Learning Spontaneity to Improve Emotion Recognition In Speech
We investigate the effect and usefulness of spontaneity (i.e. whether a given speech is spontaneous or not) in speech in the context of emotion recognition. We hypothesize that emotional content in speech is interrelated with its spontaneity, and use…
Authors: Karttikeya Mangalam, Tanaya Guha
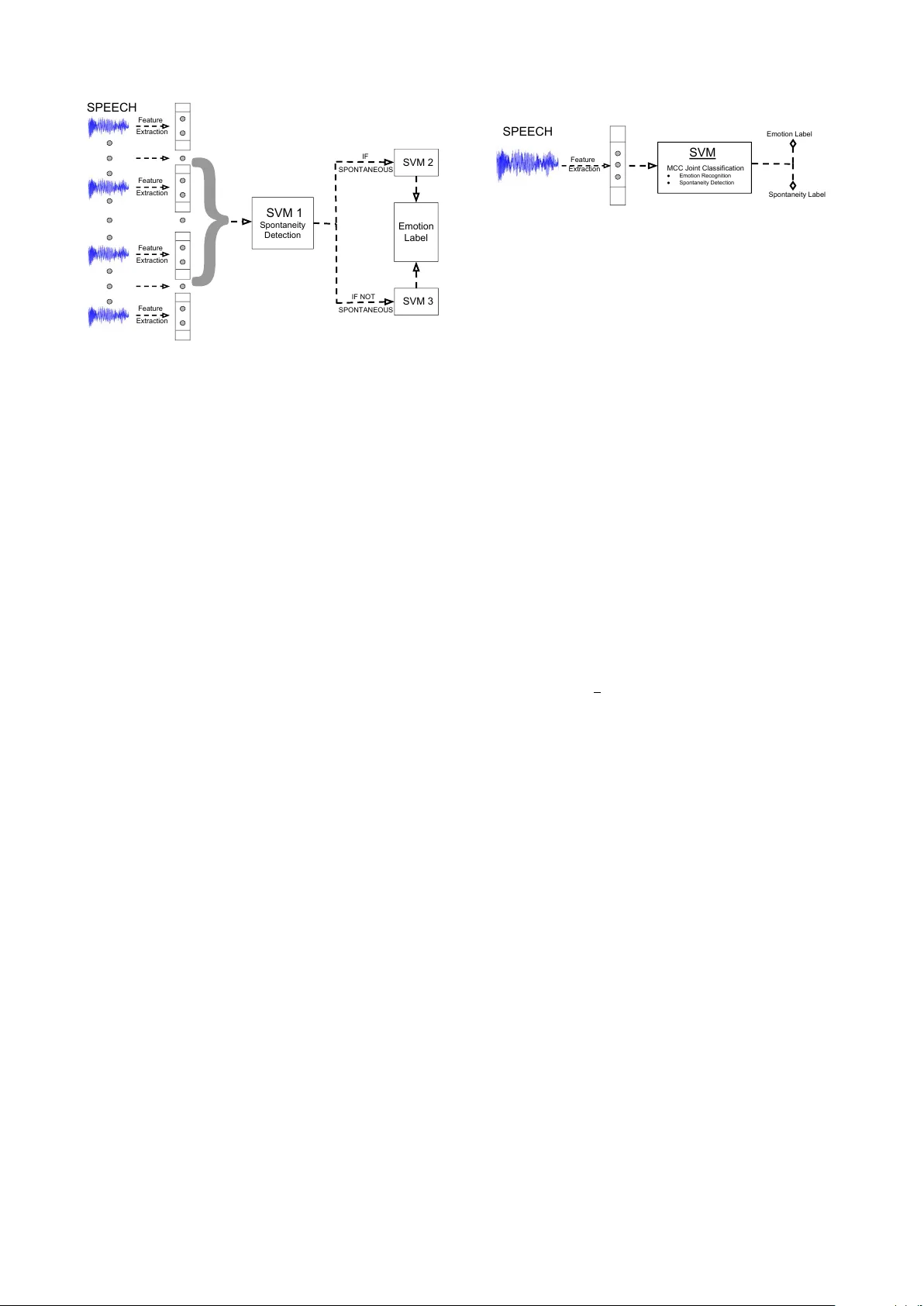
Learning Spontaneity to Impr ov e Emotion Recognition in Speech Karttike ya Mangalam, T anaya Guha Indian Institute of T echnology , Kanpur mangalam@iitk.ac.in, tanaya@iitk.ac.in Abstract W e in vestig ate the effect and usefulness of spontaneity (i.e. whether a giv en speech is spontaneous or not) in speech in the context of emotion recognition. W e hypothesize that emotional content in speech is interrelated with its spontaneity , and use spontaneity classification as an auxiliary task to the problem of emotion recognition. W e propose two supervised learning set- tings that utilize spontaneity to improve speech emotion recog- nition: a hierarchical model that performs spontaneity detec- tion before performing emotion recognition, and a multitask learning model that jointly learns to recognize both spontane- ity and emotion. Through v arious experiments on the well- known IEMOCAP database, we sho w that by using spontane- ity detection as an additional task, significant improvement can be achiev ed ov er emotion recognition systems that are unaw are of spontaneity . W e achiev e state-of-the-art emotion recognition accuracy (4-class, 69.1%) on the IEMOCAP database outper- forming sev eral relevant and competiti ve baselines. Index T erms : Emotion Recognition, Spontaneous Speech, Multitask Learning. 1. Intr oduction Recognizing human emotion is critical for any human-centric system in volving human-human or human-machine interaction. Emotion is expressed and percei ved through various v erbal and non-verbal cues, such as speech and facial e xpressions. In the recent years, speech emotion recognition has been studied ex- tensiv ely , both as an independent modality [1, 2], and in combi- nation with others [3]. The majority of work on speech emotion recognition fol- lows a two step approach. First, a set of acoustic and prosodic features are extracted, and then a machine learning system is employed to recognize the emotion labels [4, 2, 5, 6, 7]. Al- though acoustic and prosodic features are more common, the use of lexical features, such as emotional v ector, hav e been also shown to be useful [4]. For recognition, v arious methods hav e been proposed - starting from traditional hidden Markov models (HMM) [7] to ensemble classifiers [8], and more recently , deep neural networks [9, 10, 11]. Recently , Abdelwahab and Busso [2] proposed an ensemble feature selection method that ad- dresses the problem of training and test data arising from dif fer- ent distributions. Zong et al. [5] introduced a domain-adaptiv e least squares re gression technique for the same problem. Owing to the latest trends in machine learning, autoencoders [12] and recurrent neural networks (RNN) [9] ha ve also been used for speech emotion recognition. Efforts to improve speech emo- tion recognition are primarily concentrated on building a better machine learning system. Although spontaneity , fluency and nativity of speech are well studied in the literature, their effect on emotion recognition tasks is not well studied. W ork that addressed the problem of distinguishing between spontaneous and scripted speech include acoustic and prosodic feature-based classification [13, 14], and detect ing target phonemes [15]. Du- four et al. [14] have also shown that spontaneity is useful for identifying speakers’ role [14] by utilizing spontaneity infor- mation in their automatic speech recognition system. A recent work by T ian et al. [16] has established that emotional content is essentially different in spontaneous vs. acted speech (prepared, planned, scripted). As they compare emotion recognition in the two types of speech, they observe that different sets of features contribute to the success of emotion classification in sponta- neous vs. acted speech. Another study on emotion recognition using con volutional neural network (CNN) has found that type of data (spontaneous or not) does af fect the emotion recognition results [10]; howev er, this work does not use spontaneity infor- mation in emotion recognition task. A very recent work has used gender and spontaneity information explicitely in a long short term memory (LSTM) network for effectiv e speech emo- tion recognition in an aggregated data corpus [11]. Our work differs from this work by providing a detailed analysis and in- sight to wards the ef fect of spontaneity in emotion recognition in speech, and by proposing an SVM-based hierarchical and mul- titask learning framew ork. In this w ork, we in vestigate the usefulness of spontaneity in speech in the context of emotion recognition. W e hypothesize that emotional content is interrelated with the spontaneity of speech, and propose to use spontaneity classification as an aux- iliary task to the problem of emotion recognition in speech. W e in vestigate two supervised learning settings: (i) a multilabel hi- erar chical model that performs spontaneity detection followed by emotion classification, and (ii) a multitask learning model that jointly learns to recognize both spontaneity and emotion in speech and returns two labels. T o construct the proposed mod- els, we use a set of standard acoustic and prosodic features in conjunction with support vector machine (SVM) classifiers. W e choose SVM because it has been shown to produce results com- parable to long short term memory (LSTM) networks when the training dataset is not sufficiently large [16]. Through exper- iments on the IEMOCAP database [17], we observ e that (i) recognizing emotion is easier in spontaneous speech than in scripted speech, (ii) longer conte xt is useful in spontaneity clas- sification, and (iii) significant improvement in emotion recog- nition can be achieved using spontaneity as an additional infor- mation, ov er spontaneity-unaware systems. The rest of this paper is organized as follows: Section 2 describes the feature extraction process and the two supervised classification methods we ha ve used for using spontaneity in emotion classification. Section 3 provides details on the exper - imental setup and results, followed by conclusion in Section 4. 2. Emotion Recognition using Spontaneity In this section, we propose tw o models that utilize the spontane- ity information in speech to improve emotion recognition: (i) a multilabel hierarchical model that performs spontaneity detec- tion followed by emotion recognition, and (ii) a multitask learn- SVM 1 Spontaneity Detection SPONTANEOUS SVM 3 SVM 2 Emotion Label IF IF NOT Feature Extraction Feature Extraction Feature Extraction Feature Extraction SPEECH SPONTANEOUS Figure 1: Multilabel hierar chical emotion r ecognition using spontaneity ing model that jointly recognizes both spontaneity and emotion labels. 2.1. Featur e extraction W e extract a set of speech features follo wing the Inter - speech2009 emotion challenge [18]. The feature set includes four low le vel descriptors (LLDs) - Mel-frequency cepstral co- efficients (MFCC), zero-crossing rate (ZCR), voice probability (VP) computed using autocorrelation function, and fundamen- tal frequency (F0). For each speech sample, we use a sliding window of length w with a stride length m to extract the LLDs. This generates a k dimensional local feature vector for each windowed segment. Each descriptor is then smoothed using a moving av erage filter , and the smoothed version is used to com- pute their respective first order delta coefficients. Appending the delta features, we obtain a local feature vector of dimen- sion 2 k for e very windo wed se gment. T o create a global feature for the entire speech sample, the local features are pooled tem- porally by computing 12 different statistics (e.g. mean, range, max, kurtosis) along each of the 2 k dimensions, generating a global feature vector f ∈ R d , d = 24 k for each data sample. 2.2. Multilabel hierarchical emotion recognition Let us consider N training samples and their corresponding fea- ture representations F = { f j } N i =1 , where f j ∈ R d . Each train- ing sample with feature vector f j is associated with two labels y j = { y s j , y e j } , where y s j ∈ Y s , Y s = 0 , 1 represents the binary spontaneity labels, and y e j ∈ Y e , Y e = 0 , 1 , 2 , 3 de- notes the emotion labels. Note that only four emotion labels are considered in this paper . W e denote the entire label space as Y = Y s × Y i . In order to use the spontaneity information in speech, we propose a simple system which first recognizes if a speech sam- ple is spontaneous or not. An emotion classifier is then chosen based on the decision made by the spontaneity classifier . W e divide the entire training set Ω train of N samples into two sub- sets: Ω 1 train that contains all the spontaneous speech samples, and Ω 0 train that contains all the scripted or the non-spontaneous samples. As shown in Figure 1, we train two separate support vector machine (SVM) classifiers for recognizing emotion us- ing Ω 0 train and Ω 1 train . Additionally , we train another SVM for spontaneity detection with sequence length ` (denotes the number of consecutiv e utterances in an input sample) using F on entire Ω train . The sequence length ` is used to account for Feature SPEECH Extraction SVM MCC Joint Classification ● Emotion Recognition ● Spontaneity Detection Emotion Label Spontaneity Label Figure 2: Joint emotion and spontaneity classification. the context needed to recognize spontaneity , which is known to help in emotion recognition [19]. Later , in Section 3.2, we in- vestigate the role of ` in spontaneity detection. Note that only the spontaneity classifier uses a sequence length of ` = 10 , but the emotion recognition is performed at utterance lev el. 2.3. Multitask learning for emotion and spontaneity According to our hypothesis, spontaneity and emotional infor- mation in speech are interrelated. W e perform the tasks of spon- taneity detection and emotion recognition together in a multi- task learning frame work. Instead of focusing on a single learn- ing task, a multitask learning paradigm shares representations among related tasks by learning simultaneously , and enables better generalization [20]. Following this idea, we jointly learn to classify both spontaneity and emotion. This is posed as a multilabel multioutput classification problem. The basic idea is presented in Fig. 2, where we train a single classifier that learns to optimize a joint loss function pertaining to the two tasks. W e define a weight matrix W ∈ R | Y |× d containing a set of weight vectors w { y s ,y e } for classifying each of the | Y | possible label tuples { y s , y e } , where |·| denotes the cardinality of the set. In order to jointly model spontaneity and emotion, we intend to minimize a loss function L ( W , Y , F ) defined as follows. L ( W , Y , F ) = 1 2 X ( y s ,y e ) ∈ Y || w { y s ,y e } || 2 + C N X j =1 ζ j (1) The loss function L is sum of a a regularization loss term k w { y s ,y e } k and soft-mar gin loss term (optimization with slacks) i.e., ζ j . The parameter C controls the relative balance of the two cost terms. The term ζ j allows for misclassifica- tion of the near-margin training samples while penalizing L by imposing a loss term that varies on the degree of the misclassi- fication. The optimal classifier weights W ∗ are then learned by minimizing the joint loss function L ( W , Y , F ) as W ∗ ← arg min W ∈ R | Y |× d L ( W , Y , F ) (2) The classifier is trained i.e., W ∗ is learned using the entire Ω train using the same set of features described earlier . Since emotion can v ary between two consecuti ve recordings, the joint model uses a sequence length of ` = 1 . 3. P erf ormance Evaluation W e perform detailed experiments on the IEMOCAP database [17] to demonstrate the importance of spontaneity in the context of emotion recognition, and to validate the proposed classifica- tion models. 3.1. Experimental setup Database: W e used the USC-IEMOCAP database [17] for per- formance ev aluation. It comprises 12 hours of audiovisual data Figure 3: Effect of varying conte xt ( ` ) on spontaneity classifica- tion. along with motion capture (mocap) recordings of face and text transcriptions. The data is collected in 5 dif ferent sessions, and each session contains several dyadic con versations. Altogether there are 151 con versations, which are labeled either impro- vised (spontaneous) or scripted. This serves as our spontaneity label y s . There are almost equal number of scripted ( 52 . 2% ) and spontaneous ( 47 . 8% ) conv ersations in this database. Each con versation is further broken down to separate samples or utterances, which are organized speaker-wise in a turn-by-turn fashion. All samples are labeled by multiple annotators into one or more of the following six categories - neutral, joy , sadness, anger , frustration and e xcitement. A single sample may hav e multiple labels owing to dif ferent annotators. In such cases, the final label is chosen to be the label noted by the most annotators and randomly between all the leading labels in case of a tie. W e used the four emotion categories: anger , joy , neutral , and sadness . P arameter settings : The features described in Section 2.1 are computed using a sliding window of length w = 25 ms with a stride of m = 10 ms. This yields a local feature vector of di- mension k = 15 , and a global feature vector f of dimension d = 360 for each sample. The features are normalized to hav e values between − 1 to 1 . The SVMs use the radial basis func- tion (RBF) kernel. All results reported are the av erage statistics computed ov er a 5 -fold cross validation. 3.2. Understanding spontaneity Sanity check: W e started with the hypothesis that emotional content is different in the spontaneous vs. scripted speech. In order to check this experimentally , we trained an SVM (under the same experimental conditions described in the previous section) on Ω train of the IEMOCAP database that can discriminate among the anger, joy , neutral and sadness. During the test phase, we computed the recognition accuracy for the spontaneous and scripted speech separately . W e observe that while the overall accurac y (using the baseline SVM) of emotion recognition is 65 . 4% , recognition accurac y is higher for speech samples labeled spontaneous i.e. 73 . 0% and 56 . 8% for scripted speech (see T able 4). This basic result supports our assumption that emotional content is different in spontaneous vs. scripted speech. This observation is also consistent with the results reported in a CNN-based recent work [10]. T able 1: Effect of features on spontaneity classification accu- racy (in %) Featur e(s) removed ` = 5 ` = 10 None 91 . 4 93 . 0 ZCR 91 . 0 92 . 4 VP 90 . 6 92 . 6 F0 90 . 5 92 . 6 MFCC 83 . 4 85 . 5 VP , MFCC 80 . 7 83 . 8 F0, MFCC 83 . 2 84 . 9 ZCR, MFCC 78 . 8 82 . 3 VP , F0 90 . 6 91 . 5 VP , ZCR 90 . 2 92 . 1 F0, ZCR 90 . 6 92 . 2 VP , ZCR, F0 83 . 7 91 . 9 Any two, MFCC < 76 < 80 T able 2: Effect of keeping only the delta featur es on spontaneity classification accuracy (in %) Featur e(s) removed ` = 5 ` = 10 None 91 . 4 93 . 0 ZCR 91 . 0 92 . 4 VP 91 . 0 92 . 2 F0 90 . 9 92 . 7 MFCC 86 . 8 90 . 1 Role of context in spontaneity: W e performed spontaneity clas- sification to understand the role of v arious parameters. W e in- vestigate the role of context and the contrib ution of v arious fea- tures in spontaneity detection. W e train an SVM classifier with RBF kernel to distinguish between spontaneous and scripted speech using the features described in Section 2.1. At the ut- terance level, i.e. for ` = 1 , this system achieves an average accuracy of 80 % . In order to study the ef fect of conte xt on spontaneity classification, we vary the sequence length ` . T o account for longer conte xt, we increase ` by concatenating con- secutiv e utterances. Consequently , we concatenate their corre- sponding global features. This yields a feature v ector F ` ∈ R d . The variation of classification accuracy with different v alues of ` is shown in Fig. 3. The general trend is that the classification accuracy improves with the longer conte xt (sequence length), and achiev es 93 % accuracy for ` = 10 . This result can be intuitiv ely explained by the fact that as longer parts of the con- versation is used for classification, it becomes easier to detect spontaneity . The result also highlights that spontaneity can be detected with a fairly high accuracy and hence assures us that an additional spontaneity detection module would not harm the ov erall performance of a speech processing pipleline because of incorrect detection of spontaneity . Role of features: W e in vestigate the importance of each feature individually in spontaneity classification by performing an ab- lation study . W e e xclude one or more of the LLD features at a time, and record the corresponding spontaneity classification accuracy . From the results presented in T able 1, we observe that (i) MFCC features are the most important of all. (ii) Any single LLD feature can provide an accuracy of ∼ 75% indicating that any LLD feature is well suited for the task of spontaneity clas- sification. Moreover , comparing the accuracies achieved when removing both the delta and the actual features (as in T able 1) to removing the actual features but retaining the delta features T able 3: Emotion r ecognition results for individual classes in terms of weighted accuracy (in %). Anger Joy Neutral Sadness SVM baseline 69 . 2 37 . 0 62 . 9 76 . 9 RF baseline 73 . 1 6 . 1 78 . 8 64 . 6 CNN-based [10] 58 . 2 51 . 9 52 . 8 66 . 5 Rep. learning [21] 53 . 5 36 . 9 52 . 6 64 . 3 Spontaneity-aware methods Hierarchical 80 . 2 37 . 5 65 . 9 73 . 3 Joint 71 . 2 13 . 1 75 . 9 76 . 3 T able 4: Emotion recognition r esults for all classes together in terms of weighted accuracy (in %). Scripted Spontaneous Overall SVM baseline 56 . 8 73 . 0 65 . 4 RF baseline 62 . 1 66 . 0 64 . 1 CNN-based [10] 53 . 2 62 . 1 56 . 1 Rep. learning [21] - 52 . 8 50 . 4 Spontaneity-aware methods LSTM [11] - - 56 . 7 Hierarchical 64 . 2 74 . 0 69 . 1 Joint 63 . 2 69 . 8 66 . 1 (see T able 2), we notice that the delta features play a more cru- cial role than the original features themselv es for the task of spontaneity classification. 3.3. Emotion recognition results T o compare the gain from using the spontaneity information, we construct two baselines: an SVM-based emotion classifier , and a random forest (RF)-based emotion classifier . Both classi- fiers are trained to recognize emotion without using any infor- mation about the spontaneity labels. W e also compare with tw o other recent work on emotion recognition: CNN-based emo- tion recognition [10] and representation learning-based emo- tion recognition [21]. Additionally , we compare our results with a recent LSTM-based framew ork [11] that uses gender and spontaneity information for emotion classification. The per- formances of the proposed spontaneity-aw are emotion recogni- tion methods (i.e., hierarchical and joint) along with those for the baselines and other existing methods are presented in T a- ble 3 and T able 4. The proposed hierarchical SVM outperforms the baselines and all other competing methods by achieving an ov erall recognition accuracy of 69 . 1 %. The joint SVM model achiev es an accuracy of 66 . 1 %. Comparing the performance of the baseline SVM with the proposed spontaneity aware SVM methods, we observe that e ven with the same features and clas- sifier more than 3% improv ement for the hierarchical method in ov erall emotion recognition accuracy is achie ved just by adding spontaneity information (see T able 4). Looking at the improv e- ments in individual classes, the class anger benefits the most from spontaneity information. This is evident from a notable 11% improvement in recognition accurac y while using the hi- erarchical model over the SVM baseline (see T able 3. On the other hand, neutral shows 3% improvement, and joy is only slightly af fected by spontaneity as we compare the hierarchi- cal method to the SVM baseline. Sadness does not show any improv ement when using spontaneity . The indi vidual emo- tion recognition accuracies may possibly indicate that anger is a more spontaneous emotion (i.e., dif ficult to fak e) than other emotions, such as sadness. T able 4 shows that recognition ac- curacy is always lower for scripted speech irrespecti ve of the classification method used. This indicates that emotion is eas- ier to detect in spontaneous speech, and this result is consistent with the observations made in an earlier w ork [10]. The proposed hierarchical classifier performs slightly bet- ter than our joint classifier possibly owing to the more accurate spontaneity classification. Recall that the spontaneity classifier for the hierarchical model used longer context ( ` = 10 ) while the joint model uses ` = 1 . Ne vertheless, the joint classifier is still of practical use in the scenario when the temporal sequence of the recording is unkno wn, and hence the sequence length for spontaneity is necessarily constrained. Clearly , spontaneity information helps emotion recogni- tion. Our SVM-based methods could achiev e better result than all competing methods by explicitly detecting and us- ing spontaneity information in speech. The reason behind our SVM-based methods outperforming deep learning-based meth- ods (e.g., CNN-based [10], Rep. learning [21] ) is possibly the use of spontaneity and a longer context in the case of hierar- chical method. The LSTM-based spontaneity a ware method though uses the same four classes as ours, they use an aggre- gated corpus (using IEMOCAP and other databases) for training the LSTM network. Such training is different from our experi- mental setting. 4. Conclusion In this paper , we studied ho w spontaneity information in speech can inform and improve an emotion recognition system. The primary goal of this work is to study the aspects of data that can inform an emotion recognition system, and also to gain insights to the relationship between spontaneous speech and the task of emotion recognition. T o this end, we in vestigated two super- vised schemes that utilize spontaneity to impro ve emotion clas- sification: a multilabel hierarchical model that performs spon- taneity classification before emotion recognition, and a multi- task learning model that jointly learns to classify both spontane- ity and emotion. Through v arious experiments, we sho wed that spontaneity is a useful information for speech emotion recog- nition, and can significantly improve the recognition rate. Our method achiev es state-of-the-art recognition accurac y (4-class, 69.1%) on the IEMOCAP database. Future work could be di- rected to wards understanding the effect of other meta informa- tion, such as age and gender . 5. Acknowledgement The authors would like to thank SAIL, USC for pro viding ac- cess to the IEMOCAP database. 6. Refer ences [1] F . Dellaert, T . Polzin, and A. W aibel, “Recognizing emotion in speech, ” in Spoken Language , 1996. ICSLP 96. Pr oceedings., F ourth International Conference on , vol. 3. IEEE, 1996, pp. 1970–1973. [2] M. Abdelw ahab and C. Busso, “Ensemble feature selection for domain adaptation in speech emotion recognition, ” in ICASSP 2017 , 2017. [3] C. Busso, Z. Deng, S. Y ildirim, M. Bulut, C. M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, and S. Narayanan, “ Anal- ysis of emotion recognition using facial expressions, speech and multimodal information, ” in Proceedings of the 6th international confer ence on Multimodal interfaces . ACM, 2004, pp. 205–211. [4] Q. Jin, C. Li, S. Chen, and H. Wu, “Speech emotion recognition with acoustic and lexical features, ” in ICASSP 2015 . IEEE, 2015, pp. 4749–4753. [5] Y . Zong, W . Zheng, T . Zhang, and X. Huang, “Cross-corpus speech emotion recognition based on domain-adaptiv e least- squares regression, ” IEEE Signal Pr ocessing Letters , vol. 23, no. 5, pp. 585–589, 2016. [6] T . L. Nwe, S. W . Foo, and L. C. De Silva, “Speech emotion recognition using hidden markov models, ” Speech communica- tion , vol. 41, no. 4, pp. 603–623, 2003. [7] B. Schuller, G. Rigoll, and M. Lang, “Hidden markov model- based speech emotion recognition, ” in Multimedia and Expo, 2003. ICME’03. Proceedings. 2003 International Conference on , vol. 1. IEEE, 2003, pp. I–401. [8] C. M. Lee and S. S. Narayanan, “T oward detecting emotions in spoken dialogs, ” IEEE trans. speech and audio pr ocessing , vol. 13, no. 2, pp. 293–303, 2005. [9] W . Lim, D. Jang, and T . Lee, “Speech emotion recognition us- ing conv olutional and recurrent neural networks, ” in Signal and Information Processing Association Annual Summit and Confer- ence (APSIP A), 2016 Asia-P acific . IEEE, 2016, pp. 1–4. [10] M. Neumann and N. T . V u, “ Attentive conv olutional neural net- work based speech emotion recognition: A study on the impact of input features, signal length, and acted speech, ” in Interspeec h , 2017. [11] J. Kim, G. Englebienne, K. T ruong, and V . Ev ers, T owards Speech Emotion Recognition ”in the wild” using Aggre gated Corpora and Deep Multi-T ask Learning . International Speech Communi- cation Association (ISCA), 2017, pp. 1113–1117. [12] J. Deng, Z. Zhang, F . Eyben, and B. Schuller , “ Autoencoder-based unsupervised domain adaptation for speech emotion recognition, ” IEEE Signal Pr ocessing Letters , vol. 21, no. 9, pp. 1068–1072, 2014. [13] R. Dufour , V . Jousse, Y . Est ` eve, F . B ´ echet, and G. Linar ` es, “Spontaneous speech characterization and detection in large au- dio database, ” SPECOM, St. P etersbur g , 2009. [14] R. Dufour , Y . Est ` eve, and P . Del ´ eglise, “Characterizing and de- tecting spontaneous speech: Application to speaker role recogni- tion, ” Speech communication , v ol. 56, pp. 1–18, 2014. [15] G. Mehta and A. Cutler , “Detection of tar get phonemes in sponta- neous and read speech, ” Language and Speech , v ol. 31, no. 2, pp. 135–156, 1988, pMID: 3256770. [16] L. Tian, J. D. Moore, and C. Lai, “Emotion recognition in sponta- neous and acted dialogues, ” in Int. Conf. Af fective Computing and Intelligent Interaction (A CII) . IEEE, 2015, pp. 698–704. [17] C. Busso, M. Bulut, C. Lee, A. Kazemzadeh, E. Mower , S. Kim, J. Chang, S. Lee, and S. Narayanan, “Iemocap: Interactiv e emo- tional dyadic motion capture database, ” Language Resources and Evaluation , vol. 42, no. 4, pp. 335–359, 12 2008. [18] B. Schuller, S. Steidl, and A. Batliner , “The interspeech 2009 emotion challenge, ” in T enth Annual Confer ence of the Interna- tional Speech Communication Association , 2009. [19] R. Gupta, N. Malandrakis, B. Xiao, T . Guha, M. V an Segbroeck, M. Black, A. Potamianos, and S. Narayanan, “Multimodal predic- tion of affecti ve dimensions and depression in human-computer interactions, ” in Proceedings of the 4th International W orkshop on Audio/V isual Emotion Challenge . ACM, 2014, pp. 33–40. [20] T . Evgeniou and M. Pontil, “Regularized multi–task learning, ” in Pr oceedings of the tenth ACM SIGKDD international conference on Knowledg e discovery and data mining . ACM, 2004, pp. 109– 117. [21] S. Ghosh, E. Laksana, L.-P . Morency , and S. Scherer , “Repre- sentation learning for speech emotion recognition. ” in INTER- SPEECH , 2016, pp. 3603–3607.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment