Early Evaluation of Intel Optane Non-Volatile Memory with HPC I/O Workloads
High performance computing (HPC) applications have a high requirement on storage speed and capacity. Non-volatile memory is a promising technology to replace traditional storage devices to improve HPC performance. Earlier in 2017, Intel and Micron released first NVM product – Intel Optane SSDs. Optane is much faster and more durable than the traditional storage device. It creates a bridge to narrow the performance gap between DRAM and storage. But is the existing HPC I/O stack still suitable for new NVM devices like Intel Optane? How does HPC I/O workload perform with Intel Optane? In this paper, we analyze the performance of I/O intensive HPC applications with Optane as a block device and try to answer the above questions. We study the performance from three perspectives: (1) basic read and write bandwidth of Optane, (2) a performance comparison study between Optane and HDD, including checkpoint workload, MPI individual I/O vs. POSIX I/O, and MPI individual I/O vs. MPI collective I/O, and (3) the impact of Optane on the performance of a parallel file system, PVFS2.
💡 Research Summary
The paper presents a comprehensive performance evaluation of Intel Optane SSDs—based on 3D XPoint non‑volatile memory—when used as a block device in high‑performance computing (HPC) environments. The authors address three core questions: (1) What raw bandwidth and latency does Optane provide compared with traditional hard‑disk drives (HDDs)? (2) How does Optane affect the performance of typical HPC I/O workloads, including checkpointing, POSIX I/O, and MPI‑IO (both independent and collective modes)? (3) What is the impact of Optane on a parallel file system, specifically PVFS2?
Methodology
Four benchmarks are employed: Intel Open Storage Toolkit (for low‑level bandwidth/IOPS measurement), HACC‑IO (a checkpoint‑oriented kernel from an N‑body simulation), IOR (a widely used parallel I/O benchmark supporting POSIX, MPI‑IO independent, and MPI‑IO collective), and mpi‑io‑test (shipped with PVFS2). Experiments are conducted on two testbeds: an NFS‑based cluster (four nodes) and a PVFS2‑based cluster (six nodes). Each node is equipped with an Intel Xeon E5‑2690 v4 CPU, 128 GB RAM, a 1 TB SATA HDD, and a 370 GB Optane SSD (M.2 PCIe). All nodes run Linux 3.10 and MPICH 2.6 over 10 GbE. The study compares only Optane versus HDD, as no conventional SSD is available.
Raw Device Performance
Using the Open Storage Toolkit, the authors measure sequential and random read/write bandwidth on a single node. Optane delivers roughly 2.17 GB/s for both sequential and random reads, and about 2.17 GB/s for writes, whereas the HDD provides only ~200 MB/s for sequential reads and ~6 MB/s for random writes. The random‑vs‑sequential gap that plagues HDDs disappears on Optane, confirming its low latency and high IOPS characteristics.
Checkpoint (HACC‑IO) Results
In a realistic checkpoint scenario (three compute nodes writing to one storage node over NFS), Optane still outperforms HDD, but the performance gap shrinks to about 5.6× (versus >10× in raw tests). The authors attribute this reduction to network latency dominating the end‑to‑end I/O path; the 10 GbE link adds more delay than the storage device itself, masking much of Optane’s advantage. Moreover, scalability plateaus when more than four MPI tasks per node are used, indicating that the network becomes the bottleneck before the storage device is saturated.
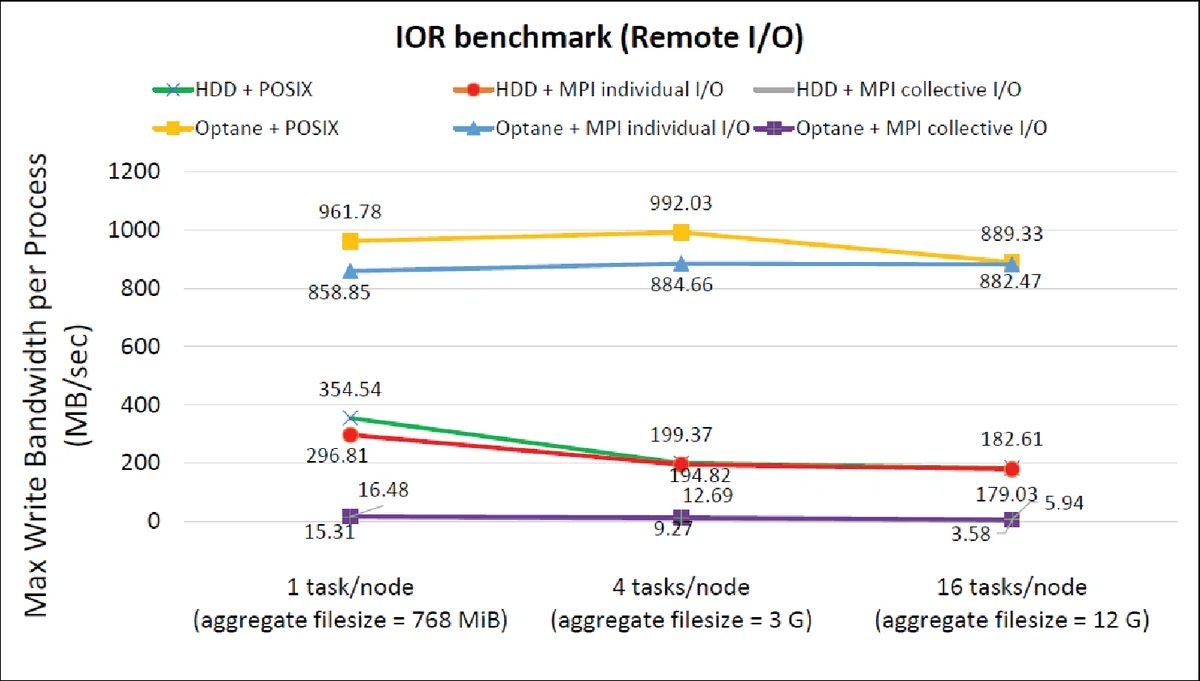
POSIX vs. MPI Independent I/O
The IOR benchmark is used to compare plain POSIX I/O against MPI independent I/O on Optane and HDD. With a small number of MPI tasks per node (1–4), MPI independent I/O incurs noticeable overhead on Optane, leading to lower throughput than POSIX I/O. As the task count rises to 16, the throughput gap disappears because MPI’s internal data aggregation starts to offset its own overhead. This demonstrates that MPI’s benefits are workload‑dependent and that on ultra‑fast storage the extra validation and data‑rearrangement steps can dominate performance.
MPI Collective I/O vs. Independent I/O (NFS)
Collective I/O adds a data‑shuffle phase where MPI processes exchange data before issuing I/O calls, aiming to reduce the number of I/O operations on slow storage. In the NFS experiments, collective I/O consistently underperforms independent I/O for both Optane and HDD. The authors explain that the data‑shuffle phase incurs network traffic that outweighs any reduction in I/O calls, especially given the already limited network bandwidth. Consequently, the classic assumption that collective I/O is always beneficial does not hold when the storage device is fast but the interconnect is not.
PVFS2 Experiments
The authors then evaluate Optane within the PVFS2 parallel file system, varying three parameters: (a) I/O block size, (b) number of client processes per compute node, and (c) number of I/O nodes.
Block Size: As block size grows, HDD throughput rises steadily, while Optane shows a peak around 120 KB and then a drop at 2 MB, likely due to misalignment across multiple I/O nodes.
Clients per Compute Node: Optane scales well; increasing clients from 1 to 24 yields a near‑linear increase in write bandwidth. HDD, by contrast, plateaus early, indicating that Optane’s higher per‑node bandwidth can be fully exploited when enough parallel clients are present.
I/O Nodes: Adding I/O nodes improves both devices, but Optane’s bandwidth improves by less than 15 % whereas HDD’s improves by 2.6×. This suggests that for Optane the storage subsystem is no longer the bottleneck; network and PVFS2 metadata handling dominate.
Collective vs. Independent I/O in PVFS2: Unlike the NFS case, collective I/O now outperforms independent I/O for both Optane and HDD. PVFS2 incorporates internal optimizations (e.g., aggregation of network messages) that reduce the cost of the data‑shuffle phase, allowing the benefits of collective I/O to manifest.
Key Insights
- Device‑Level Superiority: Optane provides an order‑of‑magnitude improvement over HDD in raw bandwidth, with negligible difference between random and sequential accesses.
- Network‑Centric Bottleneck: In typical HPC clusters using 10 GbE, the network latency and bandwidth dominate end‑to‑end I/O performance, limiting the observable gains from fast storage.
- MPI Overhead Re‑Evaluation: MPI‑IO’s validation and data‑rearrangement overhead becomes significant on fast storage; independent I/O may be preferable for small task counts, while collective I/O’s advantage depends heavily on the underlying interconnect and file‑system implementation.
- Parallel File System Interaction: PVFS2’s internal communication optimizations can revive the usefulness of collective I/O even with fast storage, but block‑size alignment and I/O node configuration still affect performance.
- Scalability Considerations: Optane’s high per‑node bandwidth can be fully utilized only when sufficient parallelism (clients, MPI tasks) is present; otherwise the system is limited by network or file‑system metadata paths.
Conclusions
The study demonstrates that Intel Optane SSDs dramatically improve raw storage performance for HPC workloads, yet realizing these gains at the application level requires a holistic redesign of the I/O stack. Network infrastructure, MPI‑IO strategies, and parallel file‑system configurations must be revisited to avoid new bottlenecks that mask the benefits of NVM‑based storage. Future work should explore higher‑speed interconnects (e.g., InfiniBand HDR), direct‑access (DAX) interfaces that bypass the page cache, and file‑system designs that exploit byte‑addressability and low latency of NVM.
Comments & Academic Discussion
Loading comments...
Leave a Comment