Multi-Reward Reinforced Summarization with Saliency and Entailment
Abstractive text summarization is the task of compressing and rewriting a long document into a short summary while maintaining saliency, directed logical entailment, and non-redundancy. In this work, we address these three important aspects of a good summary via a reinforcement learning approach with two novel reward functions: ROUGESal and Entail, on top of a coverage-based baseline. The ROUGESal reward modifies the ROUGE metric by up-weighting the salient phrases/words detected via a keyphrase classifier. The Entail reward gives high (length-normalized) scores to logically-entailed summaries using an entailment classifier. Further, we show superior performance improvement when these rewards are combined with traditional metric (ROUGE) based rewards, via our novel and effective multi-reward approach of optimizing multiple rewards simultaneously in alternate mini-batches. Our method achieves the new state-of-the-art results (including human evaluation) on the CNN/Daily Mail dataset as well as strong improvements in a test-only transfer setup on DUC-2002.
💡 Research Summary
The paper tackles three essential qualities of a good abstractive summary—saliency (the inclusion of the most important information), logical entailment (the summary must be a logically consistent compression of the source), and non‑redundancy. While recent neural summarizers have addressed redundancy through coverage mechanisms, they still treat all tokens equally when optimizing for ROUGE, and they lack explicit signals for saliency and entailment. To fill this gap, the authors propose a reinforcement‑learning (RL) framework that augments the standard ROUGE‑L reward with two novel reward functions: ROUGESal and Entail.
ROUGESal modifies the ROUGE calculation by weighting each token with a saliency score. These scores are produced by a dedicated saliency predictor trained on the SQuAD reading‑comprehension dataset: answer spans are treated as human‑annotated salient phrases, and a bidirectional LSTM classifier learns to assign a probability of “salient” to every token in a sentence. The resulting probabilities are used as multiplicative weights in the precision, recall, and F‑measure components of ROUGE, thereby giving more credit to summaries that contain important phrases.
Entail measures how well the generated summary is logically entailed by the reference summary (used as premise) using a pre‑trained natural‑language‑inference (NLI) model (the Decomposable Attention model of Parikh et al., 2016) trained on SNLI and Multi‑NLI. For each generated sentence, the model computes the entailment probability with respect to the ground‑truth summary; the average of these probabilities forms the Entail reward. To prevent short, trivial sentences from receiving inflated scores, the authors apply a length‑normalization factor that scales the reward by the ratio of generated‑summary length to reference‑summary length.
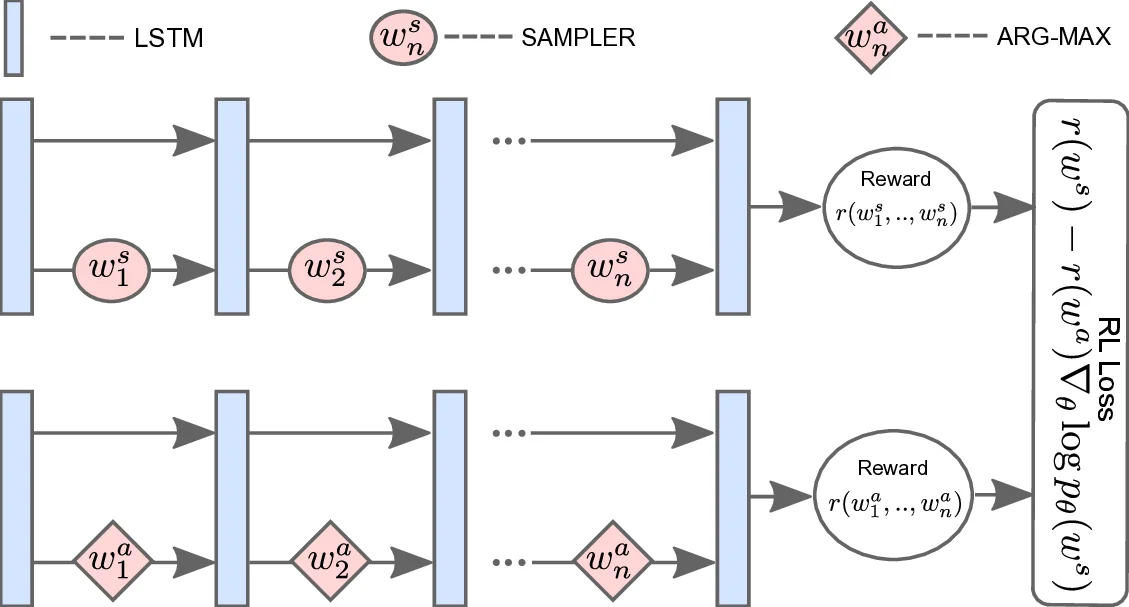
Training proceeds with the Self‑Critical Sequence Training (SCST) variant of REINFORCE: the baseline is the ROUGE (or other) score of the model’s own greedy output, and the sampled output’s reward is compared against this baseline to compute the policy gradient. The overall loss is a convex combination of the standard cross‑entropy loss and the RL loss (γ·L_RL + (1‑γ)·L_XE), ensuring fluency while still optimizing the non‑differentiable rewards.
A key methodological contribution is the “multi‑reward optimization” strategy. Instead of forming a weighted sum of the different rewards—a process that would require careful scaling and hyper‑parameter tuning—the authors alternate mini‑batches: one batch optimizes the ROUGESal loss, the next batch optimizes the Entail loss, and so on. All batches share the same model parameters, akin to multi‑task learning, but each batch’s loss is computed with a single reward. This simple alternating scheme sidesteps the scaling problem while still allowing the model to learn from multiple signals simultaneously.
The experimental setup uses the non‑anonymous CNN/Daily Mail corpus for primary evaluation and DUC‑2002 for a test‑only transfer experiment. The baseline is the pointer‑generator network with coverage (See et al., 2017). Saliency predictor training uses SQuAD; the entailment classifier is trained on the combined SNLI and Multi‑NLI corpora. Evaluation metrics include ROUGE‑1, ROUGE‑2, ROUGE‑L, and METEOR, plus a human study on Amazon Mechanical Turk assessing relevance (saliency, correctness, non‑redundancy) and readability (fluency, grammar, coherence).
Results show that each new reward alone improves over the baseline and over a pure ROUGE‑L RL reward. ROUGESal yields higher ROUGE‑1/2/L and METEOR scores, confirming that emphasizing salient tokens helps the model select more important content. Entail improves ROUGE‑L and dramatically boosts METEOR, indicating better semantic fidelity. When combined, ROUGESal + Entail achieves the best scores across all automatic metrics (ROUGE‑1 = 40.43, ROUGE‑2 = 18.00, ROUGE‑L = 37.10, METEOR = 20.02), surpassing the previous state‑of‑the‑art. Human evaluation (100 random examples) shows the multi‑reward model is preferred over See et al.’s model in 55 vs. 34 cases for relevance and 54 vs. 33 for readability, with 11–13 “not distinguishable” judgments. In the DUC‑2002 transfer setting, the ROUGESal + Entail model also outperforms the baseline, demonstrating that the learned saliency and entailment signals generalize beyond the training domain.
The authors discuss several insights: (1) Saliency prediction from QA answer spans is an effective proxy for keyphrase importance; (2) Entailment scoring at the sentence level, combined with length normalization, provides a robust semantic consistency signal without requiring document‑level NLI, which remains challenging; (3) Alternating multi‑reward training is a lightweight yet powerful way to integrate heterogeneous objectives. Limitations include reliance on SQuAD (wiki‑domain) for saliency, which may bias the model toward topics common in that corpus, and the fact that the entailment reward only checks sentence‑to‑sentence entailment rather than full‑document logical coherence. Future work could explore domain‑specific saliency annotations, document‑level entailment models, or meta‑learning approaches to automatically balance multiple rewards.
In summary, the paper introduces a principled method for injecting saliency and logical entailment into abstractive summarization via reinforcement learning. By designing reward functions that directly reflect these qualities and by training with an alternating multi‑reward schedule, the authors achieve state‑of‑the‑art performance on a major benchmark and demonstrate improved transferability, offering a compelling blueprint for quality‑oriented reward design in other text generation tasks.
Comments & Academic Discussion
Loading comments...
Leave a Comment