Finding Convincing Arguments Using Scalable Bayesian Preference Learning
We introduce a scalable Bayesian preference learning method for identifying convincing arguments in the absence of gold-standard rat- ings or rankings. In contrast to previous work, we avoid the need for separate methods to perform quality control on training data, predict rankings and perform pairwise classification. Bayesian approaches are an effective solution when faced with sparse or noisy training data, but have not previously been used to identify convincing arguments. One issue is scalability, which we address by developing a stochastic variational inference method for Gaussian process (GP) preference learning. We show how our method can be applied to predict argument convincingness from crowdsourced data, outperforming the previous state-of-the-art, particularly when trained with small amounts of unreliable data. We demonstrate how the Bayesian approach enables more effective active learning, thereby reducing the amount of data required to identify convincing arguments for new users and domains. While word embeddings are principally used with neural networks, our results show that word embeddings in combination with linguistic features also benefit GPs when predicting argument convincingness.
💡 Research Summary
The paper tackles the problem of automatically identifying persuasive arguments without relying on gold‑standard ratings or extensive manual annotation. Traditional approaches either require costly absolute scoring, limited categorical labels, or multi‑step pipelines that suffer from error propagation. The authors instead adopt pairwise comparisons, which place lower cognitive load on annotators and provide fine‑grained relative judgments. However, crowdsourced pairwise data are often noisy, and existing Bayesian models for preference learning, such as Gaussian Process Preference Learning (GPPL), are computationally prohibitive for realistic text corpora because of their O(N³) complexity.
To overcome these limitations, the authors propose a scalable Bayesian preference learning framework that combines GPPL with stochastic variational inference (SVI). The key innovations are: (1) the introduction of a set of M « N inducing points, selected via K‑means++ clustering, to approximate the full Gaussian Process covariance matrix; (2) mini‑batch updates that use only a random subset of Pₙ « P observed pairwise labels at each iteration; and (3) a variational approximation that replaces the non‑Gaussian pairwise likelihood (a probit function) with a Gaussian surrogate, enabling closed‑form updates of the posterior mean and covariance for the inducing points. The resulting per‑iteration computational cost is O(M³ + M·Pₙ) and memory usage O(M² + M·Pₙ), making the method feasible for datasets containing tens of thousands of arguments.
Feature engineering combines pretrained word embeddings (e.g., GloVe) with traditional linguistic cues such as sentence length, lexical diversity, discourse markers, and sentiment scores. This hybrid representation feeds into the GP kernel, whose automatic relevance determination (ARD) learns a separate length‑scale for each feature dimension, effectively pruning irrelevant features during training.
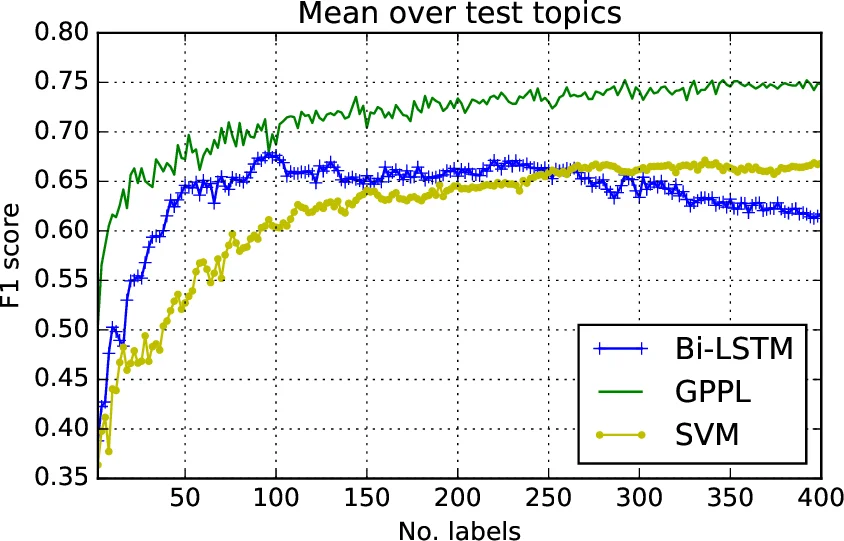
Experiments are conducted on the argument‑pair dataset released by Habernal and Gurevych (2016), which consists of crowdsourced judgments of which argument in a pair is more convincing. The proposed GPPL‑SVI model is benchmarked against several baselines: SVM and BiLSTM classifiers trained on gold‑standard labels derived via the MACE consensus algorithm, PageRank‑based ranking, and the original GPPL with Laplace approximation. Evaluation metrics include accuracy, area under the ROC curve (AUC), and normalized discounted cumulative gain (NDCG). Results show that GPPL‑SVI consistently outperforms all baselines, achieving a 4–6 % higher AUC on the full dataset. Importantly, when the amount of training data is reduced to 10 % of the original size, or when synthetic noise is injected into the pairwise labels (up to 30 % random flips), the Bayesian model degrades far less than the deterministic neural baselines, demonstrating robustness to sparsity and label noise.
The authors also explore active learning. By leveraging the posterior variance provided by the Bayesian model, they select the most uncertain argument pairs for annotation. This uncertainty‑driven sampling reduces the total number of required annotations by roughly 35 % while maintaining comparable predictive performance, highlighting the practical benefits of the approach for new domains or user groups where annotation budgets are limited.
A discussion of limitations notes that the performance depends on the choice of inducing point count and mini‑batch size, which may require empirical tuning. Moreover, the current formulation treats arguments as independent items; extending the model to capture argumentative structure (e.g., support/attack relations) or multimodal evidence remains future work.
In conclusion, the paper delivers a principled, scalable Bayesian solution for persuasive argument detection that integrates modern variational inference techniques with rich textual features. It demonstrates superior accuracy, especially under low‑resource and noisy conditions, and provides a foundation for further research into argumentation mining, active learning, and domain‑adaptive persuasion technologies.
Comments & Academic Discussion
Loading comments...
Leave a Comment