 10 4 N = 10 5 Majority V oting 6 . 3 7 . 08 7 . 04 7 . 13 KOS 27 . 70 33 . 33 32 . 21 32 . 53 EigenRatio 6 . 30 5 . 75 5 . 69 5 . 64 TE 4 . 20 4 . 91 4 . 61 4 . 67 SML 15 . 80 11 . 38 11 . 82 12 . 26 EM + MV 21 . 2 27 . 67 26 . 50 27 . 01 EM + Spectral 17 . 7 27 . 72 26 . 50 27 . 01 Alg. 2 ML 6 . 30 2 . 70 1 . 97 1 . 87 Alg. 2 MAP 2 . 40 1 . 40 1 . 13 1 . 11 Oracle ML 1 . 6 2 . 05 1 . 81 1 . 86 Oracle MAP 1 . 1 1 . 31 1 . 11 1 . 11 T ABLE I C L AS S I FI CATI O N E R F O R A S Y N T HE T I C DAT A S ET W I TH K = 2 , P R I OR P RO BA B I LI T I E S π = [0 . 9003 , 0 . 0997] > A N D M = 10 A N N OT A TO R S . Algorithm N = 100 N = 1000 N = 10 4 N = 10 5 Majority V oting 8 . 10 8 . 27 8 . 27 8 . 19 KOS 8 . 30 6 . 46 6 . 65 6 . 58 EigenRatio 7 . 40 6 . 35 6 . 39 6 . 21 TE 10 . 20 6 . 04 6 . 35 6 . 20 SML 13 . 10 8 . 47 4 . 66 4 . 61 EM + MV 6 . 60 5 . 15 4 . 93 4 . 87 EM + Spectral 6 . 60 5 . 15 4 . 93 4 . 87 Alg. 2 ML 6 . 50 4 . 86 4 . 66 4 . 61 Alg. 2 MAP 6 . 20 4 . 85 4 . 59 4 . 51 Oracle ML 4 . 10 4 . 86 4 . 66 4 . 61 Oracle MAP 3 . 90 4 . 81 4 . 58 4 . 50 T ABLE II C L AS S I FI CATI O N E R F O R A S Y N T HE T I C DAT A S ET W I TH K = 2 , P R I OR P RO BA B I LI T I E S π = [0 . 5856 , 0 . 4144] > A N D M = 10 A N N OT A TO R S . approach in adversarial learning setups [40], [41]. B. Real data Further tests were conducted using real datasets. In this case, in addition to other ensemble learning algorithms, the proposed methods are also compared to the single best annotator , that is the classifier that exhibited the highest accuracy . For all exper- iments, a collection of M = 15 classification algorithms from MA TLAB’ s machine learning toolbox were trained, each on a different randomly selected subset of the dataset. Afterwards, the algorithms provided labels for all data in each dataset. The classification algorithms considered were k -nearest neighbor classifiers, for varying number of neighbors k and different distance measures; support vector machine classifiers, utilizing different kernels; and decision trees with varying depth. The Algorithm N = 100 N = 1000 N = 10 4 N = 10 5 KOS 0 . 013 0 . 004 0 . 005 0 . 05 EigenRatio 0 . 003 0 . 002 0 . 005 0 . 03 TE 0 . 003 0 . 001 0 . 012 0 . 10 SML 0 . 04 0 . 09 0 . 76 11 . 98 EM + MV 0 . 01 0 . 02 0 . 12 1 . 47 EM + Spectral 1 . 48 1 . 55 1 . 58 3 . 00 Alg. 2 1 . 82 2 . 32 2 . 05 3 . 01 T ABLE III C L AS S I FI CATI O N T I M E ( I N S E C ON D S ) F O R A S Y NT H E T IC DAT A SE T W I TH K = 2 , P R IO R P RO BA B I LI T I E S π = [0 . 5856 , 0 . 4144] > A N D M = 10 A N NO T A TO R S . 100 1000 10000 100000 N 0 0.05 0.1 0.15 0.2 0.25 0.3 0.35 100 1000 10000 100000 N 0 0.005 0.01 0.015 0.02 0.025 0.03 0.035 0.04 Fig. 2. A verage estimation errors of confusion matrices (top); and prior probabilities (bottom), for two synthetic datasets with K = 2 and M = 10 annotators 10 3 10 4 10 5 10 6 N 20 30 40 50 60 70 80 Classification ER (%) Alg. 2 MAP Alg. 2 ML Alg. 2 fixed π Majority Vote KOS EM - MV EM - Spectral Oracle MAP Oracle ML Fig. 3. Classification ER for a synthetic dataset with K = 5 classes, priors π = [0 . 2404 , 0 . 2679 , 0 . 0731 , 0 . 1950 , 0 . 2236] > and M = 10 annotators. real datasets considered are the MNIST dataset [42], and 5 UCI datasets [43]: the CoverT ype database, the PokerHand dataset, the Connect- 4 dataset, the Magic dataset and the Dota 2 dataset. MNIST contains N = 70 , 000 28 × 28 images of handwritten digits, each belonging to one of K = 10 classes (one per digit). F or this dataset, each classification algorithm was trained on subsets of 2 , 000 instances. The Cov erT ype dataset consists of N = 581 , 012 data belonging to K = 7 classes. Each cluster corresponds to a dif ferent forest cov er type. Data are vectors of dimension D = 54 that contain cartographic variables, such as soil type, elev ation, hillshade etc. Here, each classification algorithm was trained on a subset of 1 , 000 instances. The PokerHand database contains N = 10 6 data belonging to K = 10 classes. Each datum is a 5 -card hand drawn from a deck of 52 cards, with each card being described by its rank and suit (spades, hearts, 10 10 3 10 4 10 5 10 6 N 20 40 60 80 100 Classification ER (%) Alg. 2 MAP Alg. 2 ML Alg. 2 fixed π Majority Vote KOS EM - MV EM - Spectral Oracle MAP Oracle ML Fig. 4. Classification ER for a synthetic dataset with K = 7 classes, priors π = [0 . 2347 , 0 . 0230 , 0 . 0705 , 0 . 1477 , 0 . 2659 , 0 . 0043 , 0 . 2539] > and M = 10 annotators. 1000 10000 100000 1e+06 N 0 0.2 0.4 0.6 0.8 1 Average k Γ m − ˆ Γ m k 1 Alg. 2 (K=5) Alg. 2 fixed π (K=5) Alg. 2 (K=7) Alg. 2 fixed π (K=7) 1000 10000 100000 1e+06 N 0 0.02 0.04 0.06 0.08 0.1 Average k π − ˆ π k 1 K=5 K=7 Fig. 5. A verage estimation errors of confusion matrices (top); and prior probabilities (bottom) for two synthetic datasets with K = 5 and K = 7 classes and M = 10 annotators diamonds, and clubs). Each class represents a valid Poker hand. For this experiment the 3 most pre valent classes are considered. Here, each classification algorithm was trained on a subset of 10 , 000 instances. Connect- 4 contains N = 67 , 557 vectors of size 42 × 1 , each representing the possible positions in a connect-4 game. These vectors belong to one of K = 3 classes, indicating whether the first player is in a position to win, lose, or, tie the game. Here, each classification algorithm was trained on a subset of 300 instances. The Magic dataset contains N = 19 , 020 data captured by ground-based atmo- spheric Cherenkov gamma-ray detector . The dataset contains K = 2 classes, each indicating the presence or abscence of Gamma rays. For this dataset, each classification algorithm was trained on subsets of 100 instances. The Dota 2 dataset contains N = 102 , 944 data, corresponding to different Dota Algorithm N = 1000 N = 10 4 N = 10 5 N = 10 6 KOS 0 . 016 0 . 02 0 . 17 2 . 03 EM + MV 0 . 04 0 . 27 3 . 43 37 . 27 EM + Spectral 119 . 35 124 . 94 119 . 35 160 . 54 Alg. 2 28 . 27 40 . 23 36 . 08 47 . 17 Alg. 2 fixed π 13 . 34 6 . 23 6 . 11 18 . 16 T ABLE IV C L AS S I FI CATI O N T I M E ( I N S E C ON D S ) F O R A S Y NT H E T IC DAT A SE T W I TH K = 5 C L AS S E S , P R I OR S π = [0 . 2404 , 0 . 2679 , 0 . 0731 , 0 . 1950 , 0 . 2236] > A N D M = 10 A N N OT A TO R S . Algorithm N = 1000 N = 10 4 N = 10 5 N = 10 6 KOS 0 . 017 0 . 025 0 . 23 2 . 83 EM + MV 0 . 05 0 . 30 4 . 80 48 . 87 EM + Spectral 619 . 61 616 . 47 621 . 30 676 . 95 Alg. 2 46 . 19 52 . 66 54 . 50 69 . 99 Alg. 2 fixed π 34 . 94 38 . 88 39 . 11 40 . 17 T ABLE V C L AS S I FI CATI O N T I M E ( I N S E C ON D S ) F O R A S Y NT H E T IC DAT A SE T W I TH K = 7 C L AS S E S , P R I OR S π = [0 . 2347 , 0 . 0230 , 0 . 0705 , 0 . 1477 , 0 . 2659 , 0 . 0043 , 0 . 2539] > A N D M = 10 A NN O T A T O R S . 2 games played, between two teams of 5 players. The dataset is split into K = 2 classes, corresponding to the team that won the game. Each datum consists of the starting parameters of each game, such as the game type (ranked or amateur) and which heroes were chosen from the players. Finally , for this dataset, each classification algorithm was trained on subsets of 5 , 000 instances. T able VIII lists classification ER results for the real data experiments. For most datasets, the proposed approaches out- perform the competing alternatives, as well as the single-best classifier . For the MNIST dataset the EM methods of [22] outperform our approaches. Nev ertheless, Alg. 1 comes very close to the performance of the EM schemes and if the confusion matrix estimates { ˆ Γ m } M m =1 of Alg. 2 are refined using EM, we also reach a classification ER of 6 . 23% . C. Cr owdsour cing data In this section, the proposed scheme of Sec. III-F is ev al- uated on crowdsourcing data. The datasets considered are the Adult dataset [44], the TREC dataset [45] and the Bird 5 10 15 20 25 30 M 0 10 20 30 40 50 Classification ER (%) Alg. 2 MAP Alg. 2 ML Majority Vote KOS EM - MV EM - Spectral Oracle MAP Oracle ML Fig. 6. Classification ER for a synthetic dataset with K = 3 classes, priors π = [0 . 2318 , 0 . 4713 , 0 . 2969] > and N = 10 6 data. 11 Dataset K Single best MV EigenRatio TE SML KOS EM + MV EM + Spectral Alg. 2 MAP Alg. 2 ML MNIST 10 7 . 29 7 . 0986 - - - 9 . 84 6 . 23 6 . 23 6 . 3986 6 . 3843 CoverT ype 7 29 . 89 28 . 642 - - - 31 . 13 58 . 68 95 . 62 28 . 574 28 . 913 PokerHand 3 41 . 95 43 . 365 - - - 49 . 62 53 . 62 78 . 38 39 . 436 39 . 339 Connect- 4 3 29 . 17 31 . 636 - - - 32 . 33 44 . 27 61 . 20 26 . 176 26 . 86 Magic 2 21 . 32 21 . 73 26 . 25 26 . 28 21 . 27 21 . 29 21 . 17 21 . 14 20 . 77 20 . 98 Dota 2 2 41 . 27 42 . 174 45 . 55 45 . 75 40 . 568 40 . 59 40 . 80 59 . 19 40 . 497 40 . 549 T ABLE VIII C L AS S I FI CATI O N E R F O R R E AL DAT A E X P E RI M E NT S W I TH M = 15 . Algorithm M = 5 M = 10 M = 20 M = 30 KOS 0 . 44 0 . 96 4 . 13 5 . 29 EM + MV 11 . 48 21 . 67 41 . 88 62 . 19 EM + Spectral 21 . 92 32 . 77 53 . 88 75 . 24 Alg. 2 4 . 85 15 . 43 83 . 73 271 . 71 T ABLE VI C L AS S I FI CATI O N T I M E ( I N S E C ON D S ) F O R A S Y NT H E T IC DAT A SE T W I TH K = 3 C L AS S E S , P R I OR S π = [0 . 2318 , 0 . 4713 , 0 . 2969] > A N D N = 10 6 DAT A . 5 10 15 20 25 30 M 0 20 40 60 80 Classification ER (%) Alg. 2 MAP Alg. 2 ML Majority Vote KOS EM - MV EM - Spectral Oracle MAP Oracle ML Fig. 7. Classification ER for a synthetic dataset with K = 5 classes, priors π = [0 . 3596 , 0 . 1553 , 0 . 1229 , 0 . 3258 , 0 . 0364] > and N = 10 6 data. dataset [46]. In most datasets, only a small set of ground-truth labels was av ailable, and the performance of each method was ev aluated on this set. For the Adult dataset, annotators were tasked with classify- ing N = 11 , 028 websites into K = 4 dif ferent classes, using Amazon’ s Mechanical Turk [5]. The 4 classes correspond to different le vels of adult content of a website. T o maintain reasonable computational complexity , we only considered an- notators that had given labels for all 4 classes and provided labels for more than 370 websites. For the TREC dataset, annotators from Amazon’ s Mechan- ical Turk [5] were tasked with classifying N = 19 , 033 Algorithm M = 5 M = 10 M = 20 M = 30 KOS 0 . 85 1 . 90 8 . 99 11 . 11 EM + MV 18 . 47 34 . 68 67 . 14 99 . 82 EM + Spectral 136 . 30 153 . 35 186 . 99 221 . 50 Alg. 2 12 . 92 28 . 89 150 . 33 471 . 22 T ABLE VII C L AS S I FI CATI O N T I M E ( I N S E C ON D S ) F O R A S Y NT H E T IC DAT A SE T W I TH K = 5 C L AS S E S , P R I OR S π = [0 . 3596 , 0 . 1553 , 0 . 1229 , 0 . 3258 , 0 . 0364] > A N D N = 10 6 DAT A . 5 10 15 20 25 30 M 0 20 40 60 80 Classification ER (%) Alg. 2 MAP Alg. 2 ML Majority Vote KOS EM - MV EM - Spectral Oracle MAP Oracle ML Fig. 8. Classification ER for a synthetic dataset with K = 5 classes, priors π = [0 . 3596 , 0 . 1553 , 0 . 1229 , 0 . 3258 , 0 . 0364] > and N = 5 , 000 data. 5 10 20 30 M 0 0.1 0.2 0.3 0.4 0.5 0.6 Average k Γ m − ˆ Γ m k 1 K = 3, N=10 6 K = 5, N=10 6 K = 5, N = 5,000 5 10 20 30 M 0 0.05 0.1 0.15 0.2 Average k π − ˆ π k 1 K = 3, N=10 6 K = 5, N=10 6 K=5, N=5,000 Fig. 9. A verage estimation errors of confusion matrices (top); and prior probabilities (bottom) for two synthetic datasets with K = 3 and K = 5 classes and N = 10 6 data, and a synthetic dataset with K = 5 classes and N = 5 , 000 data. websites into K = 2 classes: “rele vant” or “irrele v ant” to some search queries. Again, to maintain reasonable computational complexity for our approach, we only considered annotators that had gi ven labels for both classes and provided labels for more than 708 websites. 12 1000 10000 100000 1e+06 N 0 2 4 6 8 Classification ER (%) MAP (L=1) ML (L=1) MAP (L=2) ML (L=2) MAP (L=4) ML (L=4) MAP (L=5) ML (L=5) Majority Vote Oracle MAP Oracle ML 1000 10000 100000 1e+06 N 10 0 10 1 10 2 10 3 Time (s) L=1 L=2 L=4 L=5 Fig. 10. Classification ER (top); and time (in seconds) (bottom) for a synthetic dataset with K = 3 classes, priors π = [0 . 3096 , 0 . 3416 , 0 . 3488] > , M = 30 annotators for varying number of data N and annotator groups L . 10 15 20 25 30 35 40 45 50 α % 0 20 40 60 80 100 Classification ER (%) Alg. 2 MAP Alg. 2 ML Majority Vote KOS EM - MV EM - Spectral Oracle MAP Oracle ML Fig. 11. Classification ER for a synthetic dataset with K = 3 classes, priors π = [0 . 31 , 0 . 34 , 0 . 35] > , N = 10 6 , M = 10 annotators and varying percentage of adversarial annotators α . For the bird dataset, annotators from Amazon’ s Mechanical T urk were tasked with classifying N = 108 images of birds into K = 2 classes: “Indigo Bunting” or “Blue Grosbeak”. T able IX lists classification ER for the two cro wdsourcing experiments. The column “Labels” denotes the number of ground-truth labels available. As with the previous e xperi- ments, our approach exhibits lower classification ER than the competing alternati ves, in both multiclass and binary classification settings. V I . C O N C L U S I O N S A N D F U T U R E D I R E C T I O N S This paper introduced a nov el approach to blind ensemble and cro wdsourced classification that relies solely on anno- tator responses to assess their quality and combine their answers. Compact e xpressions of annotator moments, based on P ARAF A C tensor decompositions were deriv ed, and a novel moment matching scheme was de veloped using A O-ADMM. The performance of the novel algorithm was ev aluated on real and synthetic data. Sev eral interesting research venues open up: i) Distributed and online implementations of the proposed algorithm to fa- cilitate truly large-scale ensemble classification; ii) multiclass ensemble classification with dependent classifiers, along the lines of [47]; iii) ensemble clustering and regression; and i v) further in vestigation into the theoretical and practical implica- tions of adversarial annotators along with possible remedies. A P P E N D I X A A L G O R I T H M D E R I V AT I O N A. ADMM subproblem for π Consider the following problem that is equiv alent to (22) min π , φ g N , π ( φ ) + ρ C p ( π ) (28) s.to π = φ where φ is an auxiliary variable used to capture the smooth part of the optimization problem, and ρ C p is an indicator function for the constraints of (22), namely ρ C p ( u ) := ( 0 if u ∈ C p ∞ otherwise . (29) The augmented Lagrangian of (28) is then ` = g N , π ( φ ) + ρ C p ( π ) + λ 2 k π − φ + δ k 2 2 (30) where the K × 1 v ector δ contains the scaled Lagrange multipliers for subproblem (22). Per ADMM iteration, (30) is minimized w .r .t. φ and π before performing a gradient ascent step for δ . Specifically , the update for φ at iteration i + 1 is obtained by setting the gradient of ` w .r .t. φ to 0 , and solving for φ ; that is, ( λ + ν ) I + M X m =1 Γ > m Γ m + M X m =1 m 0 >m K > m 0 m K m 0 m + M X m =1 m 0 >m m 00 >m 0 ( Γ m 00 K m 0 m ) > ( Γ m 00 K m 0 m ) φ [ i + 1] = M X m =1 Γ > m µ m + M X m =1 m 0 >m K > m 0 m s mm 0 + ν π (prev) + λ ( π [ i ] + δ [ i ]) + X m =1 m 0 >m m 00 >m 0 ( Γ m 00 K m 0 m ) > t mm 0 m 00 , (31) where K mm 0 := Γ m Γ m 0 . Brackets here indicate ADMM iteration indices. Accordingly , the update for π is given by π [ i + 1] = P C p φ [ i + 1] − δ [ i ] (32) where P C p is the projection operator onto the con v ex set C p ; that is, φ [ i + 1] − δ [ i ] is projected onto the probability simple x. 13 Dataset N K M Labels MV EigenRatio TE SML KOS EM + MV EM + Spectral Alg. 2 MAP Alg. 2 ML Adult 11 , 028 4 38 347 36 . 023 - - - 80 . 98 40 . 63 38 . 90 33 . 429 34 . 87 TREC 19 , 033 2 23 2 , 275 50 . 002 43 . 34 48 . 97 48 . 44 54 . 68 56 . 04 40 . 62 37 . 846 39 . 824 Bird 108 2 39 108 24 . 07 27 . 78 17 . 59 11 . 11 11 . 11 11 . 11 10 . 19 10 . 19 10 . 19 T ABLE IX C L AS S I FI CATI O N E R F O R C ROW D S O UR C I N G DAT A E X P ER I M E NT S . This projection can be performed using efficient methods [48]. Finally , a gradient ascent step is performed for δ as δ [ i + 1] = δ [ i ] + π [ i + 1] − φ [ i + 1] . (33) Note that products of the form K > m 0 m K m 0 m = ( Γ m Γ m 0 ) > ( Γ m Γ m 0 ) can be ef ficiently computed by using the following observ ation: ( Γ m Γ m 0 ) > ( Γ m Γ m 0 ) = ( Γ > m Γ m ) ∗ ( Γ > m 0 Γ m 0 ) , where ∗ denotes the elementwise matrix product [11]. In addition, the products Γ > m Γ m do not hav e to be explicitly computed each time (28) is solved, as they can be cached every time (34) is solved. As suggested in [28], the maximum number of ADMM iterations, I , for each subproblem can be set to be small, e.g. I = 10 . B. ADMM subproblem for Γ m Proceeding along similar lines with the previous subsection, consider the following problem which is equiv alent to (23) min Γ m , Φ ¯ g N ,m ( Γ m , Φ ) (34) s.to Γ m = Φ > where Φ is an auxiliary variable used to capture the smooth part of the optimization problem in (23), and ¯ g N ,m ( Γ m , Φ ) = g N ,m ( Φ > ) + ρ C ( Γ m ) . The augmented Lagrangian of (34) is then ` 0 = ¯ g N ,m ( Γ m , Φ ) + λ 2 k Γ m − Φ > + ∆ m k 2 F (35) where the K × K matrix ∆ m contains the scaled Lagrange multipliers for subproblem (23), and λ is a positive scalar . As in the previous section, per ADMM iteration, (35) is minimized with respect to (w .r .t.) Φ and Γ m before performing a gradient ascent step for ∆ m . Specifically , the update for Φ at iteration i + 1 is obtained by setting the gradient of ` 0 w .r .t. Φ to 0 , and solving for Φ . Since S m 0 m = S > mm 0 and Π = Π > , it is easy to see that the update w .r .t. Φ can be expressed as ( λ + ν ) I + π π > + M X m 0 6 = m ΠΓ > m 0 Γ m 0 Π + X m 0 >m m 00 >m 0 ΠK > m 00 m 0 K m 00 m 0 Π Φ [ i + 1] = π µ > m + M X m 0 6 = m ΠΓ > m 0 S m 0 m + X m 0 >m m 00 >m 0 ΠK > m 00 m 0 T (1) mm 0 m 00 + ν Γ (prev) m > + λ ( Γ m [ i ] + ∆ m [ i ]) > . (36) Accordingly , the update for Γ m is giv en by Γ m [ i + 1] = P C Φ > [ i + 1] − ∆ m [ i ] (37) where P C is the projection operator onto the conv e x set C with each column of Φ > [ i + 1] − ∆ m [ i ] projected onto the probability simplex. Finally , a gradient ascent step is performed per ∆ m , as follows ∆ m [ i + 1] = ∆ m [ i ] + Γ m [ i + 1] − Φ > [ i + 1] . (38) C. Algorithm complexity For the ADMM subproblems of Apps. A-A and A-B the complexity per iteration is dominated by the matrix in versions required in (31) and (36) respectiv ely , that is O ( K 3 ) . Ho we ver , in order to instantiate the left- and right-hand sides of (31), O ( M 3 K 2 ) and O ( M 3 K 4 ) operations are required respec- tiv ely . These operations hav e to be performed only once and cached to be used in each iteration. The increased complexity of the right-hand side is due to the matricized tensor times Khatri-Rao product (MTTKRP) ( Γ m 00 K m 0 m ) > t mm 0 m 00 . These MTTKRPs howe v er , can be computed efficiently due to the Khatri-Rao structure, and are easily parallelizable, see e.g. [49]. This brings the ov erall complexity of App. A-A to O ( M 3 K 4 + I K 3 ) , with I denoting the number of ADMM iterations. Accordingly , the operations required to instantiate the left- and right-hand sides of (36) are O ( M 2 K 2 ) and O ( M 2 K 4 ) respectively . This brings the total complexity of App. A-B to O ( M 2 K 4 + I K 3 ) . As the number of iterations for the ADMM algorithms of Apps. A-A and A-B is set to be small the overall computational complexity of Alg. 1 is O ( I T M 3 K 4 ) , where I T is the number of A O-ADMM iterations required until con ver gence. Furthermore, the number of tensors T mm 0 m 00 required to solve (21) is M 3 , while the number of matrices S mm 0 required is M 2 , and the number of vectors µ m is M . Thus, for K classes, the memory needed for storing all the tensors, ma- trices and vectors in volv ed is O M 3 K 3 + M 2 K 2 + M K . Finally , computing the cross-correlation tensors, matrices and mean vectors of annotators incurs a comple xity of O ( M 3 K N ) as each of the annotator response matrices { F m } M m =1 is of size K × N and has N nonzero entries. A P P E N D I X B P RO O F S Proof of Lemma 1. Suppose that rank ( Γ m ) = rank ( Γ m 0 ) = rank ( Γ m 00 ) = K , for some m 6 = m 0 , m 00 and m 0 6 = m 00 . Then by [11, Thm. 2] the decomposition of Ψ mm 0 m 00 is essentially unique . Inv oking [36, Prop 4.10] the joint tensor 14 decomposition of (21) is essentially unique , meaning the solutions of (21) will be of the form ˆ Γ m = Γ ∗ m PΛ m , m = 1 , . . . , M , ˆ π = ΛP > π ∗ where P is a permutation matrix, and { Λ m } M m =1 , Λ are diagonal scaling matrices such that Λ m Λ m 0 Λ m 00 = Λ − 1 , for m 6 = m 0 , m 00 , m 0 6 = m 00 . Since { ˆ Γ m } and ˆ π are the solutions to (21), they must satisfy the constraints of the optimization problem; that is ˆ Γ m ∈ C m = 1 , . . . , M and ˆ π ∈ C p . Since Γ ∗ m > 1 = 1 for all m , and P > 1 = 1 , we have ˆ Γ > m 1 = 1 ⇒ Λ m P > Γ ∗ m > 1 = 1 ⇒ Λ m 1 = 1 m = 1 , . . . , M which implies that Λ m = I for m = 1 , . . . , M . Since Λ m Λ m 0 Λ m 00 = Λ − 1 , for m 6 = m 0 , m 00 , m 0 6 = m 00 , we arriv e at Λ = I . Thus, the constraints of (21) solve the possible scaling ambiguities. Letting ˆ P = P > = P − 1 , we arrive at the statement of the lemma. Proof of Theorem 1. For notational con v enience, collect all optimization variables in θ , and denote the aggregated con- straint set as ¯ C . Note that ¯ C is a compact set, since the probability simplex is compact and ¯ C is an intersection of simplex es. Since h N ( θ ) is continuous and ¯ C is compact, h N ( θ ) is uniformly continuous on ¯ C , that is, ∀ ε > 0 there exists a neighborhood V of ˜ θ such that sup θ ∈V ∩ ¯ C | h N ( θ ) − h N ( ˜ θ ) | < ε/ 2 . (39) Due to the compactness of ¯ C there exist a finite number of points θ 1 , . . . , θ L ∈ ¯ C , with corresponding neighborhoods V 1 , . . . , V L that cover ¯ C , that is sup θ ∈V ` ∩ ¯ C | h N ( θ ) − h N ( θ ` ) | < ε/ 2 , for ` = 1 , . . . , L. (40) In v oking the LLN, it is straightforward to sho w that, for sufficiently large N , w .p. 1 | h N ( θ ` ) − h ∞ ( θ ` ) | < ε/ 2 , for ` = 1 , . . . , L. (41) Using the triangle inequality along with (40), and (41) we ha ve sup θ ∈ ¯ C | h N ( θ ) − h ∞ ( θ ) | < ε, (42) that is, for suf ficiently large N , h N con v erges uniformly to h ∞ on ¯ C . Then, by [38, Thm. 5.3] we hav e that D ( S N , S ∗ ) → 0 as N → ∞ . Proof of Theorem 2. Let ¯ L ( x | k ) = L ( x | k ) π k , with L ( x | k ) as defined in Sec. III-A. Then the av erage probability of error of the MAP detector can be expressed as P e = K X k =1 P e , k π k (43) where P e , k = Pr( ¯ L ( x | k ) < ¯ L ( x | k 0 ) , k 0 6 = k | Y = k ) . By applying a union bound on P e , k it is easy to show that P e , k ≤ X k 0 6 = k Pr( ¯ L ( x | k ) < ¯ L ( x | k 0 ) | Y = k ) . (44) Defining P ¯ L ( k , k 0 ) := Pr( ¯ L ( x | k ) < ¯ L ( x | k 0 ) | Y = k ) , substituting (44) in (43) and grouping terms we hav e P e ≤ K X k =1 K X k 0 >k π k P ¯ L ( k , k 0 ) + π k 0 P ¯ L ( k 0 , k ) . (45) Consider now the binary hypothesis testing problem between classes k and k 0 6 = k . The av erage probability of error of a MAP detector for the binary problem is P e ( k , k 0 ) = π k π k + π k 0 P ¯ L ( k , k 0 ) + π k 0 π k + π k 0 P ¯ L ( k 0 , k ) . (46) Then π k P ¯ L ( k , k 0 ) + π k 0 P ¯ L ( k 0 , k ) = ( π k + π k 0 )P e ( k , k 0 ) ≤ P e ( k , k 0 ) (47) where the inequality is due to π k + π k 0 ≤ 1 . Combining (47) with (45) yields P e ≤ K X k =1 K X k 0 >k P e ( k , k 0 ) . (48) Therefore, we hav e upper bounded the average probability of error of our M -class hypothesis testing problem by the av- erage error probabilities of binary hypothesis testing problems. For the binary hypothesis testing problem between classes k and k 0 6 = k , collect all annotator responses in an M × 1 vector ˜ f and define two complementary regions R and R C as R = { ˜ f : ¯ L ( x | k ) < ¯ L ( x | k 0 ) } (49a) R C = { ˜ f : ¯ L ( x | k 0 ) < ¯ L ( x | k ) } . (49b) Upon defining ˜ π k,k 0 = π k π k + π k 0 and using (49), (46) can be rewritten as P e ( k , k 0 ) = Pr( ˜ f ∈ R| Y = k ) ˜ π k,k 0 + Pr( ˜ f ∈ R C | Y = k 0 ) ˜ π k 0 ,k = M Y m =1 Pr([ ˜ f ] m ∈ R m | Y = k ) ˜ π k,k 0 + M Y m =1 Pr([ ˜ f ] m ∈ R C m | Y = k 0 ) ˜ π k 0 ,k (50) where the second equality follows from As. 1 and R m , R C m denote the subsets of R , R C corresponding to the m -th entry of ˜ f , respectiv ely . Now let m ∗ = arg max m Pr([ ˜ f ] m ∈ R m | Y = k ) M ˜ π k,k 0 (51) + Pr([ ˜ f ] m ∈ R C m | Y = k 0 ) M ˜ π k 0 ,k and define ¯ P e ( k , k 0 ) = Pr([ ˜ f ] m ∗ ∈ R m ∗ | Y = k ) M ˜ π k,k 0 + Pr([ ˜ f ] m ∗ ∈ R C m ∗ | Y = k 0 ) M ˜ π k 0 ,k . (52) Clearly P e ( k , k 0 ) ≤ ¯ P e ( k , k 0 ) . From standard results in detec- tion theory (52) can be bounded as [50], [51] ¯ P e ( k , k 0 ) ≤ exp( − M d ( p || q )) (53) where p := Pr([ ˜ f ] m ∗ ∈ R m ∗ | Y = k ) , q := Pr([ ˜ f ] m ∗ ∈ R C m ∗ | Y = k 0 ) , and d ( p || q ) denotes the Chernof f information between pdfs p and q . Combining (53) with (48) yields the claim of the theorem. 15 R E F E R E N C E S [1] F . Wright, C. De V ito, B. Langer, A. Hunter et al. , “Multidisciplinary cancer conferences: A systematic revie w and development of practice standards, ” European Journal of Cancer , vol. 43, pp. 1002–1010, 2007. [2] M. Micsinai, F . Parisi, F . Strino, P . Asp, B. D. Dynlacht, and Y . Kluger, “Picking chip-seq peak detectors for analyzing chromatin modification experiments, ” Nucleic Acids Resear ch , vol. 40, no. 9, May 2012. [3] A. T immermann, “Forecast combinations, ” Handbook of Economic F orecasting , vol. 1, pp. 135–196, 2006. [4] D. C. Brabham, “Crowdsourcing as a model for problem solving: An introduction and cases, ” Conver gence , vol. 14, no. 1, pp. 75–90, 2008. [5] A. Kittur, E. H. Chi, and B. Suh, “Crowdsourcing user studies with mechanical turk, ” in Proc. of SIGCHI Conf. on Human F actors in Computing Systems . Florence, Italy: A CM, 2008, pp. 453–456. [6] J. N. Tsitsiklis, “Decentralized detection, ” Advances in Statistical Signal Pr ocessing , vol. 2, no. 2, pp. 297–344, 1993. [7] P . K. V arshney , Distributed Detection and Data Fusion . Springer Science & Business Media, 2012. [8] T . Berger , Z. Zhang, and H. V iswanathan, “The CEO problem, ” IEEE T r ansactions on Information Theory , vol. 42, no. 3, pp. 887–902, 1996. [9] T . G. Dietterich, “Ensemble methods in machine learning, ” in Intl. W orkshop on Multiple Classifier Systems . Springer , 2000, pp. 1–15. [10] Y . Freund, R. E. Schapire et al. , “Experiments with a new boosting algorithm, ” in Pr oc. of the Intl. Conf. on Machine Learning , vol. 96, Bari, Italy , 1996, pp. 148–156. [11] N. D. Sidiropoulos, L. De Lathauwer, X. Fu, K. Huang, E. E. Papalex- akis, and C. Faloutsos, “T ensor decomposition for signal processing and machine learning, ” IEEE T ransactions on Signal Pr ocessing , vol. 65, no. 13, pp. 3551–3582, 2017. [12] N. Kargas and N. D. Sidiropoulos, “Completing a joint pmf from projec- tions: a low-rank coupled tensor factorization approach, ” in Information Theory and Applications W orkshop . IEEE, 2017. [13] L. Breiman, “Random forests, ” Machine Learning , vol. 45, no. 1, pp. 5–32, 2001. [14] A. P . Dawid and A. M. Skene, “Maximum likelihood estimation of observer error-rates using the EM algorithm, ” Applied Statistics , pp. 20– 28, 1979. [15] A. Ghosh, S. Kale, and P . McAfee, “Who moderates the moderators?: Crowdsourcing abuse detection in user-generated content, ” in Proceed- ings of the 12th ACM Confer ence on Electr onic Commerce . San Jose, CA: A CM, 2011, pp. 167–176. [16] N. Dalvi, A. Dasgupta, R. Kumar , and V . Rastogi, “ Aggregating crowd- sourced binary ratings, ” in Proceedings of the Intl. Conf. on W orld W ide W eb . Rio de Janeiro, Brazil: ACM, 2013, pp. 285–294. [17] D. R. Karger , S. Oh, and D. Shah, “Efficient crowdsourcing for multi- class labeling, ” ACM SIGMETRICS P erformance Evaluation Review , vol. 41, no. 1, pp. 81–92, 2013. [18] F . Parisi, F . Strino, B. Nadler, and Y . Kluger, “Ranking and combining multiple predictors without labeled data, ” Proc. of the Ntl. Academy of Sciences , vol. 111, no. 4, pp. 1253–1258, 2014. [19] A. Jaffe, B. Nadler, and Y . Kluger , “Estimating the accuracies of multiple classifiers without labeled data. ” in AIST A TS , vol. 2, San Diego, CA, 2015, p. 4. [20] T . Bonald and R. Combes, “ A minimax optimal algorithm for crowdsourcing, ” in Advances in Neural Information Processing Systems 30 , I. Guyon, U. V . Luxburg, S. Bengio, H. W allach, R. Fergus, S. V ishwanathan, and R. Garnett, Eds. Curran Associates, Inc., 2017, pp. 4352–4360. [Online]. A vailable: http://papers.nips.cc/paper/7022-a- minimax-optimal-algorithm-for-cro wdsourcing.pdf [21] P . Jain and S. Oh, “Learning mixtures of discrete product distributions using spectral decompositions. ” Journal of Machine Learning Resear ch , vol. 35, pp. 824–856, 2014. [22] Y . Zhang, X. Chen, D. Zhou, and M. I. Jordan, “Spectral methods meet EM: A prov ably optimal algorithm for crowdsourcing, ” in Advances in Neural Information Processing Systems , 2014, pp. 1260–1268. [23] M. Kim, “ A maximum-likelihood and moment-matching density estima- tor for crowd-sourcing label prediction, ” Applied Intelligence , vol. 48, no. 2, pp. 381–389, Feb 2018. [24] P . A. Trag anitis, A. Pag ` es-Zamora, and G. B. Giannakis, “Learning from unequally reliable blind ensembles of classifiers, ” in Pr oc. of the 5th IEEE Global Conference on Signal and Information Pr ocessing . Montreal, CA: IEEE, 2017. [25] R. A. Harshman and M. E. Lundy , “P ARAF AC: Parallel factor analysis, ” Computational Statistics & Data Analysis , vol. 18, no. 1, pp. 39–72, 1994. [26] C. A. Andersson and R. Bro, “The N-way toolbox for MA TLAB, ” Chemometrics and Intelligent Laboratory Systems , vol. 52, no. 1, pp. 1–4, 2000. [27] N. V ervliet, O. Debals, L. Sorber, M. V an Barel, and L. De Lathauwer, “T ensorlab 3.0, ” available online, URL: www . tensorlab. net , 2016. [28] K. Huang, N. D. Sidiropoulos, and A. P . Liavas, “ A flexible and efficient algorithmic framework for constrained matrix and tensor factorization, ” IEEE T ransactions on Signal Pr ocessing , vol. 64, no. 19, pp. 5052–5065, 2016. [29] S. M. Kay , Fundamentals of Statistical Signal Processing, volume II: Detection Theory . Prentice Hall, 1998. [30] ——, Fundamentals of Statistical Signal Processing, volume I: Estima- tion Theory . Prentice Hall, 1993. [31] N. Parikh, S. Boyd et al. , “Proximal algorithms, ” F oundations and T r ends R in Optimization , vol. 1, no. 3, pp. 127–239, 2014. [32] D. P . Bertsekas, Nonlinear Progr amming . Athena scientific, 1999. [33] W . Liu, J. He, and S.-F . Chang, “Large graph construction for scalable semi-supervised learning, ” in Pr oceedings of Intl. Conf. on Machine Learning , 2010, pp. 679–686. [34] G. B. Giannakis, Q. Ling, G. Mateos, I. D. Schizas, and H. Zhu, “Decentralized learning for wireless communications and networking, ” in Splitting Methods in Communication and Imaging, Science and Engineering , R. Glo winski, S. Osher , and W . Y in, Eds. Springer, 2016. [35] M. Razaviyayn, M. Hong, and Z.-Q. Luo, “ A unified conv ergence analysis of block successiv e minimization methods for nonsmooth optimization, ” SIAM Journal on Optimization , vol. 23, no. 2, pp. 1126– 1153, 2013. [36] M. Sørensen and L. De Lathauwer, “Coupled canonical polyadic decompositions and (coupled) decompositions in multilinear rank- ( L r,n , L r,n , 1) terms—part I: Uniqueness, ” SIAM Journal on Matrix Analysis and Applications , vol. 36, no. 2, pp. 496–522, 2015. [37] V . V apnik, The Nature of Statistical Learning Theory . Springer Science and Business Media, 2013. [38] A. Shapiro, D. Dentche va, and A. Ruszczy ´ nski, Lectures on Stochastic Pr ogr amming: Modeling and Theory . SIAM, 2009. [39] MA TLAB, version 8.6.0 (R2015b) . Natick, Massachusetts: The Math- W orks Inc., 2015. [40] B. Biggio, G. Fumera, and F . Roli, “Multiple classifier systems for rob ust classifier design in adversarial environments, ” International Journal of Machine Learning and Cybernetics , vol. 1, no. 1-4, pp. 27–41, 2010. [41] D. Chinavle, P . Kolari, T . Oates, and T . Finin, “Ensembles in adversarial classification for spam, ” in Proc. of the ACM Conf. on Information and Knowledge Management . Hong Kong: A CM, 2009, pp. 2015–2018. [42] Y . LeCun, L. Bottou, Y . Bengio, and P . Haf fner , “Gradient-based learning applied to document recognition, ” Pr oceedings of the IEEE , vol. 86, no. 11, pp. 2278–2324, 1998. [43] M. Lichman, “UCI machine learning repository , ” 2013. [Online]. A vailable: http://archive.ics.uci.edu/ml [44] V . S. Sheng, F . Pro vost, and P . G. Ipeirotis, “Get another label? improving data quality and data mining using multiple, noisy labelers, ” in Pr oceedings of the 14th ACM SIGKDD Intl. Conf. on Knowledge Discovery and Data Mining . Las V egas, NV : ACM, 2008, pp. 614– 622. [45] C. Buckley , M. Lease, and M. D. Smucker , “Overview of the TREC 2010 Relev ance Feedback Track (Notebook), ” in The Nineteenth T ext Retrieval Conference (TREC) Notebook , 2010. [46] P . W elinder, S. Branson, P . Perona, and S. J. Belongie, “The mul- tidimensional wisdom of crowds, ” in Advances in Neural Information Pr ocessing Systems 23 , J. D. Lafferty , C. K. I. Williams, J. Shawe- T aylor , R. S. Zemel, and A. Culotta, Eds. Curran Associates, Inc., 2010, pp. 2424–2432. [Online]. A v ailable: http://papers.nips.cc/paper/4074- the-multidimensional-wisdom-of-crowds.pdf [47] A. Jaf fe, E. Fetaya, B. Nadler , T . Jiang, and Y . Kluger, “Unsupervised ensemble learning with dependent classifiers, ” in Artificial Intelligence and Statistics , 2016, pp. 351–360. [48] J. Duchi, S. Shalev-Shw artz, Y . Singer, and T . Chandra, “Efficient projections onto the l1-ball for learning in high dimensions, ” in Pr oc. of the Intl. Conf, on Machine Learning . Helsinki, Finland: A CM, 2008, pp. 272–279. [49] B. W . Bader and T . G. K olda, “Ef ficient matlab computations with sparse and factored tensors, ” SIAM Journal on Scientific Computing , vol. 30, no. 1, pp. 205–231, 2008. [50] H. V . Poor, An Introduction to Signal Detection and Estimation . Springer Science & Business Media, 2013. [51] T . M. Cover and J. A. Thomas, Elements of Information Theory . John W iley & Sons, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment