A Comparison of Adaptation Techniques and Recurrent Neural Network Architectures
Recently, recurrent neural networks have become state-of-the-art in acoustic modeling for automatic speech recognition. The long short-term memory (LSTM) units are the most popular ones. However, alternative units like gated recurrent unit (GRU) and …
Authors: Jan Vanek, Josef Michalek, Jan Zelinka
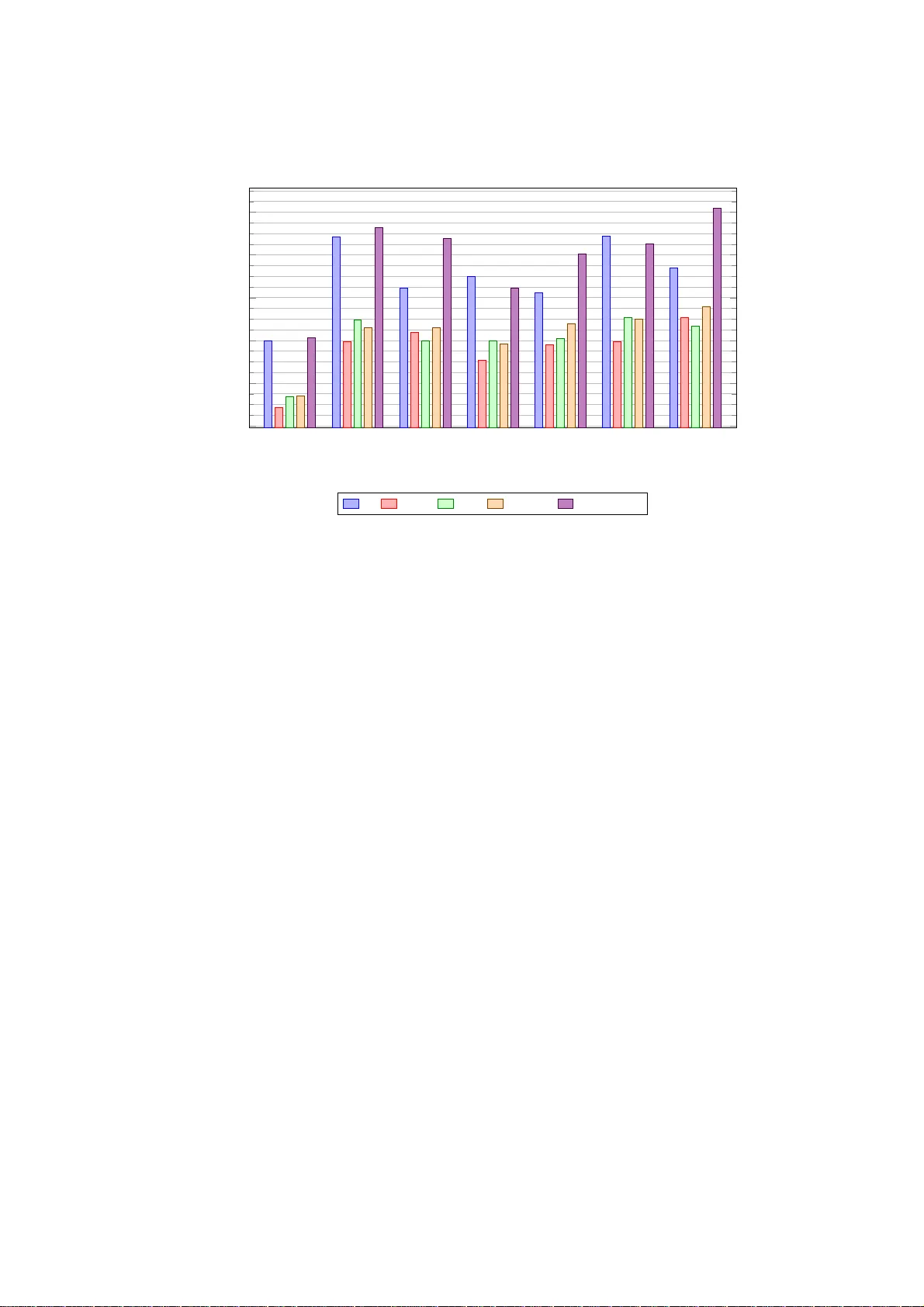
A Comparison of Adaptation T ec hniques and Recurren t Neural Net w ork Arc hitectures Jan V anˇ ek [0000 − 0002 − 2639 − 6731] , Josef Mich´ alek [0000 − 0001 − 7757 − 3163] , Jan Zelink a [0000 − 0001 − 6834 − 9178] , and Josef Psutk a [0000 − 0002 − 0764 − 3207] Universit y of W est Bohemia Univerzitn ´ ı 8, 301 00 Pilsen, Czech Republic { vanekyj, orcus,zelinka,psut ka } @kky.zcu.cz Abstract. Recently , recurrent neural netw orks h a ve b ecome state-of- the-art in acoustic mo deling for automatic sp eech reco gnition. The long short-term memory (LSTM) units are the most p opular ones. How ever, alternativ e units like gated recurrent unit (GR U) and its mo difications outp erformed LS TM in some pu blications. In this pap er, w e compared five neural netw ork (NN ) architectures with vari ous adaptation and fea- ture normalization techniques. W e hav e ev aluated feature-space maxi- mum lik eliho o d linear regression, five v arian ts of i-vector adaptation and tw o va riants of cepstral mean normalization. The most adaptation and normalization techniques were developed for feed-forw ard NNs and, ac- cording t o results in th is pap er, not all of them work ed also with RNNs. F or exp eriments, w e hav e c hosen a w ell known and av ailable TIMIT phone recognition task. The phone recognition is muc h more sensitive t o the qualit y of AM than large vocabulary task with a complex language mod el. Also, w e p u blished the op en -source scripts to easily rep licate the results and to help contin ue the d evelo p ment. Keywords: neural netw orks · acoustic mo del · TIMIT · LSTM · GRU · phone recognition · adaptation · i-vectors 1 In tro duction Neural Netw or ks (NNs) and deep NNs (DNNs) b ecame dominant in the field of the acoustic mo deling several y ears ago. Simple feed-forward (FF) DNNs were faded aw ay in r ecent years. The curren t pr ogress is based on the modeling of a longer tempor al con text of individual feature frames. Ma in t wo ways ar e actu- ally p o pula r: First, a larger co nt ex t is modeled b y a time-delay ed NN (TDNN) [16], [9]. TDNNs mo del long term tempo ral dep endencies with training times comparable to standard feed-forward DNNs. In the TDNN ar chit e cture, the ini- tial transforms learn narrow co nt e x ts and the dee p er lay er s process the hidden activ ations from a wider temp oral context. Hence the higher lay ers hav e the ability to lea r n wider tempo ral relations hips. The s econd wa y to lea rn the longer tempo ral co nt ex t is to use recurre nt NNs (RNNs). The most p opular RNN ar chi- tecture is a long shor t- term memor y (LSTM) that has b een desig ned to addres s 2 J. V an ˇ ek, J. Mic h´ a lek, J. Zelink a, J. Psutk a the v anishing and explo ding g radient problems of conv entional RNNs. Unlike feed-forward neura l net works, RNNs have cyclic connec tio ns making them pow- erful for mo deling s equences [12]. The main drawback is muc h slow er training due to the sequential nature of t he lear ning a lgorithm. An unfolding of t he re- current netw or k during training w as prop osed in [1 3] to sp eed-up the training, how ever it is still significantly slow er than FF NNs or TDNNs. More r ecently , another t yp e of recur rent unit, a g ated r ecurrent unit (G RU), w as propo s ed in [2], [3]. Similarly to the LSTM unit, the GRU has g a ting units that mo dulate the flow of info r mation inside the unit, how ever, without having a se pa rate mem- ory cells. F urther revising GR Us leaded t o a simplified ar chitecture po tentially more suitable fo r s p eech recog nitio n in [11]. Firs t, removing the rese t gate in the GR U design resulted in a simpler single -gate architecture ca lled mo dified GR U (M-GR U). Seco nd, r eplacing tanh with R eLU activ ations in the sta te up date equations was prop ose d and called M-reluGRU. A more detailed ov erv ie w o f the RNN architectures follows in Section 3. Even if larg e datasets are used for the DNN training, an adaptation of a n acoustic mo del (AM) to a test sp eaker and en v ir onment is b eneficial. A lot of techn iq ues hav e b een rep or ted on the adaptation, such as the cla ssical maxi- m um a pos terior (MAP) and maximum likelihoo d linear regressio n (MLLR) for traditional GMM-HMM acoustic mo dels . Although this technique can b e mod- ified f o r a n NN-based acoustic mo del, a muc h s impler application ha s so-ca lled feature space MLLR (fMLLR) [4] b ecause fMLLR changes only features a nd it do e s not a da pt NN para meter s. This s p ea ker adaptation tec hnique can b e easily applied in an NN-bas e d acoustic model [15], [8], [10]. Therefore, fMLLR can b e used to a ny DNN ar chitecture. I-vectors or iginally develope d for sp eaker recognition can b e used to the s pe a ker and environment adaptation als o [14], [7]. Alternative a pproach is using of dis c riminative sp e a ker co des [17], [6]. Mo re detailed description of the adaptation techniques used in this pa pe r follows. 2 Adaptation of DNNs The simples t way of the adapta tion is a feature level adaptatio n. When ada pting input features, NN can hav e an y structur e. The most popula r a nd w ell known techn iq ue is fMLLR base d o n an underlying HMM-GMM that is us ed during initial stage of the NN training. 2.1 fMLLR The fMLLR transforms feature frames with a s pe a ker-spec ific square matrix A and a bia s b . F or HMM-GMMs, A and b are e s timated to maximize the like- liho o d o f the a daptation data given the mo del [4], [15 ]. In the tra ining phase, the sp ea ker-specific tr ansform may b e updated several-times alternating HMM- GMM update. Thes e approach is usually called a speaker adaptive training (SA T). The result o f the training phas e is a canonical mo del that require s us- ing adaptation during testing phase. How ever, t wo-pass pro cessing is re q uired A Comparison of Adaptation T echniques and RNN Architectures 3 during tes t pha se. The first pa ss pr o duces uns up er vised a lignment that is used to estimate the transform par ameters via maximum likeliho o d. The mo del used for a lignment do es not need to b e the iden tica l mo del to the final canonical o ne. Because all the steps ar e using the underline HMM-GMM an y NN architecture may b e used to train the final NN acoustic mo del. 2.2 i-v ectors The i-vector extraction is a w ell known tec hnique, so we focused he r e to more practical p oints. An detailed description of i-vectors can b e found in [14], [7] and further pap ers referenced in there. The i- vector extraction is comprised from following steps : 1. An universal ba ckground model (UBM) nee ds to b e trained. Usua lly a GMM with 5 12 to 2048 dia gonal co mpo nents is used. The qua lity of GMM is not critical, so some sp eed-up metho ds can b e utilized. F eatur es for UBM do not need to match witch fea tures for NN nor i-vector a ccumulators. Usu- ally , features with cepstr al mean normalization (CMN) or cepstral mean and v ariance normaliz ation (CMVN) a re used for UBM. The nor malization techn iq ues reduce sp eaker and environment v ariability . F eatures without any normalizatio n are used for the i-vector a ccumulators to carry more sp eaker- and environmen t-r elated information. 2. Zero-order and centered first-or der statistics are accumulated for every speaker according to the UBM po steriors . 3. The i-vector extraction tra nsforms are estimated itera tively b y exp e cta- tion/maximization (EM) algor ithm. 4. The i-vector for individual sp eakers is ev aluated. F or tr a ining sp eakers, zero- order and centered fir st-order statistics hav e b een alr e ady accumulated. F or other s p e a kers, statistics must b e accum ulated. Then, the i-v ector is ev alu- ated by the i-vector extra ction transforms computed in the thir d step. The four step pro cess seems simple but there are so me details that need to be men tio ned: – CMN or CMVN may b e computed online o r offline. The o ffline v ariant may be p er-utter ance o r per-s pea ker. The online v aria nt starts from glo ba l cep- stral mean a nd it is subsequen tly up dated. An expo nential forgetting is us- able for very lo ng utterances. The training setup should match with the testing one. – The accumulated statistic should b e sa turated or sca le d-down for long ut- terances due to an i-vector ov erfitting. – The offline sce na rio is not proper f o r training . The n umber o f sp eakers and th us v ariants of i-vectors is very limited a nd leads to NN overfitting. The online s cenario is recommended for tra ining , in the Ka ldi Switch b oard exam- ple recipe the n umber of sp eakers is also bo os ted b y pseudo-spea kers. Tw o training utterances represent one pseudo-s p e a ker. The offline scenario may be used in the test phase. 4 J. V an ˇ ek, J. Mic h´ a lek, J. Zelink a, J. Psutk a 3 Recurren t Neural N et work Architectures 3.1 Long Short-T erm Memory Long shor t- term memor y (LSTM) is a widely used type of r ecurrent neural net- work (RNN). Standard RNNs suffer from b oth explo ding a nd v anishing gr adient problems. Bo th of these problems a re cause d by the fact, that infor mation flowing through the RNN passes throug h many s tages of mu ltiplica tion. The gr adient is essentially equal to the weigh t ma tr ix r aised to a high p ower. This re sults in the gradient growing or shrinking at an exp onential r ate to the num ber o f timesteps. The explo ding gradient problem can b e solved simply by truncating the gra- dient . On the other hand, the v anishing g r adient pro ble m is har der to overcome. It do es not simply ca use the gradient to b e small; the gradient co mpo nents corres p o nding to long-term dep endencies ar e s mall while the comp onents corre- sp onding to sho r t-term depe ndencies are larg e. Resulting RNN can then lea rn short-term dependencie s but not long-ter m dep endencies . The LSTM was prop osed in 199 7 b y Ho chreiter and Scmidhuber [5] as a solution to the v anishing gradient pr oblem. Let c t denote a hidden s ta te of a LSTM. The main idea is that instead of computing c t directly from c t − 1 with matrix-vector pro duct follo wed by an activ atio n f unctio n, th e LSTM computes ∆c t and adds it to c t − 1 to get c t . The addition op eratio n is wha t eliminates the v anishing gradient problem. Each LSTM cell is comp osed of smaller units called gates, which control the flow of information through the cell. The forget g ate f t controls what information will b e disca rded fro m the cell state, input gate i t controls wha t new infor mation will b e sto red in the cell state a nd o utput gate o t controls what infor mation fro m the cell state will b e used in the output. The LSTM has t wo hidden states, c t and h t . The s ta te c t fights the gr adient v anishing pro blem while h t allows the net work to mak e complex decisions o ver short p erio ds of time. Ther e ar e several slightly diff e r ent LSTM v ariants. The architecture used in this pap er is sp ecified by the following eq uations: i t = σ ( W xi x t + W hi h t − 1 + b i ) f t = σ ( W xf x t + W hf h t − 1 + b f ) o t = σ ( W xo x t + W ho h t − 1 + b o ) c t = f t ∗ c t − 1 + i t ∗ tanh( W xc x t + W hc h t − 1 + b c ) h t = o t ∗ tanh( c t ) The figure 1 shows the int er nal structure of LSTM. 3.2 Gated Recurren t Unit A gated recurrent unit (GRU) was pr op osed in 201 4 by Cho et a l.[3] Similar ly to the LSTM unit, the GRU has ga ting units that mo dulate the flow of infor ma tion inside the unit, how ever, without having a separa te memory cells. A Comparison of Adaptation T echniques and RNN Architectures 5 σ σ tanh σ × + × tanh h t − 1 h t x t × c t − 1 c t h t f t i t o t Fig. 1. Structure of a LSTM unit The upda te gate z t decides how muc h the unit up dates its activ ation a nd reset gate r t determines which informa tion will b e kept fro m the old state. GRU do es no t hav e an y mechanism to control what inf o rmation to output, therefor e it exp oses the whole state. The ma in differences b etw een LSTM unit and GR U a re: – GR U has 2 gates, LSTM has 3 gates – GR Us do not have a n internal memory different from the unit output, LSTMs hav e an in ter na l memory c t and the output is controlled by an output g ate – Second nonlinearity is no t applied when computing the output of GRUs The GRU unit used in this work is describ ed by the following e q uations: r t = σ ( W r x t + U r h t − 1 + b r ) z t = σ ( W z x t + U z h t − 1 + b z ) ˜ h t = tanh( W x t + U ( r t ∗ h t − 1 ) + b h ) h t = (1 − z t ) ∗ h t − 1 + z t ∗ ˜ h t 3.3 Mo difi e d Ga te d Recurren t Unit with ReLU Rav anelli intro duced a simplified GR U ar chitecture, called M-r eluGRU , in [11]. This simplified arc hitectur e does not hav e the r eset gate a nd uses ReLU as an activ ation function instead of tanh. The M-re lu GRU unit is descr ibed by the following equations: z t = σ ( W z x t + U z h t − 1 + b z ) ˜ h t = ReL U ( W x t + U h t − 1 + b h ) h t = (1 − z t ) ∗ h t − 1 + z t ∗ ˜ h t 6 J. V an ˇ ek, J. Mic h´ a lek, J. Zelink a, J. Psutk a W e hav e also used this unit with the reset g ate to ev aluate the impact of the miss ing reset gate on the netw ork p erfor mance. This unit is effectivelly a normal GRU with ReLU as an activ ation function a nd we ca lled it r eluGRU in this pap er. The figure 2 shows the internal s tr ucture and difference of GRU a nd M- reluGRU units. σ σ tanh × 1 − × + × x t h t h t h t − 1 r t z t ˜ h t (a) GRU σ ReLU × 1 − × + x t h t h t h t − 1 z t ˜ h t (b) M-reluGRU Fig. 2. Structure of GRU and M-reluGRU units 4 Exp erimen ts W e hav e chosen TIMIT, a small phone reco g nition task, as a b enchmark of the NN a r chitectures and a daptation tec hniques. The TIMIT corpus is w ell known and av aila ble. The small size allows a ra pid testing and simulates a low-resourc e scenario that is still an issue for many minor languag e s. The phone reco gnition is m uch mor e sensitive to quality of AM than large voc a bulary task with a complex language mo del. The TIMIT cor pus co ntains re cordings of phonetically- balanced pro mpted English speech. It w as recorded using a Sennheiser close-talking micr ophone at 16 kHz rate with 1 6 bit sample resolution. T IMIT contains a to tal o f 630 0 sentences (5 .4 hours), co nsisting o f 10 sentences s po ken by e a ch o f 630 sp eakers from 8 ma jor dialect regions of the United States. All sentences were manually segmented at the phone level. The prompts for the 6300 utterances c onsist of 2 dia lect sentences (SA), 450 phonetically compa c t s entences (SX) a nd 1890 phonetically-diverse sentences (SI). The training set c ontains 3696 utterance s from 462 sp e a kers. The cor e test set c onsists o f 1 92 utter a nces, 8 from each o f 2 4 sp ea kers (2 males and 1 female from each dialect reg io n). The training and test sets do not ov er lap. A Comparison of Adaptation T echniques and RNN Architectures 7 4.1 Sp eech Data, Pro cessing, and T est Description As men tioned ab ov e, w e used TIMIT da ta av a ilable fro m LDC as a corpus LDC93S1. Then, we ran the K a ldi TIMIT example s cript s5 , whic h tr ained v arious NN-based phone reco gnition systems with a common HMM-GMM tied- triphone mo del and alignments. The common baseline system consis ted of the following metho ds: It started from MF CC features w hich were a ugmented by ∆ and ∆∆ co efficients and then pro cessed b y LDA. Final feature vector dimension was 4 0. W e obtained final alignments by HMM-GMM tied-tripho ne mo del with 1909 tied-states (may v ary slig htly if rerun the s cript). W e trained the mo del with MLL T and SA T metho ds, and we used fMLLR for the SA T training and a test phase adaptation. W e dump ed all tr aining, development a nd test fMLLR pro cessed data , and alignments to disk . Therefore, it w a s easy to do compatible exp eriments from the sa me c o mmon starting po int. W e als o dump ed MFCC pro cessed by LD A with no nor malization and CMN calcula ted b oth per sp eaker and per utt er ance. W e employ ed a bigra m langua ge/phone mo del for the final phone r ecognition. A bigram mo del is a very weak mode l for pho ne recognition; ho wever, it forced fo cus to the a coustic part of the system, and it bo osted b enchmark sensitivity . The training, as well as the recog nition, was done fo r 4 8 pho ne s . W e mapp ed the fina l res ults on TIMIT core test se t to 39 phones (a s is usual for TIMIT corpus pro cessing), and phone error rate (PE R) was ev aluated by the pro vided NIST scr ipt to b e compatible with pr e viously published works. In contrast to the Kaldi recipe, we used a different pho ne decoder. It is a s tandard Viterbi-based triphone deco der. It gives b etter r esults than the Kaldi standa rd WFST deco de r on the TIMIT phone recognition task. W e have us ed an op en-sour ce Chainer 3.2 DNNs Pytho n tranining to ol that suppo rts NVidia GPUs [1]. It is m ultiplatfor m and easy to use. 4.2 DNN T ra i ning First, a s a refer e nce to RNNs, we trained feed-forward (FF) DNN with ReLU activ ation function without any pre-training. W e used drop out p = 0 . 2. W e stack ed 11 input feature frames to 44 0 NN input dimension, like in Kaldi example s5. W e hav e used a netw ork with 8 hidden la yers and 2048 ReLU neurons, beca use it gave the best p er formance accor ding to o ur preliminar y exper iments. The final softmax layer had 1909 neur ons. W e used SGD with momen tum 0.9. The net works w er e trained in 3 sta g es with learning rate 1 e–2, 4e–3 and 1e–4. The batch size was gradua lly incre a sed fro m initial 256 to 1024, and fina lly to 2048. The training in each stage was s topp e d whe n the developmen t da ta criterion increased in comparison to the last ep o ch. Then we hav e trained LSTM, GR U, r eluGRU and M-reluGRU netw o rks. F or all of these recurrent networks, w e hav e used identical training setup. W e used 4 la yers with 1024 units in each. The drop out used was p = 0 . 2 . W e hav e us e d output time delay equal to 5 time steps. RNNs were trained in 4 s tages. The first stage used Adam optimization a lgorithm with batc h size 51 2. The other stages 8 J. V an ˇ ek, J. Mic h´ a lek, J. Zelink a, J. Psutk a used SGD with mo mentum 0.9, ba tch siz e 128 and learning rate equa l to 1e– 3, 1e–4, and 1e–5 respectivelly . The training in ea ch stage was s topp ed when the developmen t data cr iterion increa sed in compar ison to the last e p o c h, as in FF net work case. W e hav e trained each netw or k on sev era l input data and i-vector com bina- tions. W e used fMLLR da ta describ ed in the pr e vious section, MFCC a nd MF CC with CMN. The norma lization was calculated either p er sp eaker or p er utter- ance. F or training and testing, we used no i- vectors, o nline i-vectors a nd offline i-vectors calculated als o either p er speaker or per utter ance. W e also ev aluated online i-vectors for training and offline i-vectors for testing. The i-vectors were computed acc o rding to Kaldi Switch b o a rd example s cript. How ever, b eca use of small TIMIT size, we did not use any reduction o f data. Ent ir e training dataset was us ed to estimate i-vector extra ctor in all steps. The i-vector extractor has bee n tr a ined only once a nd online, per -sp eaker, and p er-uttera nce i-vectors sets were extracted by the same extra ctor tr ansforms. Because of sto chastic nature of results due to random initialization and sto chastic gradient desce nt , w e ha ve pe rformed eac h exp er iment 1 0 times in total. Then, we have calculated the a verage pho ne error rate (P E R) and its standard deviation. 4.3 Results W e hav e ev a luated av erag e PER, its standard deviation for all combinations of three fea tures v ar iants, six i-v ector v ariants, and fiv e NNs archit ec tures. W e had to split the res ults in to t wo tables b e cause of the page size. T able 1 shows the average PER for each exp eriment for FF, LSTM, and GRU NNs arc hi- tectures. T able 2 compares three v ariants of GRU-based NNs: GRU, reluGRU, M-reluGRU. A subset of the most v aluable res ults is a lso depicted in Figure 3. It is clear tha t fMLLR adaptation technique w o rked quite well. All the NN arc hi- tectures g ave the be st r esult with fMLLR. The i-vector ada ptation had a stable gain only for FF NN. Two v ariants of the i- vector adaptation were the bes t: online i-vectors for training a nd online or o ffline p er-s p ea ker for testing. Results of RNNs with the i-vector adaptation were interesting, bea cause there was no significant ga in. The results with ada ptation w ere rather w ors e . Betw een RNN architectures, LSTM was the winner (PER 15 .43 % with fMLLR). The GRU and reluGRU gav e comparable PERs, 15 .7 % with fMLLR, tha t w as slightly worse than LSTM. M-re luGR U did not p erformed well and the res ults w er e often worse than FF. 5 Conclusion In this pap er, we hav e compared feed-forward and several recurr e nt netw ork architectures o n input data with fMLLR or i-vector adapta tion techniques. The used recurre nt netw ork s were based on LSTM and GRU units. W e have a lso ev aluated tw o GRU modifica tions: reluGRU, with ReLU activ atio n function, A Comparison of Adaptation T echniques and RNN Architectures 9 T able 1: Phone Error Rate [%] for FF, LSTM and GRU Net works i-vectors Phone Error Rate [%] Data T raining T esting FF LSTM GRU fMLLR - - 17 . 0 0 ± 0 . 13 15 . 43 ± 0 . 28 15 . 69 ± 0 . 19 Off. spk. Off. spk. 17 . 17 ± 0 . 16 16 . 08 ± 0 . 19 16 . 04 ± 0 . 29 Off. utt. Off. utt. 17 . 3 2 ± 0 . 15 16 . 34 ± 0 . 32 16 . 43 ± 0 . 25 Online Off. spk. 17 . 17 ± 0 . 16 16 . 14 ± 0 . 22 16 . 15 ± 0 . 28 Online Off. utt. 17 . 1 0 ± 0 . 21 16 . 27 ± 0 . 34 16 . 14 ± 0 . 24 Online Online 17 . 1 8 ± 0 . 14 16 . 23 ± 0 . 26 16 . 23 ± 0 . 19 MF CC - - 19 . 4 2 ± 0 . 18 16 . 98 ± 0 . 27 1 7 . 48 ± 0 . 19 Off. spk. Off. spk. 19 . 02 ± 0 . 15 17 . 50 ± 0 . 19 17 . 6 3 ± 0 . 22 Off. utt. Off. utt. 19 . 2 9 ± 0 . 19 1 8 . 12 ± 0 . 27 18 . 09 ± 0 . 29 Online Off. spk. 18 . 22 ± 0 . 19 17 . 19 ± 0 . 26 17 . 00 ± 0 . 28 Online Off. utt. 18 . 4 8 ± 0 . 16 1 7 . 27 ± 0 . 26 17 . 21 ± 0 . 20 Online Online 18 . 1 9 ± 0 . 19 17 . 21 ± 0 . 15 1 7 . 33 ± 0 . 37 MF CC - - 18 . 4 9 ± 0 . 19 16 . 53 ± 0 . 20 1 7 . 00 ± 0 . 25 with Off. spk. Off. spk. 18 . 47 ± 0 . 20 17 . 20 ± 0 . 23 17 . 3 3 ± 0 . 21 CMN Off. utt. Off. utt. 18 . 5 9 ± 0 . 10 1 7 . 45 ± 0 . 19 17 . 36 ± 0 . 21 p er Online Off. spk. 18 . 11 ± 0 . 24 16 . 90 ± 0 . 24 17 . 0 4 ± 0 . 16 sp eaker Online Off. utt. 18 . 1 7 ± 0 . 22 1 7 . 34 ± 0 . 31 17 . 06 ± 0 . 20 Online Online 18 . 2 1 ± 0 . 19 1 7 . 25 ± 0 . 26 17 . 24 ± 0 . 31 MF CC - - 19 . 4 4 ± 0 . 27 16 . 98 ± 0 . 20 1 7 . 54 ± 0 . 20 with Off. spk. Off. spk. 19 . 10 ± 0 . 17 17 . 60 ± 0 . 31 17 . 6 4 ± 0 . 33 CMN Off. utt. Off. utt. 19 . 3 2 ± 0 . 14 1 8 . 28 ± 0 . 35 18 . 15 ± 0 . 35 p er Online Off. spk. 18 . 70 ± 0 . 18 17 . 53 ± 0 . 23 17 . 33 ± 0 . 18 utterance Online Off. utt. 18 . 6 3 ± 0 . 16 1 7 . 60 ± 0 . 23 17 . 46 ± 0 . 19 Online Online 18 . 7 3 ± 0 . 18 1 7 . 66 ± 0 . 23 17 . 43 ± 0 . 19 and M-reluGRU, with ReLU activ ation function and without the r eset ga te. As features, we hav e us ed MFCC pro c e s sed by LDA without normaliz a tion o r with CMN c a lculated either pe r sp eaker or p er utterance, a nd also fMLLR a daptation. W e hav e also a ugmented the features with several v a riants of i-vectors: online or offline calculated either p er sp eaker or per utterance. Due to the sto chastic nature o f the used optimizers, we hav e p er formed all exp eriments 10 times in total and calculated the av era ge phone error rate and its standar d deviation. F or all net works, we have obtained the be st results with fMLLR adaptation. The i-vector a daptation consistently improved the results only for FF netw orks . In the ca se of RNN, i-vectors did not lea d to any significant improvemen t; it even gav e worse results in all LSTM e xp eriments and in some exp er iments with GRU v ariants. W e hav e achieved the best results with LSTM ne tw o rk (P ER 15.4 3 % with fMLLR). GRU and reluGRU were slightly worse (b oth having PER 15.7 % with fMLLR). M-reluGRU was in some cases even worse tha n FF netw ork. F or a ll our expe r iments, we hav e us ed Cha iner 3.2 DNN training fra mework with P ython pr ogra mming lang uage and w e hav e published our op en- s ource 10 J. V an ˇ ek, J. Mic h´ a lek, J. Zelink a, J. Psutk a T able 2: Phone Err or Rate [%] for GRU and Its Mo difications i-vectors Phone Error Rate [%] Data T raining T esting GRU reluGRU M-reluGRU fMLLR - - 15 . 69 ± 0 . 19 15 . 70 ± 0 . 56 1 7 . 06 ± 0 . 77 Off. spk. Off. spk. 16 . 04 ± 0 . 29 16 . 28 ± 0 . 38 1 7 . 50 ± 0 . 72 Off. utt. Off. utt. 16 . 43 ± 0 . 25 16 . 33 ± 0 . 13 18 . 25 ± 0 . 85 Online Off. spk. 16 . 15 ± 0 . 28 16 . 19 ± 0 . 22 1 7 . 76 ± 0 . 94 Online Off. utt. 16 . 14 ± 0 . 24 16 . 23 ± 0 . 18 1 7 . 85 ± 0 . 76 Online Online 16 . 23 ± 0 . 19 16 . 39 ± 0 . 33 1 7 . 60 ± 0 . 67 MF CC - - 17 . 48 ± 0 . 19 17 . 30 ± 0 . 50 19 . 64 ± 1 . 05 Off. spk. Off. spk. 17 . 63 ± 0 . 22 18 . 32 ± 0 . 39 2 0 . 13 ± 0 . 93 Off. utt. Off. utt. 18 . 09 ± 0 . 29 18 . 35 ± 0 . 37 2 0 . 70 ± 0 . 65 Online Off. spk. 17 . 00 ± 0 . 28 17 . 30 ± 0 . 38 1 9 . 38 ± 0 . 96 Online Off. utt. 17 . 21 ± 0 . 20 17 . 52 ± 0 . 47 1 9 . 44 ± 0 . 89 Online Online 17 . 33 ± 0 . 37 17 . 41 ± 0 . 44 1 9 . 29 ± 0 . 89 MF CC - - 17 . 00 ± 0 . 25 16 . 91 ± 0 . 22 18 . 23 ± 0 . 53 with Off. spk. Off. spk. 17 . 33 ± 0 . 21 17 . 70 ± 0 . 39 1 9 . 44 ± 0 . 66 CMN Off. utt. Off. utt. 17 . 36 ± 0 . 21 17 . 91 ± 0 . 35 1 9 . 43 ± 1 . 17 p er Online Off. spk. 17 . 04 ± 0 . 16 17 . 39 ± 0 . 27 1 9 . 03 ± 1 . 07 sp eaker Online Off. utt. 17 . 06 ± 0 . 20 17 . 48 ± 0 . 29 1 8 . 93 ± 0 . 74 Online Online 17 . 24 ± 0 . 31 17 . 45 ± 0 . 27 1 8 . 89 ± 0 . 78 MF CC - - 17 . 54 ± 0 . 20 17 . 50 ± 0 . 29 19 . 26 ± 0 . 85 with Off. spk. Off. spk. 17 . 64 ± 0 . 33 18 . 05 ± 0 . 27 1 9 . 08 ± 0 . 77 CMN Off. utt. Off. utt. 18 . 15 ± 0 . 35 18 . 52 ± 0 . 33 2 1 . 04 ± 0 . 97 p er Online Off. spk. 17 . 33 ± 0 . 18 17 . 79 ± 0 . 31 2 0 . 10 ± 0 . 95 utterance Online Off. utt. 17 . 46 ± 0 . 19 18 . 05 ± 0 . 24 1 9 . 63 ± 0 . 99 Online Online 17 . 43 ± 0 . 19 17 . 85 ± 0 . 18 2 0 . 01 ± 0 . 69 scripts at https: //gith ub.com/OrcusCZ/NNAcousticModeling to easily repli- cate the results and to help contin ue the developmen t. Ac knowledgem ent This work was supp or ted by the pro ject no. P 103/ 12/G08 4 of the Grant Agency of the Czec h Republic and b y the grant of the University of W est Bohemia , pro ject No. SGS-20 1 6-03 9 . Access to computing and s to rage facilities owned by parties a nd pro jects contributing to the National Gr id Infr astructure MetaCen- trum provided under the pr ogra mme ”Pro jects of La rge Resear ch, Developmen t, and Innov ations Infrastr uctures” (CESNET LM201 5042 ), is g r eatly appr eciated. A Comparison of Adaptation T echniques and RNN Architectures 11 fMLLR MFCC MFCC + i-vectors MFCC CMN Spk. MFCC CMN Spk. + i-vectors MFCC CMN Utt. MFCC CMN Utt. + i-vectors 15 16 17 18 19 20 PER [%] FF LSTM GRU reluGRU M-rel uGRU Fig. 3. P hone E rror Rate [%] on F eatures with Best Performing i-vector V ar iants References 1. A flexible framew ork of neu ral netw orks for deep learning. https://c hainer.org 2. Cho, K ., V an Merri ¨ enbo er, B., Bahdanau, D., Bengio, Y .: On the proper- ties of neural machine translation: Enco der-deco der approaches. arXiv prep rint arXiv:1409.12 59 (20 14) 3. Ch u ng, J., Gulcehre, C., Cho, K ., Bengio, Y .: Empirical ev aluation of gated recu r- rent neural netw orks on seq u ence modeling. arXiv p reprint arX iv :1412.3 555 (2014) 4. Gales, M.: Maxim um lik elihoo d linear transformati ons for HMM-based sp eech recognition. Computer S p eec h & Language 12 (2), 75 – 98 (1998) 5. Hochreiter, S., Schmidh ub er, J.: Long short- term memory . Neural computation 9 (8), 1735–178 0 (1997 ) 6. Huang, Z., T ang, J., X u e, S., Dai, L.: Sp eaker Adaptation of RNN- BLSTM for Sp eec Recognition b ased on Sp eaker Code. Icassp 1 , 5305–5 309 (2016). https://doi .org/10.1109/IC A SSP .201 6.747269 0 7. Karafi´ at, M., Burget, L., Matˇ ejk a, P ., Glembek, O., ˇ Cernock´ y , J.: iV ector-based discriminativ e adaptation for automatic sp eech recognition. 2011 IEEE W orkshop on Automatic Sp eech Recognition and Und erstanding, ASRU 2011, Proceedings pp. 152–157 (2011). https:// d oi.org/1 0.1109/ASRU.2011. 6163922 8. P arthasarathi, S .H.K., Hoffmeister, B., Matsouk as, S., Mandal, A., Strom, N., Garimella, S .: fmllr based feature-space sp eaker adaptation of dnn acoustic mo dels. In: INTERSPEECH. pp . 3630–3634. ISCA (2015) 9. P edd inti, V., P ove y , D., K hudanpur, S.: A time delay neural net work architecture for efficient mo deling of long temporal contexts. Pro ceedin gs of t he Annual Con- ference of the I nternational Sp eech Communication Association, INTERSPEECH 2015-Jan ua , 3214–3218 (2015) 12 J. V an ˇ ek, J. Mic h´ alek, J. Zelink a, J. Psutka 10. Rath, S.P ., P ove y , D., V esel´ y, K., ˇ Cernock´ y , J.: Improv ed feature processing for deep neural netw orks. I n: INTERSPEECH. pp. 109–113. ISCA (2013) 11. Ra vanell i, M., Brakel, P ., O mologo, M., Bengio, Y., K essler, F.B.: Improving sp eech recognition by revising gated recurrent un its. In: Intersp eec h 2017. pp. 1308–131 2 (2017). https://doi.o rg/10.21437/In tersp eech.2017-775 12. Sak, H., Senior, A., Beaufays, F.: Long Sh ort-T erm Memory Based Recurrent Neural Netw ork Architectures for Large V ocabu lary Sp eech Recognition. I nterspeech 1 , 338–342 (2014). https:// d oi.org/arXiv:14 02.1128 , http://arx iv.org/abs/1402.11 28 13. Saon, G., Soltau, H.: U nfolded Recurrent Neural Net works for Sp eech Recognition. INTERSPEECH 1 , 343–347 (2014), http://maz sola.iit.uni- miskolc.hu/{ ~ }czap/leto ltes/IS14/IS2014/P D F/AUTHOR/IS141054.PDF 14. Saon, G., Soltau, H., Nahamoo, D., Pichen y , M.: Sp eaker adaptation of n eural netw ork acoustic models using i-vectors. In: 2013 IEEE W orkshop on A utomatic Sp eech Recognition and Understanding. pp. 55–59 (2013) 15. Seide, F., Chen, X., Y u, D.: F eature engineering in context-dep endent deep n eural netw orks for conv ersational sp eech transcription. In: in ASRU (2011) 16. W aib el, A., Hanazaw a, T., Hinton, G., Shika n o, K., Lang, K.J.: Phoneme recognition using time-dela y neural netw orks. IEEE T ransactions on Acoustics, Sp eech, a n d Signal Pro cessing 37 (3), 328–339 (Mar 1989). https://doi .org/10.1109/2 9.21701 17. Xue, S., Ab del-H amid, O., Jiang, H., Dai, L., Liu, Q.: F ast adaptation of deep n eural netw ork b ased on discriminant co des for sp eech recognition. IEEE/A CM T ransactions on Sp eec h and Language Pro cessing 22 (12) (2014). https://doi .org/10.1109/T ASLP .2014.2346313
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment