Learning Visually Grounded Sentence Representations
We introduce a variety of models, trained on a supervised image captioning corpus to predict the image features for a given caption, to perform sentence representation grounding. We train a grounded sentence encoder that achieves good performance on COCO caption and image retrieval and subsequently show that this encoder can successfully be transferred to various NLP tasks, with improved performance over text-only models. Lastly, we analyze the contribution of grounding, and show that word embeddings learned by this system outperform non-grounded ones.
💡 Research Summary
The paper tackles the longstanding “grounding problem” in sentence representation learning by explicitly linking textual sentences to visual information. While most prior work on universal sentence embeddings relies solely on large text corpora—using methods such as Skip‑Thought, InferSent, or unsupervised composition of word vectors—these approaches lack any connection to the external world and therefore struggle to capture concrete, perceptual semantics. To address this, the authors propose a suite of models that are trained on the COCO image‑caption dataset to predict visual features from a caption, thereby forcing the sentence encoder to learn representations that are compatible with a visual semantic space.
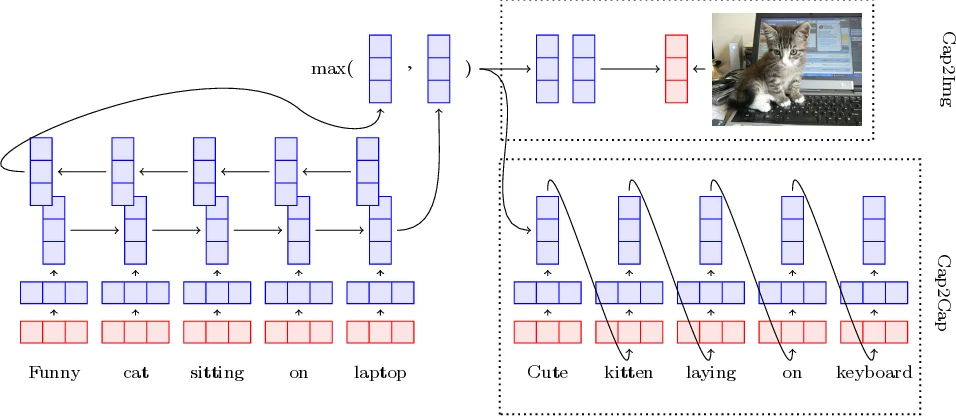
The core architecture consists of a bidirectional LSTM (BiLSTM) that processes fixed GloVe word embeddings (300‑dim). Before feeding the embeddings into the BiLSTM, a learnable linear transformation U maps them into a “grounded word space”. The forward and backward hidden states are combined by element‑wise max‑pooling, yielding a fixed‑size sentence vector h_T (2048 dimensions). Three grounding strategies are explored:
-
Cap2Img (strong perceptual grounding) – h_T is passed through several non‑linear projection layers (ELU activation) to predict the latent image representation v extracted from the final layer of a ResNet‑101 pretrained on ImageNet. Training uses a margin‑based ranking loss that pushes the cosine similarity of the correct image higher than that of negative samples.
-
Cap2Cap (weak implicit grounding) – Pairs of captions describing the same image are used in a sequence‑to‑sequence setup. The encoder is the same BiLSTM; a decoder LSTM generates an alternative caption, optimized with the standard cross‑entropy loss. This indirect grounding leverages the shared visual context without directly using image features.
-
Cap2Both (combined grounding) – Both the ranking loss of Cap2Img and the cross‑entropy loss of Cap2Cap are summed, allowing the model to benefit from strong visual alignment and from the richer linguistic signal provided by caption paraphrasing.
Because COCO focuses on concrete objects and scenes, the authors acknowledge that purely visual grounding may be insufficient for abstract sentences. To mitigate this, they concatenate the grounded sentence vectors with language‑only sentence embeddings trained on the large Toronto Books corpus (e.g., Skip‑Thought). The resulting hybrid representation, named Ground‑Sent (GS), comes in three variants: GroundSent‑Img, GroundSent‑Cap, and GroundSent‑Both, depending on the underlying grounding strategy.
Experiments are conducted on two fronts. First, the authors evaluate image‑caption retrieval on the COCO 5K benchmark. GroundSent‑Both achieves the highest Recall@1/5/10, outperforming the single‑task models by 3–5 percentage points, demonstrating that the learned sentence vectors are effective proxies for visual content. Second, they transfer the learned representations to a suite of seven downstream NLP tasks using the SentEval framework (including sentiment analysis, paraphrase detection, textual similarity, and question classification). Across almost all tasks, GroundSent‑Both surpasses a strong baseline of layer‑normalized Skip‑Thought vectors, with average gains of roughly 2–3 % in accuracy or correlation. Notably, tasks that benefit from concrete semantics (e.g., semantic textual similarity) show the largest improvements.
A further analysis examines the word embeddings themselves. By extracting the transformed GloVe vectors (U · x) after training, the authors find consistent gains on standard word similarity benchmarks (SimLex‑999, WordSim‑353) compared to the original GloVe vectors, indicating that visual grounding refines lexical semantics as well.
The paper discusses several important observations. Grounding is most beneficial for concrete language; abstract sentences receive limited help from visual features and may even suffer from noise, which justifies the concatenation with language‑only embeddings. The ranking loss is shown to be more robust than an L2 regression loss, as it focuses learning on the dimensions of the visual space that matter for semantic alignment. The authors also note dataset bias: COCO’s limited domain may restrict the universality of the learned representations, and they propose future work on multi‑task joint training, incorporation of more powerful visual backbones (e.g., Vision Transformers), and extension to multilingual caption datasets.
In summary, this work introduces a clear and effective method for grounding sentence representations in visual data, demonstrates that such grounding yields measurable improvements on both vision‑language retrieval and a broad set of pure‑text NLP tasks, and provides evidence that visual grounding can also enhance word‑level embeddings. The study offers a compelling argument for integrating multimodal signals into universal language models and sets a solid foundation for future research on multimodal, multilingual, and abstract‑concept‑aware sentence encoding.
Comments & Academic Discussion
Loading comments...
Leave a Comment