Concept-Based Embeddings for Natural Language Processing
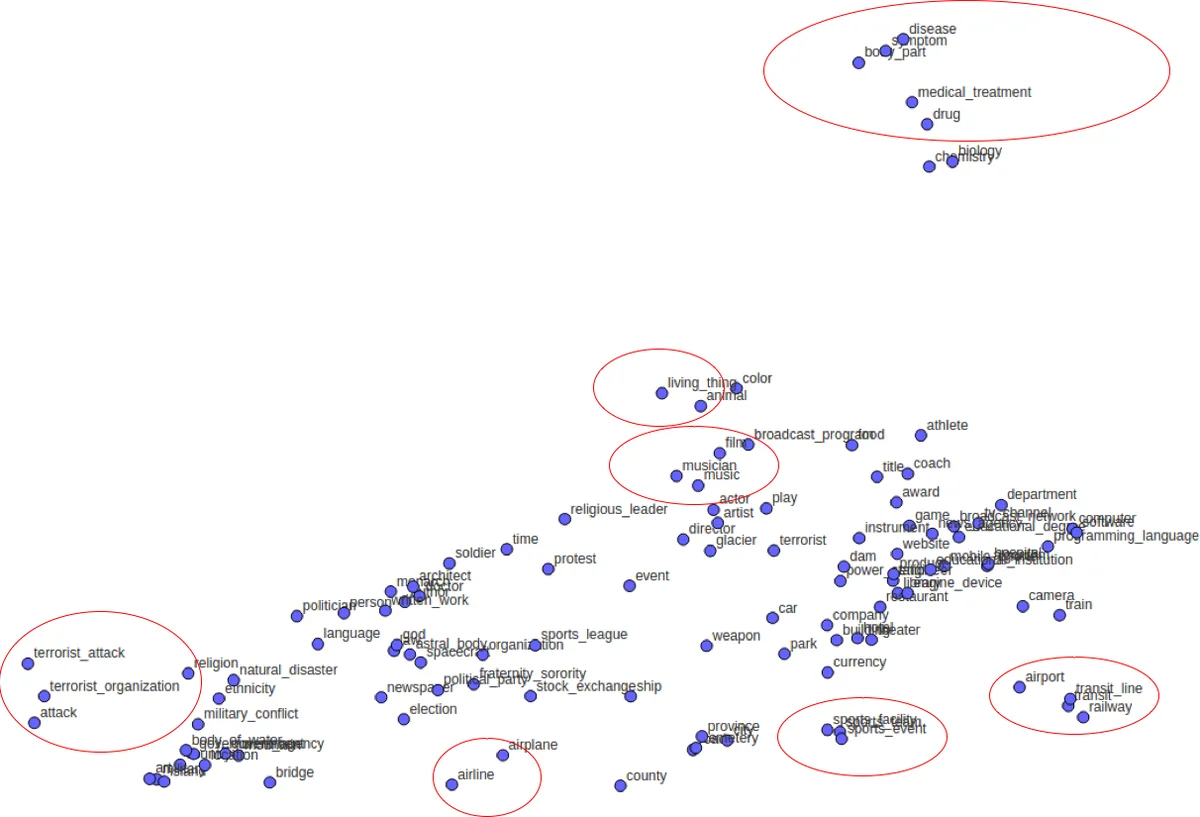
In this work, we focus on effectively leveraging and integrating information from concept-level as well as word-level via projecting concepts and words into a lower dimensional space while retaining most critical semantics. In a broad context of opinion understanding system, we investigate the use of the fused embedding for several core NLP tasks: named entity detection and classification, automatic speech recognition reranking, and targeted sentiment analysis.
💡 Research Summary
The dissertation “Concept‑Based Embeddings for Natural Language Processing” presents a unified framework that jointly leverages concept‑level and word‑level information by projecting both into a shared low‑dimensional space while preserving essential semantics. The work is motivated by the observation that human language conveys meaning not only through individual words but also through higher‑order concepts such as noun phrases, verb phrases, and abstract entities. These concepts often appear as multi‑word expressions and carry rich relational attributes, leading to a “curse of dimensionality” if treated naively.
Chapter 1 introduces the problem and outlines the research agenda. Chapter 2 reviews background literature on named‑entity recognition (NER), fine‑grained NER (FNET), targeted sentiment analysis, automatic speech recognition (ASR) hypothesis reranking, and existing embedding models (count‑based and prediction‑based).
In Chapter 3 the author proposes a multi‑task, entity‑aware word embedding method. Instead of learning embeddings solely from surrounding word co‑occurrences, the model incorporates named‑entity features (type, hierarchy, surface form) as additional training signals. A baseline CRF‑based NER system is enhanced by feeding these enriched embeddings as features. Experiments on telephone‑conversation transcripts show a consistent 2–3 percentage‑point increase in F1, especially when training data are scarce.
Chapter 4 tackles fine‑grained entity typing by constructing label embeddings that encode both hierarchical relationships and prototype‑based similarity. Prototypes are derived via pointwise mutual information (PMI) from large corpora, and hierarchical constraints are imposed during embedding learning. Because label embeddings are pre‑computed, they add no runtime overhead. Evaluations on three benchmark datasets (BBN, OntoNotes, FIGER) demonstrate superior performance in both zero‑shot and few‑shot settings compared with state‑of‑the‑art neural FNET models.
Chapter 5 introduces a binary entity embedding for ASR hypothesis reranking. A Restricted Boltzmann Machine (RBM) encodes the presence of named entities as binary latent variables. These embeddings serve as a prior in a discriminative reranker that rescales ASR scores. The author further extends the RBM to handle speech hypotheses directly (p‑dRBM). On the TED‑LIUM corpus, the approach reduces word error rate by 1.2 percentage points, outperforming traditional n‑gram‑based rerankers while maintaining low computational cost.
Chapter 6 focuses on targeted sentiment analysis, where the goal is to determine the sentiment polarity of a specific entity (target) with respect to particular aspects. The proposed architecture augments a Long Short‑Term Memory (LSTM) network with (a) target‑level attention, (b) sentence‑level attention, and (c) commonsense concept embeddings derived from SenticNet. A knowledge‑embedded LSTM integrates these concept vectors directly into the cell state, allowing the model to reason about implicit attributes (e.g., “battery life” for a phone). Experiments on the Sentihood and SemEval‑2015 datasets show an average 3.5 percentage‑point gain over strong baselines, confirming the benefit of explicit concept integration.
Chapter 7 summarizes contributions, discusses limitations, and outlines future work. The main limitations identified are (1) the manual effort required to build and maintain high‑quality concept resources, (2) the subjectivity in defining label hierarchies, and (3) the current reliance on static, text‑only knowledge bases. Future directions include graph‑based concept embeddings, dynamic multimodal concept acquisition, and deployment in real‑time dialogue systems.
Overall, the thesis demonstrates that concept‑aware embeddings can be seamlessly incorporated into diverse NLP pipelines, yielding measurable improvements in accuracy and robustness while preserving inference efficiency. The label‑embedding and RBM‑based reranking components are particularly noteworthy for enabling zero‑shot learning and for leveraging prior knowledge without incurring additional runtime cost, offering valuable insights for both academic research and industrial applications.
Comments & Academic Discussion
Loading comments...
Leave a Comment