Single-channel Speech Dereverberation via Generative Adversarial Training
In this paper, we propose a single-channel speech dereverberation system (DeReGAT) based on convolutional, bidirectional long short-term memory and deep feed-forward neural network (CBLDNN) with generative adversarial training (GAT). In order to obta…
Authors: Chenxing Li, Tieqiang Wang, Shuang Xu
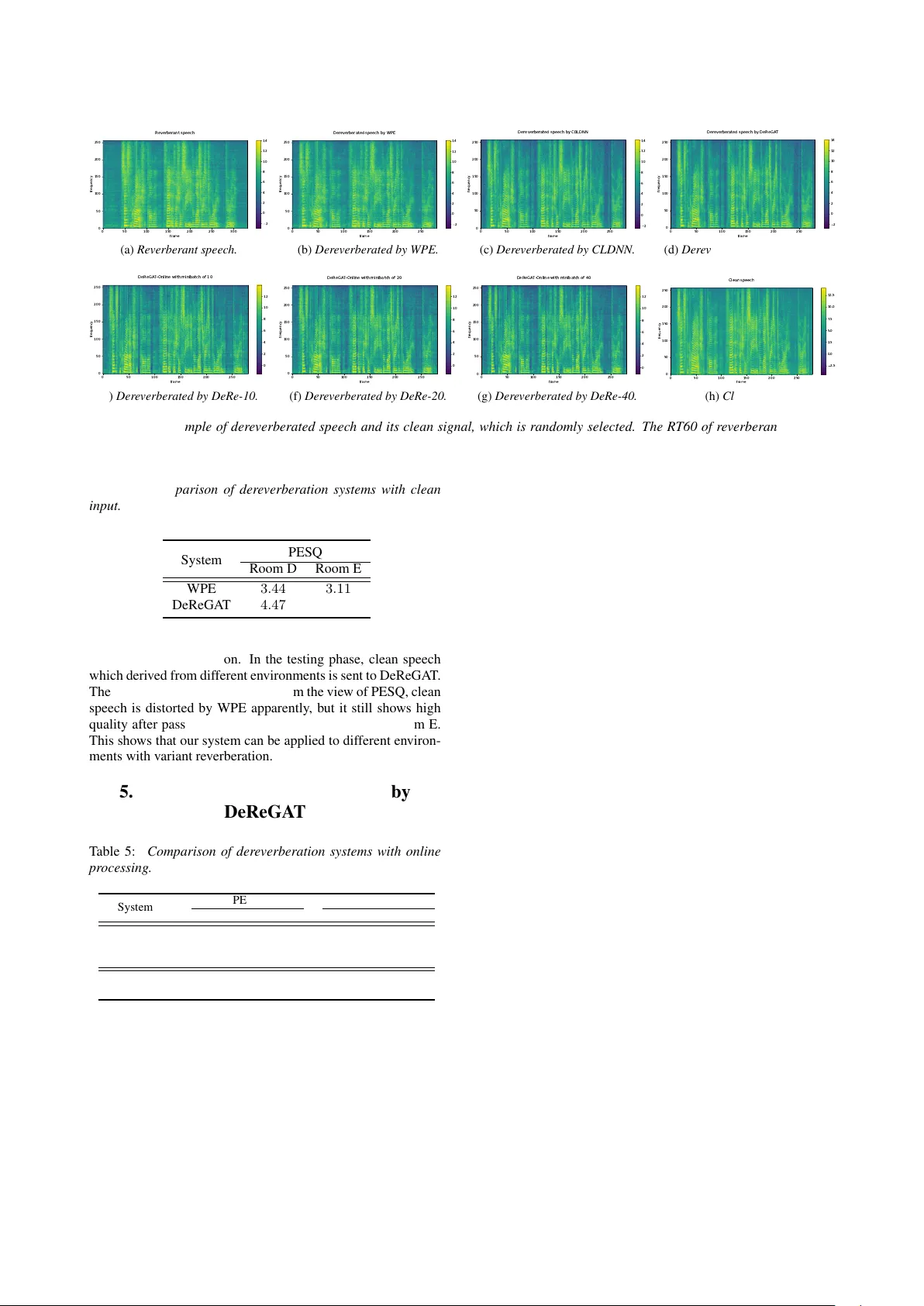
Single-channel Speech Der ev erberation via Generativ e Adv ersarial T raining Chenxing Li 1 , 2 , T ieqiang W ang 1 , 2 , Shuang Xu 1 , Bo Xu 1 1 Institute of Automation, Chinese Academy of Sciences, Beijing, P .R.China 2 Uni versity of Chinese Academy of Sciences, Beijing, P .R.China { lichenxing2015, wangtieqiang2015, shuang.xu, xubo } @ia.ac.cn Abstract In this paper , we propose a single-channel speech derev erber- ation system (DeReGA T) based on conv olutional, bidirectional long short-term memory and deep feed-forward neural netw ork (CBLDNN) with generati v e adversarial training (GA T). In or- der to obtain better speech quality instead of only minimizing a mean square error (MSE), GA T is employed to make the dere- verberated speech indistinguishable form the clean samples. Besides, our system can deal with wide range re verberation and be well adapted to v ariant en vironments. The experimental re- sults show that the proposed model outperforms weighted pre- diction error (WPE) and deep neural network-based systems. In addition, DeReGA T is extended to an online speech dere verber - ation scenario, which reports comparable performance with the offline case. Index T erms : speech dere verberation, generativ e adv ersarial training, CBLDNN. 1. Introduction In an enclosed space, speech signals recorded by receivers will be the mixes of original signals and their delayed and attenu- ated v ersion, this phenomenon is caused by the reflections from different directions. These various reflections damage speech intelligibility , de grade the performance of source localization or speech recognition and are generally hard to be described by deterministic functions or models. T o draw these issues, effec- tiv e speech dere verberation system should be established. Many approaches ha ve been proposed for decades: (1). In verse filtering of the room impulse response (RIR) [1, 2] con v olves reverberant speech with the inverse filters to re- fine speech, b ut the minimum phase assumption severely re- stricts this method. Some impro vements hav e been conducted in [3, 4]. But the time-varying RIR is still hard to estimate. (2). Blind multi-channel speech derev erberation is another pop- ular method, which based on multi-channel linear prediction (MCLP) [5, 6, 7, 8, 9]. MCLP-based methods predict undesired rev erberant component in the microphone signals, which is sub- sequently subtracted from the same signals. Ho we ver , since these methods lack additional knowledge about the undesired components, they may lead to a significant ov erestimation of these components and severe distortions of the output signals. (3). Spatial processing uses multiple microphones and spec- tral enhancement to suppress rev erberation [10]. Microphone array processing techniques such as beamforming provide spa- tial filtering to suppress specular reflections so that the speech signals from the desired directions can be enhanced (delay and sum beamformer in [11], minimum variance distortionless re- sponse (MVDR) beamformer in [12]). (4). Recently , WPE al- gorithm has shown promising results [13, 14]. Standard WPE requires entire utterance to be obtained before calculating the filter taps, and then dereverberation can be performed. Se veral improv ements have also been gradually proposed, such as adap- tiv e v ersion [15] and online WPE [16]. WPE and MVDR are also combined in a two stages algorithm [17]. Besides, WPE can be applied to both single and multi-channel conditions. Now adays, deep neural network is gradually applied to speech dere verberation. DNN in [18] learns a spectral map- ping from rev erberant to anechoic speech. Ho wever , perfor- mance is still limited at lo w re v erberation time (R T60). More- ov er , their system is en vironmentally insensitive, though LSTM has been utilized to further promote the performance in [19]. Furthermore, DNN-based nonlinear feature mapping and sta- tistical linear feature adaptation approaches are also in vesti- gated in [20] for reducing rev erberation in speech signals, and a rev erberation-time-aw are DNN-based speech derev erberation framew ork [21] is proposed to handle a wide range of re verber- ation times. Ho we ver , this network highly relies on an accurate estimation of R T60. Howe ver , the methods mentioned above come with sev- eral shortcomings: (1). Most of the methods rely on complex pipelines composed of multiple algorithms and hand-designed processing stages. (2). MSE loss utilized in these methods only concerns the numerical difference in the estimation, and the nu- merical error reduction may not necessarily lead to perceptual improv ement on the derev erberated speech. (3). Most of meth- ods above only work well in specific environments. Thus we propose a speech dereverberation system based on generative adversarial network. In this paper , we mainly focus on single- channel speech dereverberation. Our contributions are as fol- lows: (1). A more sophisticated structure, CBLDNN, is used to improv e the performance; (2). Our system has the ability to deal with the speech with a wide range of R T60 in dif ferent en viron- ments. (3). GA T is employed to train the network to further enhance the speech quality . In order to illuminate the ef fectiv eness of this method, sev- eral experiments are conducted. Perceptual ev aluation of speech quality (PESQ) [22] and speech to reverberation modulation energy ratio (SRMR) [23] are utilized to evaluate the perfor- mance. Compared with WPE and deep neural network-based methods, experiments show that our DeReGA T achieves bet- ter performances both in PESQ and SRMR. At the same time, our DeReGA T also works well in clean condition, which indi- cates that our system is robust in variate R T60 and room sizes. Furthermore, we extend the DeReGA T to online speech dere- verberation, which enables the output of the proposed method can be thrown into subsequent online speech enhancement and recognition. The rest of this paper is organized as follows. Section 2 introduces the single-channel speech dereverberation. Section 3 describes the generati v e adversarial training methodology in this paper . Experimental setup and results are presented in Sec- tion 4. Section 5 details the online version of the proposed DeReGA T . Finally , Section 6 concludes our work. 2. Single-channel speech der ev erberation Speech dere v erberation aims at estimating anechoic speech sig- nals from re verberant speech. In this paper , we focus on single- channel speech derev erberation task, and additive noise is ig- nored. The reverberant speech can be represented as: y ( n ) = x ( n ) ∗ h, (1) where y ( n ) represents rev erberant speech, x ( n ) is anechoic speech and h is RIR. The following relationship is still satis- fied after short time fourier transform (STFT): Y ( t, f ) = X ( t, f ) × H, (2) where Y ( t, f ) and X ( t, f ) represent the STFT of speech y ( n ) and x ( n ) respectively . Thus, our task is clarified as recov- ering anechoic signal x ( n ) from y ( n ) or Y ( t, f ) . In speech separation task, better results can be obtained by estimating a set of masks [24]. Similarly , mask is adopted as training target rather than spectral magnitude in our task. In our ex- periment, we firstly deploy a deep neural network to estimate mask M ( t, f ) in frequency domain instead of directly recover - ing x ( n ) from y ( n ) . In the follo wing equation, H ( | Y ( t, f ) | , θ ) represents a non-linear representation from STFT spectral mag- nitude | Y ( t, f ) | to M ( t, f ) . H ( | Y ( t, f ) | , θ ) = M ( t, f ) , (3) and | X ( t, f ) | can be recovered by M ( t, f ) × | Y ( t, f ) | ( × indi- cates element-wise multiplication). The anechoic speech signal x ( n ) can be obtained by in verse STFT . Masks are to be estimated as the training tar gets, and sev- eral widely-accepted masks are utilized in paper [24]. Phase sensitiv e mask (PSM) takes the differences of phases into ac- count, and it achie v es the state-of-the-art performance in speech separation task. Therefore, PSM mask is adopted in this paper , which is defined as: M PSM = | X ( t, f ) | × cos ( θ y ( t, f ) − θ ( t, f )) / | Y ( t, f ) | , (4) where θ y ( t, f ) is the phase of re v erberant speech, and θ ( t, f ) is the phase of clean signal. 3. Generative adversarial training Generativ e adversarial net [25] comprises two adv ersarial sub networks, a generator which generates the f ake examples from the random noises, and a discriminator which discriminates whether the input is real or generated by the generator . In this paper , we implement a conditional GAN [26, 27], where the generator , a CLDNN-based model, performs map- ping conditioned on some extra clues. Specifically , the gener- ator learns a mapping from observed feature | Y ( t, f ) | to mask M ( t, f ) . The discriminator is trained to classify whether the STFT feature comes from clean speech or generated. This train- ing procedure is diagrammed in Figure 1. 3.1. CBLDNN-based generator In this section, an utterance-level CLDNN-based generator is proposed. By using conv olutional layers, some acoustic vari- ations can be effectiv ely normalized and the resultant feature representation may be immune to speaker variations, colored background and channel noises. Besides, filters that work on conv3 conv1 conv2 conv4 conv5 conv5-f8 conv5-f2 conv5-f1 ... feature CONCAT DNN BLSTM BLSTM STFT spectral magnitude Generator ... BLSTM BLSTM DNN STFT spectral magnitude(Cle an) MULTIPLY Discriminator Figure 1: CLDNN-based speech dere verberation with GA T . local frequency region provide an efficient way to represent lo- cal structures and their combinations, which give a more pre- cise spectral structure to derev erberated speech. Higher con- volutional layers capture wider frequency variations and cover longer range R T60. BLSTMs well model temporal variations and DNN layers map features to a more separable space. The CBLDNN architecture incorporates the three layers in a unified framew ork, fusing the benefits of indi vidual layers. The proposed CBLDNN model is similar to [28], b ut with fine adjustment and more sophisticated structure. As depicted in Figure 1. The proposed model consists of 5 stacked con vo- lutional layers, 2 stacked BLSTM layers and 1 output layer . In (inChannel, outChannel, kernelW , kernelH) format, the conv o- lutional part ha ve (1, 4, 10, 10)-, (4, 4, 5, 5)-, (4, 8, 7, 7)-, (8, 8, 5, 5)- and (8, 8, 3, 3)-con volution layer from shallo w to deep with no pooling and 1 stride. Each BLSTM layer has 256 units. The model has 1 fully-connected (FC) layers, which has 257 output nodes. 3.2. BLCDNN-based discriminator In our experiment, we use utterance-lev el BLCDNN-based dis- criminator , which is depicted in Figure 1. W e aim to use BLSTM to model the dependency of the speech and con volutional layer to extract discriminativ e features that are useful for classification task. As for con volutional layer , to extract complementary features and enrich the representation, we learn sev eral different filters simultaneously . Conv olutional filters with multiple sizes capture valuable features from differ - ent scales, which contrib ute a lot to robust classification. The feature maps produced by the con volution layer are forwarded to the pooling layer . 1-max pooling is employed on each fea- ture map to reduce it to a single but the most dominant feature. The features are then joined to form a feature vector input to the final layer . This step transforms the variable-length, high- dimensional vector into a fixed-length vector . Finally , an FC layer maps it to one output node. The input is more like a clean speech when the output value is closer to 1. The BLCDNN model consists of 2 BLSTM layers, 1 con- T able 1: Configurations used for simulating training and de- velopment data. Dataset 12776 utterances in training set and 1206 in dev elopment set Room Size(m) Room A ( 3 × 3 × 3 ), Room B ( 6 × 6 × 4 ), Room C ( 9 × 9 × 5 ) RT 60 (ms) Uniformly sampled from 0 to 700ms volutional layer and 1 FC layer . Each BLSTM layer has 256 units. In (kernelW , kernelH) format, the conv olutional layer has 3 different filter sizes that are (5, 5), (3, 3) and (1, 1) both with 4 output channels and 1 stride. 3.3. Loss function For comparison, a derev erberation system with PSM-based deep neural network (CBLDNN) is selected as baseline, and MSE-based loss function is: L PSM 2 = 1 N || M PSM × | Y | − | X | cos( θ y − θ ) || 2 , (5) where M , | Y | and | X | represent mask, STFT spectral mag- nitude of reverberant speech and STFT spectral magnitude of clean speech for one utterance respectively . N is the total number of time-frequency bins. θ y is the phase of re verberant speech, and θ is the phase of clean signal. In this experiment, we train network by GA T , and LS- GAN [29] based method is utilized. At the same time, L 1 - regularization is utilized to guide the training. In order to balance GAN loss and L 1 -regularization, λ is taken as hyper - parameter in this experiment. The loss function is listed as: min D L ( D ) = E | X |∼ p data ( | X | ) [( D ( | X | ) − 1) 2 ] + E | Y |∼ p data ( | Y | ) [( D ( G ( | Y | ) × | Y | )) 2 ] , min G L ( G ) = E | Y |∼ p data ( | Y | ) [( D ( G ( | Y | ) × | Y | ) − 1) 2 ] + λ L PSM 1 . (6) 4. Experiments 4.1. Experimental setup T o build a large-scale training dataset for DeReGA T , clean speech is selected from WSJ0 dataset [30], which has 12776 ut- terances, 1206 utterances and 651 utterances in training set, de- velopment set and test set respectively . Then reverberant speech is generated by con v olving the clean speech with RIR. The im- pulse responses are generated by [31, 32]. W e place 1 microphone at the very centre of the room. Three different Room (Room A, B, C) and two different Room (Room D, E) are conducted for training and test. For training and development set, R T60 is uniformly distributed between 0 and 700ms, and R T60 is uniformly distributed between 70ms and 600ms in test set. Sound source is randomly placed in each room. Thus, 38328, 3618 and 1302 utterances are conducted as training set, development set and test set respectiv ely . Detailed configuration is listed in T able 1 and T able 2. Development set is used to choose the model. The experimental results are all ev aluated on test set. The input features of generator and discriminator are 257- dimensional STFT spectral magnitude computed with a frame T able 2: Configurations used for simulating test data. Dataset 651 utterances in test set Room Size(m) Room D ( 4 × 5 × 3 ), Room E ( 10 × 12 × 6 ) RT 60 (ms) Uniformly sampled from 70ms to 600ms T able 3: Comparison of der everber ation systems with differ ent methods. System PESQ SRMR Room D Room E Room D Room E WPE 2 . 00 2 . 21 4 . 45 4 . 67 CBLDNN 2 . 28 2 . 37 4 . 93 5 . 11 DeReGA T 2 . 54 2 . 76 5 . 70 5 . 42 Rev erberant 1 . 75 2 . 04 4 . 09 4 . 28 Clean − − 5 . 73 5 . 62 size of 32ms and 16ms shift. The phase of the anechoic sig- nal is used to build PSM-based loss function, and the phase of the rev erberant speech is used to restore the speech. After fine adjustment, hyper-parameters λ is set as 1. The models are all trained on T ensorflow [33]. RMSprop algorithm [34] is utilized for training where the learning rate started at 0.0002. 4.2. Baseline systems W e conduct several baseline systems. A standard WPE-based system and a deep neural network-based system, CBLDNN, are conducted. CBLDNN outputs PSM-based mask, and MSE is selected as loss function. CBLDNN has the same model struc- ture as the generator of DeReGA T . The performance of these systems is listed in T able 3. 4.3. DeReGA T dereverberation system In this section, we explore the impact of GA T . In GA T , PSM is used to measure the loss of L 1 , which is utilized to minimize the distance between generations and clean examples. From T able 3, e xperimental results show that all listed methods have contribution to dere verberation in dif ferent rooms, and DeRe- GA T obtains the best results. Compared with existing meth- ods, PESQ and SRMR of DeReGA T have been significantly improv ed. The SRMR of speech processed by DeReGA T is markedly approximate to the clean speech. The results mean GA T plays an important role in improving the performance. GA T makes the speech produced by generator approaches to clean one. The results also state that our DeReGA T achiev es better derev erberation performance in v ariant en vironments. Figure 2 shows the spectrogram of derev erberated speech based on different methods. Compared with speech dere ver - berated by WPE and CBLDNN, the speech dereverberated by DeReGA T has clearer and more compact spectrum structure. At the same time, the speech derev erberated by WPE remains obviously re verberations. 4.4. DeReGA T in clean envir onment In practice, due to en vironments differences, speech collected by microphone may bear various degrees of re verberation or hav e little rev erberation. Therefore, W e augment clean sam- ples and weakly-re verberated samples into training set to ensure that dere verberation system not only has an impressiv e ef fect to derev erberate re verberant speech but also maintain speech with 0 50 100 150 200 250 300 frame 0 50 100 150 200 250 frequency Reverberant speech 2 0 2 4 6 8 10 12 14 (a) Reverberant speec h. 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency Dereverberated speech by WPE 2 0 2 4 6 8 10 12 14 (b) Der everber ated by WPE. 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency Dereverberated speech by CBLDNN 2 0 2 4 6 8 10 12 14 (c) Der everber ated by CLDNN. 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency Dereverberated speech by DeReGAT 2 0 2 4 6 8 10 12 14 (d) Der everber ated by DeReGA T . 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency DeReGAT-Online with minibatch of 10 0 2 4 6 8 10 12 (e) Der everber ated by DeRe-10. 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency DeReGAT-Online with minibatch of 20 0 2 4 6 8 10 12 (f) Der everber ated by DeRe-20. 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency DeReGAT-Online with minibatch of 40 0 2 4 6 8 10 12 (g) Der everber ated by DeRe-40. 0 50 100 150 200 250 frame 0 50 100 150 200 250 frequency Clean speech 2.5 0.0 2.5 5.0 7.5 10.0 12.5 (h) Clean signal. Figure 2: An example of dere verberated speech and its clean signal, whic h is r andomly selected. The RT60 of reverber ant speech is 468ms. T able 4: Comparison of dere verber ation systems with clean input. System PESQ Room D Room E WPE 3 . 44 3 . 11 DeReGA T 4 . 47 4 . 48 zero or little rev erberation. In the testing phase, clean speech which derived from different en vironments is sent to DeReGA T . The results are shown in T able 4. From the view of PESQ, clean speech is distorted by WPE apparently , but it still shows high quality after passing DeReGA T both in Room D and Room E. This shows that our system can be applied to different en viron- ments with variant re verberation. 5. Online speech der ev erberation by DeReGA T T able 5: Comparison of dere verberation systems with online pr ocessing . System PESQ SRMR Room D Room E Room D Room E DeRe-10 1 . 54 1 . 55 4 . 96 4 . 77 DeRe-20 2 . 12 2 . 23 5 . 44 5 . 25 DeRe-40 2 . 33 2 . 41 5 . 63 5 . 35 DeReGA T 2 . 54 2 . 76 5 . 70 5 . 42 Rev erberant 1 . 75 2 . 04 4 . 09 4 . 28 In this section, we extend the proposed DeReGA T to en- able online speech dere verberation (DeReGA T -online). W e assume that the reverberant signal is obtained as a sequence of mini-batches. In detail, compared with offline DeReGA T , DeReGA T -online is performed without updating parameters. DeReGA T -online receiv es the mini-batch and outputs the dere- verberated batch. The size of the mini-batches are selected as 10 (DeRe-10), 20 (DeRe-20), 40 (DeRe-40) frames, which rep- resent 160ms, 320ms, 640ms delays respectiv ely . The results are listed in T able 5. Compared with utterance- lev el DeReGA T , the performance of DeReGA T -online de- grades. Compared with rev erberant speech, the worse PESQ of DeRe-10 sho ws hea vy distortion in speech quality . The compa- rable performance of DeRe-40 with DeReGA T mak es it capable of serving as an online system, where the ov erall delay consists of model’ s feed-forward time and the size of mini-batch. An ex- ample is also depicted in Figure 2. The visual intervals in Fig- ure 2(e) make the corresponding speech sounds off and on. The speech derev erberated by DeRe-20 sounds better , and DeRe-40 generates the most consistent speech among all online systems. 6. Conclusions In this paper, we introduce CBLDNN-based single-channel speech dere verberation system with GA T . Our results indicate that DeReGA T sho ws impressiv e performance improvement compared with traditional WPE and MSE-based deep neural network methods. Our DeReGA T ef fecti vely deals with v ariant R T60 and environmental differences. Additionally , DeReGA T is e xtended to an online version, which can achiev e comparable performance with of fline DeReGA T . This sho ws great potential for further deployment. W e note that the proposed method has great potential for the further impro vement. W e can compress the model to further reduce the system size, which can reduce the storage size and feed-forward time. Furthermore, single- channel DeReGA T can be e xtended to multi-channel DeRe- GA T , which can utilize the information of source location. 7. Acknowledgments This work is supported by National Key Research and De vel- opment Program of China under Grant No.2016YFB1001404 and Beijing Engineering Research Center Program under Grant No.Z171100002217015. 8. References [1] S. T . Neely and J. B. Allen, “In vertibility of a room impulse re- sponse, ” The Journal of the Acoustical Society of America , vol. 66, no. 1, pp. 165–169, 1979. [2] P . A. Naylor and N. D. Gaubitch, Speech dere verberation . Springer Science & Business Media, 2010. [3] M. W u and D. W ang, “ A tw o-stage algorithm for one-microphone rev erberant speech enhancement, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 14, no. 3, pp. 774–784, 2006. [4] S. Mosayyebpour, M. Esmaeili, and T . A. Gulliver , “Single- microphone early and late rev erberation suppression in noisy speech, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , v ol. 21, no. 2, pp. 322–335, 2013. [5] A. Juki ´ c, T . van W aterschoot, and S. Doclo, “ Adaptiv e speech derev erberation using constrained sparse multichannel linear pre- diction, ” IEEE Signal Processing Letters , v ol. 24, no. 1, pp. 101– 105, 2017. [6] A. Juki ´ c, T . van W aterschoot, T . Gerkmann, and S. Doclo, “Multi-channel linear prediction-based speech derev erberation with sparse priors, ” IEEE/ACM T ransactions on Audio, Speech and Language Pr ocessing , vol. 23, no. 9, pp. 1509–1520, 2015. [7] A. Jukic, T . v an W aterschoot, T . Gerkmann, and S. Doclo, “ A gen- eral frame work for multichannel speech derev erberation exploit- ing sparsity , ” in International Confer ence on Der everberation and Reverberation of A udio, Music, and Speec h) , 2016. [8] T . Y oshioka, H. T achibana, T . Nakatani, and M. Miyoshi, “ Adaptiv e dereverberation of speech signals with speaker -position change detection, ” in IEEE International Conference on Acous- tics, Speech and Signal Pr ocessing , 2009, pp. 3733–3736. [9] T . Y oshioka and T . Nakatani, “Dereverberation for reverberation- robust microphone arrays, ” in European Signal Pr ocessing Con- fer ence , 2013, pp. 1–5. [10] J. Allen, D. Berkley , and J. Blauert, “Multimicrophone signal- processing technique to remove room reverberation from speech signals, ” The Journal of the Acoustical Society of America , vol. 62, no. 4, pp. 912–915, 1977. [11] E. A. P . Habets, J. Benesty , I. Cohen, S. Gannot, and J. Dmo- chowski, “New insights into the MVDR beamformer in room acoustics, ” IEEE T ransactions on A udio, Speech, and Language Pr ocessing , v ol. 18, no. 1, pp. 158–170, 2010. [12] E. A. Habets and J. Benesty , “ A two-stage beamforming approach for noise reduction and dereverberation, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 21, no. 5, pp. 945– 958, 2013. [13] T . Nakatani, T . Y oshioka, K. Kinoshita, M. Miyoshi, and B.-H. Juang, “Blind speech dereverberation with multi-channel linear prediction based on short time fourier transform representation, ” in IEEE International Confer ence on Acoustics, Speech and Sig- nal Pr ocessing , 2008, pp. 85–88. [14] ——, “Speech dereverberation based on variance-normalized de- layed linear prediction, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , vol. 18, no. 7, pp. 1717–1731, 2010. [15] J. Caroselli, I. Shafran, A. Narayanan, and R. Rose, “ Adaptive multichannel dereverberation for automatic speech recognition, ” in INTERSPEECH , 2017. [16] K. Kinoshita, M. Delcroix, H. Kwon, T . Mori, and T . Nakatani, “Neural network-based spectrum estimation for online WPE dere- verberation, ” INTERSPEECH , pp. 384–388, 2017. [17] A. Cohen, G. Stemmer, S. Ingalsuo, and S. Markovich-Golan, “Combined weighted prediction error and minimum v ariance dis- tortionless response for dere v erberation, ” in IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing , 2017, pp. 446–450. [18] K. Han, Y . W ang, D. W ang, W . S. W oods, I. Merks, and T . Zhang, “Learning spectral mapping for speech derev erberation and de- noising, ” IEEE/ACM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 23, no. 6, pp. 982–992, 2015. [19] F . W eninger, J. Geiger , M. W ¨ ollmer , B. Schuller, and G. Rigoll, “Feature enhancement by deep LSTM networks for ASR in re- verberant multisource en vironments, ” Computer Speech & Lan- guage , v ol. 28, no. 4, pp. 888–902, 2014. [20] X. Xiao, S. Zhao, D. H. H. Nguyen, X. Zhong, D. L. Jones, E. S. Chng, and H. Li, “Speech dereverberation for enhancement and recognition using dynamic features constrained deep neural net- works and feature adaptation, ” EURASIP Journal on Advances in Signal Pr ocessing , v ol. 2016, no. 1, p. 4, 2016. [21] B. W u, K. Li, M. Y ang, and C.-H. Lee, “ A rev erberation-time- aware approach to speech dereverberation based on deep neural networks, ” IEEE/A CM T ransactions on Audio, Speech, and Lan- guage Pr ocessing , vol. 25, no. 1, pp. 102–111, 2017. [22] A. W . Rix, J. G. Beerends, M. P . Hollier , and A. P . Hekstra, “Per- ceptual ev aluation of speech quality (PESQ)-a new method for speech quality assessment of telephone networks and codecs, ” in IEEE International Conference on Acoustics, Speech, and Signal Pr ocessing , v ol. 2, 2001, pp. 749–752. [23] T . H. Falk and W .-Y . Chan, “ A non-intrusive quality measure of derev erberated speech, ” in International W orkshop on Acoustic Echo and Noise Contr ol , 2008. [24] M. Kolbæk, D. Y u, Z.-H. T an, and J. Jensen, “Multitalker speech separation with utterance-lev el permutation in variant training of deep recurrent neural networks, ” IEEE/ACM T ransactions on Au- dio, Speech, and Language Pr ocessing , vol. 25, no. 10, pp. 1901– 1913, 2017. [25] I. Goodfellow , J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- Farley , S. Ozair, A. Courville, and Y . Bengio, “Generative adver - sarial nets, ” in Advances in Neural Information Pr ocessing Ssys- tems , 2014, pp. 2672–2680. [26] P . Isola, J.-Y . Zhu, T . Zhou, and A. A. Efros, “Image-to-image translation with conditional adversarial networks, ” arXiv pr eprint arXiv:1611.07004 , 2016. [27] S. Pascual, A. Bonafonte, and J. Serr ` a, “SEGAN: Speech enhancement generative adversarial network, ” arXiv pr eprint arXiv:1703.09452 , 2017. [28] T . N. Sainath, O. V inyals, A. Senior , and H. Sak, “Conv olutional, long short-term memory , fully connected deep neural networks, ” in IEEE International Confer ence on Acoustics, Speech and Sig- nal Pr ocessing , 2015, pp. 4580–4584. [29] X. Mao, Q. Li, H. Xie, R. Y . Lau, Z. W ang, and S. P . Smolley , “Least squares generativ e adversarial networks, ” arXiv preprint ArXiv:1611.04076 , 2016. [30] J. Garofalo, D. Graff, D. Paul, and D. Pallett, “Csr-i (wsj0) com- plete, ” Linguistic Data Consortium , 2007. [31] J. B. Allen and D. A. Berkley , “Image method for efficiently sim- ulating small-room acoustics, ” The Journal of the Acoustical So- ciety of America , vol. 65, no. 4, pp. 943–950, 1979. [32] E. A. Lehmann and A. M. Johansson, “Prediction of energy de- cay in room impulse responses simulated with an image-source model, ” The Journal of the Acoustical Society of America , vol. 124, no. 1, pp. 269–277, 2008. [33] M. Abadi, A. Agarwal, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin et al. , “T ensorflow: Large-scale machine learning on heterogeneous distributed sys- tems, ” arXiv preprint , 2016. [34] T . T ieleman and G. Hinton, “Lecture 6.5-rmsprop: Divide the gra- dient by a running av erage of its recent magnitude, ” COURSERA: Neural networks for machine learning , v ol. 4, no. 2, pp. 26–31, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment