Voice Imitating Text-to-Speech Neural Networks
We propose a neural text-to-speech (TTS) model that can imitate a new speaker's voice using only a small amount of speech sample. We demonstrate voice imitation using only a 6-seconds long speech sample without any other information such as transcrip…
Authors: Younggun Lee, Taesu Kim, Soo-Young Lee
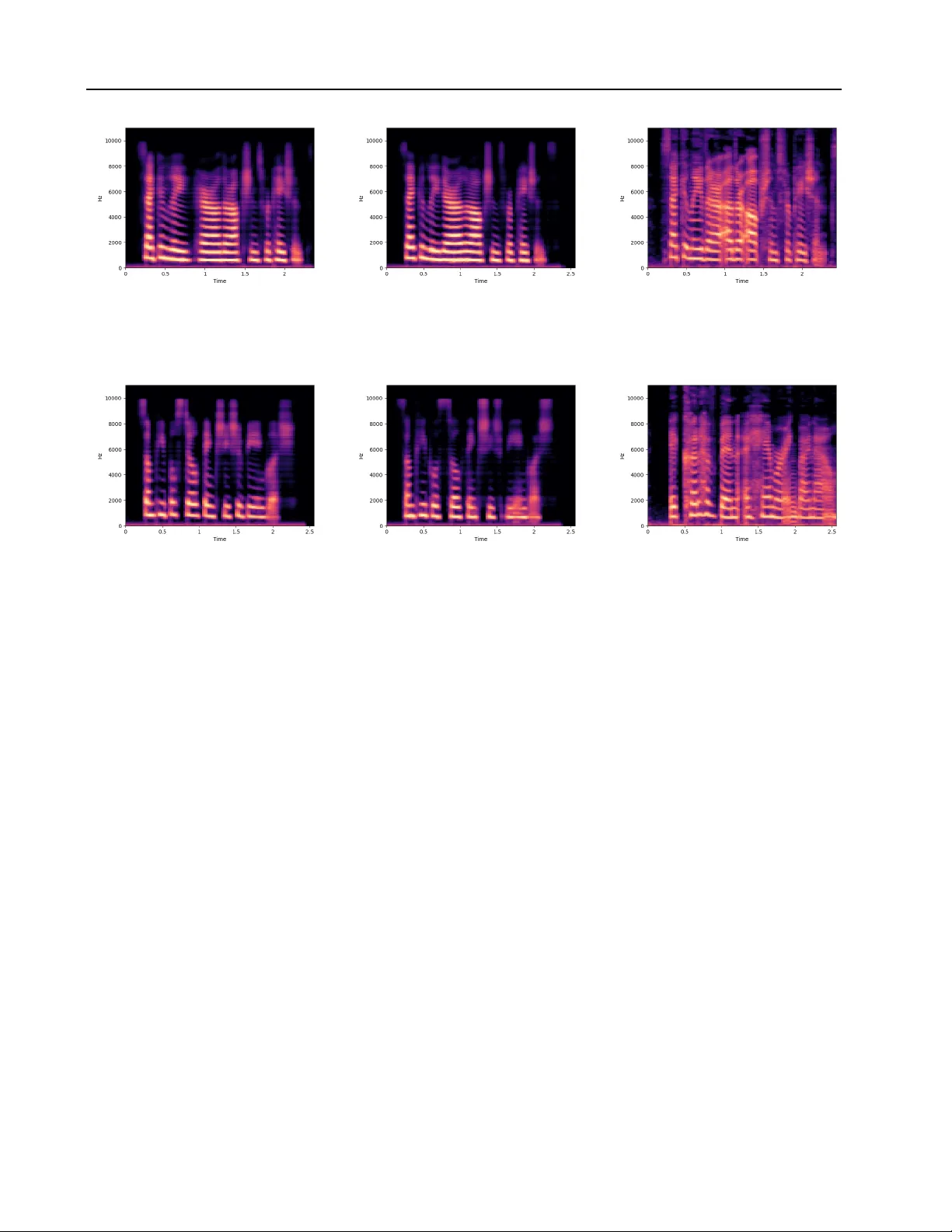
V oice Imitating T ext-to-Speech Neural Networks Y ounggun Lee 1 T aesu Kim 1 Soo-Y oung Lee 2 Abstract W e propose a neural text-to-speech (TTS) model that can imitate a new speak er’ s voice using only a small amount of speech sample. W e demon- strate voice imitation using only a 6-seconds long speech sample without any other information such as transcripts. Our model also enables voice imi- tation instantly without additional training of the model. W e implemented the voice imitating TTS model by combining a speaker embedder network with a state-of-the-art TTS model, T acotron. The speaker embedder network takes a ne w speaker’ s speech sample and returns a speaker embedding. The speaker embedding with a tar get sentence are fed to T acotron, and speech is generated with the new speaker’ s voice. W e show that the speaker embeddings extracted by the speaker embedder network can represent the latent structure in dif- ferent v oices. The generated speech samples from our model have comparable voice quality to the ones from existing multi-speaker TTS models. 1. Introduction W ith recent improvements in deep neural network, re- searchers came up with neural netw ork based vocoders such as W aveNet ( van den Oord et al. , 2016 ) and SampleRNN ( Mehri et al. , 2017 ). Those models sho wed their ability to generate high quality waveform from acoustic features. Some researchers further devised neural netw ork based text- to-speech (TTS) models which can replace the entire TTS system with neural networks ( Arık et al. , 2017a ; b ; Ping et al. , 2018 ; W ang et al. , 2017 ; Shen et al. , 2017 ). Neu- ral network based TTS models can be built without prior knowledge of a language when generating speech. Neural TTS models can be easily built compared to the previous approaches, which require carefully designed features, if we hav e enough (speech, te xt) pair data. Furthermore, the 1 Neosapience, Seoul, Korea 2 K orea Advanced Institute of Science and T echnology , Daejeon, K orea. Correspon- dence to: Y ounggun Lee < yg@neosapience.com > , T aesu Kim < taesu@neosapience.com > . Preliminary work. neural network based TTS models are capable of generating speech with different v oices by conditioning on a speaker’ s index ( Arık et al. , 2017b ; Ping et al. , 2018 ) or an emotion label ( Lee et al. , 2017 ). Some researchers ha ve tried to imitate a ne w speaker’ s v oice using the speaker’ s recordings ( T aigman et al. , 2018 ). T aig- man et al. reported their model’ s ability to mimic a ne w speaker’ s voice by learning a speaker embedding of the ne w speaker ( 2018 ). Ho we v er , this approach requires additional training stage and transcriptions of the new speaker’ s speech sample. The transcription may not be alw ays av ailable, and the additional training stage prohibits immediate imitation of a ne w speaker’ s voice. In this study , we propose a v oice imitating TTS model that can imitate a new speaker’ s voice without transcript of speech sample or additional training. This enables the v oice imitation process immediately us- ing only a short speech sample of a speak er . The proposed model takes two inputs: (1) tar get text and (2) a speaker’ s speech sample. The speech sample is first transformed into a speaker embedding by the speaker embedder network. Then a neural network based TTS model generates speech output by conditioning on the speaker embedding and the text input. W e implemented a baseline multi-speak er TTS model based on T acotron, and we also implemented voice imitating TTS model by extending the baseline model. W e inv estigated la- tent space of the learned speaker embeddings by visualizing with principal component analysis (PCA). W e directly qual- itativ ely compared similarity of voice from the both TTS models and the ground truth data. W e further conducted two types of surve ys to analyze the result quantitatively . The first surve y compared generation quality of the v oice imitating TTS and the multi-speaker TTS. The second surve y checked how speaker-discriminable speech samples are generated by the both models. The main contributions of this study can be summarized as follows: 1. The proposed model makes it possible to imitate a new speaker’ s voice using only a 6-seconds long speech sample. 2. Imitating a ne w speaker’ s voice can be done immedi- ately without additional training. V oice Imitating T ext-to-Speech Neural Networks 3. Our approach allows TTS model to utilize various sources of information by changing the input of the speaker embedder network. 2. Background In this section, we re vie w previous works that are related to our study . W e will cover both traditional TTS systems and neural netw ork based TTS systems. The neural netw ork based TTS systems includes neural vocoder , single-speak er TTS, multi-speaker TTS, and v oice imitation model. Common TTS systems are composed of two major parts: (1) text encoding part and (2) speech generation part. Using prior kno wledge about the target language, domain e xperts hav e defined useful features of the target language and have extracted them from input texts. This process is called a text encoding part, and man y natural language processing techniques hav e been used in this stage. For e xample, a grapheme-to-phoneme model is applied to input texts to obtain phoneme sequences, and a part-of-speech tagger is applied to obtain syntactic information. In this manner , the text encoding part takes a text input and returns various linguistic features. Then, the follo wing speech generation part takes the linguistic features and generates wav eform of the speech. Examples of the speech generation part include concatenativ e and parametric approach. The concatena- tiv e approach generates speech by connecting short units of speech which has a scale of phoneme or sub-phoneme lev el, and the parametric TTS utilizes a generative model to generate speech. Having seen neural networks show great performance in regression and classification tasks, researchers ha ve tried to substitute previously used components in TTS systems. Some group of researchers came up with neural network architectures that can substitute the vocoder of the speech generation part. Those works include W av enet ( van den Oord et al. , 2016 ) and SampleRNN ( Mehri et al. , 2017 ). W av enet can generate speech by conditioning on sev eral lin- guistic features, and Sotelo et al. showed that SampleRNN can generate speech by conditioning on vocoder parame- ters ( 2017 ). Although these approaches can substitute some parts of the pre viously used speech synthesis frame works, they still required external modules to e xtract the linguis- tic features or the v ocoder parameters. Some researchers came up with neural netw ork architectures that can substi- tute the whole speech synthesis framew ork. Deep V oice 1 ( Arık et al. , 2017a ) is made of 5 modules where all mod- ules are modelled using neural networks. The 5 modules exhausti v ely substitute the te xt encoding part and the speech generation part of the common speech synthesis framew ork. While Deep voice 1 is composed of only neural networks, it was not trained in end-to-end fashion. W ang et al. proposed fully end-to-end speech synthesis model called T acotron ( 2017 ). T acotron can be regarded as a v ariant of a sequence-to-sequence network with at- tention mechanism ( Bahdanau et al. , 2014 ). T acotron is composed of three modules: encoder, decoder , and post- processor (refer to Figure 1 ). T acotron basically follows the sequence-to-sequence framew ork with attention mecha- nism, especially which con v erts a character sequence into corresponding wa v eform. More specifically , the encoder takes the character sequence as an input and generates a text encoding sequence which has same length with the character sequence. The decoder generates Mel-scale spec- trogram in an autoregressi v e manner . Combining attention alignment with the text encoding gi v es a context vector , and decoder RNN takes conte xt v ector and output of the atten- tion RNN as inputs. The decoder RNN predicts Mel-scale spectrogram, and the post-processor module consequently generates linear-scale spectrogram from the Mel-scale spec- trogram. Finally , Grif fin-Lim reconstruction algorithm esti- mates wa veform from the linear -scale spectrogram ( Griffin & Lim , 1984 ). Single-speaker TTS systems have further extended to the multi-speaker TTS systems which can generate speech by conditioning on a speaker index. Arik et al. proposed Deep V oice 2, a modified version of Deep V oice 1, to enable multi- speaker TTS ( 2017a ; 2017b ). By feeding learned speaker embedding as nonlinearity biases, recurrent neural network initial states, and multiplicativ e gating factors, the y showed their model can generate multiple voices. They also sho wed T acotron is able to generate multiple voice using the similar approach. Another study reported a TTS system that can generate voice containing emotions ( Lee et al. , 2017 ). This approach is similar to the multi-speaker T acotron in Deep V oice 2 paper, but the model could be b uilt with less number of speaker embedding input connections. Multi-speaker TTS model is further extended to v oice imita- tion model. Current multi-speaker TTS models takes a one- hot represented speaker index vector as an input, and this is not easily extendable to generate v oices which are not in the training data. Because the model can learn embeddings only for the speakers represented by one-hot v ectors, there is no way to get a new speaker’ s embedding. If we want to generate speech of a ne w speaker , we need to retrain the whole TTS model or fine-tune the embedding layer of the TTS model. Ho we v er , training of the network requires large amount of annotated speech data, and it takes time to train the network until con ver gence. T aigman et al. proposed a model that can mimic a new speak er’ s voice ( 2018 ). While freezing the model’ s parameters, the y backpropagated errors using new speaker’ s (speech, text, speaker index) pairs to get a learned embedding. Howe ver , this model could not ov ercome the problems we mentioned earlier . The retrain- ing step requires (speech, text) pair which can be inaccurate V oice Imitating T ext-to-Speech Neural Networks Figure 1. Multi-speaker T acotron or e v en una v ailable for data from the wild. Furthermore, because of the additional training, v oice imitation cannot be done immediately . In this study , we will propose a TTS model that does not require annotated (speech, text) pairs so that it can be utilized in more general situations. Moreo ver , our model can immediately mimic a new speaker’ s voice without retraining. 3. V oice imitating neural speech synthesizer 3.1. Multi-speaker TTS One advantage to use neural network for a TTS model is that it is easy to give conditions when generating speech. For in- stance, we can giv e condition by just adding a speaker inde x input. Among se v eral approaches to neural network based multi-speaker TTS models, we decided to adopt the architec- ture of Lee et al. ( 2017 ). Their model e xtends T acotron to take a speaker embedding vector at the decoder of T acotron (see Figure 1 ). If we drop the connections from the one-hot speaker ID input and the speaker embedding vector s , there is no difference from the original T acotron architecture. The model has two tar gets in its objecti ve function: (1) Mel-scale spectrogram target Y mel and (2) linear -scale spectrogram target Y linear . L1 distances of each Mel-scale spectrograms ˆ Y mel and Y mel and linear-scale spectrograms ˆ Y linear and Y linear are added to compute the objecti ve function as fol- lows: Loss = || Y linear − ˆ Y linear || 1 + || Y mel − ˆ Y mel || 1 (1) where ˆ Y ’ s are output of the T acotron and Y ’ s are the ground truth spectrograms. Note that, there is no direct supervi- sion on the speaker embedding vector , and each speaker Figure 2. The speaker embedder network index will ha ve corresponding speak er embedding vector s learned by backpropagated error from the loss function ( 1 ). By its formulation, the model can store only the speaker em- beddings appeared in the training data at the Lookup table. When we want to generate a speech with a new speaker’ s voice, we need another speaker embedding for that speak er . In order to get a speaker embedding of the unseen speakers, we should train the model again with the ne w speaker’ s data. This retraining process consumes much time, and the model’ s usability limited to the voice with large data size. V oice Imitating T ext-to-Speech Neural Networks Figure 3. V oice imitating T acotron 3.2. Proposed model One possible approach to address the problem is direct ma- nipulation of the speaker embedding v ector . Assuming the speaker embedding vector can represent arbitrary speakers’ voices, we may get desired voice by changing values of the speaker embedding vector , but it will be hard to find the exact combination of v alues of the speak er embedding vector . This approach is not only inaccurate but also labor intensiv e. Another possible approach is to retrain the net- work using the ne w speaker’ s data. W ith enough amount of data, this approach can gi ve us the desired speech out- put. Howe ver , it is not likely to ha v e enough data of the new speaker , and the training process requires much time until con v ergence. T o tackle this problem more ef ficiently , we propose a no vel TTS architecture that can generate a new speak ers voice using a small amount of speech sample. The imitation of a speaker’ s v oice can be done immediately without requiring additional training or manual search of the speaker embedding vector . The proposed v oice imitating TTS model is an extension of the multi-speaker T acotron in Section 3.1 . W e added a subnetwork that predicts a speak er embedding vector from a speech sample of a target speaker . Figure 2 shows the sub- network, the speaker embedder , that contains con volutional layers followed by fully connected layers. This network takes log-Mel-spectrogram as input and predicts a fixed di- mensional speaker embedding vector . Notice that, the input of speaker embedder network is not limited to the speech sample. Substituting input of the speaker embedder net- work enables TTS models to condition on various sources of information, but we focus on conditioning on a speaker’ s speech sample in this paper . Prediction of the speaker embedding vector requires only one forward pass of the speaker embedder network. This enables immediate imitation of the proposed model to gen- erate speech for a new speak er . Although the input spectro- grams may ha ve v arious lengths, the max-over -time pooling layer , which is located at the end of the con v olutional lay- ers, squeezes the input into a fixed dimensional vector with length 1 for time axis. In this way , the voice imitating TTS model can deal with input spectrograms with arbitrary lengths. The speaker embedder with input speech sample re- places the Lookup table with one-hot speaker ID input of the multi-speaker T acotron as described in Figure 3 . F or train- ing of the voice imitating TTS model, we also use the same objectiv e function ( 1 ) with the multi-speaker TTS. Note also that, there is no supervision on training the speaker embedding vector . 4. Experiments 4.1. Dataset In accordance with Arik et al., we used VCTK corpus which contains 109 nati ve English speak ers with v arious accents ( 2017b ). The population of speak ers in VCTK corpus has various accents and ages, and each speaker recorded around 400 sentences. W e preprocessed the raw dataset in several ways. At first, we manually annotated transcripts for audio files which did not hav e corresponding transcripts. Then, for the text data, we filtered out symbols if they are not English letters or numbers or punctuation marks. W e used capital letters with- out decapitalization. F or the audio data, we trimmed silence using W ebR TC V oice Acti vity Detector ( Google ). Report- V oice Imitating T ext-to-Speech Neural Networks T able 1. Speaker profiles of the test set. I D A G E G E N D E R A C C E N T S R E G I O N 2 2 5 2 3 F E N G L I S H S . E N G L A N D 2 2 6 2 2 M E N G L I S H S U R R E Y 2 4 3 2 2 M E N G L I S H L O N D O N 2 4 4 2 2 F E N G L I S H M A N C H E S T E R 2 6 2 2 3 F S C O T T I S H E D I N B U R G H 2 6 3 2 2 M S C O T T I S H A B E R D E E N 3 0 2 2 0 M C A NA D I A N M O N T R E A L 3 0 3 2 4 F C A NA D I A N T O RO N T O 3 6 0 1 9 M A M E R I C AN N E W J E R S E Y 3 6 1 1 9 F A M E R I C AN N E W J E R S E Y edly , trimming silence is important for training T acotron ( Arık et al. , 2017b ; W ang et al. , 2017 ). Note that, there is no label which tells the model when to start speech. If there is silence in the beginning of audio file, the model cannot learn what is the proper time to start speech. Removing silence can alleviate this problem by aligning the starting times of speeches. After the trimming, the total length of the dataset became 29.97 hours. Then, we calculated log- Mel-spectrogram and log-linear-spectrogram of each audio file. When generating spectrogram, we used Hann windo w of frame length 50ms and shifted windows by 12.5ms. 4.2. T raining In this experiment, we trained two TTS models: multi- speaker T acotron and voice imitating T acotron. In the rest of this paper , we will use terms multi-speaker TTS and voice imitating TTS to refer the two models respectiv ely . T o train the latter model, we did additional data preparation process. W e prepared speech samples of each speaker since the model needs to predict a speak er embedding from log- Mel-spectrogram of a speech sample. Since we thought it is hard to capture a speakers characteristic in a short sentence, we concatenated one speakers whole speech data and made samples by applying fixed size rectangular windo w with ov erlap. The resulting window covers around 6 seconds of speech, which can contain sev eral sentences. W e fed a speech sample a tar get speaker to the model together with text input, while randomly drawing the speech sample from the windowed sample pool. W e did not used the speech sample that is matched to the text input to pre v ent model from learning to generate by coping from the input speech sample. Furthermore, when training the v oice imitating TTS model, we held out 10 speakers data for test set since we wanted to check if the model can generate unseen speakers voices. The profiles of 10 held out speakers are shown in T able 1 . W e selected them to have similar distrib ution with training data in terms of gender , age, and accent. For the T acotrons parameters, we basically followed speci- fications written in the original T acotron paper except the (a) V oice imitating TTS (b) Multi-speaker TTS Figure 4. Principal component of speaker embeddings of v oice imitating TTS and multi-speaker TTS, sho wn with gender of the speakers reduction factor r ( W ang et al. , 2017 ). W e used 5 for the r , which means generating 5 spectrogram frames at each time-step. For hyperparameters of the speaker embedder network, we used the following settings. W e used 5-layered 1D-con v olutional neural network with 128 channels and window size of 3. The first 2 layers hav e stride of 1 and the remaining 3 layers have stride of 2. W e used 2 linear layers with 128 hidden units after the con v olutional lay- ers. W e used ReLU as a nonlinearity and applied batch normalization for ev ery layer ( Iof fe & Szegedy , 2015 ). W e also applied dropout with ratio of 0.5 to improv e generaliza- tion ( Sri vasta v a et al. , 2014 ). The last layer of the speak er embedder network is a learnable projection layer without nonlinearity and dropout. W e used mini-batch size of 32. During the training, lim- ited capacity of GPUs memory prevented us from loading a mini-batch of long sequences at once. T o maximize the uti- lization of data, we used truncated backpropagation through time ( Rumelhart et al. , 1985 ). W e used gradient clipping to av oid the exploding gradient problem ( P ascanu et al. , 2013 ). W e used 1.0 as a clipping threshold. For the optimization, we used AD AM ( Kingma & Ba , 2014 ), which adaptively changes scale of update, with parameters 0.001, 0.9, and 0.999 for learning rate, β 1 , and β 2 respectiv ely . 5. Result W e first checked performance of v oice imitating TTS quali- tativ ely by in v estigating learned latent space of the speaker embeddings. In order to check how the speak er embeddings are trained, we applied PCA to the speaker embeddings. Pre- vious researches reported discriminati v e patterns were found from the speaker embeddings in terms of gender and other aspects ( Arık et al. , 2017b ; T aigman et al. , 2018 ). Figure 4 shows the first two principal components of the speaker embeddings where green and red colors represent female and male respecti vely . W e could see clear separation from speaker embeddings of the multi-speaker TTS as reported from other studies. Although the speaker embeddings of voice imitating TTS had an o v erlapped area, we could ob- V oice Imitating T ext-to-Speech Neural Networks V oice imitating TTS Multi-speaker TTS Ground truth Figure 5. Mel-spectrogram from Multi-speaker TTS and voice imitating TTS, generated for train set V oice imitating TTS Multi-speaker TTS Ground truth Figure 6. Mel-spectrogram from Multi-speaker TTS and voice imitating TTS, generated for test set serve that the female embeddings are dominant in the left part, whereas the male embeddings are dominant in the right part. Besides, some of the embeddings located far from the center . W e suspect that the o verlap and the outliers are ex- isting because the speaker embedding is extracted from a randomly chosen speech sample of a speaker . A speech sample of a male speaker can hav e only the particularly lower -pitched v oice, or a speech sample of a female speaker can ha ve only particularly higher-pitched v oice. This may result in prediction of the out-lying embeddings, and similar argument could be applied for the ov erlapping embeddings. T o check how similar are the generated voices and the ground truth v oice, we compared spectrogram and speech samples from the voice imitating TTS to that of multi- speaker TTS model and the ground truth data. Then, by feeding a text from the training data while conditioning on the same speaker , we generated samples from voice im- itating TTS and multi-speaker TTS. Then we compared the generated samples and the corresponding ground truth speech samples. Example spectrograms from the both mod- els and the ground truth data are sho wn in Figure 5 . W e could observ e both models gav e us similar spectrogram, and also the dif ference between them was negligible when we listened to the speech samples. From the spectrogram, we could observe the y ha ve similar pitch and speed by seeing heights and widths of harmonic patterns. When we com- pared generated samples of the both models to the ground truth data, we could observ e the samples from the both mod- els having simliar pitch with the ground truth. W e could see the model can learn to predict speaker embedding from the speech samples. Similarly , we analyzed spectrograms to check whether the voice imitating TTS can generalize well on the test set. Note that, the multi-speak er TTS included the test set of the voice imitating TTS for its training data, because otherwise multi- speaker TTS cannot generate speech for unseen speakers. In Figure 6 , we also could observe spectrograms from gen- erated samples showing similar pattern, especially for the pitch of each speaker . With these results, we conjecture that the model at least learned to encode pitch information in the speaker embedding, and it w as generalizable to the unseen speakers. Since it is difficult to e v aluate generated speech sample ob- jectiv ely , we conducted surve ys using cro wdsourcing plat- forms such as Amazon’ s Mechanical T urk. W e first made speech sample comparison questions to ev aluate voice qual- ity of generated samples. This survey is composed of 10 questions. For each question, 2 audio samples–one from the voice imitating TTS and the other one from the multi- V oice Imitating T ext-to-Speech Neural Networks Figure 7. A verage scores of generated sample comparison surve y , where the symbols mean: M >> I - M (the multi-speaker TTS) is far better than I (the voice imitating TTS), M > I - M is little better than I, M = I - Both M and I hav e same quality speaker TTS–are presented to participants, and the partici- pants are asked to gi ve a score from -2 (multi-speak er TTS is far better than voice imitating TTS) to 2 (multi-speaker TTS is far worse than voice imitating TTS). W e gathered 590 ratings on the 10 questions from 59 participants (see Figure 7 ). From the result, we could observe the ratings were concentrated on the center with ov erall mean score of − 0 . 10 ± 1 . 16 . It seems there is not much difference in the voice quality of the voice imitating TTS and the multi- speaker TTS. For the second surve y , we made speaker identification ques- tions to check whether generated speech samples contain distinct characteristics. The surve y consists of 40 questions, where each question has 3 audio samples: ground truth sam- ple and two generated samples. The two generated samples were from the same TTS model, but each of which condi- tioned on different speak ers’ index or speech samples. The participants are asked to choose one speech sample that sounds mimicking the same speaker identity of the ground truth speech sample. From the cro wdsourcing platform, we found 50 participants for surveying the v oice imitating TTS and other 50 participants for surveying the multi-speak er TTS model. The resulted speak er identification accuracies were 60.1 % and 70.5 % for the voice imitating TTS and the multi-speaker TTS respecti vely . Considering random selection will score 50 % of accuracy , we may argue higher accuracies than 50 % reflect distinguishable speaker iden- tity in the generated speech samples. By its nature of the problem, it is more dif ficult to generate distinct v oice for the voice imitating TTS. Because the voice imitating TTS must capture a speaker’ s characteristic in a short sample whereas the multi-speaker TTS can learn the characteristic from v ast amount of speech data. Considering these difficulties, we think the score gap between the two models are explainable. 6. Conclusion W e ha ve proposed a no vel architecture that can imitate a new speaker’ s v oice. In contrast to the current multi-speaker speech synthesis models the voice imitating TTS could gen- erate a new speaker’ s voice using a small amount of speech sample. Furthermore, our method could imitate voice im- mediately without additional training. W e have ev aluated generation performance of the proposed model both in qual- itativ ely and quantitati vely , and we have found there is no significant difference in the v oice quality between the voice imitating TTS and the multi-speaker TTS. Though gener - ated speech from the voice imitating TTS hav e sho wed less distinguishable speaker identity than that from the multi- speaker TTS, generated v oices from the voice imitating TTS contained pitch information which can make voice distin- guishable from other speakers’ v oice. Our approach is particularly differentiated from the previous approaches by learning to extract features with the speak er embedder network. Feeding v arious sources of information to the speaker embedder network makes TTS models more versatile, and exploring its possibility is connected to our fu- ture works. W e expect intriguing researches can be done in the future by e xtending our approach. One possible direction will be a multi-modal conditioned text-to-speech. Although this paper has focused on extracting speaker embedding from a speech sample, the speak er embedder network can learn to extract speaker embedding from various sources such as video. In this paper , the speaker embedder network has extracted a speak er’ s characteristic from a speech sam- ple. By applying same approach to a facial video sample, the speaker embedder netw ork may capture emotion or other characteristics from the video sample. The resulting TTS system will be able to generate a speaker’ s voice which contains appropriate emotion or characteristics for a given facial video clip and an input text. Another direction will be cross-lingual voice imitation. Since our model requires no transcript corresponding to the new speaker’ s speech sample, the model has a potential to be applied in the cross-lingual en vironment. For instance, imitating a Chinese speaker’ s voice to generate English sentence can be done. References Arık, Sercan ¨ O., Chrzanowski, Mike, Coates, Adam, Di- amos, Gregory , Gibiansky , Andre w , Kang, Y ongguo, Li, Xian, Miller , John, Ng, Andre w , Raiman, Jonathan, Sen- gupta, Shubho, and Shoeybi, Mohammad. Deep voice: Real-time neural te xt-to-speech. In Precup, Doina and T eh, Y ee Whye (eds.), Proceedings of the 34th Interna- tional Conference on Machine Learning , volume 70 of Pr oceedings of Mac hine Learning Researc h , pp. 195–204, International Con v ention Centre, Sydney , Australia, 06– 11 Aug 2017a. PMLR. V oice Imitating T ext-to-Speech Neural Networks Arık, Sercan O, Diamos, Gregory , Gibiansky , Andrew , Miller , John, Peng, Kainan, Ping, W ei, Raiman, Jonathan, and Zhou, Y anqi. Deep v oice 2: Multi-speaker neural text-to-speech. In Guyon, I., Luxburg, U. V ., Bengio, S., W allach, H., Fer gus, R., V ishwanathan, S., and Garnett, R. (eds.), Advances in Neural Information Pr ocessing Sys- tems 30 , pp. 2966–2974. Curran Associates, Inc., 2017b. Bahdanau, Dzmitry , Cho, Kyungh yun, and Bengio, Y oshua. Neural machine translation by jointly learning to align and translate. 2014. URL 1409.0473 . Google. W ebrtc voice activity detector . https:// webrtc.org/ . Griffin, Daniel and Lim, Jae. Signal estimation from modi- fied short-time fourier transform. IEEE T ransactions on Acoustics, Speech, and Signal Pr ocessing , 32(2):236–243, 1984. Ioffe, Ser ge y and Szegedy , Christian. Batch normalization: Accelerating deep network training by reducing internal cov ariate shift. In International confer ence on mac hine learning , pp. 448–456, 2015. Kingma, Diederik P . and Ba, Jimmy . Adam: A method for stochastic optimization. International Conference on Learning Repr esentations , 2014. Lee, Y ounggun, Rabiee, Azam, and Lee, Soo-Y oung. Emo- tional end-to-end neural speech synthesizer . W orkshop Machine Learning for Audio Signal Pr ocessing at NIPS (ML4Audio@NIPS17) , 2017. Mehri, Soroush, Kumar , K undan, Gulrajani, Ishaan, Kumar , Rithesh, Jain, Shubham, Sotelo, Jose, Courville, Aaron, and Bengio, Y oshua. Samplernn: An unconditional end- to-end neural audio generation model. International Con- fer ence on Learning Repr esentations , 2017. Pascanu, Razv an, Mikolov , T omas, and Bengio, Y oshua. On the difficulty of training recurrent neural networks. In International Conference on Machine Learning , pp. 1310–1318, 2013. Ping, W ei, Peng, Kainan, Gibiansky , Andrew , Arik, Ser- can O., Kannan, Ajay , Narang, Sharan, Raiman, Jonathan, and Miller , John. Deep voice 3: 2000-speaker neural text-to-speech. International Confer ence on Learning Repr esentations , 2018. Rumelhart, David E, Hinton, Geoffrey E, and Williams, Ronald J. Learning internal representations by error prop- agation. T echnical report, California Univ San Die go La Jolla Inst for Cognitiv e Science, 1985. Shen, Jonathan, Pang, Ruoming, W eiss, Ron J, Schuster , Mike, Jaitly , Navdeep, Y ang, Zongheng, Chen, Zhifeng, Zhang, Y u, W ang, Y uxuan, Skerry-Ryan, RJ, et al. Nat- ural tts synthesis by conditioning wa venet on mel spec- trogram predictions. arXiv pr eprint arXiv:1712.05884 , 2017. Sotelo, Jose, Mehri, Soroush, Kumar , Kundan, Santos, Joao Felipe, Kastner , Kyle, Courville, Aaron, and Ben- gio, Y oshua. Char2w av: End-to-end speech synthesis. International Confer ence on Learning Repr esentations workshop , 2017. Sriv asta v a, Nitish, Hinton, Geoffre y , Krizhevsk y , Alex, Sutske ver , Ilya, and Salakhutdinov , Ruslan. Dropout: A simple way to prev ent neural networks from overfit- ting. The J ournal of Machine Learning Resear ch , 15(1): 1929–1958, 2014. T aigman, Y aniv , W olf, Lior , Polyak, Adam, and Nachmani, Eliya. V oiceloop: V oice fitting and synthesis via a phono- logical loop. International Confer ence on Learning Rep- r esentations , 2018. van den Oord, Aaron, Dieleman, Sander , Zen, Heiga, Simonyan, Karen, V inyals, Oriol, Graves, Alexander , Kalchbrenner , Nal, Senior , Andre w , and Ka vukcuoglu, K oray . W av enet: A generati ve model for raw audio. In Arxiv , 2016. URL 1609.03499 . W ang, Y uxuan, Skerry-Ryan, R.J., Stanton, Daisy , W u, Y onghui, W eiss, Ron J., Jaitly , Na vdeep, Y ang, Zongheng, Xiao, Y ing, Chen, Zhifeng, Bengio, Samy , Le, Quoc, Agiomyrgiannakis, Y annis, Clark, Rob, and Saurous, Rif A. T acotron: T owards end-to-end speech synthe- sis. In Pr oc. Interspeec h 2017 , pp. 4006–4010, 2017. doi: 10.21437/Interspeech.2017- 1452.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment