Transfer Learning from Adult to Children for Speech Recognition: Evaluation, Analysis and Recommendations
Children speech recognition is challenging mainly due to the inherent high variability in children's physical and articulatory characteristics and expressions. This variability manifests in both acoustic constructs and linguistic usage due to the rap…
Authors: Prashanth Gurunath Shivakumar, Panayiotis Georgiou
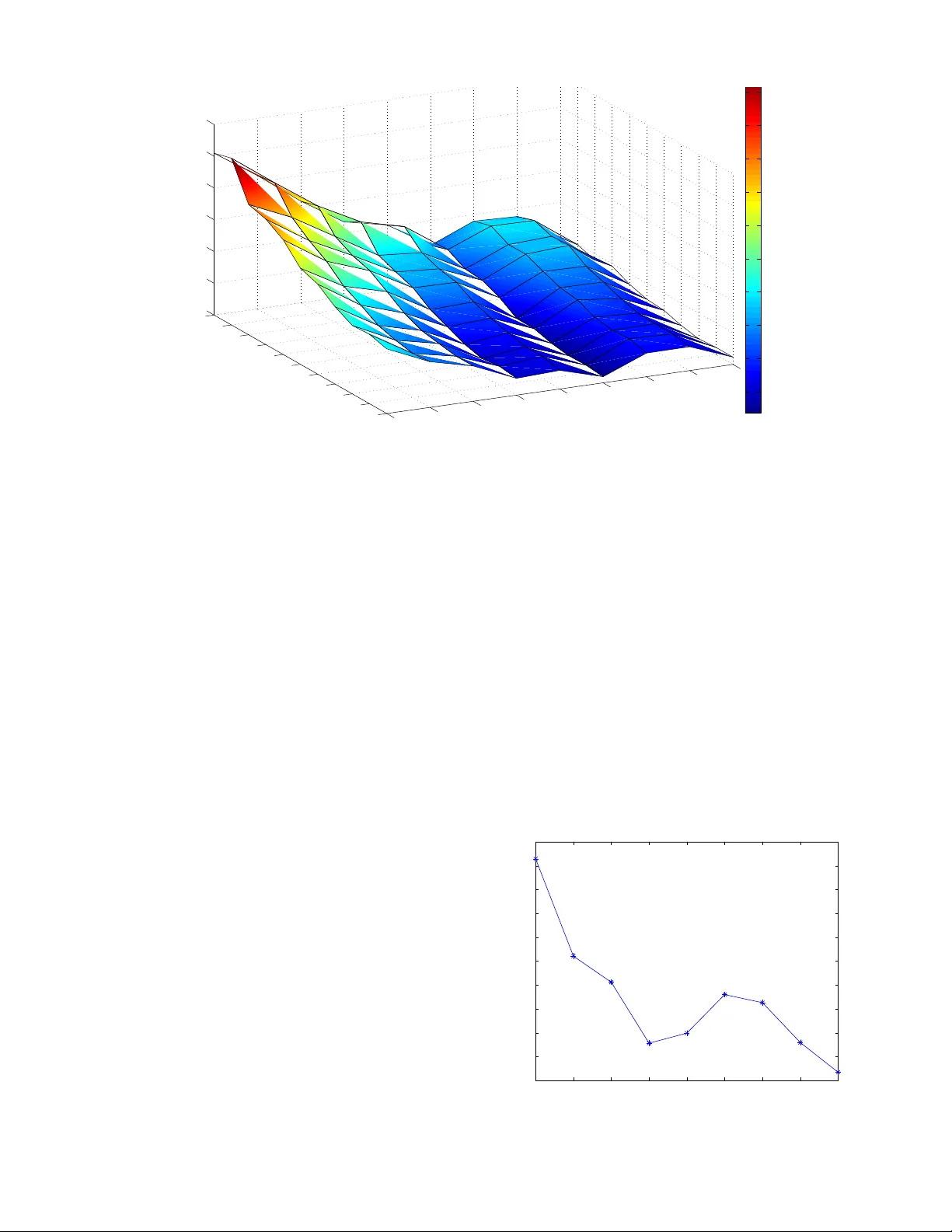
1 T ransfer Learning from Adult to Children for Speech Recognition: Ev aluation, Analysis and Recommendations Prashanth Gurunath Shi v akumar , Member , IEEE and Panayiotis Geor giou, Senior Member , IEEE Abstract —Children speech recognition is challenging mainly due to the inherent high variability in children’ s physical and articulatory characteristics and expr essions. This variability man- ifests in both acoustic constructs and linguistic usage due to the rapidly changing developmental stage in children’ s life. Part of the challenge is due to the lack of large amounts of available children speech data for efficient modeling. This work attempts to address the key challenges using transfer lear ning from adult’s models to children’ s models in a Deep Neural Network (DNN) framework for children’ s A utomatic Speech Recognition (ASR) task ev aluating on multiple childr en’ s speech corpora with a large vocab ulary . The paper presents a systematic and an extensive analysis of the proposed transfer learning technique considering the key factors affecting children’ s speech recognition from prior literature. Evaluations ar e presented on (i) comparisons of earlier GMM-HMM and the newer DNN Models, (ii) effectiveness of standard adaptation techniques versus transfer learning, (iii) var - ious adaptation configurations in tackling the variabilities pr esent in children speech, in terms of (a) acoustic spectral variability , and (b) pronunciation variability and linguistic constraints. Our Analysis spans over (i) number of DNN model parameters (for adaptation), (ii) amount of adaptation data, (iii) ages of children, (iv) age dependent-independent adaptation. Finally , we provide Recommendations on (i) the fav orable strategies over various afor ementioned - analyzed parameters, and (ii) potential future resear ch directions and relev ant challenges/problems persisting in DNN based ASR for children’ s speech. Index T erms —A utomatic Speech Recognition, Deep Learning, T ransfer Learning, Deep Neural Network, Children Speech Recognition I . I N T RO D U C T I O N Speech recognition has become an ubiquitous part of our life. A range of applications, such as human-machine interac- tion, communication, education, pronunciation and communi- cation tutoring, entertainment and interactive gaming depend on such functionality . This has become partly possible due to high accuracies achieved by state-of-the-art speech recog- nition systems. An important user population for many such technologies are children. Howe ver , Automatic Speech Recog- nition (ASR) for children is still significantly less accurate than that of adults. With the recent increased deployment of speech based technologies it becomes ever more important to be inclusi ve towards children. Thus there is a need to robustly address the challenges brought by the variability in kids speech. Researchers hav e studied how the speech patterns of chil- dren differ to that of the adults. Prior studies ha ve looked The authors are with the University of Southern California, Los Angeles, USA; e-mail:pgurunat@usc.edu and georgiou@sipi.usc.edu into the factors affecting, and degrading, the performance of ASR. Children speech was found to exhibit high lev el of variability . The research suggests that the variability exists in two le vels. Firstly , the variability is embedded in the acoustic signals in the form of spectral and temporal variability , due to the physiological and de velopmental differences of children. Secondly , there is variability in kids pronunciation patterns, due to differing and partial linguistic knowledge. Acoustic variability can be attributed to three main factors (i) shifted ov erall spectral content and formant frequencies for children [1], (ii) high within-subject variability in the spectral content, that affects formant locations [2], (iii) high inter - speaker variability observed across age groups, due to devel- opmental changes, especially vocal tract [3]. [2] conducted a detailed study analyzing the temporal and spectral parameters of children speech. The study found that the within-subject variability decreased with increase in age from 5 years to 12 years, reaching adult levels at an age of 15. The wor d err or rates (WER) for children’ s ASR were found to be 2 to 5 times worse than adults [1]. Due to the specificity associated with children’ s speech, training children-specific ASR models w as found to be highly advantageous. Age dependent ASR models were also studied giving promising improv ements, thereby confirming high inter-age dependent acoustic variability in children [4]. [5] studied the effect of speech bandwidth on recognition accuracy . The study found that the recognition performance degraded more rapidly for children when the bandwidth was reduced from 4kHz to 1.5kHz. In vestig ation of the possible causes showed that the average formant frequencies F1, F2 and F3 for children exceeded those of adults by more than 60% [6]. Sev eral techniques to tackle the acoustic variability were proposed in recent times. Different front-end robust features such as Mel-F r equency Cepstr al Coefficients (MFCC), P er- ceptual Linear Prediction (PLP) cepstral coefficients, and spectrum based filter bank features have been tried [7]. Sev eral minor alterations of front-end features have also been inv esti- gated [6]–[10]. Howe ver , MFCC features have dominated due to their robustness and compatibility with adult ASR systems. [1] proposed sev eral front-end frequency warping tech- niques and speaker normalization techniques with e valuations ov er different age groups. Particularly , V ocal T ract Length Normalization (VTLN) technique to suppress acoustic vari- ability introduced by the dev eloping vocal tracts in children has become a standard in children ASR systems [7], [11], [12], effecti vely reducing inter -speaker and inter -age-group acoustic 2 variability . Adapting acoustic models with Maximum Likeli- hood Linear Regr ession (MLLR) and Maximum A-P osteriori (MAP) was found to be effecti ve [7], [13], [14]. Further modest gains were achiev ed using Speaker Adaptive T raining (SA T) based on Constr ained MLLR (CMLLR) for children ASR [7], [14]. Some research efforts ha ve also concentrated on dealing with the increased pronunciation variability and mispronunci- ations present in kids due to limited and developing linguistic knowledge. Performance gap between spontaneous speech recognition and read speech is particularly large for children [15]. [3] sho wed that spontaneous speech annotations are extremely useful. They showed that language usage efficienc y increases with age for children reaching adult le vels at 13 years of age i.e., disfluencies decrease with age. [16] performed an in-depth analysis of linguistic variability in the context of spoken dialogue systems for children. Inter-speak er linguistic variability was found to be twice the intra-speaker v ariability . Mispronunciations in children were found to be twice as high for children of 8-10 years compared to that of 11-14 years, while the trend was re versed for filler pauses. Age dependencies were also found for the frequency of false-starts, duration, utterance length and breathing. [17] showed that language models trained on children speech were adv antageous to using adult models suggest- ing children use dif ferent grammatical constructs. In [14], language model adaptation from adult to children showed improv ements. Children tend to also mispronounce, thus customized dic- tionaries for children can provide performance benefits [5]. Pronunciation variations among children vary with age. Data- driv en pronunciation variation modeling is shown to be useful across children of all ages [7]. Howe ver , part of the variations are attributed towards the phonological processes and hence the customization of dictionaries have their limitations [18]. There are also significant efforts in speech applications for kids tow ards learning. For example [19], [20] focused on read speech assessment. Further , [21] focused on pronunciation assessment in Mandarin. [22] proposed subword unit based speech recognition for children enabling assessment of chil- dren speech at finer details and detection of speech events such as partial words and mispronunciations. More modern methods, specifically related to deep learning, hav e been e xtremely successful in improving ASR perfor - mance. The successes of Deep Neural Networks (DNN) hav e been attributed to DNN’ s ability to use vast amount of training data and to better approximate the non-linear functions needed to model speech, thus surpassing GMM based ASR systems. Howe ver , relatively less work has inv estigated DNNs for children’ s speech probably due to lack of large amounts of children’ s training data. [23], [24] conducted ASR experiments using a hybrid DNN-HMM based ASR system. They trained on approximately 10 hours of Italian children’ s speech giving small impro vements o ver traditional GMM based systems. [25] used a DNN to predict the frequency warping factors for VTLN which was later used to train a hybrid DNN-HMM system. [26] employed conv olutional long short-term memory recurrent neural networks to train children ASR for use with Y outube Kids. They further employed data augmentation through artificially adding noise for more robustness. Combin- ing adults’ speech with children’ s speech for training impro ved results for both adults and children [26]–[29]. Particularly , combining female adult speech in the training was shown to be more advantageous [27]. Multi-task learning frameworks for adapting adults’ speech to children’ s speech were presented in [21], [30]. In [31], [32], a technique similar to [30] was adopted to overcome limited training data for DNN. Most recently , multi-lingual data adaptation in a transfer learning and multi-task learning framew ork was found to be useful for the task of ASR for children speaking in non-nativ e language [33]. Howe ver , most of the prior works pertaining to analysis of children’ s speech in context of speech recognition has been on gaussian mixture based hidden mark ov models (GMM-HMM). Although there has been a wide consensus in the community about the adv antages of DNN acoustic modeling for children’ s speech [21], [23]–[31], there has been no work to the best of our kno wledge, which attempts to ev aluate and analyze where the strengths of the DNNs lie in context to children’ s ASR. More importantly there is a need for an analysis of the shortcomings of the DNN based ASRs, i.e., problems and challenges persisting in children speech recognition using state-of-the-art speech recognition systems. Our study attempts to contribute to this gap and provide insights towards future dev elopments. In this work, we conduct Evaluations on large vocab ulary continuous speech recognition (L VCSR) for children, to: 1) Compare older GMM-HMM models and newer DNN models. 2) In vestigate dif ferent transfer learning adaptation tech- niques. Particularly we look at two factors degrading children ASR: acoustic v ariability and pronunciation vari- ability in a DNN setup. 3) Assess effecti veness of different speaker normalization and adaptation techniques like VTLN, fMLLR, i-vector based adaptation versus the employed transfer learning technique. Further , we conduct Analysis ov er the follo wing parameters in context of transfer learning: 1) DNN model parameters. 2) Amount of adaptation data. 3) Ef fect of children’ s ages. 4) Age dependent transformations obtained from transfer learning and their validity , portability over the children’ s age span. Recommendations are pro vided from the insights gained from conducting the aforementioned ev aluations and analysis for: 1) Fa vorable transfer learning adaptation strategies for low data and high data scenarios. 2) Suggested transfer learning adaptation techniques for children of different ages. 3) Amount of adaptation data required for efficient perfor- mance ov er children’ s ages. 3 . . . . . . . . . . . . . . . . . . . . . x 1 x 2 x 3 x 40 i 1 i 2 i 3 i 100 x 1 x 2 x 3 x 40 i 1 i 2 i 3 i 100 y 1 y 2 y 3 y 4 y 5 y 6 y 7 y n Input layer Input layer Output layer Fig. 1: Acoustic V ariability Modeling Neuron color scheme: Red-Output, Blue-Hidden, Gray-iv ector input, Green-MFCC input 4) potential future research directions and relev ant chal- lenges and problems persisting in children speech recog- nition. The rest of the paper is formatted as follows: Section II motiv ates and describes the proposed transfer learning tech- nique. Section III describes the databases used for recognition experiments. The experimental setup and baseline systems for both adult and children ASR models are described in Section IV. Section V presents experiment results and dis- cussion. Section VI analyzes the amount of adaptation data and its effect on the performance. W e carry out analysis of transfer learning technique on children’ s age in Section VII. Section VIII discusses the study of age dependent transfer learning transformations and Section IX provides comparisons between the age dependent and age independent transfer learning transformations. Finally , Section X discusses potential future work and concludes. I I . P RO P O S E D T R A N S F E R L E A R N I N G T E C H N I Q U E T ransfer learning is a method of seeding models of a ne w task by using the kno wledge gained from a related task. The method has been used successfully , for cross-lingual knowledge transfer in DNN-based speech recognition [34], [35] and character recognition tasks [36]. T ransfer learning often exploits the v arious lev el of information that are captured by the different neural network layers. Often layers closer to the signal capture signal specific characteristics, e . g . edge characteristics, basic shapes, or spectral content. Higher layers capture information more related to the task at hand, e . g . phoneme classes, object types [37]. Children, as described abov e, differ (i) in acoustics and (ii) pronunciation from adults. This motiv ates us to inv estigate the transfer learning between adult and children ASR systems in two ways: (i) acoustic variability , as those relate to layers near input, and (ii) pronunciation v ariability as it relates to layers near output. A. Accounting for Acoustic V ariability W e assume that acoustic variability af fects the lower -level network structures only and hence these layers need to be adapted to better represent the children’ s feature subspace. This could be thought of as retaining the knowledge of higher lev el abstract functions (mappings) from an adult’ s ASR, while accounting for the spectral variabilities. This parallels alternate approaches such as feature space transforms like VTLN, fMLLR. One important dif ference is the degrees of freedom and hence parameters that this technique allows, likely resulting in better transformations but also much larger demands on adaptation data. Hence, to account for the acoustic variability we retain all the hidden layers from adult models except the bottom-most layer as shown in Figure 1. The DNN is retrained with children speech until conv ergence to estimate the optimal parameters of the lowest layer . This find is interesting as most of the transfer learning techniques adapt the output layers [21], [30]–[32] while for this task we adapt the input layer(s). Moreov er, we also augment the MFCC features with i- vector information. The i-vector subspace has been shown to capture speaker specific information ef ficiently [38]. It has also been successfully used for capturing speaker age characteristics [39]. Further speaker specific information is useful for speaker adaptation of DNN acoustic models [40]. The augmentation of i-vectors enables for better adaptation of the bottom layers during transfer learning by estimating speaker and age specific spectral transformations which are highly rele v ant for modeling children speech. B. Accounting for Pr onunciation V ariability W e assume that phonemic v ariability affects the higher- lev el network structures only and hence these layers need to be adapted to better represent the children’ s pronunciation variance. Hence we propose to adapt higher layers tow ards 4 . . . . . . . . . . . . . . . x 1 x 2 x 3 x 40 i 1 i 2 i 3 i 100 y 1 y 2 y 3 y 4 y 5 y 6 y 7 y n y 1 y 2 y 3 y 4 y 5 y 6 y 7 y n Input layer Output layer Output layer Fig. 2: Pronunciation V ariability Modeling Neuron color scheme: Red-Output, Blue-Hidden, Gray-iv ector input, Green-MFCC input modeling pronunciations as illustrated in Figure 2. This paral- lels work in adapting acoustic models across languages [34], [35] or for non-nati ve speakers [33]. In this case we are only tackling the pronunciation variability and as such the lower - order layers will remain unchanged. C. Accounting for Acoustic & Pr onunciation V ariability Finally , to account for both the acoustic and pronunciation variability , we would like to update both the top-most and bottom-most layers and keep the rest of the layers fix ed. This is attempted in two ways: (i) keeping weights of the middle hidden layers fixed and allow the top-most and bottom- most layer(s) to update simultaneously , (ii) dis-jointly and alternately training the v arious layers (top & bottom) until con vergence. The motiv ation behind the disjoint training is to constrain the updatable parameters at any time, to limit the adaptation, and to regulate the amount of knowledge retained from adult acoustic models. I I I . D A TA BA S E S In this work we employ 5 dif ferent children speech databases and 1 adult speech corpora. All the data are pro- cessed at 16kHz. The follo wing children speech databases were used: 1) CU Kid’ s Prompted and Read Speech Corpus [41] 2) CU Kid’ s Read and Summarized Story Corpus [42] 3) OGI Kid’ s Speech Corpus [43] 4) ChIMP Corpus [16] 5) CID Children’ s Speech Corpus [2] Using multiple children’ s speech corpora makes the problem more challenging and more relev ant to real world scenarios. The CID Children’ s Speech Corpus is used for testing and the rest for training. The summary of breakup of databases and their split for training and testing is provided in table I. The distribution of data ov er the age is illustrated in Figure 3. The adults corpus employed in this work is the TED-LIUM ASR corpus [44]. It consists a total of 206 hours of speech data of 774 speakers giving TED talks. I V . E X P E R I M E N TAL S E T U P & B A S E L I N E S Y S T E M A. Experimental Setup The experimental setup is very similar to the one used in our pre vious work [7]. GMM-HMM System: W e employ as a baseline a Gaussian Mixture Model based Hidden Markov Model ASR. For this Corpus # Hours # Speakers Age Split CU Prompted & Read 25.69 663 6-11 T rain CU Read & Summarized 33.11 320 6-11 T rain OGI 22.56 509 6-11 T rain ChIMP 10.25 97 6-14 T rain CID 2.26 324 6-14 T est T otal (Children-T rain) 91.61 1589 6 - 14 T rain TED-LIUM (Adult) 205.82 774 N A Train T ABLE I: Summary of Corpora and their training-testing splits 5 6 7 8 9 10 11 12 13 14 0 5 10 15 20 25 30 Age Hours Amount of Data vs. Age Fig. 3: Distribution of training data over Children Age system the features used are standard Mel-Frequency Cepstral Coefficients (MFCC) of dimension 13 with window size of 25ms and shift of 10 ms with their first order and second order deriv ativ es. The HMMs were modeled using 3 states for non- silence phones and 5 for silence phones. W e also employ the front-end adaptation techniques of Linear Discriminant Anal- ysis (LDA), Maximum Likelihood Linear Regression (MLLR) and Feature space MLLR (fMLLR) for speaker independent and speaker adaptiv e training. Dictionary: W e employ the CMU Pronunciation dictionary [45]. This dictionary corresponds to American-English pro- nunciations and that makes it compatible with our av ailable children and adult data. T o account for the out-of-vocab ulary (OO V) words during training, a grapheme to phoneme con- verter was used to generate phoneme transcripts for OO V words. Language Model: T wo language models were interpolated, one trained on a subset of children’ s training data reference transcripts and the second generic English language model from CMU-Sphinx-4 1 [46]. The interpolation helps incorpo- rating children’ s grammar which is beneficial for children’ s ASR along with the adult’ s grammar to facilitate the transfer learning process between adults and children. Since this work deals with ev aluating acoustic models, we keep the language model fixed for all our experiments. i-V ector Setup: W e employ high-resolution, 40-dimensional MFCCs as front-end features for i-v ector training. T o introduce context, we used an LD A transform with a context of 3 left and 3 right. Both the univ ersal background model (UBM) and the total-variability matrix for the i-vector were trained on adults speech data to allow transfer learning from these as well. W e 1 Language model version: cmusphinx-5.0-en-us.lm used 2048 Gaussian components to train the UBM, whereas the i-vector dimension was fixed to 100. Hybrid DNN-HMM System: W e employed a hybrid DNN- HMM system, where the DNN is used to replace the posterior probabilities of a traditional GMM system. DNN architecture employed is a time delay neural network which uses sub- sampling for exploiting long contextual information [47]. The DNN consumes high resolution MFCC features with a context of 13 left and 9 right frames. The MFCC features were concatenated with the i-v ector and were used to train the DNN. The DNN has 7 hidden layers, each of dimension 3500. p- norm non-linearity was used in the hidden layers. The output Softmax layer consists of 3976 units trained to predict the posterior . W e used greedy layer-wise training to train the DNN [48]. B. Baseline System 1) Childr en’ s ASR: The Children’ s ASR was trained only on the children speech data (splits illustrated in table I). In order to compare to the DNN and to relate to the previous work [7], we provide the result of the GMM-HMM systems. T o asses the advantage of the proposed transfer learning, we also trained a hybrid DNN-HMM based baseline system on children-only speech data. T o provide a range of baselines we also employ popular adaptation techniques such as VTLN, SA T , i-v ector , which have been proven successful for chil- dren’ s speech, in conjunction with the Hybrid DNN-HMM. 2) Adult’ s ASR: An additional ASR was trained only on adults speech data from TED-LIUM. The performance of this system was ev aluated by decoding on the test set of children speech to compare its performance to that of the baseline children ASR. This system is used for transfer learning to adapt to children speech. 6 Model WER GMM-HMM Monophone 54.53% GMM-HMM Triphone 36.96% GMM-HMM Triphone LD A+MLL T 32.79% GMM-HMM Triphone LD A+MLL T+SA T 24.55% GMM-HMM Triphone LD A+MLL T+SA T + VTLN 25.66% Hybrid DNN-HMM 35.97% Hybrid DNN-HMM + VTLN 32.72% Hybrid DNN-HMM + LDA+MLL T+SA T 21.31% Hybrid DNN-HMM + LDA+MLL T+SA T + VTLN 21.82% Hybrid DNN-HMM + online i-vector (speaker) 28.03% Hybrid DNN-HMM + online i-vector (utterance) 26.59% Hybrid DNN-HMM + offline i-vector (utterance) 25.53% T ABLE II: Baseline results of ASR trained only on children’ s speech (91 hours). V . R E C O G N I T I O N R E S U LTS A N D D I S C U S S I O N S A. Baseline Results T able II sho ws the results of the baseline system. The GMM-HMM results are comparable to that of the previous study [7] although more data has been incorporated for training in the current system. W e see that the SA T gi ves the best results among the GMM-HMM framework. The hybrid DNN- HMM system improv es over its respective GMM counterpart by 1% absolute. W e believe the reason for the minimal improv ement is that DNN requires more data to generalize well for children speech. W e also compare different adaptation techniques for the DNN-HMM model. VTLN provides an absolute 3.25% im- prov ement over the raw MFCC features. SA T performs much better and reduces the WER to 21.31% an absolute improve- ment of 14.66% over raw features. Howe ver , we find that a combination of VTLN and SA T doesn’t provide any major improv ement. Trials augmenting raw features with i-vectors suggest that the best performance is achie ved by using the offline version of i-vectors calculated on the whole utterance. Howe ver , these still fail to surpass the performance of the SA T by 4.22% absolute, thereby confirming SA T is crucial for children speech adaptation irrespectiv e of GMM or DNN acoustic modeling. B. T ransfer Learning Results T able III sho ws results of the proposed transfer learning technique. The baseline adult’ s model is significantly worse than children’ s model, as expected and consistent with previ- ous studies. W e first conduct adaptation experiments by adapting a single layer at a time. This allows us to assess the types of variability present in children’ s speech relativ e to the adult-trained DNN. It also allows us to e v aluate performance benefits through addressing specific variability types. Adapting bottom layers should help counter acoustic variability in kids. Adapting top layers should attempt to account for pronunciation variability . W e observe as hypothesized that with single-layer mod- ifications addressing acoustic variability (24.26%) is more advantageous than accounting for pronunciation variability (26.97%). Both are providing big gains ov er both the original adult’ s baseline of 39.32%. Often, in transfer learning the top layers, representing high lev el abstract information, are used for adaptation [34], [35]. Howe ver , our finding is in agreement with prior studies showing high variability in spectral characteristics of children speech [1], [2], [4], [5] that denotes the need for input-layer adaptation. This suggests that the transfer learning adaptation configuration is task dependent. Model A V PV Configuration WER DNN Children 7 7 Baseline 25.53% DNN Adult 7 7 Baseline 39.32% DNN Children + Adult 7 7 - 20.35% DNN TL 7 3 1 layer 26.97% DNN TL 3 7 1 layer 24.26% DNN TL 3 3 1 layer each 19.63% DNN TL 3 3 dis-joint 1 layer each 20.01% DNN TL 3 3 2 layers each 17.8% DNN TL 3 3 dis-joint 2 layers each 18.74% DNN TL - - all layers 17.8% T ABLE III: Transfer Learning Results (DNN: Hybrid DNN-HMM + offline i-vector (utterance lev el) A V : Acoustic V ariability Modeling, PV : Pronunciation V ariability Modeling) 7 0.316228 1 3.16228 10 31.6228 100 18 20 22 24 26 28 30 32 34 36 38 Hours of training data Word Error Rate % Data vs. WER 2 layers 4 layers 6 layers all layers Fig. 4: Amount of Adaptation Data (Log-scale) versus W ord Error Rate; Four Different DNN configurations V I . A NA LY S I S O F A M O U N T O F A D A P T AT I O N D A TA W e also in vestigate letting both the top and bottom layers update, i.e., by modeling both the acoustic and pronunciation variability simultaneously . W e observe a further boost in accuracy with the WER dropping to 19.63% giving a relativ e gain of 23.1% over the baseline children model and 50.1% ov er adults model. One interesting observation is that the performance benefits achiev ed by simultaneously updating the top and bottom layer is complementary to that achieved by adapting each layers individually . This suggests that the acoustic variability and the pr onunciation variability are fairly exclusive of each other in case of childr en . Dis-joint training doesn’t pro vide improv ements, likely due to the sufficient amounts of data to simultaneously account for the degrees of freedom of joint training. It could ho wever be beneficial in the case of less data as we show in the subsequent section (Section VI-A). In our experiments we also found that using 2 layers to update instead of 1 giv es further improvements. W e achieve a word error rate (WER) of 17.8% which is a modest 9.3% gain ov er using single layers for adaptation. Subsequent ex- periments with more layers did not provide any significant improv ements. Adapting all the layers gives the same perfor- mance of 17.8% WER. This suggests that all the v ariability present between the children and the adult is concentrated at the top (pronunciation level) and bottom (acoustic lev el) layers of the DNN in agreement with the initial hypothesis made in this work. This indicates that the underlying middle hidden layers ef ficiently model the basic human speech structure. Overall, the proposed transfer learning technique outper- forms the best results obtained using the baseline model trained on children’ s speech with SA T by a relativ e 16.5% (relativ e 54.7% improvements over the baseline adult model). The results highlight the po wer of transfer learning in the DNN framew ork in outperforming SA T , the prior best performing recipe for children ASR [7]. Finally , we compare the proposed adaptation technique against a model trained on combined data of adult’ s and chil- dren’ s speech which was proposed in [26]–[29]. Combining adults’ and children’ s data provides modest improv ements Adaptation Data Model (training) WER 35 minutes 2 layers (simultaneous) 35.73% 35 minutes 2 layers (dis-joint) 35.04% 45 minutes 2 layers (simultaneous) 35.13% 45 minutes 2 layers (dis-joint) 34.33% 2 hours 2 layers (simultaneous) 32.35% 2 hours 2 layers (dis-joint) 32.94% T ABLE IV: Adaptation at extreme low data scenarios 8 6 7 8 9 10 11 12 13 14 0 5 10 15 20 25 30 35 Age Word Error Rate (WER) Age vs. Layer configurations 2layers 4layers 6layers all layers Fig. 5: Children Age vs. Adaptation layer configurations ov er the baseline systems trained only on children (5.18% absolute) and adult (18.97% absolute) data. Howe ver , our proposed adaptation technique proves to be superior with 2.55% absolute improv ement over the model trained on adults and children. Informed by the abov e results, for the rest of this work, we experiment with four different adaptation configurations: 1) 2 layers: (bottom-most + top-most) 2) 4 layers: (2-bottom-most + 2-top-most) 3) 6 layers: (3-bottom-most + 3-top-most) 4) all layers. W e always adapt ev en number of layers, thus maintaining symmetry in the structure in terms of top and bottom layers for maximum performance. Moreover , from our experiments we found that adapting a single layer never surpasses the adap- tation using symmetric 2 layers and thus we skip presenting those results. Figure 4 shows the transfer learning adaptation performance curve over amount of adaptation data (in terms of WER and hours). Each curv e represents different adaptation architectures of the DNN in terms of number of layers used for adaptation. The follo wing inferences can be drawn from the plot: • The WER decays exponentially with increase in amount of data. • The curves are almost always monotonically decreasing, suggesting that more adaptation data always helps. W e note that the graph has not con verged, meaning more data could help the adaptation further , suggesting that the constraint is still the amount of children data av ailable. • Any amount of children data is helpful for adaptation, as in our experiments even as low as 35 minutes of children adaptation data was found to gi ve improvements of up-to 9.1% (relati ve) over the adult model. • Adapting less number of layers yields better results for low data scenario, i.e., we find that adapting only 2 layers consistently outperforms adapting with more layers until about 25 hours of adaptation data. • W ith 25 hours of adaptation data, all of the 4 curves more or less intersect suggesting that all the four architectures giv es approximately the same improv ements. • For more than 25 hours of data, we find that adapting 4, 6 and all layers conv erge to approximately same performance in agreement of the findings in section V -B. A. T ransfer Learning for low resour ce scenarios T able IV represents three extreme low data adaptation scenarios. W e apply dis-joint training to account for data sparsity as explained in section II-C. Since earlier experiments indicated that 2 layers pro vided maximum benefits for lo w data, we present the effect of dis-joint training for 2 layers only . The series of experiments in volv ed first training with top and bottom layer and fixing those weights. W e then continue training with layer 2 and 6 to update. W e find that the dis-joint training further improv es the adaptation for small amounts of data i.e., 35 and 45 minutes. The improvements diminish when more data is used, as in the case of 2 hours and as seen earlier in table III. Approximately 1.9% and 2.3% relati ve reduction in WER is observed for 35 and 45 minutes respectiv ely . V I I . A G E D E P E N D E N T A N A L Y S I S A. Age vs. Adaptation layer configurations In this section, we analyze the effect of different layer adaptation configurations on the children’ s age. The model is trained on all available children data independent of age 9 0.607 0.76 2 3.48 5 10 20 40 55 75 90 6 7 8 9 10 11 12 13 1 4 10 20 30 40 50 60 70 Age of children # of hours training data WER 15 20 25 30 35 40 45 50 55 60 Fig. 6: Amount of training data vs. Children Age (age-independent acoustic model). The results are plotted as a bar graph in Figure 5. W e observe the following: • Overall performance increases with increase in age, irre- spectiv e of the adaptation configuration. The two peaks corresponding to ages 12 and 13 years is probably a consequence of the acoustic model mismatch posed by relativ ely less training data for elder children (11 - 14 years) (See Figure 3). • Performance is worse for younger children, consistent with past work [7]. • The adaptation configuration affects more younger chil- dren. T o demonstrate this, Figure 7 shows the WER variance between the 4 configurations plotted over age. It is evident from the plot that the v ariance for younger chil- dren is significantly higher and decreases with increase in age. Similar peaks found in Figure 5 for ages 12 and 13 years is also apparent in variance plot. • Y ounger children benefit with adaptation of more layers than older children. This aligns with the expectation that younger children manifest higher acoustic comple xity and hence more parameters (layers) are necessary to capture the increased complexity . For example, from Figure 5, if 2 layers are adapted rather than all layers we ha ve significantly fewer gains for 6 year olds than 14 year olds. This is also justified to certain extent by looking at the variances in Figure 7. This also suggests that despite the acoustic and pronunciation variability , young-children speech encodes more variability that af fects the whole network. B. Amount of Adaptation Data vs. Age W e also in vestigate the amount of adaptation data and its effect on children’ s age. Figure 6 shows a 3-d plot of WER ov er the amount of adaptation data and the children’ s age. Adaptation data are chosen at random and hence follow the proportions in Figure 3. W e make the follo wing inferences from the figure: • It is evident that more the adaptation data better is the performance irrespecti ve of age of the children. • W e see that younger children need more data to reach the same lev el of performance as older children. The trend is in accordance with the age, i.e., as the age of children increases, less amount of adaptation data is sufficient. • In-spite of large amount of matched-adaptation data, we observe that the performance of younger children of age 6-8 years doesn’t meet that of the elder children. • Although the adaptation data for older children is mainly mismatched (see Figure 3 for distribution of training data), the y need as lo w as 30 minutes of adaptation data to surpass the performance of the younger children adapted on all (90 hours) of data. 6 7 8 9 10 11 12 13 14 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 Age Variance over adaptation layer configurations Fig. 7: WER V ariance over Adaptation Layer Configurations across Children Age Groups 10 0.607 0.76 2 3.48 5 10 20 40 55 75 90 6 7 8 9 10 11 12 13 1 4 −6 −4 −2 0 2 4 6 Age of children # of hours training data WER −4 −3 −2 −1 0 1 2 3 4 5 Fig. 8: Layer configurations vs. Amount of Adaptation Data vs. Age C. Layer configurations vs. Amount of Adaptation Data vs. Age T o gain insights into the optimal adaptation strate gy in terms of 4 earlier mentioned adaptation layer configurations as a function of the amount adaptation data and age of children, we plot the difference of WER between different adaptation layer configurations. Figure 8 sho ws a 3-d plot for difference between the WER when adapting all layers and WER when adapting only 2 layers. Any positiv e values indicate that adapting with 2 layers to be superior than adapting all the layers and vice-versa. W e can deduce the following by looking at Figure 8: 1) Adapting 2-layers is more beneficial when adaptation data av ailable is lo w . When more adaptation data is av ailable, it is advantageous to adapt more layers. The trend is consistent over all the children ages - 6 years to 14 years which is in accordance with the finding from Section VII-A and Section VII-B. 2) For younger children, 6 years to 11 years, we find that it is better to use fe wer adaptation layers when the adaptation data av ailable is lo w . The performance of the system is significantly lower when adapting with all the layers. This is because of the increased variability affecting the ov erall performance of the system. This is especially true when a large amount of parameters are adapted with little data, due to noise introduced from high variabil- ity . The performance of the system ev entually recovers and surpasses the 2-layer adaptation configuration when sufficient amount of adaptation data is av ailable. 3) For younger children, with sufficiently high adaptation data, we find that the effecti ve gains made between the layer configuration is much higher compared to elder children. Thereby asserting their sensitivity to adaptation data and layer configurations. 4) For older children, 12 years to 14 years, the system adapts rapidly with considerably less data compared to younger children. 5) For older children, the performance gains are comparable between 2-layer adaptation and all layer adaptation. The analysis is only presented for differences between adapting all the layers and adapting only 2-layers. The par- ticular plot was chosen to illustrate the differences as in an extreme case. Similar trends were observed for differences of other configurations, i.e., adapting more layers versus fewer layers. V I I I . A NA LY S I S O F A G E D E P E N D E N T T R A N S F O R M A T I O N S In order to assess the validity of the transformations learnt by adapting the layers and its extensibility and relev ance to children’ s speech, we analyze age specific transformations resulting from age dependent transfer learning adaptation. The transformations would be meaningful if there exists some level of meaningful portability between different ages. Note: these transformations are not equiv alent and shouldn’t be mistaken to age specific models. Figure 9 shows the 3-d plot of WER from application of age dependent transformations on each age group, when adapting the model with all the layers. The following can be inferred from the plot: 1) For younger children, ages 6 years to 10 years, the matched models i.e., application of same aged transfor- mations provide significant improv ements. 2) For younger children, as the mismatch increases (in terms of age), the performance decreases. 11 6 7 8 9 10 11 12 13 14 6 7 8 9 10 11 12 13 14 10 20 30 40 50 60 70 80 age model test data WER 20 30 40 50 60 70 Fig. 9: Age dependent model performance - Adapting all layers 3) For younger children, the rate of performance degradation is much more drastic as the mismatch (in terms of age) increases compared to older children. 4) For ages 11 years to 14 years, the surface is more or less plateaued, this is probably because of data scarcity for estimation of meaningful transformations (See Figure 3). 5) The ov erall surface is tilted to wards the left, indicating that performance of elder children are significantly better irrespectiv e of the applied transformation. The abov e observations confirm the validity of the trans- formations and its portability across the ages. Although the transformations are not equiv alent to age-dependent mod- els, the abov e observations prov e they exhibit similar trends (performance-wise) as reported in previous literature [13]. A. Age dependent tr ansformations versus Adaptation layer configurations Figure 11 illustrates the confusion matrix obtained by the application of age dependent transformations on each group for each of the 4 adaptation configurations. A quick inspection shows that all of the configurations exhibit similar trends observed in Section VIII. I X . A G E D E P E N D E N T T R A N S F O R M A T I O N S V E R S U S A G E I N D E P E N D E N T T R A N S F O R M A T I O N S Figure 10 compares the performance of the age independent transformations (obtained by adapting on all the data) against the application of matched age dependent transformations. T o keep the analysis consistent over dif ferent adaptation layer configurations, we consider only the configuration of adapting all the layers. W e find that the age independent transforma- tion trained on significantly more data outperforms the age dependent transformations consistently over all the ages. This finding suggests that DNN can e xploit more data to offset and surpass the performance and effecti vely generalize over different ages due to its large parameter space. It does not lose its generalizability when exposed to different ages. This is in contrast to GMM models, that when adapted (e.g. via MLLR), to a wider diverse population with limited data underperform specific adaptations [49]. By e xamining the difference between the WER trajectories ov er age, we find a peak ov er the ages 11 years to 14 years, highlighting the aforementioned effect of limited data for these age groups as in Figure 3. Howe ver , by providing a correction factor to compensate 6 7 8 9 10 11 12 13 14 0 5 10 15 20 25 30 35 40 WER Age Age Independent Age Dependent Difference Fig. 10: Age dependent transformations versus Age indepen- dent transformations 12 all−layers age model test data 6 8 10 12 14 6 7 8 9 10 11 12 13 14 6−layers age model test data 6 8 10 12 14 6 7 8 9 10 11 12 13 14 4−layers age model test data 6 8 10 12 14 6 7 8 9 10 11 12 13 14 2−layers age model test data 6 8 10 12 14 6 7 8 9 10 11 12 13 14 20 30 40 50 60 70 20 30 40 50 60 70 20 30 40 50 60 70 20 30 40 50 60 70 Fig. 11: Age dependent model performances - All layer configurations for the difference between the amount of data between the age dependent and independent transforms, enables for a more fair comparison between the transforms. T o enable such an analysis we adopt 2 different types of data correction factors for age independent transformation: 1) W e restrict the amount of data used for the computation of age independent transformation by taking the av er- age data (ov er ages - Figure 3) which in our case is approximately 10 hours. W e refer to this as average age- independent transform (Blue line in Figure 12). 2) W e train multiple age independent transforms by restrict- ing the amount of adaptation data closest to that of each age. This gives us one age-independent model for each age best matched to age-dependent transform in terms of adaptation data. W e refer to this as matched age- independent transform (Green line in Figure 12). Since the sampling of data in either case is random, this retains the original corpus proportions (with respect to age). Figure 12 compares the data normalized age independent transform against the age dependent transformations. The following observations are apparent from the plot: 1) After normalizing the amount of data, we now see that the age dependent transformations outperform the age independent transformations for younger children (ages 6 years to 10 years) in both cases (av erage and matched versions). 2) W e observe that the improvements from age dependent transforms gets more prominent as the age decreases, with maximum gains for 6 year old. 3) W e observe a crossover for elder children (ages 11 years to 14 years) in both the cases of average and matched versions, i.e., the age independent transformations are better compared to that of age dependent. (For elder children, the av erage version of age independent transfor- mation shows higher demarcation due to the heightened mismatch in adaptation data. Hence, the matched version is more representati ve.). This interesting finding could be attributed to wards the higher similarity between the speech of adults and elder children. (Note: this is not a case of age-dependent acoustic modeling, but rather an adaptation from adult’ s speech). 4) Looking at the difference between the ‘best performing’ age-independent transformation and the age dependent transform, i.e., the potential gains from exploiting more data with age-independent transform increases with in- crease in age. This is expected, considering that the elder children exhibit relatively lower v ariability in acoustic and pronunciation constructs and hence e xhibit much similar speech structure to that of the adult. A. Ef fect of adaptation layer configurations Figure 13 plots the difference between the age-dependent transform and the matched version of age-independent trans- form for different adaptation layer configurations. The takeout from the plot is, the age-dependent transforms outperform the age-independent transforms for younger children, whereas the age-independent transforms are beneficial for elder children. The trend observed earlier, with all the layers, remains ap- parent over all the layer configurations. Note the absolute 13 6 7 8 9 10 11 12 13 14 10 20 30 40 50 60 70 WER Age Age Independent vs. Age Dependent Transforms (all layers) Age Dependent Avg. Age Independent (10hr) Age Independent (35min) Age Independent (45min) Age Independent (2hr) Age Independent (3.48hr) Age Independent (5hr) Age Independent (20hr) Age Independent (40hr) Age Independent (55hr) Age Independent (75hr) Age Independent (90hr) Matched Age Independent Fig. 12: Age dependent transformations versus data-normalized Age independent transformations (Adapting all layers) values (trajectories) are a function of the amount of data present for each age and age itself, as supported by our earlier observations in Section VII-C. Hence, the inter-relations of different configuration trajectories is complex. X . C O N C L U S I O N & F U T U R E W O R K In this study , we conduct an analysis of L VCSR adaptation and transfer learning for children’ s speech using multiple databases. W e compare the advantages of DNN acoustic models over the GMM-HMM systems. W e also compare 6 7 8 9 10 11 12 13 14 −6 −4 −2 0 2 4 6 8 WER gain with Age−dependent transform Age All layers 6 layers 4 layers 2 layers Fig. 13: Effect of adaptation layer configurations: Difference of WER between Age dependent transformations and matched age-independent transformations adult and children DNN acoustic model performance for decoding children speech. Sev eral transfer learning techniques are ev aluated, on adult models, specifically to address the increased acoustic variability and pronunciation v ariability found in children. Extensiv e analysis is performed to study the effect of the amount of adaptation data, DNN transfer learning configurations and their impact on different age groups. In the case of sev erely limited in-domain (kids) data we proposed and analyzed disjoint adaptation. W e also analyzed the amount of adaptation data required for children of dif ferent ages. W e in vestigated various transfer learning configurations and their effect on different age groups and data sizes. Our work validated the benefits of age dependent transfer learning and examined the portability and extensibility of models ov er the different age groups. W e also presented comparisons of age dependent and age independent transfer learning. These provide valuable insights to wards future research directions in terms of persisting challenges and problems in children’ s speech recognition. In future we would like to analyze the variability internal to the DNN, i.e. how the weights of the “adapted layers” change. Comparisons of such variability between adult and child models can inform on linguistic and structural aspects of kids speech. These can also help identify the aspects of non- linearities in normalization and adaptation techniques tow ards improv ed kids speech processing. Such models can provide insights in analyzing the effect on various speech parameters in regards to pitch, intensity , voice quality , duration, formant frequencies etc, which are valuable aspects in assessing the difficulties faced for children ASR. 14 F I NA N C I A L S U P P O RT The U.S. Army Medical Research Acquisition Activity , 820 Chandler Street, Fort Detrick MD 21702- 5014 is the awarding and administering acquisition office. This work was supported by the Office of the Assistant Secretary of Defense for Health Aff airs through the Psychological Health and T raumatic Brain Injury Research Program under A ward No. W81XWH-15-1- 0632. Opinions, interpretations, conclusions and recommenda- tions are those of the author and are not necessarily endorsed by the Department of Defense. R E F E R E N C E S [1] A. Potamianos and S. Narayanan, “Robust recognition of children’ s speech, ” IEEE T ransactions on speech and audio pr ocessing , vol. 11, no. 6, pp. 603–616, 2003. [2] S. Lee, A. Potamianos, and S. Narayanan, “ Acoustics of childrens speech: Developmental changes of temporal and spectral parameters, ” The Journal of the Acoustical Society of America , vol. 105, no. 3, pp. 1455–1468, 1999. [3] M. Gerosa, D. Giuliani, and S. Narayanan, “ Acoustic analysis and automatic recognition of spontaneous children’ s speech, ” in Ninth In- ternational Conference on Spoken Language Pr ocessing , 2006. [4] A. Potamianos, S. Narayanan, and S. Lee, “ Automatic speech recognition for children. ” in Eurospeec h , 1997. [5] Q. Li and M. J. Russell, “ An analysis of the causes of increased error rates in children’s speech recognition, ” in Seventh International Confer ence on Spoken Language Pr ocessing , 2002. [6] Q. L. M. J. Russell, “Why is automatic recognition of children’ s speech difficult?” 2001. [7] P . G. Shiv akumar , A. Potamianos, S. Lee, and S. Narayanan, “Improving speech recognition for children using acoustic adaptation and pronunci- ation modeling, ” in Pr oc. W orkshop on Child, Computer and Interaction (WOCCI) , 2014. [8] S. Umesh and R. Sinha, “ A study of filter bank smoothing in mfcc features for recognition of children’ s speech, ” IEEE T ransactions on audio, speech, and language pr ocessing , vol. 15, no. 8, pp. 2418–2430, 2007. [9] S. Ghai and R. Sinha, “Pitch adaptive mfcc features for improving childrens mismatched asr, ” International J ournal of Speech T echnology , vol. 18, no. 3, pp. 489–503, 2015. [10] S. Shahnawazuddin, A. Dey , and R. Sinha, “Pitch-adaptive front-end features for robust children’ s asr . ” in INTERSPEECH , 2016, pp. 3459– 3463. [11] D. Giuliani and M. Gerosa, “In vestigating recognition of children’ s speech, ” in Acoustics, Speech, and Signal Pr ocessing, 2003. Pr oceed- ings.(ICASSP’03). 2003 IEEE International Conference on , v ol. 2. IEEE, 2003, pp. II–137. [12] G. Stemmer, C. Hacker , S. Steidl, and E. N ¨ oth, “ Acoustic normalization of children’ s speech. ” in INTERSPEECH , 2003. [13] D. Elenius and M. Blomberg, “ Adaptation and normalization experi- ments in speech recognition for 4 to 8 year old children. ” in Interspeech , 2005, pp. 2749–2752. [14] S. S. Gray , D. Willett, J. Lu, J. Pinto, P . Maergner, and N. Bodenstab, “Child automatic speech recognition for us english: child interaction with living-room-electronic-devices, ” in Proceedings of workshop on child computer interaction (WOCCI) , 2014. [15] M. Gerosa, D. Giuliani, S. Narayanan, and A. Potamianos, “ A review of asr technologies for children’ s speech, ” in Pr oceedings of the 2nd W orkshop on Child, Computer and Interaction . A CM, 2009, p. 7. [16] A. Potamianos and S. Narayanan, “Spoken dialog systems for children, ” in Acoustics, Speech and Signal Pr ocessing, 1998. Proceedings of the 1998 IEEE International Conference on , vol. 1. IEEE, 1998, pp. 197– 200. [17] S. Das, D. Nix, and M. Picheny , “Improvements in children’s speech recognition performance, ” in Acoustics, Speech and Signal Processing, 1998. Pr oceedings of the 1998 IEEE International Conference on , vol. 1. IEEE, 1998, pp. 433–436. [18] E. Fringi, J. F . Lehman, and M. Russell, “Evidence of phonological processes in automatic recognition of children’ s speech, ” in Sixteenth Annual Confer ence of the International Speech Communication Associ- ation , 2015. [19] J. T epperman, S. Lee, S. S. Narayanan, and A. Alwan, “ A generative student model for scoring word reading skills, ” IEEE T ransactions on Audio, Speech, and Language Processing , vol. 19, no. 2, pp. 348 – 360, 2011. [20] H. Tulsiani, P . Swarup, and P . Rao, “ Acoustic and language modeling for children’ s read speech assessment, ” in Communications (NCC), 2017 T wenty-third National Confer ence on . IEEE, 2017, pp. 1–6. [21] R. T ong, N. F . Chen, and B. Ma, “Multi-task learning for mispro- nunciation detection on singapore childrens mandarin speech, ” Proc. Interspeech 2017 , pp. 2193–2197, 2017. [22] A. Hagen, B. Pellom, and R. Cole, “Highly accurate childrens speech recognition for interactive reading tutors using subword units, ” speech communication , vol. 49, no. 12, pp. 861–873, 2007. [23] D. Giuliani and B. BabaAli, “Large vocabulary children’ s speech recog- nition with dnn-hmm and sgmm acoustic modeling, ” in Sixteenth Annual Confer ence of the International Speech Communication Association , 2015. [24] P . Cosi, “ A kaldi-dnn-based asr system for italian, ” in 2015 International Joint Confer ence on Neural Networks (IJCNN) . IEEE, 2015, pp. 1–5. [25] R. Serizel and D. Giuliani, “V ocal tract length normalisation approaches to dnn-based children’s and adults’ speech recognition, ” in Spoken Language T echnology W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 135–140. [26] H. Liao, G. Pundak, O. Siohan, M. Carroll, N. Coccaro, Q.-M. Jiang, T . N. Sainath, A. Senior , F . Beaufays, and M. Bacchiani, “Large vocab ulary automatic speech recognition for children, ” 2015. [27] M. Qian, I. McLoughlin, W . Quo, and L. Dai, “Mismatched training data enhancement for automatic recognition of children’ s speech using dnn- hmm, ” in Chinese Spoken Language Processing (ISCSLP), 2016 10th International Symposium on . IEEE, 2016, pp. 1–5. [28] J. Fainberg, P . Bell, M. Lincoln, and S. Renals, “Improving children’ s speech recognition through out-of-domain data augmentation. ” in IN- TERSPEECH , 2016, pp. 1598–1602. [29] Y . Qian, X. W ang, K. Evanini, and D. Suendermann-Oeft, “Improving dnn-based automatic recognition of non-native children speech with adult speech, ” in W orkshop on Child Computer Interaction , 2017, pp. 40–44. [30] R. T ong, L. W ang, and B. Ma, “Transfer learning for children’s speech recognition, ” in Asian Language Processing (IALP), 2017 International Confer ence on . IEEE, 2017, pp. 36–39. [31] R. Serizel and D. Giuliani, “Deep neural network adaptation for chil- drens and adults speech recognition, ” in Proc. of the F irst Italian Computational Linguistics Confer ence , 2014. [32] ——, “Deep-neural network approaches for speech recognition with heterogeneous groups of speak ers including children, ” Natural Languag e Engineering , vol. 23, no. 3, pp. 325–350, 2017. [33] M. Matassoni, R. Gretter , and G. D. Falavigna, Daniele and, “Non-nati ve children speech recognition through transfer learning, ” Acoustics, Speec h and Signal Pr ocessing (ICASSP), 2018 IEEE International Conference on , pp. 6229–6233, apr 2018. [34] G. Heigold, V . V anhoucke, A. Senior , P . Nguyen, M. Ranzato, M. Devin, and J. Dean, “Multilingual acoustic models using distributed deep neural networks, ” in 2013 IEEE International Conference on Acoustics, Speec h and Signal Pr ocessing . IEEE, 2013, pp. 8619–8623. [35] J.-T . Huang, J. Li, D. Y u, L. Deng, and Y . Gong, “Cross-language knowledge transfer using multilingual deep neural network with shared hidden layers, ” in 2013 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing . IEEE, 2013, pp. 7304–7308. [36] D. C. Cires ¸an, U. Meier, and J. Schmidhuber, “T ransfer learning for latin and chinese characters with deep neural networks, ” in The 2012 International Joint Confer ence on Neural Networks (IJCNN) . IEEE, 2012, pp. 1–6. [37] Y . Bengio, A. Courville, and P . V incent, “Representation learning: A revie w and new perspectiv es, ” IEEE transactions on pattern analysis and machine intelligence , vol. 35, no. 8, pp. 1798–1828, 2013. [38] N. Dehak, P . Kenny , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker verification, ” Audio, Speech, and Language Pr ocessing, IEEE T ransactions on , vol. 19, no. 4, pp. 788–798, 2011. [39] P . G. Shivakumar , M. Li, V . Dhandhania, and S. S. Narayanan, “Sim- plified and supervised i-vector modeling for speaker age regression, ” in Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on . IEEE, 2014, pp. 4833–4837. [40] G. Saon, H. Soltau, D. Nahamoo, and M. Picheny , “Speaker adaptation of neural network acoustic models using i-vectors. ” in ASRU , 2013, pp. 55–59. [41] R. Cole, P . Hosom, and B. Pellom, “Univ ersity of colorado prompted and read childrens speech corpus, ” T echnical Report TR-CSLR-2006-02, Center for Spoken Language Research, Univ ersity of Colorado, Boulder, T ech. Rep., 2006. 15 [42] R. Cole and B. Pellom, “Univ ersity of colorado read and summarized story corpus, ” T echnical Report TR-CSLR-2006-03, Univ ersity of Col- orado, T ech. Rep., 2006. [43] K. Shobaki, J.-P . Hosom, and R. Cole, “The ogi kids’ speech corpus and recognizers, ” in Proc. of ICSLP , 2000, pp. 564–567. [44] A. Rousseau, P . Del ´ eglise, and Y . Est ` eve, “Enhancing the ted-lium corpus with selected data for language modeling and more ted talks. ” in LREC , 2014, pp. 3935–3939. [45] R. W eide, “The cmu pronunciation dictionary , release 0.6, ” 1998. [46] W . W alker , P . Lamere, P . Kwok, B. Raj, R. Singh, E. Gouvea, P . W olf, and J. W oelfel, “Sphinx-4: A flexible open source framework for speech recognition, ” 2004. [47] V . Peddinti, D. Pov ey , and S. Khudanpur, “ A time delay neural network architecture for efficient modeling of long temporal contexts, ” in Six- teenth Annual Conference of the International Speech Communication Association , 2015. [48] Y . Bengio, P . Lamblin, D. Popovici, H. Larochelle et al. , “Greedy layer-wise training of deep networks, ” Advances in neural information pr ocessing systems , vol. 19, p. 153, 2007. [49] M. J. Gales and P . C. W oodland, “Mean and variance adaptation within the mllr framework, ” Computer Speech & Language , vol. 10, no. 4, pp. 249–264, 1996.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment