GHTraffic: A Dataset for Reproducible Research in Service-Oriented Computing
We present GHTraffic, a dataset of significant size comprising HTTP transactions extracted from GitHub data and augmented with synthetic transaction data. The dataset facilitates reproducible research on many aspects of service-oriented computing. This paper discusses use cases for such a dataset and extracts a set of requirements from these use cases. We then discuss the design of GHTraffic, and the methods and tool used to construct it. We conclude our contribution with some selective metrics that characterise GHTraffic.
💡 Research Summary
The paper introduces GHTraffic, a large‑scale dataset of HTTP transactions derived from GitHub’s REST API and augmented with synthetically generated requests. Recognizing the growing importance of reproducible research in service‑oriented computing (SOC), the authors first identify four primary use cases: performance benchmarking, functional testing, service virtualization, and broader empirical studies. From these scenarios they derive six design requirements (R1–R6): the dataset must be large yet manageable (multiple size editions), easy to use (standardized JSON schema and processing scripts), reproducible and principled (extracted from real‑world data or generated by well‑defined procedures), current (reflect modern API usage), precise (conform to HTTP syntax and semantics), and diverse (cover a wide range of methods and status codes).
A review of existing benchmarks (TPC‑W, SPECweb2009) and security‑focused traffic collections (DARPA, CSIC) shows that they are limited to GET/POST and 200 responses, failing to capture the richness of contemporary RESTful services. GHTraffic therefore fills a gap by including GET, POST, PUT, DELETE, PATCH and other methods, as well as a spectrum of response codes (200, 201, 204, 400‑500).
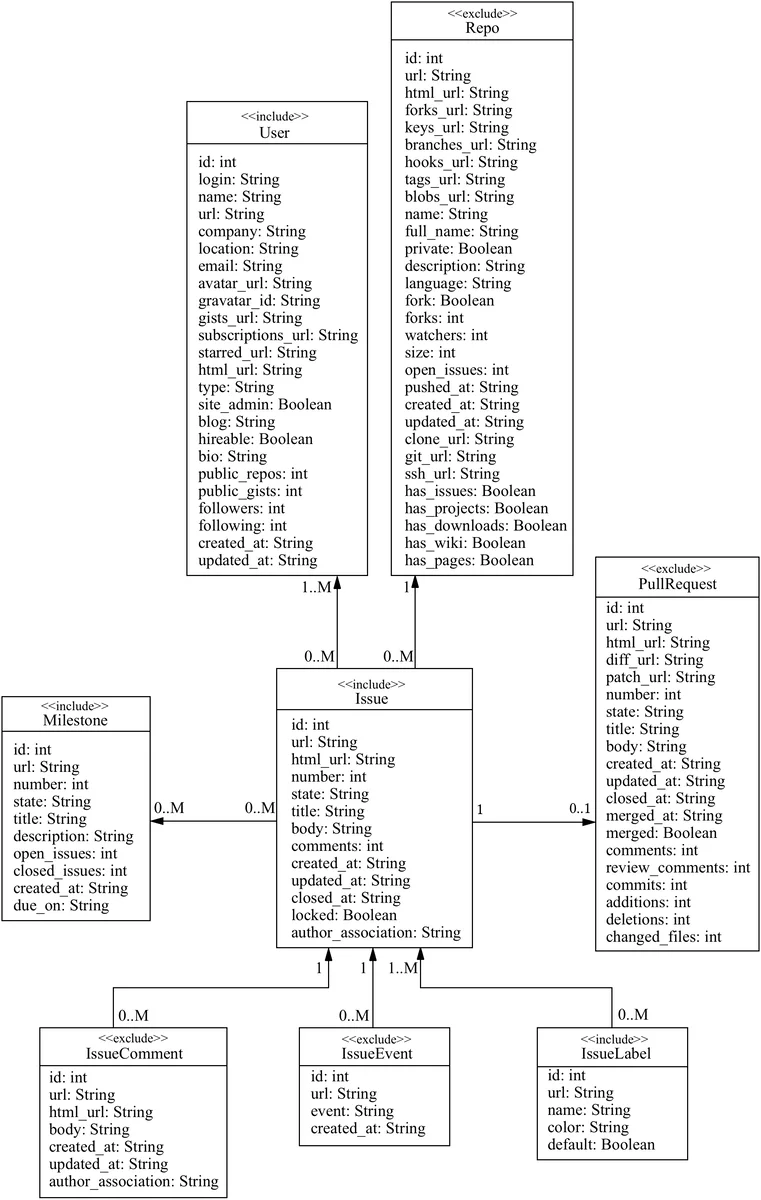
The construction pipeline leverages the GHTorrent project, which provides terabyte‑scale snapshots of GitHub’s data model. To keep the dataset manageable (R1), the authors focus on the Issue tracking subsystem, selecting four entities—Issue, User, Milestone, and Label. By reverse‑engineering the snapshots, they infer create, read, update, and delete (CRUD) API calls that must have occurred to produce the observed state. Because snapshots are static, they miss read‑only GET requests, failed operations, and “shadowed” requests (e.g., a successful PUT later deleted). To address this, a synthetic augmentation step generates missing transactions according to well‑defined rules that preserve logical consistency (e.g., a GET on a non‑existent resource yields 404, a successful POST yields 201).
The final dataset comprises over 100 million real transactions and an additional ~50 million synthetic ones, totaling more than 150 million records. It is distributed as compressed line‑delimited JSON files together with a metadata schema and a set of Python/R/Shell utilities for loading, filtering, and basic analytics. The authors provide three size editions (small, medium, large) to satisfy R1.
Evaluation includes statistical analyses of method distribution, status‑code frequencies, temporal patterns, and comparison with live GitHub API logs, confirming high fidelity. The dataset’s diversity enables realistic benchmarking of web servers, micro‑service frameworks, and machine‑learning models for service virtualization. Sample experiments demonstrate latency/throughput measurement under realistic workloads and the use of GHTraffic as an oracle for testing inferred service models.
Threats to validity are discussed: potential missing requests due to reverse‑engineering limits, API version drift, and the realism of synthetic data. The authors mitigate these by planning periodic updates, open‑source tooling, and community feedback loops.
In conclusion, GHTraffic satisfies the six articulated requirements, offering a publicly available, standards‑compliant, and richly featured HTTP transaction corpus. It supports reproducible experiments across performance, functional correctness, and automated service modeling, thereby advancing the methodological rigor of SOC research.
Comments & Academic Discussion
Loading comments...
Leave a Comment