Phase reconstruction from amplitude spectrograms based on von-Mises-distribution deep neural network
This paper presents a deep neural network (DNN)-based phase reconstruction from amplitude spectrograms. In audio signal and speech processing, the amplitude spectrogram is often used for processing, and the corresponding phase spectrogram is reconstr…
Authors: Shinnosuke Takamichi, Yuki Saito, Norihiro Takamune
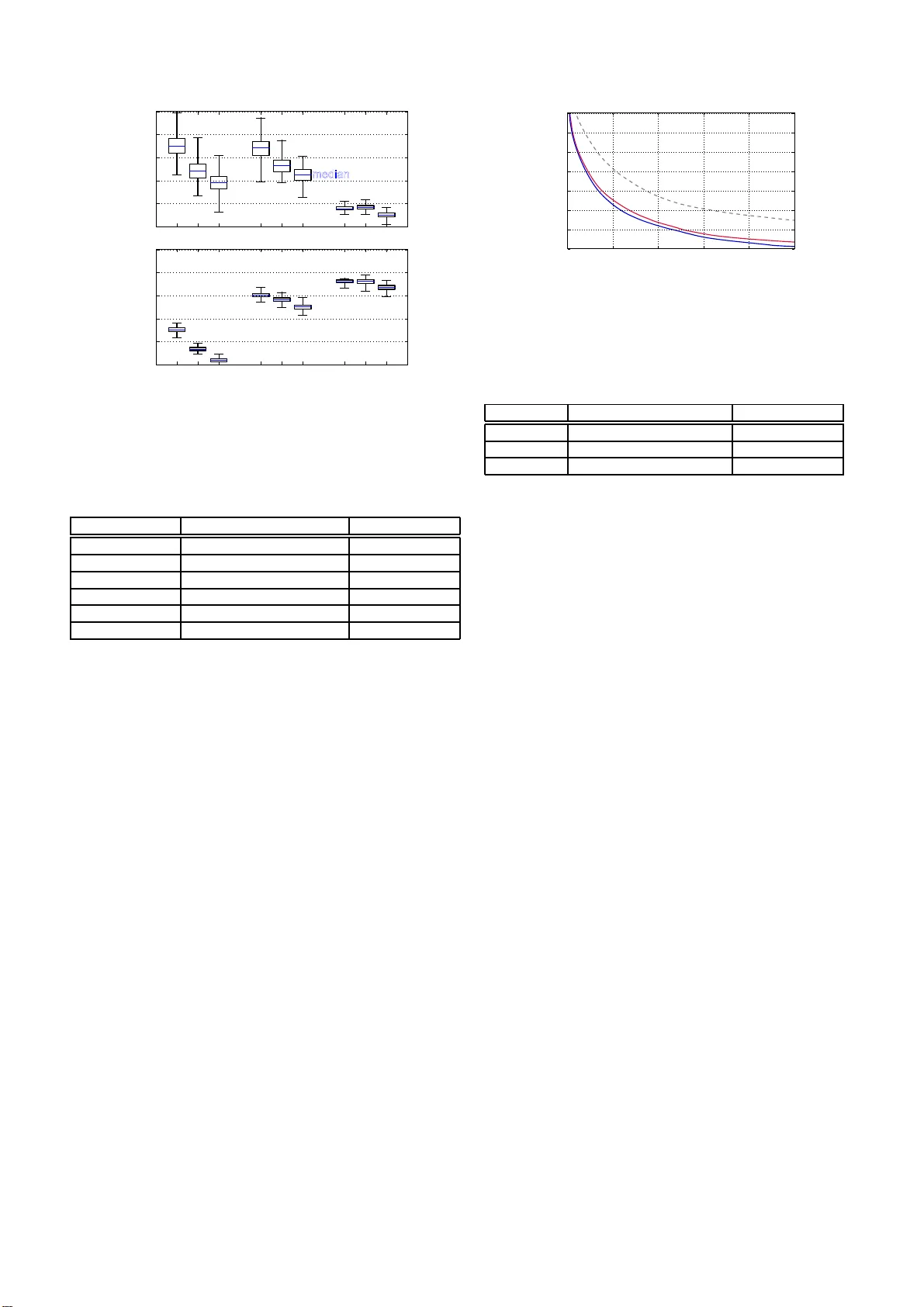
PHASE RECONSTR UCTION FR OM AMPLITUDE SPECTR OGRAMS B ASED ON V ON-MISES-DISTRIBUTION DEEP NEURAL NETW ORK Shinnosuke T akamichi † , Y uki Saito † , Norihir o T akamune † , Daichi K ita mu ra ‡ , and Hir oshi Saruwatari † † Graduate School of Information Science and T echnology , The Univ ersity of T okyo, Japan. ‡ Department of Electrical and Computer Engineering, National Institut e of T echnology , Kagaw a College, Japan. ABSTRA CT This paper presents a deep neural network (DNN)-based phase reconstruction from amplitude spectrograms. In audio signal and speech processing, the amplitude spectrogram is often used for pro- cessing, and the corresponding phase spectrogram is reconstructed from the amplitude spectrogram on the basis o f the Griffin-Lim method. Howe ver , the Griffin-Lim method causes unnatural arti - facts in synthetic speech. Addressing this problem, we introduce the von-M ises-distribution DNN for phase reconstruction. The DNN is a generativ e model hav ing t he von Mises distribution that can model distributions of a pe riodic variable such as a pha se, and the model parameters of the DNN are esti mated on the basis of the maximum likelihood criterion. Furthermore, we propose a group-delay loss for DNN tr aining to make the predicted group delay close to a nat- ural group delay . The experimental results demonstrate that 1) the trained DNN can predict group delay accu rately more than phases themselves, and 2) our phase reconstruction methods achie ve better speech quality than the conv entional Griffin-Lim method. Index T erms — speech analysis, p hase reconstruction, deep neural network, von Mises distribution, group delay 1. INTRODUCTION A variety of audio signal processing and machine learning-based methods, such as audio source separation and speech enhanc ement, in volv e processing t he amplitude spectrogram obtained via short- term Fourier transform (STFT). Also, st ati stical parametric text-to- speech synthesis [1] is shifting from vocoder-b ased (source filter model-based) to STFT -based frame works [2, 3, 4]. T o produce syn- thetic speech, we require the corresponding phase spectrogram, but it is often unav ailable. The Gr i ffin-Lim method [5] is a well-kno wn examp le that iteratively estimates of the phase spectrogram through STFT and inv erse ST F T while fixing the amplitude spectrogram. This signal-processing-base d method has high portability without a priori training but causes unnatu ral artifacts in synthetic speech. Therefore, this paper p roposes building a t rainab le phase reconstruc- tion method using generati ve models. A deep neural network (DNN) is a po werful generati ve model. There are two types of distri butions: non-parametric [6, 7, 8, 9] and parametric ones. This pap er addresses the latter . The re are many types of the parametric approaches related to the G aussian distribu- tion, e.g., isotrop ic multi variate Gaussian [10] and temporal-delta- constrained Gaussian [11, 12] (a.k.a., trajectory DNN in statistical parametric speech synthesis). The loss function (e.g., mean squared error) for training DNNs is often deriv ed to minimize the negati ve log-likelihood of t he distribution. The straightforward way to pre- dict a phase spectrogram from an amplitude spectrogram is to use Amplitude Predicted phase Freq. 1 Freq. F DNN T arget phase Phase loss (von Mises distribution) Group-delay loss Group-delay calculation … Freq. 1 Freq. F … Fig. 1 . Overvie w of proposed phase r econstruction method. T his fi g- ure shows frame-by-frame phase prediction rather than multi-frame or sequence-wise prediction for clear illustration. these models. Ho wev er, the Gaussian distribution is inappropriate for modeling distr i butions of a phase that is a periodic variable wi t h a period of 2 π . This paper proposes phase reconstruction from amplitude spec- trograms based on the von-Mises-distribution DNN . The von Mises distribution is a probability distr i bution on the circle [13], which is suitable for modeling periodic v ariables. The v on-Mises-distribution DNN is a generativ e model that has the von Mises distribution as a conditional probability distribution. T he von-Mises-distrib ution shallo w neural network w as originally proposed by Nabney et al. [14], and this paper utili zes it for predicting the phase spectrogram from the amplitude spectrogram. The loss function for DNN train- ing, named the phase loss (see Fig. 1 ), is defined by minimizing lik e- lihoods of the von Mises distribution. Also, we propose another loss function named gr oup-delay loss , which has a stronger connection to the amplitude spectrum [15]. The group-d elay loss is used t o make group delay of the predicted phase close to that of the target phase. Since the group delay and group-delay l oss are differentiable by the phase, the DNN can be trained by a standard backpropagation algo- rithm. W e condu ct objectiv e and subjectiv e ev aluations to ev aluate the effectiv eness of the proposed methods. The results demonstrate that 1) the trained DNN can predict group delay accu rately more than phases themselv es, and 2) our phase reconstruction method outper- forms the con ventional Griffin-Lim method i n terms of quality of synthesized speech. 2. GRIF FIN-LIM P HASE RECONS TRUCTION This section briefly describes the con ventiona l Grif fin-Lim method [5]. The Gri ffin-Lim method is a signal-processing-based it - erativ e algorithm to reconstruct a phase spe ctrogram from the amplitude spectrogram . Let x = [ x 1 , · · · , x t , · · · , x T ] and y = [ y 1 , · · · , y t , · · · , y T ] be amplitude and phase spectro- grams, respecti vely . x t = [ x t, 0 , · · · , x t,f , · · · , x t,F ] and y t = [ y t, 0 , · · · , y t,f , · · · , y t,F ] are the amplitude and phase at frame t , respecti vely . f is the frequency index , and F corresponds to the Nyquist frequency . Both x t,f and y t,f are real-v alued variables, but only y t,f is a variable with a period of 2 π . The Gr i ffin-Lim method randomly initializes y first. 1) Then it takes in verse STFT to obtain a wav eform from x and y . 2) The method takes ST FT to re-obtain y from t he wavefo rm. 3) W e substitute t he original x for the re-obtained x and then go back to step 1). These inv erse STFT and S TFT are iterati vely performed until they h ave con verged . The method can reconstruct the phase spectrogram consistent with the gi ven amplitude spectrogram but makes some artifacts in the synthesized speech, e.g., extra re verberation and phasiness owing to inappropriate initi alization of y . 3. P HASE RECONS TRUCTION B ASED ON V ON-MISES - D IS TRIBUTION DNNS This section introduces the von-M ises-distribution DNN and pro- poses l oss functions for the DNN training. 3.1. von Mises di st ri buti on The von Mises distribution P (vM) ( · ) [13] is a probability distribu- tion for a periodic variable y t,f , giv en as P (vM) ( y t,f ; µ, κ ) = exp ( κ cos ( y t,f − µ )) 2 π I 0 ( κ ) , (1) where µ i s the mean direction of the distribution (analogous t o the mean of the Gaussian distribution), κ is t he shape parameter (analo- gous to the precision of the Gaussian distribution), and I 0 ( · ) is t he modified Bessel function of the first kind of order 0. T he negati ve log likelihood gi ven y t is: − log P (vM) ( y t ; µ, κ ) ∝ − F X f =0 cos ( y t,f − µ ) + Const. , (2) where Const. is a va lue constant to µ . Not only y t,f but also a max- imum li kelihood estimate of µ has a period of 2 π . 3.2. DNN training W e train a DNN that has the von Mises distribution as a conditional probability distribution. The mean direction is predicted from x at each frame and frequen cy . Here , let G ( · ) be the DNN . The pre- dicted phase (mean direction) ˆ y = [ ˆ y 1 , · · · , ˆ y t , · · · , ˆ y T ] is give n as ˆ y = G ( x ) . The following sections propose two loss functions for estimating model parameters of G ( · ) : phase loss L ph ( y t , ˆ y t ) and group-d elay loss L gd ( y t , ˆ y t ) . 3.2.1. P hase loss The phase loss function is deriv ed from Eq. ( 2 ) as follows: L ph ( y t , ˆ y t ) = F X f =0 − cos ( y t,f − ˆ y t,f ) . (3) Model parameters of G ( · ) are iterativ ely updated by backpropaga- tion algorithm to minimize this loss function. The minimum point of ˆ y t,f is periodic, i.e., ˆ y t,f = y t,f ± 2 π N , where N is an arbitrary integer valu e. 3.2.2. Group -delay loss Group delay of speech has a high potential in speech processing, such as speech and speaker recognition [15, 16]. The group de- lay is defined as the ne gativ e deriv ativ e of phase by frequency . In general, speech production via a human vocal tract is well mod- eled as an all- pole filter defined by A ( ω ) exp( j φ ( ω ) ) , where A ( ω ) and φ ( ω ) are t he amplitude and phase func tions, respectiv ely , and 36.2 32.5 12.9 2.31 0.17 0.01 0.00 0.03 1.50 14.4 0 5 10 15 20 25 30 35 40 2 3 4 5 6 -4 -3 -2 - 0 Phase [rad] Frequency [%] Fig. 2 . Histogram of predicted phases. The target phases ha ve a range of [0 , 2 π ] , bu t the predicted phases hav e a r ange of [ − 4 π , 6 π ] . All frames and frequency bins of the ev aluation data in Section 4.1 are represented in this fi gure. ω = π f /F is the angular f requenc y . If t he filter has P c omplex- v alued poles z p = r p exp( j ω p ) ( p = 1 , .. ., P ), we ha ve log A ( ω ) = log Q P p =1 A p ( ω ) = 2 P P p =1 P ∞ n =1 r n p /n cos n ( ω − ω p ) , whe re A p ( ω ) is the amplitude of the single-pole model for the specific p -th pole [15]. Then, the group delay can be gi ven by − dφ ( ω ) dω = c P X p =1 ∞ X n =1 n cos n ( ω − ω p ) Z π − π log A p ( ω ) cos( nω ) d ω , (4) where c is a constant v alue; this shows the strong correlation between the group delay and the amplitude spectrum, which motiv ates us to utilize the group delay as a r e gularization term . In t his paper , we app roximate the group delay at frame t and frequenc y bin f with the follo wing equation: ∆ y t,f = − ( y t,f +1 − y t,f ) . (5) Since ∆ y t,f is also a periodic v ariable, the group-delay loss is de- fined as similar to Eq. (3): L gd ( y t , ˆ y t ) = F X f =0 − cos (∆ y t,f − ∆ ˆ y t,f ) . (6) The group-delay loss makes ∆ ˆ y t,f close to ∆ y t,f . Because Eq. (5) for ˆ y t is a linear transformation of y t , the backpropa gation algo- rithm can be used as the same as in Section 3.2.1 . 3.2.3. Multi- t ask learning On the basis of the multi-task learning formulation, the DN N can be trained using both phase loss and group-delay loss. The loss fu nction L ( y t , ˆ y t ) is: L ( y t , ˆ y t ) = L ph ( y t , ˆ y t ) + αL gd ( y t , ˆ y t ) , (7) where α is the weigh t of the secondary task (group-delay loss). Note that, since ranges of Eq. (3) and Eq. (6) are the same, no scale normalization factor is required. 3.3. Di scussion The generalized version of the von Mises distribution is the gener al- ized card ioid distribution [17] give n as P (GC) ( y t,f ; µ, κ, ψ ) = (cosh ( κψ )) 1 /ψ (1 + tanh ( κψ ) cos ( y t,f − µ )) 1 /ψ 2 π P 1 /ψ (cosh ( κψ )) , (8) where P 1 /ψ is the associated Legend re function of t he first kind of degree 1 /ψ and order 0. The von Mises distribution is the special case ( ψ → 0 ) of this distribution . Also, this distribution i s equi valent to the cardioid distribution and the wrapped Cauchy distribution for ψ = 1 and ψ = − 1 , respectiv ely . The neg ative log likelihood for µ for the cardioid and wrapped Cauchy distribution s are equal to Eq. (2). Therefore, DNNs with these two distributions are trained in the same manner . One possible way to ex tend our work is to model phases using this generalized card ioid distribution. Other possible ways are to use an asymmetric distribution [18] and mixture model. As describe d in Section 3.2.1 , the phase loss is minimized when ˆ y t,f = y t,f ± 2 π N for arbitrary N . Therefore, von-Mises- distribution DNNs suffer from an exp loding v alue of ˆ y t,f . T o in vestigate this, Fig. 2 plots a histogram of the predicted phase spectrograms. W e can see that the predicted phase spectrograms hav e a wider range than the target phase ( [0 , 2 π ] ), but the valu e does not explode. 4. E X P ERIMENT AL EV ALU A TION 4.1. E xp eriment al setup Eva luations were performed using th e JSUT corpus [19] , a free Japanese speech corpus uttered by a female speaker . W e used 5,000 utterances (approx. 6 hours) of the subset B ASIC5000 for training and 300 utterances of the subset ONOMA TOPEE300 for e valuation. Speech signals were downsa mpled at a rate of 16 kHz. The window length, shift length, an d FFT length were set to 400 samples (25 ms), 80 samples (5 ms), and 512 samples, respecti vely . The Hamming windo w was used. F eatures fed to a DNN were the joint vectors of the log amplitude spectra at current and ± 2 frames, and they were normalized to hav e zero-mean unit-v ariance. The DNN archi- tectures were Feed-Forward networks that included 3 × 1024 -unit gated linear unit [20] hidden l ayers. The activ ation of the output layer was a li near function. W e empirically explored DNN architec- tures within Feed-Forward networks and found that the gated linear unit is significantly better than a rectified linear unit (ReLU) [21] or LeakyReLU [22 ] hidden units. The DNN parameters were randomly initialized and the AdaGrad algorithm [ 23] with its learning rate set to 0.001 was used for the optimization algorithm. W e compared the con ventional Griffin-Lim and t hree proposed phase reconstruction methods. PH only phase loss (Eq. (3)) GD only group-delay loss (Eq. ( 6)) PH+GD multi-task learning (E q. (7)) In the Grif fin-Li m method, phase spectrograms were randomly ini- tialized. The number of iterations was set to 100. T he weight α for multi-task learning was set to 0 . 1 . In the proposed methods, phases in t he low frequency band are first estimated by DNNs, and those in the remaining frequency b ins are ran domly generated. W e use d three settings of frequency bands of the predicted phase sp ectrograms: 0-2 (96 dim.), 0-4 (128 dim.), and 0-8 kHz (257 dim.). Aft er predicting the phase spectrogram by DN N s, we further applied the Griffin-Lim method to refine the phase. The number of iterations of the phase refinement was 100. 4.2. P rediction accuracy W e ev aluated prediction accuracies of phases and group delay . Fig. 3 shows cosine distances between target and predicted phases and group delays. The distances were av eraged ov er all frames and fre- quenc y bins of the predicted phases (0-2, 0-4, or 0-8 kHz). The prediction accuracy of “PH (2 kHz)” ranges from 0 . 1 5 t o 0 . 31 , and t he distribution seems symmetric. Also, the accuracy be- comes smaller as the frequenc y band widens (“PH (4, 8 kHz)”). This result is natural because phases at higher frequency bins are easily changed by the temporal position of frame analysis. On the other − 0 . 0 5 0 .0 0 0 .0 5 0 .1 0 0 .1 5 0 .2 0 0 .2 5 0 .3 0 0 .3 5 PH GD PH+GD Cosine dist. (phase) Cosine dist. (group delay) median max min 2 4 8 2 4 8 2 4 8 [kHz] − 0 . 2 0 .0 0 .2 0 .4 0 .6 0 .8 Fig. 3 . Box plots of cosine distances between target and predicted phases (upper) and group delays (lo wer). The box indicates the first and third quartiles. T able 1 . Results of preference tests: co n ventional Grif fin-Lim method vs. proposed methods. Bold indicates preferred method that has a p -value smaller than 0 . 05 Method A Scores p -v alue Method B Griffin-Lim 0.497 vs. 0.503 0.871 PH (2 kHz) Griffin-Lim 0.280 vs. 0.720 < 10 − 9 PH (4 kHz) Griffin-Lim 0.277 vs. 0.723 < 10 − 9 PH (8 kHz) Griffin-Lim 0.453 vs. 0.547 0.022 PH+GD (2 kHz) Griffin-Lim 0.233 vs. 0.767 < 10 − 9 PH+GD (4 kHz) Griffin-Lim 0.247 vs. 0.753 < 10 − 9 PH+GD (8 kHz) Griffin-Lim 0.447 vs. 0.553 0.009 GD (2 kHz) Griffin-Lim 0.463 vs. 0.537 0.073 GD (4 kHz) Griffin-Lim 0.490 vs. 0.510 0.619 GD (8 kHz) hand, when using only group-delay loss (“GD”), group delay can be predicted more accurately than phase for all settings of frequ ency bands. T his result sho ws us that the Feed-Fo rward DNN can pre- dict group delay better than phases themselves. Finally , combined phase loss and group-delay loss (“PH+GD”) predicts phase more accurately than “GD” and group delay more accura tely than “PH” for all settings of frequency bands. Therefore, we can demonstrate the effectiv eness of the proposed multi-task training. 4.3. Comparison of Griffin-Lim and proposed methods T o ev aluate the ef fectiven ess of the proposed methods, we compared the quality of synthetic speech of Gr iffin-Lim and proposed meth- ods. Preference AB tests (listening tests) on speech quality were performed in our crowdsou rcing ev aluation system. 30 l i steners par- ticipated i n each test. Appro ximately $0 . 46 were paid to each lis- tener . Each listener preferred better-quality speech and answered for ten pairs of samples, i.e., 300 answers were obtained in each ev alua- tion. Speech samples of pairs of methods were randomly presented to the listeners. These settings are also used not only here but also in the following sections. T able 1 l ists the results. The propos ed methods outperform the con ven tional Griffin-Lim method in all settings of loss functions and frequenc y bands. In particular , “PH+GD” always has significantly better scores than the con ventional Griffin-Lim method. These re- 0 .0 5 0 .1 0 0 .1 5 0 .2 0 0 .2 5 0 .3 0 PH GD PH+GD Cosine dist. (phase) Cosine dist. (group delay) median max min 2 4 8 2 4 8 2 4 8 [kHz] − 0 . 2 0 .0 0 .2 0 .4 0 .6 0 .8 Fig. 4 . Box plots of cosine distances between predicted and refined phases (upper) and group delays (lo wer). The box indicates the first and third quartiles. T able 2 . Results of preference tests: proposed methods with dif- ferent f requenc y bands. Bold indicates preferred method that has a p -value smaller t han 0 . 05 Method A Scores p -v alue Method B PH (2 kHz) 0.270 vs. 0.730 < 10 − 9 PH (4 kHz) PH (4 kHz) 0.507 vs. 0.493 0.744 PH (8 kHz) PH+GD (2 kHz) 0.223 vs. 0.777 < 10 − 9 PH+GD (4 kHz) PH+GD (4 kHz) 0.493 vs. 0.507 0.744 PH+GD (8 kHz) GD (2 kHz) 0.513 vs. 0.487 0.514 GD (4 kHz) GD (4 kHz) 0.567 vs. 0.433 0.001 GD (8 kHz) sults demonstrate the effec tiven ess of the proposed methods. 4.4. E f f ect of phase refinements As explained in Section 4.1 , after phases were predicted by DNNs, they were refined by the Grif fin-Lim method. Here, we e va luated effe cts of the phase refinements. Fig. 4 sho ws cosine distances be- tween predicted and refined phases and group delays. T endencies were almost the same as those in F ig. 3 . When phase loss is used in training (“PH” and “PH+GD”), phase information is compara- bly preserved. Similarly , when group-delay loss is used in train- ing (“GD” and “PH+GD”), the group-delay information is compara- bly preserved. In the preliminary ev aluation, we compared speech quality of refi ned and unrefined phases (i.e., phases predicted by DNNs were directly used f or fi nally syn thesized speech). The res ults demonstrated that unrefined phases had significantly w orse speech quality than refined phases. 4.5. E f f ect of frequency bands W e compared effects of frequency bands of predicted phases within one loss function (“PH”, “P H+GD”, or “GD”). T able 2 shows t he results of preference A B tests on speech quality . In “PH” and “PH+GD, ” speech quality for 0-4 kHz frequency band s is signifi- cantly better than that f or 0-2 kHz, and is comparable with that for 0-8 kHz. These results suggest that at least 0-4 kHz frequency band s needs to be predicted but the spectrograms in the higher frequency bands may be exc ited by random phases (this tendency is simi l ar to the harmonics plus noise model [24 ]). A curious point is that “GD” 0 2 0 4 0 6 0 8 0 1 0 0 − 1 . 3 − 1 . 2 − 1 . 1 − 1 . 0 − 0 . 9 − 0 . 8 − 0 . 7 − 0 . 6 Iteration index Log spectral convergence Random PH+GD (4 kHz) PH (4 kHz) Fig. 5 . L og spectral con ver gence by phase refinements. When the v alue is −∞ , perfect reconstruction thro ugh STFT and in verse STFT is achie ved. This is the result of one of the ev aluation datasets, but the same tendency was observ ed in all ev aluation datasets. T able 3 . Results of preference tests: effects of group-delay loss. Bold indicates preferred method tha t has a p -value smaller th an 0 . 05 Method A Scores p -v alue Method B PH (2 kHz) 0.487 vs. 0.513 0.514 PH+GD (2 kHz) PH (4 kHz) 0.486 vs. 0.514 0.500 PH+GD (4 kHz) PH (8 kHz) 0.545 vs. 0.455 0.031 PH+GD (8 kHz) has dif ferent tenden cies: speech quality for 0-8 kHz frequen cy bands was significantly worse than that for 0-4 kHz. W e wil l inv estigate the reason for this. 4.6. E f f ect of group-delay loss W e in vestigated the ef fectiv eness of group-delay loss compared with phase loss. First, we ev aluated con vergen ce of phase refinemen ts. Fig. 5 sho ws the log spectral con ver gence [25] of “P H (4 kHz)” and “PH+GD (4 kHz). ” For co mparison, results of randomized initializa- tion of phases are also sho wn as “Random. ” The proposed methods (“PH (4 kHz)” and “PH+GD (4 kHz)”) hav e a smaller value for the spectral conv ergence than “Random. ” Also, “P H +GD (4 kHz)” has a smaller v alue than “PH (4 kHz)”, i.e., “PH+GD (4 kHz)” is the closest to the perfect reconstruction. In addition, we compared speec h quality of “PH” and “P H+GD. ” T able 3 lists the results of the comp arison with fr equency band s of 0 - 2, 0-4, and 0-8 kHz. “PH” is preferred more in 0-8 kHz with stati st i- cal significance, but “PH+GD” is preferred more in 0-2 and 0-4 kHz (without stati stical significance). Therefore, we can demonstrate the effe ctiven ess of group-delay loss in speech quality . 5. CONCL USION This paper presented DNN-based phase reconstruction from an am- plitude spectrogram. Based on maximum like lihood estimation of the von Mises distri bution, we introduced two loss functions for DNN training: phase loss and group-delay loss. W e demonstrated 1) the trained DNNs can predict group delay more accurately than phases, and 2) our proposed phase reconstruction methods achiev e better speech quality than the con ventional Griffin-Lim phase recon- struction method. For future work, we wi ll implement other proba- bility distributions for periodic v ariables, propose other approaches for phase refinements, and integrate our method with t ext-to-speec h synthesis t hat generates amplitude spectrograms [4]. Acknowledgments: Part of this wo rk wa s suppo rted by S E COM Science and T echno logy Foundation, and JSP S KAKENHI Grant Number 18K181 00. 6. RE FERENCES [1] H. Zen, K. T okuda, and A. Black, “Statistical parametric speech synthesis, ” Spee ch Communication , vo l. 51, no. 11, pp. 1039–1064, 2009. [2] S. T akaki, H. Kameoka, and J. Y amagishi, “Direct modeling of frequenc y spectra and wav eform generation based on phase recov ery for DNN-based speech synthesis, ” in Pro c. INT ER- SPEECH , Stockholm, Sweden, Aug. 2017. [3] Y . W ang, RJ Ske rry-Ryan, D. Stanton, Y . W u, Ron J. W eiss, N. Jaitly , Z. Y ang, Y . Xi ao, Z. Chen, S. Bengio, Q. Le, Y . Agiomyrgiannakis, R. Clark, and R. A. S aurous, “T acotron: T ow ards end-to-en d speech syn thesis, ” vol. abs/1609.03499, 2017. [4] Y . Saito, S. T akamichi, and H. Saruwatari, “T ext-to-spe ech synthesis u sing stft sp ectra based on low-/multi-resolution ge n- erativ e adversarial networks, ” in Pro c. ICASSP , Calgary , Canada, Apr . 2018, pp. 5299–5303 . [5] D. W . Griffin and J. S. Lim, “Signal estimation from modified short-time fourier transform, ” IE EE Tr ansactions on Acoustics, Speec h and Signal P rocessing , vol. 32, no. 2, pp. 236–243, Apr . 1984. [6] I. Goodfello w , J. P ouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S . Ozair , A. Courville, and Y . Bengio, “Generativ e ad- versarial nets, ” Proc. NIPS , pp. 2672–2 680, 2014. [7] Y . Saito, S. T akamichi, and H. Saruwa tari, “Statistical para- metric speech synthesis incorporating generati ve adversarial networks, ” IEEE/ACM T ransactions on Audio, Speech, and Langua ge Pro cessing , vol. 26, no. 1, pp. 755–767, Jun. 2018. [8] Y . Li, K. S wersky , and R. Zemel, “Generati ve moment match- ing netw orks, ” in Pro c. ICML , Lille, France, Jul. 201 5, pp. 1718–1 727. [9] S. T akamichi, K. T omoki, and H. Saruwatari, “Sampling- based speech parameter generation using moment-matching network, ” in Pr oc. INTERSPEECH , Stockholm, Sweden, Aug. 2017, pp. 3961–3965 . [10] H. Zen, A. Senior , and M. Schuster , “Statistical paramet- ric speech synthesis using deep neural networks, ” in Pr oc. ICASSP . V ancouv er , C anada, May 2013. [11] Z. W u and S. Ki ng, “Minimum trajectory error training for deep neural networks, combined with stacked bottleneck fea- tures, ” i n Pro c. INT ERSPEECH , Dresden, Germany , Sep. 2015, pp. 309–313. [12] K. Hashimoto, K. Oura, Y . Nanka ku, and K. T okuda, “T he effe ct of neural networks in statistical parametric speech syn- thesis, ” in Proc. ICASSP , Brisbane, A ustrali a, Apr . 2015, pp. 4455–4 459. [13] K. V . Mardia and P . E. Jupp, Dir ectional Statistics , John Wiley & S ons Ltd., 1999. [14] I.T . Nabney , C.M. Bishop, and C. Legleye , “Modelling con- ditional probability distribu tions for periodic variables, ” in 1995 F ourth Interna tional Confer ence on Arti ficial Neur al Net- works , Cal gary , Canada, Jun. 1995, pp. 177–182 . [15] F . I t akura and T . U mezaki, “Distance measure for speech recognition based on the smoothed group delay spectrum, ” i n Pr oc. ICA SSP , Dallas, U.S.A. , Apr . 1987, pp. 1257– 1260. [16] R. Pa dmanabhan, S. H. K. Parthasarathi, and H. A. Mu rthy , “Robu stness of phase based features for speake r recognition, ” in Pr oc. INTER SPE ECH , Brighton, U. K., Sep. 2009, pp. 2355–2 358. [17] M. C. Jones and Arthur Pewse y , “ A family of symmetric dis- tributions on the circle, ” Journa l of the American Statistical Association , vol. 100, no. 472, pp. 1422–1428, Dec. 2005. [18] T . Abe and A. P e wsey , “ Sine-skewe d circular distributions, ” Statistical P apers , vol. 52, no. 3, pp. 683–707, Aug. 2011. [19] R. Sonobe, S. T akamichi, and H. Saruwatari, “JSUT corpus: free large-sc ale japanese speech corpus f or end-to-end speech synthesis, ” vol. abs/1711.00 354, 2017. [20] Y . N. Dauphin , A. Fan, M. Auli, and D. Grangier , “Lan- guage modeling with gated con volutional networks, ” vol. abs/1612.08 083, 2016. [21] X. Glorot, A. Bordes, and Y . Bengio, “Deep sparse rectifier neural network s, ” in Pr oc. AIST A TS , Lauderdale, U.S.A., Apr . 2011, pp. 315–323. [22] L. A. Maas, Y . A. Hannun, and Y . A. Ng, “Recti fi er nonlinear- ities improv e neural network acoustic models, ” in Pro c. ICML , 2013, vol. 30. [23] J. Duchi, E . Hazan, and Y . Singer , “ Adaptiv e subgradient meth- ods for o nline learning and stoch astic optimization, ” EUR ASIP J ournal on Applied Sig nal P r ocessing , vol. 12 , pp. 2121– 2159, 2011. [24] Y . Stylianou, “ Applying the harmonics plus noise model in concatenati ve speech syn thesis, ” IEEE T ransactions on Speech and Audio Pr ocessing , vol. 9, no. 1, pp. 21–29, Jun. 2001. [25] N. St urmel and L. Daudet, “Signal reconstruction from STFT magnitude: A state of t he art, ” in Proc. of 14th International Confer ence on Digital Audio Effects DAFx-11 , Paris, France, Sep. 2011, pp. 177–1 82.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment