Automatically Identifying Fake News in Popular Twitter Threads
Information quality in social media is an increasingly important issue, but web-scale data hinders experts’ ability to assess and correct much of the inaccurate content, or `fake news,’ present in these platforms. This paper develops a method for automating fake news detection on Twitter by learning to predict accuracy assessments in two credibility-focused Twitter datasets: CREDBANK, a crowdsourced dataset of accuracy assessments for events in Twitter, and PHEME, a dataset of potential rumors in Twitter and journalistic assessments of their accuracies. We apply this method to Twitter content sourced from BuzzFeed’s fake news dataset and show models trained against crowdsourced workers outperform models based on journalists’ assessment and models trained on a pooled dataset of both crowdsourced workers and journalists. All three datasets, aligned into a uniform format, are also publicly available. A feature analysis then identifies features that are most predictive for crowdsourced and journalistic accuracy assessments, results of which are consistent with prior work. We close with a discussion contrasting accuracy and credibility and why models of non-experts outperform models of journalists for fake news detection in Twitter.
💡 Research Summary
The paper tackles the pressing problem of automatically detecting fake news on Twitter, a task complicated by the scarcity of large, reliably labeled datasets that distinguish true from false stories. To overcome this limitation, the authors adopt a transfer‑learning strategy: they train credibility‑prediction models on two existing Twitter‑based datasets—CREDBANK and PHEME—and then apply these models to a third, independent dataset derived from BuzzFeed’s fact‑checking work.
CREDBANK is a massive crowdsourced collection of roughly 1,400 events, each annotated by 30 Amazon Mechanical Turk workers on a five‑point Likert scale ranging from “certainly inaccurate” (‑2) to “certainly accurate” (+2). The annotations are heavily skewed toward the “accurate” end, reflecting a general tendency of non‑experts to assume information is correct. PHEME, by contrast, consists of 330 rumor threads curated by Swissinfo journalists, each labeled as true, false, or unverified. The authors also incorporate the BuzzFeed dataset, which contains 35 highly shared political stories (both true and false) originally fact‑checked on Facebook; they retrieve the corresponding Twitter threads by searching for the story headlines and extracting the most retweeted tweets.
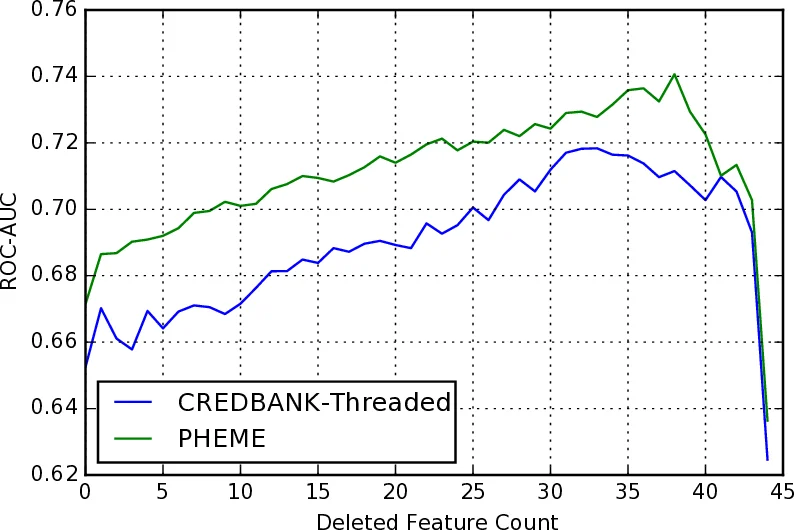
To enable a fair comparison across these heterogeneous sources, the authors engineer a unified feature set of 45 variables spanning four categories: (1) structural features (e.g., total tweet count, thread lifetime, depth of the conversation tree, ratios of hashtags, media, mentions, retweets, and URLs); (2) user features (e.g., account age, average follower/friend/status counts, presence of verified accounts, and a network‑density metric derived from a graph of mentions/retweets); (3) content features (e.g., sentiment polarity, subjectivity, proportion of disagreement or refutation tweets, use of question/exclamation marks, pronoun frequencies, emoticons); and (4) temporal features (slopes of the aforementioned variables over time, obtained by fitting linear regressions to log‑transformed cumulative values). Many of these features are directly borrowed from Castillo et al.’s 2013 credibility study, while others (notably the network‑density and temporal‑slope measures) are novel contributions.
The authors train standard classifiers—logistic regression and random forests—using five‑fold cross‑validation, converting the original multi‑class labels into a binary “accurate vs. inaccurate” format for evaluation. Performance is measured primarily by accuracy and F1‑score, with Castillo et al.’s 64 % accuracy on credibility classification serving as a baseline.
Results reveal a clear hierarchy: models trained on CREDBANK achieve the highest accuracy (≈66 %), modestly surpassing the baseline; PHEME‑trained models lag behind (≈58 %); and a pooled model that combines both datasets actually performs worse than CREDBANK alone (≈60 %). Feature‑importance analysis uncovers systematic differences: the CREDBANK model relies heavily on network‑centric variables (density, temporal growth of tweet volume, account‑age gaps), suggesting that crowdsourced workers are more sensitive to how information propagates through the social graph. In contrast, the PHEME model places greater weight on textual cues (sentiment polarity, disagreement ratios, punctuation usage), aligning with the intuition that journalists focus on the content of the messages themselves.
The authors discuss several implications. First, the superior performance of the crowdsourced model challenges the conventional wisdom that expert judgments are inherently more reliable for misinformation detection. It appears that non‑experts capture “social dynamics” cues that are highly predictive of falsehoods, whereas experts may overlook these signals. Second, the study highlights the importance of feature selection tailored to the labeling population; a one‑size‑fits‑all feature set may not be optimal when the ground truth originates from different annotator groups.
Limitations are acknowledged. Mapping BuzzFeed’s Facebook‑centric stories to Twitter threads inevitably introduces noise, as headline searches may retrieve unrelated tweets or miss relevant ones. The CREDBANK label distribution is heavily biased toward “accurate,” potentially inflating the model’s conservatism. Moreover, the analysis is confined to Twitter; extending the approach to other platforms (Facebook, Reddit, Instagram) would test its generality.
In conclusion, the paper makes three primary contributions: (1) an end‑to‑end pipeline for automatically classifying popular Twitter threads as true or false, (2) a comparative analysis of how crowdsourced versus journalist annotations influence feature importance and model performance, and (3) the public release of three aligned datasets in a uniform format to facilitate future research. By demonstrating that non‑expert crowdsourced assessments can outperform journalist‑based ones in the context of fake‑news detection, the work invites a re‑examination of how credibility signals are harvested and leveraged in automated fact‑checking systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment